from embedding import SecWord2Vec
keywords = ['hello', 'sentence', 'meow']
model = SecWord2Vec(keywords, corpus_file='data/test.txt', min_count=1, size=10, iter=1)
model.train_embed()
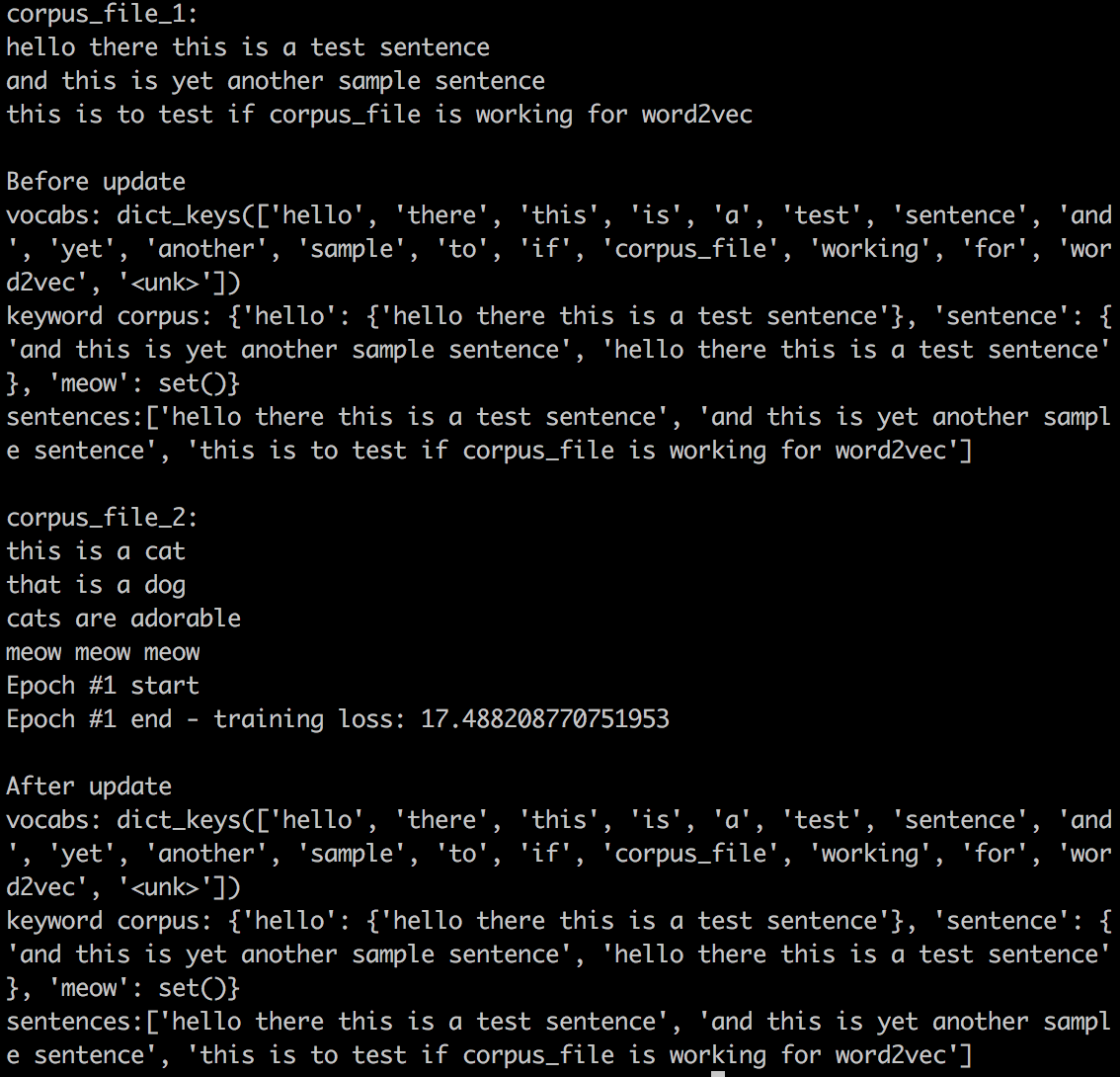
print('corpus_file_1:')
for line in open('data/test.txt'):
print(line.strip())
print('\nBefore update')
print('vocabs: {}'.format(model.wv.vocab.keys()))
print('keyword corpus: {}'.format(model.kc))
print('sentences:{}'.format(model.sentences))
print('\ncorpus_file_2:')
for line in open('data/test_2.txt'):
print(line.strip())
model.train_embed(corpus_file='data/test_2.txt')
print('\nAfter update')
print('vocabs: {}'.format(model.wv.vocab.keys()))
print('keyword corpus: {}'.format(model.kc))
print('sentences:{}'.format(model.sentences))
Test code:
Output: