diff --git a/.gitignore b/.gitignore
index dce8600..6ac18e3 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,7 @@
+.DS_Store
+*.pyc
+__pycache__
+
# Created by .ignore support plugin (hsz.mobi)
### Python template
# Byte-compiled / optimized / DLL files
diff --git a/README.md b/README.md
index d9b05e9..e11fbf2 100644
--- a/README.md
+++ b/README.md
@@ -1,13 +1,20 @@
## Date Calculator
-Hello there!
-I needed a bit of motivation to learn Python and Alfred workflows, so I thought I’d kill two horses with one bullet, so to speak.
-Right, so this is a date calculator – kind of. It won’t tell you when you will the lottery, or how long you’ve got to hide your ‘arty videos’ before your wife gets home, but it will answer one or two _very simple_ questions about dates.
-
+Does simple stuff with dates! 🗓️
-(Download from [Packal.org](http://www.packal.org/workflow/date-calculator))
+Original by [@MuppetGate](https://github.com/MuppetGate)
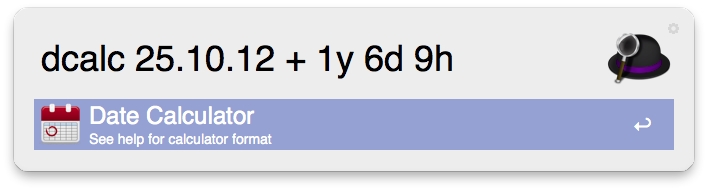
-For example, if you enter
+Ported to Python 3 and Alfred 5
+
+
+
+
+![Downloads]()
+
+
+
+For example, if you enter:
**dcalc 25.12.14 - 18.01.14**
@@ -225,43 +232,17 @@ A list of things that made my first attempt at Python programming possible:
- And finally, and by no means least – Mr Smirnoff for discovering how to bottle patience.
### Version History
-(Version 2.7) - Removed the exclude stuff. It wasn't very reliable and was very hard to explain. Also fixed a problem which caused incorrect date calculuations if the input phrase was right at the end of the month.
-
-(Version 2.4) - Bugt fixes. Added abbreviations. Added functions for Pancake Day, Lent and Martin Luther King Day
-
-(Version 2.3) - Bug fixes. Reworked the auto formatting. You can now apply exclusions to date calculations as well as timespan calculations.
-Added function to return the date when given a year, a week number and an optional day of the week.
-
-(Version 2.1) - Bug fixes. Made the default formatting a little bit more intelligent.
-
-Latest release (Version 2.0). Refactoring. Added a natural date language parser. Added support for 12-hour clock. Added function to get date of the next passover
-
-Latest release (Version 1.6). Refactoring. Added exclusion functionality, and macros for _year start_ and _year end_. Changed the calls for days of the week: You now need to enter _next mon_ to get the date for next Monday, but you can also now type _prev mon_ to get the date for last Monday. Huzzah!
-Increased the accuracy of the date intervals. If you select _y_ for the date format then you will get _11.5 years_. But if you select _ym_ then you get _11 years, 6 months_. Trust me, it’s better this way.
-
-Latest release (Version 1.5). Refactoring. Rewrote the code for date subtraction arithmetic.
-Now it’s a lot more accurate, even when working with uneven months and weeks. Minor bug fixes.
-
-Last release (Version 1.4) Fixed bug that caused inaccuracies when calculating anniversaries.
-Refactored code to make it easier to add new date functions and date formatters. General tidy-up
-
-Last release (Version 1.3) Adds extra formatting functions (day of week) and bug fixes.
-
-Last release (Version 1.2) was an improvement to add user-defined macros.
-
-Last release (Version 1.1) was on the 01.07.2014. This included a new anniversary list function,
-and the addition of the international date format (yyyy-mm-dd).
+- 4.1 Alfred 5 version
+- 4.0.1 added new date format (`d.m.yyyy`)
+- 4.0 ported to Python 3
-Last release (Version 1.0) was on the 27.06.2014. This included an improved date parser,
-added macros (days of week, christmas and easter) and a general tidy up.
-The symbol for getting the week number for a particular date has changed
-from ‘^’ to ‘!’ or ‘wn’. Why? Because I seemed to be struggling to find ‘^’ on the keyboard.
### License
Well, I guess the [MIT](http://opensource.org/licenses/MIT) one will do. :-)
-The MIT License (MIT)
-Copyright (c) 2014 MuppetGate Media
+#### The MIT License (MIT)
+- Copyright (c) 2014 MuppetGate Media
+- Copyright (c) 2022 Giovanni Coppola
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
diff --git a/arrow/__init__.py b/arrow/__init__.py
deleted file mode 100644
index 916297a..0000000
--- a/arrow/__init__.py
+++ /dev/null
@@ -1,8 +0,0 @@
-# -*- coding: utf-8 -*-
-
-from .arrow import Arrow
-from .factory import ArrowFactory
-from .api import get, now, utcnow
-
-__version__ = '0.8.0'
-VERSION = __version__
diff --git a/arrow/api.py b/arrow/api.py
deleted file mode 100644
index 495eef4..0000000
--- a/arrow/api.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# -*- coding: utf-8 -*-
-'''
-Provides the default implementation of :class:`ArrowFactory `
-methods for use as a module API.
-
-'''
-
-from __future__ import absolute_import
-
-from arrow.factory import ArrowFactory
-
-
-# internal default factory.
-_factory = ArrowFactory()
-
-
-def get(*args, **kwargs):
- ''' Implements the default :class:`ArrowFactory `
- ``get`` method.
-
- '''
-
- return _factory.get(*args, **kwargs)
-
-def utcnow():
- ''' Implements the default :class:`ArrowFactory `
- ``utcnow`` method.
-
- '''
-
- return _factory.utcnow()
-
-
-def now(tz=None):
- ''' Implements the default :class:`ArrowFactory `
- ``now`` method.
-
- '''
-
- return _factory.now(tz)
-
-
-def factory(type):
- ''' Returns an :class:`.ArrowFactory` for the specified :class:`Arrow `
- or derived type.
-
- :param type: the type, :class:`Arrow ` or derived.
-
- '''
-
- return ArrowFactory(type)
-
-
-__all__ = ['get', 'utcnow', 'now', 'factory', 'iso']
-
diff --git a/arrow/arrow.py b/arrow/arrow.py
deleted file mode 100644
index b17c435..0000000
--- a/arrow/arrow.py
+++ /dev/null
@@ -1,912 +0,0 @@
-# -*- coding: utf-8 -*-
-'''
-Provides the :class:`Arrow ` class, an enhanced ``datetime``
-replacement.
-
-'''
-
-from __future__ import absolute_import
-
-from datetime import datetime, timedelta, tzinfo
-from dateutil import tz as dateutil_tz
-from dateutil.relativedelta import relativedelta
-import calendar
-import sys
-
-from arrow import util, locales, parser, formatter
-
-
-class Arrow(object):
- '''An :class:`Arrow ` object.
-
- Implements the ``datetime`` interface, behaving as an aware ``datetime`` while implementing
- additional functionality.
-
- :param year: the calendar year.
- :param month: the calendar month.
- :param day: the calendar day.
- :param hour: (optional) the hour. Defaults to 0.
- :param minute: (optional) the minute, Defaults to 0.
- :param second: (optional) the second, Defaults to 0.
- :param microsecond: (optional) the microsecond. Defaults 0.
- :param tzinfo: (optional) the ``tzinfo`` object. Defaults to ``None``.
-
- If tzinfo is None, it is assumed to be UTC on creation.
-
- Usage::
-
- >>> import arrow
- >>> arrow.Arrow(2013, 5, 5, 12, 30, 45)
-
-
- '''
-
- resolution = datetime.resolution
-
- _ATTRS = ['year', 'month', 'day', 'hour', 'minute', 'second', 'microsecond']
- _ATTRS_PLURAL = ['{0}s'.format(a) for a in _ATTRS]
- _MONTHS_PER_QUARTER = 3
-
- def __init__(self, year, month, day, hour=0, minute=0, second=0, microsecond=0,
- tzinfo=None):
-
- if util.isstr(tzinfo):
- tzinfo = parser.TzinfoParser.parse(tzinfo)
- tzinfo = tzinfo or dateutil_tz.tzutc()
-
- self._datetime = datetime(year, month, day, hour, minute, second,
- microsecond, tzinfo)
-
-
- # factories: single object, both original and from datetime.
-
- @classmethod
- def now(cls, tzinfo=None):
- '''Constructs an :class:`Arrow ` object, representing "now".
-
- :param tzinfo: (optional) a ``tzinfo`` object. Defaults to local time.
-
- '''
-
- utc = datetime.utcnow().replace(tzinfo=dateutil_tz.tzutc())
- dt = utc.astimezone(dateutil_tz.tzlocal() if tzinfo is None else tzinfo)
-
- return cls(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, dt.tzinfo)
-
- @classmethod
- def utcnow(cls):
- ''' Constructs an :class:`Arrow ` object, representing "now" in UTC
- time.
-
- '''
-
- dt = datetime.utcnow()
-
- return cls(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, dateutil_tz.tzutc())
-
- @classmethod
- def fromtimestamp(cls, timestamp, tzinfo=None):
- ''' Constructs an :class:`Arrow ` object from a timestamp.
-
- :param timestamp: an ``int`` or ``float`` timestamp, or a ``str`` that converts to either.
- :param tzinfo: (optional) a ``tzinfo`` object. Defaults to local time.
-
- '''
-
- tzinfo = tzinfo or dateutil_tz.tzlocal()
- timestamp = cls._get_timestamp_from_input(timestamp)
- dt = datetime.fromtimestamp(timestamp, tzinfo)
-
- return cls(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, tzinfo)
-
- @classmethod
- def utcfromtimestamp(cls, timestamp):
- '''Constructs an :class:`Arrow ` object from a timestamp, in UTC time.
-
- :param timestamp: an ``int`` or ``float`` timestamp, or a ``str`` that converts to either.
-
- '''
-
- timestamp = cls._get_timestamp_from_input(timestamp)
- dt = datetime.utcfromtimestamp(timestamp)
-
- return cls(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, dateutil_tz.tzutc())
-
- @classmethod
- def fromdatetime(cls, dt, tzinfo=None):
- ''' Constructs an :class:`Arrow ` object from a ``datetime`` and optional
- ``tzinfo`` object.
-
- :param dt: the ``datetime``
- :param tzinfo: (optional) a ``tzinfo`` object. Defaults to UTC.
-
- '''
-
- tzinfo = tzinfo or dt.tzinfo or dateutil_tz.tzutc()
-
- return cls(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, tzinfo)
-
- @classmethod
- def fromdate(cls, date, tzinfo=None):
- ''' Constructs an :class:`Arrow ` object from a ``date`` and optional
- ``tzinfo`` object. Time values are set to 0.
-
- :param date: the ``date``
- :param tzinfo: (optional) a ``tzinfo`` object. Defaults to UTC.
- '''
-
- tzinfo = tzinfo or dateutil_tz.tzutc()
-
- return cls(date.year, date.month, date.day, tzinfo=tzinfo)
-
- @classmethod
- def strptime(cls, date_str, fmt, tzinfo=None):
- ''' Constructs an :class:`Arrow ` object from a date string and format,
- in the style of ``datetime.strptime``.
-
- :param date_str: the date string.
- :param fmt: the format string.
- :param tzinfo: (optional) an optional ``tzinfo``
- '''
-
- dt = datetime.strptime(date_str, fmt)
- tzinfo = tzinfo or dt.tzinfo
-
- return cls(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, tzinfo)
-
-
- # factories: ranges and spans
-
- @classmethod
- def range(cls, frame, start, end=None, tz=None, limit=None):
- ''' Returns an array of :class:`Arrow ` objects, representing
- an iteration of time between two inputs.
-
- :param frame: the timeframe. Can be any ``datetime`` property (day, hour, minute...).
- :param start: A datetime expression, the start of the range.
- :param end: (optional) A datetime expression, the end of the range.
- :param tz: (optional) A timezone expression. Defaults to UTC.
- :param limit: (optional) A maximum number of tuples to return.
-
- **NOTE**: the **end** or **limit** must be provided. Call with **end** alone to
- return the entire range, with **limit** alone to return a maximum # of results from the
- start, and with both to cap a range at a maximum # of results.
-
- Supported frame values: year, quarter, month, week, day, hour, minute, second
-
- Recognized datetime expressions:
-
- - An :class:`Arrow ` object.
- - A ``datetime`` object.
-
- Recognized timezone expressions:
-
- - A ``tzinfo`` object.
- - A ``str`` describing a timezone, similar to 'US/Pacific', or 'Europe/Berlin'.
- - A ``str`` in ISO-8601 style, as in '+07:00'.
- - A ``str``, one of the following: 'local', 'utc', 'UTC'.
-
- Usage:
-
- >>> start = datetime(2013, 5, 5, 12, 30)
- >>> end = datetime(2013, 5, 5, 17, 15)
- >>> for r in arrow.Arrow.range('hour', start, end):
- ... print repr(r)
- ...
-
-
-
-
-
-
- '''
-
- _, frame_relative, relative_steps = cls._get_frames(frame)
-
- tzinfo = cls._get_tzinfo(start.tzinfo if tz is None else tz)
-
- start = cls._get_datetime(start).replace(tzinfo=tzinfo)
- end, limit = cls._get_iteration_params(end, limit)
- end = cls._get_datetime(end).replace(tzinfo=tzinfo)
-
- current = cls.fromdatetime(start)
- results = []
-
- while current <= end and len(results) < limit:
- results.append(current)
-
- values = [getattr(current, f) for f in cls._ATTRS]
- current = cls(*values, tzinfo=tzinfo) + relativedelta(**{frame_relative: relative_steps})
-
- return results
-
-
- @classmethod
- def span_range(cls, frame, start, end, tz=None, limit=None):
- ''' Returns an array of tuples, each :class:`Arrow ` objects,
- representing a series of timespans between two inputs.
-
- :param frame: the timeframe. Can be any ``datetime`` property (day, hour, minute...).
- :param start: A datetime expression, the start of the range.
- :param end: (optional) A datetime expression, the end of the range.
- :param tz: (optional) A timezone expression. Defaults to UTC.
- :param limit: (optional) A maximum number of tuples to return.
-
- **NOTE**: the **end** or **limit** must be provided. Call with **end** alone to
- return the entire range, with **limit** alone to return a maximum # of results from the
- start, and with both to cap a range at a maximum # of results.
-
- Supported frame values: year, quarter, month, week, day, hour, minute, second
-
- Recognized datetime expressions:
-
- - An :class:`Arrow ` object.
- - A ``datetime`` object.
-
- Recognized timezone expressions:
-
- - A ``tzinfo`` object.
- - A ``str`` describing a timezone, similar to 'US/Pacific', or 'Europe/Berlin'.
- - A ``str`` in ISO-8601 style, as in '+07:00'.
- - A ``str``, one of the following: 'local', 'utc', 'UTC'.
-
- Usage:
-
- >>> start = datetime(2013, 5, 5, 12, 30)
- >>> end = datetime(2013, 5, 5, 17, 15)
- >>> for r in arrow.Arrow.span_range('hour', start, end):
- ... print r
- ...
- (, )
- (, )
- (, )
- (, )
- (, )
-
- '''
- tzinfo = cls._get_tzinfo(start.tzinfo if tz is None else tz)
- start = cls.fromdatetime(start, tzinfo).span(frame)[0]
- _range = cls.range(frame, start, end, tz, limit)
- return [r.span(frame) for r in _range]
-
-
- # representations
-
- def __repr__(self):
-
- dt = self._datetime
- attrs = ', '.join([str(i) for i in [dt.year, dt.month, dt.day, dt.hour, dt.minute,
- dt.second, dt.microsecond]])
-
- return '<{0} [{1}]>'.format(self.__class__.__name__, self.__str__())
-
- def __str__(self):
- return self._datetime.isoformat()
-
- def __format__(self, formatstr):
-
- if len(formatstr) > 0:
- return self.format(formatstr)
-
- return str(self)
-
- def __hash__(self):
- return self._datetime.__hash__()
-
-
- # attributes & properties
-
- def __getattr__(self, name):
-
- if name == 'week':
- return self.isocalendar()[1]
-
- if name == 'quarter':
- return int(self.month/self._MONTHS_PER_QUARTER) + 1
-
- if not name.startswith('_'):
- value = getattr(self._datetime, name, None)
-
- if value is not None:
- return value
-
- return object.__getattribute__(self, name)
-
- @property
- def tzinfo(self):
- ''' Gets the ``tzinfo`` of the :class:`Arrow ` object. '''
-
- return self._datetime.tzinfo
-
- @tzinfo.setter
- def tzinfo(self, tzinfo):
- ''' Sets the ``tzinfo`` of the :class:`Arrow ` object. '''
-
- self._datetime = self._datetime.replace(tzinfo=tzinfo)
-
- @property
- def datetime(self):
- ''' Returns a datetime representation of the :class:`Arrow ` object. '''
-
- return self._datetime
-
- @property
- def naive(self):
- ''' Returns a naive datetime representation of the :class:`Arrow ` object. '''
-
- return self._datetime.replace(tzinfo=None)
-
- @property
- def timestamp(self):
- ''' Returns a timestamp representation of the :class:`Arrow ` object. '''
-
- return calendar.timegm(self._datetime.utctimetuple())
-
- @property
- def float_timestamp(self):
- ''' Returns a floating-point representation of the :class:`Arrow ` object. '''
-
- return self.timestamp + float(self.microsecond) / 1000000
-
-
- # mutation and duplication.
-
- def clone(self):
- ''' Returns a new :class:`Arrow ` object, cloned from the current one.
-
- Usage:
-
- >>> arw = arrow.utcnow()
- >>> cloned = arw.clone()
-
- '''
-
- return self.fromdatetime(self._datetime)
-
- def replace(self, **kwargs):
- ''' Returns a new :class:`Arrow ` object with attributes updated
- according to inputs.
-
- Use single property names to set their value absolutely:
-
- >>> import arrow
- >>> arw = arrow.utcnow()
- >>> arw
-
- >>> arw.replace(year=2014, month=6)
-
-
- Use plural property names to shift their current value relatively:
-
- >>> arw.replace(years=1, months=-1)
-
-
- You can also provide a timezone expression can also be replaced:
-
- >>> arw.replace(tzinfo=tz.tzlocal())
-
-
- Recognized timezone expressions:
-
- - A ``tzinfo`` object.
- - A ``str`` describing a timezone, similar to 'US/Pacific', or 'Europe/Berlin'.
- - A ``str`` in ISO-8601 style, as in '+07:00'.
- - A ``str``, one of the following: 'local', 'utc', 'UTC'.
-
- '''
-
- absolute_kwargs = {}
- relative_kwargs = {}
-
- for key, value in kwargs.items():
-
- if key in self._ATTRS:
- absolute_kwargs[key] = value
- elif key in self._ATTRS_PLURAL or key in ['weeks', 'quarters']:
- relative_kwargs[key] = value
- elif key in ['week', 'quarter']:
- raise AttributeError('setting absolute {0} is not supported'.format(key))
- elif key !='tzinfo':
- raise AttributeError('unknown attribute: "{0}"'.format(key))
-
- # core datetime does not support quarters, translate to months.
- if 'quarters' in relative_kwargs.keys():
- if relative_kwargs.get('months') is None:
- relative_kwargs['months'] = 0
- relative_kwargs['months'] += (value * self._MONTHS_PER_QUARTER)
- relative_kwargs.pop('quarters')
-
- current = self._datetime.replace(**absolute_kwargs)
- current += relativedelta(**relative_kwargs)
-
- tzinfo = kwargs.get('tzinfo')
-
- if tzinfo is not None:
- tzinfo = self._get_tzinfo(tzinfo)
- current = current.replace(tzinfo=tzinfo)
-
- return self.fromdatetime(current)
-
- def to(self, tz):
- ''' Returns a new :class:`Arrow ` object, converted to the target
- timezone.
-
- :param tz: an expression representing a timezone.
-
- Recognized timezone expressions:
-
- - A ``tzinfo`` object.
- - A ``str`` describing a timezone, similar to 'US/Pacific', or 'Europe/Berlin'.
- - A ``str`` in ISO-8601 style, as in '+07:00'.
- - A ``str``, one of the following: 'local', 'utc', 'UTC'.
-
- Usage::
-
- >>> utc = arrow.utcnow()
- >>> utc
-
-
- >>> utc.to('US/Pacific')
-
-
- >>> utc.to(tz.tzlocal())
-
-
- >>> utc.to('-07:00')
-
-
- >>> utc.to('local')
-
-
- >>> utc.to('local').to('utc')
-
-
- '''
-
- if not isinstance(tz, tzinfo):
- tz = parser.TzinfoParser.parse(tz)
-
- dt = self._datetime.astimezone(tz)
-
- return self.__class__(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second,
- dt.microsecond, dt.tzinfo)
-
- def span(self, frame, count=1):
- ''' Returns two new :class:`Arrow ` objects, representing the timespan
- of the :class:`Arrow ` object in a given timeframe.
-
- :param frame: the timeframe. Can be any ``datetime`` property (day, hour, minute...).
- :param count: (optional) the number of frames to span.
-
- Supported frame values: year, quarter, month, week, day, hour, minute, second
-
- Usage::
-
- >>> arrow.utcnow()
-
-
- >>> arrow.utcnow().span('hour')
- (, )
-
- >>> arrow.utcnow().span('day')
- (, )
-
- >>> arrow.utcnow().span('day', count=2)
- (, )
-
- '''
-
- frame_absolute, frame_relative, relative_steps = self._get_frames(frame)
-
- if frame_absolute == 'week':
- attr = 'day'
- elif frame_absolute == 'quarter':
- attr = 'month'
- else:
- attr = frame_absolute
-
- index = self._ATTRS.index(attr)
- frames = self._ATTRS[:index + 1]
-
- values = [getattr(self, f) for f in frames]
-
- for i in range(3 - len(values)):
- values.append(1)
-
- floor = self.__class__(*values, tzinfo=self.tzinfo)
-
- if frame_absolute == 'week':
- floor = floor + relativedelta(days=-(self.isoweekday() - 1))
- elif frame_absolute == 'quarter':
- floor = floor + relativedelta(months=-((self.month - 1) % 3))
-
- ceil = floor + relativedelta(
- **{frame_relative: count * relative_steps}) + relativedelta(microseconds=-1)
-
- return floor, ceil
-
- def floor(self, frame):
- ''' Returns a new :class:`Arrow ` object, representing the "floor"
- of the timespan of the :class:`Arrow ` object in a given timeframe.
- Equivalent to the first element in the 2-tuple returned by
- :func:`span `.
-
- :param frame: the timeframe. Can be any ``datetime`` property (day, hour, minute...).
-
- Usage::
-
- >>> arrow.utcnow().floor('hour')
-
- '''
-
- return self.span(frame)[0]
-
- def ceil(self, frame):
- ''' Returns a new :class:`Arrow ` object, representing the "ceiling"
- of the timespan of the :class:`Arrow ` object in a given timeframe.
- Equivalent to the second element in the 2-tuple returned by
- :func:`span `.
-
- :param frame: the timeframe. Can be any ``datetime`` property (day, hour, minute...).
-
- Usage::
-
- >>> arrow.utcnow().ceil('hour')
-
- '''
-
- return self.span(frame)[1]
-
-
- # string output and formatting.
-
- def format(self, fmt='YYYY-MM-DD HH:mm:ssZZ', locale='en_us'):
- ''' Returns a string representation of the :class:`Arrow ` object,
- formatted according to a format string.
-
- :param fmt: the format string.
-
- Usage::
-
- >>> arrow.utcnow().format('YYYY-MM-DD HH:mm:ss ZZ')
- '2013-05-09 03:56:47 -00:00'
-
- >>> arrow.utcnow().format('X')
- '1368071882'
-
- >>> arrow.utcnow().format('MMMM DD, YYYY')
- 'May 09, 2013'
-
- >>> arrow.utcnow().format()
- '2013-05-09 03:56:47 -00:00'
-
- '''
-
- return formatter.DateTimeFormatter(locale).format(self._datetime, fmt)
-
-
- def humanize(self, other=None, locale='en_us', only_distance=False):
- ''' Returns a localized, humanized representation of a relative difference in time.
-
- :param other: (optional) an :class:`Arrow ` or ``datetime`` object.
- Defaults to now in the current :class:`Arrow ` object's timezone.
- :param locale: (optional) a ``str`` specifying a locale. Defaults to 'en_us'.
- :param only_distance: (optional) returns only time difference eg: "11 seconds" without "in" or "ago" part.
- Usage::
-
- >>> earlier = arrow.utcnow().replace(hours=-2)
- >>> earlier.humanize()
- '2 hours ago'
-
- >>> later = later = earlier.replace(hours=4)
- >>> later.humanize(earlier)
- 'in 4 hours'
-
- '''
-
- locale = locales.get_locale(locale)
-
- if other is None:
- utc = datetime.utcnow().replace(tzinfo=dateutil_tz.tzutc())
- dt = utc.astimezone(self._datetime.tzinfo)
-
- elif isinstance(other, Arrow):
- dt = other._datetime
-
- elif isinstance(other, datetime):
- if other.tzinfo is None:
- dt = other.replace(tzinfo=self._datetime.tzinfo)
- else:
- dt = other.astimezone(self._datetime.tzinfo)
-
- else:
- raise TypeError()
-
- delta = int(util.total_seconds(self._datetime - dt))
- sign = -1 if delta < 0 else 1
- diff = abs(delta)
- delta = diff
-
- if diff < 10:
- return locale.describe('now', only_distance=only_distance)
-
- if diff < 45:
- return locale.describe('seconds', sign, only_distance=only_distance)
-
- elif diff < 90:
- return locale.describe('minute', sign, only_distance=only_distance)
- elif diff < 2700:
- minutes = sign * int(max(delta / 60, 2))
- return locale.describe('minutes', minutes, only_distance=only_distance)
-
- elif diff < 5400:
- return locale.describe('hour', sign, only_distance=only_distance)
- elif diff < 79200:
- hours = sign * int(max(delta / 3600, 2))
- return locale.describe('hours', hours, only_distance=only_distance)
-
- elif diff < 129600:
- return locale.describe('day', sign, only_distance=only_distance)
- elif diff < 2160000:
- days = sign * int(max(delta / 86400, 2))
- return locale.describe('days', days, only_distance=only_distance)
-
- elif diff < 3888000:
- return locale.describe('month', sign, only_distance=only_distance)
- elif diff < 29808000:
- self_months = self._datetime.year * 12 + self._datetime.month
- other_months = dt.year * 12 + dt.month
-
- months = sign * int(max(abs(other_months - self_months), 2))
-
- return locale.describe('months', months, only_distance=only_distance)
-
- elif diff < 47260800:
- return locale.describe('year', sign, only_distance=only_distance)
- else:
- years = sign * int(max(delta / 31536000, 2))
- return locale.describe('years', years, only_distance=only_distance)
-
-
- # math
-
- def __add__(self, other):
-
- if isinstance(other, (timedelta, relativedelta)):
- return self.fromdatetime(self._datetime + other, self._datetime.tzinfo)
-
- raise TypeError()
-
- def __radd__(self, other):
- return self.__add__(other)
-
- def __sub__(self, other):
-
- if isinstance(other, timedelta):
- return self.fromdatetime(self._datetime - other, self._datetime.tzinfo)
-
- elif isinstance(other, datetime):
- return self._datetime - other
-
- elif isinstance(other, Arrow):
- return self._datetime - other._datetime
-
- raise TypeError()
-
- def __rsub__(self, other):
-
- if isinstance(other, datetime):
- return other - self._datetime
-
- raise TypeError()
-
-
- # comparisons
-
- def _cmperror(self, other):
- raise TypeError('can\'t compare \'{0}\' to \'{1}\''.format(
- type(self), type(other)))
-
- def __eq__(self, other):
-
- if not isinstance(other, (Arrow, datetime)):
- return False
-
- other = self._get_datetime(other)
-
- return self._datetime == self._get_datetime(other)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __gt__(self, other):
-
- if not isinstance(other, (Arrow, datetime)):
- self._cmperror(other)
-
- return self._datetime > self._get_datetime(other)
-
- def __ge__(self, other):
-
- if not isinstance(other, (Arrow, datetime)):
- self._cmperror(other)
-
- return self._datetime >= self._get_datetime(other)
-
- def __lt__(self, other):
-
- if not isinstance(other, (Arrow, datetime)):
- self._cmperror(other)
-
- return self._datetime < self._get_datetime(other)
-
- def __le__(self, other):
-
- if not isinstance(other, (Arrow, datetime)):
- self._cmperror(other)
-
- return self._datetime <= self._get_datetime(other)
-
-
- # datetime methods
-
- def date(self):
- ''' Returns a ``date`` object with the same year, month and day. '''
-
- return self._datetime.date()
-
- def time(self):
- ''' Returns a ``time`` object with the same hour, minute, second, microsecond. '''
-
- return self._datetime.time()
-
- def timetz(self):
- ''' Returns a ``time`` object with the same hour, minute, second, microsecond and tzinfo. '''
-
- return self._datetime.timetz()
-
- def astimezone(self, tz):
- ''' Returns a ``datetime`` object, adjusted to the specified tzinfo.
-
- :param tz: a ``tzinfo`` object.
-
- '''
-
- return self._datetime.astimezone(tz)
-
- def utcoffset(self):
- ''' Returns a ``timedelta`` object representing the whole number of minutes difference from UTC time. '''
-
- return self._datetime.utcoffset()
-
- def dst(self):
- ''' Returns the daylight savings time adjustment. '''
- return self._datetime.dst()
-
- def timetuple(self):
- ''' Returns a ``time.struct_time``, in the current timezone. '''
-
- return self._datetime.timetuple()
-
- def utctimetuple(self):
- ''' Returns a ``time.struct_time``, in UTC time. '''
-
- return self._datetime.utctimetuple()
-
- def toordinal(self):
- ''' Returns the proleptic Gregorian ordinal of the date. '''
-
- return self._datetime.toordinal()
-
- def weekday(self):
- ''' Returns the day of the week as an integer (0-6). '''
-
- return self._datetime.weekday()
-
- def isoweekday(self):
- ''' Returns the ISO day of the week as an integer (1-7). '''
-
- return self._datetime.isoweekday()
-
- def isocalendar(self):
- ''' Returns a 3-tuple, (ISO year, ISO week number, ISO weekday). '''
-
- return self._datetime.isocalendar()
-
- def isoformat(self, sep='T'):
- '''Returns an ISO 8601 formatted representation of the date and time. '''
-
- return self._datetime.isoformat(sep)
-
- def ctime(self):
- ''' Returns a ctime formatted representation of the date and time. '''
-
- return self._datetime.ctime()
-
- def strftime(self, format):
- ''' Formats in the style of ``datetime.strptime``.
-
- :param format: the format string.
-
- '''
-
- return self._datetime.strftime(format)
-
- def for_json(self):
- '''Serializes for the ``for_json`` protocol of simplejson.'''
- return self.isoformat()
-
- # internal tools.
-
- @staticmethod
- def _get_tzinfo(tz_expr):
-
- if tz_expr is None:
- return dateutil_tz.tzutc()
- if isinstance(tz_expr, tzinfo):
- return tz_expr
- else:
- try:
- return parser.TzinfoParser.parse(tz_expr)
- except parser.ParserError:
- raise ValueError('\'{0}\' not recognized as a timezone'.format(
- tz_expr))
-
- @classmethod
- def _get_datetime(cls, expr):
-
- if isinstance(expr, Arrow):
- return expr.datetime
-
- if isinstance(expr, datetime):
- return expr
-
- try:
- expr = float(expr)
- return cls.utcfromtimestamp(expr).datetime
- except:
- raise ValueError(
- '\'{0}\' not recognized as a timestamp or datetime'.format(expr))
-
- @classmethod
- def _get_frames(cls, name):
-
- if name in cls._ATTRS:
- return name, '{0}s'.format(name), 1
-
- elif name in ['week', 'weeks']:
- return 'week', 'weeks', 1
- elif name in ['quarter', 'quarters']:
- return 'quarter', 'months', 3
-
- raise AttributeError()
-
- @classmethod
- def _get_iteration_params(cls, end, limit):
-
- if end is None:
-
- if limit is None:
- raise Exception('one of \'end\' or \'limit\' is required')
-
- return cls.max, limit
-
- else:
- return end, sys.maxsize
-
- @staticmethod
- def _get_timestamp_from_input(timestamp):
-
- try:
- return float(timestamp)
- except:
- raise ValueError('cannot parse \'{0}\' as a timestamp'.format(timestamp))
-
-Arrow.min = Arrow.fromdatetime(datetime.min)
-Arrow.max = Arrow.fromdatetime(datetime.max)
diff --git a/arrow/factory.py b/arrow/factory.py
deleted file mode 100644
index a5d690b..0000000
--- a/arrow/factory.py
+++ /dev/null
@@ -1,254 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-Implements the :class:`ArrowFactory ` class,
-providing factory methods for common :class:`Arrow `
-construction scenarios.
-
-"""
-
-from __future__ import absolute_import
-
-from arrow.arrow import Arrow
-from arrow import parser
-from arrow.util import is_timestamp, isstr
-
-from datetime import datetime, tzinfo, date
-from dateutil import tz as dateutil_tz
-from time import struct_time
-import calendar
-
-
-class ArrowFactory(object):
- ''' A factory for generating :class:`Arrow ` objects.
-
- :param type: (optional) the :class:`Arrow `-based class to construct from.
- Defaults to :class:`Arrow `.
-
- '''
-
- def __init__(self, type=Arrow):
- self.type = type
-
- def get(self, *args, **kwargs):
- ''' Returns an :class:`Arrow ` object based on flexible inputs.
-
- Usage::
-
- >>> import arrow
-
- **No inputs** to get current UTC time::
-
- >>> arrow.get()
-
-
- **None** to also get current UTC time::
-
- >>> arrow.get(None)
-
-
- **One** :class:`Arrow ` object, to get a copy.
-
- >>> arw = arrow.utcnow()
- >>> arrow.get(arw)
-
-
- **One** ``str``, ``float``, or ``int``, convertible to a floating-point timestamp, to get that timestamp in UTC::
-
- >>> arrow.get(1367992474.293378)
-
-
- >>> arrow.get(1367992474)
-
-
- >>> arrow.get('1367992474.293378')
-
-
- >>> arrow.get('1367992474')
-
-
- **One** ISO-8601-formatted ``str``, to parse it::
-
- >>> arrow.get('2013-09-29T01:26:43.830580')
-
-
- **One** ``tzinfo``, to get the current time in that timezone::
-
- >>> arrow.get(tz.tzlocal())
-
-
- **One** naive ``datetime``, to get that datetime in UTC::
-
- >>> arrow.get(datetime(2013, 5, 5))
-
-
- **One** aware ``datetime``, to get that datetime::
-
- >>> arrow.get(datetime(2013, 5, 5, tzinfo=tz.tzlocal()))
-
-
- **One** naive ``date``, to get that date in UTC::
-
- >>> arrow.get(date(2013, 5, 5))
-
-
- **Two** arguments, a naive or aware ``datetime``, and a timezone expression (as above)::
-
- >>> arrow.get(datetime(2013, 5, 5), 'US/Pacific')
-
-
- **Two** arguments, a naive ``date``, and a timezone expression (as above)::
-
- >>> arrow.get(date(2013, 5, 5), 'US/Pacific')
-
-
- **Two** arguments, both ``str``, to parse the first according to the format of the second::
-
- >>> arrow.get('2013-05-05 12:30:45', 'YYYY-MM-DD HH:mm:ss')
-
-
- **Two** arguments, first a ``str`` to parse and second a ``list`` of formats to try::
-
- >>> arrow.get('2013-05-05 12:30:45', ['MM/DD/YYYY', 'YYYY-MM-DD HH:mm:ss'])
-
-
- **Three or more** arguments, as for the constructor of a ``datetime``::
-
- >>> arrow.get(2013, 5, 5, 12, 30, 45)
-
-
- **One** time.struct time::
- >>> arrow.get(gmtime(0))
-
-
- '''
-
- arg_count = len(args)
- locale = kwargs.get('locale', 'en_us')
- tz = kwargs.get('tzinfo', None)
-
- # () -> now, @ utc.
- if arg_count == 0:
- if isinstance(tz, tzinfo):
- return self.type.now(tz)
- return self.type.utcnow()
-
- if arg_count == 1:
- arg = args[0]
-
- # (None) -> now, @ utc.
- if arg is None:
- return self.type.utcnow()
-
- # try (int, float, str(int), str(float)) -> utc, from timestamp.
- if is_timestamp(arg):
- return self.type.utcfromtimestamp(arg)
-
- # (Arrow) -> from the object's datetime.
- if isinstance(arg, Arrow):
- return self.type.fromdatetime(arg.datetime)
-
- # (datetime) -> from datetime.
- if isinstance(arg, datetime):
- return self.type.fromdatetime(arg)
-
- # (date) -> from date.
- if isinstance(arg, date):
- return self.type.fromdate(arg)
-
- # (tzinfo) -> now, @ tzinfo.
- elif isinstance(arg, tzinfo):
- return self.type.now(arg)
-
- # (str) -> now, @ tzinfo.
- elif isstr(arg):
- dt = parser.DateTimeParser(locale).parse_iso(arg)
- return self.type.fromdatetime(dt)
-
- # (struct_time) -> from struct_time
- elif isinstance(arg, struct_time):
- return self.type.utcfromtimestamp(calendar.timegm(arg))
-
- else:
- raise TypeError('Can\'t parse single argument type of \'{0}\''.format(type(arg)))
-
- elif arg_count == 2:
-
- arg_1, arg_2 = args[0], args[1]
-
- if isinstance(arg_1, datetime):
-
- # (datetime, tzinfo) -> fromdatetime @ tzinfo/string.
- if isinstance(arg_2, tzinfo) or isstr(arg_2):
- return self.type.fromdatetime(arg_1, arg_2)
- else:
- raise TypeError('Can\'t parse two arguments of types \'datetime\', \'{0}\''.format(
- type(arg_2)))
-
- # (date, tzinfo/str) -> fromdate @ tzinfo/string.
- elif isinstance(arg_1, date):
-
- if isinstance(arg_2, tzinfo) or isstr(arg_2):
- return self.type.fromdate(arg_1, tzinfo=arg_2)
- else:
- raise TypeError('Can\'t parse two arguments of types \'date\', \'{0}\''.format(
- type(arg_2)))
-
- # (str, format) -> parse.
- elif isstr(arg_1) and (isstr(arg_2) or isinstance(arg_2, list)):
- dt = parser.DateTimeParser(locale).parse(args[0], args[1])
- return self.type.fromdatetime(dt, tzinfo=tz)
-
- else:
- raise TypeError('Can\'t parse two arguments of types \'{0}\', \'{1}\''.format(
- type(arg_1), type(arg_2)))
-
- # 3+ args -> datetime-like via constructor.
- else:
- return self.type(*args, **kwargs)
-
- def utcnow(self):
- '''Returns an :class:`Arrow ` object, representing "now" in UTC time.
-
- Usage::
-
- >>> import arrow
- >>> arrow.utcnow()
-
- '''
-
- return self.type.utcnow()
-
- def now(self, tz=None):
- '''Returns an :class:`Arrow ` object, representing "now".
-
- :param tz: (optional) An expression representing a timezone. Defaults to local time.
-
- Recognized timezone expressions:
-
- - A ``tzinfo`` object.
- - A ``str`` describing a timezone, similar to 'US/Pacific', or 'Europe/Berlin'.
- - A ``str`` in ISO-8601 style, as in '+07:00'.
- - A ``str``, one of the following: 'local', 'utc', 'UTC'.
-
- Usage::
-
- >>> import arrow
- >>> arrow.now()
-
-
- >>> arrow.now('US/Pacific')
-
-
- >>> arrow.now('+02:00')
-
-
- >>> arrow.now('local')
-
- '''
-
- if tz is None:
- tz = dateutil_tz.tzlocal()
- elif not isinstance(tz, tzinfo):
- tz = parser.TzinfoParser.parse(tz)
-
- return self.type.now(tz)
diff --git a/arrow/formatter.py b/arrow/formatter.py
deleted file mode 100644
index 0ae2389..0000000
--- a/arrow/formatter.py
+++ /dev/null
@@ -1,105 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import absolute_import
-
-import calendar
-import re
-from dateutil import tz as dateutil_tz
-from arrow import util, locales
-
-
-class DateTimeFormatter(object):
-
- _FORMAT_RE = re.compile('(YYY?Y?|MM?M?M?|Do|DD?D?D?|d?dd?d?|HH?|hh?|mm?|ss?|SS?S?S?S?S?|ZZ?|a|A|X)')
-
- def __init__(self, locale='en_us'):
-
- self.locale = locales.get_locale(locale)
-
- def format(cls, dt, fmt):
-
- return cls._FORMAT_RE.sub(lambda m: cls._format_token(dt, m.group(0)), fmt)
-
- def _format_token(self, dt, token):
-
- if token == 'YYYY':
- return self.locale.year_full(dt.year)
- if token == 'YY':
- return self.locale.year_abbreviation(dt.year)
-
- if token == 'MMMM':
- return self.locale.month_name(dt.month)
- if token == 'MMM':
- return self.locale.month_abbreviation(dt.month)
- if token == 'MM':
- return '{0:02d}'.format(dt.month)
- if token == 'M':
- return str(dt.month)
-
- if token == 'DDDD':
- return '{0:03d}'.format(dt.timetuple().tm_yday)
- if token == 'DDD':
- return str(dt.timetuple().tm_yday)
- if token == 'DD':
- return '{0:02d}'.format(dt.day)
- if token == 'D':
- return str(dt.day)
-
- if token == 'Do':
- return self.locale.ordinal_number(dt.day)
-
- if token == 'dddd':
- return self.locale.day_name(dt.isoweekday())
- if token == 'ddd':
- return self.locale.day_abbreviation(dt.isoweekday())
- if token == 'd':
- return str(dt.isoweekday())
-
- if token == 'HH':
- return '{0:02d}'.format(dt.hour)
- if token == 'H':
- return str(dt.hour)
- if token == 'hh':
- return '{0:02d}'.format(dt.hour if 0 < dt.hour < 13 else abs(dt.hour - 12))
- if token == 'h':
- return str(dt.hour if 0 < dt.hour < 13 else abs(dt.hour - 12))
-
- if token == 'mm':
- return '{0:02d}'.format(dt.minute)
- if token == 'm':
- return str(dt.minute)
-
- if token == 'ss':
- return '{0:02d}'.format(dt.second)
- if token == 's':
- return str(dt.second)
-
- if token == 'SSSSSS':
- return str('{0:06d}'.format(int(dt.microsecond)))
- if token == 'SSSSS':
- return str('{0:05d}'.format(int(dt.microsecond / 10)))
- if token == 'SSSS':
- return str('{0:04d}'.format(int(dt.microsecond / 100)))
- if token == 'SSS':
- return str('{0:03d}'.format(int(dt.microsecond / 1000)))
- if token == 'SS':
- return str('{0:02d}'.format(int(dt.microsecond / 10000)))
- if token == 'S':
- return str(int(dt.microsecond / 100000))
-
- if token == 'X':
- return str(calendar.timegm(dt.utctimetuple()))
-
- if token in ['ZZ', 'Z']:
- separator = ':' if token == 'ZZ' else ''
- tz = dateutil_tz.tzutc() if dt.tzinfo is None else dt.tzinfo
- total_minutes = int(util.total_seconds(tz.utcoffset(dt)) / 60)
-
- sign = '+' if total_minutes > 0 else '-'
- total_minutes = abs(total_minutes)
- hour, minute = divmod(total_minutes, 60)
-
- return '{0}{1:02d}{2}{3:02d}'.format(sign, hour, separator, minute)
-
- if token in ('a', 'A'):
- return self.locale.meridian(dt.hour, token)
-
diff --git a/arrow/locales.py b/arrow/locales.py
deleted file mode 100644
index 5af4267..0000000
--- a/arrow/locales.py
+++ /dev/null
@@ -1,1789 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import inspect
-import sys
-
-
-def get_locale(name):
- '''Returns an appropriate :class:`Locale ` corresponding
- to an inpute locale name.
-
- :param name: the name of the locale.
-
- '''
-
- locale_cls = _locales.get(name.lower())
-
- if locale_cls is None:
- raise ValueError('Unsupported locale \'{0}\''.format(name))
-
- return locale_cls()
-
-
-# base locale type.
-
-class Locale(object):
- ''' Represents locale-specific data and functionality. '''
-
- names = []
-
- timeframes = {
- 'now': '',
- 'seconds': '',
- 'minute': '',
- 'minutes': '',
- 'hour': '',
- 'hours': '',
- 'day': '',
- 'days': '',
- 'month': '',
- 'months': '',
- 'year': '',
- 'years': '',
- }
-
- meridians = {
- 'am': '',
- 'pm': '',
- 'AM': '',
- 'PM': '',
- }
-
- past = None
- future = None
-
- month_names = []
- month_abbreviations = []
-
- day_names = []
- day_abbreviations = []
-
- ordinal_day_re = r'(\d+)'
-
- def __init__(self):
-
- self._month_name_to_ordinal = None
-
- def describe(self, timeframe, delta=0, only_distance=False):
- ''' Describes a delta within a timeframe in plain language.
-
- :param timeframe: a string representing a timeframe.
- :param delta: a quantity representing a delta in a timeframe.
- :param only_distance: return only distance eg: "11 seconds" without "in" or "ago" keywords
- '''
-
- humanized = self._format_timeframe(timeframe, delta)
- if not only_distance:
- humanized = self._format_relative(humanized, timeframe, delta)
-
- return humanized
-
- def day_name(self, day):
- ''' Returns the day name for a specified day of the week.
-
- :param day: the ``int`` day of the week (1-7).
-
- '''
-
- return self.day_names[day]
-
- def day_abbreviation(self, day):
- ''' Returns the day abbreviation for a specified day of the week.
-
- :param day: the ``int`` day of the week (1-7).
-
- '''
-
- return self.day_abbreviations[day]
-
- def month_name(self, month):
- ''' Returns the month name for a specified month of the year.
-
- :param month: the ``int`` month of the year (1-12).
-
- '''
-
- return self.month_names[month]
-
- def month_abbreviation(self, month):
- ''' Returns the month abbreviation for a specified month of the year.
-
- :param month: the ``int`` month of the year (1-12).
-
- '''
-
- return self.month_abbreviations[month]
-
- def month_number(self, name):
- ''' Returns the month number for a month specified by name or abbreviation.
-
- :param name: the month name or abbreviation.
-
- '''
-
- if self._month_name_to_ordinal is None:
- self._month_name_to_ordinal = self._name_to_ordinal(self.month_names)
- self._month_name_to_ordinal.update(self._name_to_ordinal(self.month_abbreviations))
-
- return self._month_name_to_ordinal.get(name)
-
- def year_full(self, year):
- ''' Returns the year for specific locale if available
-
- :param name: the ``int`` year (4-digit)
- '''
- return '{0:04d}'.format(year)
-
- def year_abbreviation(self, year):
- ''' Returns the year for specific locale if available
-
- :param name: the ``int`` year (4-digit)
- '''
- return '{0:04d}'.format(year)[2:]
-
- def meridian(self, hour, token):
- ''' Returns the meridian indicator for a specified hour and format token.
-
- :param hour: the ``int`` hour of the day.
- :param token: the format token.
- '''
-
- if token == 'a':
- return self.meridians['am'] if hour < 12 else self.meridians['pm']
- if token == 'A':
- return self.meridians['AM'] if hour < 12 else self.meridians['PM']
-
- def ordinal_number(self, n):
- ''' Returns the ordinal format of a given integer
-
- :param n: an integer
- '''
- return self._ordinal_number(n)
-
- def _ordinal_number(self, n):
- return '{0}'.format(n)
-
- def _name_to_ordinal(self, lst):
- return dict(map(lambda i: (i[1].lower(), i[0] + 1), enumerate(lst[1:])))
-
- def _format_timeframe(self, timeframe, delta):
-
- return self.timeframes[timeframe].format(abs(delta))
-
- def _format_relative(self, humanized, timeframe, delta):
-
- if timeframe == 'now':
- return humanized
-
- direction = self.past if delta < 0 else self.future
-
- return direction.format(humanized)
-
-
-# base locale type implementations.
-
-class EnglishLocale(Locale):
-
- names = ['en', 'en_us', 'en_gb', 'en_au', 'en_be', 'en_jp', 'en_za', 'en_ca']
-
- past = '{0} ago'
- future = 'in {0}'
-
- timeframes = {
- 'now': 'just now',
- 'seconds': 'seconds',
- 'minute': 'a minute',
- 'minutes': '{0} minutes',
- 'hour': 'an hour',
- 'hours': '{0} hours',
- 'day': 'a day',
- 'days': '{0} days',
- 'month': 'a month',
- 'months': '{0} months',
- 'year': 'a year',
- 'years': '{0} years',
- }
-
- meridians = {
- 'am': 'am',
- 'pm': 'pm',
- 'AM': 'AM',
- 'PM': 'PM',
- }
-
- month_names = ['', 'January', 'February', 'March', 'April', 'May', 'June', 'July',
- 'August', 'September', 'October', 'November', 'December']
- month_abbreviations = ['', 'Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug',
- 'Sep', 'Oct', 'Nov', 'Dec']
-
- day_names = ['', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
- day_abbreviations = ['', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
-
- ordinal_day_re = r'((?P[2-3]?1(?=st)|[2-3]?2(?=nd)|[2-3]?3(?=rd)|[1-3]?[04-9](?=th)|1[1-3](?=th))(st|nd|rd|th))'
-
- def _ordinal_number(self, n):
- if n % 100 not in (11, 12, 13):
- remainder = abs(n) % 10
- if remainder == 1:
- return '{0}st'.format(n)
- elif remainder == 2:
- return '{0}nd'.format(n)
- elif remainder == 3:
- return '{0}rd'.format(n)
- return '{0}th'.format(n)
-
-
-class ItalianLocale(Locale):
- names = ['it', 'it_it']
- past = '{0} fa'
- future = 'tra {0}'
-
- timeframes = {
- 'now': 'adesso',
- 'seconds': 'qualche secondo',
- 'minute': 'un minuto',
- 'minutes': '{0} minuti',
- 'hour': 'un\'ora',
- 'hours': '{0} ore',
- 'day': 'un giorno',
- 'days': '{0} giorni',
- 'month': 'un mese',
- 'months': '{0} mesi',
- 'year': 'un anno',
- 'years': '{0} anni',
- }
-
- month_names = ['', 'gennaio', 'febbraio', 'marzo', 'aprile', 'maggio', 'giugno', 'luglio',
- 'agosto', 'settembre', 'ottobre', 'novembre', 'dicembre']
- month_abbreviations = ['', 'gen', 'feb', 'mar', 'apr', 'mag', 'giu', 'lug', 'ago',
- 'set', 'ott', 'nov', 'dic']
-
- day_names = ['', 'lunedì', 'martedì', 'mercoledì', 'giovedì', 'venerdì', 'sabato', 'domenica']
- day_abbreviations = ['', 'lun', 'mar', 'mer', 'gio', 'ven', 'sab', 'dom']
-
- ordinal_day_re = r'((?P[1-3]?[0-9](?=[ºª]))[ºª])'
-
- def _ordinal_number(self, n):
- return '{0}º'.format(n)
-
-
-class SpanishLocale(Locale):
- names = ['es', 'es_es']
- past = 'hace {0}'
- future = 'en {0}'
-
- timeframes = {
- 'now': 'ahora',
- 'seconds': 'segundos',
- 'minute': 'un minuto',
- 'minutes': '{0} minutos',
- 'hour': 'una hora',
- 'hours': '{0} horas',
- 'day': 'un día',
- 'days': '{0} días',
- 'month': 'un mes',
- 'months': '{0} meses',
- 'year': 'un año',
- 'years': '{0} años',
- }
-
- month_names = ['', 'enero', 'febrero', 'marzo', 'abril', 'mayo', 'junio', 'julio',
- 'agosto', 'septiembre', 'octubre', 'noviembre', 'diciembre']
- month_abbreviations = ['', 'ene', 'feb', 'mar', 'abr', 'may', 'jun', 'jul', 'ago',
- 'sep', 'oct', 'nov', 'dic']
-
- day_names = ['', 'lunes', 'martes', 'miércoles', 'jueves', 'viernes', 'sábado', 'domingo']
- day_abbreviations = ['', 'lun', 'mar', 'mie', 'jue', 'vie', 'sab', 'dom']
-
- ordinal_day_re = r'((?P[1-3]?[0-9](?=[ºª]))[ºª])'
-
- def _ordinal_number(self, n):
- return '{0}º'.format(n)
-
-
-class FrenchLocale(Locale):
- names = ['fr', 'fr_fr']
- past = 'il y a {0}'
- future = 'dans {0}'
-
- timeframes = {
- 'now': 'maintenant',
- 'seconds': 'quelques secondes',
- 'minute': 'une minute',
- 'minutes': '{0} minutes',
- 'hour': 'une heure',
- 'hours': '{0} heures',
- 'day': 'un jour',
- 'days': '{0} jours',
- 'month': 'un mois',
- 'months': '{0} mois',
- 'year': 'un an',
- 'years': '{0} ans',
- }
-
- month_names = ['', 'janvier', 'février', 'mars', 'avril', 'mai', 'juin', 'juillet',
- 'août', 'septembre', 'octobre', 'novembre', 'décembre']
- month_abbreviations = ['', 'janv', 'févr', 'mars', 'avr', 'mai', 'juin', 'juil', 'août',
- 'sept', 'oct', 'nov', 'déc']
-
- day_names = ['', 'lundi', 'mardi', 'mercredi', 'jeudi', 'vendredi', 'samedi', 'dimanche']
- day_abbreviations = ['', 'lun', 'mar', 'mer', 'jeu', 'ven', 'sam', 'dim']
-
- ordinal_day_re = r'((?P\b1(?=er\b)|[1-3]?[02-9](?=e\b)|[1-3]1(?=e\b))(er|e)\b)'
-
- def _ordinal_number(self, n):
- if abs(n) == 1:
- return '{0}er'.format(n)
- return '{0}e'.format(n)
-
-
-class GreekLocale(Locale):
-
- names = ['el', 'el_gr']
-
- past = '{0} πριν'
- future = 'σε {0}'
-
- timeframes = {
- 'now': 'τώρα',
- 'seconds': 'δευτερόλεπτα',
- 'minute': 'ένα λεπτό',
- 'minutes': '{0} λεπτά',
- 'hour': 'μια ώρα',
- 'hours': '{0} ώρες',
- 'day': 'μια μέρα',
- 'days': '{0} μέρες',
- 'month': 'ένα μήνα',
- 'months': '{0} μήνες',
- 'year': 'ένα χρόνο',
- 'years': '{0} χρόνια',
- }
-
- month_names = ['', 'Ιανουαρίου', 'Φεβρουαρίου', 'Μαρτίου', 'Απριλίου', 'Μαΐου', 'Ιουνίου',
- 'Ιουλίου', 'Αυγούστου', 'Σεπτεμβρίου', 'Οκτωβρίου', 'Νοεμβρίου', 'Δεκεμβρίου']
- month_abbreviations = ['', 'Ιαν', 'Φεβ', 'Μαρ', 'Απρ', 'Μαϊ', 'Ιον', 'Ιολ', 'Αυγ',
- 'Σεπ', 'Οκτ', 'Νοε', 'Δεκ']
-
- day_names = ['', 'Δευτέρα', 'Τρίτη', 'Τετάρτη', 'Πέμπτη', 'Παρασκευή', 'Σάββατο', 'Κυριακή']
- day_abbreviations = ['', 'Δευ', 'Τρι', 'Τετ', 'Πεμ', 'Παρ', 'Σαβ', 'Κυρ']
-
-
-class JapaneseLocale(Locale):
-
- names = ['ja', 'ja_jp']
-
- past = '{0}前'
- future = '{0}後'
-
- timeframes = {
- 'now': '現在',
- 'seconds': '数秒',
- 'minute': '1分',
- 'minutes': '{0}分',
- 'hour': '1時間',
- 'hours': '{0}時間',
- 'day': '1日',
- 'days': '{0}日',
- 'month': '1ヶ月',
- 'months': '{0}ヶ月',
- 'year': '1年',
- 'years': '{0}年',
- }
-
- month_names = ['', '1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月',
- '9月', '10月', '11月', '12月']
- month_abbreviations = ['', ' 1', ' 2', ' 3', ' 4', ' 5', ' 6', ' 7', ' 8',
- ' 9', '10', '11', '12']
-
- day_names = ['', '月曜日', '火曜日', '水曜日', '木曜日', '金曜日', '土曜日', '日曜日']
- day_abbreviations = ['', '月', '火', '水', '木', '金', '土', '日']
-
-
-class SwedishLocale(Locale):
-
- names = ['sv', 'sv_se']
-
- past = 'för {0} sen'
- future = 'om {0}'
-
- timeframes = {
- 'now': 'just nu',
- 'seconds': 'några sekunder',
- 'minute': 'en minut',
- 'minutes': '{0} minuter',
- 'hour': 'en timme',
- 'hours': '{0} timmar',
- 'day': 'en dag',
- 'days': '{0} dagar',
- 'month': 'en månad',
- 'months': '{0} månader',
- 'year': 'ett år',
- 'years': '{0} år',
- }
-
- month_names = ['', 'januari', 'februari', 'mars', 'april', 'maj', 'juni', 'juli',
- 'augusti', 'september', 'oktober', 'november', 'december']
- month_abbreviations = ['', 'jan', 'feb', 'mar', 'apr', 'maj', 'jun', 'jul',
- 'aug', 'sep', 'okt', 'nov', 'dec']
-
- day_names = ['', 'måndag', 'tisdag', 'onsdag', 'torsdag', 'fredag', 'lördag', 'söndag']
- day_abbreviations = ['', 'mån', 'tis', 'ons', 'tor', 'fre', 'lör', 'sön']
-
-
-class FinnishLocale(Locale):
-
- names = ['fi', 'fi_fi']
-
- # The finnish grammar is very complex, and its hard to convert
- # 1-to-1 to something like English.
-
- past = '{0} sitten'
- future = '{0} kuluttua'
-
- timeframes = {
- 'now': ['juuri nyt', 'juuri nyt'],
- 'seconds': ['muutama sekunti', 'muutaman sekunnin'],
- 'minute': ['minuutti', 'minuutin'],
- 'minutes': ['{0} minuuttia', '{0} minuutin'],
- 'hour': ['tunti', 'tunnin'],
- 'hours': ['{0} tuntia', '{0} tunnin'],
- 'day': ['päivä', 'päivä'],
- 'days': ['{0} päivää', '{0} päivän'],
- 'month': ['kuukausi', 'kuukauden'],
- 'months': ['{0} kuukautta', '{0} kuukauden'],
- 'year': ['vuosi', 'vuoden'],
- 'years': ['{0} vuotta', '{0} vuoden'],
- }
-
- # Months and days are lowercase in Finnish
- month_names = ['', 'tammikuu', 'helmikuu', 'maaliskuu', 'huhtikuu',
- 'toukokuu', 'kesäkuu', 'heinäkuu', 'elokuu',
- 'syyskuu', 'lokakuu', 'marraskuu', 'joulukuu']
-
- month_abbreviations = ['', 'tammi', 'helmi', 'maalis', 'huhti',
- 'touko', 'kesä', 'heinä', 'elo',
- 'syys', 'loka', 'marras', 'joulu']
-
- day_names = ['', 'maanantai', 'tiistai', 'keskiviikko', 'torstai',
- 'perjantai', 'lauantai', 'sunnuntai']
-
- day_abbreviations = ['', 'ma', 'ti', 'ke', 'to', 'pe', 'la', 'su']
-
- def _format_timeframe(self, timeframe, delta):
- return (self.timeframes[timeframe][0].format(abs(delta)),
- self.timeframes[timeframe][1].format(abs(delta)))
-
- def _format_relative(self, humanized, timeframe, delta):
- if timeframe == 'now':
- return humanized[0]
-
- direction = self.past if delta < 0 else self.future
- which = 0 if delta < 0 else 1
-
- return direction.format(humanized[which])
-
- def _ordinal_number(self, n):
- return '{0}.'.format(n)
-
-
-class ChineseCNLocale(Locale):
-
- names = ['zh', 'zh_cn']
-
- past = '{0}前'
- future = '{0}后'
-
- timeframes = {
- 'now': '刚才',
- 'seconds': '几秒',
- 'minute': '1分钟',
- 'minutes': '{0}分钟',
- 'hour': '1小时',
- 'hours': '{0}小时',
- 'day': '1天',
- 'days': '{0}天',
- 'month': '1个月',
- 'months': '{0}个月',
- 'year': '1年',
- 'years': '{0}年',
- }
-
- month_names = ['', '一月', '二月', '三月', '四月', '五月', '六月', '七月',
- '八月', '九月', '十月', '十一月', '十二月']
- month_abbreviations = ['', ' 1', ' 2', ' 3', ' 4', ' 5', ' 6', ' 7', ' 8',
- ' 9', '10', '11', '12']
-
- day_names = ['', '星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日']
- day_abbreviations = ['', '一', '二', '三', '四', '五', '六', '日']
-
-
-class ChineseTWLocale(Locale):
-
- names = ['zh_tw']
-
- past = '{0}前'
- future = '{0}後'
-
- timeframes = {
- 'now': '剛才',
- 'seconds': '幾秒',
- 'minute': '1分鐘',
- 'minutes': '{0}分鐘',
- 'hour': '1小時',
- 'hours': '{0}小時',
- 'day': '1天',
- 'days': '{0}天',
- 'month': '1個月',
- 'months': '{0}個月',
- 'year': '1年',
- 'years': '{0}年',
- }
-
- month_names = ['', '1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月',
- '9月', '10月', '11月', '12月']
- month_abbreviations = ['', ' 1', ' 2', ' 3', ' 4', ' 5', ' 6', ' 7', ' 8',
- ' 9', '10', '11', '12']
-
- day_names = ['', '周一', '周二', '周三', '周四', '周五', '周六', '周日']
- day_abbreviations = ['', '一', '二', '三', '四', '五', '六', '日']
-
-
-class KoreanLocale(Locale):
-
- names = ['ko', 'ko_kr']
-
- past = '{0} 전'
- future = '{0} 후'
-
- timeframes = {
- 'now': '지금',
- 'seconds': '몇 초',
- 'minute': '1분',
- 'minutes': '{0}분',
- 'hour': '1시간',
- 'hours': '{0}시간',
- 'day': '1일',
- 'days': '{0}일',
- 'month': '1개월',
- 'months': '{0}개월',
- 'year': '1년',
- 'years': '{0}년',
- }
-
- month_names = ['', '1월', '2월', '3월', '4월', '5월', '6월', '7월', '8월',
- '9월', '10월', '11월', '12월']
- month_abbreviations = ['', ' 1', ' 2', ' 3', ' 4', ' 5', ' 6', ' 7', ' 8',
- ' 9', '10', '11', '12']
-
- day_names = ['', '월요일', '화요일', '수요일', '목요일', '금요일', '토요일', '일요일']
- day_abbreviations = ['', '월', '화', '수', '목', '금', '토', '일']
-
-
-# derived locale types & implementations.
-class DutchLocale(Locale):
-
- names = ['nl', 'nl_nl']
-
- past = '{0} geleden'
- future = 'over {0}'
-
- timeframes = {
- 'now': 'nu',
- 'seconds': 'seconden',
- 'minute': 'een minuut',
- 'minutes': '{0} minuten',
- 'hour': 'een uur',
- 'hours': '{0} uur',
- 'day': 'een dag',
- 'days': '{0} dagen',
- 'month': 'een maand',
- 'months': '{0} maanden',
- 'year': 'een jaar',
- 'years': '{0} jaar',
- }
-
- # In Dutch names of months and days are not starting with a capital letter
- # like in the English language.
- month_names = ['', 'januari', 'februari', 'maart', 'april', 'mei', 'juni', 'juli',
- 'augustus', 'september', 'oktober', 'november', 'december']
- month_abbreviations = ['', 'jan', 'feb', 'mrt', 'apr', 'mei', 'jun', 'jul', 'aug',
- 'sep', 'okt', 'nov', 'dec']
-
- day_names = ['', 'maandag', 'dinsdag', 'woensdag', 'donderdag', 'vrijdag', 'zaterdag', 'zondag']
- day_abbreviations = ['', 'ma', 'di', 'wo', 'do', 'vr', 'za', 'zo']
-
-
-class SlavicBaseLocale(Locale):
-
- def _format_timeframe(self, timeframe, delta):
-
- form = self.timeframes[timeframe]
- delta = abs(delta)
-
- if isinstance(form, list):
-
- if delta % 10 == 1 and delta % 100 != 11:
- form = form[0]
- elif 2 <= delta % 10 <= 4 and (delta % 100 < 10 or delta % 100 >= 20):
- form = form[1]
- else:
- form = form[2]
-
- return form.format(delta)
-
-class BelarusianLocale(SlavicBaseLocale):
-
- names = ['be', 'be_by']
-
- past = '{0} таму'
- future = 'праз {0}'
-
- timeframes = {
- 'now': 'зараз',
- 'seconds': 'некалькі секунд',
- 'minute': 'хвіліну',
- 'minutes': ['{0} хвіліну', '{0} хвіліны', '{0} хвілін'],
- 'hour': 'гадзіну',
- 'hours': ['{0} гадзіну', '{0} гадзіны', '{0} гадзін'],
- 'day': 'дзень',
- 'days': ['{0} дзень', '{0} дні', '{0} дзён'],
- 'month': 'месяц',
- 'months': ['{0} месяц', '{0} месяцы', '{0} месяцаў'],
- 'year': 'год',
- 'years': ['{0} год', '{0} гады', '{0} гадоў'],
- }
-
- month_names = ['', 'студзеня', 'лютага', 'сакавіка', 'красавіка', 'траўня', 'чэрвеня',
- 'ліпеня', 'жніўня', 'верасня', 'кастрычніка', 'лістапада', 'снежня']
- month_abbreviations = ['', 'студ', 'лют', 'сак', 'крас', 'трав', 'чэрв', 'ліп', 'жнів',
- 'вер', 'каст', 'ліст', 'снеж']
-
- day_names = ['', 'панядзелак', 'аўторак', 'серада', 'чацвер', 'пятніца', 'субота', 'нядзеля']
- day_abbreviations = ['', 'пн', 'ат', 'ср', 'чц', 'пт', 'сб', 'нд']
-
-
-class PolishLocale(SlavicBaseLocale):
-
- names = ['pl', 'pl_pl']
-
- past = '{0} temu'
- future = 'za {0}'
-
- timeframes = {
- 'now': 'teraz',
- 'seconds': 'kilka sekund',
- 'minute': 'minutę',
- 'minutes': ['{0} minut', '{0} minuty', '{0} minut'],
- 'hour': 'godzina',
- 'hours': ['{0} godzin', '{0} godziny', '{0} godzin'],
- 'day': 'dzień',
- 'days': ['{0} dzień', '{0} dni', '{0} dni'],
- 'month': 'miesiąc',
- 'months': ['{0} miesiąc', '{0} miesiące', '{0} miesięcy'],
- 'year': 'rok',
- 'years': ['{0} rok', '{0} lata', '{0} lat'],
- }
-
- month_names = ['', 'styczeń', 'luty', 'marzec', 'kwiecień', 'maj',
- 'czerwiec', 'lipiec', 'sierpień', 'wrzesień', 'październik',
- 'listopad', 'grudzień']
- month_abbreviations = ['', 'sty', 'lut', 'mar', 'kwi', 'maj', 'cze', 'lip',
- 'sie', 'wrz', 'paź', 'lis', 'gru']
-
- day_names = ['', 'poniedziałek', 'wtorek', 'środa', 'czwartek', 'piątek',
- 'sobota', 'niedziela']
- day_abbreviations = ['', 'Pn', 'Wt', 'Śr', 'Czw', 'Pt', 'So', 'Nd']
-
-
-class RussianLocale(SlavicBaseLocale):
-
- names = ['ru', 'ru_ru']
-
- past = '{0} назад'
- future = 'через {0}'
-
- timeframes = {
- 'now': 'сейчас',
- 'seconds': 'несколько секунд',
- 'minute': 'минуту',
- 'minutes': ['{0} минуту', '{0} минуты', '{0} минут'],
- 'hour': 'час',
- 'hours': ['{0} час', '{0} часа', '{0} часов'],
- 'day': 'день',
- 'days': ['{0} день', '{0} дня', '{0} дней'],
- 'month': 'месяц',
- 'months': ['{0} месяц', '{0} месяца', '{0} месяцев'],
- 'year': 'год',
- 'years': ['{0} год', '{0} года', '{0} лет'],
- }
-
- month_names = ['', 'января', 'февраля', 'марта', 'апреля', 'мая', 'июня',
- 'июля', 'августа', 'сентября', 'октября', 'ноября', 'декабря']
- month_abbreviations = ['', 'янв', 'фев', 'мар', 'апр', 'май', 'июн', 'июл',
- 'авг', 'сен', 'окт', 'ноя', 'дек']
-
- day_names = ['', 'понедельник', 'вторник', 'среда', 'четверг', 'пятница',
- 'суббота', 'воскресенье']
- day_abbreviations = ['', 'пн', 'вт', 'ср', 'чт', 'пт', 'сб', 'вс']
-
-
-class BulgarianLocale(SlavicBaseLocale):
-
- names = ['bg', 'bg_BG']
-
- past = '{0} назад'
- future = 'напред {0}'
-
- timeframes = {
- 'now': 'сега',
- 'seconds': 'няколко секунди',
- 'minute': 'минута',
- 'minutes': ['{0} минута', '{0} минути', '{0} минути'],
- 'hour': 'час',
- 'hours': ['{0} час', '{0} часа', '{0} часа'],
- 'day': 'ден',
- 'days': ['{0} ден', '{0} дни', '{0} дни'],
- 'month': 'месец',
- 'months': ['{0} месец', '{0} месеца', '{0} месеца'],
- 'year': 'година',
- 'years': ['{0} година', '{0} години', '{0} години'],
- }
-
- month_names = ['', 'януари', 'февруари', 'март', 'април', 'май', 'юни',
- 'юли', 'август', 'септември', 'октомври', 'ноември', 'декември']
- month_abbreviations = ['', 'ян', 'февр', 'март', 'апр', 'май', 'юни', 'юли',
- 'авг', 'септ', 'окт', 'ноем', 'дек']
-
- day_names = ['', 'понеделник', 'вторник', 'сряда', 'четвъртък', 'петък',
- 'събота', 'неделя']
- day_abbreviations = ['', 'пон', 'вт', 'ср', 'четв', 'пет', 'съб', 'нед']
-
-
-class UkrainianLocale(SlavicBaseLocale):
-
- names = ['ua', 'uk_ua']
-
- past = '{0} тому'
- future = 'за {0}'
-
- timeframes = {
- 'now': 'зараз',
- 'seconds': 'кілька секунд',
- 'minute': 'хвилину',
- 'minutes': ['{0} хвилину', '{0} хвилини', '{0} хвилин'],
- 'hour': 'годину',
- 'hours': ['{0} годину', '{0} години', '{0} годин'],
- 'day': 'день',
- 'days': ['{0} день', '{0} дні', '{0} днів'],
- 'month': 'місяць',
- 'months': ['{0} місяць', '{0} місяці', '{0} місяців'],
- 'year': 'рік',
- 'years': ['{0} рік', '{0} роки', '{0} років'],
- }
-
- month_names = ['', 'січня', 'лютого', 'березня', 'квітня', 'травня', 'червня',
- 'липня', 'серпня', 'вересня', 'жовтня', 'листопада', 'грудня']
- month_abbreviations = ['', 'січ', 'лют', 'бер', 'квіт', 'трав', 'черв', 'лип', 'серп',
- 'вер', 'жовт', 'лист', 'груд']
-
- day_names = ['', 'понеділок', 'вівторок', 'середа', 'четвер', 'п’ятниця', 'субота', 'неділя']
- day_abbreviations = ['', 'пн', 'вт', 'ср', 'чт', 'пт', 'сб', 'нд']
-
-
-class _DeutschLocaleCommonMixin(object):
-
- past = 'vor {0}'
- future = 'in {0}'
-
- timeframes = {
- 'now': 'gerade eben',
- 'seconds': 'Sekunden',
- 'minute': 'einer Minute',
- 'minutes': '{0} Minuten',
- 'hour': 'einer Stunde',
- 'hours': '{0} Stunden',
- 'day': 'einem Tag',
- 'days': '{0} Tagen',
- 'month': 'einem Monat',
- 'months': '{0} Monaten',
- 'year': 'einem Jahr',
- 'years': '{0} Jahren',
- }
-
- month_names = [
- '', 'Januar', 'Februar', 'März', 'April', 'Mai', 'Juni', 'Juli',
- 'August', 'September', 'Oktober', 'November', 'Dezember'
- ]
-
- month_abbreviations = [
- '', 'Jan', 'Feb', 'Mär', 'Apr', 'Mai', 'Jun', 'Jul', 'Aug', 'Sep',
- 'Okt', 'Nov', 'Dez'
- ]
-
- day_names = [
- '', 'Montag', 'Dienstag', 'Mittwoch', 'Donnerstag', 'Freitag',
- 'Samstag', 'Sonntag'
- ]
-
- day_abbreviations = [
- '', 'Mo', 'Di', 'Mi', 'Do', 'Fr', 'Sa', 'So'
- ]
-
- def _ordinal_number(self, n):
- return '{0}.'.format(n)
-
-
-class GermanLocale(_DeutschLocaleCommonMixin, Locale):
-
- names = ['de', 'de_de']
-
- timeframes = _DeutschLocaleCommonMixin.timeframes.copy()
- timeframes['days'] = '{0} Tagen'
-
-
-class AustriaLocale(_DeutschLocaleCommonMixin, Locale):
-
- names = ['de', 'de_at']
-
- timeframes = _DeutschLocaleCommonMixin.timeframes.copy()
- timeframes['days'] = '{0} Tage'
-
-
-class NorwegianLocale(Locale):
-
- names = ['nb', 'nb_no']
-
- past = 'for {0} siden'
- future = 'om {0}'
-
- timeframes = {
- 'now': 'nå nettopp',
- 'seconds': 'noen sekunder',
- 'minute': 'ett minutt',
- 'minutes': '{0} minutter',
- 'hour': 'en time',
- 'hours': '{0} timer',
- 'day': 'en dag',
- 'days': '{0} dager',
- 'month': 'en måned',
- 'months': '{0} måneder',
- 'year': 'ett år',
- 'years': '{0} år',
- }
-
- month_names = ['', 'januar', 'februar', 'mars', 'april', 'mai', 'juni',
- 'juli', 'august', 'september', 'oktober', 'november',
- 'desember']
- month_abbreviations = ['', 'jan', 'feb', 'mar', 'apr', 'mai', 'jun', 'jul',
- 'aug', 'sep', 'okt', 'nov', 'des']
-
- day_names = ['', 'mandag', 'tirsdag', 'onsdag', 'torsdag', 'fredag',
- 'lørdag', 'søndag']
- day_abbreviations = ['', 'ma', 'ti', 'on', 'to', 'fr', 'lø', 'sø']
-
-
-class NewNorwegianLocale(Locale):
-
- names = ['nn', 'nn_no']
-
- past = 'for {0} sidan'
- future = 'om {0}'
-
- timeframes = {
- 'now': 'no nettopp',
- 'seconds': 'nokre sekund',
- 'minute': 'ett minutt',
- 'minutes': '{0} minutt',
- 'hour': 'ein time',
- 'hours': '{0} timar',
- 'day': 'ein dag',
- 'days': '{0} dagar',
- 'month': 'en månad',
- 'months': '{0} månader',
- 'year': 'eit år',
- 'years': '{0} år',
- }
-
- month_names = ['', 'januar', 'februar', 'mars', 'april', 'mai', 'juni',
- 'juli', 'august', 'september', 'oktober', 'november',
- 'desember']
- month_abbreviations = ['', 'jan', 'feb', 'mar', 'apr', 'mai', 'jun', 'jul',
- 'aug', 'sep', 'okt', 'nov', 'des']
-
- day_names = ['', 'måndag', 'tysdag', 'onsdag', 'torsdag', 'fredag',
- 'laurdag', 'sundag']
- day_abbreviations = ['', 'må', 'ty', 'on', 'to', 'fr', 'la', 'su']
-
-
-class PortugueseLocale(Locale):
- names = ['pt', 'pt_pt']
-
- past = 'há {0}'
- future = 'em {0}'
-
- timeframes = {
- 'now': 'agora',
- 'seconds': 'segundos',
- 'minute': 'um minuto',
- 'minutes': '{0} minutos',
- 'hour': 'uma hora',
- 'hours': '{0} horas',
- 'day': 'um dia',
- 'days': '{0} dias',
- 'month': 'um mês',
- 'months': '{0} meses',
- 'year': 'um ano',
- 'years': '{0} anos',
- }
-
- month_names = ['', 'janeiro', 'fevereiro', 'março', 'abril', 'maio', 'junho', 'julho',
- 'agosto', 'setembro', 'outubro', 'novembro', 'dezembro']
- month_abbreviations = ['', 'jan', 'fev', 'mar', 'abr', 'maio', 'jun', 'jul', 'ago',
- 'set', 'out', 'nov', 'dez']
-
- day_names = ['', 'segunda-feira', 'terça-feira', 'quarta-feira', 'quinta-feira', 'sexta-feira',
- 'sábado', 'domingo']
- day_abbreviations = ['', 'seg', 'ter', 'qua', 'qui', 'sex', 'sab', 'dom']
-
-
-class BrazilianPortugueseLocale(PortugueseLocale):
- names = ['pt_br']
-
- past = 'fazem {0}'
-
-
-class TagalogLocale(Locale):
-
- names = ['tl']
-
- past = 'nakaraang {0}'
- future = '{0} mula ngayon'
-
- timeframes = {
- 'now': 'ngayon lang',
- 'seconds': 'segundo',
- 'minute': 'isang minuto',
- 'minutes': '{0} minuto',
- 'hour': 'isang oras',
- 'hours': '{0} oras',
- 'day': 'isang araw',
- 'days': '{0} araw',
- 'month': 'isang buwan',
- 'months': '{0} buwan',
- 'year': 'isang taon',
- 'years': '{0} taon',
- }
-
- month_names = ['', 'Enero', 'Pebrero', 'Marso', 'Abril', 'Mayo', 'Hunyo', 'Hulyo',
- 'Agosto', 'Setyembre', 'Oktubre', 'Nobyembre', 'Disyembre']
- month_abbreviations = ['', 'Ene', 'Peb', 'Mar', 'Abr', 'May', 'Hun', 'Hul', 'Ago',
- 'Set', 'Okt', 'Nob', 'Dis']
-
- day_names = ['', 'Lunes', 'Martes', 'Miyerkules', 'Huwebes', 'Biyernes', 'Sabado', 'Linggo']
- day_abbreviations = ['', 'Lun', 'Mar', 'Miy', 'Huw', 'Biy', 'Sab', 'Lin']
-
-
-class VietnameseLocale(Locale):
-
- names = ['vi', 'vi_vn']
-
- past = '{0} trước'
- future = '{0} nữa'
-
- timeframes = {
- 'now': 'hiện tại',
- 'seconds': 'giây',
- 'minute': 'một phút',
- 'minutes': '{0} phút',
- 'hour': 'một giờ',
- 'hours': '{0} giờ',
- 'day': 'một ngày',
- 'days': '{0} ngày',
- 'month': 'một tháng',
- 'months': '{0} tháng',
- 'year': 'một năm',
- 'years': '{0} năm',
- }
-
- month_names = ['', 'Tháng Một', 'Tháng Hai', 'Tháng Ba', 'Tháng Tư', 'Tháng Năm', 'Tháng Sáu', 'Tháng Bảy',
- 'Tháng Tám', 'Tháng Chín', 'Tháng Mười', 'Tháng Mười Một', 'Tháng Mười Hai']
- month_abbreviations = ['', 'Tháng 1', 'Tháng 2', 'Tháng 3', 'Tháng 4', 'Tháng 5', 'Tháng 6', 'Tháng 7', 'Tháng 8',
- 'Tháng 9', 'Tháng 10', 'Tháng 11', 'Tháng 12']
-
- day_names = ['', 'Thứ Hai', 'Thứ Ba', 'Thứ Tư', 'Thứ Năm', 'Thứ Sáu', 'Thứ Bảy', 'Chủ Nhật']
- day_abbreviations = ['', 'Thứ 2', 'Thứ 3', 'Thứ 4', 'Thứ 5', 'Thứ 6', 'Thứ 7', 'CN']
-
-
-class TurkishLocale(Locale):
-
- names = ['tr', 'tr_tr']
-
- past = '{0} önce'
- future = '{0} sonra'
-
- timeframes = {
- 'now': 'şimdi',
- 'seconds': 'saniye',
- 'minute': 'bir dakika',
- 'minutes': '{0} dakika',
- 'hour': 'bir saat',
- 'hours': '{0} saat',
- 'day': 'bir gün',
- 'days': '{0} gün',
- 'month': 'bir ay',
- 'months': '{0} ay',
- 'year': 'a yıl',
- 'years': '{0} yıl',
- }
-
- month_names = ['', 'Ocak', 'Şubat', 'Mart', 'Nisan', 'Mayıs', 'Haziran', 'Temmuz',
- 'Ağustos', 'Eylül', 'Ekim', 'Kasım', 'Aralık']
- month_abbreviations = ['', 'Oca', 'Şub', 'Mar', 'Nis', 'May', 'Haz', 'Tem', 'Ağu',
- 'Eyl', 'Eki', 'Kas', 'Ara']
-
- day_names = ['', 'Pazartesi', 'Salı', 'Çarşamba', 'Perşembe', 'Cuma', 'Cumartesi', 'Pazar']
- day_abbreviations = ['', 'Pzt', 'Sal', 'Çar', 'Per', 'Cum', 'Cmt', 'Paz']
-
-
-class ArabicLocale(Locale):
-
- names = ['ar', 'ar_eg']
-
- past = 'منذ {0}'
- future = 'خلال {0}'
-
- timeframes = {
- 'now': 'الآن',
- 'seconds': 'ثوان',
- 'minute': 'دقيقة',
- 'minutes': '{0} دقائق',
- 'hour': 'ساعة',
- 'hours': '{0} ساعات',
- 'day': 'يوم',
- 'days': '{0} أيام',
- 'month': 'شهر',
- 'months': '{0} شهور',
- 'year': 'سنة',
- 'years': '{0} سنوات',
- }
-
- month_names = ['', 'يناير', 'فبراير', 'مارس', 'أبريل', 'مايو', 'يونيو', 'يوليو',
- 'أغسطس', 'سبتمبر', 'أكتوبر', 'نوفمبر', 'ديسمبر']
- month_abbreviations = ['', 'يناير', 'فبراير', 'مارس', 'أبريل', 'مايو', 'يونيو', 'يوليو',
- 'أغسطس', 'سبتمبر', 'أكتوبر', 'نوفمبر', 'ديسمبر']
-
- day_names = ['', 'الاثنين', 'الثلاثاء', 'الأربعاء', 'الخميس', 'الجمعة', 'السبت', 'الأحد']
- day_abbreviations = ['', 'اثنين', 'ثلاثاء', 'أربعاء', 'خميس', 'جمعة', 'سبت', 'أحد']
-
-
-class IcelandicLocale(Locale):
-
- def _format_timeframe(self, timeframe, delta):
-
- timeframe = self.timeframes[timeframe]
- if delta < 0:
- timeframe = timeframe[0]
- elif delta > 0:
- timeframe = timeframe[1]
-
- return timeframe.format(abs(delta))
-
- names = ['is', 'is_is']
-
- past = 'fyrir {0} síðan'
- future = 'eftir {0}'
-
- timeframes = {
- 'now': 'rétt í þessu',
- 'seconds': ('nokkrum sekúndum', 'nokkrar sekúndur'),
- 'minute': ('einni mínútu', 'eina mínútu'),
- 'minutes': ('{0} mínútum', '{0} mínútur'),
- 'hour': ('einum tíma', 'einn tíma'),
- 'hours': ('{0} tímum', '{0} tíma'),
- 'day': ('einum degi', 'einn dag'),
- 'days': ('{0} dögum', '{0} daga'),
- 'month': ('einum mánuði', 'einn mánuð'),
- 'months': ('{0} mánuðum', '{0} mánuði'),
- 'year': ('einu ári', 'eitt ár'),
- 'years': ('{0} árum', '{0} ár'),
- }
-
- meridians = {
- 'am': 'f.h.',
- 'pm': 'e.h.',
- 'AM': 'f.h.',
- 'PM': 'e.h.',
- }
-
- month_names = ['', 'janúar', 'febrúar', 'mars', 'apríl', 'maí', 'júní',
- 'júlí', 'ágúst', 'september', 'október', 'nóvember', 'desember']
- month_abbreviations = ['', 'jan', 'feb', 'mar', 'apr', 'maí', 'jún',
- 'júl', 'ágú', 'sep', 'okt', 'nóv', 'des']
-
- day_names = ['', 'mánudagur', 'þriðjudagur', 'miðvikudagur', 'fimmtudagur',
- 'föstudagur', 'laugardagur', 'sunnudagur']
- day_abbreviations = ['', 'mán', 'þri', 'mið', 'fim', 'fös', 'lau', 'sun']
-
-
-class DanishLocale(Locale):
-
- names = ['da', 'da_dk']
-
- past = 'for {0} siden'
- future = 'efter {0}'
-
- timeframes = {
- 'now': 'lige nu',
- 'seconds': 'et par sekunder',
- 'minute': 'et minut',
- 'minutes': '{0} minutter',
- 'hour': 'en time',
- 'hours': '{0} timer',
- 'day': 'en dag',
- 'days': '{0} dage',
- 'month': 'en måned',
- 'months': '{0} måneder',
- 'year': 'et år',
- 'years': '{0} år',
- }
-
- month_names = ['', 'januar', 'februar', 'marts', 'april', 'maj', 'juni',
- 'juli', 'august', 'september', 'oktober', 'november', 'december']
- month_abbreviations = ['', 'jan', 'feb', 'mar', 'apr', 'maj', 'jun',
- 'jul', 'aug', 'sep', 'okt', 'nov', 'dec']
-
- day_names = ['', 'mandag', 'tirsdag', 'onsdag', 'torsdag', 'fredag',
- 'lørdag', 'søndag']
- day_abbreviations = ['', 'man', 'tir', 'ons', 'tor', 'fre', 'lør', 'søn']
-
-
-class MalayalamLocale(Locale):
-
- names = ['ml']
-
- past = '{0} മുമ്പ്'
- future = '{0} ശേഷം'
-
- timeframes = {
- 'now': 'ഇപ്പോൾ',
- 'seconds': 'സെക്കന്റ്',
- 'minute': 'ഒരു മിനിറ്റ്',
- 'minutes': '{0} മിനിറ്റ്',
- 'hour': 'ഒരു മണിക്കൂർ',
- 'hours': '{0} മണിക്കൂർ',
- 'day': 'ഒരു ദിവസം ',
- 'days': '{0} ദിവസം ',
- 'month': 'ഒരു മാസം ',
- 'months': '{0} മാസം ',
- 'year': 'ഒരു വർഷം ',
- 'years': '{0} വർഷം ',
- }
-
- meridians = {
- 'am': 'രാവിലെ',
- 'pm': 'ഉച്ചക്ക് ശേഷം',
- 'AM': 'രാവിലെ',
- 'PM': 'ഉച്ചക്ക് ശേഷം',
- }
-
- month_names = ['', 'ജനുവരി', 'ഫെബ്രുവരി', 'മാർച്ച്', 'ഏപ്രിൽ ', 'മെയ് ', 'ജൂണ്', 'ജൂലൈ',
- 'ഓഗസ്റ്റ്', 'സെപ്റ്റംബർ', 'ഒക്ടോബർ', 'നവംബർ', 'ഡിസംബർ']
- month_abbreviations = ['', 'ജനു', 'ഫെബ് ', 'മാർ', 'ഏപ്രിൽ', 'മേയ്', 'ജൂണ്', 'ജൂലൈ', 'ഓഗസ്റ',
- 'സെപ്റ്റ', 'ഒക്ടോ', 'നവം', 'ഡിസം']
-
- day_names = ['', 'തിങ്കള്', 'ചൊവ്വ', 'ബുധന്', 'വ്യാഴം', 'വെള്ളി', 'ശനി', 'ഞായര്']
- day_abbreviations = ['', 'തിങ്കള്', 'ചൊവ്വ', 'ബുധന്', 'വ്യാഴം', 'വെള്ളി', 'ശനി', 'ഞായര്']
-
-
-class HindiLocale(Locale):
-
- names = ['hi']
-
- past = '{0} पहले'
- future = '{0} बाद'
-
- timeframes = {
- 'now': 'अभी',
- 'seconds': 'सेकंड्',
- 'minute': 'एक मिनट ',
- 'minutes': '{0} मिनट ',
- 'hour': 'एक घंटा',
- 'hours': '{0} घंटे',
- 'day': 'एक दिन',
- 'days': '{0} दिन',
- 'month': 'एक माह ',
- 'months': '{0} महीने ',
- 'year': 'एक वर्ष ',
- 'years': '{0} साल ',
- }
-
- meridians = {
- 'am': 'सुबह',
- 'pm': 'शाम',
- 'AM': 'सुबह',
- 'PM': 'शाम',
- }
-
- month_names = ['', 'जनवरी', 'फरवरी', 'मार्च', 'अप्रैल ', 'मई', 'जून', 'जुलाई',
- 'अगस्त', 'सितंबर', 'अक्टूबर', 'नवंबर', 'दिसंबर']
- month_abbreviations = ['', 'जन', 'फ़र', 'मार्च', 'अप्रै', 'मई', 'जून', 'जुलाई', 'आग',
- 'सित', 'अकत', 'नवे', 'दिस']
-
- day_names = ['', 'सोमवार', 'मंगलवार', 'बुधवार', 'गुरुवार', 'शुक्रवार', 'शनिवार', 'रविवार']
- day_abbreviations = ['', 'सोम', 'मंगल', 'बुध', 'गुरुवार', 'शुक्र', 'शनि', 'रवि']
-
-class CzechLocale(Locale):
- names = ['cs', 'cs_cz']
-
- timeframes = {
- 'now': 'Teď',
- 'seconds': {
- 'past': '{0} sekundami',
- 'future': ['{0} sekundy', '{0} sekund']
- },
- 'minute': {'past': 'minutou', 'future': 'minutu', 'zero': '{0} minut'},
- 'minutes': {
- 'past': '{0} minutami',
- 'future': ['{0} minuty', '{0} minut']
- },
- 'hour': {'past': 'hodinou', 'future': 'hodinu', 'zero': '{0} hodin'},
- 'hours': {
- 'past': '{0} hodinami',
- 'future': ['{0} hodiny', '{0} hodin']
- },
- 'day': {'past': 'dnem', 'future': 'den', 'zero': '{0} dnů'},
- 'days': {
- 'past': '{0} dny',
- 'future': ['{0} dny', '{0} dnů']
- },
- 'month': {'past': 'měsícem', 'future': 'měsíc', 'zero': '{0} měsíců'},
- 'months': {
- 'past': '{0} měsíci',
- 'future': ['{0} měsíce', '{0} měsíců']
- },
- 'year': {'past': 'rokem', 'future': 'rok', 'zero': '{0} let'},
- 'years': {
- 'past': '{0} lety',
- 'future': ['{0} roky', '{0} let']
- }
- }
-
- past = 'Před {0}'
- future = 'Za {0}'
-
- month_names = ['', 'leden', 'únor', 'březen', 'duben', 'květen', 'červen',
- 'červenec', 'srpen', 'září', 'říjen', 'listopad', 'prosinec']
- month_abbreviations = ['', 'led', 'úno', 'bře', 'dub', 'kvě', 'čvn', 'čvc',
- 'srp', 'zář', 'říj', 'lis', 'pro']
-
- day_names = ['', 'pondělí', 'úterý', 'středa', 'čtvrtek', 'pátek',
- 'sobota', 'neděle']
- day_abbreviations = ['', 'po', 'út', 'st', 'čt', 'pá', 'so', 'ne']
-
-
- def _format_timeframe(self, timeframe, delta):
- '''Czech aware time frame format function, takes into account the differences between past and future forms.'''
- form = self.timeframes[timeframe]
- if isinstance(form, dict):
- if delta == 0:
- form = form['zero'] # And *never* use 0 in the singular!
- elif delta > 0:
- form = form['future']
- else:
- form = form['past']
- delta = abs(delta)
-
- if isinstance(form, list):
- if 2 <= delta % 10 <= 4 and (delta % 100 < 10 or delta % 100 >= 20):
- form = form[0]
- else:
- form = form[1]
-
- return form.format(delta)
-
-class FarsiLocale(Locale):
-
- names = ['fa', 'fa_ir']
-
- past = '{0} قبل'
- future = 'در {0}'
-
- timeframes = {
- 'now': 'اکنون',
- 'seconds': 'ثانیه',
- 'minute': 'یک دقیقه',
- 'minutes': '{0} دقیقه',
- 'hour': 'یک ساعت',
- 'hours': '{0} ساعت',
- 'day': 'یک روز',
- 'days': '{0} روز',
- 'month': 'یک ماه',
- 'months': '{0} ماه',
- 'year': 'یک سال',
- 'years': '{0} سال',
- }
-
- meridians = {
- 'am': 'قبل از ظهر',
- 'pm': 'بعد از ظهر',
- 'AM': 'قبل از ظهر',
- 'PM': 'بعد از ظهر',
- }
-
- month_names = ['', 'January', 'February', 'March', 'April', 'May', 'June', 'July',
- 'August', 'September', 'October', 'November', 'December']
- month_abbreviations = ['', 'Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug',
- 'Sep', 'Oct', 'Nov', 'Dec']
-
- day_names = ['', 'دو شنبه', 'سه شنبه', 'چهارشنبه', 'پنجشنبه', 'جمعه', 'شنبه', 'یکشنبه']
- day_abbreviations = ['', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
-
-
-class MacedonianLocale(Locale):
- names = ['mk', 'mk_mk']
-
- past = 'пред {0}'
- future = 'за {0}'
-
- timeframes = {
- 'now': 'сега',
- 'seconds': 'секунди',
- 'minute': 'една минута',
- 'minutes': '{0} минути',
- 'hour': 'еден саат',
- 'hours': '{0} саати',
- 'day': 'еден ден',
- 'days': '{0} дена',
- 'month': 'еден месец',
- 'months': '{0} месеци',
- 'year': 'една година',
- 'years': '{0} години',
- }
-
- meridians = {
- 'am': 'дп',
- 'pm': 'пп',
- 'AM': 'претпладне',
- 'PM': 'попладне',
- }
-
- month_names = ['', 'Јануари', 'Февруари', 'Март', 'Април', 'Мај', 'Јуни', 'Јули', 'Август', 'Септември', 'Октомври',
- 'Ноември', 'Декември']
- month_abbreviations = ['', 'Јан.', ' Фев.', ' Мар.', ' Апр.', ' Мај', ' Јун.', ' Јул.', ' Авг.', ' Септ.', ' Окт.',
- ' Ноем.', ' Декем.']
-
- day_names = ['', 'Понеделник', ' Вторник', ' Среда', ' Четврток', ' Петок', ' Сабота', ' Недела']
- day_abbreviations = ['', 'Пон.', ' Вт.', ' Сре.', ' Чет.', ' Пет.', ' Саб.', ' Нед.']
-
-
-class HebrewLocale(Locale):
-
- names = ['he', 'he_IL']
-
- past = 'לפני {0}'
- future = 'בעוד {0}'
-
- timeframes = {
- 'now': 'הרגע',
- 'seconds': 'שניות',
- 'minute': 'דקה',
- 'minutes': '{0} דקות',
- 'hour': 'שעה',
- 'hours': '{0} שעות',
- '2-hours': 'שעתיים',
- 'day': 'יום',
- 'days': '{0} ימים',
- '2-days': 'יומיים',
- 'month': 'חודש',
- 'months': '{0} חודשים',
- '2-months': 'חודשיים',
- 'year': 'שנה',
- 'years': '{0} שנים',
- '2-years': 'שנתיים',
- }
-
- meridians = {
- 'am': 'לפנ"צ',
- 'pm': 'אחר"צ',
- 'AM': 'לפני הצהריים',
- 'PM': 'אחרי הצהריים',
- }
-
- month_names = ['', 'ינואר', 'פברואר', 'מרץ', 'אפריל', 'מאי', 'יוני', 'יולי',
- 'אוגוסט', 'ספטמבר', 'אוקטובר', 'נובמבר', 'דצמבר']
- month_abbreviations = ['', 'ינו׳', 'פבר׳', 'מרץ', 'אפר׳', 'מאי', 'יוני', 'יולי', 'אוג׳',
- 'ספט׳', 'אוק׳', 'נוב׳', 'דצמ׳']
-
- day_names = ['', 'שני', 'שלישי', 'רביעי', 'חמישי', 'שישי', 'שבת', 'ראשון']
- day_abbreviations = ['', 'ב׳', 'ג׳', 'ד׳', 'ה׳', 'ו׳', 'ש׳', 'א׳']
-
- def _format_timeframe(self, timeframe, delta):
- '''Hebrew couple of aware'''
- couple = '2-{0}'.format(timeframe)
- if abs(delta) == 2 and couple in self.timeframes:
- return self.timeframes[couple].format(abs(delta))
- else:
- return self.timeframes[timeframe].format(abs(delta))
-
-class MarathiLocale(Locale):
-
- names = ['mr']
-
- past = '{0} आधी'
- future = '{0} नंतर'
-
- timeframes = {
- 'now': 'सद्य',
- 'seconds': 'सेकंद',
- 'minute': 'एक मिनिट ',
- 'minutes': '{0} मिनिट ',
- 'hour': 'एक तास',
- 'hours': '{0} तास',
- 'day': 'एक दिवस',
- 'days': '{0} दिवस',
- 'month': 'एक महिना ',
- 'months': '{0} महिने ',
- 'year': 'एक वर्ष ',
- 'years': '{0} वर्ष ',
- }
-
- meridians = {
- 'am': 'सकाळ',
- 'pm': 'संध्याकाळ',
- 'AM': 'सकाळ',
- 'PM': 'संध्याकाळ',
- }
-
- month_names = ['', 'जानेवारी', 'फेब्रुवारी', 'मार्च', 'एप्रिल', 'मे', 'जून', 'जुलै',
- 'अॉगस्ट', 'सप्टेंबर', 'अॉक्टोबर', 'नोव्हेंबर', 'डिसेंबर']
- month_abbreviations = ['', 'जान', 'फेब्रु', 'मार्च', 'एप्रि', 'मे', 'जून', 'जुलै', 'अॉग',
- 'सप्टें', 'अॉक्टो', 'नोव्हें', 'डिसें']
-
- day_names = ['', 'सोमवार', 'मंगळवार', 'बुधवार', 'गुरुवार', 'शुक्रवार', 'शनिवार', 'रविवार']
- day_abbreviations = ['', 'सोम', 'मंगळ', 'बुध', 'गुरु', 'शुक्र', 'शनि', 'रवि']
-
-def _map_locales():
-
- locales = {}
-
- for cls_name, cls in inspect.getmembers(sys.modules[__name__], inspect.isclass):
- if issubclass(cls, Locale):
- for name in cls.names:
- locales[name.lower()] = cls
-
- return locales
-
-class CatalanLocale(Locale):
- names = ['ca', 'ca_es', 'ca_ad', 'ca_fr', 'ca_it']
- past = 'Fa {0}'
- future = 'En {0}'
-
- timeframes = {
- 'now': 'Ara mateix',
- 'seconds': 'segons',
- 'minute': '1 minut',
- 'minutes': '{0} minuts',
- 'hour': 'una hora',
- 'hours': '{0} hores',
- 'day': 'un dia',
- 'days': '{0} dies',
- 'month': 'un mes',
- 'months': '{0} mesos',
- 'year': 'un any',
- 'years': '{0} anys',
- }
-
- month_names = ['', 'Gener', 'Febrer', 'Març', 'Abril', 'Maig', 'Juny', 'Juliol', 'Agost', 'Setembre', 'Octubre', 'Novembre', 'Desembre']
- month_abbreviations = ['', 'Gener', 'Febrer', 'Març', 'Abril', 'Maig', 'Juny', 'Juliol', 'Agost', 'Setembre', 'Octubre', 'Novembre', 'Desembre']
- day_names = ['', 'Dilluns', 'Dimarts', 'Dimecres', 'Dijous', 'Divendres', 'Dissabte', 'Diumenge']
- day_abbreviations = ['', 'Dilluns', 'Dimarts', 'Dimecres', 'Dijous', 'Divendres', 'Dissabte', 'Diumenge']
-
-class BasqueLocale(Locale):
- names = ['eu', 'eu_eu']
- past = 'duela {0}'
- future = '{0}' # I don't know what's the right phrase in Basque for the future.
-
- timeframes = {
- 'now': 'Orain',
- 'seconds': 'segundu',
- 'minute': 'minutu bat',
- 'minutes': '{0} minutu',
- 'hour': 'ordu bat',
- 'hours': '{0} ordu',
- 'day': 'egun bat',
- 'days': '{0} egun',
- 'month': 'hilabete bat',
- 'months': '{0} hilabet',
- 'year': 'urte bat',
- 'years': '{0} urte',
- }
-
- month_names = ['', 'urtarrilak', 'otsailak', 'martxoak', 'apirilak', 'maiatzak', 'ekainak', 'uztailak', 'abuztuak', 'irailak', 'urriak', 'azaroak', 'abenduak']
- month_abbreviations = ['', 'urt', 'ots', 'mar', 'api', 'mai', 'eka', 'uzt', 'abu', 'ira', 'urr', 'aza', 'abe']
- day_names = ['', 'asteleehna', 'asteartea', 'asteazkena', 'osteguna', 'ostirala', 'larunbata', 'igandea']
- day_abbreviations = ['', 'al', 'ar', 'az', 'og', 'ol', 'lr', 'ig']
-
-
-class HungarianLocale(Locale):
-
- names = ['hu', 'hu_hu']
-
- past = '{0} ezelőtt'
- future = '{0} múlva'
-
- timeframes = {
- 'now': 'éppen most',
- 'seconds': {
- 'past': 'másodpercekkel',
- 'future': 'pár másodperc'
- },
- 'minute': {'past': 'egy perccel', 'future': 'egy perc'},
- 'minutes': {'past': '{0} perccel', 'future': '{0} perc'},
- 'hour': {'past': 'egy órával', 'future': 'egy óra'},
- 'hours': {'past': '{0} órával', 'future': '{0} óra'},
- 'day': {
- 'past': 'egy nappal',
- 'future': 'egy nap'
- },
- 'days': {
- 'past': '{0} nappal',
- 'future': '{0} nap'
- },
- 'month': {'past': 'egy hónappal', 'future': 'egy hónap'},
- 'months': {'past': '{0} hónappal', 'future': '{0} hónap'},
- 'year': {'past': 'egy évvel', 'future': 'egy év'},
- 'years': {'past': '{0} évvel', 'future': '{0} év'},
- }
-
- month_names = ['', 'január', 'február', 'március', 'április', 'május',
- 'június', 'július', 'augusztus', 'szeptember',
- 'október', 'november', 'december']
- month_abbreviations = ['', 'jan', 'febr', 'márc', 'ápr', 'máj', 'jún',
- 'júl', 'aug', 'szept', 'okt', 'nov', 'dec']
-
- day_names = ['', 'hétfő', 'kedd', 'szerda', 'csütörtök', 'péntek',
- 'szombat', 'vasárnap']
- day_abbreviations = ['', 'hét', 'kedd', 'szer', 'csüt', 'pént',
- 'szom', 'vas']
-
- meridians = {
- 'am': 'de',
- 'pm': 'du',
- 'AM': 'DE',
- 'PM': 'DU',
- }
-
- def _format_timeframe(self, timeframe, delta):
- form = self.timeframes[timeframe]
-
- if isinstance(form, dict):
- if delta > 0:
- form = form['future']
- else:
- form = form['past']
-
- return form.format(abs(delta))
-
-
-class EsperantoLocale(Locale):
- names = ['eo', 'eo_xx']
- past = 'antaŭ {0}'
- future = 'post {0}'
-
- timeframes = {
- 'now': 'nun',
- 'seconds': 'kelkaj sekundoj',
- 'minute': 'unu minuto',
- 'minutes': '{0} minutoj',
- 'hour': 'un horo',
- 'hours': '{0} horoj',
- 'day': 'unu tago',
- 'days': '{0} tagoj',
- 'month': 'unu monato',
- 'months': '{0} monatoj',
- 'year': 'unu jaro',
- 'years': '{0} jaroj',
- }
-
- month_names = ['', 'januaro', 'februaro', 'marto', 'aprilo', 'majo',
- 'junio', 'julio', 'aŭgusto', 'septembro', 'oktobro',
- 'novembro', 'decembro']
- month_abbreviations = ['', 'jan', 'feb', 'mar', 'apr', 'maj', 'jun',
- 'jul', 'aŭg', 'sep', 'okt', 'nov', 'dec']
-
- day_names = ['', 'lundo', 'mardo', 'merkredo', 'ĵaŭdo', 'vendredo',
- 'sabato', 'dimanĉo']
- day_abbreviations = ['', 'lun', 'mar', 'mer', 'ĵaŭ', 'ven',
- 'sab', 'dim']
-
- meridians = {
- 'am': 'atm',
- 'pm': 'ptm',
- 'AM': 'ATM',
- 'PM': 'PTM',
- }
-
- ordinal_day_re = r'((?P[1-3]?[0-9](?=a))a)'
-
- def _ordinal_number(self, n):
- return '{0}a'.format(n)
-
-
-class ThaiLocale(Locale):
-
- names = ['th', 'th_th']
-
- past = '{0}{1}ที่ผ่านมา'
- future = 'ในอีก{1}{0}'
-
- timeframes = {
- 'now': 'ขณะนี้',
- 'seconds': 'ไม่กี่วินาที',
- 'minute': '1 นาที',
- 'minutes': '{0} นาที',
- 'hour': '1 ชั่วโมง',
- 'hours': '{0} ชั่วโมง',
- 'day': '1 วัน',
- 'days': '{0} วัน',
- 'month': '1 เดือน',
- 'months': '{0} เดือน',
- 'year': '1 ปี',
- 'years': '{0} ปี',
- }
-
- month_names = ['', 'มกราคม', 'กุมภาพันธ์', 'มีนาคม', 'เมษายน',
- 'พฤษภาคม', 'มิถุนายน', 'กรกฏาคม', 'สิงหาคม',
- 'กันยายน', 'ตุลาคม', 'พฤศจิกายน', 'ธันวาคม']
- month_abbreviations = ['', 'ม.ค.', 'ก.พ.', 'มี.ค.', 'เม.ย.', 'พ.ค.',
- 'มิ.ย.', 'ก.ค.', 'ส.ค.', 'ก.ย.', 'ต.ค.',
- 'พ.ย.', 'ธ.ค.']
-
- day_names = ['', 'จันทร์', 'อังคาร', 'พุธ', 'พฤหัสบดี', 'ศุกร์',
- 'เสาร์', 'อาทิตย์']
- day_abbreviations = ['', 'จ', 'อ', 'พ', 'พฤ', 'ศ', 'ส', 'อา']
-
- meridians = {
- 'am': 'am',
- 'pm': 'pm',
- 'AM': 'AM',
- 'PM': 'PM',
- }
-
- BE_OFFSET = 543
-
- def year_full(self, year):
- '''Thai always use Buddhist Era (BE) which is CE + 543'''
- year += self.BE_OFFSET
- return '{0:04d}'.format(year)
-
- def year_abbreviation(self, year):
- '''Thai always use Buddhist Era (BE) which is CE + 543'''
- year += self.BE_OFFSET
- return '{0:04d}'.format(year)[2:]
-
- def _format_relative(self, humanized, timeframe, delta):
- '''Thai normally doesn't have any space between words'''
- if timeframe == 'now':
- return humanized
- space = '' if timeframe == 'seconds' else ' '
- direction = self.past if delta < 0 else self.future
-
- return direction.format(humanized, space)
-
-
-
-class BengaliLocale(Locale):
-
- names = ['bn', 'bn_bd', 'bn_in']
-
- past = '{0} আগে'
- future = '{0} পরে'
-
- timeframes = {
- 'now': 'এখন',
- 'seconds': 'সেকেন্ড',
- 'minute': 'এক মিনিট',
- 'minutes': '{0} মিনিট',
- 'hour': 'এক ঘণ্টা',
- 'hours': '{0} ঘণ্টা',
- 'day': 'এক দিন',
- 'days': '{0} দিন',
- 'month': 'এক মাস',
- 'months': '{0} মাস ',
- 'year': 'এক বছর',
- 'years': '{0} বছর',
- }
-
- meridians = {
- 'am': 'সকাল',
- 'pm': 'বিকাল',
- 'AM': 'সকাল',
- 'PM': 'বিকাল',
- }
-
- month_names = ['', 'জানুয়ারি', 'ফেব্রুয়ারি', 'মার্চ', 'এপ্রিল', 'মে', 'জুন', 'জুলাই',
- 'আগস্ট', 'সেপ্টেম্বর', 'অক্টোবর', 'নভেম্বর', 'ডিসেম্বর']
- month_abbreviations = ['', 'জানু', 'ফেব', 'মার্চ', 'এপ্রি', 'মে', 'জুন', 'জুল',
- 'অগা','সেপ্ট', 'অক্টো', 'নভে', 'ডিসে']
-
- day_names = ['', 'সোমবার', 'মঙ্গলবার', 'বুধবার', 'বৃহস্পতিবার', 'শুক্রবার', 'শনিবার', 'রবিবার']
- day_abbreviations = ['', 'সোম', 'মঙ্গল', 'বুধ', 'বৃহঃ', 'শুক্র', 'শনি', 'রবি']
-
- def _ordinal_number(self, n):
- if n > 10 or n == 0:
- return '{0}তম'.format(n)
- if n in [1, 5, 7, 8, 9, 10]:
- return '{0}ম'.format(n)
- if n in [2, 3]:
- return '{0}য়'.format(n)
- if n == 4:
- return '{0}র্থ'.format(n)
- if n == 6:
- return '{0}ষ্ঠ'.format(n)
-
-
-class RomanshLocale(Locale):
-
- names = ['rm', 'rm_ch']
-
- past = 'avant {0}'
- future = 'en {0}'
-
- timeframes = {
- 'now': 'en quest mument',
- 'seconds': 'secundas',
- 'minute': 'ina minuta',
- 'minutes': '{0} minutas',
- 'hour': 'in\'ura',
- 'hours': '{0} ura',
- 'day': 'in di',
- 'days': '{0} dis',
- 'month': 'in mais',
- 'months': '{0} mais',
- 'year': 'in onn',
- 'years': '{0} onns',
- }
-
- month_names = [
- '', 'schaner', 'favrer', 'mars', 'avrigl', 'matg', 'zercladur',
- 'fanadur', 'avust', 'settember', 'october', 'november', 'december'
- ]
-
- month_abbreviations = [
- '', 'schan', 'fav', 'mars', 'avr', 'matg', 'zer', 'fan', 'avu',
- 'set', 'oct', 'nov', 'dec'
- ]
-
- day_names = [
- '', 'glindesdi', 'mardi', 'mesemna', 'gievgia', 'venderdi',
- 'sonda', 'dumengia'
- ]
-
- day_abbreviations = [
- '', 'gli', 'ma', 'me', 'gie', 've', 'so', 'du'
- ]
-
-
-_locales = _map_locales()
diff --git a/arrow/parser.py b/arrow/parser.py
deleted file mode 100644
index 6e94a10..0000000
--- a/arrow/parser.py
+++ /dev/null
@@ -1,331 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-from datetime import datetime
-from dateutil import tz
-import re
-from arrow import locales
-
-
-class ParserError(RuntimeError):
- pass
-
-
-class DateTimeParser(object):
-
- _FORMAT_RE = re.compile('(YYY?Y?|MM?M?M?|Do|DD?D?D?|d?d?d?d|HH?|hh?|mm?|ss?|SS?S?S?S?S?|ZZ?Z?|a|A|X)')
- _ESCAPE_RE = re.compile('\[[^\[\]]*\]')
-
- _ONE_THROUGH_SIX_DIGIT_RE = re.compile('\d{1,6}')
- _ONE_THROUGH_FIVE_DIGIT_RE = re.compile('\d{1,5}')
- _ONE_THROUGH_FOUR_DIGIT_RE = re.compile('\d{1,4}')
- _ONE_TWO_OR_THREE_DIGIT_RE = re.compile('\d{1,3}')
- _ONE_OR_TWO_DIGIT_RE = re.compile('\d{1,2}')
- _FOUR_DIGIT_RE = re.compile('\d{4}')
- _TWO_DIGIT_RE = re.compile('\d{2}')
- _TZ_RE = re.compile('[+\-]?\d{2}:?(\d{2})?')
- _TZ_NAME_RE = re.compile('\w[\w+\-/]+')
-
-
- _BASE_INPUT_RE_MAP = {
- 'YYYY': _FOUR_DIGIT_RE,
- 'YY': _TWO_DIGIT_RE,
- 'MM': _TWO_DIGIT_RE,
- 'M': _ONE_OR_TWO_DIGIT_RE,
- 'DD': _TWO_DIGIT_RE,
- 'D': _ONE_OR_TWO_DIGIT_RE,
- 'HH': _TWO_DIGIT_RE,
- 'H': _ONE_OR_TWO_DIGIT_RE,
- 'hh': _TWO_DIGIT_RE,
- 'h': _ONE_OR_TWO_DIGIT_RE,
- 'mm': _TWO_DIGIT_RE,
- 'm': _ONE_OR_TWO_DIGIT_RE,
- 'ss': _TWO_DIGIT_RE,
- 's': _ONE_OR_TWO_DIGIT_RE,
- 'X': re.compile('\d+'),
- 'ZZZ': _TZ_NAME_RE,
- 'ZZ': _TZ_RE,
- 'Z': _TZ_RE,
- 'SSSSSS': _ONE_THROUGH_SIX_DIGIT_RE,
- 'SSSSS': _ONE_THROUGH_FIVE_DIGIT_RE,
- 'SSSS': _ONE_THROUGH_FOUR_DIGIT_RE,
- 'SSS': _ONE_TWO_OR_THREE_DIGIT_RE,
- 'SS': _ONE_OR_TWO_DIGIT_RE,
- 'S': re.compile('\d'),
- }
-
- MARKERS = ['YYYY', 'MM', 'DD']
- SEPARATORS = ['-', '/', '.']
-
- def __init__(self, locale='en_us'):
-
- self.locale = locales.get_locale(locale)
- self._input_re_map = self._BASE_INPUT_RE_MAP.copy()
- self._input_re_map.update({
- 'MMMM': self._choice_re(self.locale.month_names[1:], re.IGNORECASE),
- 'MMM': self._choice_re(self.locale.month_abbreviations[1:],
- re.IGNORECASE),
- 'Do': re.compile(self.locale.ordinal_day_re),
- 'dddd': self._choice_re(self.locale.day_names[1:], re.IGNORECASE),
- 'ddd': self._choice_re(self.locale.day_abbreviations[1:],
- re.IGNORECASE),
- 'd' : re.compile("[1-7]"),
- 'a': self._choice_re(
- (self.locale.meridians['am'], self.locale.meridians['pm'])
- ),
- # note: 'A' token accepts both 'am/pm' and 'AM/PM' formats to
- # ensure backwards compatibility of this token
- 'A': self._choice_re(self.locale.meridians.values())
- })
-
- def parse_iso(self, string):
-
- has_time = 'T' in string or ' ' in string.strip()
- space_divider = ' ' in string.strip()
-
- if has_time:
- if space_divider:
- date_string, time_string = string.split(' ', 1)
- else:
- date_string, time_string = string.split('T', 1)
- time_parts = re.split('[+-]', time_string, 1)
- has_tz = len(time_parts) > 1
- has_seconds = time_parts[0].count(':') > 1
- has_subseconds = '.' in time_parts[0]
-
- if has_subseconds:
- subseconds_token = 'S' * min(len(re.split('\D+', time_parts[0].split('.')[1], 1)[0]), 6)
- formats = ['YYYY-MM-DDTHH:mm:ss.%s' % subseconds_token]
- elif has_seconds:
- formats = ['YYYY-MM-DDTHH:mm:ss']
- else:
- formats = ['YYYY-MM-DDTHH:mm']
- else:
- has_tz = False
- # generate required formats: YYYY-MM-DD, YYYY-MM-DD, YYYY
- # using various separators: -, /, .
- l = len(self.MARKERS)
- formats = [separator.join(self.MARKERS[:l-i])
- for i in range(l)
- for separator in self.SEPARATORS]
-
- if has_time and has_tz:
- formats = [f + 'Z' for f in formats]
-
- if space_divider:
- formats = [item.replace('T', ' ', 1) for item in formats]
-
- return self._parse_multiformat(string, formats)
-
- def parse(self, string, fmt):
-
- if isinstance(fmt, list):
- return self._parse_multiformat(string, fmt)
-
- # fmt is a string of tokens like 'YYYY-MM-DD'
- # we construct a new string by replacing each
- # token by its pattern:
- # 'YYYY-MM-DD' -> '(?P\d{4})-(?P\d{2})-(?P\d{2})'
- tokens = []
- offset = 0
-
- # Extract the bracketed expressions to be reinserted later.
- escaped_fmt = re.sub(self._ESCAPE_RE, "#" , fmt)
- escaped_data = re.findall(self._ESCAPE_RE, fmt)
-
- fmt_pattern = escaped_fmt
-
- for m in self._FORMAT_RE.finditer(escaped_fmt):
- token = m.group(0)
- try:
- input_re = self._input_re_map[token]
- except KeyError:
- raise ParserError('Unrecognized token \'{0}\''.format(token))
- input_pattern = '(?P<{0}>{1})'.format(token, input_re.pattern)
- tokens.append(token)
- # a pattern doesn't have the same length as the token
- # it replaces! We keep the difference in the offset variable.
- # This works because the string is scanned left-to-right and matches
- # are returned in the order found by finditer.
- fmt_pattern = fmt_pattern[:m.start() + offset] + input_pattern + fmt_pattern[m.end() + offset:]
- offset += len(input_pattern) - (m.end() - m.start())
-
- final_fmt_pattern = ""
- a = fmt_pattern.split("#")
- b = escaped_data
-
- # Due to the way Python splits, 'a' will always be longer
- for i in range(len(a)):
- final_fmt_pattern += a[i]
- if i < len(b):
- final_fmt_pattern += b[i][1:-1]
-
- match = re.search(final_fmt_pattern, string, flags=re.IGNORECASE)
- if match is None:
- raise ParserError('Failed to match \'{0}\' when parsing \'{1}\''.format(final_fmt_pattern, string))
- parts = {}
- for token in tokens:
- if token == 'Do':
- value = match.group('value')
- else:
- value = match.group(token)
- self._parse_token(token, value, parts)
- return self._build_datetime(parts)
-
- def _parse_token(self, token, value, parts):
-
- if token == 'YYYY':
- parts['year'] = int(value)
- elif token == 'YY':
- value = int(value)
- parts['year'] = 1900 + value if value > 68 else 2000 + value
-
- elif token in ['MMMM', 'MMM']:
- parts['month'] = self.locale.month_number(value.lower())
-
- elif token in ['MM', 'M']:
- parts['month'] = int(value)
-
- elif token in ['DD', 'D']:
- parts['day'] = int(value)
-
- elif token in ['Do']:
- parts['day'] = int(value)
-
- elif token.upper() in ['HH', 'H']:
- parts['hour'] = int(value)
-
- elif token in ['mm', 'm']:
- parts['minute'] = int(value)
-
- elif token in ['ss', 's']:
- parts['second'] = int(value)
-
- elif token == 'SSSSSS':
- parts['microsecond'] = int(value)
- elif token == 'SSSSS':
- parts['microsecond'] = int(value) * 10
- elif token == 'SSSS':
- parts['microsecond'] = int(value) * 100
- elif token == 'SSS':
- parts['microsecond'] = int(value) * 1000
- elif token == 'SS':
- parts['microsecond'] = int(value) * 10000
- elif token == 'S':
- parts['microsecond'] = int(value) * 100000
-
- elif token == 'X':
- parts['timestamp'] = int(value)
-
- elif token in ['ZZZ', 'ZZ', 'Z']:
- parts['tzinfo'] = TzinfoParser.parse(value)
-
- elif token in ['a', 'A']:
- if value in (
- self.locale.meridians['am'],
- self.locale.meridians['AM']
- ):
- parts['am_pm'] = 'am'
- elif value in (
- self.locale.meridians['pm'],
- self.locale.meridians['PM']
- ):
- parts['am_pm'] = 'pm'
-
- @staticmethod
- def _build_datetime(parts):
-
- timestamp = parts.get('timestamp')
-
- if timestamp:
- tz_utc = tz.tzutc()
- return datetime.fromtimestamp(timestamp, tz=tz_utc)
-
- am_pm = parts.get('am_pm')
- hour = parts.get('hour', 0)
-
- if am_pm == 'pm' and hour < 12:
- hour += 12
- elif am_pm == 'am' and hour == 12:
- hour = 0
-
- return datetime(year=parts.get('year', 1), month=parts.get('month', 1),
- day=parts.get('day', 1), hour=hour, minute=parts.get('minute', 0),
- second=parts.get('second', 0), microsecond=parts.get('microsecond', 0),
- tzinfo=parts.get('tzinfo'))
-
- def _parse_multiformat(self, string, formats):
-
- _datetime = None
-
- for fmt in formats:
- try:
- _datetime = self.parse(string, fmt)
- break
- except:
- pass
-
- if _datetime is None:
- raise ParserError('Could not match input to any of {0} on \'{1}\''.format(formats, string))
-
- return _datetime
-
- @staticmethod
- def _map_lookup(input_map, key):
-
- try:
- return input_map[key]
- except KeyError:
- raise ParserError('Could not match "{0}" to {1}'.format(key, input_map))
-
- @staticmethod
- def _try_timestamp(string):
-
- try:
- return float(string)
- except:
- return None
-
- @staticmethod
- def _choice_re(choices, flags=0):
- return re.compile('({0})'.format('|'.join(choices)), flags=flags)
-
-
-class TzinfoParser(object):
-
- _TZINFO_RE = re.compile('([+\-])?(\d\d):?(\d\d)?')
-
- @classmethod
- def parse(cls, string):
-
- tzinfo = None
-
- if string == 'local':
- tzinfo = tz.tzlocal()
-
- elif string in ['utc', 'UTC']:
- tzinfo = tz.tzutc()
-
- else:
-
- iso_match = cls._TZINFO_RE.match(string)
-
- if iso_match:
- sign, hours, minutes = iso_match.groups()
- if minutes is None:
- minutes = 0
- seconds = int(hours) * 3600 + int(minutes) * 60
-
- if sign == '-':
- seconds *= -1
-
- tzinfo = tz.tzoffset(None, seconds)
-
- else:
- tzinfo = tz.gettz(string)
-
- if tzinfo is None:
- raise ParserError('Could not parse timezone expression "{0}"', string)
-
- return tzinfo
diff --git a/arrow/util.py b/arrow/util.py
deleted file mode 100644
index 546cff2..0000000
--- a/arrow/util.py
+++ /dev/null
@@ -1,45 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import absolute_import
-
-import sys
-
-# python 2.6 / 2.7 definitions for total_seconds function.
-
-def _total_seconds_27(td): # pragma: no cover
- return td.total_seconds()
-
-def _total_seconds_26(td):
- return (td.microseconds + (td.seconds + td.days * 24 * 3600) * 1e6) / 1e6
-
-
-# get version info and assign correct total_seconds function.
-
-version = '{0}.{1}.{2}'.format(*sys.version_info[:3])
-
-if version < '2.7': # pragma: no cover
- total_seconds = _total_seconds_26
-else: # pragma: no cover
- total_seconds = _total_seconds_27
-
-def is_timestamp(value):
- try:
- float(value)
- return True
- except:
- return False
-
-# python 2.7 / 3.0+ definitions for isstr function.
-
-try: # pragma: no cover
- basestring
-
- def isstr(s):
- return isinstance(s, basestring)
-
-except NameError: #pragma: no cover
-
- def isstr(s):
- return isinstance(s, str)
-
-
-__all__ = ['total_seconds', 'is_timestamp', 'isstr']
diff --git a/date_format_mappings.pyc b/date_format_mappings.pyc
deleted file mode 100644
index 334ff6b..0000000
Binary files a/date_format_mappings.pyc and /dev/null differ
diff --git a/dateutil/__init__.py b/dateutil/__init__.py
deleted file mode 100644
index 290814c..0000000
--- a/dateutil/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-"""
-Copyright (c) 2003-2010 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-__version__ = "1.5"
diff --git a/dateutil/__init__.pyc b/dateutil/__init__.pyc
deleted file mode 100644
index e091fba..0000000
Binary files a/dateutil/__init__.pyc and /dev/null differ
diff --git a/dateutil/easter.py b/dateutil/easter.py
deleted file mode 100644
index d794410..0000000
--- a/dateutil/easter.py
+++ /dev/null
@@ -1,92 +0,0 @@
-"""
-Copyright (c) 2003-2007 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-
-import datetime
-
-__all__ = ["easter", "EASTER_JULIAN", "EASTER_ORTHODOX", "EASTER_WESTERN"]
-
-EASTER_JULIAN = 1
-EASTER_ORTHODOX = 2
-EASTER_WESTERN = 3
-
-def easter(year, method=EASTER_WESTERN):
- """
- This method was ported from the work done by GM Arts,
- on top of the algorithm by Claus Tondering, which was
- based in part on the algorithm of Ouding (1940), as
- quoted in "Explanatory Supplement to the Astronomical
- Almanac", P. Kenneth Seidelmann, editor.
-
- This algorithm implements three different easter
- calculation methods:
-
- 1 - Original calculation in Julian calendar, valid in
- dates after 326 AD
- 2 - Original method, with date converted to Gregorian
- calendar, valid in years 1583 to 4099
- 3 - Revised method, in Gregorian calendar, valid in
- years 1583 to 4099 as well
-
- These methods are represented by the constants:
-
- EASTER_JULIAN = 1
- EASTER_ORTHODOX = 2
- EASTER_WESTERN = 3
-
- The default method is method 3.
-
- More about the algorithm may be found at:
-
- http://users.chariot.net.au/~gmarts/eastalg.htm
-
- and
-
- http://www.tondering.dk/claus/calendar.html
-
- """
-
- if not (1 <= method <= 3):
- raise ValueError, "invalid method"
-
- # g - Golden year - 1
- # c - Century
- # h - (23 - Epact) mod 30
- # i - Number of days from March 21 to Paschal Full Moon
- # j - Weekday for PFM (0=Sunday, etc)
- # p - Number of days from March 21 to Sunday on or before PFM
- # (-6 to 28 methods 1 & 3, to 56 for method 2)
- # e - Extra days to add for method 2 (converting Julian
- # date to Gregorian date)
-
- y = year
- g = y % 19
- e = 0
- if method < 3:
- # Old method
- i = (19*g+15)%30
- j = (y+y//4+i)%7
- if method == 2:
- # Extra dates to convert Julian to Gregorian date
- e = 10
- if y > 1600:
- e = e+y//100-16-(y//100-16)//4
- else:
- # New method
- c = y//100
- h = (c-c//4-(8*c+13)//25+19*g+15)%30
- i = h-(h//28)*(1-(h//28)*(29//(h+1))*((21-g)//11))
- j = (y+y//4+i+2-c+c//4)%7
-
- # p can be from -6 to 56 corresponding to dates 22 March to 23 May
- # (later dates apply to method 2, although 23 May never actually occurs)
- p = i-j+e
- d = 1+(p+27+(p+6)//40)%31
- m = 3+(p+26)//30
- return datetime.date(int(y),int(m),int(d))
-
diff --git a/dateutil/parser.py b/dateutil/parser.py
deleted file mode 100644
index 5d824e4..0000000
--- a/dateutil/parser.py
+++ /dev/null
@@ -1,886 +0,0 @@
-# -*- coding:iso-8859-1 -*-
-"""
-Copyright (c) 2003-2007 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-
-import datetime
-import string
-import time
-import sys
-import os
-
-try:
- from cStringIO import StringIO
-except ImportError:
- from StringIO import StringIO
-
-import relativedelta
-import tz
-
-
-__all__ = ["parse", "parserinfo"]
-
-
-# Some pointers:
-#
-# http://www.cl.cam.ac.uk/~mgk25/iso-time.html
-# http://www.iso.ch/iso/en/prods-services/popstds/datesandtime.html
-# http://www.w3.org/TR/NOTE-datetime
-# http://ringmaster.arc.nasa.gov/tools/time_formats.html
-# http://search.cpan.org/author/MUIR/Time-modules-2003.0211/lib/Time/ParseDate.pm
-# http://stein.cshl.org/jade/distrib/docs/java.text.SimpleDateFormat.html
-
-
-class _timelex(object):
-
- def __init__(self, instream):
- if isinstance(instream, basestring):
- instream = StringIO(instream)
- self.instream = instream
- self.wordchars = ('abcdfeghijklmnopqrstuvwxyz'
- 'ABCDEFGHIJKLMNOPQRSTUVWXYZ_'
- '��������������������������������'
- '������������������������������')
- self.numchars = '0123456789'
- self.whitespace = ' \t\r\n'
- self.charstack = []
- self.tokenstack = []
- self.eof = False
-
- def get_token(self):
- if self.tokenstack:
- return self.tokenstack.pop(0)
- seenletters = False
- token = None
- state = None
- wordchars = self.wordchars
- numchars = self.numchars
- whitespace = self.whitespace
- while not self.eof:
- if self.charstack:
- nextchar = self.charstack.pop(0)
- else:
- nextchar = self.instream.read(1)
- while nextchar == '\x00':
- nextchar = self.instream.read(1)
- if not nextchar:
- self.eof = True
- break
- elif not state:
- token = nextchar
- if nextchar in wordchars:
- state = 'a'
- elif nextchar in numchars:
- state = '0'
- elif nextchar in whitespace:
- token = ' '
- break # emit token
- else:
- break # emit token
- elif state == 'a':
- seenletters = True
- if nextchar in wordchars:
- token += nextchar
- elif nextchar == '.':
- token += nextchar
- state = 'a.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- elif state == '0':
- if nextchar in numchars:
- token += nextchar
- elif nextchar == '.':
- token += nextchar
- state = '0.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- elif state == 'a.':
- seenletters = True
- if nextchar == '.' or nextchar in wordchars:
- token += nextchar
- elif nextchar in numchars and token[-1] == '.':
- token += nextchar
- state = '0.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- elif state == '0.':
- if nextchar == '.' or nextchar in numchars:
- token += nextchar
- elif nextchar in wordchars and token[-1] == '.':
- token += nextchar
- state = 'a.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- if (state in ('a.', '0.') and
- (seenletters or token.count('.') > 1 or token[-1] == '.')):
- l = token.split('.')
- token = l[0]
- for tok in l[1:]:
- self.tokenstack.append('.')
- if tok:
- self.tokenstack.append(tok)
- return token
-
- def __iter__(self):
- return self
-
- def next(self):
- token = self.get_token()
- if token is None:
- raise StopIteration
- return token
-
- def split(cls, s):
- return list(cls(s))
- split = classmethod(split)
-
-
-class _resultbase(object):
-
- def __init__(self):
- for attr in self.__slots__:
- setattr(self, attr, None)
-
- def _repr(self, classname):
- l = []
- for attr in self.__slots__:
- value = getattr(self, attr)
- if value is not None:
- l.append("%s=%s" % (attr, `value`))
- return "%s(%s)" % (classname, ", ".join(l))
-
- def __repr__(self):
- return self._repr(self.__class__.__name__)
-
-
-class parserinfo(object):
-
- # m from a.m/p.m, t from ISO T separator
- JUMP = [" ", ".", ",", ";", "-", "/", "'",
- "at", "on", "and", "ad", "m", "t", "of",
- "st", "nd", "rd", "th"]
-
- WEEKDAYS = [("Mon", "Monday"),
- ("Tue", "Tuesday"),
- ("Wed", "Wednesday"),
- ("Thu", "Thursday"),
- ("Fri", "Friday"),
- ("Sat", "Saturday"),
- ("Sun", "Sunday")]
- MONTHS = [("Jan", "January"),
- ("Feb", "February"),
- ("Mar", "March"),
- ("Apr", "April"),
- ("May", "May"),
- ("Jun", "June"),
- ("Jul", "July"),
- ("Aug", "August"),
- ("Sep", "September"),
- ("Oct", "October"),
- ("Nov", "November"),
- ("Dec", "December")]
- HMS = [("h", "hour", "hours"),
- ("m", "minute", "minutes"),
- ("s", "second", "seconds")]
- AMPM = [("am", "a"),
- ("pm", "p")]
- UTCZONE = ["UTC", "GMT", "Z"]
- PERTAIN = ["of"]
- TZOFFSET = {}
-
- def __init__(self, dayfirst=False, yearfirst=False):
- self._jump = self._convert(self.JUMP)
- self._weekdays = self._convert(self.WEEKDAYS)
- self._months = self._convert(self.MONTHS)
- self._hms = self._convert(self.HMS)
- self._ampm = self._convert(self.AMPM)
- self._utczone = self._convert(self.UTCZONE)
- self._pertain = self._convert(self.PERTAIN)
-
- self.dayfirst = dayfirst
- self.yearfirst = yearfirst
-
- self._year = time.localtime().tm_year
- self._century = self._year//100*100
-
- def _convert(self, lst):
- dct = {}
- for i in range(len(lst)):
- v = lst[i]
- if isinstance(v, tuple):
- for v in v:
- dct[v.lower()] = i
- else:
- dct[v.lower()] = i
- return dct
-
- def jump(self, name):
- return name.lower() in self._jump
-
- def weekday(self, name):
- if len(name) >= 3:
- try:
- return self._weekdays[name.lower()]
- except KeyError:
- pass
- return None
-
- def month(self, name):
- if len(name) >= 3:
- try:
- return self._months[name.lower()]+1
- except KeyError:
- pass
- return None
-
- def hms(self, name):
- try:
- return self._hms[name.lower()]
- except KeyError:
- return None
-
- def ampm(self, name):
- try:
- return self._ampm[name.lower()]
- except KeyError:
- return None
-
- def pertain(self, name):
- return name.lower() in self._pertain
-
- def utczone(self, name):
- return name.lower() in self._utczone
-
- def tzoffset(self, name):
- if name in self._utczone:
- return 0
- return self.TZOFFSET.get(name)
-
- def convertyear(self, year):
- if year < 100:
- year += self._century
- if abs(year-self._year) >= 50:
- if year < self._year:
- year += 100
- else:
- year -= 100
- return year
-
- def validate(self, res):
- # move to info
- if res.year is not None:
- res.year = self.convertyear(res.year)
- if res.tzoffset == 0 and not res.tzname or res.tzname == 'Z':
- res.tzname = "UTC"
- res.tzoffset = 0
- elif res.tzoffset != 0 and res.tzname and self.utczone(res.tzname):
- res.tzoffset = 0
- return True
-
-
-class parser(object):
-
- def __init__(self, info=None):
- self.info = info or parserinfo()
-
- def parse(self, timestr, default=None,
- ignoretz=False, tzinfos=None,
- **kwargs):
- if not default:
- default = datetime.datetime.now().replace(hour=0, minute=0,
- second=0, microsecond=0)
- res = self._parse(timestr, **kwargs)
- if res is None:
- raise ValueError, "unknown string format"
- repl = {}
- for attr in ["year", "month", "day", "hour",
- "minute", "second", "microsecond"]:
- value = getattr(res, attr)
- if value is not None:
- repl[attr] = value
- ret = default.replace(**repl)
- if res.weekday is not None and not res.day:
- ret = ret+relativedelta.relativedelta(weekday=res.weekday)
- if not ignoretz:
- if callable(tzinfos) or tzinfos and res.tzname in tzinfos:
- if callable(tzinfos):
- tzdata = tzinfos(res.tzname, res.tzoffset)
- else:
- tzdata = tzinfos.get(res.tzname)
- if isinstance(tzdata, datetime.tzinfo):
- tzinfo = tzdata
- elif isinstance(tzdata, basestring):
- tzinfo = tz.tzstr(tzdata)
- elif isinstance(tzdata, int):
- tzinfo = tz.tzoffset(res.tzname, tzdata)
- else:
- raise ValueError, "offset must be tzinfo subclass, " \
- "tz string, or int offset"
- ret = ret.replace(tzinfo=tzinfo)
- elif res.tzname and res.tzname in time.tzname:
- ret = ret.replace(tzinfo=tz.tzlocal())
- elif res.tzoffset == 0:
- ret = ret.replace(tzinfo=tz.tzutc())
- elif res.tzoffset:
- ret = ret.replace(tzinfo=tz.tzoffset(res.tzname, res.tzoffset))
- return ret
-
- class _result(_resultbase):
- __slots__ = ["year", "month", "day", "weekday",
- "hour", "minute", "second", "microsecond",
- "tzname", "tzoffset"]
-
- def _parse(self, timestr, dayfirst=None, yearfirst=None, fuzzy=False):
- info = self.info
- if dayfirst is None:
- dayfirst = info.dayfirst
- if yearfirst is None:
- yearfirst = info.yearfirst
- res = self._result()
- l = _timelex.split(timestr)
- try:
-
- # year/month/day list
- ymd = []
-
- # Index of the month string in ymd
- mstridx = -1
-
- len_l = len(l)
- i = 0
- while i < len_l:
-
- # Check if it's a number
- try:
- value_repr = l[i]
- value = float(value_repr)
- except ValueError:
- value = None
-
- if value is not None:
- # Token is a number
- len_li = len(l[i])
- i += 1
- if (len(ymd) == 3 and len_li in (2, 4)
- and (i >= len_l or (l[i] != ':' and
- info.hms(l[i]) is None))):
- # 19990101T23[59]
- s = l[i-1]
- res.hour = int(s[:2])
- if len_li == 4:
- res.minute = int(s[2:])
- elif len_li == 6 or (len_li > 6 and l[i-1].find('.') == 6):
- # YYMMDD or HHMMSS[.ss]
- s = l[i-1]
- if not ymd and l[i-1].find('.') == -1:
- ymd.append(info.convertyear(int(s[:2])))
- ymd.append(int(s[2:4]))
- ymd.append(int(s[4:]))
- else:
- # 19990101T235959[.59]
- res.hour = int(s[:2])
- res.minute = int(s[2:4])
- res.second, res.microsecond = _parsems(s[4:])
- elif len_li == 8:
- # YYYYMMDD
- s = l[i-1]
- ymd.append(int(s[:4]))
- ymd.append(int(s[4:6]))
- ymd.append(int(s[6:]))
- elif len_li in (12, 14):
- # YYYYMMDDhhmm[ss]
- s = l[i-1]
- ymd.append(int(s[:4]))
- ymd.append(int(s[4:6]))
- ymd.append(int(s[6:8]))
- res.hour = int(s[8:10])
- res.minute = int(s[10:12])
- if len_li == 14:
- res.second = int(s[12:])
- elif ((i < len_l and info.hms(l[i]) is not None) or
- (i+1 < len_l and l[i] == ' ' and
- info.hms(l[i+1]) is not None)):
- # HH[ ]h or MM[ ]m or SS[.ss][ ]s
- if l[i] == ' ':
- i += 1
- idx = info.hms(l[i])
- while True:
- if idx == 0:
- res.hour = int(value)
- if value%1:
- res.minute = int(60*(value%1))
- elif idx == 1:
- res.minute = int(value)
- if value%1:
- res.second = int(60*(value%1))
- elif idx == 2:
- res.second, res.microsecond = \
- _parsems(value_repr)
- i += 1
- if i >= len_l or idx == 2:
- break
- # 12h00
- try:
- value_repr = l[i]
- value = float(value_repr)
- except ValueError:
- break
- else:
- i += 1
- idx += 1
- if i < len_l:
- newidx = info.hms(l[i])
- if newidx is not None:
- idx = newidx
- elif i+1 < len_l and l[i] == ':':
- # HH:MM[:SS[.ss]]
- res.hour = int(value)
- i += 1
- value = float(l[i])
- res.minute = int(value)
- if value%1:
- res.second = int(60*(value%1))
- i += 1
- if i < len_l and l[i] == ':':
- res.second, res.microsecond = _parsems(l[i+1])
- i += 2
- elif i < len_l and l[i] in ('-', '/', '.'):
- sep = l[i]
- ymd.append(int(value))
- i += 1
- if i < len_l and not info.jump(l[i]):
- try:
- # 01-01[-01]
- ymd.append(int(l[i]))
- except ValueError:
- # 01-Jan[-01]
- value = info.month(l[i])
- if value is not None:
- ymd.append(value)
- assert mstridx == -1
- mstridx = len(ymd)-1
- else:
- return None
- i += 1
- if i < len_l and l[i] == sep:
- # We have three members
- i += 1
- value = info.month(l[i])
- if value is not None:
- ymd.append(value)
- mstridx = len(ymd)-1
- assert mstridx == -1
- else:
- ymd.append(int(l[i]))
- i += 1
- elif i >= len_l or info.jump(l[i]):
- if i+1 < len_l and info.ampm(l[i+1]) is not None:
- # 12 am
- res.hour = int(value)
- if res.hour < 12 and info.ampm(l[i+1]) == 1:
- res.hour += 12
- elif res.hour == 12 and info.ampm(l[i+1]) == 0:
- res.hour = 0
- i += 1
- else:
- # Year, month or day
- ymd.append(int(value))
- i += 1
- elif info.ampm(l[i]) is not None:
- # 12am
- res.hour = int(value)
- if res.hour < 12 and info.ampm(l[i]) == 1:
- res.hour += 12
- elif res.hour == 12 and info.ampm(l[i]) == 0:
- res.hour = 0
- i += 1
- elif not fuzzy:
- return None
- else:
- i += 1
- continue
-
- # Check weekday
- value = info.weekday(l[i])
- if value is not None:
- res.weekday = value
- i += 1
- continue
-
- # Check month name
- value = info.month(l[i])
- if value is not None:
- ymd.append(value)
- assert mstridx == -1
- mstridx = len(ymd)-1
- i += 1
- if i < len_l:
- if l[i] in ('-', '/'):
- # Jan-01[-99]
- sep = l[i]
- i += 1
- ymd.append(int(l[i]))
- i += 1
- if i < len_l and l[i] == sep:
- # Jan-01-99
- i += 1
- ymd.append(int(l[i]))
- i += 1
- elif (i+3 < len_l and l[i] == l[i+2] == ' '
- and info.pertain(l[i+1])):
- # Jan of 01
- # In this case, 01 is clearly year
- try:
- value = int(l[i+3])
- except ValueError:
- # Wrong guess
- pass
- else:
- # Convert it here to become unambiguous
- ymd.append(info.convertyear(value))
- i += 4
- continue
-
- # Check am/pm
- value = info.ampm(l[i])
- if value is not None:
- if value == 1 and res.hour < 12:
- res.hour += 12
- elif value == 0 and res.hour == 12:
- res.hour = 0
- i += 1
- continue
-
- # Check for a timezone name
- if (res.hour is not None and len(l[i]) <= 5 and
- res.tzname is None and res.tzoffset is None and
- not [x for x in l[i] if x not in string.ascii_uppercase]):
- res.tzname = l[i]
- res.tzoffset = info.tzoffset(res.tzname)
- i += 1
-
- # Check for something like GMT+3, or BRST+3. Notice
- # that it doesn't mean "I am 3 hours after GMT", but
- # "my time +3 is GMT". If found, we reverse the
- # logic so that timezone parsing code will get it
- # right.
- if i < len_l and l[i] in ('+', '-'):
- l[i] = ('+', '-')[l[i] == '+']
- res.tzoffset = None
- if info.utczone(res.tzname):
- # With something like GMT+3, the timezone
- # is *not* GMT.
- res.tzname = None
-
- continue
-
- # Check for a numbered timezone
- if res.hour is not None and l[i] in ('+', '-'):
- signal = (-1,1)[l[i] == '+']
- i += 1
- len_li = len(l[i])
- if len_li == 4:
- # -0300
- res.tzoffset = int(l[i][:2])*3600+int(l[i][2:])*60
- elif i+1 < len_l and l[i+1] == ':':
- # -03:00
- res.tzoffset = int(l[i])*3600+int(l[i+2])*60
- i += 2
- elif len_li <= 2:
- # -[0]3
- res.tzoffset = int(l[i][:2])*3600
- else:
- return None
- i += 1
- res.tzoffset *= signal
-
- # Look for a timezone name between parenthesis
- if (i+3 < len_l and
- info.jump(l[i]) and l[i+1] == '(' and l[i+3] == ')' and
- 3 <= len(l[i+2]) <= 5 and
- not [x for x in l[i+2]
- if x not in string.ascii_uppercase]):
- # -0300 (BRST)
- res.tzname = l[i+2]
- i += 4
- continue
-
- # Check jumps
- if not (info.jump(l[i]) or fuzzy):
- return None
-
- i += 1
-
- # Process year/month/day
- len_ymd = len(ymd)
- if len_ymd > 3:
- # More than three members!?
- return None
- elif len_ymd == 1 or (mstridx != -1 and len_ymd == 2):
- # One member, or two members with a month string
- if mstridx != -1:
- res.month = ymd[mstridx]
- del ymd[mstridx]
- if len_ymd > 1 or mstridx == -1:
- if ymd[0] > 31:
- res.year = ymd[0]
- else:
- res.day = ymd[0]
- elif len_ymd == 2:
- # Two members with numbers
- if ymd[0] > 31:
- # 99-01
- res.year, res.month = ymd
- elif ymd[1] > 31:
- # 01-99
- res.month, res.year = ymd
- elif dayfirst and ymd[1] <= 12:
- # 13-01
- res.day, res.month = ymd
- else:
- # 01-13
- res.month, res.day = ymd
- if len_ymd == 3:
- # Three members
- if mstridx == 0:
- res.month, res.day, res.year = ymd
- elif mstridx == 1:
- if ymd[0] > 31 or (yearfirst and ymd[2] <= 31):
- # 99-Jan-01
- res.year, res.month, res.day = ymd
- else:
- # 01-Jan-01
- # Give precendence to day-first, since
- # two-digit years is usually hand-written.
- res.day, res.month, res.year = ymd
- elif mstridx == 2:
- # WTF!?
- if ymd[1] > 31:
- # 01-99-Jan
- res.day, res.year, res.month = ymd
- else:
- # 99-01-Jan
- res.year, res.day, res.month = ymd
- else:
- if ymd[0] > 31 or \
- (yearfirst and ymd[1] <= 12 and ymd[2] <= 31):
- # 99-01-01
- res.year, res.month, res.day = ymd
- elif ymd[0] > 12 or (dayfirst and ymd[1] <= 12):
- # 13-01-01
- res.day, res.month, res.year = ymd
- else:
- # 01-13-01
- res.month, res.day, res.year = ymd
-
- except (IndexError, ValueError, AssertionError):
- return None
-
- if not info.validate(res):
- return None
- return res
-
-DEFAULTPARSER = parser()
-def parse(timestr, parserinfo=None, **kwargs):
- if parserinfo:
- return parser(parserinfo).parse(timestr, **kwargs)
- else:
- return DEFAULTPARSER.parse(timestr, **kwargs)
-
-
-class _tzparser(object):
-
- class _result(_resultbase):
-
- __slots__ = ["stdabbr", "stdoffset", "dstabbr", "dstoffset",
- "start", "end"]
-
- class _attr(_resultbase):
- __slots__ = ["month", "week", "weekday",
- "yday", "jyday", "day", "time"]
-
- def __repr__(self):
- return self._repr("")
-
- def __init__(self):
- _resultbase.__init__(self)
- self.start = self._attr()
- self.end = self._attr()
-
- def parse(self, tzstr):
- res = self._result()
- l = _timelex.split(tzstr)
- try:
-
- len_l = len(l)
-
- i = 0
- while i < len_l:
- # BRST+3[BRDT[+2]]
- j = i
- while j < len_l and not [x for x in l[j]
- if x in "0123456789:,-+"]:
- j += 1
- if j != i:
- if not res.stdabbr:
- offattr = "stdoffset"
- res.stdabbr = "".join(l[i:j])
- else:
- offattr = "dstoffset"
- res.dstabbr = "".join(l[i:j])
- i = j
- if (i < len_l and
- (l[i] in ('+', '-') or l[i][0] in "0123456789")):
- if l[i] in ('+', '-'):
- # Yes, that's right. See the TZ variable
- # documentation.
- signal = (1,-1)[l[i] == '+']
- i += 1
- else:
- signal = -1
- len_li = len(l[i])
- if len_li == 4:
- # -0300
- setattr(res, offattr,
- (int(l[i][:2])*3600+int(l[i][2:])*60)*signal)
- elif i+1 < len_l and l[i+1] == ':':
- # -03:00
- setattr(res, offattr,
- (int(l[i])*3600+int(l[i+2])*60)*signal)
- i += 2
- elif len_li <= 2:
- # -[0]3
- setattr(res, offattr,
- int(l[i][:2])*3600*signal)
- else:
- return None
- i += 1
- if res.dstabbr:
- break
- else:
- break
-
- if i < len_l:
- for j in range(i, len_l):
- if l[j] == ';': l[j] = ','
-
- assert l[i] == ','
-
- i += 1
-
- if i >= len_l:
- pass
- elif (8 <= l.count(',') <= 9 and
- not [y for x in l[i:] if x != ','
- for y in x if y not in "0123456789"]):
- # GMT0BST,3,0,30,3600,10,0,26,7200[,3600]
- for x in (res.start, res.end):
- x.month = int(l[i])
- i += 2
- if l[i] == '-':
- value = int(l[i+1])*-1
- i += 1
- else:
- value = int(l[i])
- i += 2
- if value:
- x.week = value
- x.weekday = (int(l[i])-1)%7
- else:
- x.day = int(l[i])
- i += 2
- x.time = int(l[i])
- i += 2
- if i < len_l:
- if l[i] in ('-','+'):
- signal = (-1,1)[l[i] == "+"]
- i += 1
- else:
- signal = 1
- res.dstoffset = (res.stdoffset+int(l[i]))*signal
- elif (l.count(',') == 2 and l[i:].count('/') <= 2 and
- not [y for x in l[i:] if x not in (',','/','J','M',
- '.','-',':')
- for y in x if y not in "0123456789"]):
- for x in (res.start, res.end):
- if l[i] == 'J':
- # non-leap year day (1 based)
- i += 1
- x.jyday = int(l[i])
- elif l[i] == 'M':
- # month[-.]week[-.]weekday
- i += 1
- x.month = int(l[i])
- i += 1
- assert l[i] in ('-', '.')
- i += 1
- x.week = int(l[i])
- if x.week == 5:
- x.week = -1
- i += 1
- assert l[i] in ('-', '.')
- i += 1
- x.weekday = (int(l[i])-1)%7
- else:
- # year day (zero based)
- x.yday = int(l[i])+1
-
- i += 1
-
- if i < len_l and l[i] == '/':
- i += 1
- # start time
- len_li = len(l[i])
- if len_li == 4:
- # -0300
- x.time = (int(l[i][:2])*3600+int(l[i][2:])*60)
- elif i+1 < len_l and l[i+1] == ':':
- # -03:00
- x.time = int(l[i])*3600+int(l[i+2])*60
- i += 2
- if i+1 < len_l and l[i+1] == ':':
- i += 2
- x.time += int(l[i])
- elif len_li <= 2:
- # -[0]3
- x.time = (int(l[i][:2])*3600)
- else:
- return None
- i += 1
-
- assert i == len_l or l[i] == ','
-
- i += 1
-
- assert i >= len_l
-
- except (IndexError, ValueError, AssertionError):
- return None
-
- return res
-
-
-DEFAULTTZPARSER = _tzparser()
-def _parsetz(tzstr):
- return DEFAULTTZPARSER.parse(tzstr)
-
-
-def _parsems(value):
- """Parse a I[.F] seconds value into (seconds, microseconds)."""
- if "." not in value:
- return int(value), 0
- else:
- i, f = value.split(".")
- return int(i), int(f.ljust(6, "0")[:6])
-
-
-# vim:ts=4:sw=4:et
diff --git a/dateutil/relativedelta.py b/dateutil/relativedelta.py
deleted file mode 100644
index 0c72a81..0000000
--- a/dateutil/relativedelta.py
+++ /dev/null
@@ -1,432 +0,0 @@
-"""
-Copyright (c) 2003-2010 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-
-import datetime
-import calendar
-
-__all__ = ["relativedelta", "MO", "TU", "WE", "TH", "FR", "SA", "SU"]
-
-class weekday(object):
- __slots__ = ["weekday", "n"]
-
- def __init__(self, weekday, n=None):
- self.weekday = weekday
- self.n = n
-
- def __call__(self, n):
- if n == self.n:
- return self
- else:
- return self.__class__(self.weekday, n)
-
- def __eq__(self, other):
- try:
- if self.weekday != other.weekday or self.n != other.n:
- return False
- except AttributeError:
- return False
- return True
-
- def __repr__(self):
- s = ("MO", "TU", "WE", "TH", "FR", "SA", "SU")[self.weekday]
- if not self.n:
- return s
- else:
- return "%s(%+d)" % (s, self.n)
-
-MO, TU, WE, TH, FR, SA, SU = weekdays = tuple([weekday(x) for x in range(7)])
-
-class relativedelta:
- """
-The relativedelta type is based on the specification of the excelent
-work done by M.-A. Lemburg in his mx.DateTime extension. However,
-notice that this type does *NOT* implement the same algorithm as
-his work. Do *NOT* expect it to behave like mx.DateTime's counterpart.
-
-There's two different ways to build a relativedelta instance. The
-first one is passing it two date/datetime classes:
-
- relativedelta(datetime1, datetime2)
-
-And the other way is to use the following keyword arguments:
-
- year, month, day, hour, minute, second, microsecond:
- Absolute information.
-
- years, months, weeks, days, hours, minutes, seconds, microseconds:
- Relative information, may be negative.
-
- weekday:
- One of the weekday instances (MO, TU, etc). These instances may
- receive a parameter N, specifying the Nth weekday, which could
- be positive or negative (like MO(+1) or MO(-2). Not specifying
- it is the same as specifying +1. You can also use an integer,
- where 0=MO.
-
- leapdays:
- Will add given days to the date found, if year is a leap
- year, and the date found is post 28 of february.
-
- yearday, nlyearday:
- Set the yearday or the non-leap year day (jump leap days).
- These are converted to day/month/leapdays information.
-
-Here is the behavior of operations with relativedelta:
-
-1) Calculate the absolute year, using the 'year' argument, or the
- original datetime year, if the argument is not present.
-
-2) Add the relative 'years' argument to the absolute year.
-
-3) Do steps 1 and 2 for month/months.
-
-4) Calculate the absolute day, using the 'day' argument, or the
- original datetime day, if the argument is not present. Then,
- subtract from the day until it fits in the year and month
- found after their operations.
-
-5) Add the relative 'days' argument to the absolute day. Notice
- that the 'weeks' argument is multiplied by 7 and added to
- 'days'.
-
-6) Do steps 1 and 2 for hour/hours, minute/minutes, second/seconds,
- microsecond/microseconds.
-
-7) If the 'weekday' argument is present, calculate the weekday,
- with the given (wday, nth) tuple. wday is the index of the
- weekday (0-6, 0=Mon), and nth is the number of weeks to add
- forward or backward, depending on its signal. Notice that if
- the calculated date is already Monday, for example, using
- (0, 1) or (0, -1) won't change the day.
- """
-
- def __init__(self, dt1=None, dt2=None,
- years=0, months=0, days=0, leapdays=0, weeks=0,
- hours=0, minutes=0, seconds=0, microseconds=0,
- year=None, month=None, day=None, weekday=None,
- yearday=None, nlyearday=None,
- hour=None, minute=None, second=None, microsecond=None):
- if dt1 and dt2:
- if not isinstance(dt1, datetime.date) or \
- not isinstance(dt2, datetime.date):
- raise TypeError, "relativedelta only diffs datetime/date"
- if type(dt1) is not type(dt2):
- if not isinstance(dt1, datetime.datetime):
- dt1 = datetime.datetime.fromordinal(dt1.toordinal())
- elif not isinstance(dt2, datetime.datetime):
- dt2 = datetime.datetime.fromordinal(dt2.toordinal())
- self.years = 0
- self.months = 0
- self.days = 0
- self.leapdays = 0
- self.hours = 0
- self.minutes = 0
- self.seconds = 0
- self.microseconds = 0
- self.year = None
- self.month = None
- self.day = None
- self.weekday = None
- self.hour = None
- self.minute = None
- self.second = None
- self.microsecond = None
- self._has_time = 0
-
- months = (dt1.year*12+dt1.month)-(dt2.year*12+dt2.month)
- self._set_months(months)
- dtm = self.__radd__(dt2)
- if dt1 < dt2:
- while dt1 > dtm:
- months += 1
- self._set_months(months)
- dtm = self.__radd__(dt2)
- else:
- while dt1 < dtm:
- months -= 1
- self._set_months(months)
- dtm = self.__radd__(dt2)
- delta = dt1 - dtm
- self.seconds = delta.seconds+delta.days*86400
- self.microseconds = delta.microseconds
- else:
- self.years = years
- self.months = months
- self.days = days+weeks*7
- self.leapdays = leapdays
- self.hours = hours
- self.minutes = minutes
- self.seconds = seconds
- self.microseconds = microseconds
- self.year = year
- self.month = month
- self.day = day
- self.hour = hour
- self.minute = minute
- self.second = second
- self.microsecond = microsecond
-
- if type(weekday) is int:
- self.weekday = weekdays[weekday]
- else:
- self.weekday = weekday
-
- yday = 0
- if nlyearday:
- yday = nlyearday
- elif yearday:
- yday = yearday
- if yearday > 59:
- self.leapdays = -1
- if yday:
- ydayidx = [31,59,90,120,151,181,212,243,273,304,334,366]
- for idx, ydays in enumerate(ydayidx):
- if yday <= ydays:
- self.month = idx+1
- if idx == 0:
- self.day = yday
- else:
- self.day = yday-ydayidx[idx-1]
- break
- else:
- raise ValueError, "invalid year day (%d)" % yday
-
- self._fix()
-
- def _fix(self):
- if abs(self.microseconds) > 999999:
- s = self.microseconds//abs(self.microseconds)
- div, mod = divmod(self.microseconds*s, 1000000)
- self.microseconds = mod*s
- self.seconds += div*s
- if abs(self.seconds) > 59:
- s = self.seconds//abs(self.seconds)
- div, mod = divmod(self.seconds*s, 60)
- self.seconds = mod*s
- self.minutes += div*s
- if abs(self.minutes) > 59:
- s = self.minutes//abs(self.minutes)
- div, mod = divmod(self.minutes*s, 60)
- self.minutes = mod*s
- self.hours += div*s
- if abs(self.hours) > 23:
- s = self.hours//abs(self.hours)
- div, mod = divmod(self.hours*s, 24)
- self.hours = mod*s
- self.days += div*s
- if abs(self.months) > 11:
- s = self.months//abs(self.months)
- div, mod = divmod(self.months*s, 12)
- self.months = mod*s
- self.years += div*s
- if (self.hours or self.minutes or self.seconds or self.microseconds or
- self.hour is not None or self.minute is not None or
- self.second is not None or self.microsecond is not None):
- self._has_time = 1
- else:
- self._has_time = 0
-
- def _set_months(self, months):
- self.months = months
- if abs(self.months) > 11:
- s = self.months//abs(self.months)
- div, mod = divmod(self.months*s, 12)
- self.months = mod*s
- self.years = div*s
- else:
- self.years = 0
-
- def __radd__(self, other):
- if not isinstance(other, datetime.date):
- raise TypeError, "unsupported type for add operation"
- elif self._has_time and not isinstance(other, datetime.datetime):
- other = datetime.datetime.fromordinal(other.toordinal())
- year = (self.year or other.year)+self.years
- month = self.month or other.month
- if self.months:
- assert 1 <= abs(self.months) <= 12
- month += self.months
- if month > 12:
- year += 1
- month -= 12
- elif month < 1:
- year -= 1
- month += 12
- day = min(calendar.monthrange(year, month)[1],
- self.day or other.day)
- repl = {"year": year, "month": month, "day": day}
- for attr in ["hour", "minute", "second", "microsecond"]:
- value = getattr(self, attr)
- if value is not None:
- repl[attr] = value
- days = self.days
- if self.leapdays and month > 2 and calendar.isleap(year):
- days += self.leapdays
- ret = (other.replace(**repl)
- + datetime.timedelta(days=days,
- hours=self.hours,
- minutes=self.minutes,
- seconds=self.seconds,
- microseconds=self.microseconds))
- if self.weekday:
- weekday, nth = self.weekday.weekday, self.weekday.n or 1
- jumpdays = (abs(nth)-1)*7
- if nth > 0:
- jumpdays += (7-ret.weekday()+weekday)%7
- else:
- jumpdays += (ret.weekday()-weekday)%7
- jumpdays *= -1
- ret += datetime.timedelta(days=jumpdays)
- return ret
-
- def __rsub__(self, other):
- return self.__neg__().__radd__(other)
-
- def __add__(self, other):
- if not isinstance(other, relativedelta):
- raise TypeError, "unsupported type for add operation"
- return relativedelta(years=other.years+self.years,
- months=other.months+self.months,
- days=other.days+self.days,
- hours=other.hours+self.hours,
- minutes=other.minutes+self.minutes,
- seconds=other.seconds+self.seconds,
- microseconds=other.microseconds+self.microseconds,
- leapdays=other.leapdays or self.leapdays,
- year=other.year or self.year,
- month=other.month or self.month,
- day=other.day or self.day,
- weekday=other.weekday or self.weekday,
- hour=other.hour or self.hour,
- minute=other.minute or self.minute,
- second=other.second or self.second,
- microsecond=other.second or self.microsecond)
-
- def __sub__(self, other):
- if not isinstance(other, relativedelta):
- raise TypeError, "unsupported type for sub operation"
- return relativedelta(years=other.years-self.years,
- months=other.months-self.months,
- days=other.days-self.days,
- hours=other.hours-self.hours,
- minutes=other.minutes-self.minutes,
- seconds=other.seconds-self.seconds,
- microseconds=other.microseconds-self.microseconds,
- leapdays=other.leapdays or self.leapdays,
- year=other.year or self.year,
- month=other.month or self.month,
- day=other.day or self.day,
- weekday=other.weekday or self.weekday,
- hour=other.hour or self.hour,
- minute=other.minute or self.minute,
- second=other.second or self.second,
- microsecond=other.second or self.microsecond)
-
- def __neg__(self):
- return relativedelta(years=-self.years,
- months=-self.months,
- days=-self.days,
- hours=-self.hours,
- minutes=-self.minutes,
- seconds=-self.seconds,
- microseconds=-self.microseconds,
- leapdays=self.leapdays,
- year=self.year,
- month=self.month,
- day=self.day,
- weekday=self.weekday,
- hour=self.hour,
- minute=self.minute,
- second=self.second,
- microsecond=self.microsecond)
-
- def __nonzero__(self):
- return not (not self.years and
- not self.months and
- not self.days and
- not self.hours and
- not self.minutes and
- not self.seconds and
- not self.microseconds and
- not self.leapdays and
- self.year is None and
- self.month is None and
- self.day is None and
- self.weekday is None and
- self.hour is None and
- self.minute is None and
- self.second is None and
- self.microsecond is None)
-
- def __mul__(self, other):
- f = float(other)
- return relativedelta(years=self.years*f,
- months=self.months*f,
- days=self.days*f,
- hours=self.hours*f,
- minutes=self.minutes*f,
- seconds=self.seconds*f,
- microseconds=self.microseconds*f,
- leapdays=self.leapdays,
- year=self.year,
- month=self.month,
- day=self.day,
- weekday=self.weekday,
- hour=self.hour,
- minute=self.minute,
- second=self.second,
- microsecond=self.microsecond)
-
- def __eq__(self, other):
- if not isinstance(other, relativedelta):
- return False
- if self.weekday or other.weekday:
- if not self.weekday or not other.weekday:
- return False
- if self.weekday.weekday != other.weekday.weekday:
- return False
- n1, n2 = self.weekday.n, other.weekday.n
- if n1 != n2 and not ((not n1 or n1 == 1) and (not n2 or n2 == 1)):
- return False
- return (self.years == other.years and
- self.months == other.months and
- self.days == other.days and
- self.hours == other.hours and
- self.minutes == other.minutes and
- self.seconds == other.seconds and
- self.leapdays == other.leapdays and
- self.year == other.year and
- self.month == other.month and
- self.day == other.day and
- self.hour == other.hour and
- self.minute == other.minute and
- self.second == other.second and
- self.microsecond == other.microsecond)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __div__(self, other):
- return self.__mul__(1/float(other))
-
- def __repr__(self):
- l = []
- for attr in ["years", "months", "days", "leapdays",
- "hours", "minutes", "seconds", "microseconds"]:
- value = getattr(self, attr)
- if value:
- l.append("%s=%+d" % (attr, value))
- for attr in ["year", "month", "day", "weekday",
- "hour", "minute", "second", "microsecond"]:
- value = getattr(self, attr)
- if value is not None:
- l.append("%s=%s" % (attr, `value`))
- return "%s(%s)" % (self.__class__.__name__, ", ".join(l))
-
-# vim:ts=4:sw=4:et
diff --git a/dateutil/relativedelta.pyc b/dateutil/relativedelta.pyc
deleted file mode 100644
index 2809250..0000000
Binary files a/dateutil/relativedelta.pyc and /dev/null differ
diff --git a/dateutil/rrule.py b/dateutil/rrule.py
deleted file mode 100644
index 6bd83ca..0000000
--- a/dateutil/rrule.py
+++ /dev/null
@@ -1,1097 +0,0 @@
-"""
-Copyright (c) 2003-2010 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-
-import itertools
-import datetime
-import calendar
-import thread
-import sys
-
-__all__ = ["rrule", "rruleset", "rrulestr",
- "YEARLY", "MONTHLY", "WEEKLY", "DAILY",
- "HOURLY", "MINUTELY", "SECONDLY",
- "MO", "TU", "WE", "TH", "FR", "SA", "SU"]
-
-# Every mask is 7 days longer to handle cross-year weekly periods.
-M366MASK = tuple([1]*31+[2]*29+[3]*31+[4]*30+[5]*31+[6]*30+
- [7]*31+[8]*31+[9]*30+[10]*31+[11]*30+[12]*31+[1]*7)
-M365MASK = list(M366MASK)
-M29, M30, M31 = range(1,30), range(1,31), range(1,32)
-MDAY366MASK = tuple(M31+M29+M31+M30+M31+M30+M31+M31+M30+M31+M30+M31+M31[:7])
-MDAY365MASK = list(MDAY366MASK)
-M29, M30, M31 = range(-29,0), range(-30,0), range(-31,0)
-NMDAY366MASK = tuple(M31+M29+M31+M30+M31+M30+M31+M31+M30+M31+M30+M31+M31[:7])
-NMDAY365MASK = list(NMDAY366MASK)
-M366RANGE = (0,31,60,91,121,152,182,213,244,274,305,335,366)
-M365RANGE = (0,31,59,90,120,151,181,212,243,273,304,334,365)
-WDAYMASK = [0,1,2,3,4,5,6]*55
-del M29, M30, M31, M365MASK[59], MDAY365MASK[59], NMDAY365MASK[31]
-MDAY365MASK = tuple(MDAY365MASK)
-M365MASK = tuple(M365MASK)
-
-(YEARLY,
- MONTHLY,
- WEEKLY,
- DAILY,
- HOURLY,
- MINUTELY,
- SECONDLY) = range(7)
-
-# Imported on demand.
-easter = None
-parser = None
-
-class weekday(object):
- __slots__ = ["weekday", "n"]
-
- def __init__(self, weekday, n=None):
- if n == 0:
- raise ValueError, "Can't create weekday with n == 0"
- self.weekday = weekday
- self.n = n
-
- def __call__(self, n):
- if n == self.n:
- return self
- else:
- return self.__class__(self.weekday, n)
-
- def __eq__(self, other):
- try:
- if self.weekday != other.weekday or self.n != other.n:
- return False
- except AttributeError:
- return False
- return True
-
- def __repr__(self):
- s = ("MO", "TU", "WE", "TH", "FR", "SA", "SU")[self.weekday]
- if not self.n:
- return s
- else:
- return "%s(%+d)" % (s, self.n)
-
-MO, TU, WE, TH, FR, SA, SU = weekdays = tuple([weekday(x) for x in range(7)])
-
-class rrulebase:
- def __init__(self, cache=False):
- if cache:
- self._cache = []
- self._cache_lock = thread.allocate_lock()
- self._cache_gen = self._iter()
- self._cache_complete = False
- else:
- self._cache = None
- self._cache_complete = False
- self._len = None
-
- def __iter__(self):
- if self._cache_complete:
- return iter(self._cache)
- elif self._cache is None:
- return self._iter()
- else:
- return self._iter_cached()
-
- def _iter_cached(self):
- i = 0
- gen = self._cache_gen
- cache = self._cache
- acquire = self._cache_lock.acquire
- release = self._cache_lock.release
- while gen:
- if i == len(cache):
- acquire()
- if self._cache_complete:
- break
- try:
- for j in range(10):
- cache.append(gen.next())
- except StopIteration:
- self._cache_gen = gen = None
- self._cache_complete = True
- break
- release()
- yield cache[i]
- i += 1
- while i < self._len:
- yield cache[i]
- i += 1
-
- def __getitem__(self, item):
- if self._cache_complete:
- return self._cache[item]
- elif isinstance(item, slice):
- if item.step and item.step < 0:
- return list(iter(self))[item]
- else:
- return list(itertools.islice(self,
- item.start or 0,
- item.stop or sys.maxint,
- item.step or 1))
- elif item >= 0:
- gen = iter(self)
- try:
- for i in range(item+1):
- res = gen.next()
- except StopIteration:
- raise IndexError
- return res
- else:
- return list(iter(self))[item]
-
- def __contains__(self, item):
- if self._cache_complete:
- return item in self._cache
- else:
- for i in self:
- if i == item:
- return True
- elif i > item:
- return False
- return False
-
- # __len__() introduces a large performance penality.
- def count(self):
- if self._len is None:
- for x in self: pass
- return self._len
-
- def before(self, dt, inc=False):
- if self._cache_complete:
- gen = self._cache
- else:
- gen = self
- last = None
- if inc:
- for i in gen:
- if i > dt:
- break
- last = i
- else:
- for i in gen:
- if i >= dt:
- break
- last = i
- return last
-
- def after(self, dt, inc=False):
- if self._cache_complete:
- gen = self._cache
- else:
- gen = self
- if inc:
- for i in gen:
- if i >= dt:
- return i
- else:
- for i in gen:
- if i > dt:
- return i
- return None
-
- def between(self, after, before, inc=False):
- if self._cache_complete:
- gen = self._cache
- else:
- gen = self
- started = False
- l = []
- if inc:
- for i in gen:
- if i > before:
- break
- elif not started:
- if i >= after:
- started = True
- l.append(i)
- else:
- l.append(i)
- else:
- for i in gen:
- if i >= before:
- break
- elif not started:
- if i > after:
- started = True
- l.append(i)
- else:
- l.append(i)
- return l
-
-class rrule(rrulebase):
- def __init__(self, freq, dtstart=None,
- interval=1, wkst=None, count=None, until=None, bysetpos=None,
- bymonth=None, bymonthday=None, byyearday=None, byeaster=None,
- byweekno=None, byweekday=None,
- byhour=None, byminute=None, bysecond=None,
- cache=False):
- rrulebase.__init__(self, cache)
- global easter
- if not dtstart:
- dtstart = datetime.datetime.now().replace(microsecond=0)
- elif not isinstance(dtstart, datetime.datetime):
- dtstart = datetime.datetime.fromordinal(dtstart.toordinal())
- else:
- dtstart = dtstart.replace(microsecond=0)
- self._dtstart = dtstart
- self._tzinfo = dtstart.tzinfo
- self._freq = freq
- self._interval = interval
- self._count = count
- if until and not isinstance(until, datetime.datetime):
- until = datetime.datetime.fromordinal(until.toordinal())
- self._until = until
- if wkst is None:
- self._wkst = calendar.firstweekday()
- elif type(wkst) is int:
- self._wkst = wkst
- else:
- self._wkst = wkst.weekday
- if bysetpos is None:
- self._bysetpos = None
- elif type(bysetpos) is int:
- if bysetpos == 0 or not (-366 <= bysetpos <= 366):
- raise ValueError("bysetpos must be between 1 and 366, "
- "or between -366 and -1")
- self._bysetpos = (bysetpos,)
- else:
- self._bysetpos = tuple(bysetpos)
- for pos in self._bysetpos:
- if pos == 0 or not (-366 <= pos <= 366):
- raise ValueError("bysetpos must be between 1 and 366, "
- "or between -366 and -1")
- if not (byweekno or byyearday or bymonthday or
- byweekday is not None or byeaster is not None):
- if freq == YEARLY:
- if not bymonth:
- bymonth = dtstart.month
- bymonthday = dtstart.day
- elif freq == MONTHLY:
- bymonthday = dtstart.day
- elif freq == WEEKLY:
- byweekday = dtstart.weekday()
- # bymonth
- if not bymonth:
- self._bymonth = None
- elif type(bymonth) is int:
- self._bymonth = (bymonth,)
- else:
- self._bymonth = tuple(bymonth)
- # byyearday
- if not byyearday:
- self._byyearday = None
- elif type(byyearday) is int:
- self._byyearday = (byyearday,)
- else:
- self._byyearday = tuple(byyearday)
- # byeaster
- if byeaster is not None:
- if not easter:
- from dateutil import easter
- if type(byeaster) is int:
- self._byeaster = (byeaster,)
- else:
- self._byeaster = tuple(byeaster)
- else:
- self._byeaster = None
- # bymonthay
- if not bymonthday:
- self._bymonthday = ()
- self._bynmonthday = ()
- elif type(bymonthday) is int:
- if bymonthday < 0:
- self._bynmonthday = (bymonthday,)
- self._bymonthday = ()
- else:
- self._bymonthday = (bymonthday,)
- self._bynmonthday = ()
- else:
- self._bymonthday = tuple([x for x in bymonthday if x > 0])
- self._bynmonthday = tuple([x for x in bymonthday if x < 0])
- # byweekno
- if byweekno is None:
- self._byweekno = None
- elif type(byweekno) is int:
- self._byweekno = (byweekno,)
- else:
- self._byweekno = tuple(byweekno)
- # byweekday / bynweekday
- if byweekday is None:
- self._byweekday = None
- self._bynweekday = None
- elif type(byweekday) is int:
- self._byweekday = (byweekday,)
- self._bynweekday = None
- elif hasattr(byweekday, "n"):
- if not byweekday.n or freq > MONTHLY:
- self._byweekday = (byweekday.weekday,)
- self._bynweekday = None
- else:
- self._bynweekday = ((byweekday.weekday, byweekday.n),)
- self._byweekday = None
- else:
- self._byweekday = []
- self._bynweekday = []
- for wday in byweekday:
- if type(wday) is int:
- self._byweekday.append(wday)
- elif not wday.n or freq > MONTHLY:
- self._byweekday.append(wday.weekday)
- else:
- self._bynweekday.append((wday.weekday, wday.n))
- self._byweekday = tuple(self._byweekday)
- self._bynweekday = tuple(self._bynweekday)
- if not self._byweekday:
- self._byweekday = None
- elif not self._bynweekday:
- self._bynweekday = None
- # byhour
- if byhour is None:
- if freq < HOURLY:
- self._byhour = (dtstart.hour,)
- else:
- self._byhour = None
- elif type(byhour) is int:
- self._byhour = (byhour,)
- else:
- self._byhour = tuple(byhour)
- # byminute
- if byminute is None:
- if freq < MINUTELY:
- self._byminute = (dtstart.minute,)
- else:
- self._byminute = None
- elif type(byminute) is int:
- self._byminute = (byminute,)
- else:
- self._byminute = tuple(byminute)
- # bysecond
- if bysecond is None:
- if freq < SECONDLY:
- self._bysecond = (dtstart.second,)
- else:
- self._bysecond = None
- elif type(bysecond) is int:
- self._bysecond = (bysecond,)
- else:
- self._bysecond = tuple(bysecond)
-
- if self._freq >= HOURLY:
- self._timeset = None
- else:
- self._timeset = []
- for hour in self._byhour:
- for minute in self._byminute:
- for second in self._bysecond:
- self._timeset.append(
- datetime.time(hour, minute, second,
- tzinfo=self._tzinfo))
- self._timeset.sort()
- self._timeset = tuple(self._timeset)
-
- def _iter(self):
- year, month, day, hour, minute, second, weekday, yearday, _ = \
- self._dtstart.timetuple()
-
- # Some local variables to speed things up a bit
- freq = self._freq
- interval = self._interval
- wkst = self._wkst
- until = self._until
- bymonth = self._bymonth
- byweekno = self._byweekno
- byyearday = self._byyearday
- byweekday = self._byweekday
- byeaster = self._byeaster
- bymonthday = self._bymonthday
- bynmonthday = self._bynmonthday
- bysetpos = self._bysetpos
- byhour = self._byhour
- byminute = self._byminute
- bysecond = self._bysecond
-
- ii = _iterinfo(self)
- ii.rebuild(year, month)
-
- getdayset = {YEARLY:ii.ydayset,
- MONTHLY:ii.mdayset,
- WEEKLY:ii.wdayset,
- DAILY:ii.ddayset,
- HOURLY:ii.ddayset,
- MINUTELY:ii.ddayset,
- SECONDLY:ii.ddayset}[freq]
-
- if freq < HOURLY:
- timeset = self._timeset
- else:
- gettimeset = {HOURLY:ii.htimeset,
- MINUTELY:ii.mtimeset,
- SECONDLY:ii.stimeset}[freq]
- if ((freq >= HOURLY and
- self._byhour and hour not in self._byhour) or
- (freq >= MINUTELY and
- self._byminute and minute not in self._byminute) or
- (freq >= SECONDLY and
- self._bysecond and second not in self._bysecond)):
- timeset = ()
- else:
- timeset = gettimeset(hour, minute, second)
-
- total = 0
- count = self._count
- while True:
- # Get dayset with the right frequency
- dayset, start, end = getdayset(year, month, day)
-
- # Do the "hard" work ;-)
- filtered = False
- for i in dayset[start:end]:
- if ((bymonth and ii.mmask[i] not in bymonth) or
- (byweekno and not ii.wnomask[i]) or
- (byweekday and ii.wdaymask[i] not in byweekday) or
- (ii.nwdaymask and not ii.nwdaymask[i]) or
- (byeaster and not ii.eastermask[i]) or
- ((bymonthday or bynmonthday) and
- ii.mdaymask[i] not in bymonthday and
- ii.nmdaymask[i] not in bynmonthday) or
- (byyearday and
- ((i < ii.yearlen and i+1 not in byyearday
- and -ii.yearlen+i not in byyearday) or
- (i >= ii.yearlen and i+1-ii.yearlen not in byyearday
- and -ii.nextyearlen+i-ii.yearlen
- not in byyearday)))):
- dayset[i] = None
- filtered = True
-
- # Output results
- if bysetpos and timeset:
- poslist = []
- for pos in bysetpos:
- if pos < 0:
- daypos, timepos = divmod(pos, len(timeset))
- else:
- daypos, timepos = divmod(pos-1, len(timeset))
- try:
- i = [x for x in dayset[start:end]
- if x is not None][daypos]
- time = timeset[timepos]
- except IndexError:
- pass
- else:
- date = datetime.date.fromordinal(ii.yearordinal+i)
- res = datetime.datetime.combine(date, time)
- if res not in poslist:
- poslist.append(res)
- poslist.sort()
- for res in poslist:
- if until and res > until:
- self._len = total
- return
- elif res >= self._dtstart:
- total += 1
- yield res
- if count:
- count -= 1
- if not count:
- self._len = total
- return
- else:
- for i in dayset[start:end]:
- if i is not None:
- date = datetime.date.fromordinal(ii.yearordinal+i)
- for time in timeset:
- res = datetime.datetime.combine(date, time)
- if until and res > until:
- self._len = total
- return
- elif res >= self._dtstart:
- total += 1
- yield res
- if count:
- count -= 1
- if not count:
- self._len = total
- return
-
- # Handle frequency and interval
- fixday = False
- if freq == YEARLY:
- year += interval
- if year > datetime.MAXYEAR:
- self._len = total
- return
- ii.rebuild(year, month)
- elif freq == MONTHLY:
- month += interval
- if month > 12:
- div, mod = divmod(month, 12)
- month = mod
- year += div
- if month == 0:
- month = 12
- year -= 1
- if year > datetime.MAXYEAR:
- self._len = total
- return
- ii.rebuild(year, month)
- elif freq == WEEKLY:
- if wkst > weekday:
- day += -(weekday+1+(6-wkst))+self._interval*7
- else:
- day += -(weekday-wkst)+self._interval*7
- weekday = wkst
- fixday = True
- elif freq == DAILY:
- day += interval
- fixday = True
- elif freq == HOURLY:
- if filtered:
- # Jump to one iteration before next day
- hour += ((23-hour)//interval)*interval
- while True:
- hour += interval
- div, mod = divmod(hour, 24)
- if div:
- hour = mod
- day += div
- fixday = True
- if not byhour or hour in byhour:
- break
- timeset = gettimeset(hour, minute, second)
- elif freq == MINUTELY:
- if filtered:
- # Jump to one iteration before next day
- minute += ((1439-(hour*60+minute))//interval)*interval
- while True:
- minute += interval
- div, mod = divmod(minute, 60)
- if div:
- minute = mod
- hour += div
- div, mod = divmod(hour, 24)
- if div:
- hour = mod
- day += div
- fixday = True
- filtered = False
- if ((not byhour or hour in byhour) and
- (not byminute or minute in byminute)):
- break
- timeset = gettimeset(hour, minute, second)
- elif freq == SECONDLY:
- if filtered:
- # Jump to one iteration before next day
- second += (((86399-(hour*3600+minute*60+second))
- //interval)*interval)
- while True:
- second += self._interval
- div, mod = divmod(second, 60)
- if div:
- second = mod
- minute += div
- div, mod = divmod(minute, 60)
- if div:
- minute = mod
- hour += div
- div, mod = divmod(hour, 24)
- if div:
- hour = mod
- day += div
- fixday = True
- if ((not byhour or hour in byhour) and
- (not byminute or minute in byminute) and
- (not bysecond or second in bysecond)):
- break
- timeset = gettimeset(hour, minute, second)
-
- if fixday and day > 28:
- daysinmonth = calendar.monthrange(year, month)[1]
- if day > daysinmonth:
- while day > daysinmonth:
- day -= daysinmonth
- month += 1
- if month == 13:
- month = 1
- year += 1
- if year > datetime.MAXYEAR:
- self._len = total
- return
- daysinmonth = calendar.monthrange(year, month)[1]
- ii.rebuild(year, month)
-
-class _iterinfo(object):
- __slots__ = ["rrule", "lastyear", "lastmonth",
- "yearlen", "nextyearlen", "yearordinal", "yearweekday",
- "mmask", "mrange", "mdaymask", "nmdaymask",
- "wdaymask", "wnomask", "nwdaymask", "eastermask"]
-
- def __init__(self, rrule):
- for attr in self.__slots__:
- setattr(self, attr, None)
- self.rrule = rrule
-
- def rebuild(self, year, month):
- # Every mask is 7 days longer to handle cross-year weekly periods.
- rr = self.rrule
- if year != self.lastyear:
- self.yearlen = 365+calendar.isleap(year)
- self.nextyearlen = 365+calendar.isleap(year+1)
- firstyday = datetime.date(year, 1, 1)
- self.yearordinal = firstyday.toordinal()
- self.yearweekday = firstyday.weekday()
-
- wday = datetime.date(year, 1, 1).weekday()
- if self.yearlen == 365:
- self.mmask = M365MASK
- self.mdaymask = MDAY365MASK
- self.nmdaymask = NMDAY365MASK
- self.wdaymask = WDAYMASK[wday:]
- self.mrange = M365RANGE
- else:
- self.mmask = M366MASK
- self.mdaymask = MDAY366MASK
- self.nmdaymask = NMDAY366MASK
- self.wdaymask = WDAYMASK[wday:]
- self.mrange = M366RANGE
-
- if not rr._byweekno:
- self.wnomask = None
- else:
- self.wnomask = [0]*(self.yearlen+7)
- #no1wkst = firstwkst = self.wdaymask.index(rr._wkst)
- no1wkst = firstwkst = (7-self.yearweekday+rr._wkst)%7
- if no1wkst >= 4:
- no1wkst = 0
- # Number of days in the year, plus the days we got
- # from last year.
- wyearlen = self.yearlen+(self.yearweekday-rr._wkst)%7
- else:
- # Number of days in the year, minus the days we
- # left in last year.
- wyearlen = self.yearlen-no1wkst
- div, mod = divmod(wyearlen, 7)
- numweeks = div+mod//4
- for n in rr._byweekno:
- if n < 0:
- n += numweeks+1
- if not (0 < n <= numweeks):
- continue
- if n > 1:
- i = no1wkst+(n-1)*7
- if no1wkst != firstwkst:
- i -= 7-firstwkst
- else:
- i = no1wkst
- for j in range(7):
- self.wnomask[i] = 1
- i += 1
- if self.wdaymask[i] == rr._wkst:
- break
- if 1 in rr._byweekno:
- # Check week number 1 of next year as well
- # TODO: Check -numweeks for next year.
- i = no1wkst+numweeks*7
- if no1wkst != firstwkst:
- i -= 7-firstwkst
- if i < self.yearlen:
- # If week starts in next year, we
- # don't care about it.
- for j in range(7):
- self.wnomask[i] = 1
- i += 1
- if self.wdaymask[i] == rr._wkst:
- break
- if no1wkst:
- # Check last week number of last year as
- # well. If no1wkst is 0, either the year
- # started on week start, or week number 1
- # got days from last year, so there are no
- # days from last year's last week number in
- # this year.
- if -1 not in rr._byweekno:
- lyearweekday = datetime.date(year-1,1,1).weekday()
- lno1wkst = (7-lyearweekday+rr._wkst)%7
- lyearlen = 365+calendar.isleap(year-1)
- if lno1wkst >= 4:
- lno1wkst = 0
- lnumweeks = 52+(lyearlen+
- (lyearweekday-rr._wkst)%7)%7//4
- else:
- lnumweeks = 52+(self.yearlen-no1wkst)%7//4
- else:
- lnumweeks = -1
- if lnumweeks in rr._byweekno:
- for i in range(no1wkst):
- self.wnomask[i] = 1
-
- if (rr._bynweekday and
- (month != self.lastmonth or year != self.lastyear)):
- ranges = []
- if rr._freq == YEARLY:
- if rr._bymonth:
- for month in rr._bymonth:
- ranges.append(self.mrange[month-1:month+1])
- else:
- ranges = [(0, self.yearlen)]
- elif rr._freq == MONTHLY:
- ranges = [self.mrange[month-1:month+1]]
- if ranges:
- # Weekly frequency won't get here, so we may not
- # care about cross-year weekly periods.
- self.nwdaymask = [0]*self.yearlen
- for first, last in ranges:
- last -= 1
- for wday, n in rr._bynweekday:
- if n < 0:
- i = last+(n+1)*7
- i -= (self.wdaymask[i]-wday)%7
- else:
- i = first+(n-1)*7
- i += (7-self.wdaymask[i]+wday)%7
- if first <= i <= last:
- self.nwdaymask[i] = 1
-
- if rr._byeaster:
- self.eastermask = [0]*(self.yearlen+7)
- eyday = easter.easter(year).toordinal()-self.yearordinal
- for offset in rr._byeaster:
- self.eastermask[eyday+offset] = 1
-
- self.lastyear = year
- self.lastmonth = month
-
- def ydayset(self, year, month, day):
- return range(self.yearlen), 0, self.yearlen
-
- def mdayset(self, year, month, day):
- set = [None]*self.yearlen
- start, end = self.mrange[month-1:month+1]
- for i in range(start, end):
- set[i] = i
- return set, start, end
-
- def wdayset(self, year, month, day):
- # We need to handle cross-year weeks here.
- set = [None]*(self.yearlen+7)
- i = datetime.date(year, month, day).toordinal()-self.yearordinal
- start = i
- for j in range(7):
- set[i] = i
- i += 1
- #if (not (0 <= i < self.yearlen) or
- # self.wdaymask[i] == self.rrule._wkst):
- # This will cross the year boundary, if necessary.
- if self.wdaymask[i] == self.rrule._wkst:
- break
- return set, start, i
-
- def ddayset(self, year, month, day):
- set = [None]*self.yearlen
- i = datetime.date(year, month, day).toordinal()-self.yearordinal
- set[i] = i
- return set, i, i+1
-
- def htimeset(self, hour, minute, second):
- set = []
- rr = self.rrule
- for minute in rr._byminute:
- for second in rr._bysecond:
- set.append(datetime.time(hour, minute, second,
- tzinfo=rr._tzinfo))
- set.sort()
- return set
-
- def mtimeset(self, hour, minute, second):
- set = []
- rr = self.rrule
- for second in rr._bysecond:
- set.append(datetime.time(hour, minute, second, tzinfo=rr._tzinfo))
- set.sort()
- return set
-
- def stimeset(self, hour, minute, second):
- return (datetime.time(hour, minute, second,
- tzinfo=self.rrule._tzinfo),)
-
-
-class rruleset(rrulebase):
-
- class _genitem:
- def __init__(self, genlist, gen):
- try:
- self.dt = gen()
- genlist.append(self)
- except StopIteration:
- pass
- self.genlist = genlist
- self.gen = gen
-
- def next(self):
- try:
- self.dt = self.gen()
- except StopIteration:
- self.genlist.remove(self)
-
- def __cmp__(self, other):
- return cmp(self.dt, other.dt)
-
- def __init__(self, cache=False):
- rrulebase.__init__(self, cache)
- self._rrule = []
- self._rdate = []
- self._exrule = []
- self._exdate = []
-
- def rrule(self, rrule):
- self._rrule.append(rrule)
-
- def rdate(self, rdate):
- self._rdate.append(rdate)
-
- def exrule(self, exrule):
- self._exrule.append(exrule)
-
- def exdate(self, exdate):
- self._exdate.append(exdate)
-
- def _iter(self):
- rlist = []
- self._rdate.sort()
- self._genitem(rlist, iter(self._rdate).next)
- for gen in [iter(x).next for x in self._rrule]:
- self._genitem(rlist, gen)
- rlist.sort()
- exlist = []
- self._exdate.sort()
- self._genitem(exlist, iter(self._exdate).next)
- for gen in [iter(x).next for x in self._exrule]:
- self._genitem(exlist, gen)
- exlist.sort()
- lastdt = None
- total = 0
- while rlist:
- ritem = rlist[0]
- if not lastdt or lastdt != ritem.dt:
- while exlist and exlist[0] < ritem:
- exlist[0].next()
- exlist.sort()
- if not exlist or ritem != exlist[0]:
- total += 1
- yield ritem.dt
- lastdt = ritem.dt
- ritem.next()
- rlist.sort()
- self._len = total
-
-class _rrulestr:
-
- _freq_map = {"YEARLY": YEARLY,
- "MONTHLY": MONTHLY,
- "WEEKLY": WEEKLY,
- "DAILY": DAILY,
- "HOURLY": HOURLY,
- "MINUTELY": MINUTELY,
- "SECONDLY": SECONDLY}
-
- _weekday_map = {"MO":0,"TU":1,"WE":2,"TH":3,"FR":4,"SA":5,"SU":6}
-
- def _handle_int(self, rrkwargs, name, value, **kwargs):
- rrkwargs[name.lower()] = int(value)
-
- def _handle_int_list(self, rrkwargs, name, value, **kwargs):
- rrkwargs[name.lower()] = [int(x) for x in value.split(',')]
-
- _handle_INTERVAL = _handle_int
- _handle_COUNT = _handle_int
- _handle_BYSETPOS = _handle_int_list
- _handle_BYMONTH = _handle_int_list
- _handle_BYMONTHDAY = _handle_int_list
- _handle_BYYEARDAY = _handle_int_list
- _handle_BYEASTER = _handle_int_list
- _handle_BYWEEKNO = _handle_int_list
- _handle_BYHOUR = _handle_int_list
- _handle_BYMINUTE = _handle_int_list
- _handle_BYSECOND = _handle_int_list
-
- def _handle_FREQ(self, rrkwargs, name, value, **kwargs):
- rrkwargs["freq"] = self._freq_map[value]
-
- def _handle_UNTIL(self, rrkwargs, name, value, **kwargs):
- global parser
- if not parser:
- from dateutil import parser
- try:
- rrkwargs["until"] = parser.parse(value,
- ignoretz=kwargs.get("ignoretz"),
- tzinfos=kwargs.get("tzinfos"))
- except ValueError:
- raise ValueError, "invalid until date"
-
- def _handle_WKST(self, rrkwargs, name, value, **kwargs):
- rrkwargs["wkst"] = self._weekday_map[value]
-
- def _handle_BYWEEKDAY(self, rrkwargs, name, value, **kwarsg):
- l = []
- for wday in value.split(','):
- for i in range(len(wday)):
- if wday[i] not in '+-0123456789':
- break
- n = wday[:i] or None
- w = wday[i:]
- if n: n = int(n)
- l.append(weekdays[self._weekday_map[w]](n))
- rrkwargs["byweekday"] = l
-
- _handle_BYDAY = _handle_BYWEEKDAY
-
- def _parse_rfc_rrule(self, line,
- dtstart=None,
- cache=False,
- ignoretz=False,
- tzinfos=None):
- if line.find(':') != -1:
- name, value = line.split(':')
- if name != "RRULE":
- raise ValueError, "unknown parameter name"
- else:
- value = line
- rrkwargs = {}
- for pair in value.split(';'):
- name, value = pair.split('=')
- name = name.upper()
- value = value.upper()
- try:
- getattr(self, "_handle_"+name)(rrkwargs, name, value,
- ignoretz=ignoretz,
- tzinfos=tzinfos)
- except AttributeError:
- raise ValueError, "unknown parameter '%s'" % name
- except (KeyError, ValueError):
- raise ValueError, "invalid '%s': %s" % (name, value)
- return rrule(dtstart=dtstart, cache=cache, **rrkwargs)
-
- def _parse_rfc(self, s,
- dtstart=None,
- cache=False,
- unfold=False,
- forceset=False,
- compatible=False,
- ignoretz=False,
- tzinfos=None):
- global parser
- if compatible:
- forceset = True
- unfold = True
- s = s.upper()
- if not s.strip():
- raise ValueError, "empty string"
- if unfold:
- lines = s.splitlines()
- i = 0
- while i < len(lines):
- line = lines[i].rstrip()
- if not line:
- del lines[i]
- elif i > 0 and line[0] == " ":
- lines[i-1] += line[1:]
- del lines[i]
- else:
- i += 1
- else:
- lines = s.split()
- if (not forceset and len(lines) == 1 and
- (s.find(':') == -1 or s.startswith('RRULE:'))):
- return self._parse_rfc_rrule(lines[0], cache=cache,
- dtstart=dtstart, ignoretz=ignoretz,
- tzinfos=tzinfos)
- else:
- rrulevals = []
- rdatevals = []
- exrulevals = []
- exdatevals = []
- for line in lines:
- if not line:
- continue
- if line.find(':') == -1:
- name = "RRULE"
- value = line
- else:
- name, value = line.split(':', 1)
- parms = name.split(';')
- if not parms:
- raise ValueError, "empty property name"
- name = parms[0]
- parms = parms[1:]
- if name == "RRULE":
- for parm in parms:
- raise ValueError, "unsupported RRULE parm: "+parm
- rrulevals.append(value)
- elif name == "RDATE":
- for parm in parms:
- if parm != "VALUE=DATE-TIME":
- raise ValueError, "unsupported RDATE parm: "+parm
- rdatevals.append(value)
- elif name == "EXRULE":
- for parm in parms:
- raise ValueError, "unsupported EXRULE parm: "+parm
- exrulevals.append(value)
- elif name == "EXDATE":
- for parm in parms:
- if parm != "VALUE=DATE-TIME":
- raise ValueError, "unsupported RDATE parm: "+parm
- exdatevals.append(value)
- elif name == "DTSTART":
- for parm in parms:
- raise ValueError, "unsupported DTSTART parm: "+parm
- if not parser:
- from dateutil import parser
- dtstart = parser.parse(value, ignoretz=ignoretz,
- tzinfos=tzinfos)
- else:
- raise ValueError, "unsupported property: "+name
- if (forceset or len(rrulevals) > 1 or
- rdatevals or exrulevals or exdatevals):
- if not parser and (rdatevals or exdatevals):
- from dateutil import parser
- set = rruleset(cache=cache)
- for value in rrulevals:
- set.rrule(self._parse_rfc_rrule(value, dtstart=dtstart,
- ignoretz=ignoretz,
- tzinfos=tzinfos))
- for value in rdatevals:
- for datestr in value.split(','):
- set.rdate(parser.parse(datestr,
- ignoretz=ignoretz,
- tzinfos=tzinfos))
- for value in exrulevals:
- set.exrule(self._parse_rfc_rrule(value, dtstart=dtstart,
- ignoretz=ignoretz,
- tzinfos=tzinfos))
- for value in exdatevals:
- for datestr in value.split(','):
- set.exdate(parser.parse(datestr,
- ignoretz=ignoretz,
- tzinfos=tzinfos))
- if compatible and dtstart:
- set.rdate(dtstart)
- return set
- else:
- return self._parse_rfc_rrule(rrulevals[0],
- dtstart=dtstart,
- cache=cache,
- ignoretz=ignoretz,
- tzinfos=tzinfos)
-
- def __call__(self, s, **kwargs):
- return self._parse_rfc(s, **kwargs)
-
-rrulestr = _rrulestr()
-
-# vim:ts=4:sw=4:et
diff --git a/dateutil/tz.py b/dateutil/tz.py
deleted file mode 100644
index 0e28d6b..0000000
--- a/dateutil/tz.py
+++ /dev/null
@@ -1,951 +0,0 @@
-"""
-Copyright (c) 2003-2007 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-
-import datetime
-import struct
-import time
-import sys
-import os
-
-relativedelta = None
-parser = None
-rrule = None
-
-__all__ = ["tzutc", "tzoffset", "tzlocal", "tzfile", "tzrange",
- "tzstr", "tzical", "tzwin", "tzwinlocal", "gettz"]
-
-try:
- from dateutil.tzwin import tzwin, tzwinlocal
-except (ImportError, OSError):
- tzwin, tzwinlocal = None, None
-
-ZERO = datetime.timedelta(0)
-EPOCHORDINAL = datetime.datetime.utcfromtimestamp(0).toordinal()
-
-class tzutc(datetime.tzinfo):
-
- def utcoffset(self, dt):
- return ZERO
-
- def dst(self, dt):
- return ZERO
-
- def tzname(self, dt):
- return "UTC"
-
- def __eq__(self, other):
- return (isinstance(other, tzutc) or
- (isinstance(other, tzoffset) and other._offset == ZERO))
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __repr__(self):
- return "%s()" % self.__class__.__name__
-
- __reduce__ = object.__reduce__
-
-class tzoffset(datetime.tzinfo):
-
- def __init__(self, name, offset):
- self._name = name
- self._offset = datetime.timedelta(seconds=offset)
-
- def utcoffset(self, dt):
- return self._offset
-
- def dst(self, dt):
- return ZERO
-
- def tzname(self, dt):
- return self._name
-
- def __eq__(self, other):
- return (isinstance(other, tzoffset) and
- self._offset == other._offset)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __repr__(self):
- return "%s(%s, %s)" % (self.__class__.__name__,
- `self._name`,
- self._offset.days*86400+self._offset.seconds)
-
- __reduce__ = object.__reduce__
-
-class tzlocal(datetime.tzinfo):
-
- _std_offset = datetime.timedelta(seconds=-time.timezone)
- if time.daylight:
- _dst_offset = datetime.timedelta(seconds=-time.altzone)
- else:
- _dst_offset = _std_offset
-
- def utcoffset(self, dt):
- if self._isdst(dt):
- return self._dst_offset
- else:
- return self._std_offset
-
- def dst(self, dt):
- if self._isdst(dt):
- return self._dst_offset-self._std_offset
- else:
- return ZERO
-
- def tzname(self, dt):
- return time.tzname[self._isdst(dt)]
-
- def _isdst(self, dt):
- # We can't use mktime here. It is unstable when deciding if
- # the hour near to a change is DST or not.
- #
- # timestamp = time.mktime((dt.year, dt.month, dt.day, dt.hour,
- # dt.minute, dt.second, dt.weekday(), 0, -1))
- # return time.localtime(timestamp).tm_isdst
- #
- # The code above yields the following result:
- #
- #>>> import tz, datetime
- #>>> t = tz.tzlocal()
- #>>> datetime.datetime(2003,2,15,23,tzinfo=t).tzname()
- #'BRDT'
- #>>> datetime.datetime(2003,2,16,0,tzinfo=t).tzname()
- #'BRST'
- #>>> datetime.datetime(2003,2,15,23,tzinfo=t).tzname()
- #'BRST'
- #>>> datetime.datetime(2003,2,15,22,tzinfo=t).tzname()
- #'BRDT'
- #>>> datetime.datetime(2003,2,15,23,tzinfo=t).tzname()
- #'BRDT'
- #
- # Here is a more stable implementation:
- #
- timestamp = ((dt.toordinal() - EPOCHORDINAL) * 86400
- + dt.hour * 3600
- + dt.minute * 60
- + dt.second)
- return time.localtime(timestamp+time.timezone).tm_isdst
-
- def __eq__(self, other):
- if not isinstance(other, tzlocal):
- return False
- return (self._std_offset == other._std_offset and
- self._dst_offset == other._dst_offset)
- return True
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __repr__(self):
- return "%s()" % self.__class__.__name__
-
- __reduce__ = object.__reduce__
-
-class _ttinfo(object):
- __slots__ = ["offset", "delta", "isdst", "abbr", "isstd", "isgmt"]
-
- def __init__(self):
- for attr in self.__slots__:
- setattr(self, attr, None)
-
- def __repr__(self):
- l = []
- for attr in self.__slots__:
- value = getattr(self, attr)
- if value is not None:
- l.append("%s=%s" % (attr, `value`))
- return "%s(%s)" % (self.__class__.__name__, ", ".join(l))
-
- def __eq__(self, other):
- if not isinstance(other, _ttinfo):
- return False
- return (self.offset == other.offset and
- self.delta == other.delta and
- self.isdst == other.isdst and
- self.abbr == other.abbr and
- self.isstd == other.isstd and
- self.isgmt == other.isgmt)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __getstate__(self):
- state = {}
- for name in self.__slots__:
- state[name] = getattr(self, name, None)
- return state
-
- def __setstate__(self, state):
- for name in self.__slots__:
- if name in state:
- setattr(self, name, state[name])
-
-class tzfile(datetime.tzinfo):
-
- # http://www.twinsun.com/tz/tz-link.htm
- # ftp://elsie.nci.nih.gov/pub/tz*.tar.gz
-
- def __init__(self, fileobj):
- if isinstance(fileobj, basestring):
- self._filename = fileobj
- fileobj = open(fileobj)
- elif hasattr(fileobj, "name"):
- self._filename = fileobj.name
- else:
- self._filename = `fileobj`
-
- # From tzfile(5):
- #
- # The time zone information files used by tzset(3)
- # begin with the magic characters "TZif" to identify
- # them as time zone information files, followed by
- # sixteen bytes reserved for future use, followed by
- # six four-byte values of type long, written in a
- # ``standard'' byte order (the high-order byte
- # of the value is written first).
-
- if fileobj.read(4) != "TZif":
- raise ValueError, "magic not found"
-
- fileobj.read(16)
-
- (
- # The number of UTC/local indicators stored in the file.
- ttisgmtcnt,
-
- # The number of standard/wall indicators stored in the file.
- ttisstdcnt,
-
- # The number of leap seconds for which data is
- # stored in the file.
- leapcnt,
-
- # The number of "transition times" for which data
- # is stored in the file.
- timecnt,
-
- # The number of "local time types" for which data
- # is stored in the file (must not be zero).
- typecnt,
-
- # The number of characters of "time zone
- # abbreviation strings" stored in the file.
- charcnt,
-
- ) = struct.unpack(">6l", fileobj.read(24))
-
- # The above header is followed by tzh_timecnt four-byte
- # values of type long, sorted in ascending order.
- # These values are written in ``standard'' byte order.
- # Each is used as a transition time (as returned by
- # time(2)) at which the rules for computing local time
- # change.
-
- if timecnt:
- self._trans_list = struct.unpack(">%dl" % timecnt,
- fileobj.read(timecnt*4))
- else:
- self._trans_list = []
-
- # Next come tzh_timecnt one-byte values of type unsigned
- # char; each one tells which of the different types of
- # ``local time'' types described in the file is associated
- # with the same-indexed transition time. These values
- # serve as indices into an array of ttinfo structures that
- # appears next in the file.
-
- if timecnt:
- self._trans_idx = struct.unpack(">%dB" % timecnt,
- fileobj.read(timecnt))
- else:
- self._trans_idx = []
-
- # Each ttinfo structure is written as a four-byte value
- # for tt_gmtoff of type long, in a standard byte
- # order, followed by a one-byte value for tt_isdst
- # and a one-byte value for tt_abbrind. In each
- # structure, tt_gmtoff gives the number of
- # seconds to be added to UTC, tt_isdst tells whether
- # tm_isdst should be set by localtime(3), and
- # tt_abbrind serves as an index into the array of
- # time zone abbreviation characters that follow the
- # ttinfo structure(s) in the file.
-
- ttinfo = []
-
- for i in range(typecnt):
- ttinfo.append(struct.unpack(">lbb", fileobj.read(6)))
-
- abbr = fileobj.read(charcnt)
-
- # Then there are tzh_leapcnt pairs of four-byte
- # values, written in standard byte order; the
- # first value of each pair gives the time (as
- # returned by time(2)) at which a leap second
- # occurs; the second gives the total number of
- # leap seconds to be applied after the given time.
- # The pairs of values are sorted in ascending order
- # by time.
-
- # Not used, for now
- if leapcnt:
- leap = struct.unpack(">%dl" % (leapcnt*2),
- fileobj.read(leapcnt*8))
-
- # Then there are tzh_ttisstdcnt standard/wall
- # indicators, each stored as a one-byte value;
- # they tell whether the transition times associated
- # with local time types were specified as standard
- # time or wall clock time, and are used when
- # a time zone file is used in handling POSIX-style
- # time zone environment variables.
-
- if ttisstdcnt:
- isstd = struct.unpack(">%db" % ttisstdcnt,
- fileobj.read(ttisstdcnt))
-
- # Finally, there are tzh_ttisgmtcnt UTC/local
- # indicators, each stored as a one-byte value;
- # they tell whether the transition times associated
- # with local time types were specified as UTC or
- # local time, and are used when a time zone file
- # is used in handling POSIX-style time zone envi-
- # ronment variables.
-
- if ttisgmtcnt:
- isgmt = struct.unpack(">%db" % ttisgmtcnt,
- fileobj.read(ttisgmtcnt))
-
- # ** Everything has been read **
-
- # Build ttinfo list
- self._ttinfo_list = []
- for i in range(typecnt):
- gmtoff, isdst, abbrind = ttinfo[i]
- # Round to full-minutes if that's not the case. Python's
- # datetime doesn't accept sub-minute timezones. Check
- # http://python.org/sf/1447945 for some information.
- gmtoff = (gmtoff+30)//60*60
- tti = _ttinfo()
- tti.offset = gmtoff
- tti.delta = datetime.timedelta(seconds=gmtoff)
- tti.isdst = isdst
- tti.abbr = abbr[abbrind:abbr.find('\x00', abbrind)]
- tti.isstd = (ttisstdcnt > i and isstd[i] != 0)
- tti.isgmt = (ttisgmtcnt > i and isgmt[i] != 0)
- self._ttinfo_list.append(tti)
-
- # Replace ttinfo indexes for ttinfo objects.
- trans_idx = []
- for idx in self._trans_idx:
- trans_idx.append(self._ttinfo_list[idx])
- self._trans_idx = tuple(trans_idx)
-
- # Set standard, dst, and before ttinfos. before will be
- # used when a given time is before any transitions,
- # and will be set to the first non-dst ttinfo, or to
- # the first dst, if all of them are dst.
- self._ttinfo_std = None
- self._ttinfo_dst = None
- self._ttinfo_before = None
- if self._ttinfo_list:
- if not self._trans_list:
- self._ttinfo_std = self._ttinfo_first = self._ttinfo_list[0]
- else:
- for i in range(timecnt-1,-1,-1):
- tti = self._trans_idx[i]
- if not self._ttinfo_std and not tti.isdst:
- self._ttinfo_std = tti
- elif not self._ttinfo_dst and tti.isdst:
- self._ttinfo_dst = tti
- if self._ttinfo_std and self._ttinfo_dst:
- break
- else:
- if self._ttinfo_dst and not self._ttinfo_std:
- self._ttinfo_std = self._ttinfo_dst
-
- for tti in self._ttinfo_list:
- if not tti.isdst:
- self._ttinfo_before = tti
- break
- else:
- self._ttinfo_before = self._ttinfo_list[0]
-
- # Now fix transition times to become relative to wall time.
- #
- # I'm not sure about this. In my tests, the tz source file
- # is setup to wall time, and in the binary file isstd and
- # isgmt are off, so it should be in wall time. OTOH, it's
- # always in gmt time. Let me know if you have comments
- # about this.
- laststdoffset = 0
- self._trans_list = list(self._trans_list)
- for i in range(len(self._trans_list)):
- tti = self._trans_idx[i]
- if not tti.isdst:
- # This is std time.
- self._trans_list[i] += tti.offset
- laststdoffset = tti.offset
- else:
- # This is dst time. Convert to std.
- self._trans_list[i] += laststdoffset
- self._trans_list = tuple(self._trans_list)
-
- def _find_ttinfo(self, dt, laststd=0):
- timestamp = ((dt.toordinal() - EPOCHORDINAL) * 86400
- + dt.hour * 3600
- + dt.minute * 60
- + dt.second)
- idx = 0
- for trans in self._trans_list:
- if timestamp < trans:
- break
- idx += 1
- else:
- return self._ttinfo_std
- if idx == 0:
- return self._ttinfo_before
- if laststd:
- while idx > 0:
- tti = self._trans_idx[idx-1]
- if not tti.isdst:
- return tti
- idx -= 1
- else:
- return self._ttinfo_std
- else:
- return self._trans_idx[idx-1]
-
- def utcoffset(self, dt):
- if not self._ttinfo_std:
- return ZERO
- return self._find_ttinfo(dt).delta
-
- def dst(self, dt):
- if not self._ttinfo_dst:
- return ZERO
- tti = self._find_ttinfo(dt)
- if not tti.isdst:
- return ZERO
-
- # The documentation says that utcoffset()-dst() must
- # be constant for every dt.
- return tti.delta-self._find_ttinfo(dt, laststd=1).delta
-
- # An alternative for that would be:
- #
- # return self._ttinfo_dst.offset-self._ttinfo_std.offset
- #
- # However, this class stores historical changes in the
- # dst offset, so I belive that this wouldn't be the right
- # way to implement this.
-
- def tzname(self, dt):
- if not self._ttinfo_std:
- return None
- return self._find_ttinfo(dt).abbr
-
- def __eq__(self, other):
- if not isinstance(other, tzfile):
- return False
- return (self._trans_list == other._trans_list and
- self._trans_idx == other._trans_idx and
- self._ttinfo_list == other._ttinfo_list)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
-
- def __repr__(self):
- return "%s(%s)" % (self.__class__.__name__, `self._filename`)
-
- def __reduce__(self):
- if not os.path.isfile(self._filename):
- raise ValueError, "Unpickable %s class" % self.__class__.__name__
- return (self.__class__, (self._filename,))
-
-class tzrange(datetime.tzinfo):
-
- def __init__(self, stdabbr, stdoffset=None,
- dstabbr=None, dstoffset=None,
- start=None, end=None):
- global relativedelta
- if not relativedelta:
- from dateutil import relativedelta
- self._std_abbr = stdabbr
- self._dst_abbr = dstabbr
- if stdoffset is not None:
- self._std_offset = datetime.timedelta(seconds=stdoffset)
- else:
- self._std_offset = ZERO
- if dstoffset is not None:
- self._dst_offset = datetime.timedelta(seconds=dstoffset)
- elif dstabbr and stdoffset is not None:
- self._dst_offset = self._std_offset+datetime.timedelta(hours=+1)
- else:
- self._dst_offset = ZERO
- if dstabbr and start is None:
- self._start_delta = relativedelta.relativedelta(
- hours=+2, month=4, day=1, weekday=relativedelta.SU(+1))
- else:
- self._start_delta = start
- if dstabbr and end is None:
- self._end_delta = relativedelta.relativedelta(
- hours=+1, month=10, day=31, weekday=relativedelta.SU(-1))
- else:
- self._end_delta = end
-
- def utcoffset(self, dt):
- if self._isdst(dt):
- return self._dst_offset
- else:
- return self._std_offset
-
- def dst(self, dt):
- if self._isdst(dt):
- return self._dst_offset-self._std_offset
- else:
- return ZERO
-
- def tzname(self, dt):
- if self._isdst(dt):
- return self._dst_abbr
- else:
- return self._std_abbr
-
- def _isdst(self, dt):
- if not self._start_delta:
- return False
- year = datetime.datetime(dt.year,1,1)
- start = year+self._start_delta
- end = year+self._end_delta
- dt = dt.replace(tzinfo=None)
- if start < end:
- return dt >= start and dt < end
- else:
- return dt >= start or dt < end
-
- def __eq__(self, other):
- if not isinstance(other, tzrange):
- return False
- return (self._std_abbr == other._std_abbr and
- self._dst_abbr == other._dst_abbr and
- self._std_offset == other._std_offset and
- self._dst_offset == other._dst_offset and
- self._start_delta == other._start_delta and
- self._end_delta == other._end_delta)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __repr__(self):
- return "%s(...)" % self.__class__.__name__
-
- __reduce__ = object.__reduce__
-
-class tzstr(tzrange):
-
- def __init__(self, s):
- global parser
- if not parser:
- from dateutil import parser
- self._s = s
-
- res = parser._parsetz(s)
- if res is None:
- raise ValueError, "unknown string format"
-
- # Here we break the compatibility with the TZ variable handling.
- # GMT-3 actually *means* the timezone -3.
- if res.stdabbr in ("GMT", "UTC"):
- res.stdoffset *= -1
-
- # We must initialize it first, since _delta() needs
- # _std_offset and _dst_offset set. Use False in start/end
- # to avoid building it two times.
- tzrange.__init__(self, res.stdabbr, res.stdoffset,
- res.dstabbr, res.dstoffset,
- start=False, end=False)
-
- if not res.dstabbr:
- self._start_delta = None
- self._end_delta = None
- else:
- self._start_delta = self._delta(res.start)
- if self._start_delta:
- self._end_delta = self._delta(res.end, isend=1)
-
- def _delta(self, x, isend=0):
- kwargs = {}
- if x.month is not None:
- kwargs["month"] = x.month
- if x.weekday is not None:
- kwargs["weekday"] = relativedelta.weekday(x.weekday, x.week)
- if x.week > 0:
- kwargs["day"] = 1
- else:
- kwargs["day"] = 31
- elif x.day:
- kwargs["day"] = x.day
- elif x.yday is not None:
- kwargs["yearday"] = x.yday
- elif x.jyday is not None:
- kwargs["nlyearday"] = x.jyday
- if not kwargs:
- # Default is to start on first sunday of april, and end
- # on last sunday of october.
- if not isend:
- kwargs["month"] = 4
- kwargs["day"] = 1
- kwargs["weekday"] = relativedelta.SU(+1)
- else:
- kwargs["month"] = 10
- kwargs["day"] = 31
- kwargs["weekday"] = relativedelta.SU(-1)
- if x.time is not None:
- kwargs["seconds"] = x.time
- else:
- # Default is 2AM.
- kwargs["seconds"] = 7200
- if isend:
- # Convert to standard time, to follow the documented way
- # of working with the extra hour. See the documentation
- # of the tzinfo class.
- delta = self._dst_offset-self._std_offset
- kwargs["seconds"] -= delta.seconds+delta.days*86400
- return relativedelta.relativedelta(**kwargs)
-
- def __repr__(self):
- return "%s(%s)" % (self.__class__.__name__, `self._s`)
-
-class _tzicalvtzcomp:
- def __init__(self, tzoffsetfrom, tzoffsetto, isdst,
- tzname=None, rrule=None):
- self.tzoffsetfrom = datetime.timedelta(seconds=tzoffsetfrom)
- self.tzoffsetto = datetime.timedelta(seconds=tzoffsetto)
- self.tzoffsetdiff = self.tzoffsetto-self.tzoffsetfrom
- self.isdst = isdst
- self.tzname = tzname
- self.rrule = rrule
-
-class _tzicalvtz(datetime.tzinfo):
- def __init__(self, tzid, comps=[]):
- self._tzid = tzid
- self._comps = comps
- self._cachedate = []
- self._cachecomp = []
-
- def _find_comp(self, dt):
- if len(self._comps) == 1:
- return self._comps[0]
- dt = dt.replace(tzinfo=None)
- try:
- return self._cachecomp[self._cachedate.index(dt)]
- except ValueError:
- pass
- lastcomp = None
- lastcompdt = None
- for comp in self._comps:
- if not comp.isdst:
- # Handle the extra hour in DST -> STD
- compdt = comp.rrule.before(dt-comp.tzoffsetdiff, inc=True)
- else:
- compdt = comp.rrule.before(dt, inc=True)
- if compdt and (not lastcompdt or lastcompdt < compdt):
- lastcompdt = compdt
- lastcomp = comp
- if not lastcomp:
- # RFC says nothing about what to do when a given
- # time is before the first onset date. We'll look for the
- # first standard component, or the first component, if
- # none is found.
- for comp in self._comps:
- if not comp.isdst:
- lastcomp = comp
- break
- else:
- lastcomp = comp[0]
- self._cachedate.insert(0, dt)
- self._cachecomp.insert(0, lastcomp)
- if len(self._cachedate) > 10:
- self._cachedate.pop()
- self._cachecomp.pop()
- return lastcomp
-
- def utcoffset(self, dt):
- return self._find_comp(dt).tzoffsetto
-
- def dst(self, dt):
- comp = self._find_comp(dt)
- if comp.isdst:
- return comp.tzoffsetdiff
- else:
- return ZERO
-
- def tzname(self, dt):
- return self._find_comp(dt).tzname
-
- def __repr__(self):
- return "" % `self._tzid`
-
- __reduce__ = object.__reduce__
-
-class tzical:
- def __init__(self, fileobj):
- global rrule
- if not rrule:
- from dateutil import rrule
-
- if isinstance(fileobj, basestring):
- self._s = fileobj
- fileobj = open(fileobj)
- elif hasattr(fileobj, "name"):
- self._s = fileobj.name
- else:
- self._s = `fileobj`
-
- self._vtz = {}
-
- self._parse_rfc(fileobj.read())
-
- def keys(self):
- return self._vtz.keys()
-
- def get(self, tzid=None):
- if tzid is None:
- keys = self._vtz.keys()
- if len(keys) == 0:
- raise ValueError, "no timezones defined"
- elif len(keys) > 1:
- raise ValueError, "more than one timezone available"
- tzid = keys[0]
- return self._vtz.get(tzid)
-
- def _parse_offset(self, s):
- s = s.strip()
- if not s:
- raise ValueError, "empty offset"
- if s[0] in ('+', '-'):
- signal = (-1,+1)[s[0]=='+']
- s = s[1:]
- else:
- signal = +1
- if len(s) == 4:
- return (int(s[:2])*3600+int(s[2:])*60)*signal
- elif len(s) == 6:
- return (int(s[:2])*3600+int(s[2:4])*60+int(s[4:]))*signal
- else:
- raise ValueError, "invalid offset: "+s
-
- def _parse_rfc(self, s):
- lines = s.splitlines()
- if not lines:
- raise ValueError, "empty string"
-
- # Unfold
- i = 0
- while i < len(lines):
- line = lines[i].rstrip()
- if not line:
- del lines[i]
- elif i > 0 and line[0] == " ":
- lines[i-1] += line[1:]
- del lines[i]
- else:
- i += 1
-
- tzid = None
- comps = []
- invtz = False
- comptype = None
- for line in lines:
- if not line:
- continue
- name, value = line.split(':', 1)
- parms = name.split(';')
- if not parms:
- raise ValueError, "empty property name"
- name = parms[0].upper()
- parms = parms[1:]
- if invtz:
- if name == "BEGIN":
- if value in ("STANDARD", "DAYLIGHT"):
- # Process component
- pass
- else:
- raise ValueError, "unknown component: "+value
- comptype = value
- founddtstart = False
- tzoffsetfrom = None
- tzoffsetto = None
- rrulelines = []
- tzname = None
- elif name == "END":
- if value == "VTIMEZONE":
- if comptype:
- raise ValueError, \
- "component not closed: "+comptype
- if not tzid:
- raise ValueError, \
- "mandatory TZID not found"
- if not comps:
- raise ValueError, \
- "at least one component is needed"
- # Process vtimezone
- self._vtz[tzid] = _tzicalvtz(tzid, comps)
- invtz = False
- elif value == comptype:
- if not founddtstart:
- raise ValueError, \
- "mandatory DTSTART not found"
- if tzoffsetfrom is None:
- raise ValueError, \
- "mandatory TZOFFSETFROM not found"
- if tzoffsetto is None:
- raise ValueError, \
- "mandatory TZOFFSETFROM not found"
- # Process component
- rr = None
- if rrulelines:
- rr = rrule.rrulestr("\n".join(rrulelines),
- compatible=True,
- ignoretz=True,
- cache=True)
- comp = _tzicalvtzcomp(tzoffsetfrom, tzoffsetto,
- (comptype == "DAYLIGHT"),
- tzname, rr)
- comps.append(comp)
- comptype = None
- else:
- raise ValueError, \
- "invalid component end: "+value
- elif comptype:
- if name == "DTSTART":
- rrulelines.append(line)
- founddtstart = True
- elif name in ("RRULE", "RDATE", "EXRULE", "EXDATE"):
- rrulelines.append(line)
- elif name == "TZOFFSETFROM":
- if parms:
- raise ValueError, \
- "unsupported %s parm: %s "%(name, parms[0])
- tzoffsetfrom = self._parse_offset(value)
- elif name == "TZOFFSETTO":
- if parms:
- raise ValueError, \
- "unsupported TZOFFSETTO parm: "+parms[0]
- tzoffsetto = self._parse_offset(value)
- elif name == "TZNAME":
- if parms:
- raise ValueError, \
- "unsupported TZNAME parm: "+parms[0]
- tzname = value
- elif name == "COMMENT":
- pass
- else:
- raise ValueError, "unsupported property: "+name
- else:
- if name == "TZID":
- if parms:
- raise ValueError, \
- "unsupported TZID parm: "+parms[0]
- tzid = value
- elif name in ("TZURL", "LAST-MODIFIED", "COMMENT"):
- pass
- else:
- raise ValueError, "unsupported property: "+name
- elif name == "BEGIN" and value == "VTIMEZONE":
- tzid = None
- comps = []
- invtz = True
-
- def __repr__(self):
- return "%s(%s)" % (self.__class__.__name__, `self._s`)
-
-if sys.platform != "win32":
- TZFILES = ["/etc/localtime", "localtime"]
- TZPATHS = ["/usr/share/zoneinfo", "/usr/lib/zoneinfo", "/etc/zoneinfo"]
-else:
- TZFILES = []
- TZPATHS = []
-
-def gettz(name=None):
- tz = None
- if not name:
- try:
- name = os.environ["TZ"]
- except KeyError:
- pass
- if name is None or name == ":":
- for filepath in TZFILES:
- if not os.path.isabs(filepath):
- filename = filepath
- for path in TZPATHS:
- filepath = os.path.join(path, filename)
- if os.path.isfile(filepath):
- break
- else:
- continue
- if os.path.isfile(filepath):
- try:
- tz = tzfile(filepath)
- break
- except (IOError, OSError, ValueError):
- pass
- else:
- tz = tzlocal()
- else:
- if name.startswith(":"):
- name = name[:-1]
- if os.path.isabs(name):
- if os.path.isfile(name):
- tz = tzfile(name)
- else:
- tz = None
- else:
- for path in TZPATHS:
- filepath = os.path.join(path, name)
- if not os.path.isfile(filepath):
- filepath = filepath.replace(' ','_')
- if not os.path.isfile(filepath):
- continue
- try:
- tz = tzfile(filepath)
- break
- except (IOError, OSError, ValueError):
- pass
- else:
- tz = None
- if tzwin:
- try:
- tz = tzwin(name)
- except OSError:
- pass
- if not tz:
- from dateutil.zoneinfo import gettz
- tz = gettz(name)
- if not tz:
- for c in name:
- # name must have at least one offset to be a tzstr
- if c in "0123456789":
- try:
- tz = tzstr(name)
- except ValueError:
- pass
- break
- else:
- if name in ("GMT", "UTC"):
- tz = tzutc()
- elif name in time.tzname:
- tz = tzlocal()
- return tz
-
-# vim:ts=4:sw=4:et
diff --git a/dateutil/tzwin.py b/dateutil/tzwin.py
deleted file mode 100644
index 073e0ff..0000000
--- a/dateutil/tzwin.py
+++ /dev/null
@@ -1,180 +0,0 @@
-# This code was originally contributed by Jeffrey Harris.
-import datetime
-import struct
-import _winreg
-
-__author__ = "Jeffrey Harris & Gustavo Niemeyer "
-
-__all__ = ["tzwin", "tzwinlocal"]
-
-ONEWEEK = datetime.timedelta(7)
-
-TZKEYNAMENT = r"SOFTWARE\Microsoft\Windows NT\CurrentVersion\Time Zones"
-TZKEYNAME9X = r"SOFTWARE\Microsoft\Windows\CurrentVersion\Time Zones"
-TZLOCALKEYNAME = r"SYSTEM\CurrentControlSet\Control\TimeZoneInformation"
-
-def _settzkeyname():
- global TZKEYNAME
- handle = _winreg.ConnectRegistry(None, _winreg.HKEY_LOCAL_MACHINE)
- try:
- _winreg.OpenKey(handle, TZKEYNAMENT).Close()
- TZKEYNAME = TZKEYNAMENT
- except WindowsError:
- TZKEYNAME = TZKEYNAME9X
- handle.Close()
-
-_settzkeyname()
-
-class tzwinbase(datetime.tzinfo):
- """tzinfo class based on win32's timezones available in the registry."""
-
- def utcoffset(self, dt):
- if self._isdst(dt):
- return datetime.timedelta(minutes=self._dstoffset)
- else:
- return datetime.timedelta(minutes=self._stdoffset)
-
- def dst(self, dt):
- if self._isdst(dt):
- minutes = self._dstoffset - self._stdoffset
- return datetime.timedelta(minutes=minutes)
- else:
- return datetime.timedelta(0)
-
- def tzname(self, dt):
- if self._isdst(dt):
- return self._dstname
- else:
- return self._stdname
-
- def list():
- """Return a list of all time zones known to the system."""
- handle = _winreg.ConnectRegistry(None, _winreg.HKEY_LOCAL_MACHINE)
- tzkey = _winreg.OpenKey(handle, TZKEYNAME)
- result = [_winreg.EnumKey(tzkey, i)
- for i in range(_winreg.QueryInfoKey(tzkey)[0])]
- tzkey.Close()
- handle.Close()
- return result
- list = staticmethod(list)
-
- def display(self):
- return self._display
-
- def _isdst(self, dt):
- dston = picknthweekday(dt.year, self._dstmonth, self._dstdayofweek,
- self._dsthour, self._dstminute,
- self._dstweeknumber)
- dstoff = picknthweekday(dt.year, self._stdmonth, self._stddayofweek,
- self._stdhour, self._stdminute,
- self._stdweeknumber)
- if dston < dstoff:
- return dston <= dt.replace(tzinfo=None) < dstoff
- else:
- return not dstoff <= dt.replace(tzinfo=None) < dston
-
-
-class tzwin(tzwinbase):
-
- def __init__(self, name):
- self._name = name
-
- handle = _winreg.ConnectRegistry(None, _winreg.HKEY_LOCAL_MACHINE)
- tzkey = _winreg.OpenKey(handle, "%s\%s" % (TZKEYNAME, name))
- keydict = valuestodict(tzkey)
- tzkey.Close()
- handle.Close()
-
- self._stdname = keydict["Std"].encode("iso-8859-1")
- self._dstname = keydict["Dlt"].encode("iso-8859-1")
-
- self._display = keydict["Display"]
-
- # See http://ww_winreg.jsiinc.com/SUBA/tip0300/rh0398.htm
- tup = struct.unpack("=3l16h", keydict["TZI"])
- self._stdoffset = -tup[0]-tup[1] # Bias + StandardBias * -1
- self._dstoffset = self._stdoffset-tup[2] # + DaylightBias * -1
-
- (self._stdmonth,
- self._stddayofweek, # Sunday = 0
- self._stdweeknumber, # Last = 5
- self._stdhour,
- self._stdminute) = tup[4:9]
-
- (self._dstmonth,
- self._dstdayofweek, # Sunday = 0
- self._dstweeknumber, # Last = 5
- self._dsthour,
- self._dstminute) = tup[12:17]
-
- def __repr__(self):
- return "tzwin(%s)" % repr(self._name)
-
- def __reduce__(self):
- return (self.__class__, (self._name,))
-
-
-class tzwinlocal(tzwinbase):
-
- def __init__(self):
-
- handle = _winreg.ConnectRegistry(None, _winreg.HKEY_LOCAL_MACHINE)
-
- tzlocalkey = _winreg.OpenKey(handle, TZLOCALKEYNAME)
- keydict = valuestodict(tzlocalkey)
- tzlocalkey.Close()
-
- self._stdname = keydict["StandardName"].encode("iso-8859-1")
- self._dstname = keydict["DaylightName"].encode("iso-8859-1")
-
- try:
- tzkey = _winreg.OpenKey(handle, "%s\%s"%(TZKEYNAME, self._stdname))
- _keydict = valuestodict(tzkey)
- self._display = _keydict["Display"]
- tzkey.Close()
- except OSError:
- self._display = None
-
- handle.Close()
-
- self._stdoffset = -keydict["Bias"]-keydict["StandardBias"]
- self._dstoffset = self._stdoffset-keydict["DaylightBias"]
-
-
- # See http://ww_winreg.jsiinc.com/SUBA/tip0300/rh0398.htm
- tup = struct.unpack("=8h", keydict["StandardStart"])
-
- (self._stdmonth,
- self._stddayofweek, # Sunday = 0
- self._stdweeknumber, # Last = 5
- self._stdhour,
- self._stdminute) = tup[1:6]
-
- tup = struct.unpack("=8h", keydict["DaylightStart"])
-
- (self._dstmonth,
- self._dstdayofweek, # Sunday = 0
- self._dstweeknumber, # Last = 5
- self._dsthour,
- self._dstminute) = tup[1:6]
-
- def __reduce__(self):
- return (self.__class__, ())
-
-def picknthweekday(year, month, dayofweek, hour, minute, whichweek):
- """dayofweek == 0 means Sunday, whichweek 5 means last instance"""
- first = datetime.datetime(year, month, 1, hour, minute)
- weekdayone = first.replace(day=((dayofweek-first.isoweekday())%7+1))
- for n in xrange(whichweek):
- dt = weekdayone+(whichweek-n)*ONEWEEK
- if dt.month == month:
- return dt
-
-def valuestodict(key):
- """Convert a registry key's values to a dictionary."""
- dict = {}
- size = _winreg.QueryInfoKey(key)[1]
- for i in range(size):
- data = _winreg.EnumValue(key, i)
- dict[data[0]] = data[1]
- return dict
diff --git a/dateutil/zoneinfo/__init__.py b/dateutil/zoneinfo/__init__.py
deleted file mode 100644
index 9bed626..0000000
--- a/dateutil/zoneinfo/__init__.py
+++ /dev/null
@@ -1,87 +0,0 @@
-"""
-Copyright (c) 2003-2005 Gustavo Niemeyer
-
-This module offers extensions to the standard python 2.3+
-datetime module.
-"""
-from dateutil.tz import tzfile
-from tarfile import TarFile
-import os
-
-__author__ = "Gustavo Niemeyer "
-__license__ = "PSF License"
-
-__all__ = ["setcachesize", "gettz", "rebuild"]
-
-CACHE = []
-CACHESIZE = 10
-
-class tzfile(tzfile):
- def __reduce__(self):
- return (gettz, (self._filename,))
-
-def getzoneinfofile():
- filenames = os.listdir(os.path.join(os.path.dirname(__file__)))
- filenames.sort()
- filenames.reverse()
- for entry in filenames:
- if entry.startswith("zoneinfo") and ".tar." in entry:
- return os.path.join(os.path.dirname(__file__), entry)
- return None
-
-ZONEINFOFILE = getzoneinfofile()
-
-del getzoneinfofile
-
-def setcachesize(size):
- global CACHESIZE, CACHE
- CACHESIZE = size
- del CACHE[size:]
-
-def gettz(name):
- tzinfo = None
- if ZONEINFOFILE:
- for cachedname, tzinfo in CACHE:
- if cachedname == name:
- break
- else:
- tf = TarFile.open(ZONEINFOFILE)
- try:
- zonefile = tf.extractfile(name)
- except KeyError:
- tzinfo = None
- else:
- tzinfo = tzfile(zonefile)
- tf.close()
- CACHE.insert(0, (name, tzinfo))
- del CACHE[CACHESIZE:]
- return tzinfo
-
-def rebuild(filename, tag=None, format="gz"):
- import tempfile, shutil
- tmpdir = tempfile.mkdtemp()
- zonedir = os.path.join(tmpdir, "zoneinfo")
- moduledir = os.path.dirname(__file__)
- if tag: tag = "-"+tag
- targetname = "zoneinfo%s.tar.%s" % (tag, format)
- try:
- tf = TarFile.open(filename)
- for name in tf.getnames():
- if not (name.endswith(".sh") or
- name.endswith(".tab") or
- name == "leapseconds"):
- tf.extract(name, tmpdir)
- filepath = os.path.join(tmpdir, name)
- os.system("zic -d %s %s" % (zonedir, filepath))
- tf.close()
- target = os.path.join(moduledir, targetname)
- for entry in os.listdir(moduledir):
- if entry.startswith("zoneinfo") and ".tar." in entry:
- os.unlink(os.path.join(moduledir, entry))
- tf = TarFile.open(target, "w:%s" % format)
- for entry in os.listdir(zonedir):
- entrypath = os.path.join(zonedir, entry)
- tf.add(entrypath, entry)
- tf.close()
- finally:
- shutil.rmtree(tmpdir)
diff --git a/dateutil/zoneinfo/zoneinfo-2010g.tar.gz b/dateutil/zoneinfo/zoneinfo-2010g.tar.gz
deleted file mode 100644
index 8bd4f96..0000000
Binary files a/dateutil/zoneinfo/zoneinfo-2010g.tar.gz and /dev/null differ
diff --git a/humanfriendly.pyc b/humanfriendly.pyc
deleted file mode 100644
index 1bad1ce..0000000
Binary files a/humanfriendly.pyc and /dev/null differ
diff --git a/images/DateCalc.png b/images/DateCalc.png
new file mode 100644
index 0000000..d44f4b7
Binary files /dev/null and b/images/DateCalc.png differ
diff --git a/parsedatetime/__init__.py b/parsedatetime/__init__.py
deleted file mode 100755
index 990b9ca..0000000
--- a/parsedatetime/__init__.py
+++ /dev/null
@@ -1,2787 +0,0 @@
-# -*- coding: utf-8 -*-
-#
-# vim: sw=2 ts=2 sts=2
-#
-# Copyright 2004-2016 Mike Taylor
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""parsedatetime
-
-Parse human-readable date/time text.
-
-Requires Python 2.6 or later
-"""
-
-from __future__ import with_statement, absolute_import, unicode_literals
-
-import re
-import time
-import logging
-import warnings
-import datetime
-import calendar
-import contextlib
-import email.utils
-
-from .pdt_locales import (locales as _locales,
- get_icu, load_locale)
-from .context import pdtContext, pdtContextStack
-from .warns import pdt20DeprecationWarning
-
-
-__author__ = 'Mike Taylor'
-__email__ = 'bear@bear.im'
-__copyright__ = 'Copyright (c) 2017 Mike Taylor'
-__license__ = 'Apache License 2.0'
-__version__ = '2.5'
-__url__ = 'https://github.com/bear/parsedatetime'
-__download_url__ = 'https://pypi.python.org/pypi/parsedatetime'
-__description__ = 'Parse human-readable date/time text.'
-
-# as a library, do *not* setup logging
-# see docs.python.org/2/howto/logging.html#configuring-logging-for-a-library
-# Set default logging handler to avoid "No handler found" warnings.
-
-try: # Python 2.7+
- from logging import NullHandler
-except ImportError:
- class NullHandler(logging.Handler):
-
- def emit(self, record):
- pass
-
-log = logging.getLogger(__name__)
-log.addHandler(NullHandler())
-
-debug = False
-
-pdtLocales = dict([(x, load_locale(x)) for x in _locales])
-
-
-# Copied from feedparser.py
-# Universal Feedparser
-# Copyright (c) 2002-2006, Mark Pilgrim, All rights reserved.
-# Originally a def inside of _parse_date_w3dtf()
-def _extract_date(m):
- year = int(m.group('year'))
- if year < 100:
- year = 100 * int(time.gmtime()[0] / 100) + int(year)
- if year < 1000:
- return 0, 0, 0
- julian = m.group('julian')
- if julian:
- julian = int(julian)
- month = julian / 30 + 1
- day = julian % 30 + 1
- jday = None
- while jday != julian:
- t = time.mktime((year, month, day, 0, 0, 0, 0, 0, 0))
- jday = time.gmtime(t)[-2]
- diff = abs(jday - julian)
- if jday > julian:
- if diff < day:
- day = day - diff
- else:
- month = month - 1
- day = 31
- elif jday < julian:
- if day + diff < 28:
- day = day + diff
- else:
- month = month + 1
- return year, month, day
- month = m.group('month')
- day = 1
- if month is None:
- month = 1
- else:
- month = int(month)
- day = m.group('day')
- if day:
- day = int(day)
- else:
- day = 1
- return year, month, day
-
-
-# Copied from feedparser.py
-# Universal Feedparser
-# Copyright (c) 2002-2006, Mark Pilgrim, All rights reserved.
-# Originally a def inside of _parse_date_w3dtf()
-def _extract_time(m):
- if not m:
- return 0, 0, 0
- hours = m.group('hours')
- if not hours:
- return 0, 0, 0
- hours = int(hours)
- minutes = int(m.group('minutes'))
- seconds = m.group('seconds')
- if seconds:
- seconds = seconds.replace(',', '.').split('.', 1)[0]
- seconds = int(seconds)
- else:
- seconds = 0
- return hours, minutes, seconds
-
-
-def _pop_time_accuracy(m, ctx):
- if not m:
- return
- if m.group('hours'):
- ctx.updateAccuracy(ctx.ACU_HOUR)
- if m.group('minutes'):
- ctx.updateAccuracy(ctx.ACU_MIN)
- if m.group('seconds'):
- ctx.updateAccuracy(ctx.ACU_SEC)
-
-
-# Copied from feedparser.py
-# Universal Feedparser
-# Copyright (c) 2002-2006, Mark Pilgrim, All rights reserved.
-# Modified to return a tuple instead of mktime
-#
-# Original comment:
-# W3DTF-style date parsing adapted from PyXML xml.utils.iso8601, written by
-# Drake and licensed under the Python license. Removed all range checking
-# for month, day, hour, minute, and second, since mktime will normalize
-# these later
-def __closure_parse_date_w3dtf():
- # the __extract_date and __extract_time methods were
- # copied-out so they could be used by my code --bear
- def __extract_tzd(m):
- '''Return the Time Zone Designator as an offset in seconds from UTC.'''
- if not m:
- return 0
- tzd = m.group('tzd')
- if not tzd:
- return 0
- if tzd == 'Z':
- return 0
- hours = int(m.group('tzdhours'))
- minutes = m.group('tzdminutes')
- if minutes:
- minutes = int(minutes)
- else:
- minutes = 0
- offset = (hours * 60 + minutes) * 60
- if tzd[0] == '+':
- return -offset
- return offset
-
- def _parse_date_w3dtf(dateString):
- m = __datetime_rx.match(dateString)
- if m is None or m.group() != dateString:
- return
- return _extract_date(m) + _extract_time(m) + (0, 0, 0)
-
- __date_re = (r'(?P\d\d\d\d)'
- r'(?:(?P-|)'
- r'(?:(?P\d\d\d)'
- r'|(?P\d\d)(?:(?P=dsep)(?P\d\d))?))?')
- __tzd_re = r'(?P[-+](?P\d\d)(?::?(?P\d\d))|Z)'
- # __tzd_rx = re.compile(__tzd_re)
- __time_re = (r'(?P\d\d)(?P:|)(?P\d\d)'
- r'(?:(?P=tsep)(?P\d\d(?:[.,]\d+)?))?' +
- __tzd_re)
- __datetime_re = '%s(?:T%s)?' % (__date_re, __time_re)
- __datetime_rx = re.compile(__datetime_re)
-
- return _parse_date_w3dtf
-
-
-_parse_date_w3dtf = __closure_parse_date_w3dtf()
-del __closure_parse_date_w3dtf
-
-_monthnames = set([
- 'jan', 'feb', 'mar', 'apr', 'may', 'jun', 'jul',
- 'aug', 'sep', 'oct', 'nov', 'dec',
- 'january', 'february', 'march', 'april', 'may', 'june', 'july',
- 'august', 'september', 'october', 'november', 'december'])
-_daynames = set(['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun'])
-
-
-# Copied from feedparser.py
-# Universal Feedparser
-# Copyright (c) 2002-2006, Mark Pilgrim, All rights reserved.
-# Modified to return a tuple instead of mktime
-def _parse_date_rfc822(dateString):
- '''Parse an RFC822, RFC1123, RFC2822, or asctime-style date'''
- data = dateString.split()
- if data[0][-1] in (',', '.') or data[0].lower() in _daynames:
- del data[0]
- if len(data) == 4:
- s = data[3]
- s = s.split('+', 1)
- if len(s) == 2:
- data[3:] = s
- else:
- data.append('')
- dateString = " ".join(data)
- if len(data) < 5:
- dateString += ' 00:00:00 GMT'
- return email.utils.parsedate_tz(dateString)
-
-
-# rfc822.py defines several time zones, but we define some extra ones.
-# 'ET' is equivalent to 'EST', etc.
-# _additional_timezones = {'AT': -400, 'ET': -500,
-# 'CT': -600, 'MT': -700,
-# 'PT': -800}
-# email.utils._timezones.update(_additional_timezones)
-
-VERSION_FLAG_STYLE = 1
-VERSION_CONTEXT_STYLE = 2
-
-
-class Calendar(object):
-
- """
- A collection of routines to input, parse and manipulate date and times.
- The text can either be 'normal' date values or it can be human readable.
- """
-
- def __init__(self, constants=None, version=VERSION_FLAG_STYLE):
- """
- Default constructor for the L{Calendar} class.
-
- @type constants: object
- @param constants: Instance of the class L{Constants}
- @type version: integer
- @param version: Default style version of current Calendar instance.
- Valid value can be 1 (L{VERSION_FLAG_STYLE}) or
- 2 (L{VERSION_CONTEXT_STYLE}). See L{parse()}.
-
- @rtype: object
- @return: L{Calendar} instance
- """
- # if a constants reference is not included, use default
- if constants is None:
- self.ptc = Constants()
- else:
- self.ptc = constants
-
- self.version = version
- if version == VERSION_FLAG_STYLE:
- warnings.warn(
- 'Flag style will be deprecated in parsedatetime 2.0. '
- 'Instead use the context style by instantiating `Calendar()` '
- 'with argument `version=parsedatetime.VERSION_CONTEXT_STYLE`.',
- pdt20DeprecationWarning)
- self._ctxStack = pdtContextStack()
-
- @contextlib.contextmanager
- def context(self):
- ctx = pdtContext()
- self._ctxStack.push(ctx)
- yield ctx
- ctx = self._ctxStack.pop()
- if not self._ctxStack.isEmpty():
- self.currentContext.update(ctx)
-
- @property
- def currentContext(self):
- return self._ctxStack.last()
-
- def _convertUnitAsWords(self, unitText):
- """
- Converts text units into their number value.
-
- @type unitText: string
- @param unitText: number text to convert
-
- @rtype: integer
- @return: numerical value of unitText
- """
- word_list, a, b = re.split(r"[,\s-]+", unitText), 0, 0
- for word in word_list:
- x = self.ptc.small.get(word)
- if x is not None:
- a += x
- elif word == "hundred":
- a *= 100
- else:
- x = self.ptc.magnitude.get(word)
- if x is not None:
- b += a * x
- a = 0
- elif word in self.ptc.ignore:
- pass
- else:
- raise Exception("Unknown number: " + word)
- return a + b
-
- def _buildTime(self, source, quantity, modifier, units):
- """
- Take C{quantity}, C{modifier} and C{unit} strings and convert them
- into values. After converting, calcuate the time and return the
- adjusted sourceTime.
-
- @type source: time
- @param source: time to use as the base (or source)
- @type quantity: string
- @param quantity: quantity string
- @type modifier: string
- @param modifier: how quantity and units modify the source time
- @type units: string
- @param units: unit of the quantity (i.e. hours, days, months, etc)
-
- @rtype: struct_time
- @return: C{struct_time} of the calculated time
- """
- ctx = self.currentContext
- debug and log.debug('_buildTime: [%s][%s][%s]',
- quantity, modifier, units)
-
- if source is None:
- source = time.localtime()
-
- if quantity is None:
- quantity = ''
- else:
- quantity = quantity.strip()
-
- qty = self._quantityToReal(quantity)
-
- if modifier in self.ptc.Modifiers:
- qty = qty * self.ptc.Modifiers[modifier]
-
- if units is None or units == '':
- units = 'dy'
-
- # plurals are handled by regex's (could be a bug tho)
-
- (yr, mth, dy, hr, mn, sec, _, _, _) = source
-
- start = datetime.datetime(yr, mth, dy, hr, mn, sec)
- target = start
- # realunit = next((key for key, values in self.ptc.units.items()
- # if any(imap(units.__contains__, values))), None)
- realunit = units
- for key, values in self.ptc.units.items():
- if units in values:
- realunit = key
- break
-
- debug and log.debug('units %s --> realunit %s (qty=%s)',
- units, realunit, qty)
-
- try:
- if realunit in ('years', 'months'):
- target = self.inc(start, **{realunit[:-1]: qty})
- elif realunit in ('days', 'hours', 'minutes', 'seconds', 'weeks'):
- delta = datetime.timedelta(**{realunit: qty})
- target = start + delta
- except OverflowError:
- # OverflowError is raise when target.year larger than 9999
- pass
- else:
- ctx.updateAccuracy(realunit)
-
- return target.timetuple()
-
- def parseDate(self, dateString, sourceTime=None):
- """
- Parse short-form date strings::
-
- '05/28/2006' or '04.21'
-
- @type dateString: string
- @param dateString: text to convert to a C{datetime}
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: struct_time
- @return: calculated C{struct_time} value of dateString
- """
- if sourceTime is None:
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = time.localtime()
- else:
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = sourceTime
-
- # values pulled from regex's will be stored here and later
- # assigned to mth, dy, yr based on information from the locale
- # -1 is used as the marker value because we want zero values
- # to be passed thru so they can be flagged as errors later
- v1 = -1
- v2 = -1
- v3 = -1
- accuracy = []
-
- s = dateString
- m = self.ptc.CRE_DATE2.search(s)
- if m is not None:
- index = m.start()
- v1 = int(s[:index])
- s = s[index + 1:]
-
- m = self.ptc.CRE_DATE2.search(s)
- if m is not None:
- index = m.start()
- v2 = int(s[:index])
- v3 = int(s[index + 1:])
- else:
- v2 = int(s.strip())
-
- v = [v1, v2, v3]
- d = {'m': mth, 'd': dy, 'y': yr}
-
- # yyyy/mm/dd format
- dp_order = self.ptc.dp_order if v1 <= 31 else ['y', 'm', 'd']
-
- for i in range(0, 3):
- n = v[i]
- c = dp_order[i]
- if n >= 0:
- d[c] = n
- accuracy.append({'m': pdtContext.ACU_MONTH,
- 'd': pdtContext.ACU_DAY,
- 'y': pdtContext.ACU_YEAR}[c])
-
- # if the year is not specified and the date has already
- # passed, increment the year
- if v3 == -1 and ((mth > d['m']) or (mth == d['m'] and dy > d['d'])):
- yr = d['y'] + self.ptc.YearParseStyle
- else:
- yr = d['y']
-
- mth = d['m']
- dy = d['d']
-
- # birthday epoch constraint
- if yr < self.ptc.BirthdayEpoch:
- yr += 2000
- elif yr < 100:
- yr += 1900
-
- daysInCurrentMonth = self.ptc.daysInMonth(mth, yr)
- debug and log.debug('parseDate: %s %s %s %s',
- yr, mth, dy, daysInCurrentMonth)
-
- with self.context() as ctx:
- if mth > 0 and mth <= 12 and dy > 0 and \
- dy <= daysInCurrentMonth:
- sourceTime = (yr, mth, dy, hr, mn, sec, wd, yd, isdst)
- ctx.updateAccuracy(*accuracy)
- else:
- # return current time if date string is invalid
- sourceTime = time.localtime()
-
- return sourceTime
-
- def parseDateText(self, dateString, sourceTime=None):
- """
- Parse long-form date strings::
-
- 'May 31st, 2006'
- 'Jan 1st'
- 'July 2006'
-
- @type dateString: string
- @param dateString: text to convert to a datetime
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: struct_time
- @return: calculated C{struct_time} value of dateString
- """
- if sourceTime is None:
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = time.localtime()
- else:
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = sourceTime
-
- currentMth = mth
- currentDy = dy
- accuracy = []
-
- debug and log.debug('parseDateText currentMth %s currentDy %s',
- mth, dy)
-
- s = dateString.lower()
- m = self.ptc.CRE_DATE3.search(s)
- mth = m.group('mthname')
- mth = self.ptc.MonthOffsets[mth]
- accuracy.append('month')
-
- if m.group('day') is not None:
- dy = int(m.group('day'))
- accuracy.append('day')
- else:
- dy = 1
-
- if m.group('year') is not None:
- yr = int(m.group('year'))
- accuracy.append('year')
-
- # birthday epoch constraint
- if yr < self.ptc.BirthdayEpoch:
- yr += 2000
- elif yr < 100:
- yr += 1900
-
- elif (mth < currentMth) or (mth == currentMth and dy < currentDy):
- # if that day and month have already passed in this year,
- # then increment the year by 1
- yr += self.ptc.YearParseStyle
-
- with self.context() as ctx:
- if dy > 0 and dy <= self.ptc.daysInMonth(mth, yr):
- sourceTime = (yr, mth, dy, hr, mn, sec, wd, yd, isdst)
- ctx.updateAccuracy(*accuracy)
- else:
- # Return current time if date string is invalid
- sourceTime = time.localtime()
-
- debug and log.debug('parseDateText returned '
- 'mth %d dy %d yr %d sourceTime %s',
- mth, dy, yr, sourceTime)
-
- return sourceTime
-
- def evalRanges(self, datetimeString, sourceTime=None):
- """
- Evaluate the C{datetimeString} text and determine if
- it represents a date or time range.
-
- @type datetimeString: string
- @param datetimeString: datetime text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of: start datetime, end datetime and the invalid flag
- """
- rangeFlag = retFlag = 0
- startStr = endStr = ''
-
- s = datetimeString.strip().lower()
-
- if self.ptc.rangeSep in s:
- s = s.replace(self.ptc.rangeSep, ' %s ' % self.ptc.rangeSep)
- s = s.replace(' ', ' ')
-
- for cre, rflag in [(self.ptc.CRE_TIMERNG1, 1),
- (self.ptc.CRE_TIMERNG2, 2),
- (self.ptc.CRE_TIMERNG4, 7),
- (self.ptc.CRE_TIMERNG3, 3),
- (self.ptc.CRE_DATERNG1, 4),
- (self.ptc.CRE_DATERNG2, 5),
- (self.ptc.CRE_DATERNG3, 6)]:
- m = cre.search(s)
- if m is not None:
- rangeFlag = rflag
- break
-
- debug and log.debug('evalRanges: rangeFlag = %s [%s]', rangeFlag, s)
-
- if m is not None:
- if (m.group() != s):
- # capture remaining string
- parseStr = m.group()
- chunk1 = s[:m.start()]
- chunk2 = s[m.end():]
- s = '%s %s' % (chunk1, chunk2)
-
- sourceTime, ctx = self.parse(s, sourceTime,
- VERSION_CONTEXT_STYLE)
-
- if not ctx.hasDateOrTime:
- sourceTime = None
- else:
- parseStr = s
-
- if rangeFlag in (1, 2):
- m = re.search(self.ptc.rangeSep, parseStr)
- startStr = parseStr[:m.start()]
- endStr = parseStr[m.start() + 1:]
- retFlag = 2
-
- elif rangeFlag in (3, 7):
- m = re.search(self.ptc.rangeSep, parseStr)
- # capturing the meridian from the end time
- if self.ptc.usesMeridian:
- ampm = re.search(self.ptc.am[0], parseStr)
-
- # appending the meridian to the start time
- if ampm is not None:
- startStr = parseStr[:m.start()] + self.ptc.meridian[0]
- else:
- startStr = parseStr[:m.start()] + self.ptc.meridian[1]
- else:
- startStr = parseStr[:m.start()]
-
- endStr = parseStr[m.start() + 1:]
- retFlag = 2
-
- elif rangeFlag == 4:
- m = re.search(self.ptc.rangeSep, parseStr)
- startStr = parseStr[:m.start()]
- endStr = parseStr[m.start() + 1:]
- retFlag = 1
-
- elif rangeFlag == 5:
- m = re.search(self.ptc.rangeSep, parseStr)
- endStr = parseStr[m.start() + 1:]
-
- # capturing the year from the end date
- date = self.ptc.CRE_DATE3.search(endStr)
- endYear = date.group('year')
-
- # appending the year to the start date if the start date
- # does not have year information and the end date does.
- # eg : "Aug 21 - Sep 4, 2007"
- if endYear is not None:
- startStr = (parseStr[:m.start()]).strip()
- date = self.ptc.CRE_DATE3.search(startStr)
- startYear = date.group('year')
-
- if startYear is None:
- startStr = startStr + ', ' + endYear
- else:
- startStr = parseStr[:m.start()]
-
- retFlag = 1
-
- elif rangeFlag == 6:
- m = re.search(self.ptc.rangeSep, parseStr)
-
- startStr = parseStr[:m.start()]
-
- # capturing the month from the start date
- mth = self.ptc.CRE_DATE3.search(startStr)
- mth = mth.group('mthname')
-
- # appending the month name to the end date
- endStr = mth + parseStr[(m.start() + 1):]
-
- retFlag = 1
-
- else:
- # if range is not found
- startDT = endDT = time.localtime()
-
- if retFlag:
- startDT, sctx = self.parse(startStr, sourceTime,
- VERSION_CONTEXT_STYLE)
- endDT, ectx = self.parse(endStr, sourceTime,
- VERSION_CONTEXT_STYLE)
-
- if not sctx.hasDateOrTime or not ectx.hasDateOrTime:
- retFlag = 0
-
- return startDT, endDT, retFlag
-
- def _CalculateDOWDelta(self, wd, wkdy, offset, style, currentDayStyle):
- """
- Based on the C{style} and C{currentDayStyle} determine what
- day-of-week value is to be returned.
-
- @type wd: integer
- @param wd: day-of-week value for the current day
- @type wkdy: integer
- @param wkdy: day-of-week value for the parsed day
- @type offset: integer
- @param offset: offset direction for any modifiers (-1, 0, 1)
- @type style: integer
- @param style: normally the value
- set in C{Constants.DOWParseStyle}
- @type currentDayStyle: integer
- @param currentDayStyle: normally the value
- set in C{Constants.CurrentDOWParseStyle}
-
- @rtype: integer
- @return: calculated day-of-week
- """
- diffBase = wkdy - wd
- origOffset = offset
-
- if offset == 2:
- # no modifier is present.
- # i.e. string to be parsed is just DOW
- if wkdy * style > wd * style or \
- currentDayStyle and wkdy == wd:
- # wkdy located in current week
- offset = 0
- elif style in (-1, 1):
- # wkdy located in last (-1) or next (1) week
- offset = style
- else:
- # invalid style, or should raise error?
- offset = 0
-
- # offset = -1 means last week
- # offset = 0 means current week
- # offset = 1 means next week
- diff = diffBase + 7 * offset
- if style == 1 and diff < -7:
- diff += 7
- elif style == -1 and diff > 7:
- diff -= 7
-
- debug and log.debug("wd %s, wkdy %s, offset %d, "
- "style %d, currentDayStyle %d",
- wd, wkdy, origOffset, style, currentDayStyle)
-
- return diff
-
- def _quantityToReal(self, quantity):
- """
- Convert a quantity, either spelled-out or numeric, to a float
-
- @type quantity: string
- @param quantity: quantity to parse to float
- @rtype: int
- @return: the quantity as an float, defaulting to 0.0
- """
- if not quantity:
- return 1.0
-
- try:
- return float(quantity.replace(',', '.'))
- except ValueError:
- pass
-
- try:
- return float(self.ptc.numbers[quantity])
- except KeyError:
- pass
-
- return 0.0
-
- def _evalModifier(self, modifier, chunk1, chunk2, sourceTime):
- """
- Evaluate the C{modifier} string and following text (passed in
- as C{chunk1} and C{chunk2}) and if they match any known modifiers
- calculate the delta and apply it to C{sourceTime}.
-
- @type modifier: string
- @param modifier: modifier text to apply to sourceTime
- @type chunk1: string
- @param chunk1: text chunk that preceded modifier (if any)
- @type chunk2: string
- @param chunk2: text chunk that followed modifier (if any)
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of: remaining text and the modified sourceTime
- """
- ctx = self.currentContext
- offset = self.ptc.Modifiers[modifier]
-
- if sourceTime is not None:
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst) = sourceTime
- else:
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst) = time.localtime()
-
- if self.ptc.StartTimeFromSourceTime:
- startHour = hr
- startMinute = mn
- startSecond = sec
- else:
- startHour = 9
- startMinute = 0
- startSecond = 0
-
- # capture the units after the modifier and the remaining
- # string after the unit
- m = self.ptc.CRE_REMAINING.search(chunk2)
- if m is not None:
- index = m.start() + 1
- unit = chunk2[:m.start()]
- chunk2 = chunk2[index:]
- else:
- unit = chunk2
- chunk2 = ''
-
- debug and log.debug("modifier [%s] chunk1 [%s] "
- "chunk2 [%s] unit [%s]",
- modifier, chunk1, chunk2, unit)
-
- if unit in self.ptc.units['months']:
- currentDaysInMonth = self.ptc.daysInMonth(mth, yr)
- if offset == 0:
- dy = currentDaysInMonth
- sourceTime = (yr, mth, dy, startHour, startMinute,
- startSecond, wd, yd, isdst)
- elif offset == 2:
- # if day is the last day of the month, calculate the last day
- # of the next month
- if dy == currentDaysInMonth:
- dy = self.ptc.daysInMonth(mth + 1, yr)
-
- start = datetime.datetime(yr, mth, dy, startHour,
- startMinute, startSecond)
- target = self.inc(start, month=1)
- sourceTime = target.timetuple()
- else:
- start = datetime.datetime(yr, mth, 1, startHour,
- startMinute, startSecond)
- target = self.inc(start, month=offset)
- sourceTime = target.timetuple()
- ctx.updateAccuracy(ctx.ACU_MONTH)
-
- elif unit in self.ptc.units['weeks']:
- if offset == 0:
- start = datetime.datetime(yr, mth, dy, 17, 0, 0)
- target = start + datetime.timedelta(days=(4 - wd))
- sourceTime = target.timetuple()
- elif offset == 2:
- start = datetime.datetime(yr, mth, dy, startHour,
- startMinute, startSecond)
- target = start + datetime.timedelta(days=7)
- sourceTime = target.timetuple()
- else:
- start = datetime.datetime(yr, mth, dy, startHour,
- startMinute, startSecond)
- target = start + offset * datetime.timedelta(weeks=1)
- sourceTime = target.timetuple()
- ctx.updateAccuracy(ctx.ACU_WEEK)
-
- elif unit in self.ptc.units['days']:
- if offset == 0:
- sourceTime = (yr, mth, dy, 17, 0, 0, wd, yd, isdst)
- ctx.updateAccuracy(ctx.ACU_HALFDAY)
- elif offset == 2:
- start = datetime.datetime(yr, mth, dy, hr, mn, sec)
- target = start + datetime.timedelta(days=1)
- sourceTime = target.timetuple()
- else:
- start = datetime.datetime(yr, mth, dy, startHour,
- startMinute, startSecond)
- target = start + datetime.timedelta(days=offset)
- sourceTime = target.timetuple()
- ctx.updateAccuracy(ctx.ACU_DAY)
-
- elif unit in self.ptc.units['hours']:
- if offset == 0:
- sourceTime = (yr, mth, dy, hr, 0, 0, wd, yd, isdst)
- else:
- start = datetime.datetime(yr, mth, dy, hr, 0, 0)
- target = start + datetime.timedelta(hours=offset)
- sourceTime = target.timetuple()
- ctx.updateAccuracy(ctx.ACU_HOUR)
-
- elif unit in self.ptc.units['years']:
- if offset == 0:
- sourceTime = (yr, 12, 31, hr, mn, sec, wd, yd, isdst)
- elif offset == 2:
- sourceTime = (yr + 1, mth, dy, hr, mn, sec, wd, yd, isdst)
- else:
- sourceTime = (yr + offset, 1, 1, startHour, startMinute,
- startSecond, wd, yd, isdst)
- ctx.updateAccuracy(ctx.ACU_YEAR)
-
- elif modifier == 'eom':
- dy = self.ptc.daysInMonth(mth, yr)
- sourceTime = (yr, mth, dy, startHour, startMinute,
- startSecond, wd, yd, isdst)
- ctx.updateAccuracy(ctx.ACU_DAY)
-
- elif modifier == 'eoy':
- mth = 12
- dy = self.ptc.daysInMonth(mth, yr)
- sourceTime = (yr, mth, dy, startHour, startMinute,
- startSecond, wd, yd, isdst)
- ctx.updateAccuracy(ctx.ACU_MONTH)
-
- elif self.ptc.CRE_WEEKDAY.match(unit):
- m = self.ptc.CRE_WEEKDAY.match(unit)
- debug and log.debug('CRE_WEEKDAY matched')
- wkdy = m.group()
-
- if modifier == 'eod':
- ctx.updateAccuracy(ctx.ACU_HOUR)
- # Calculate the upcoming weekday
- sourceTime, subctx = self.parse(wkdy, sourceTime,
- VERSION_CONTEXT_STYLE)
- sTime = self.ptc.getSource(modifier, sourceTime)
- if sTime is not None:
- sourceTime = sTime
- ctx.updateAccuracy(ctx.ACU_HALFDAY)
- else:
- # unless one of these modifiers is being applied to the
- # day-of-week, we want to start with target as the day
- # in the current week.
- dowOffset = offset
- relativeModifier = modifier not in ['this', 'next', 'last', 'prior', 'previous']
- if relativeModifier:
- dowOffset = 0
-
- wkdy = self.ptc.WeekdayOffsets[wkdy]
- diff = self._CalculateDOWDelta(
- wd, wkdy, dowOffset, self.ptc.DOWParseStyle,
- self.ptc.CurrentDOWParseStyle)
- start = datetime.datetime(yr, mth, dy, startHour,
- startMinute, startSecond)
- target = start + datetime.timedelta(days=diff)
-
- if chunk1 != '' and relativeModifier:
- # consider "one day before thursday": we need to parse chunk1 ("one day")
- # and apply according to the offset ("before"), rather than allowing the
- # remaining parse step to apply "one day" without the offset direction.
- t, subctx = self.parse(chunk1, sourceTime, VERSION_CONTEXT_STYLE)
- if subctx.hasDateOrTime:
- delta = time.mktime(t) - time.mktime(sourceTime)
- target = start + datetime.timedelta(days=diff) + datetime.timedelta(seconds=delta * offset)
- chunk1 = ''
-
- sourceTime = target.timetuple()
- ctx.updateAccuracy(ctx.ACU_DAY)
-
- elif chunk1 == '' and chunk2 == '' and self.ptc.CRE_TIME.match(unit):
- m = self.ptc.CRE_TIME.match(unit)
- debug and log.debug('CRE_TIME matched')
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst), subctx = \
- self.parse(unit, None, VERSION_CONTEXT_STYLE)
-
- start = datetime.datetime(yr, mth, dy, hr, mn, sec)
- target = start + datetime.timedelta(days=offset)
- sourceTime = target.timetuple()
-
- else:
- # check if the remaining text is parsable and if so,
- # use it as the base time for the modifier source time
-
- debug and log.debug('check for modifications '
- 'to source time [%s] [%s]',
- chunk1, unit)
-
- unit = unit.strip()
- if unit:
- s = '%s %s' % (unit, chunk2)
- t, subctx = self.parse(s, sourceTime, VERSION_CONTEXT_STYLE)
-
- if subctx.hasDate: # working with dates
- u = unit.lower()
- if u in self.ptc.Months or \
- u in self.ptc.shortMonths:
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = t
- start = datetime.datetime(
- yr, mth, dy, hr, mn, sec)
- t = self.inc(start, year=offset).timetuple()
- elif u in self.ptc.Weekdays:
- t = t + datetime.timedelta(weeks=offset)
-
- if subctx.hasDateOrTime:
- sourceTime = t
- chunk2 = ''
-
- chunk1 = chunk1.strip()
-
- # if the word after next is a number, the string is more than
- # likely to be "next 4 hrs" which we will have to combine the
- # units with the rest of the string
- if chunk1:
- try:
- m = list(self.ptc.CRE_NUMBER.finditer(chunk1))[-1]
- except IndexError:
- pass
- else:
- qty = None
- debug and log.debug('CRE_NUMBER matched')
- qty = self._quantityToReal(m.group()) * offset
- chunk1 = '%s%s%s' % (chunk1[:m.start()],
- qty, chunk1[m.end():])
- t, subctx = self.parse(chunk1, sourceTime,
- VERSION_CONTEXT_STYLE)
-
- chunk1 = ''
-
- if subctx.hasDateOrTime:
- sourceTime = t
-
- debug and log.debug('looking for modifier %s', modifier)
- sTime = self.ptc.getSource(modifier, sourceTime)
- if sTime is not None:
- debug and log.debug('modifier found in sources')
- sourceTime = sTime
- ctx.updateAccuracy(ctx.ACU_HALFDAY)
-
- debug and log.debug('returning chunk = "%s %s" and sourceTime = %s',
- chunk1, chunk2, sourceTime)
-
- return '%s %s' % (chunk1, chunk2), sourceTime
-
- def _evalDT(self, datetimeString, sourceTime):
- """
- Calculate the datetime from known format like RFC822 or W3CDTF
-
- Examples handled::
- RFC822, W3CDTF formatted dates
- HH:MM[:SS][ am/pm]
- MM/DD/YYYY
- DD MMMM YYYY
-
- @type datetimeString: string
- @param datetimeString: text to try and parse as more "traditional"
- date/time text
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: datetime
- @return: calculated C{struct_time} value or current C{struct_time}
- if not parsed
- """
- ctx = self.currentContext
- s = datetimeString.strip()
-
- # Given string date is a RFC822 date
- if sourceTime is None:
- sourceTime = _parse_date_rfc822(s)
- debug and log.debug(
- 'attempt to parse as rfc822 - %s', str(sourceTime))
-
- if sourceTime is not None:
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst, _) = sourceTime
- ctx.updateAccuracy(ctx.ACU_YEAR, ctx.ACU_MONTH, ctx.ACU_DAY)
-
- if hr != 0 and mn != 0 and sec != 0:
- ctx.updateAccuracy(ctx.ACU_HOUR, ctx.ACU_MIN, ctx.ACU_SEC)
-
- sourceTime = (yr, mth, dy, hr, mn, sec, wd, yd, isdst)
-
- # Given string date is a W3CDTF date
- if sourceTime is None:
- sourceTime = _parse_date_w3dtf(s)
-
- if sourceTime is not None:
- ctx.updateAccuracy(ctx.ACU_YEAR, ctx.ACU_MONTH, ctx.ACU_DAY,
- ctx.ACU_HOUR, ctx.ACU_MIN, ctx.ACU_SEC)
-
- if sourceTime is None:
- sourceTime = time.localtime()
-
- return sourceTime
-
- def _evalUnits(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseUnits()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is a time string with units like "5 hrs 30 min"
- modifier = '' # TODO
-
- m = self.ptc.CRE_UNITS.search(s)
- if m is not None:
- units = m.group('units')
- quantity = s[:m.start('units')]
-
- sourceTime = self._buildTime(sourceTime, quantity, modifier, units)
- return sourceTime
-
- def _evalQUnits(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseQUnits()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is a time string with single char units like "5 h 30 m"
- modifier = '' # TODO
-
- m = self.ptc.CRE_QUNITS.search(s)
- if m is not None:
- units = m.group('qunits')
- quantity = s[:m.start('qunits')]
-
- sourceTime = self._buildTime(sourceTime, quantity, modifier, units)
- return sourceTime
-
- def _evalDateStr(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseDateStr()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is in the format "May 23rd, 2005"
- debug and log.debug('checking for MMM DD YYYY')
- return self.parseDateText(s, sourceTime)
-
- def _evalDateStd(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseDateStd()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is in the format 07/21/2006
- return self.parseDate(s, sourceTime)
-
- def _evalDayStr(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseDaystr()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is a natural language date string like today, tomorrow..
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst) = sourceTime
-
- try:
- offset = self.ptc.dayOffsets[s]
- except KeyError:
- offset = 0
-
- if self.ptc.StartTimeFromSourceTime:
- startHour = hr
- startMinute = mn
- startSecond = sec
- else:
- startHour = 9
- startMinute = 0
- startSecond = 0
-
- self.currentContext.updateAccuracy(pdtContext.ACU_DAY)
- start = datetime.datetime(yr, mth, dy, startHour,
- startMinute, startSecond)
- target = start + datetime.timedelta(days=offset)
- return target.timetuple()
-
- def _evalWeekday(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseWeekday()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is a weekday
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = sourceTime
-
- start = datetime.datetime(yr, mth, dy, hr, mn, sec)
- wkdy = self.ptc.WeekdayOffsets[s]
-
- if wkdy > wd:
- qty = self._CalculateDOWDelta(wd, wkdy, 2,
- self.ptc.DOWParseStyle,
- self.ptc.CurrentDOWParseStyle)
- else:
- qty = self._CalculateDOWDelta(wd, wkdy, 2,
- self.ptc.DOWParseStyle,
- self.ptc.CurrentDOWParseStyle)
-
- self.currentContext.updateAccuracy(pdtContext.ACU_DAY)
- target = start + datetime.timedelta(days=qty)
- return target.timetuple()
-
- def _evalTimeStr(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseTimeStr()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- if s in self.ptc.re_values['now']:
- self.currentContext.updateAccuracy(pdtContext.ACU_NOW)
- else:
- # Given string is a natural language time string like
- # lunch, midnight, etc
- sTime = self.ptc.getSource(s, sourceTime)
- if sTime:
- sourceTime = sTime
- self.currentContext.updateAccuracy(pdtContext.ACU_HALFDAY)
-
- return sourceTime
-
- def _evalMeridian(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseMeridian()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is in the format HH:MM(:SS)(am/pm)
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = sourceTime
-
- m = self.ptc.CRE_TIMEHMS2.search(s)
- if m is not None:
- dt = s[:m.start('meridian')].strip()
- if len(dt) <= 2:
- hr = int(dt)
- mn = 0
- sec = 0
- else:
- hr, mn, sec = _extract_time(m)
-
- if hr == 24:
- hr = 0
-
- meridian = m.group('meridian').lower()
-
- # if 'am' found and hour is 12 - force hour to 0 (midnight)
- if (meridian in self.ptc.am) and hr == 12:
- hr = 0
-
- # if 'pm' found and hour < 12, add 12 to shift to evening
- if (meridian in self.ptc.pm) and hr < 12:
- hr += 12
-
- # time validation
- if hr < 24 and mn < 60 and sec < 60:
- sourceTime = (yr, mth, dy, hr, mn, sec, wd, yd, isdst)
- _pop_time_accuracy(m, self.currentContext)
-
- return sourceTime
-
- def _evalTimeStd(self, datetimeString, sourceTime):
- """
- Evaluate text passed by L{_partialParseTimeStd()}
- """
- s = datetimeString.strip()
- sourceTime = self._evalDT(datetimeString, sourceTime)
-
- # Given string is in the format HH:MM(:SS)
- yr, mth, dy, hr, mn, sec, wd, yd, isdst = sourceTime
-
- m = self.ptc.CRE_TIMEHMS.search(s)
- if m is not None:
- hr, mn, sec = _extract_time(m)
- if hr == 24:
- hr = 0
-
- # time validation
- if hr < 24 and mn < 60 and sec < 60:
- sourceTime = (yr, mth, dy, hr, mn, sec, wd, yd, isdst)
- _pop_time_accuracy(m, self.currentContext)
-
- return sourceTime
-
- def _UnitsTrapped(self, s, m, key):
- # check if a day suffix got trapped by a unit match
- # for example Dec 31st would match for 31s (aka 31 seconds)
- # Dec 31st
- # ^ ^
- # | +-- m.start('units')
- # | and also m2.start('suffix')
- # +---- m.start('qty')
- # and also m2.start('day')
- m2 = self.ptc.CRE_DAY2.search(s)
- if m2 is not None:
- t = '%s%s' % (m2.group('day'), m.group(key))
- if m.start(key) == m2.start('suffix') and \
- m.start('qty') == m2.start('day') and \
- m.group('qty') == t:
- return True
- else:
- return False
- else:
- return False
-
- def _partialParseModifier(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_MODIFIER, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # Modifier like next/prev/from/after/prior..
- m = self.ptc.CRE_MODIFIER.search(s)
- if m is not None:
- if m.group() != s:
- # capture remaining string
- parseStr = m.group()
- chunk1 = s[:m.start()].strip()
- chunk2 = s[m.end():].strip()
- else:
- parseStr = s
-
- if parseStr:
- debug and log.debug('found (modifier) [%s][%s][%s]',
- parseStr, chunk1, chunk2)
- s, sourceTime = self._evalModifier(parseStr, chunk1,
- chunk2, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseUnits(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_UNITS, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # Quantity + Units
- m = self.ptc.CRE_UNITS.search(s)
- if m is not None:
- debug and log.debug('CRE_UNITS matched')
- if self._UnitsTrapped(s, m, 'units'):
- debug and log.debug('day suffix trapped by unit match')
- else:
- if (m.group('qty') != s):
- # capture remaining string
- parseStr = m.group('qty')
- chunk1 = s[:m.start('qty')].strip()
- chunk2 = s[m.end('qty'):].strip()
-
- if chunk1[-1:] == '-':
- parseStr = '-%s' % parseStr
- chunk1 = chunk1[:-1]
-
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr:
- debug and log.debug('found (units) [%s][%s][%s]',
- parseStr, chunk1, chunk2)
- sourceTime = self._evalUnits(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseQUnits(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_QUNITS, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # Quantity + Units
- m = self.ptc.CRE_QUNITS.search(s)
- if m is not None:
- debug and log.debug('CRE_QUNITS matched')
- if self._UnitsTrapped(s, m, 'qunits'):
- debug and log.debug(
- 'day suffix trapped by qunit match')
- else:
- if (m.group('qty') != s):
- # capture remaining string
- parseStr = m.group('qty')
- chunk1 = s[:m.start('qty')].strip()
- chunk2 = s[m.end('qty'):].strip()
-
- if chunk1[-1:] == '-':
- parseStr = '-%s' % parseStr
- chunk1 = chunk1[:-1]
-
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr:
- debug and log.debug('found (qunits) [%s][%s][%s]',
- parseStr, chunk1, chunk2)
- sourceTime = self._evalQUnits(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseDateStr(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_DATE3, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- m = self.ptc.CRE_DATE3.search(s)
- # NO LONGER NEEDED, THE REGEXP HANDLED MTHNAME NOW
- # for match in self.ptc.CRE_DATE3.finditer(s):
- # to prevent "HH:MM(:SS) time strings" expressions from
- # triggering this regex, we checks if the month field
- # exists in the searched expression, if it doesn't exist,
- # the date field is not valid
- # if match.group('mthname'):
- # m = self.ptc.CRE_DATE3.search(s, match.start())
- # valid_date = True
- # break
-
- # String date format
- if m is not None:
-
- if (m.group('date') != s):
- # capture remaining string
- mStart = m.start('date')
- mEnd = m.end('date')
-
- # we need to check that anything following the parsed
- # date is a time expression because it is often picked
- # up as a valid year if the hour is 2 digits
- fTime = False
- mm = self.ptc.CRE_TIMEHMS2.search(s)
- # "February 24th 1PM" doesn't get caught
- # "February 24th 12PM" does
- mYear = m.group('year')
- if mm is not None and mYear is not None:
- fTime = True
- else:
- # "February 24th 12:00"
- mm = self.ptc.CRE_TIMEHMS.search(s)
- if mm is not None and mYear is None:
- fTime = True
- if fTime:
- hoursStart = mm.start('hours')
-
- if hoursStart < m.end('year'):
- mEnd = hoursStart
-
- parseStr = s[mStart:mEnd]
- chunk1 = s[:mStart]
- chunk2 = s[mEnd:]
-
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr:
- debug and log.debug(
- 'found (date3) [%s][%s][%s]', parseStr, chunk1, chunk2)
- sourceTime = self._evalDateStr(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseDateStd(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_DATE, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # Standard date format
- m = self.ptc.CRE_DATE.search(s)
- if m is not None:
-
- if (m.group('date') != s):
- # capture remaining string
- parseStr = m.group('date')
- chunk1 = s[:m.start('date')]
- chunk2 = s[m.end('date'):]
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr:
- debug and log.debug(
- 'found (date) [%s][%s][%s]', parseStr, chunk1, chunk2)
- sourceTime = self._evalDateStd(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseDayStr(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_DAY, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # Natural language day strings
- m = self.ptc.CRE_DAY.search(s)
- if m is not None:
-
- if (m.group() != s):
- # capture remaining string
- parseStr = m.group()
- chunk1 = s[:m.start()]
- chunk2 = s[m.end():]
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr:
- debug and log.debug(
- 'found (day) [%s][%s][%s]', parseStr, chunk1, chunk2)
- sourceTime = self._evalDayStr(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseWeekday(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_WEEKDAY, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- ctx = self.currentContext
- log.debug('eval %s with context - %s, %s', s, ctx.hasDate, ctx.hasTime)
-
- # Weekday
- m = self.ptc.CRE_WEEKDAY.search(s)
- if m is not None:
- gv = m.group()
- if s not in self.ptc.dayOffsets:
-
- if (gv != s):
- # capture remaining string
- parseStr = gv
- chunk1 = s[:m.start()]
- chunk2 = s[m.end():]
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr and not ctx.hasDate:
- debug and log.debug(
- 'found (weekday) [%s][%s][%s]', parseStr, chunk1, chunk2)
- sourceTime = self._evalWeekday(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseTimeStr(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_TIME, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # Natural language time strings
- m = self.ptc.CRE_TIME.search(s)
- if m is not None or s in self.ptc.re_values['now']:
-
- if (m and m.group() != s):
- # capture remaining string
- parseStr = m.group()
- chunk1 = s[:m.start()]
- chunk2 = s[m.end():]
- s = '%s %s' % (chunk1, chunk2)
- else:
- parseStr = s
- s = ''
-
- if parseStr:
- debug and log.debug(
- 'found (time) [%s][%s][%s]', parseStr, chunk1, chunk2)
- sourceTime = self._evalTimeStr(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseMeridian(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_TIMEHMS2, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # HH:MM(:SS) am/pm time strings
- m = self.ptc.CRE_TIMEHMS2.search(s)
- if m is not None:
-
- if m.group('minutes') is not None:
- if m.group('seconds') is not None:
- parseStr = '%s:%s:%s' % (m.group('hours'),
- m.group('minutes'),
- m.group('seconds'))
- else:
- parseStr = '%s:%s' % (m.group('hours'),
- m.group('minutes'))
- else:
- parseStr = m.group('hours')
- parseStr += ' ' + m.group('meridian')
-
- chunk1 = s[:m.start()]
- chunk2 = s[m.end():]
-
- s = '%s %s' % (chunk1, chunk2)
-
- if parseStr:
- debug and log.debug('found (meridian) [%s][%s][%s]',
- parseStr, chunk1, chunk2)
- sourceTime = self._evalMeridian(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def _partialParseTimeStd(self, s, sourceTime):
- """
- test if giving C{s} matched CRE_TIMEHMS, used by L{parse()}
-
- @type s: string
- @param s: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
-
- @rtype: tuple
- @return: tuple of remained date/time text, datetime object and
- an boolean value to describ if matched or not
-
- """
- parseStr = None
- chunk1 = chunk2 = ''
-
- # HH:MM(:SS) time strings
- m = self.ptc.CRE_TIMEHMS.search(s)
- if m is not None:
-
- if m.group('seconds') is not None:
- parseStr = '%s:%s:%s' % (m.group('hours'),
- m.group('minutes'),
- m.group('seconds'))
- chunk1 = s[:m.start('hours')]
- chunk2 = s[m.end('seconds'):]
- else:
- parseStr = '%s:%s' % (m.group('hours'),
- m.group('minutes'))
- chunk1 = s[:m.start('hours')]
- chunk2 = s[m.end('minutes'):]
-
- s = '%s %s' % (chunk1, chunk2)
-
- if parseStr:
- debug and log.debug(
- 'found (hms) [%s][%s][%s]', parseStr, chunk1, chunk2)
- sourceTime = self._evalTimeStd(parseStr, sourceTime)
-
- return s, sourceTime, bool(parseStr)
-
- def parseDT(self, datetimeString, sourceTime=None,
- tzinfo=None, version=None):
- """
- C{datetimeString} is as C{.parse}, C{sourceTime} has the same semantic
- meaning as C{.parse}, but now also accepts datetime objects. C{tzinfo}
- accepts a tzinfo object. It is advisable to use pytz.
-
-
- @type datetimeString: string
- @param datetimeString: date/time text to evaluate
- @type sourceTime: struct_time, datetime, date, time
- @param sourceTime: time value to use as the base
- @type tzinfo: tzinfo
- @param tzinfo: Timezone to apply to generated datetime objs.
- @type version: integer
- @param version: style version, default will use L{Calendar}
- parameter version value
-
- @rtype: tuple
- @return: tuple of: modified C{sourceTime} and the result flag/context
-
- see .parse for return code details.
- """
- # if sourceTime has a timetuple method, use thet, else, just pass the
- # entire thing to parse and prey the user knows what the hell they are
- # doing.
- sourceTime = getattr(sourceTime, 'timetuple', (lambda: sourceTime))()
- # You REALLY SHOULD be using pytz. Using localize if available,
- # hacking if not. Note, None is a valid tzinfo object in the case of
- # the ugly hack.
- localize = getattr(
- tzinfo,
- 'localize',
- (lambda dt: dt.replace(tzinfo=tzinfo)), # ugly hack is ugly :(
- )
-
- # Punt
- time_struct, ret_code = self.parse(
- datetimeString,
- sourceTime=sourceTime,
- version=version)
-
- # Comments from GHI indicate that it is desired to have the same return
- # signature on this method as that one it punts to, with the exception
- # of using datetime objects instead of time_structs.
- dt = localize(datetime.datetime(*time_struct[:6]))
- return dt, ret_code
-
- def parse(self, datetimeString, sourceTime=None, version=None):
- """
- Splits the given C{datetimeString} into tokens, finds the regex
- patterns that match and then calculates a C{struct_time} value from
- the chunks.
-
- If C{sourceTime} is given then the C{struct_time} value will be
- calculated from that value, otherwise from the current date/time.
-
- If the C{datetimeString} is parsed and date/time value found, then::
-
- If C{version} equals to L{VERSION_FLAG_STYLE}, the second item of
- the returned tuple will be a flag to let you know what kind of
- C{struct_time} value is being returned::
-
- 0 = not parsed at all
- 1 = parsed as a C{date}
- 2 = parsed as a C{time}
- 3 = parsed as a C{datetime}
-
- If C{version} equals to L{VERSION_CONTEXT_STYLE}, the second value
- will be an instance of L{pdtContext}
-
- @type datetimeString: string
- @param datetimeString: date/time text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
- @type version: integer
- @param version: style version, default will use L{Calendar}
- parameter version value
-
- @rtype: tuple
- @return: tuple of: modified C{sourceTime} and the result flag/context
- """
- debug and log.debug('parse()')
-
- datetimeString = re.sub(r'(\w)\.(\s)', r'\1\2', datetimeString)
- datetimeString = re.sub(r'(\w)[\'"](\s|$)', r'\1 \2', datetimeString)
- datetimeString = re.sub(r'(\s|^)[\'"](\w)', r'\1 \2', datetimeString)
-
- if sourceTime:
- if isinstance(sourceTime, datetime.datetime):
- debug and log.debug('coercing datetime to timetuple')
- sourceTime = sourceTime.timetuple()
- else:
- if not isinstance(sourceTime, time.struct_time) and \
- not isinstance(sourceTime, tuple):
- raise ValueError('sourceTime is not a struct_time')
- else:
- sourceTime = time.localtime()
-
- with self.context() as ctx:
- s = datetimeString.lower().strip()
- debug and log.debug('remainedString (before parsing): [%s]', s)
-
- while s:
- for parseMeth in (self._partialParseModifier,
- self._partialParseUnits,
- self._partialParseQUnits,
- self._partialParseDateStr,
- self._partialParseDateStd,
- self._partialParseDayStr,
- self._partialParseWeekday,
- self._partialParseTimeStr,
- self._partialParseMeridian,
- self._partialParseTimeStd):
- retS, retTime, matched = parseMeth(s, sourceTime)
- if matched:
- s, sourceTime = retS.strip(), retTime
- break
- else:
- # nothing matched
- s = ''
-
- debug and log.debug('hasDate: [%s], hasTime: [%s]',
- ctx.hasDate, ctx.hasTime)
- debug and log.debug('remainedString: [%s]', s)
-
- # String is not parsed at all
- if sourceTime is None:
- debug and log.debug('not parsed [%s]', str(sourceTime))
- sourceTime = time.localtime()
-
- if not isinstance(sourceTime, time.struct_time):
- sourceTime = time.struct_time(sourceTime)
-
- version = self.version if version is None else version
- if version == VERSION_CONTEXT_STYLE:
- return sourceTime, ctx
- else:
- return sourceTime, ctx.dateTimeFlag
-
- def inc(self, source, month=None, year=None):
- """
- Takes the given C{source} date, or current date if none is
- passed, and increments it according to the values passed in
- by month and/or year.
-
- This routine is needed because Python's C{timedelta()} function
- does not allow for month or year increments.
-
- @type source: struct_time
- @param source: C{struct_time} value to increment
- @type month: float or integer
- @param month: optional number of months to increment
- @type year: float or integer
- @param year: optional number of years to increment
-
- @rtype: datetime
- @return: C{source} incremented by the number of months and/or years
- """
- yr = source.year
- mth = source.month
- dy = source.day
-
- try:
- month = float(month)
- except (TypeError, ValueError):
- month = 0
-
- try:
- year = float(year)
- except (TypeError, ValueError):
- year = 0
- finally:
- month += year * 12
- year = 0
-
- subMi = 0.0
- maxDay = 0
- if month:
- mi = int(month)
- subMi = month - mi
-
- y = int(mi / 12.0)
- m = mi - y * 12
-
- mth = mth + m
- if mth < 1: # cross start-of-year?
- y -= 1 # yes - decrement year
- mth += 12 # and fix month
- elif mth > 12: # cross end-of-year?
- y += 1 # yes - increment year
- mth -= 12 # and fix month
-
- yr += y
-
- # if the day ends up past the last day of
- # the new month, set it to the last day
- maxDay = self.ptc.daysInMonth(mth, yr)
- if dy > maxDay:
- dy = maxDay
-
- if yr > datetime.MAXYEAR or yr < datetime.MINYEAR:
- raise OverflowError('year is out of range')
-
- d = source.replace(year=yr, month=mth, day=dy)
- if subMi:
- d += datetime.timedelta(days=subMi * maxDay)
- return source + (d - source)
-
- def nlp(self, inputString, sourceTime=None, version=None):
- """Utilizes parse() after making judgements about what datetime
- information belongs together.
-
- It makes logical groupings based on proximity and returns a parsed
- datetime for each matched grouping of datetime text, along with
- location info within the given inputString.
-
- @type inputString: string
- @param inputString: natural language text to evaluate
- @type sourceTime: struct_time
- @param sourceTime: C{struct_time} value to use as the base
- @type version: integer
- @param version: style version, default will use L{Calendar}
- parameter version value
-
- @rtype: tuple or None
- @return: tuple of tuples in the format (parsed_datetime as
- datetime.datetime, flags as int, start_pos as int,
- end_pos as int, matched_text as string) or None if there
- were no matches
- """
-
- orig_inputstring = inputString
-
- # replace periods at the end of sentences w/ spaces
- # opposed to removing them altogether in order to
- # retain relative positions (identified by alpha, period, space).
- # this is required for some of the regex patterns to match
- inputString = re.sub(r'(\w)(\.)(\s)', r'\1 \3', inputString).lower()
- inputString = re.sub(r'(\w)(\'|")(\s|$)', r'\1 \3', inputString)
- inputString = re.sub(r'(\s|^)(\'|")(\w)', r'\1 \3', inputString)
-
- startpos = 0 # the start position in the inputString during the loop
-
- # list of lists in format:
- # [startpos, endpos, matchedstring, flags, type]
- matches = []
-
- while startpos < len(inputString):
-
- # empty match
- leftmost_match = [0, 0, None, 0, None]
-
- # Modifier like next\prev..
- m = self.ptc.CRE_MODIFIER.search(inputString[startpos:])
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start() + startpos:
- leftmost_match[0] = m.start() + startpos
- leftmost_match[1] = m.end() + startpos
- leftmost_match[2] = m.group()
- leftmost_match[3] = 0
- leftmost_match[4] = 'modifier'
-
- # Quantity + Units
- m = self.ptc.CRE_UNITS.search(inputString[startpos:])
- if m is not None:
- debug and log.debug('CRE_UNITS matched')
- if self._UnitsTrapped(inputString[startpos:], m, 'units'):
- debug and log.debug('day suffix trapped by unit match')
- else:
-
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start('qty') + startpos:
- leftmost_match[0] = m.start('qty') + startpos
- leftmost_match[1] = m.end('qty') + startpos
- leftmost_match[2] = m.group('qty')
- leftmost_match[3] = 3
- leftmost_match[4] = 'units'
-
- if m.start('qty') > 0 and \
- inputString[m.start('qty') - 1] == '-':
- leftmost_match[0] = leftmost_match[0] - 1
- leftmost_match[2] = '-' + leftmost_match[2]
-
- # Quantity + Units
- m = self.ptc.CRE_QUNITS.search(inputString[startpos:])
- if m is not None:
- debug and log.debug('CRE_QUNITS matched')
- if self._UnitsTrapped(inputString[startpos:], m, 'qunits'):
- debug and log.debug('day suffix trapped by qunit match')
- else:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start('qty') + startpos:
- leftmost_match[0] = m.start('qty') + startpos
- leftmost_match[1] = m.end('qty') + startpos
- leftmost_match[2] = m.group('qty')
- leftmost_match[3] = 3
- leftmost_match[4] = 'qunits'
-
- if m.start('qty') > 0 and \
- inputString[m.start('qty') - 1] == '-':
- leftmost_match[0] = leftmost_match[0] - 1
- leftmost_match[2] = '-' + leftmost_match[2]
-
- m = self.ptc.CRE_DATE3.search(inputString[startpos:])
- # NO LONGER NEEDED, THE REGEXP HANDLED MTHNAME NOW
- # for match in self.ptc.CRE_DATE3.finditer(inputString[startpos:]):
- # to prevent "HH:MM(:SS) time strings" expressions from
- # triggering this regex, we checks if the month field exists
- # in the searched expression, if it doesn't exist, the date
- # field is not valid
- # if match.group('mthname'):
- # m = self.ptc.CRE_DATE3.search(inputString[startpos:],
- # match.start())
- # break
-
- # String date format
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start('date') + startpos:
- leftmost_match[0] = m.start('date') + startpos
- leftmost_match[1] = m.end('date') + startpos
- leftmost_match[2] = m.group('date')
- leftmost_match[3] = 1
- leftmost_match[4] = 'dateStr'
-
- # Standard date format
- m = self.ptc.CRE_DATE.search(inputString[startpos:])
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start('date') + startpos:
- leftmost_match[0] = m.start('date') + startpos
- leftmost_match[1] = m.end('date') + startpos
- leftmost_match[2] = m.group('date')
- leftmost_match[3] = 1
- leftmost_match[4] = 'dateStd'
-
- # Natural language day strings
- m = self.ptc.CRE_DAY.search(inputString[startpos:])
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start() + startpos:
- leftmost_match[0] = m.start() + startpos
- leftmost_match[1] = m.end() + startpos
- leftmost_match[2] = m.group()
- leftmost_match[3] = 1
- leftmost_match[4] = 'dayStr'
-
- # Weekday
- m = self.ptc.CRE_WEEKDAY.search(inputString[startpos:])
- if m is not None:
- if inputString[startpos:] not in self.ptc.dayOffsets:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start() + startpos:
- leftmost_match[0] = m.start() + startpos
- leftmost_match[1] = m.end() + startpos
- leftmost_match[2] = m.group()
- leftmost_match[3] = 1
- leftmost_match[4] = 'weekdy'
-
- # Natural language time strings
- m = self.ptc.CRE_TIME.search(inputString[startpos:])
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start() + startpos:
- leftmost_match[0] = m.start() + startpos
- leftmost_match[1] = m.end() + startpos
- leftmost_match[2] = m.group()
- leftmost_match[3] = 2
- leftmost_match[4] = 'timeStr'
-
- # HH:MM(:SS) am/pm time strings
- m = self.ptc.CRE_TIMEHMS2.search(inputString[startpos:])
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start('hours') + startpos:
- leftmost_match[0] = m.start('hours') + startpos
- leftmost_match[1] = m.end('meridian') + startpos
- leftmost_match[2] = inputString[leftmost_match[0]:
- leftmost_match[1]]
- leftmost_match[3] = 2
- leftmost_match[4] = 'meridian'
-
- # HH:MM(:SS) time strings
- m = self.ptc.CRE_TIMEHMS.search(inputString[startpos:])
- if m is not None:
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start('hours') + startpos:
- leftmost_match[0] = m.start('hours') + startpos
- if m.group('seconds') is not None:
- leftmost_match[1] = m.end('seconds') + startpos
- else:
- leftmost_match[1] = m.end('minutes') + startpos
- leftmost_match[2] = inputString[leftmost_match[0]:
- leftmost_match[1]]
- leftmost_match[3] = 2
- leftmost_match[4] = 'timeStd'
-
- # Units only; must be preceded by a modifier
- if len(matches) > 0 and matches[-1][3] == 0:
- m = self.ptc.CRE_UNITS_ONLY.search(inputString[startpos:])
- # Ensure that any match is immediately proceded by the
- # modifier. "Next is the word 'month'" should not parse as a
- # date while "next month" should
- if m is not None and \
- inputString[startpos:startpos +
- m.start()].strip() == '':
- debug and log.debug('CRE_UNITS_ONLY matched [%s]',
- m.group())
- if leftmost_match[1] == 0 or \
- leftmost_match[0] > m.start() + startpos:
- leftmost_match[0] = m.start() + startpos
- leftmost_match[1] = m.end() + startpos
- leftmost_match[2] = m.group()
- leftmost_match[3] = 3
- leftmost_match[4] = 'unitsOnly'
-
- # set the start position to the end pos of the leftmost match
- startpos = leftmost_match[1]
-
- # nothing was detected
- # so break out of the loop
- if startpos == 0:
- startpos = len(inputString)
- else:
- if leftmost_match[3] > 0:
- m = self.ptc.CRE_NLP_PREFIX.search(
- inputString[:leftmost_match[0]] +
- ' ' + str(leftmost_match[3]))
- if m is not None:
- leftmost_match[0] = m.start('nlp_prefix')
- leftmost_match[2] = inputString[leftmost_match[0]:
- leftmost_match[1]]
- matches.append(leftmost_match)
-
- # find matches in proximity with one another and
- # return all the parsed values
- proximity_matches = []
- if len(matches) > 1:
- combined = ''
- from_match_index = 0
- date = matches[0][3] == 1
- time = matches[0][3] == 2
- units = matches[0][3] == 3
- for i in range(1, len(matches)):
-
- # test proximity (are there characters between matches?)
- endofprevious = matches[i - 1][1]
- begofcurrent = matches[i][0]
- if orig_inputstring[endofprevious:
- begofcurrent].lower().strip() != '':
- # this one isn't in proximity, but maybe
- # we have enough to make a datetime
- # TODO: make sure the combination of
- # formats (modifier, dateStd, etc) makes logical sense
- # before parsing together
- if date or time or units:
- combined = orig_inputstring[matches[from_match_index]
- [0]:matches[i - 1][1]]
- parsed_datetime, flags = self.parse(combined,
- sourceTime,
- version)
- proximity_matches.append((
- datetime.datetime(*parsed_datetime[:6]),
- flags,
- matches[from_match_index][0],
- matches[i - 1][1],
- combined))
- # not in proximity, reset starting from current
- from_match_index = i
- date = matches[i][3] == 1
- time = matches[i][3] == 2
- units = matches[i][3] == 3
- continue
- else:
- if matches[i][3] == 1:
- date = True
- if matches[i][3] == 2:
- time = True
- if matches[i][3] == 3:
- units = True
-
- # check last
- # we have enough to make a datetime
- if date or time or units:
- combined = orig_inputstring[matches[from_match_index][0]:
- matches[len(matches) - 1][1]]
- parsed_datetime, flags = self.parse(combined, sourceTime,
- version)
- proximity_matches.append((
- datetime.datetime(*parsed_datetime[:6]),
- flags,
- matches[from_match_index][0],
- matches[len(matches) - 1][1],
- combined))
-
- elif len(matches) == 0:
- return None
- else:
- if matches[0][3] == 0: # not enough info to parse
- return None
- else:
- combined = orig_inputstring[matches[0][0]:matches[0][1]]
- parsed_datetime, flags = self.parse(matches[0][2], sourceTime,
- version)
- proximity_matches.append((
- datetime.datetime(*parsed_datetime[:6]),
- flags,
- matches[0][0],
- matches[0][1],
- combined))
-
- return tuple(proximity_matches)
-
-
-def _initSymbols(ptc):
- """
- Initialize symbols and single character constants.
- """
- # build am and pm lists to contain
- # original case, lowercase, first-char and dotted
- # versions of the meridian text
- ptc.am = ['', '']
- ptc.pm = ['', '']
- for idx, xm in enumerate(ptc.locale.meridian[:2]):
- # 0: am
- # 1: pm
- target = ['am', 'pm'][idx]
- setattr(ptc, target, [xm])
- target = getattr(ptc, target)
- if xm:
- lxm = xm.lower()
- target.extend((xm[0], '{0}.{1}.'.format(*xm),
- lxm, lxm[0], '{0}.{1}.'.format(*lxm)))
-
-
-class Constants(object):
-
- """
- Default set of constants for parsedatetime.
-
- If PyICU is present, then the class will first try to get PyICU
- to return a locale specified by C{localeID}. If either C{localeID} is
- None or if the locale does not exist within PyICU, then each of the
- locales defined in C{fallbackLocales} is tried in order.
-
- If PyICU is not present or none of the specified locales can be used,
- then the class will initialize itself to the en_US locale.
-
- if PyICU is not present or not requested, only the locales defined by
- C{pdtLocales} will be searched.
- """
-
- def __init__(self, localeID=None, usePyICU=True,
- fallbackLocales=['en_US']):
- self.localeID = localeID
- self.fallbackLocales = fallbackLocales[:]
-
- if 'en_US' not in self.fallbackLocales:
- self.fallbackLocales.append('en_US')
-
- # define non-locale specific constants
- self.locale = None
- self.usePyICU = usePyICU
-
- # starting cache of leap years
- # daysInMonth will add to this if during
- # runtime it gets a request for a year not found
- self._leapYears = list(range(1904, 2097, 4))
-
- self.Second = 1
- self.Minute = 60 # 60 * self.Second
- self.Hour = 3600 # 60 * self.Minute
- self.Day = 86400 # 24 * self.Hour
- self.Week = 604800 # 7 * self.Day
- self.Month = 2592000 # 30 * self.Day
- self.Year = 31536000 # 365 * self.Day
-
- self._DaysInMonthList = (31, 28, 31, 30, 31, 30,
- 31, 31, 30, 31, 30, 31)
- self.rangeSep = '-'
- self.BirthdayEpoch = 50
-
- # When True the starting time for all relative calculations will come
- # from the given SourceTime, otherwise it will be 9am
-
- self.StartTimeFromSourceTime = False
-
- # YearParseStyle controls how we parse "Jun 12", i.e. dates that do
- # not have a year present. The default is to compare the date given
- # to the current date, and if prior, then assume the next year.
- # Setting this to 0 will prevent that.
-
- self.YearParseStyle = 1
-
- # DOWParseStyle controls how we parse "Tuesday"
- # If the current day was Thursday and the text to parse is "Tuesday"
- # then the following table shows how each style would be returned
- # -1, 0, +1
- #
- # Current day marked as ***
- #
- # Sun Mon Tue Wed Thu Fri Sat
- # week -1
- # current -1,0 ***
- # week +1 +1
- #
- # If the current day was Monday and the text to parse is "Tuesday"
- # then the following table shows how each style would be returned
- # -1, 0, +1
- #
- # Sun Mon Tue Wed Thu Fri Sat
- # week -1 -1
- # current *** 0,+1
- # week +1
-
- self.DOWParseStyle = 1
-
- # CurrentDOWParseStyle controls how we parse "Friday"
- # If the current day was Friday and the text to parse is "Friday"
- # then the following table shows how each style would be returned
- # True/False. This also depends on DOWParseStyle.
- #
- # Current day marked as ***
- #
- # DOWParseStyle = 0
- # Sun Mon Tue Wed Thu Fri Sat
- # week -1
- # current T,F
- # week +1
- #
- # DOWParseStyle = -1
- # Sun Mon Tue Wed Thu Fri Sat
- # week -1 F
- # current T
- # week +1
- #
- # DOWParseStyle = +1
- #
- # Sun Mon Tue Wed Thu Fri Sat
- # week -1
- # current T
- # week +1 F
-
- self.CurrentDOWParseStyle = False
-
- if self.usePyICU:
- self.locale = get_icu(self.localeID)
-
- if self.locale.icu is None:
- self.usePyICU = False
- self.locale = None
-
- if self.locale is None:
- if self.localeID not in pdtLocales:
- for localeId in range(0, len(self.fallbackLocales)):
- self.localeID = self.fallbackLocales[localeId]
- if self.localeID in pdtLocales:
- break
-
- self.locale = pdtLocales[self.localeID]
-
- if self.locale is not None:
-
- def _getLocaleDataAdjusted(localeData):
- """
- If localeData is defined as ["mon|mnd", 'tu|tues'...] then this
- function splits those definitions on |
- """
- adjusted = []
- for d in localeData:
- if '|' in d:
- adjusted += d.split("|")
- else:
- adjusted.append(d)
- return adjusted
-
- def re_join(g):
- return '|'.join(re.escape(i) for i in g)
-
- mths = _getLocaleDataAdjusted(self.locale.Months)
- smths = _getLocaleDataAdjusted(self.locale.shortMonths)
- swds = _getLocaleDataAdjusted(self.locale.shortWeekdays)
- wds = _getLocaleDataAdjusted(self.locale.Weekdays)
-
- # escape any regex special characters that may be found
- self.locale.re_values['months'] = re_join(mths)
- self.locale.re_values['shortmonths'] = re_join(smths)
- self.locale.re_values['days'] = re_join(wds)
- self.locale.re_values['shortdays'] = re_join(swds)
- self.locale.re_values['dayoffsets'] = \
- re_join(self.locale.dayOffsets)
- self.locale.re_values['numbers'] = \
- re_join(self.locale.numbers)
- self.locale.re_values['decimal_mark'] = \
- re.escape(self.locale.decimal_mark)
-
- units = [unit for units in self.locale.units.values()
- for unit in units] # flatten
- units.sort(key=len, reverse=True) # longest first
- self.locale.re_values['units'] = re_join(units)
- self.locale.re_values['modifiers'] = re_join(self.locale.Modifiers)
- self.locale.re_values['sources'] = re_join(self.locale.re_sources)
-
- # For distinguishing numeric dates from times, look for timeSep
- # and meridian, if specified in the locale
- self.locale.re_values['timecomponents'] = \
- re_join(self.locale.timeSep + self.locale.meridian)
-
- # build weekday offsets - yes, it assumes the Weekday and
- # shortWeekday lists are in the same order and Mon..Sun
- # (Python style)
- def _buildOffsets(offsetDict, localeData, indexStart):
- o = indexStart
- for key in localeData:
- if '|' in key:
- for k in key.split('|'):
- offsetDict[k] = o
- else:
- offsetDict[key] = o
- o += 1
-
- _buildOffsets(self.locale.WeekdayOffsets,
- self.locale.Weekdays, 0)
- _buildOffsets(self.locale.WeekdayOffsets,
- self.locale.shortWeekdays, 0)
-
- # build month offsets - yes, it assumes the Months and shortMonths
- # lists are in the same order and Jan..Dec
- _buildOffsets(self.locale.MonthOffsets,
- self.locale.Months, 1)
- _buildOffsets(self.locale.MonthOffsets,
- self.locale.shortMonths, 1)
-
- _initSymbols(self)
-
- # TODO: add code to parse the date formats and build the regexes up
- # from sub-parts, find all hard-coded uses of date/time separators
-
- # not being used in code, but kept in case others are manually
- # utilizing this regex for their own purposes
- self.RE_DATE4 = r'''(?P
- (
- (
- (?P\d\d?)
- (?P{daysuffix})?
- (,)?
- (\s)*
- )
- (?P
- \b({months}|{shortmonths})\b
- )\s*
- (?P\d\d
- (\d\d)?
- )?
- )
- )'''.format(**self.locale.re_values)
-
- # still not completely sure of the behavior of the regex and
- # whether it would be best to consume all possible irrelevant
- # characters before the option groups (but within the {1,3} repetition
- # group or inside of each option group, as it currently does
- # however, right now, all tests are passing that were,
- # including fixing the bug of matching a 4-digit year as ddyy
- # when the day is absent from the string
- self.RE_DATE3 = r'''(?P
- (?:
- (?:^|\s+)
- (?P
- {months}|{shortmonths}
- )\b
- |
- (?:^|\s+)
- (?P[1-9]|[012]\d|3[01])
- (?P{daysuffix}|)\b
- (?!\s*(?:{timecomponents}))
- |
- ,?\s+
- (?P\d\d(?:\d\d|))\b
- (?!\s*(?:{timecomponents}))
- ){{1,3}}
- (?(mthname)|$-^)
- )'''.format(**self.locale.re_values)
-
- # not being used in code, but kept in case others are manually
- # utilizing this regex for their own purposes
- self.RE_MONTH = r'''(\s+|^)
- (?P
- (
- (?P
- \b({months}|{shortmonths})\b
- )
- (\s*
- (?P(\d{{4}}))
- )?
- )
- )
- (?=\s+|$|[^\w])'''.format(**self.locale.re_values)
-
- self.RE_WEEKDAY = r'''\b
- (?:
- {days}|{shortdays}
- )
- \b'''.format(**self.locale.re_values)
-
- self.RE_NUMBER = (r'(\b(?:{numbers})\b|\d+(?:{decimal_mark}\d+|))'
- .format(**self.locale.re_values))
-
- self.RE_SPECIAL = (r'(?P^[{specials}]+)\s+'
- .format(**self.locale.re_values))
-
- self.RE_UNITS_ONLY = (r'''\b({units})\b'''
- .format(**self.locale.re_values))
-
- self.RE_UNITS = r'''\b(?P
- -?
- (?:\d+(?:{decimal_mark}\d+|)|(?:{numbers})\b)\s*
- (?P{units})
- )\b'''.format(**self.locale.re_values)
-
- self.RE_QUNITS = r'''\b(?P
- -?
- (?:\d+(?:{decimal_mark}\d+|)|(?:{numbers})\s+)\s*
- (?P{qunits})
- )\b'''.format(**self.locale.re_values)
-
- self.RE_MODIFIER = r'''\b(?:
- {modifiers}
- )\b'''.format(**self.locale.re_values)
-
- self.RE_TIMEHMS = r'''([\s(\["'-]|^)
- (?P\d\d?)
- (?P{timeseparator}|)
- (?P\d\d)
- (?:(?P=tsep)
- (?P\d\d
- (?:[\.,]\d+)?
- )
- )?\b'''.format(**self.locale.re_values)
-
- self.RE_TIMEHMS2 = r'''([\s(\["'-]|^)
- (?P\d\d?)
- (?:
- (?P{timeseparator}|)
- (?P\d\d?)
- (?:(?P=tsep)
- (?P\d\d?
- (?:[\.,]\d+)?
- )
- )?
- )?'''.format(**self.locale.re_values)
-
- # 1, 2, and 3 here refer to the type of match date, time, or units
- self.RE_NLP_PREFIX = r'''\b(?P
- (on)
- (\s)+1
- |
- (at|in)
- (\s)+2
- |
- (in)
- (\s)+3
- )'''
-
- if 'meridian' in self.locale.re_values:
- self.RE_TIMEHMS2 += (r'\s*(?P{meridian})\b'
- .format(**self.locale.re_values))
- else:
- self.RE_TIMEHMS2 += r'\b'
-
- # Always support common . and - separators
- dateSeps = ''.join(re.escape(s)
- for s in self.locale.dateSep + ['-', '.'])
-
- self.RE_DATE = r'''([\s(\["'-]|^)
- (?P
- \d\d?[{0}]\d\d?(?:[{0}]\d\d(?:\d\d)?)?
- |
- \d{{4}}[{0}]\d\d?[{0}]\d\d?
- )
- \b'''.format(dateSeps)
-
- self.RE_DATE2 = r'[{0}]'.format(dateSeps)
-
- assert 'dayoffsets' in self.locale.re_values
-
- self.RE_DAY = r'''\b
- (?:
- {dayoffsets}
- )
- \b'''.format(**self.locale.re_values)
-
- self.RE_DAY2 = r'''(?P\d\d?)
- (?P{daysuffix})?
- '''.format(**self.locale.re_values)
-
- self.RE_TIME = r'''\b
- (?:
- {sources}
- )
- \b'''.format(**self.locale.re_values)
-
- self.RE_REMAINING = r'\s+'
-
- # Regex for date/time ranges
- self.RE_RTIMEHMS = r'''(\s*|^)
- (\d\d?){timeseparator}
- (\d\d)
- ({timeseparator}(\d\d))?
- (\s*|$)'''.format(**self.locale.re_values)
-
- self.RE_RTIMEHMS2 = (r'''(\s*|^)
- (\d\d?)
- ({timeseparator}(\d\d?))?
- ({timeseparator}(\d\d?))?'''
- .format(**self.locale.re_values))
-
- if 'meridian' in self.locale.re_values:
- self.RE_RTIMEHMS2 += (r'\s*({meridian})'
- .format(**self.locale.re_values))
-
- self.RE_RDATE = r'(\d+([%s]\d+)+)' % dateSeps
- self.RE_RDATE3 = r'''(
- (
- (
- \b({months})\b
- )\s*
- (
- (\d\d?)
- (\s?|{daysuffix}|$)+
- )?
- (,\s*\d{{4}})?
- )
- )'''.format(**self.locale.re_values)
-
- # "06/07/06 - 08/09/06"
- self.DATERNG1 = (r'{0}\s*{rangeseparator}\s*{0}'
- .format(self.RE_RDATE, **self.locale.re_values))
-
- # "march 31 - june 1st, 2006"
- self.DATERNG2 = (r'{0}\s*{rangeseparator}\s*{0}'
- .format(self.RE_RDATE3, **self.locale.re_values))
-
- # "march 1rd -13th"
- self.DATERNG3 = (r'{0}\s*{rangeseparator}\s*(\d\d?)\s*(rd|st|nd|th)?'
- .format(self.RE_RDATE3, **self.locale.re_values))
-
- # "4:00:55 pm - 5:90:44 am", '4p-5p'
- self.TIMERNG1 = (r'{0}\s*{rangeseparator}\s*{0}'
- .format(self.RE_RTIMEHMS2, **self.locale.re_values))
-
- self.TIMERNG2 = (r'{0}\s*{rangeseparator}\s*{0}'
- .format(self.RE_RTIMEHMS, **self.locale.re_values))
-
- # "4-5pm "
- self.TIMERNG3 = (r'\d\d?\s*{rangeseparator}\s*{0}'
- .format(self.RE_RTIMEHMS2, **self.locale.re_values))
-
- # "4:30-5pm "
- self.TIMERNG4 = (r'{0}\s*{rangeseparator}\s*{1}'
- .format(self.RE_RTIMEHMS, self.RE_RTIMEHMS2,
- **self.locale.re_values))
-
- self.re_option = re.IGNORECASE + re.VERBOSE
- self.cre_source = {'CRE_SPECIAL': self.RE_SPECIAL,
- 'CRE_NUMBER': self.RE_NUMBER,
- 'CRE_UNITS': self.RE_UNITS,
- 'CRE_UNITS_ONLY': self.RE_UNITS_ONLY,
- 'CRE_QUNITS': self.RE_QUNITS,
- 'CRE_MODIFIER': self.RE_MODIFIER,
- 'CRE_TIMEHMS': self.RE_TIMEHMS,
- 'CRE_TIMEHMS2': self.RE_TIMEHMS2,
- 'CRE_DATE': self.RE_DATE,
- 'CRE_DATE2': self.RE_DATE2,
- 'CRE_DATE3': self.RE_DATE3,
- 'CRE_DATE4': self.RE_DATE4,
- 'CRE_MONTH': self.RE_MONTH,
- 'CRE_WEEKDAY': self.RE_WEEKDAY,
- 'CRE_DAY': self.RE_DAY,
- 'CRE_DAY2': self.RE_DAY2,
- 'CRE_TIME': self.RE_TIME,
- 'CRE_REMAINING': self.RE_REMAINING,
- 'CRE_RTIMEHMS': self.RE_RTIMEHMS,
- 'CRE_RTIMEHMS2': self.RE_RTIMEHMS2,
- 'CRE_RDATE': self.RE_RDATE,
- 'CRE_RDATE3': self.RE_RDATE3,
- 'CRE_TIMERNG1': self.TIMERNG1,
- 'CRE_TIMERNG2': self.TIMERNG2,
- 'CRE_TIMERNG3': self.TIMERNG3,
- 'CRE_TIMERNG4': self.TIMERNG4,
- 'CRE_DATERNG1': self.DATERNG1,
- 'CRE_DATERNG2': self.DATERNG2,
- 'CRE_DATERNG3': self.DATERNG3,
- 'CRE_NLP_PREFIX': self.RE_NLP_PREFIX}
- self.cre_keys = set(self.cre_source.keys())
-
- def __getattr__(self, name):
- if name in self.cre_keys:
- value = re.compile(self.cre_source[name], self.re_option)
- setattr(self, name, value)
- return value
- elif name in self.locale.locale_keys:
- return getattr(self.locale, name)
- else:
- raise AttributeError(name)
-
- def daysInMonth(self, month, year):
- """
- Take the given month (1-12) and a given year (4 digit) return
- the number of days in the month adjusting for leap year as needed
- """
- result = None
- debug and log.debug('daysInMonth(%s, %s)', month, year)
- if month > 0 and month <= 12:
- result = self._DaysInMonthList[month - 1]
-
- if month == 2:
- if year in self._leapYears:
- result += 1
- else:
- if calendar.isleap(year):
- self._leapYears.append(year)
- result += 1
-
- return result
-
- def getSource(self, sourceKey, sourceTime=None):
- """
- GetReturn a date/time tuple based on the giving source key
- and the corresponding key found in self.re_sources.
-
- The current time is used as the default and any specified
- item found in self.re_sources is inserted into the value
- and the generated dictionary is returned.
- """
- if sourceKey not in self.re_sources:
- return None
-
- if sourceTime is None:
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst) = time.localtime()
- else:
- (yr, mth, dy, hr, mn, sec, wd, yd, isdst) = sourceTime
-
- defaults = {'yr': yr, 'mth': mth, 'dy': dy,
- 'hr': hr, 'mn': mn, 'sec': sec}
-
- source = self.re_sources[sourceKey]
-
- values = {}
-
- for key, default in defaults.items():
- values[key] = source.get(key, default)
-
- return (values['yr'], values['mth'], values['dy'],
- values['hr'], values['mn'], values['sec'],
- wd, yd, isdst)
diff --git a/parsedatetime/context.py b/parsedatetime/context.py
deleted file mode 100755
index c1cc39a..0000000
--- a/parsedatetime/context.py
+++ /dev/null
@@ -1,187 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-parsedatetime/context.py
-
-Context related classes
-
-"""
-
-from threading import local
-
-
-class pdtContextStack(object):
- """
- A thread-safe stack to store context(s)
-
- Internally used by L{Calendar} object
- """
-
- def __init__(self):
- self.__local = local()
-
- @property
- def __stack(self):
- if not hasattr(self.__local, 'stack'):
- self.__local.stack = []
- return self.__local.stack
-
- def push(self, ctx):
- self.__stack.append(ctx)
-
- def pop(self):
- try:
- return self.__stack.pop()
- except IndexError:
- return None
-
- def last(self):
- try:
- return self.__stack[-1]
- except IndexError:
- raise RuntimeError('context stack is empty')
-
- def isEmpty(self):
- return not self.__stack
-
-
-class pdtContext(object):
- """
- Context contains accuracy flag detected by L{Calendar.parse()}
-
- Accuracy flag uses bitwise-OR operation and is combined by:
-
- ACU_YEAR - "next year", "2014"
- ACU_MONTH - "March", "July 2014"
- ACU_WEEK - "last week", "next 3 weeks"
- ACU_DAY - "tomorrow", "July 4th 2014"
- ACU_HALFDAY - "morning", "tonight"
- ACU_HOUR - "18:00", "next hour"
- ACU_MIN - "18:32", "next 10 minutes"
- ACU_SEC - "18:32:55"
- ACU_NOW - "now"
-
- """
-
- __slots__ = ('accuracy',)
-
- ACU_YEAR = 2 ** 0
- ACU_MONTH = 2 ** 1
- ACU_WEEK = 2 ** 2
- ACU_DAY = 2 ** 3
- ACU_HALFDAY = 2 ** 4
- ACU_HOUR = 2 ** 5
- ACU_MIN = 2 ** 6
- ACU_SEC = 2 ** 7
- ACU_NOW = 2 ** 8
-
- ACU_DATE = ACU_YEAR | ACU_MONTH | ACU_WEEK | ACU_DAY
- ACU_TIME = ACU_HALFDAY | ACU_HOUR | ACU_MIN | ACU_SEC | ACU_NOW
-
- _ACCURACY_MAPPING = [
- (ACU_YEAR, 'year'),
- (ACU_MONTH, 'month'),
- (ACU_WEEK, 'week'),
- (ACU_DAY, 'day'),
- (ACU_HALFDAY, 'halfday'),
- (ACU_HOUR, 'hour'),
- (ACU_MIN, 'min'),
- (ACU_SEC, 'sec'),
- (ACU_NOW, 'now')]
-
- _ACCURACY_REVERSE_MAPPING = {
- 'year': ACU_YEAR,
- 'years': ACU_YEAR,
- 'month': ACU_MONTH,
- 'months': ACU_MONTH,
- 'week': ACU_WEEK,
- 'weeks': ACU_WEEK,
- 'day': ACU_DAY,
- 'days': ACU_DAY,
- 'halfday': ACU_HALFDAY,
- 'morning': ACU_HALFDAY,
- 'afternoon': ACU_HALFDAY,
- 'evening': ACU_HALFDAY,
- 'night': ACU_HALFDAY,
- 'tonight': ACU_HALFDAY,
- 'midnight': ACU_HALFDAY,
- 'hour': ACU_HOUR,
- 'hours': ACU_HOUR,
- 'min': ACU_MIN,
- 'minute': ACU_MIN,
- 'mins': ACU_MIN,
- 'minutes': ACU_MIN,
- 'sec': ACU_SEC,
- 'second': ACU_SEC,
- 'secs': ACU_SEC,
- 'seconds': ACU_SEC,
- 'now': ACU_NOW}
-
- def __init__(self, accuracy=0):
- """
- Default constructor of L{pdtContext} class.
-
- @type accuracy: integer
- @param accuracy: Accuracy flag
-
- @rtype: object
- @return: L{pdtContext} instance
- """
- self.accuracy = accuracy
-
- def updateAccuracy(self, *accuracy):
- """
- Updates current accuracy flag
- """
- for acc in accuracy:
- if not isinstance(acc, int):
- acc = self._ACCURACY_REVERSE_MAPPING[acc]
- self.accuracy |= acc
-
- def update(self, context):
- """
- Uses another L{pdtContext} instance to update current one
- """
- self.updateAccuracy(context.accuracy)
-
- @property
- def hasDate(self):
- """
- Returns True if current context is accurate to date
- """
- return bool(self.accuracy & self.ACU_DATE)
-
- @property
- def hasTime(self):
- """
- Returns True if current context is accurate to time
- """
- return bool(self.accuracy & self.ACU_TIME)
-
- @property
- def dateTimeFlag(self):
- """
- Returns the old date/time flag code
- """
- return int(self.hasDate and 1) | int(self.hasTime and 2)
-
- @property
- def hasDateOrTime(self):
- """
- Returns True if current context is accurate to date/time
- """
- return bool(self.accuracy)
-
- def __repr__(self):
- accuracy_repr = []
- for acc, name in self._ACCURACY_MAPPING:
- if acc & self.accuracy:
- accuracy_repr.append('pdtContext.ACU_%s' % name.upper())
- if accuracy_repr:
- accuracy_repr = 'accuracy=' + ' | '.join(accuracy_repr)
- else:
- accuracy_repr = ''
-
- return 'pdtContext(%s)' % accuracy_repr
-
- def __eq__(self, ctx):
- return self.accuracy == ctx.accuracy
diff --git a/parsedatetime/parsedatetime.py b/parsedatetime/parsedatetime.py
deleted file mode 100755
index 647eb06..0000000
--- a/parsedatetime/parsedatetime.py
+++ /dev/null
@@ -1,2 +0,0 @@
-# Backward compatibility fix.
-from . import * # noqa
diff --git a/parsedatetime/pdt_locales/__init__.py b/parsedatetime/pdt_locales/__init__.py
deleted file mode 100755
index cb05718..0000000
--- a/parsedatetime/pdt_locales/__init__.py
+++ /dev/null
@@ -1,30 +0,0 @@
-# -*- encoding: utf-8 -*-
-
-"""
-pdt_locales
-
-All of the included locale classes shipped with pdt.
-"""
-
-from __future__ import absolute_import
-from .icu import get_icu
-
-locales = ['de_DE', 'en_AU', 'en_US', 'es', 'nl_NL', 'pt_BR', 'ru_RU', 'fr_FR']
-
-__locale_caches = {}
-
-__all__ = ['get_icu', 'load_locale']
-
-
-def load_locale(locale, icu=False):
- """
- Return data of locale
- :param locale:
- :return:
- """
- if locale not in locales:
- raise NotImplementedError("The locale '%s' is not supported" % locale)
- if locale not in __locale_caches:
- mod = __import__(__name__, fromlist=[locale], level=0)
- __locale_caches[locale] = getattr(mod, locale)
- return __locale_caches[locale]
diff --git a/parsedatetime/pdt_locales/base.py b/parsedatetime/pdt_locales/base.py
deleted file mode 100755
index 0191629..0000000
--- a/parsedatetime/pdt_locales/base.py
+++ /dev/null
@@ -1,199 +0,0 @@
-from __future__ import unicode_literals
-
-locale_keys = set([
- 'MonthOffsets', 'Months', 'WeekdayOffsets', 'Weekdays',
- 'dateFormats', 'dateSep', 'dayOffsets', 'dp_order',
- 'localeID', 'meridian', 'Modifiers', 're_sources', 're_values',
- 'shortMonths', 'shortWeekdays', 'timeFormats', 'timeSep', 'units',
- 'uses24', 'usesMeridian', 'numbers', 'decimal_mark', 'small',
- 'magnitude', 'ignore'])
-
-localeID = None
-
-dateSep = ['/', '.']
-timeSep = [':']
-meridian = ['AM', 'PM']
-usesMeridian = True
-uses24 = True
-WeekdayOffsets = {}
-MonthOffsets = {}
-
-# always lowercase any lookup values - helper code expects that
-Weekdays = [
- 'monday', 'tuesday', 'wednesday', 'thursday',
- 'friday', 'saturday', 'sunday',
-]
-
-shortWeekdays = [
- 'mon', 'tues|tue', 'wed', 'thu', 'fri', 'sat', 'sun',
-]
-
-Months = [
- 'january', 'february', 'march', 'april', 'may', 'june', 'july',
- 'august', 'september', 'october', 'november', 'december',
-]
-
-shortMonths = [
- 'jan', 'feb', 'mar', 'apr', 'may', 'jun',
- 'jul', 'aug', 'sep', 'oct', 'nov', 'dec',
-]
-
-# use the same formats as ICU by default
-dateFormats = {
- 'full': 'EEEE, MMMM d, yyyy',
- 'long': 'MMMM d, yyyy',
- 'medium': 'MMM d, yyyy',
- 'short': 'M/d/yy'
-}
-
-timeFormats = {
- 'full': 'h:mm:ss a z',
- 'long': 'h:mm:ss a z',
- 'medium': 'h:mm:ss a',
- 'short': 'h:mm a',
-}
-
-dp_order = ['m', 'd', 'y']
-
-# Used to parse expressions like "in 5 hours"
-numbers = {
- 'zero': 0,
- 'one': 1,
- 'a': 1,
- 'an': 1,
- 'two': 2,
- 'three': 3,
- 'four': 4,
- 'five': 5,
- 'six': 6,
- 'seven': 7,
- 'eight': 8,
- 'nine': 9,
- 'ten': 10,
- 'eleven': 11,
- 'thirteen': 13,
- 'fourteen': 14,
- 'fifteen': 15,
- 'sixteen': 16,
- 'seventeen': 17,
- 'eighteen': 18,
- 'nineteen': 19,
- 'twenty': 20,
-}
-
-decimal_mark = '.'
-
-
-# this will be added to re_values later
-units = {
- 'seconds': ['second', 'seconds', 'sec', 's'],
- 'minutes': ['minute', 'minutes', 'min', 'm'],
- 'hours': ['hour', 'hours', 'hr', 'h'],
- 'days': ['day', 'days', 'dy', 'd'],
- 'weeks': ['week', 'weeks', 'wk', 'w'],
- 'months': ['month', 'months', 'mth'],
- 'years': ['year', 'years', 'yr', 'y'],
-}
-
-
-# text constants to be used by later regular expressions
-re_values = {
- 'specials': 'in|on|of|at',
- 'timeseparator': ':',
- 'rangeseparator': '-',
- 'daysuffix': 'rd|st|nd|th',
- 'meridian': r'am|pm|a\.m\.|p\.m\.|a|p',
- 'qunits': 'h|m|s|d|w|y',
- 'now': ['now', 'right now'],
-}
-
-# Used to adjust the returned date before/after the source
-Modifiers = {
- 'from': 1,
- 'before': -1,
- 'after': 1,
- 'ago': -1,
- 'prior': -1,
- 'prev': -1,
- 'last': -1,
- 'next': 1,
- 'previous': -1,
- 'end of': 0,
- 'this': 0,
- 'eod': 1,
- 'eom': 1,
- 'eoy': 1,
-}
-
-dayOffsets = {
- 'tomorrow': 1,
- 'today': 0,
- 'yesterday': -1,
-}
-
-# special day and/or times, i.e. lunch, noon, evening
-# each element in the dictionary is a dictionary that is used
-# to fill in any value to be replace - the current date/time will
-# already have been populated by the method buildSources
-re_sources = {
- 'noon': {'hr': 12, 'mn': 0, 'sec': 0},
- 'afternoon': {'hr': 13, 'mn': 0, 'sec': 0},
- 'lunch': {'hr': 12, 'mn': 0, 'sec': 0},
- 'morning': {'hr': 6, 'mn': 0, 'sec': 0},
- 'breakfast': {'hr': 8, 'mn': 0, 'sec': 0},
- 'dinner': {'hr': 19, 'mn': 0, 'sec': 0},
- 'evening': {'hr': 18, 'mn': 0, 'sec': 0},
- 'midnight': {'hr': 0, 'mn': 0, 'sec': 0},
- 'night': {'hr': 21, 'mn': 0, 'sec': 0},
- 'tonight': {'hr': 21, 'mn': 0, 'sec': 0},
- 'eod': {'hr': 17, 'mn': 0, 'sec': 0},
-}
-
-small = {
- 'zero': 0,
- 'one': 1,
- 'a': 1,
- 'an': 1,
- 'two': 2,
- 'three': 3,
- 'four': 4,
- 'five': 5,
- 'six': 6,
- 'seven': 7,
- 'eight': 8,
- 'nine': 9,
- 'ten': 10,
- 'eleven': 11,
- 'twelve': 12,
- 'thirteen': 13,
- 'fourteen': 14,
- 'fifteen': 15,
- 'sixteen': 16,
- 'seventeen': 17,
- 'eighteen': 18,
- 'nineteen': 19,
- 'twenty': 20,
- 'thirty': 30,
- 'forty': 40,
- 'fifty': 50,
- 'sixty': 60,
- 'seventy': 70,
- 'eighty': 80,
- 'ninety': 90
-}
-
-magnitude = {
- 'thousand': 1000,
- 'million': 1000000,
- 'billion': 1000000000,
- 'trillion': 1000000000000,
- 'quadrillion': 1000000000000000,
- 'quintillion': 1000000000000000000,
- 'sextillion': 1000000000000000000000,
- 'septillion': 1000000000000000000000000,
- 'octillion': 1000000000000000000000000000,
- 'nonillion': 1000000000000000000000000000000,
- 'decillion': 1000000000000000000000000000000000,
-}
-
-ignore = ('and', ',')
diff --git a/parsedatetime/pdt_locales/de_DE.py b/parsedatetime/pdt_locales/de_DE.py
deleted file mode 100755
index afee991..0000000
--- a/parsedatetime/pdt_locales/de_DE.py
+++ /dev/null
@@ -1,118 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'de_DE'
-dateSep = ['.']
-timeSep = [':']
-meridian = []
-usesMeridian = False
-uses24 = True
-decimal_mark = ','
-
-Weekdays = [
- 'montag', 'dienstag', 'mittwoch',
- 'donnerstag', 'freitag', 'samstag', 'sonntag',
-]
-shortWeekdays = ['mo', 'di', 'mi', 'do', 'fr', 'sa', 'so']
-Months = [
- 'januar', 'februar', 'märz',
- 'april', 'mai', 'juni',
- 'juli', 'august', 'september',
- 'oktober', 'november', 'dezember',
-]
-shortMonths = [
- 'jan', 'feb', 'mrz', 'apr', 'mai', 'jun',
- 'jul', 'aug', 'sep', 'okt', 'nov', 'dez',
-]
-
-dateFormats = {
- 'full': 'EEEE, d. MMMM yyyy',
- 'long': 'd. MMMM yyyy',
- 'medium': 'dd.MM.yyyy',
- 'short': 'dd.MM.yy',
-}
-
-timeFormats = {
- 'full': 'HH:mm:ss v',
- 'long': 'HH:mm:ss z',
- 'medium': 'HH:mm:ss',
- 'short': 'HH:mm',
-}
-
-dp_order = ['d', 'm', 'y']
-
-# the short version would be a capital M,
-# as I understand it we can't distinguish
-# between m for minutes and M for months.
-units = {
- 'seconds': ['sekunden', 'sek', 's'],
- 'minutes': ['minuten', 'min', 'm'],
- 'hours': ['stunden', 'std', 'h'],
- 'days': ['tag', 'tage', 't'],
- 'weeks': ['wochen', 'w'],
- 'months': ['monat', 'monate'],
- 'years': ['jahr', 'jahre', 'j'],
-}
-
-re_values = re_values.copy()
-re_values.update({
- 'specials': 'am|dem|der|im|in|den|zum',
- 'timeseparator': ':',
- 'rangeseparator': '-',
- 'daysuffix': '',
- 'qunits': 'h|m|s|t|w|m|j',
- 'now': ['jetzt'],
-})
-
-# Used to adjust the returned date before/after the source
-# still looking for insight on how to translate all of them to german.
-Modifiers = {
- 'from': 1,
- 'before': -1,
- 'after': 1,
- 'vergangener': -1,
- 'vorheriger': -1,
- 'prev': -1,
- 'letzter': -1,
- 'nächster': 1,
- 'dieser': 0,
- 'previous': -1,
- 'in a': 2,
- 'end of': 0,
- 'eod': 0,
- 'eo': 0,
-}
-
-# morgen/abermorgen does not work, see
-# http://code.google.com/p/parsedatetime/issues/detail?id=19
-dayOffsets = {
- 'morgen': 1,
- 'heute': 0,
- 'gestern': -1,
- 'vorgestern': -2,
- 'übermorgen': 2,
-}
-
-# special day and/or times, i.e. lunch, noon, evening
-# each element in the dictionary is a dictionary that is used
-# to fill in any value to be replace - the current date/time will
-# already have been populated by the method buildSources
-re_sources = {
- 'mittag': {'hr': 12, 'mn': 0, 'sec': 0},
- 'mittags': {'hr': 12, 'mn': 0, 'sec': 0},
- 'mittagessen': {'hr': 12, 'mn': 0, 'sec': 0},
- 'morgen': {'hr': 6, 'mn': 0, 'sec': 0},
- 'morgens': {'hr': 6, 'mn': 0, 'sec': 0},
- 'frühstück': {'hr': 8, 'mn': 0, 'sec': 0},
- 'abendessen': {'hr': 19, 'mn': 0, 'sec': 0},
- 'abend': {'hr': 18, 'mn': 0, 'sec': 0},
- 'abends': {'hr': 18, 'mn': 0, 'sec': 0},
- 'mitternacht': {'hr': 0, 'mn': 0, 'sec': 0},
- 'nacht': {'hr': 21, 'mn': 0, 'sec': 0},
- 'nachts': {'hr': 21, 'mn': 0, 'sec': 0},
- 'heute abend': {'hr': 21, 'mn': 0, 'sec': 0},
- 'heute nacht': {'hr': 21, 'mn': 0, 'sec': 0},
- 'feierabend': {'hr': 17, 'mn': 0, 'sec': 0},
-}
diff --git a/parsedatetime/pdt_locales/en_AU.py b/parsedatetime/pdt_locales/en_AU.py
deleted file mode 100755
index bff3d3f..0000000
--- a/parsedatetime/pdt_locales/en_AU.py
+++ /dev/null
@@ -1,19 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'en_AU'
-dateSep = ['-', '/']
-uses24 = False
-
-dateFormats = {
- 'full': 'EEEE, d MMMM yyyy',
- 'long': 'd MMMM yyyy',
- 'medium': 'dd/MM/yyyy',
- 'short': 'd/MM/yy',
-}
-
-timeFormats['long'] = timeFormats['full']
-
-dp_order = ['d', 'm', 'y']
diff --git a/parsedatetime/pdt_locales/en_US.py b/parsedatetime/pdt_locales/en_US.py
deleted file mode 100755
index 12584e5..0000000
--- a/parsedatetime/pdt_locales/en_US.py
+++ /dev/null
@@ -1,7 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'en_US'
-uses24 = False
diff --git a/parsedatetime/pdt_locales/es.py b/parsedatetime/pdt_locales/es.py
deleted file mode 100755
index 351f254..0000000
--- a/parsedatetime/pdt_locales/es.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'es'
-dateSep = ['/']
-usesMeridian = False
-uses24 = True
-decimal_mark = ','
-
-Weekdays = [
- 'lunes', 'martes', 'miércoles',
- 'jueves', 'viernes', 'sábado', 'domingo',
-]
-shortWeekdays = [
- 'lun', 'mar', 'mié',
- 'jue', 'vie', 'sáb', 'dom',
-]
-Months = [
- 'enero', 'febrero', 'marzo',
- 'abril', 'mayo', 'junio',
- 'julio', 'agosto', 'septiembre',
- 'octubre', 'noviembre', 'diciembre',
-]
-shortMonths = [
- 'ene', 'feb', 'mar',
- 'abr', 'may', 'jun',
- 'jul', 'ago', 'sep',
- 'oct', 'nov', 'dic',
-]
-dateFormats = {
- 'full': "EEEE d' de 'MMMM' de 'yyyy",
- 'long': "d' de 'MMMM' de 'yyyy",
- 'medium': "dd-MMM-yy",
- 'short': "d/MM/yy",
-}
-
-timeFormats = {
- 'full': "HH'H'mm' 'ss z",
- 'long': "HH:mm:ss z",
- 'medium': "HH:mm:ss",
- 'short': "HH:mm",
-}
-
-dp_order = ['d', 'm', 'y']
diff --git a/parsedatetime/pdt_locales/fr_FR.py b/parsedatetime/pdt_locales/fr_FR.py
deleted file mode 100755
index 0e5d3ef..0000000
--- a/parsedatetime/pdt_locales/fr_FR.py
+++ /dev/null
@@ -1,248 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'fr_FR'
-dateSep = ['\/']
-timeSep = [':', 'h']
-meridian = ['du matin', 'du soir']
-usesMeridian = True
-uses24 = True
-WeekdayOffsets = {}
-MonthOffsets = {}
-
-# always lowercase any lookup values - helper code expects that
-Weekdays = [
- 'lundi', 'mardi', 'mercredi', 'jeudi',
- 'vendredi', 'samedi', 'dimanche',
-]
-
-shortWeekdays = [
- 'lun', 'mar', 'mer', 'jeu', 'ven', 'sam', 'dim',
-]
-
-Months = [
- 'janvier', 'février|fevrier', 'mars', 'avril', 'mai', 'juin', 'juillet',
- 'août|aout', 'septembre', 'octobre', 'novembre', 'décembre|decembre',
-]
-
-# We do not list 'mar' as a short name for 'mars' as it conflicts with
-# the 'mar' of 'mardi'
-shortMonths = [
- 'jan', 'fév|fev', 'mars', 'avr', 'mai', 'jui',
- 'juil', 'aoû|aou', 'sep', 'oct', 'nov', 'déc|dec',
-]
-
-# use the same formats as ICU by default
-dateFormats = {
- 'full': 'EEEE d MMMM yyyy',
- 'long': 'd MMMM yyyy',
- 'medium': 'd MMM yyyy',
- 'short': 'd/M/yy'
-}
-
-timeFormats = {
- 'full': 'h:mm:ss a z',
- 'long': 'h:mm:ss a z',
- 'medium': 'h:mm:ss a',
- 'short': 'h:mm a',
-}
-
-dp_order = ['d', 'm', 'y']
-
-# Used to parse expressions like "in 5 hours"
-numbers = {
- 'zéro': 0,
- 'zero': 0,
- 'un': 1,
- 'une': 1,
- 'deux': 2,
- 'trois': 3,
- 'quatre': 4,
- 'cinq': 5,
- 'six': 6,
- 'sept': 7,
- 'huit': 8,
- 'neuf': 9,
- 'dix': 10,
- 'onze': 11,
- 'douze': 12,
- 'treize': 13,
- 'quatorze': 14,
- 'quinze': 15,
- 'seize': 16,
- 'dix-sept': 17,
- 'dix sept': 17,
- 'dix-huit': 18,
- 'dix huit': 18,
- 'dix-neuf': 19,
- 'dix neuf': 19,
- 'vingt': 20,
- 'vingt-et-un': 21,
- 'vingt et un': 21,
- 'vingt-deux': 22,
- 'vingt deux': 22,
- 'vingt-trois': 23,
- 'vingt trois': 23,
- 'vingt-quatre': 24,
- 'vingt quatre': 24,
-}
-
-decimal_mark = ','
-
-# this will be added to re_values later
-units = {
- 'seconds': ['seconde', 'secondes', 'sec', 's'],
- 'minutes': ['minute', 'minutes', 'min', 'mn'],
- 'hours': ['heure', 'heures', 'h'],
- 'days': ['jour', 'jours', 'journée', 'journee', 'journées', 'journees', 'j'],
- 'weeks': ['semaine', 'semaines', 'sem'],
- 'months': ['mois', 'm'],
- 'years': ['année', 'annee', 'an', 'années', 'annees', 'ans'],
-}
-
-# text constants to be used by later regular expressions
-re_values = {
- 'specials': 'à|a|le|la|du|de',
- 'timeseparator': '(?:\:|h|\s*heures?\s*)',
- 'rangeseparator': '-',
- 'daysuffix': 'ième|ieme|ème|eme|ère|ere|nde',
- 'meridian': None,
- 'qunits': 'h|m|s|j|sem|a',
- 'now': ['maintenant', 'tout de suite', 'immédiatement', 'immediatement', 'à l\'instant', 'a l\'instant'],
-}
-
-# Used to adjust the returned date before/after the source
-Modifiers = {
- 'avant': -1,
- 'il y a': -1,
- 'plus tot': -1,
- 'plus tôt': -1,
- 'y a': -1,
- 'antérieur': -1,
- 'anterieur': -1,
- 'dernier': -1,
- 'dernière': -1,
- 'derniere': -1,
- 'précédent': -1,
- 'précedent': -1,
- 'precédent': -1,
- 'precedent': -1,
- 'fin de': 0,
- 'fin du': 0,
- 'fin de la': 0,
- 'fin des': 0,
- 'fin d\'': 0,
- 'ce': 0,
- 'cette': 0,
- 'depuis': 1,
- 'dans': 1,
- 'à partir': 1,
- 'a partir': 1,
- 'après': 1,
- 'apres': 1,
- 'lendemain': 1,
- 'prochain': 1,
- 'prochaine': 1,
- 'suivant': 1,
- 'suivante': 1,
- 'plus tard': 1
-}
-
-dayOffsets = {
- 'après-demain': 2,
- 'apres-demain': 2,
- 'après demain': 2,
- 'apres demain': 2,
- 'demain': 1,
- 'aujourd\'hui': 0,
- 'hier': -1,
- 'avant-hier': -2,
- 'avant hier': -2
-}
-
-# special day and/or times, i.e. lunch, noon, evening
-# each element in the dictionary is a dictionary that is used
-# to fill in any value to be replace - the current date/time will
-# already have been populated by the method buildSources
-re_sources = {
- 'après-midi': {'hr': 13, 'mn': 0, 'sec': 0},
- 'apres-midi': {'hr': 13, 'mn': 0, 'sec': 0},
- 'après midi': {'hr': 13, 'mn': 0, 'sec': 0},
- 'apres midi': {'hr': 13, 'mn': 0, 'sec': 0},
- 'midi': {'hr': 12, 'mn': 0, 'sec': 0},
- 'déjeuner': {'hr': 12, 'mn': 0, 'sec': 0},
- 'dejeuner': {'hr': 12, 'mn': 0, 'sec': 0},
- 'matin': {'hr': 6, 'mn': 0, 'sec': 0},
- 'petit-déjeuner': {'hr': 8, 'mn': 0, 'sec': 0},
- 'petit-dejeuner': {'hr': 8, 'mn': 0, 'sec': 0},
- 'petit déjeuner': {'hr': 8, 'mn': 0, 'sec': 0},
- 'petit dejeuner': {'hr': 8, 'mn': 0, 'sec': 0},
- 'diner': {'hr': 19, 'mn': 0, 'sec': 0},
- 'dîner': {'hr': 19, 'mn': 0, 'sec': 0},
- 'soir': {'hr': 18, 'mn': 0, 'sec': 0},
- 'soirée': {'hr': 18, 'mn': 0, 'sec': 0},
- 'soiree': {'hr': 18, 'mn': 0, 'sec': 0},
- 'minuit': {'hr': 0, 'mn': 0, 'sec': 0},
- 'nuit': {'hr': 21, 'mn': 0, 'sec': 0},
-}
-
-small = {
- 'zéro': 0,
- 'zero': 0,
- 'un': 1,
- 'une': 1,
- 'deux': 2,
- 'trois': 3,
- 'quatre': 4,
- 'cinq': 5,
- 'six': 6,
- 'sept': 7,
- 'huit': 8,
- 'neuf': 9,
- 'dix': 10,
- 'onze': 11,
- 'douze': 12,
- 'treize': 13,
- 'quatorze': 14,
- 'quinze': 15,
- 'seize': 16,
- 'dix-sept': 17,
- 'dix sept': 17,
- 'dix-huit': 18,
- 'dix huit': 18,
- 'dix-neuf': 19,
- 'dix neuf': 19,
- 'vingt': 20,
- 'vingt-et-un': 21,
- 'vingt et un': 21,
- 'trente': 30,
- 'quarante': 40,
- 'cinquante': 50,
- 'soixante': 60,
- 'soixante-dix': 70,
- 'soixante dix': 70,
- 'quatre-vingt': 80,
- 'quatre vingt': 80,
- 'quatre-vingt-dix': 90,
- 'quatre vingt dix': 90
-}
-
-magnitude = {
- 'mille': 1000,
- 'millier': 1000,
- 'million': 1000000,
- 'milliard': 1000000000,
- 'trillion': 1000000000000,
- 'quadrillion': 1000000000000000,
- 'quintillion': 1000000000000000000,
- 'sextillion': 1000000000000000000000,
- 'septillion': 1000000000000000000000000,
- 'octillion': 1000000000000000000000000000,
- 'nonillion': 1000000000000000000000000000000,
- 'décillion': 1000000000000000000000000000000000,
- 'decillion': 1000000000000000000000000000000000,
-}
-
-ignore = ('et', ',')
diff --git a/parsedatetime/pdt_locales/icu.py b/parsedatetime/pdt_locales/icu.py
deleted file mode 100755
index 8bee64b..0000000
--- a/parsedatetime/pdt_locales/icu.py
+++ /dev/null
@@ -1,149 +0,0 @@
-# -*- encoding: utf-8 -*-
-
-"""
-pdt_locales
-
-All of the included locale classes shipped with pdt.
-"""
-import datetime
-
-try:
- range = xrange
-except NameError:
- pass
-
-try:
- import PyICU as pyicu
-except ImportError:
- pyicu = None
-
-
-def icu_object(mapping):
- return type('_icu', (object,), mapping)
-
-
-def merge_weekdays(base_wd, icu_wd):
- result = []
- for left, right in zip(base_wd, icu_wd):
- if left == right:
- result.append(left)
- continue
- left = set(left.split('|'))
- right = set(right.split('|'))
- result.append('|'.join(left | right))
- return result
-
-
-def get_icu(locale):
- from . import base
- result = dict([(key, getattr(base, key))
- for key in dir(base) if not key.startswith('_')])
- result['icu'] = None
-
- if pyicu is None:
- return icu_object(result)
-
- if locale is None:
- locale = 'en_US'
- result['icu'] = icu = pyicu.Locale(locale)
-
- if icu is None:
- return icu_object(result)
-
- # grab spelled out format of all numbers from 0 to 100
- rbnf = pyicu.RuleBasedNumberFormat(pyicu.URBNFRuleSetTag.SPELLOUT, icu)
- result['numbers'].update([(rbnf.format(i), i) for i in range(0, 100)])
-
- symbols = result['symbols'] = pyicu.DateFormatSymbols(icu)
-
- # grab ICU list of weekdays, skipping first entry which
- # is always blank
- wd = [w.lower() for w in symbols.getWeekdays()[1:]]
- swd = [sw.lower() for sw in symbols.getShortWeekdays()[1:]]
-
- # store them in our list with Monday first (ICU puts Sunday first)
- result['Weekdays'] = merge_weekdays(result['Weekdays'],
- wd[1:] + wd[0:1])
- result['shortWeekdays'] = merge_weekdays(result['shortWeekdays'],
- swd[1:] + swd[0:1])
- result['Months'] = [m.lower() for m in symbols.getMonths()]
- result['shortMonths'] = [sm.lower() for sm in symbols.getShortMonths()]
- keys = ['full', 'long', 'medium', 'short']
-
- createDateInstance = pyicu.DateFormat.createDateInstance
- createTimeInstance = pyicu.DateFormat.createTimeInstance
- icu_df = result['icu_df'] = {
- 'full': createDateInstance(pyicu.DateFormat.kFull, icu),
- 'long': createDateInstance(pyicu.DateFormat.kLong, icu),
- 'medium': createDateInstance(pyicu.DateFormat.kMedium, icu),
- 'short': createDateInstance(pyicu.DateFormat.kShort, icu),
- }
- icu_tf = result['icu_tf'] = {
- 'full': createTimeInstance(pyicu.DateFormat.kFull, icu),
- 'long': createTimeInstance(pyicu.DateFormat.kLong, icu),
- 'medium': createTimeInstance(pyicu.DateFormat.kMedium, icu),
- 'short': createTimeInstance(pyicu.DateFormat.kShort, icu),
- }
-
- result['dateFormats'] = {}
- result['timeFormats'] = {}
- for x in keys:
- result['dateFormats'][x] = icu_df[x].toPattern()
- result['timeFormats'][x] = icu_tf[x].toPattern()
-
- am = pm = ts = ''
-
- # ICU doesn't seem to provide directly the date or time separator
- # so we have to figure it out
- o = result['icu_tf']['short']
- s = result['timeFormats']['short']
-
- result['usesMeridian'] = 'a' in s
- result['uses24'] = 'H' in s
-
- # '11:45 AM' or '11:45'
- s = o.format(datetime.datetime(2003, 10, 30, 11, 45))
-
- # ': AM' or ':'
- s = s.replace('11', '').replace('45', '')
-
- if len(s) > 0:
- ts = s[0]
-
- if result['usesMeridian']:
- # '23:45 AM' or '23:45'
- am = s[1:].strip()
- s = o.format(datetime.datetime(2003, 10, 30, 23, 45))
-
- if result['uses24']:
- s = s.replace('23', '')
- else:
- s = s.replace('11', '')
-
- # 'PM' or ''
- pm = s.replace('45', '').replace(ts, '').strip()
-
- result['timeSep'] = [ts]
- result['meridian'] = [am, pm] if am and pm else []
-
- o = result['icu_df']['short']
- s = o.format(datetime.datetime(2003, 10, 30, 11, 45))
- s = s.replace('10', '').replace('30', '').replace(
- '03', '').replace('2003', '')
-
- if len(s) > 0:
- ds = s[0]
- else:
- ds = '/'
-
- result['dateSep'] = [ds]
- s = result['dateFormats']['short']
- l = s.lower().split(ds)
- dp_order = []
-
- for s in l:
- if len(s) > 0:
- dp_order.append(s[:1])
-
- result['dp_order'] = dp_order
- return icu_object(result)
diff --git a/parsedatetime/pdt_locales/nl_NL.py b/parsedatetime/pdt_locales/nl_NL.py
deleted file mode 100755
index 45c770f..0000000
--- a/parsedatetime/pdt_locales/nl_NL.py
+++ /dev/null
@@ -1,114 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'nl_NL'
-dateSep = ['-', '/']
-timeSep = [':']
-meridian = []
-usesMeridian = False
-uses24 = True
-decimal_mark = ','
-
-Weekdays = [
- 'maandag', 'dinsdag', 'woensdag', 'donderdag',
- 'vrijdag', 'zaterdag', 'zondag',
-]
-shortWeekdays = [
- 'ma', 'di', 'wo', 'do', 'vr', 'za', 'zo',
-]
-Months = [
- 'januari', 'februari', 'maart', 'april', 'mei', 'juni', 'juli',
- 'augustus', 'september', 'oktober', 'november', 'december',
-]
-shortMonths = [
- 'jan', 'feb', 'mar', 'apr', 'mei', 'jun',
- 'jul', 'aug', 'sep', 'okt', 'nov', 'dec',
-]
-dateFormats = {
- 'full': 'EEEE, dd MMMM yyyy',
- 'long': 'dd MMMM yyyy',
- 'medium': 'dd-MM-yyyy',
- 'short': 'dd-MM-yy',
-}
-
-timeFormats = {
- 'full': 'HH:mm:ss v',
- 'long': 'HH:mm:ss z',
- 'medium': 'HH:mm:ss',
- 'short': 'HH:mm',
-}
-
-dp_order = ['d', 'm', 'y']
-
-# the short version would be a capital M,
-# as I understand it we can't distinguish
-# between m for minutes and M for months.
-units = {
- 'seconds': ['secunden', 'sec', 's'],
- 'minutes': ['minuten', 'min', 'm'],
- 'hours': ['uren', 'uur', 'h'],
- 'days': ['dagen', 'dag', 'd'],
- 'weeks': ['weken', 'w'],
- 'months': ['maanden', 'maand'],
- 'years': ['jaar', 'jaren', 'j'],
-}
-
-re_values = re_values.copy()
-re_values.update({
- 'specials': 'om',
- 'timeseparator': ':',
- 'rangeseparator': '-',
- 'daysuffix': ' |de',
- 'qunits': 'h|m|s|d|w|m|j',
- 'now': ['nu'],
-})
-
-# Used to adjust the returned date before/after the source
-# still looking for insight on how to translate all of them to german.
-Modifiers = {
- 'vanaf': 1,
- 'voor': -1,
- 'na': 1,
- 'vorige': -1,
- 'eervorige': -1,
- 'prev': -1,
- 'laastste': -1,
- 'volgende': 1,
- 'deze': 0,
- 'vorige': -1,
- 'over': 2,
- 'eind van': 0,
-}
-
-# morgen/abermorgen does not work, see
-# http://code.google.com/p/parsedatetime/issues/detail?id=19
-dayOffsets = {
- 'morgen': 1,
- 'vandaag': 0,
- 'gisteren': -1,
- 'eergisteren': -2,
- 'overmorgen': 2,
-}
-
-# special day and/or times, i.e. lunch, noon, evening
-# each element in the dictionary is a dictionary that is used
-# to fill in any value to be replace - the current date/time will
-# already have been populated by the method buildSources
-re_sources = {
- 'middag': {'hr': 12, 'mn': 0, 'sec': 0},
- 'vanmiddag': {'hr': 12, 'mn': 0, 'sec': 0},
- 'lunch': {'hr': 12, 'mn': 0, 'sec': 0},
- 'morgen': {'hr': 6, 'mn': 0, 'sec': 0},
- "'s morgens": {'hr': 6, 'mn': 0, 'sec': 0},
- 'ontbijt': {'hr': 8, 'mn': 0, 'sec': 0},
- 'avondeten': {'hr': 19, 'mn': 0, 'sec': 0},
- 'avond': {'hr': 18, 'mn': 0, 'sec': 0},
- 'avonds': {'hr': 18, 'mn': 0, 'sec': 0},
- 'middernacht': {'hr': 0, 'mn': 0, 'sec': 0},
- 'nacht': {'hr': 21, 'mn': 0, 'sec': 0},
- 'nachts': {'hr': 21, 'mn': 0, 'sec': 0},
- 'vanavond': {'hr': 21, 'mn': 0, 'sec': 0},
- 'vannacht': {'hr': 21, 'mn': 0, 'sec': 0},
-}
diff --git a/parsedatetime/pdt_locales/pt_BR.py b/parsedatetime/pdt_locales/pt_BR.py
deleted file mode 100755
index 21fdf6d..0000000
--- a/parsedatetime/pdt_locales/pt_BR.py
+++ /dev/null
@@ -1,48 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'pt_BR'
-dateSep = ['/']
-usesMeridian = False
-uses24 = True
-decimal_mark = ','
-
-Weekdays = [
- 'segunda-feira', 'terça-feira', 'quarta-feira',
- 'quinta-feira', 'sexta-feira', 'sábado', 'domingo',
-]
-shortWeekdays = [
- 'seg', 'ter', 'qua', 'qui', 'sex', 'sáb', 'dom',
-]
-Months = [
- 'janeiro', 'fevereiro', 'março', 'abril', 'maio', 'junho', 'julho',
- 'agosto', 'setembro', 'outubro', 'novembro', 'dezembro'
-]
-shortMonths = [
- 'jan', 'fev', 'mar', 'abr', 'mai', 'jun',
- 'jul', 'ago', 'set', 'out', 'nov', 'dez'
-]
-dateFormats = {
- 'full': "EEEE, d' de 'MMMM' de 'yyyy",
- 'long': "d' de 'MMMM' de 'yyyy",
- 'medium': "dd-MM-yy",
- 'short': "dd/MM/yyyy",
-}
-
-timeFormats = {
- 'full': "HH'H'mm' 'ss z",
- 'long': "HH:mm:ss z",
- 'medium': "HH:mm:ss",
- 'short': "HH:mm",
-}
-
-dp_order = ['d', 'm', 'y']
-
-units = {
- 'seconds': ['segundo', 'seg', 's'],
- 'minutes': ['minuto', 'min', 'm'],
- 'days': ['dia', 'dias', 'd'],
- 'months': ['mês', 'meses'],
-}
diff --git a/parsedatetime/pdt_locales/ru_RU.py b/parsedatetime/pdt_locales/ru_RU.py
deleted file mode 100755
index cda26f7..0000000
--- a/parsedatetime/pdt_locales/ru_RU.py
+++ /dev/null
@@ -1,164 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-from .base import * # noqa
-
-# don't use an unicode string
-localeID = 'ru_RU'
-dateSep = ['-', '.']
-timeSep = [':']
-meridian = []
-usesMeridian = False
-uses24 = True
-
-Weekdays = [
- 'понедельник', 'вторник', 'среда', 'четверг',
- 'пятница', 'суббота', 'воскресенье',
-]
-shortWeekdays = [
- 'пн', 'вт', 'ср', 'чт', 'пт', 'сб', 'вс',
-]
-# library does not know how to conjugate words
-# библиотека не умеет спрягать слова
-Months = [
- 'января', 'февраля', 'марта', 'апреля', 'мая', 'июня', 'июля',
- 'августа', 'сентября', 'октября', 'ноября', 'декабря',
-]
-shortMonths = [
- 'явн', 'фев', 'мрт', 'апр', 'май', 'июн',
- 'июл', 'авг', 'сен', 'окт', 'нбр', 'дек',
-]
-dateFormats = {
- 'full': 'EEEE, dd MMMM yyyy',
- 'long': 'dd MMMM yyyy',
- 'medium': 'dd-MM-yyyy',
- 'short': 'dd-MM-yy',
-}
-
-timeFormats = {
- 'full': 'HH:mm:ss v',
- 'long': 'HH:mm:ss z',
- 'medium': 'HH:mm:ss',
- 'short': 'HH:mm',
-}
-
-dp_order = ['d', 'm', 'y']
-
-decimal_mark = '.'
-
-units = {
- 'seconds': ['секунда', 'секунды', 'секунд', 'сек', 'с'],
- 'minutes': ['минута', 'минуты', 'минут', 'мин', 'м'],
- 'hours': ['час', 'часов', 'часа', 'ч'],
- 'days': ['день', 'дней', 'д'],
- 'weeks': ['неделя', 'недели', 'н'],
- 'months': ['месяц', 'месяца', 'мес'],
- 'years': ['год', 'года', 'годы', 'г'],
-}
-
-re_values = re_values.copy()
-re_values.update({
- 'specials': 'om',
- 'timeseparator': ':',
- 'rangeseparator': '-',
- 'daysuffix': 'ого|ой|ий|тье',
- 'qunits': 'д|мес|г|ч|н|м|с',
- 'now': ['сейчас'],
-})
-
-Modifiers = {
- 'после': 1,
- 'назад': -1,
- 'предыдущий': -1,
- 'последний': -1,
- 'далее': 1,
- 'ранее': -1,
-}
-
-dayOffsets = {
- 'завтра': 1,
- 'сегодня': 0,
- 'вчера': -1,
- 'позавчера': -2,
- 'послезавтра': 2,
-}
-
-re_sources = {
- 'полдень': {'hr': 12, 'mn': 0, 'sec': 0},
- 'день': {'hr': 13, 'mn': 0, 'sec': 0},
- 'обед': {'hr': 12, 'mn': 0, 'sec': 0},
- 'утро': {'hr': 6, 'mn': 0, 'sec': 0},
- 'завтрак': {'hr': 8, 'mn': 0, 'sec': 0},
- 'ужин': {'hr': 19, 'mn': 0, 'sec': 0},
- 'вечер': {'hr': 18, 'mn': 0, 'sec': 0},
- 'полночь': {'hr': 0, 'mn': 0, 'sec': 0},
- 'ночь': {'hr': 21, 'mn': 0, 'sec': 0},
-}
-
-small = {
- 'ноль': 0,
- 'один': 1,
- 'два': 2,
- 'три': 3,
- 'четыре': 4,
- 'пять': 5,
- 'шесть': 6,
- 'семь': 7,
- 'восемь': 8,
- 'девять': 9,
- 'десять': 10,
- 'одиннадцать': 11,
- 'двенадцать': 12,
- 'тринадцать': 13,
- 'четырнадцать': 14,
- 'пятнадцать': 15,
- 'шестнадцать': 16,
- 'семнадцать': 17,
- 'восемнадцать': 18,
- 'девятнадцать': 19,
- 'двадцать': 20,
- 'тридцать': 30,
- 'сорок': 40,
- 'пятьдесят': 50,
- 'шестьдесят': 60,
- 'семьдесят': 70,
- 'восемьдесят': 80,
- 'девяносто': 90,
-}
-
-numbers = {
- 'ноль': 0,
- 'один': 1,
- 'два': 2,
- 'три': 3,
- 'четыре': 4,
- 'пять': 5,
- 'шесть': 6,
- 'семь': 7,
- 'восемь': 8,
- 'девять': 9,
- 'десять': 10,
- 'одиннадцать': 11,
- 'двенадцать': 12,
- 'тринадцать': 13,
- 'четырнадцать': 14,
- 'пятнадцать': 15,
- 'шестнадцать': 16,
- 'семнадцать': 17,
- 'восемнадцать': 18,
- 'девятнадцать': 19,
- 'двадцать': 20,
-}
-
-magnitude = {
- 'тысяча': 1000,
- 'миллион': 1000000,
- 'миллиард': 1000000000,
- 'триллион': 1000000000000,
- 'квадриллион': 1000000000000000,
- 'квинтиллион': 1000000000000000000,
- 'секстиллион': 1000000000000000000000,
- 'септиллион': 1000000000000000000000000,
- 'октиллион': 1000000000000000000000000000,
- 'нониллион': 1000000000000000000000000000000,
- 'дециллион': 1000000000000000000000000000000000,
-}
diff --git a/parsedatetime/warns.py b/parsedatetime/warns.py
deleted file mode 100755
index a754fc9..0000000
--- a/parsedatetime/warns.py
+++ /dev/null
@@ -1,26 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-parsedatetime/warns.py
-
-All subclasses inherited from `Warning` class
-
-"""
-from __future__ import absolute_import
-
-import warnings
-
-
-class pdtDeprecationWarning(DeprecationWarning):
- pass
-
-
-class pdtPendingDeprecationWarning(PendingDeprecationWarning):
- pass
-
-
-class pdt20DeprecationWarning(pdtPendingDeprecationWarning):
- pass
-
-
-warnings.simplefilter('default', pdtDeprecationWarning)
-warnings.simplefilter('ignore', pdtPendingDeprecationWarning)
diff --git a/pyparsing.pyc b/pyparsing.pyc
deleted file mode 100644
index 19fd43b..0000000
Binary files a/pyparsing.pyc and /dev/null differ
diff --git a/pypeg2/__init__.py b/pypeg2/__init__.py
deleted file mode 100644
index d16c2c9..0000000
--- a/pypeg2/__init__.py
+++ /dev/null
@@ -1,1474 +0,0 @@
-"""
-pyPEG parsing framework
-
-pyPEG offers a packrat parser as well as a framework to parse and output
-languages for Python 2.7 and 3.x, see http://fdik.org/pyPEG2
-
-Copyleft 2012, Volker Birk.
-This program is under GNU General Public License 2.0.
-"""
-
-
-from __future__ import unicode_literals
-try:
- range = xrange
- str = unicode
-except NameError:
- pass
-
-
-__version__ = 2.15
-__author__ = "Volker Birk"
-__license__ = "This program is under GNU General Public License 2.0."
-__url__ = "http://fdik.org/pyPEG"
-
-
-import re
-import sys
-import weakref
-if __debug__:
- import warnings
-from types import FunctionType
-from collections import namedtuple
-try:
- from collections import OrderedDict
-except ImportError:
- from ordereddict import OrderedDict
-
-
-word = re.compile(r"\w+")
-"""Regular expression for scanning a word."""
-
-_RegEx = type(word)
-
-restline = re.compile(r".*")
-"""Regular expression for rest of line."""
-
-whitespace = re.compile("(?m)\s+")
-"""Regular expression for scanning whitespace."""
-
-comment_sh = re.compile(r"\#.*")
-"""Shell script style comment."""
-
-comment_cpp = re.compile(r"//.*")
-"""C++ style comment."""
-
-comment_c = re.compile(r"(?ms)/\*.*?\*/")
-"""C style comment without nesting comments."""
-
-comment_pas = re.compile(r"(?ms)\(\*.*?\*\)")
-"""Pascal style comment without nesting comments."""
-
-
-def _card(n, thing):
- # Reduce unnecessary recursions
- if len(thing) == 1:
- return n, thing[0]
- else:
- return n, thing
-
-
-def some(*thing):
- """At least one occurrence of thing, + operator.
- Inserts -2 as cardinality before thing.
- """
- return _card(-2, thing)
-
-
-def maybe_some(*thing):
- """No thing or some of them, * operator.
- Inserts -1 as cardinality before thing.
- """
- return _card(-1, thing)
-
-
-def optional(*thing):
- """Thing or no thing, ? operator.
- Inserts 0 as cardinality before thing.
- """
- return _card(0, thing)
-
-
-def _csl(separator, *thing):
- # reduce unnecessary recursions
- if len(thing) == 1:
- L = [thing[0]]
- L.extend(maybe_some(separator, blank, thing[0]))
- return tuple(L)
- else:
- L = list(thing)
- L.append(-1)
- L2 = [separator, blank]
- L2.extend(tuple(thing))
- L.append(tuple(L2))
- return tuple(L)
-
-try:
- # Python 3.x
- _exec = eval("exec")
- _exec('''
-def csl(*thing, separator=","):
- """Generate a grammar for a simple comma separated list."""
- return _csl(separator, *thing)
-''')
-except SyntaxError:
- # Python 2.7
- def csl(*thing):
- """Generate a grammar for a simple comma separated list."""
- return _csl(",", *thing)
-
-
-def attr(name, thing=word, subtype=None):
- """Generate an Attribute with that name, referencing the thing.
-
- Instance variables:
- Class Attribute class generated by namedtuple()
- """
- # if __debug__:
- # if isinstance(thing, (tuple, list)):
- # warnings.warn(type(thing).__name__
- # + " not recommended as grammar of attribute "
- # + repr(name), SyntaxWarning)
- return attr.Class(name, thing, subtype)
-
-attr.Class = namedtuple("Attribute", ("name", "thing", "subtype"))
-
-
-def flag(name, thing=None):
- """Generate an Attribute with that name which is valued True or False."""
- if thing is None:
- thing = Keyword(name)
- return attr(name, thing, "Flag")
-
-
-def attributes(grammar, invisible=False):
- """Iterates all attributes of a grammar."""
- if type(grammar) == attr.Class and (invisible or grammar.name[0] != "_"):
- yield grammar
- elif type(grammar) == tuple:
- for e in grammar:
- for a in attributes(e, invisible):
- yield a
-
-
-class Whitespace(str):
- grammar = whitespace
-
-
-class RegEx(object):
- """Regular Expression.
-
- Instance Variables:
- regex pre-compiled object from re.compile()
- """
-
- def __init__(self, value, **kwargs):
- self.regex = re.compile(value, re.U)
- self.search = self.regex.search
- self.match = self.regex.match
- self.split = self.regex.split
- self.findall = self.regex.findall
- self.finditer = self.regex.finditer
- self.sub = self.regex.sub
- self.subn = self.regex.subn
- self.flags = self.regex.flags
- self.groups = self.regex.groups
- self.groupindex = self.regex.groupindex
- self.pattern = value
- for k, v in kwargs.items():
- setattr(self, k, v)
-
- def __str__(self):
- return self.pattern
-
- def __repr__(self):
- result = type(self).__name__ + "(" + repr(self.pattern)
- try:
- result += ", name=" + repr(self.name)
- except:
- pass
- return result + ")"
-
-
-class Literal(object):
- """Literal value."""
- _basic_types = (bool, int, float, complex, str, bytes, bytearray, list,
- tuple, slice, set, frozenset, dict)
- def __init__(self, value, **kwargs):
- if isinstance(self, Literal._basic_types):
- pass
- else:
- self.value = value
- for k, v in kwargs.items():
- setattr(self, k, v)
-
- def __str__(self):
- if isinstance(self, Literal._basic_types):
- return super(Literal, self).__str__()
- else:
- return str(self.value)
-
- def __repr__(self):
- if isinstance(self, Literal._basic_types):
- return type(self).__name__ + "(" + \
- super(Literal, self).__repr__() + ")"
- else:
- return type(self).__name__ + "(" + repr(self.value) + ")"
-
- def __eq__(self, other):
- if isinstance(self, Literal._basic_types):
- if type(self) == type(other) and super().__eq__(other):
- return True
- else:
- return False
- else:
- if type(self) == type(other) and str(self) == str(other):
- return True
- else:
- return False
-
-
-class Plain(object):
- """A plain object"""
-
- def __init__(self, name=None, **kwargs):
- """Construct a plain object with an optional name and optional other
- attributes
- """
- if name is not None:
- self.name = Symbol(name)
- for k, v in kwargs:
- setattr(self, k, v)
-
- def __repr__(self):
- """x.__repr__() <==> repr(x)"""
- try:
- return self.__class__.__name__ + "(name=" + repr(self.name) + ")"
- except AttributeError:
- return self.__class__.__name__ + "()"
-
-
-class List(list):
- """A List of things."""
-
- def __init__(self, *args, **kwargs):
- """Construct a List, and construct its attributes from keyword
- arguments.
- """
- _args = []
- if len(args) == 1:
- if isinstance(args[0], str):
- self.append(args[0])
- elif isinstance(args[0], (tuple, list)):
- for e in args[0]:
- if isinstance(e, attr.Class):
- setattr(self, e.name, e.value)
- else:
- _args.append(e)
- super(List, self).__init__(_args)
- else:
- raise ValueError("initializer of List should be collection or string")
- else:
- for e in args:
- if isinstance(e, attr.Class):
- setattr(self, e.name, e.value)
- else:
- _args.append(e)
- super(List, self).__init__(_args)
-
- for k, v in kwargs.items():
- setattr(self, k, v)
-
- def __repr__(self):
- """x.__repr__() <==> repr(x)"""
- result = type(self).__name__ + "(" + super(List, self).__repr__()
- try:
- result += ", name=" + repr(self.name)
- except:
- pass
- return result + ")"
-
- def __eq__(self, other):
- return super(List, self).__eq__(list(other))
-
-
-class _UserDict(object):
- # UserDict cannot be used because of metaclass conflicts
- def __init__(self, *args, **kwargs):
- self.data = dict(*args, **kwargs)
- def __len__(self):
- return len(self.data)
- def __getitem__(self, key):
- return self.data[key]
- def __setitem__(self, key, value):
- self.data[key] = value
- def __delitem__(self, key):
- del self.data[key]
- def __iter__(self):
- return self.data.keys()
- def __contains__(self, item):
- return item in self.data
- def items(self):
- return self.data.items()
- def keys(self):
- return self.data.keys()
- def values(self):
- return self.data.values()
- def clear(self):
- self.data.clear()
- def copy(self):
- return self.data.copy()
-
-
-class Namespace(_UserDict):
- """A dictionary of things, indexed by their name."""
- name_by = lambda value: "#" + str(id(value))
-
- def __init__(self, *args, **kwargs):
- """Initialize an OrderedDict containing the data of the Namespace.
- Arguments are being put into the Namespace, keyword arguments give the
- attributes of the Namespace.
- """
- if args:
- self.data = OrderedDict(args)
- else:
- self.data = OrderedDict()
- for k, v in kwargs.items():
- setattr(self, k, v)
-
- def __setitem__(self, key, value):
- """x.__setitem__(i, y) <==> x[i]=y"""
- if key is None:
- name = Symbol(Namespace.name_by(value))
- else:
- name = Symbol(key)
- try:
- value.name = name
- except AttributeError:
- pass
- try:
- value.namespace
- except AttributeError:
- try:
- value.namespace = weakref.ref(self)
- except AttributeError:
- pass
- else:
- if not value.namespace:
- value.namespace = weakref.ref(self)
- super(Namespace, self).__setitem__(name, value)
-
- def __delitem__(self, key):
- """x.__delitem__(y) <==> del x[y]"""
- self[key].namespace = None
- super(Namespace, self).__delitem__(key)
-
- def __repr__(self):
- """x.__repr__() <==> repr(x)"""
- result = type(self).__name__ + "(["
- for key, value in self.data.items():
- result += "(" + repr(key) + ", " + repr(value) + ")"
- result += ", "
- result += "]"
- try:
- result += ", name=" + repr(self.name)
- except:
- pass
- return result + ")"
-
-
-class Enum(Namespace):
- """A Namespace which is being treated as an Enum.
- Enums can only contain Keywords or Symbols."""
-
- def __init__(self, *things, **kwargs):
- """Construct an Enum using a tuple of things."""
- self.data = OrderedDict()
- for thing in things:
- if type(thing) == str:
- thing = Symbol(thing)
- if not isinstance(thing, Symbol):
- raise TypeError(repr(thing) + " is not a Symbol")
- super(Enum, self).__setitem__(thing, thing)
- for k, v in kwargs.items():
- setattr(self, k, v)
-
- def __repr__(self):
- """x.__repr__() <==> repr(x)"""
- v = [e for e in self.values()]
- result = type(self).__name__ + "(" + repr(v)
- try:
- result += ", name=" + repr(self.name)
- except:
- pass
- return result + ")"
-
- def __setitem__(self, key, value):
- """x.__setitem__(i, y) <==> x[i]=y"""
- if not isinstance(value, Keyword) and not isinstance(value, Symbol):
- raise TypeError("Enums can only contain Keywords or Symbols")
- raise ValueError("Enums cannot be modified after creation.")
-
-
-class Symbol(str):
- """Use to scan Symbols.
-
- Class variables:
- regex regular expression to scan, default r"\w+"
- check_keywords flag if a Symbol is checked for not being a Keyword
- default: False
- """
-
- regex = word
- check_keywords = False
-
- def __init__(self, name, namespace=None):
- """Construct a Symbol with that name in Namespace namespace.
-
- Raises:
- ValueError if check_keywords is True and value is identical to
- a Keyword
- TypeError if namespace is given and not a Namespace
- """
-
- if Symbol.check_keywords and name in Keyword.table:
- raise ValueError(repr(name)
- + " is a Keyword, but is used as a Symbol")
- if namespace:
- if isinstance(namespace, Namespace):
- namespace[name] = self
- else:
- raise TypeError(repr(namespace) + " is not a Namespace")
- else:
- self.name = name
- self.namespace = None
-
- def __repr__(self):
- """x.__repr__() <==> repr(x)"""
- return type(self).__name__ + "(" + str(self).__repr__() + ")"
-
-
-class Keyword(Symbol):
- """Use to access the keyword table.
-
- Class variables:
- regex regular expression to scan, default r"\w+"
- table Namespace with keyword table
- """
-
- regex = word
- table = Namespace()
-
- def __init__(self, keyword):
- """Adds keyword to the keyword table."""
- if keyword not in Keyword.table:
- Keyword.table[keyword] = self
- self.name = keyword
-
-K = Keyword
-"""Shortcut for Keyword."""
-
-
-class Concat(List):
- """Concatenation of things.
-
- This class exists as a mutable alternative to using a tuple.
- """
-
-
-def name():
- """Generate a grammar for a symbol with name."""
- return attr("name", Symbol)
-
-
-def ignore(grammar):
- """Ignore what matches to the grammar."""
- try:
- ignore.serial += 1
- except AttributeError:
- ignore.serial = 1
- return attr("_ignore" + str(ignore.serial), grammar)
-
-
-def indent(*thing):
- """Indent thing by one level.
- Inserts -3 as cardinality before thing.
- """
- return _card(-3, thing)
-
-
-def contiguous(*thing):
- """Disable automated whitespace matching.
- Inserts -4 as cardinality before thing.
- """
- return _card(-4, thing)
-
-
-def separated(*thing):
- """Enable automated whitespace matching.
- Inserts -5 as cardinality before thing.
- """
- return _card(-5, thing)
-
-
-def omit(*thing):
- """Omit what matches to the grammar."""
- return _card(-6, thing)
-
-
-endl = lambda thing, parser: "\n"
-"""End of line marker for composing text."""
-
-
-blank = lambda thing, parser: " "
-"""Space marker for composing text."""
-
-
-class GrammarError(Exception):
- """Base class for errors in grammars."""
-
-
-class GrammarTypeError(TypeError, GrammarError):
- """Raised if grammar contains an object of unkown type."""
-
-
-class GrammarValueError(ValueError, GrammarError):
- """Raised if grammar contains an illegal value."""
-
-
-def how_many(grammar):
- """Determines the possibly parsed objects of grammar.
-
- Returns:
- 0 if there will be no objects
- 1 if there will be a maximum of one object
- 2 if there can be more than one object
-
- Raises:
- GrammarTypeError
- if grammar contains an object of unkown type
- GrammarValueError
- if grammar contains an illegal cardinality value
- """
-
- if grammar is None:
- return 0
-
- elif type(grammar) == int:
- return grammar
-
- elif _issubclass(grammar, Symbol) or isinstance(grammar, (RegEx, _RegEx)):
- return 1
-
- elif isinstance(grammar, (str, Literal)):
- return 0
-
- elif isinstance(grammar, attr.Class):
- return 0
-
- elif type(grammar) == FunctionType:
- return 0
-
- elif isinstance(grammar, (tuple, Concat)):
- length, card = 0, 1
- for e in grammar:
- if type(e) == int:
- if e < -6:
- raise GrammarValueError(
- "illegal cardinality value in grammar: " + str(e))
- if e in (-5, -4, -3):
- pass
- elif e in (-1, -2):
- card = 2
- elif e == 0:
- card = 1
- elif e == -6:
- return 0
- else:
- card = min(e, 2)
- else:
- length += card * how_many(e)
- if length >= 2:
- return 2
- return length
-
- elif isinstance(grammar, list):
- m = 0
- for e in grammar:
- m = max(m, how_many(e))
- if m == 2:
- return m
- return m
-
- elif _issubclass(grammar, object):
- return 1
-
- else:
- raise GrammarTypeError("grammar contains an illegal type: "
- + type(grammar).__name__ + ": " + repr(grammar))
-
-
-def parse(text, thing, filename=None, whitespace=whitespace, comment=None,
- keep_feeble_things=False):
- """Parse text following thing as grammar and return the resulting things or
- raise an error.
-
- Arguments:
- text text to parse
- thing grammar for things to parse
- filename filename where text is origin from
- whitespace regular expression to skip whitespace
- default: regex "(?m)\s+"
- comment grammar to parse comments
- default: None
- keep_feeble_things
- put whitespace and comments into the .feeble_things
- attribute instead of dumping them
-
- Returns generated things.
-
- Raises:
- SyntaxError if text does not match the grammar in thing
- ValueError if input does not match types
- TypeError if output classes have wrong syntax for __init__()
- GrammarTypeError
- if grammar contains an object of unkown type
- GrammarValueError
- if grammar contains an illegal cardinality value
- """
-
- parser = Parser()
- parser.whitespace = whitespace
- parser.comment = comment
- parser.text = text
- parser.filename = filename
- parser.keep_feeble_things = keep_feeble_things
-
- t, r = parser.parse(text, thing)
- if t:
- raise parser.last_error
- return r
-
-
-def compose(thing, grammar=None, indent=" ", autoblank=True):
- """Compose text using thing with grammar.
-
- Arguments:
- thing thing containing other things with grammar
- grammar grammar to use to compose thing
- default: thing.grammar
- indent string to use to indent while composing
- default: four spaces
- autoblank add blanks if grammar would possibly be
- violated otherwise
- default: True
-
- Returns text
-
- Raises:
- ValueError if input does not match grammar
- GrammarTypeError
- if grammar contains an object of unkown type
- GrammarValueError
- if grammar contains an illegal cardinality value
- """
-
- parser = Parser()
- parser.indent = indent
- parser.autoblank = autoblank
- return parser.compose(thing, grammar)
-
-
-def _issubclass(obj, cls):
- # If obj is not a class, just return False
- try:
- return issubclass(obj, cls)
- except TypeError:
- return False
-
-
-class Parser(object):
- """Offers parsing and composing capabilities. Implements a Packrat parser.
-
- Instance variables:
- whitespace regular expression to scan whitespace
- default: "(?m)\s+"
- comment grammar to parse comments
- last_error syntax error which ended parsing
- indent string to use to indent while composing
- default: four spaces
- indention_level level to indent to
- default: 0
- text original text to parse; set for decorated syntax
- errors
- filename filename where text is origin from
- autoblank add blanks while composing if grammar would possibly
- be violated otherwise
- default: True
- keep_feeble_things put whitespace and comments into the .feeble_things
- attribute instead of dumping them
- """
-
- def __init__(self):
- """Initialize instance variables to their defaults."""
- self.whitespace = whitespace
- self.comment = None
- self.last_error = None
- self.indent = " "
- self.indention_level = 0
- self.text = None
- self.filename = None
- self.autoblank = True
- self.keep_feeble_things = False
- self._memory = {}
- self._got_endl = True
- self._contiguous = False
- self._got_regex = False
-
- def clear_memory(self, thing=None):
- """Clear cache memory for packrat parsing.
-
- Arguments:
- thing thing for which cache memory is cleared,
- None if cache memory should be cleared for all
- things
- """
-
- if thing is None:
- self._memory = {}
- else:
- try:
- del self._memory[id(thing)]
- except KeyError:
- pass
-
- def parse(self, text, thing, filename=None):
- """(Partially) parse text following thing as grammar and return the
- resulting things.
-
- Arguments:
- text text to parse
- thing grammar for things to parse
- filename filename where text is origin from
-
- Returns (text, result) with:
- text unparsed text
- result generated objects or SyntaxError object
-
- Raises:
- ValueError if input does not match types
- TypeError if output classes have wrong syntax for __init__()
- GrammarTypeError
- if grammar contains an object of unkown type
- GrammarValueError
- if grammar contains an illegal cardinality value
- """
-
- self.text = text
- if filename:
- self.filename = filename
- pos = [1, 0]
- t, skip_result = self._skip(text, pos)
- t, r = self._parse(t, thing, pos)
- if type(r) == SyntaxError:
- raise r
- else:
- if self.keep_feeble_things and skip_result:
- try:
- r.feeble_things
- except AttributeError:
- try:
- r.feeble_things = skip_result
- except AttributeError:
- pass
- else:
- r.feeble_things = skip_result + r.feeble_things
- return t, r
-
- def _skip(self, text, pos=None):
- # Skip whitespace and comments from input text
- t2 = None
- t = text
- result = []
- while t2 != t:
- if self.whitespace and not self._contiguous:
- t, r = self._parse(t, Whitespace, pos)
- if self.keep_feeble_things and r and not isinstance(r,
- SyntaxError):
- result.append(r)
- t2 = t
- if self.comment:
- t, r = self._parse(t, self.comment, pos)
- if self.keep_feeble_things and r and not isinstance(r,
- SyntaxError):
- result.append(r)
- return t, result
-
- def generate_syntax_error(self, msg, pos):
- """Generate a syntax error construct with
-
- msg string with error message
- pos (lineNo, charInText) with positioning information
- """
-
- result = SyntaxError(msg)
- if pos:
- result.lineno = pos[0]
- start = max(pos[1] - 19, 0)
- end = min(pos[1] + 20, len(self.text))
- result.text = self.text[start:end]
- result.offset = pos[1] - start + 1
- while "\n" in result.text:
- lf = result.text.find("\n")
- if lf >= result.offset:
- result.text = result.text[:result.offset-1]
- break;
- else:
- L = len(result.text)
- result.text = result.text[lf+1:]
- result.offset -= L - len(result.text)
- if self.filename:
- result.filename = self.filename
- return result
-
- def _parse(self, text, thing, pos=[1, 0]):
- # Parser implementation
-
- def update_pos(text, t, pos):
- # Calculate where we are in the text
- if not pos:
- return
- if text == t:
- return
- d_text = text[:len(text) - len(t)]
- pos[0] += d_text.count("\n")
- pos[1] += len(d_text)
-
- try:
- return self._memory[id(thing)][text]
- except:
- pass
-
- if pos:
- current_pos = tuple(pos)
- else:
- current_pos = None
-
- def syntax_error(msg):
- return self.generate_syntax_error(msg, pos)
-
- try:
- thing.parse
- except AttributeError:
- pass
- else:
- t, r = thing.parse(self, text, pos)
- if not isinstance(r, SyntaxError):
- t, skip_result = self._skip(t)
- update_pos(text, t, pos)
- if self.keep_feeble_things:
- try:
- r.feeble_things
- except AttributeError:
- try:
- r.feeble_things = skip_result
- except AttributeError:
- pass
- else:
- r.feeble_things += skip_result
- return t, r
-
- skip_result = None
-
- # terminal symbols
-
- if thing is None or type(thing) == FunctionType:
- result = text, None
-
- elif isinstance(thing, Symbol):
- m = type(thing).regex.match(text)
- if m and m.group(0) == str(thing):
- t, r = text[len(thing):], None
- t, skip_result = self._skip(t)
- result = t, r
- update_pos(text, t, pos)
- else:
- result = text, syntax_error("expecting " + repr(thing))
-
- elif isinstance(thing, (RegEx, _RegEx)):
- m = thing.match(text)
- if m:
- t, r = text[len(m.group(0)):], m.group(0)
- t, skip_result = self._skip(t)
- result = t, r
- update_pos(text, t, pos)
- else:
- result = text, syntax_error("expecting match on "
- + thing.pattern)
-
- elif isinstance(thing, (str, Literal)):
- if text.startswith(str(thing)):
- t, r = text[len(str(thing)):], None
- t, skip_result = self._skip(t)
- result = t, r
- update_pos(text, t, pos)
- else:
- result = text, syntax_error("expecting " + repr(thing))
-
- elif _issubclass(thing, Symbol):
- m = thing.regex.match(text)
- if m:
- result = None
- try:
- thing.grammar
- except AttributeError:
- pass
- else:
- if thing.grammar is None:
- pass
- elif isinstance(thing.grammar, Enum):
- if not m.group(0) in thing.grammar:
- result = text, syntax_error(repr(m.group(0))
- + " is not a member of " + repr(thing.grammar))
- else:
- raise GrammarValueError(
- "Symbol " + type(thing).__name__
- + " has a grammar which is not an Enum: "
- + repr(thing.grammar))
- if not result:
- t, r = text[len(m.group(0)):], thing(m.group(0))
- t, skip_result = self._skip(t)
- result = t, r
- update_pos(text, t, pos)
- else:
- result = text, syntax_error("expecting " + thing.__name__)
-
- # non-terminal constructs
-
- elif isinstance(thing, attr.Class):
- t, r = self._parse(text, thing.thing, pos)
- if type(r) == SyntaxError:
- if thing.subtype == "Flag":
- result = t, attr(thing.name, False)
- else:
- result = text, r
- else:
- if thing.subtype == "Flag":
- result = t, attr(thing.name, True)
- else:
- result = t, attr(thing.name, r)
-
- elif isinstance(thing, (tuple, Concat)):
- if self.keep_feeble_things:
- L = List()
- else:
- L = []
- t = text
- flag = True
- _min, _max = 1, 1
- contiguous = self._contiguous
- omit = False
- for e in thing:
- if type(e) == int:
- if e < -6:
- raise GrammarValueError(
- "illegal cardinality value in grammar: " + str(e))
- if e == -6:
- omit = True
- elif e == -5:
- self._contiguous = False
- t, skip_result = self._skip(t)
- if self.keep_feeble_things and skip_result:
- try:
- L.feeble_things
- except AttributeError:
- try:
- L.feeble_things = skip_result
- except AttributeError:
- pass
- else:
- L.feeble_things += skip_result
- elif e == -4:
- self._contiguous = True
- elif e == -3:
- pass
- elif e == -2:
- _min, _max = 1, sys.maxsize
- elif e == -1:
- _min, _max = 0, sys.maxsize
- elif e == 0:
- _min, _max = 0, 1
- else:
- _min, _max = e, e
- continue
- for i in range(_max):
- t2, r = self._parse(t, e, pos)
- if type(r) == SyntaxError:
- i -= 1
- break
- elif omit:
- t = t2
- r = None
- else:
- t = t2
- if r is not None:
- if type(r) is list:
- L.extend(r)
- else:
- L.append(r)
- if i+1 < _min:
- if type(r) != SyntaxError:
- r = syntax_error("expecting " + str(_min)
- + " occurrence(s) of " + repr(e)
- + " (" + str(i+1) + " found)")
- flag = False
- break
- _min, _max = 1, 1
- omit = False
- if flag:
- if self._contiguous and not contiguous:
- self._contiguous = False
- t, skip_result = self._skip(t)
- if self.keep_feeble_things and skip_result:
- try:
- L.feeble_things
- except AttributeError:
- try:
- L.feeble_things = skip_result
- except AttributeError:
- pass
- else:
- L.feeble_things += skip_result
- if len(L) > 1 or how_many(thing) > 1:
- result = t, L
- elif not L:
- if not self.keep_feeble_things:
- return t, None
- try:
- L.feeble_things
- except AttributeError:
- return t, None
- if len(L.feeble_things):
- return t, L
- else:
- return t, None
- else:
- if self.keep_feeble_things:
- try:
- L.feeble_things
- except AttributeError:
- pass
- else:
- if L.feeble_things:
- try:
- L[0].feeble_things
- except AttributeError:
- try:
- L[0].feeble_things = L.feeble_things
- except AttributeError:
- pass
- else:
- L[0].feeble_things = L.feeble_things + \
- L[0].feeble_things
- result = t, L[0]
- else:
- result = text, r
- self._contiguous = contiguous
-
- elif isinstance(thing, list):
- found = False
- for e in thing:
- try:
- t, r = self._parse(text, e, pos)
- if type(r) != SyntaxError:
- found = True
- break
- except GrammarValueError:
- raise
- except ValueError:
- pass
- if found:
- result = t, r
- else:
- result = text, syntax_error("expecting one of " + repr(thing))
-
- elif _issubclass(thing, Namespace):
- t, r = self._parse(text, thing.grammar, pos)
- if type(r) != SyntaxError:
- if isinstance(r, thing):
- result = t, r
- else:
- obj = thing()
- for e in r:
- if type(e) == attr.Class:
- setattr(obj, e.name, e.thing)
- else:
- try:
- obj[e.name] = e
- except AttributeError:
- obj[None] = e
-
- try:
- obj.polish()
- except AttributeError:
- pass
- result = t, obj
- else:
- result = text, r
-
- elif _issubclass(thing, list):
- try:
- g = thing.grammar
- except AttributeError:
- g = csl(Symbol)
- t, r = self._parse(text, g, pos)
- if type(r) != SyntaxError:
- if isinstance(r, thing):
- result = t, r
- else:
- obj = thing()
- if type(r) == list:
- for e in r:
- if type(e) == attr.Class:
- setattr(obj, e.name, e.thing)
- else:
- obj.append(e)
- else:
- if type(r) == attr.Class:
- setattr(obj, r.name, r.thing)
- else:
- obj.append(r)
- try:
- obj.polish()
- except AttributeError:
- pass
- result = t, obj
- else:
- result = text, r
-
- elif _issubclass(thing, object):
- try:
- g = thing.grammar
- except AttributeError:
- g = word
- t, r = self._parse(text, g, pos)
- if type(r) != SyntaxError:
- if isinstance(r, thing):
- result = t, r
- else:
- try:
- if type(r) == list:
- L, a = [], []
- for e in r:
- if type(e) == attr.Class:
- a.append(e)
- else:
- L.append(e)
- if L:
- lg = how_many(thing.grammar)
- if lg == 0:
- obj = None
- elif lg == 1:
- obj = thing(L[0])
- else:
- obj = thing(L)
- else:
- obj = thing()
- for e in a:
- setattr(obj, e.name, e.thing)
- else:
- if type(r) == attr.Class:
- obj = thing()
- setattr(obj, r.name, r.thing)
- else:
- if r is None:
- obj = thing()
- else:
- obj = thing(r)
- except TypeError as t:
- L = list(t.args)
- L[0] = thing.__name__ + ": " + L[0]
- t.args = tuple(L)
- raise t
- try:
- obj.polish()
- except AttributeError:
- pass
- result = t, obj
- else:
- result = text, r
-
- else:
- raise GrammarTypeError("in grammar: " + repr(thing))
-
- if pos:
- if type(result[1]) == SyntaxError:
- pos[0] = current_pos[0]
- pos[1] = current_pos[1]
- self.last_error = result[1]
- else:
- try:
- result[1].position_in_text = current_pos
- except AttributeError:
- pass
-
- if self.keep_feeble_things and skip_result:
- try:
- result[1].feeble_things
- except AttributeError:
- try:
- result[1].feeble_things = skip_result
- except AttributeError:
- pass
- else:
- result[1].feeble_things += skip_result
-
- try:
- self._memory[id(thing)]
- except KeyError:
- self._memory[id(thing)] = { text: result }
- else:
- self._memory[id(thing)][text] = result
-
- return result
-
- def compose(self, thing, grammar=None, attr_of=None):
- """Compose text using thing with grammar.
-
- Arguments:
- thing thing containing other things with grammar
- grammar grammar to use for composing thing
- default: type(thing).grammar
- attr_of if composing the value of an attribute, this
- is a reference to the thing where this value
- is an attribute of; None if this is not an
- attribute value
-
- Returns text
-
- Raises:
- ValueError if thing does not match grammar
- GrammarTypeError
- if grammar contains an object of unkown type
- GrammarValueError
- if grammar contains an illegal cardinality value
- """
- if __debug__:
- # make sure that we're not having this typing error
- compose = None
-
- def terminal_indent(do_blank=False):
- self._got_regex = False
- if self._got_endl:
- result = self.indent * self.indention_level
- self._got_endl = False
- return result
- elif do_blank and self.whitespace:
- if self._contiguous or not self.autoblank:
- return ""
- else:
- return blank(thing, self)
- else:
- return ""
-
- try:
- thing.compose
- except AttributeError:
- pass
- else:
- return terminal_indent() + thing.compose(self, attr_of=attr_of)
-
- if not grammar:
- try:
- grammar = type(thing).grammar
- except AttributeError:
- if isinstance(thing, Symbol):
- grammar = type(thing).regex
- elif isinstance(thing, list):
- grammar = csl(Symbol)
- else:
- grammar = word
- else:
- if isinstance(thing, Symbol):
- grammar = type(thing).regex
-
- if grammar is None:
- result = ""
-
- elif type(grammar) == FunctionType:
- if grammar == endl:
- result = endl(thing, self)
- self._got_endl = True
- elif grammar == blank:
- result = terminal_indent() + blank(thing, self)
- else:
- result = self.compose(thing, grammar(thing, self))
-
- elif isinstance(grammar, (RegEx, _RegEx)):
- m = grammar.match(str(thing))
- if m:
- result = terminal_indent(do_blank=self._got_regex) + str(thing)
- else:
- raise ValueError(repr(thing) + " does not match "
- + grammar.pattern)
- self._got_regex = True
-
- elif isinstance(grammar, Keyword):
- result = terminal_indent(do_blank=self._got_regex) + str(grammar)
- self._got_regex = True
-
- elif isinstance(grammar, (str, int, Literal)):
- result = terminal_indent() + str(grammar)
-
- elif isinstance(grammar, Enum):
- if thing in grammar:
- if isinstance(thing, Keyword):
- result = terminal_indent(do_blank=self._got_regex) + str(thing)
- self._got_regex = True
- else:
- result = terminal_indent() + str(thing)
- else:
- raise ValueError(repr(thing) + " is not in " + repr(grammar))
-
- elif isinstance(grammar, attr.Class):
- if grammar.subtype == "Flag":
- if getattr(thing, grammar.name):
- result = self.compose(thing, grammar.thing, attr_of=thing)
- else:
- result = terminal_indent()
- else:
- result = self.compose(getattr(thing, grammar.name),
- grammar.thing, attr_of=thing)
-
- elif isinstance(grammar, (tuple, list)):
- def compose_tuple(thing, things, grammar):
- text = []
- multiple, card = 1, 1
- indenting = 0
- if isinstance(grammar, (tuple, Concat)):
- # concatenation
- for g in grammar:
- if g is None:
- multiple = 1
- if self.indenting:
- self.indention_level -= indenting
- self.indenting = 0
- elif type(g) == int:
- if g < -6:
- raise GrammarValueError(
- "illegal cardinality value in grammar: "
- + str(g))
- card = g
- if g in (-2, -1):
- multiple = sys.maxsize
- elif g in (-5, -4, -3, 0):
- multiple = 1
- if g == -3:
- self.indention_level += 1
- indenting += 1
- elif g == -6:
- multiple = 0
- else:
- multiple = g
- else:
- passes = 0
- try:
- for r in range(multiple):
- if isinstance(g, (str, Symbol, Literal)):
- text.append(self.compose(thing, g))
- if card < 1:
- break
- elif isinstance(g, FunctionType):
- text.append(self.compose(thing, g))
- if card < 1:
- break
- elif isinstance(g, attr.Class):
- text.append(self.compose(getattr(thing,
- g.name), g.thing, attr_of=thing))
- if card < 1:
- break
- elif isinstance(g, (tuple, list)):
- text.append(compose_tuple(thing, things, g))
- if not things:
- break
- else:
- text.append(self.compose(things.pop(), g))
- passes += 1
- except (IndexError, ValueError):
- if card == -2:
- if passes < 1:
- raise ValueError(repr(g)
- + " has to be there at least once")
- elif card > 0:
- if passes < multiple:
- raise ValueError(repr(g)
- + " has to be there exactly "
- + str(multiple) + " times")
- multiple = 1
- if indenting:
- self.indention_level -= indenting
- indenting = 0
- return ''.join(text)
- else:
- # options
- for g in grammar:
- try:
- if isinstance(g, (str, Symbol, Literal)):
- return self.compose(thing, g)
- elif isinstance(g, FunctionType):
- return self.compose(thing, g)
- elif isinstance(g, attr.Class):
- return self.compose(getattr(thing, g.name), g.thing)
- elif isinstance(g, (tuple, list)):
- return compose_tuple(thing, things, g)
- else:
- try:
- text = self.compose(things[-1], g)
- except Exception as e:
- raise e
- things.pop()
- return text
- except GrammarTypeError:
- raise
- except AttributeError:
- pass
- except KeyError:
- pass
- except TypeError:
- pass
- except ValueError:
- pass
- raise ValueError("none of the options in " + repr(grammar)
- + " found")
-
- if isinstance(thing, Namespace):
- L = [e for e in thing.values()]
- L.reverse()
- elif isinstance(thing, list):
- L = thing[:]
- L.reverse()
- else:
- L = [thing]
- result = compose_tuple(thing, L, grammar)
-
- elif _issubclass(grammar, object):
- if isinstance(thing, grammar):
- try:
- grammar.grammar
- except AttributeError:
- if _issubclass(grammar, Symbol):
- result = self.compose(thing, grammar.regex)
- else:
- result = self.compose(thing)
- else:
- result = self.compose(thing, grammar.grammar)
- else:
- if grammar == Symbol and isinstance(thing, str):
- result = self.compose(str(thing), Symbol.regex)
- else:
- raise ValueError(repr(thing) + " is not a " + repr(grammar))
-
- else:
- raise GrammarTypeError("in grammar: " + repr(grammar))
-
- return result
diff --git a/pypeg2/test/__init__.py b/pypeg2/test/__init__.py
deleted file mode 100644
index e69de29..0000000
diff --git a/pypeg2/test/test_pypeg2.py b/pypeg2/test/test_pypeg2.py
deleted file mode 100644
index 7deee1c..0000000
--- a/pypeg2/test/test_pypeg2.py
+++ /dev/null
@@ -1,377 +0,0 @@
-from __future__ import unicode_literals
-
-import unittest
-import pypeg2
-import re
-
-class GrammarTestCase1(unittest.TestCase):
- def runTest(self):
- x = pypeg2.some("thing")
- y = pypeg2.maybe_some("thing")
- z = pypeg2.optional("hello", "world")
- self.assertEqual(x, (-2, "thing"))
- self.assertEqual(y, (-1, "thing"))
- self.assertEqual(z, (0, ("hello", "world")))
-
-class GrammarTestCase2(unittest.TestCase):
- def runTest(self):
- L1 = pypeg2.csl("thing")
- L2 = pypeg2.csl("hello", "world")
- self.assertEqual(L1, ("thing", -1, (",", pypeg2.blank, "thing")))
- self.assertEqual(L2, ("hello", "world", -1, (",", pypeg2.blank, "hello", "world")))
-
-class ParserTestCase(unittest.TestCase): pass
-
-class TypeErrorTestCase(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(pypeg2.GrammarTypeError):
- parser.parse("hello, world", 23)
-
-class ParseTerminalStringTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", "hello")
- self.assertEqual(r, (", world", None))
-
-class ParseTerminalStringTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", "world")
-
-class ParseKeywordTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hallo, world", pypeg2.K("hallo"))
- self.assertEqual(r, (", world", None))
- pypeg2.Keyword.table[pypeg2.K("hallo")]
-
-class ParseKeywordTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", pypeg2.K("werld"))
- pypeg2.Keyword.table[pypeg2.K("werld")]
-
-class ParseKeywordTestCase3(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse(", world", pypeg2.K("hallo"))
- pypeg2.Keyword.table[pypeg2.K("hallo")]
-
-class ParseRegexTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", re.compile(r"h.[lx]l\S", re.U))
- self.assertEqual(r, (", world", "hello"))
-
-class ParseRegexTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", re.compile(r"\d", re.U))
-
-class ParseSymbolTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", pypeg2.Symbol)
- self.assertEqual(r, (", world", pypeg2.Symbol("hello")))
-
-class ParseSymbolTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse(", world", pypeg2.Symbol)
-
-class ParseAttributeTestCase(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", pypeg2.attr("some", pypeg2.Symbol))
- self.assertEqual(
- r,
- (
- ', world',
- pypeg2.attr.Class(name='some', thing=pypeg2.Symbol('hello'),
- subtype=None)
- )
- )
-
-class ParseTupleTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", (pypeg2.name(), ",", pypeg2.name()))
- self.assertEqual(
- r,
- (
- '',
- [
- pypeg2.attr.Class(name='name',
- thing=pypeg2.Symbol('hello'), subtype=None),
- pypeg2.attr.Class(name='name',
- thing=pypeg2.Symbol('world'), subtype=None)
- ]
- )
- )
-
-class ParseTupleTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(ValueError):
- parser.parse("hello, world", (-23, "x"))
-
-class ParseSomeTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", pypeg2.some(re.compile(r"\w", re.U)))
- self.assertEqual(r, (', world', ['h', 'e', 'l', 'l', 'o']))
-
-class ParseSomeTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", pypeg2.some(re.compile(r"\d", re.U)))
-
-class ParseMaybeSomeTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", pypeg2.maybe_some(re.compile(r"\w", re.U)))
- self.assertEqual(r, (', world', ['h', 'e', 'l', 'l', 'o']))
-
-class ParseMaybeSomeTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", pypeg2.maybe_some(re.compile(r"\d", re.U)))
- self.assertEqual(r, ('hello, world', []))
-
-class ParseCardinalityTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", (5, re.compile(r"\w", re.U)))
- self.assertEqual(r, (', world', ['h', 'e', 'l', 'l', 'o']))
-
-class ParseCardinalityTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", (6, re.compile(r"\w", re.U)))
-
-class ParseOptionsTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", [re.compile(r"\d+", re.U), pypeg2.word])
- self.assertEqual(r, (', world', 'hello'))
-
-class ParseOptionsTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", ["x", "y"])
-
-class ParseListTestCase1(ParserTestCase):
- class Chars(pypeg2.List):
- grammar = pypeg2.some(re.compile(r"\w", re.U)), pypeg2.attr("comma", ",")
-
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", ParseListTestCase1.Chars)
- self.assertEqual(r, (
- 'world',
- ParseListTestCase1.Chars(['h', 'e', 'l', 'l', 'o']))
- )
- self.assertEqual(r[1].comma, None)
-
-class ParseListTestCase2(ParserTestCase):
- class Digits(pypeg2.List):
- grammar = pypeg2.some(re.compile(r"\d", re.U))
-
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- r = parser.parse("hello, world", ParseListTestCase2.Digits)
-
-class ParseClassTestCase1(ParserTestCase):
- class Word(str):
- grammar = pypeg2.word
-
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", ParseClassTestCase1.Word)
- self.assertEqual(type(r[1]), ParseClassTestCase1.Word)
- self.assertEqual(r[1], "hello")
-
-class ParseClassTestCase2(ParserTestCase):
- class Word(str):
- grammar = pypeg2.word, pypeg2.attr("comma", ",")
- def __init__(self, data):
- self.polished = False
- def polish(self):
- self.polished = True
-
- def runTest(self):
- parser = pypeg2.Parser()
- r = parser.parse("hello, world", ParseClassTestCase2.Word)
- self.assertEqual(type(r[1]), ParseClassTestCase2.Word)
- self.assertEqual(r[1], "hello")
- self.assertTrue(r[1].polished)
- self.assertEqual(r[1].comma, None)
-
-class Parm(object):
- grammar = pypeg2.name(), "=", pypeg2.attr("value", int)
-
-class Parms(pypeg2.Namespace):
- grammar = (pypeg2.csl(Parm), pypeg2.flag("fullstop", "."),
- pypeg2.flag("semicolon", ";"))
-
-class ParseNLTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- parser.comment = pypeg2.comment_c
- t, parms = parser.parse("x=23 /* Illuminati */, y=42 /* the answer */;", Parms)
- self.assertEqual(parms["x"].value, 23)
- self.assertEqual(parms["y"].value, 42)
- self.assertEqual(parms.fullstop, False)
- self.assertEqual(parms.semicolon, True)
-
-class EnumTest(pypeg2.Symbol):
- grammar = pypeg2.Enum( pypeg2.K("int"), pypeg2.K("long") )
-
-class ParseEnumTestCase1(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- t, r = parser.parse("int", EnumTest)
- self.assertEqual(r, "int")
-
-class ParseEnumTestCase2(ParserTestCase):
- def runTest(self):
- parser = pypeg2.Parser()
- with self.assertRaises(SyntaxError):
- t, r = parser.parse("float", EnumTest)
-
-class ParseInvisibleTestCase(ParserTestCase):
- class C1(str):
- grammar = pypeg2.ignore("!"), pypeg2.restline
- def runTest(self):
- r = pypeg2.parse("!all", type(self).C1)
- self.assertEqual(str(r), "all")
- self.assertEqual(r._ignore1, None)
-
-class ParseOmitTestCase(ParserTestCase):
- def runTest(self):
- r = pypeg2.parse("hello", pypeg2.omit(pypeg2.word))
- self.assertEqual(r, None)
-
-class ComposeTestCase(unittest.TestCase): pass
-
-class ComposeString(object):
- grammar = "something"
-
-class ComposeStringTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeString()
- t = pypeg2.compose(x)
- self.assertEqual(t, "something")
-
-class ComposeRegex(str):
- grammar = pypeg2.word
-
-class ComposeRegexTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeRegex("something")
- t = pypeg2.compose(x)
- self.assertEqual(t, "something")
-
-class ComposeKeyword(object):
- grammar = pypeg2.K("hallo")
-
-class ComposeKeywordTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeKeyword()
- t = pypeg2.compose(x)
- self.assertEqual(t, "hallo")
-
-class ComposeSymbol(pypeg2.Symbol): pass
-
-class ComposeSymbolTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeSymbol("hello")
- t = pypeg2.compose(x)
- self.assertEqual(t, "hello")
-
-class ComposeAttribute(object):
- grammar = pypeg2.name()
-
-class ComposeAttributeTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeAttribute()
- x.name = pypeg2.Symbol("hello")
- t = pypeg2.compose(x)
- self.assertEqual(t, "hello")
-
-class ComposeFlag(object):
- grammar = pypeg2.flag("mark", "MARK")
-
-class ComposeFlagTestCase1(ComposeTestCase):
- def runTest(self):
- x = ComposeFlag()
- x.mark = True
- t = pypeg2.compose(x)
- self.assertEqual(t, "MARK")
-
-class ComposeFlagTestCase2(ComposeTestCase):
- def runTest(self):
- x = ComposeFlag()
- x.mark = False
- t = pypeg2.compose(x)
- self.assertEqual(t, "")
-
-class ComposeTuple(pypeg2.List):
- grammar = pypeg2.csl(pypeg2.word)
-
-class ComposeTupleTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeTuple(["hello", "world"])
- t = pypeg2.compose(x)
- self.assertEqual(t, "hello, world")
-
-class ComposeList(str):
- grammar = [ re.compile(r"\d+", re.U), pypeg2.word ]
-
-class ComposeListTestCase(ComposeTestCase):
- def runTest(self):
- x = ComposeList("hello")
- t = pypeg2.compose(x)
- self.assertEqual(t, "hello")
-
-class ComposeIntTestCase(ComposeTestCase):
- def runTest(self):
- x = pypeg2.compose(23, int)
- self.assertEqual(x, "23")
-
-class C2(str):
- grammar = pypeg2.attr("some", "!"), pypeg2.restline
-
-class ComposeInvisibleTestCase(ParserTestCase):
- def runTest(self):
- r = pypeg2.parse("!all", C2)
- self.assertEqual(str(r), "all")
- self.assertEqual(r.some, None)
- t = pypeg2.compose(r, C2)
- self.assertEqual(t, "!all")
-
-class ComposeOmitTestCase(ParserTestCase):
- def runTest(self):
- t = pypeg2.compose('hello', pypeg2.omit(pypeg2.word))
- self.assertEqual(t, "")
-
-class CslPython32Compatibility(ParserTestCase):
- def runTest(self):
- try:
- g = eval("pypeg2.csl('hello', 'world', separator=';')")
- except TypeError:
- return
- self.assertEqual(g, ("hello", "world", -1, (";", pypeg2.blank, "hello", "world")))
-
-if __name__ == '__main__':
- unittest.main()
diff --git a/pypeg2/test/test_xmlast.py b/pypeg2/test/test_xmlast.py
deleted file mode 100644
index 0aed1ac..0000000
--- a/pypeg2/test/test_xmlast.py
+++ /dev/null
@@ -1,110 +0,0 @@
-from __future__ import unicode_literals
-try:
- str = unicode
-except NameError:
- pass
-
-import unittest
-import re, sys
-import pypeg2, pypeg2.xmlast
-
-class Another(object):
- grammar = pypeg2.name(), "=", pypeg2.attr("value")
-
-class Something(pypeg2.List):
- grammar = pypeg2.name(), pypeg2.some(Another), str
-
-class Thing2etreeTestCase1(unittest.TestCase):
- def runTest(self):
- s = Something()
- s.name = "hello"
- a1 = Another()
- a1.name = "bla"
- a1.value = "blub"
- a2 = Another()
- a2.name = "foo"
- a2.value = "bar"
- s.append(a1)
- s.append(a2)
- s.append("hello, world")
-
- root = pypeg2.xmlast.create_tree(s)
-
- self.assertEqual(root.tag, "Something")
- self.assertEqual(root.attrib["name"], "hello")
-
- try:
- import lxml
- except ImportError:
- self.assertEqual(pypeg2.xmlast.etree.tostring(root), b'hello, world')
- else:
- self.assertEqual(pypeg2.xmlast.etree.tostring(root), b'hello, world')
-
-class SomethingElse(pypeg2.Namespace):
- grammar = pypeg2.name(), pypeg2.some(Another)
-
-class Thing2etreeTestCase2(unittest.TestCase):
- def runTest(self):
- s = SomethingElse()
- s.name = "hello"
- a1 = Another()
- a1.name = "bla"
- a1.value = "blub"
- a2 = Another()
- a2.name = "foo"
- a2.value = "bar"
- s[a1.name] = a1
- s[a2.name] = a2
-
- root = pypeg2.xmlast.create_tree(s)
-
- self.assertEqual(root.tag, "SomethingElse")
- self.assertEqual(root.attrib["name"], "hello")
-
- try:
- import lxml
- except ImportError:
- self.assertEqual(pypeg2.xmlast.etree.tostring(root), b'')
- else:
- self.assertEqual(pypeg2.xmlast.etree.tostring(root), b'')
-
-class Thing2XMLTestCase3(unittest.TestCase):
- class C1(str):
- grammar = pypeg2.ignore("!"), pypeg2.restline
- def runTest(self):
- r = pypeg2.parse("!all", type(self).C1)
- xml = pypeg2.xmlast.thing2xml(r)
- self.assertEqual(xml, b"all")
-
-class Key(str):
- grammar = pypeg2.name(), "=", pypeg2.restline
-
-class XML2ThingTestCase1(unittest.TestCase):
- def runTest(self):
- xml = b'bar'
- thing = pypeg2.xmlast.xml2thing(xml, globals())
- self.assertEqual(thing.name, pypeg2.Symbol("foo"))
- self.assertEqual(thing, "bar")
-
-class Instruction(str): pass
-
-class Parameter(object):
- grammar = pypeg2.attr("typing", str), pypeg2.name()
-
-class Parameters(pypeg2.Namespace):
- grammar = pypeg2.optional(pypeg2.csl(Parameter))
-
-class Function(pypeg2.List):
- grammar = pypeg2.name(), pypeg2.attr("parms", Parameters), "{", pypeg2.maybe_some(Instruction), "}"
-
-class XML2ThingTestCase2(unittest.TestCase):
- def runTest(self):
- xml = b'do_this'
- f = pypeg2.xmlast.xml2thing(xml, globals())
- self.assertEqual(f.name, pypeg2.Symbol("f"))
- self.assertEqual(f.parms["a"].name, pypeg2.Symbol("a"))
- self.assertEqual(f.parms["a"].typing, pypeg2.Symbol("int"))
- self.assertEqual(f[0], "do_this")
-
-if __name__ == '__main__':
- unittest.main()
diff --git a/pypeg2/xmlast.py b/pypeg2/xmlast.py
deleted file mode 100644
index b02882f..0000000
--- a/pypeg2/xmlast.py
+++ /dev/null
@@ -1,210 +0,0 @@
-"""
-XML AST generator
-
-pyPEG parsing framework
-
-Copyleft 2012, Volker Birk.
-This program is under GNU General Public License 2.0.
-"""
-
-
-from __future__ import unicode_literals
-try:
- str = unicode
-except NameError:
- pass
-
-
-__version__ = 2.15
-__author__ = "Volker Birk"
-__license__ = "This program is under GNU General Public License 2.0."
-__url__ = "http://fdik.org/pyPEG"
-
-
-try:
- import lxml
- from lxml import etree
-except ImportError:
- import xml.etree.ElementTree as etree
-
-if __debug__:
- import warnings
-import pypeg2
-
-
-def create_tree(thing, parent=None, object_names=False):
- """Create an XML etree from a thing.
-
- Arguments:
- thing thing to interpret
- parent etree.Element to put subtree into
- default: create a new Element tree
- object_names experimental feature: if True tag names are object
- names instead of types
-
- Returns:
- etree.Element instance created
- """
-
- try:
- grammar = type(thing).grammar
- except AttributeError:
- if isinstance(thing, list):
- grammar = pypeg2.csl(pypeg2.name())
- else:
- grammar = pypeg2.word
-
- name = type(thing).__name__
-
- if object_names:
- try:
- name = str(thing.name)
- name = name.replace(" ", "_")
- except AttributeError:
- pass
-
- if parent is None:
- me = etree.Element(name)
- else:
- me = etree.SubElement(parent, name)
-
- for e in pypeg2.attributes(grammar):
- if object_names and e.name == "name":
- if name != type(thing).__name__:
- continue
- key, value = e.name, getattr(thing, e.name, None)
- if value is not None:
- if pypeg2._issubclass(e.thing, (str, int, pypeg2.Literal)) \
- or type(e.thing) == pypeg2._RegEx:
- me.set(key, str(value))
- else:
- create_tree(value, me, object_names)
-
- if isinstance(thing, list):
- things = thing
- elif isinstance(thing, pypeg2.Namespace):
- things = thing.values()
- else:
- things = []
-
- last = None
- for t in things:
- if type(t) == str:
- if last is not None:
- last.tail = str(t)
- else:
- me.text = str(t)
- else:
- last = create_tree(t, me, object_names)
-
- if isinstance(thing, str):
- me.text = str(thing)
-
- return me
-
-
-def thing2xml(thing, pretty=False, object_names=False):
- """Create XML text from a thing.
-
- Arguments:
- thing thing to interpret
- pretty True if XML should be indented
- False if XML should be plain
- object_names experimental feature: if True tag names are object
- names instead of types
-
- Returns:
- bytes with encoded XML
- """
-
- tree = create_tree(thing, None, object_names)
- try:
- if lxml:
- return etree.tostring(tree, pretty_print=pretty)
- except NameError:
- if __debug__:
- if pretty:
- warnings.warn("lxml is needed for pretty printing",
- ImportWarning)
- return etree.tostring(tree)
-
-
-def create_thing(element, symbol_table):
- """Create thing from an XML element.
-
- Arguments:
- element etree.Element instance to read
- symbol_table symbol table where the classes can be found
-
- Returns:
- thing created
- """
-
- C = symbol_table[element.tag]
- if element.text:
- thing = C(element.text)
- else:
- thing = C()
-
- subs = iter(element)
- iterated_already = False
-
- try:
- grammar = C.grammar
- except AttributeError:
- pass
- else:
- for e in pypeg2.attributes(grammar):
- key = e.name
- if pypeg2._issubclass(e.thing, (str, int, pypeg2.Literal)) \
- or type(e.thing) == pypeg2._RegEx:
- try:
- value = element.attrib[e.name]
- except KeyError:
- pass
- else:
- setattr(thing, key, e.thing(value))
- else:
- try:
- if not iterated_already:
- iterated_already = True
- sub = next(subs)
- except StopIteration:
- pass
- if sub.tag == e.thing.__name__:
- iterated_already = False
- t = create_thing(sub, symbol_table)
- setattr(thing, key, t)
-
- if issubclass(C, list) or issubclass(C, pypeg2.Namespace):
- try:
- while True:
- if iterated_already:
- iterated_alread = False
- else:
- sub = next(subs)
- t = create_thing(sub, symbol_table)
- if isinstance(thing, pypeg2.List):
- thing.append(t)
- else:
- thing[t.name] = t
- except StopIteration:
- pass
-
- return thing
-
-
-def xml2thing(xml, symbol_table):
- """Create thing from XML text.
-
- Arguments:
- xml bytes with encoded XML
- symbol_table symbol table where the classes can be found
-
- Returns:
- created thing
- """
-
- element = etree.fromstring(xml)
- return create_thing(element, symbol_table)
-
diff --git a/releases/DateCalculator_4-0-1.alfredworkflow b/releases/DateCalculator_4-0-1.alfredworkflow
new file mode 100644
index 0000000..9ef7c36
Binary files /dev/null and b/releases/DateCalculator_4-0-1.alfredworkflow differ
diff --git a/releases/DateCalculator_4-0.alfredworkflow b/releases/DateCalculator_4-0.alfredworkflow
new file mode 100644
index 0000000..9b2f5cf
Binary files /dev/null and b/releases/DateCalculator_4-0.alfredworkflow differ
diff --git a/releases/DateCalculator_4-1.alfredworkflow b/releases/DateCalculator_4-1.alfredworkflow
new file mode 100644
index 0000000..d3ba4a5
Binary files /dev/null and b/releases/DateCalculator_4-1.alfredworkflow differ
diff --git a/82367634-DAB1-4D69-BC58-77B4F9322402.png b/src/82367634-DAB1-4D69-BC58-77B4F9322402.png
similarity index 100%
rename from 82367634-DAB1-4D69-BC58-77B4F9322402.png
rename to src/82367634-DAB1-4D69-BC58-77B4F9322402.png
diff --git a/B222BD5C-5A0E-4EC1-9D9E-E308621BC7C8.png b/src/B222BD5C-5A0E-4EC1-9D9E-E308621BC7C8.png
similarity index 100%
rename from B222BD5C-5A0E-4EC1-9D9E-E308621BC7C8.png
rename to src/B222BD5C-5A0E-4EC1-9D9E-E308621BC7C8.png
diff --git a/anniversary_list.py b/src/anniversary_list.py
similarity index 100%
rename from anniversary_list.py
rename to src/anniversary_list.py
diff --git a/date_calculator.py b/src/date_calculator.py
similarity index 98%
rename from date_calculator.py
rename to src/date_calculator.py
index 0710de4..0b2532c 100644
--- a/date_calculator.py
+++ b/src/date_calculator.py
@@ -1,8 +1,8 @@
from collections import Counter
from datetime import timedelta
-
+from datetime import datetime
import arrow
-from arrow.arrow import datetime
+# from arrow.arrow import datetime
from date_format_mappings import DEFAULT_WORKFLOW_SETTINGS, \
TIME_CALCULATION, VALID_FORMAT_OPTIONS, MAX_LOOKAHEAD_ATTEMPTS
from date_formatters import DATE_FORMATTERS_MAP
@@ -206,7 +206,8 @@ def valid_command_format(command_format):
repeats_search = Counter(command_format)
repeated_items = filter(lambda x: x > 1, repeats_search.values())
- if len(repeated_items) == 0:
+ #if len(repeated_items) == 0:
+ if len(list(repeated_items)) == 0:
return True
else:
return False
@@ -237,6 +238,7 @@ def calculate_time_interval(interval, start_datetime, end_datetime):
datetime_list = arrow.Arrow.range(interval, start_datetime, end_datetime)
if datetime_list:
+ datetime_list = list (datetime_list)
return len(datetime_list) - 1, datetime_list[-1]
else:
return 0, start_datetime
diff --git a/date_format_list.py b/src/date_format_list.py
similarity index 100%
rename from date_format_list.py
rename to src/date_format_list.py
diff --git a/date_format_mappings.py b/src/date_format_mappings.py
similarity index 95%
rename from date_format_mappings.py
rename to src/date_format_mappings.py
index e9e741f..0cc7ae9 100644
--- a/date_format_mappings.py
+++ b/src/date_format_mappings.py
@@ -16,11 +16,12 @@ def fill_minutes(date_time_str):
DATE_MAPPINGS = {
'dd-mm-yy': {'name': 'short UK date (-)', 'date-format': '%d-%m-%y', 'regex': '\d{2}-\d{2}-\d{2}'},
+ 'd.m.yyyy': {'name': '🇮🇹 format (.)', 'date-format': '%-d.%-m.%Y', 'regex': '\d{1,2}\.\d{1,2}\.\d{4}'},
'dd-mm-yyyy': {'name': 'long UK date (-)', 'date-format': '%d-%m-%Y', 'regex': '\d{2}-\d{2}-\d{4}'},
'dd/mm/yy': {'name': 'short UK date (/)', 'date-format': '%d/%m/%y', 'regex': '\d{2}/\d{2}/\d{2}'},
'dd/mm/yyyy': {'name': 'long UK date (/)', 'date-format': '%d/%m/%Y', 'regex': '\d{2}/\d{2}/\d{4}'},
'dd.mm.yy': {'name': 'short UK date (.)', 'date-format': '%d.%m.%y', 'regex': '\d{2}\.\d{2}\.\d{2}'},
- 'dd.mm.yyyy': {'name': 'long UK date (.)', 'date-format': '%d.%m.%Y', 'regex': '\d{2}\.\d{2}\.\d{4}'},
+ #'dd.mm.yyyy': {'name': 'long UK date (.)', 'date-format': '%d.%m.%Y', 'regex': '\d{2}\.\d{2}\.\d{4}'},
'mm-dd-yy': {'name': 'short US date (-)', 'date-format': '%m-%d-%y', 'regex': '\d{2}-\d{2}-\d{2}'},
'mm-dd-yyyy': {'name': 'long US date (-)', 'date-format': '%m-%d-%Y', 'regex': '\d{2}-\d{2}-\d{4}'},
'mm/dd/yy': {'name': 'short US date (/)', 'date-format': '%m/%d/%y', 'regex': '\d{2}/\d{2}/\d{2}'},
diff --git a/date_formatters.py b/src/date_formatters.py
similarity index 100%
rename from date_formatters.py
rename to src/date_formatters.py
diff --git a/date_functions.py b/src/date_functions.py
similarity index 77%
rename from date_functions.py
rename to src/date_functions.py
index a7f0960..506e999 100644
--- a/date_functions.py
+++ b/src/date_functions.py
@@ -1,8 +1,9 @@
# This file contains all the functions that the workflow
# uses for specialised dates.
from math import floor
-
-from arrow.arrow import datetime, timedelta
+from datetime import datetime
+from datetime import timedelta
+#from arrow.arrow import datetime, timedelta
# The DAY_MAP is specific to relative delta
from date_format_mappings import DATE_MAPPINGS, TIME_MAPPINGS, DATE_TIME_MAPPINGS
from dateutil.relativedelta import relativedelta, MO, TU, WE, TH, FR, SA, SU
@@ -281,144 +282,71 @@ def martin_luther_king_day(settings):
{'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR))},
- "wkdy":
-
- {'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR))},
-
"weekends":
{'days': {'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(SA, SU))},
- "wknd":
- {'days': {'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(SA, SU))},
-
"mondays":
{'days': {'Monday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=MO)},
- "mon":
- {'days': {'Monday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=MO)},
-
"tuesdays":
- {'days': {'Tuesday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=TU)},
-
- "tue":
- {'days': {'Tuesday'},
+ {'days':{'Tuesday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=TU)},
"wednesdays":
{'days': {'Wednesday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=WE)},
- "wed":
- {'days': {'Wednesday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=WE)},
-
"thursdays":
{'days': {'Thursday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=TH)},
- "thu":
- {'days': {'Thursday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=TH)},
-
"fridays":
{'days': {'Friday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=FR)},
- "fri":
- {'days': {'Friday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=FR)},
-
"saturdays":
{'days': {'Saturday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=SA)},
- "sat":
- {'days': {'Saturday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=SA)},
-
"sundays":
{'days': {'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=SU)},
- "sun":
- {'days': {'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=SU)},
-
"all except weekdays":
{'days': {'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(SA, SU))},
- "xwkdy":
- {'days': {'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(SA, SU))},
-
"all except weekends":
{'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR))},
- "xwknd":
- {'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR))},
-
"all except mondays":
{'days': {'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(TU, WE, TH, FR, SA, SU))},
- "xmon":
- {'days': {'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(TU, WE, TH, FR, SA, SU))},
-
"all except tuesdays":
{'days': {'Monday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, WE, TH, FR, SA, SU))},
- "xtue":
- {'days': {'Monday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, WE, TH, FR, SA, SU))},
-
"all except wednesdays":
{'days': {'Monday', 'Tuesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, TH, FR, SA, SU))},
- "xwed":
- {'days': {'Monday', 'Tuesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, TH, FR, SA, SU))},
-
"all except thursdays":
{'days': {'Monday', 'Tuesday', 'Wednesday', 'Friday', 'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, FR, SA, SU))},
- "xthu":
- {'days': {'Monday', 'Tuesday', 'Wednesday', 'Friday', 'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, FR, SA, SU))},
-
"all except fridays":
{'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Saturday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, SA, SU))},
- "xfri":
- {'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Saturday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, SA, SU))},
-
"all except saturdays":
{'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR, SU))},
- "exsat":
- {'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR, SU))},
-
"all except sundays":
- {'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Sunday'},
- 'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR, SA))},
-
- "exsun":
{'days': {'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Sunday'},
'rule': lambda start, end: rrule(freq=DAILY, dtstart=start, until=end, byweekday=(MO, TU, WE, TH, FR, SA))}
}
diff --git a/date_parser.py b/src/date_parser.py
similarity index 100%
rename from date_parser.py
rename to src/date_parser.py
diff --git a/date_time_format_list.py b/src/date_time_format_list.py
similarity index 96%
rename from date_time_format_list.py
rename to src/date_time_format_list.py
index 73a4df2..7bf3714 100644
--- a/date_time_format_list.py
+++ b/src/date_time_format_list.py
@@ -1,7 +1,8 @@
from __future__ import unicode_literals, print_function
import sys
-from arrow.arrow import datetime
+#from arrow.arrow import datetime
+from datetime import datetime
from versioning import update_settings
from workflow import Workflow
diff --git a/humanfriendly.py b/src/humanfriendly.py
similarity index 100%
rename from humanfriendly.py
rename to src/humanfriendly.py
diff --git a/icon.png b/src/icon.png
similarity index 100%
rename from icon.png
rename to src/icon.png
diff --git a/info.plist b/src/info.plist
similarity index 79%
rename from info.plist
rename to src/info.plist
index dee4831..2dd3fd1 100644
--- a/info.plist
+++ b/src/info.plist
@@ -4,8 +4,6 @@
bundleid
muppet.gate.net.DateCalculator
- category
- Productivity
connections
0D06D18F-E39D-49F3-BF9C-D8919BC950B7
@@ -305,6 +303,8 @@
alfredfiltersresultsmatchmode
0
+ argumenttreatemptyqueryasnil
+
argumenttrimmode
0
argumenttype
@@ -324,7 +324,9 @@
runningsubtext
Loading list . . .
script
- python date_format_list.py
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 date_format_list.py
scriptargtype
0
scriptfile
@@ -343,7 +345,7 @@
uid
B222BD5C-5A0E-4EC1-9D9E-E308621BC7C8
version
- 2
+ 3
config
@@ -353,7 +355,9 @@
escaping
126
script
- python set_date_format.py "{query}"
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 set_date_format.py "{query}"
scriptargtype
0
scriptfile
@@ -376,7 +380,9 @@
escaping
126
script
- python show_date_format.py
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 show_date_format.py
scriptargtype
0
scriptfile
@@ -415,15 +421,31 @@
config
+ alignment
+ 0
+ backgroundcolor
+
+ fadespeed
+ 0
+ fillmode
+ 0
+ font
+
+ ignoredynamicplaceholders
+
largetypetext
{query}
+ textcolor
+
+ wrapat
+ 50
type
alfred.workflow.output.largetype
uid
C0DB0242-54B1-475E-A327-B61C54C7B668
version
- 2
+ 3
config
@@ -432,6 +454,8 @@
alfredfiltersresultsmatchmode
0
+ argumenttreatemptyqueryasnil
+
argumenttrimmode
0
argumenttype
@@ -439,7 +463,7 @@
escaping
126
keyword
- dcalc
+ {var:mainkeyword}
queuedelaycustom
1
queuedelayimmediatelyinitially
@@ -451,7 +475,9 @@
runningsubtext
Calculating . . .
script
- python date_calculator.py "{query}"
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 date_calculator.py "{query}"
scriptargtype
0
scriptfile
@@ -470,7 +496,7 @@
uid
6A04F044-39CB-4830-8CAF-6E471F570AE8
version
- 2
+ 3
config
@@ -479,6 +505,8 @@
clipboardtext
{query}
+ ignoredynamicplaceholders
+
transient
@@ -487,7 +515,7 @@
uid
93F1AC54-E8DD-416A-BA06-74779BDA2668
version
- 2
+ 3
config
@@ -497,7 +525,7 @@
escaping
0
script
- tell application "Alfred 3" to search "dcalc {query}"
+ tell application "Alfred" to search "dcalc {query}"
scriptargtype
0
scriptfile
@@ -562,7 +590,9 @@
escaping
0
script
- python set_anniversary.py "{query}"
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 set_anniversary.py "{query}"
scriptargtype
0
scriptfile
@@ -585,7 +615,7 @@
escaping
0
script
- tell application "Alfred 3" to search "dcalcset list delete {query}"
+ tell application "Alfred" to search "dcalcset list delete {query}"
scriptargtype
0
scriptfile
@@ -607,6 +637,8 @@
alfredfiltersresultsmatchmode
0
+ argumenttreatemptyqueryasnil
+
argumenttrimmode
0
argumenttype
@@ -626,7 +658,9 @@
runningsubtext
Please wait . . .
script
- python anniversary_list.py "{query}"
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 anniversary_list.py "{query}"
scriptargtype
0
scriptfile
@@ -645,7 +679,7 @@
uid
6344C161-C077-4BB5-800B-6BCF7A98F450
version
- 2
+ 3
config
@@ -655,7 +689,7 @@
escaping
0
script
- tell application "Alfred 3" to search "dcalcset list edit {query}"
+ tell application "Alfred" to search "dcalcset list edit {query}"
scriptargtype
0
scriptfile
@@ -678,7 +712,7 @@
escaping
0
script
- tell application "Alfred 3" to search "dcalc {query}"
+ tell application "Alfred" to search "dcalc {query}"
scriptargtype
0
scriptfile
@@ -701,7 +735,7 @@
escaping
0
script
- tell application "Alfred 3" to search "dcalc ^{query}"
+ tell application "Alfred" to search "dcalc ^{query}"
scriptargtype
0
scriptfile
@@ -724,7 +758,7 @@
escaping
127
script
- tell application "Alfred 3" to search "dcalcshow list {query}"
+ tell application "Alfred" to search "dcalcshow list {query}"
scriptargtype
0
scriptfile
@@ -790,6 +824,8 @@
alfredfiltersresultsmatchmode
0
+ argumenttreatemptyqueryasnil
+
argumenttrimmode
0
argumenttype
@@ -809,7 +845,9 @@
runningsubtext
Loading list . . .
script
- python time_format_list.py
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 time_format_list.py
scriptargtype
0
scriptfile
@@ -828,7 +866,7 @@
uid
0D06D18F-E39D-49F3-BF9C-D8919BC950B7
version
- 2
+ 3
config
@@ -838,7 +876,9 @@
escaping
127
script
- python set_time_format.py "{query}"
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 set_time_format.py "{query}"
scriptargtype
0
scriptfile
@@ -903,7 +943,9 @@
escaping
127
script
- python show_time_format.py
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 show_time_format.py
scriptargtype
0
scriptfile
@@ -921,15 +963,31 @@
config
+ alignment
+ 0
+ backgroundcolor
+
+ fadespeed
+ 0
+ fillmode
+ 0
+ font
+
+ ignoredynamicplaceholders
+
largetypetext
{query}
+ textcolor
+
+ wrapat
+ 50
type
alfred.workflow.output.largetype
uid
5F6FEA98-E805-408A-A1F4-A8A5FC49DC81
version
- 2
+ 3
config
@@ -960,7 +1018,9 @@
escaping
127
script
- python set_date_time_format.py "{query}"
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 set_date_time_format.py "{query}"
scriptargtype
0
scriptfile
@@ -982,6 +1042,8 @@
alfredfiltersresultsmatchmode
0
+ argumenttreatemptyqueryasnil
+
argumenttrimmode
0
argumenttype
@@ -1001,7 +1063,9 @@
runningsubtext
Loading list . . .
script
- python date_time_format_list.py
+ export PATH=/opt/homebrew/bin:/usr/local/bin:$PATH
+export PYTHONPATH="$PWD/lib"
+python3 date_time_format_list.py
scriptargtype
0
scriptfile
@@ -1020,19 +1084,21 @@
uid
E4238A84-F102-401E-A26E-ABC81E1B1E9E
version
- 2
+ 3
config
browser
+ skipqueryencode
+
+ skipvarencode
+
spaces
url
http://muppetgate.github.io/pages/date-calculator-help-page.html
- utf8
-
type
alfred.workflow.action.openurl
@@ -1065,19 +1131,13 @@
readme
## Date Calculator
-Hello there!
-I needed a bit of motivation to learn Python and Alfred workflows, so I thought I’d kill two horses with one bullet, so to speak.
-Right, so this is a date calculator – kind of. It won’t tell you when you will the lottery, or how long you’ve got to hide your ‘arty videos’ before your wife gets home, but it will answer one or two _very simple_ questions about dates.
+Original by [@MuppetGate](https://github.com/MuppetGate)
-
-
-For example, if you enter
+https://github.com/giovannicoppola/alfred-DateCalculator
**dcalc 25.12.14 - 18.01.14**
-then it will tell you the number of days between those dates. Note that the workflow parses the command as you enter it, so you’ll see _invalid command_, _invalid expression_ and _invalid format_ errors as you type. Once you’ve completed the command then you’ll be given the result.
-
-You could also try
+then it will tell you the number of days between those dates.
**dcalc 25.12.14 - now**
@@ -1114,7 +1174,7 @@ or combine ‘em
**dcalc 18.12.12 + 5y 9d 3w - 2d + 1d 1w**
What does that mess do?
-- Take the date 18.12.12
+- Take the date 18.12.12
- Add 5 years
- Add another 9 days
- Add another 3 weeks
@@ -1130,6 +1190,27 @@ Or for a specific date:
**dcalc 25.12.14 wn**
+The **wn** function also works in reverse, finding dates from week numbers:
+
+**dcalc wn 2015 5**
+
+will give you the date for the fifth week inside for 2015. The expression will give you the date on Monday of that week, but you can also supply your own day adjustment if you want to.
+
+**dcalc wn 2015 5 sun**
+
+And of course, you can do some basic calculations, if you can stand the syntax!
+
+**dcalc wn 2015 6 tue +1d wd**
+
+Should give you the Tuesday for week 6 in the year 2015, then add 1 day to that and give back the day of week.
+Which is Wednesday, obviously :-)
+
+I've included defaults so that the workflow will fill in missing parameters:
+
+**dcalc wn 7**
+
+will return the date of the current day of week (Monday, as I'm writing this) for the seventh week of the current year.
+
You can also use the _today_ thing in other places too:
**dcalc today + 4d**
@@ -1155,7 +1236,7 @@ Probably not all that useful, but some of this other stuff might be. You know al
**dcalc now**
-For giving you the current time and date. While you can use
+For giving you the current time and date. While you can use
**dcalc tomorrow**
@@ -1181,7 +1262,7 @@ That about covers it, I think. I haven’t done anything clever with locales, bu
**dcalcset date format**
-And we also support both 12-hour and 24-hour time formats.
+And we also support both 12-hour and 24-hour time formats.
**dcalcset time format**
@@ -1218,7 +1299,7 @@ or
**dcalc "1 day after tomorrow"**
-Yup! A natural date language parser!
+Yup! A natural date language parser!
You can even combine it with the existing parser:
@@ -1226,320 +1307,281 @@ You can even combine it with the existing parser:
This is a little bit experimental (I might drop it later if it proves to be problematic), but I thought I'd throw it in for a bit of a fun.
-## Exclusions
-Added at the request of a friend, though I'm not sure there's a lot of call for it. Okay, say you need to know how long you have to complete a project:
-
-**dcalc today - christmas**
-
-Not a problem, but hang on a mo – you don't like to work on weekends, so you'd better exclude them:
-
-**dcalc today - christmas exclude weekends**
-
-That'll exclude weekends from the calculations. Fantastic! But hang on, the wife's birthday! You won't be working on that day if you know what's good for you:
-
-**dcalc today - christmas exclude weekends 26.09.2014**
-
-Nicely saved, my friend; but there is still that small break you were planning in October:
-
-**dcalc today - christmas exclude weekends 26.09.2014 05.10.2014 to 10.10.2014**
-
-Crap! You're also having a wisdom tooth removed next wednesday
-
-**dcalc today - christmas exclude weekends 26.09.2014 05.10.2014 to 10.10.2014 next wed**
-Though I think you'll need more than a day to get over that. The _exclude_ keyword is a little verbose for the lightning typists, so you can also use _x_ instead:
+## Abbreviations
+To speed up entering calculations, there are a couple of function abbreviations you can use within expressions:
-**dcalc today - christmas x weekends tuesdays**
-As you might have guessed, this will work out the number of days between now and Christmas, not counting weekends and Tuesdays. We also have a very wordy variation which excludes every day except the one specified:
+**<** yesterday
-** dcalc today - easter x all except tuesdays**
+**\*** today
+**\>** tomorrow
-### Credits
-A list of things that made my first attempt at Python programming possible:
-- Dean Jackson for his more-than-slightly awesome [Alfred Workflow framework](http://www.deanishe.net/alfred-workflow/), and for his ‘parse-as-you-type’ idea.
-- The folk at [Jetbrains](http://www.jetbrains.com/pycharm/), for making programming, in any language, bearable.
-- Peter Odding for writing [HumanFriendly](https://humanfriendly.readthedocs.org/en/latest/).
-- Gustavo Niemeyer for [Python-DateUtil](https://labix.org/python-dateutil).
-- Volker Birk for [PyPEG](http://fdik.org/pyPEG/).
-- Mike Taylor for [ParseDateTime](https://github.com/bear/parsedatetime).
-- [Programming Praxis](http://programmingpraxis.com) for the Passover calculation.
+**&** time
-- And finally, and by no means least – Mr Smirnoff for discovering how to bottle patience.
+**\#** now
-### Version History
-(Version 2.3) - Bug fixes. Reworked the auto formatting. You can now apply exclusions to date calculations as well as timespan calculations.
-Added function to return the date when given a year, a week number and an optional day of the week
-(Version 2.1) - Bug fixes. Made the default formatting a little bit more intelligent.
-Latest release (Version 2.0). Refactoring. Added a natural date language parser. Added support for 12-hour clock. Added function to get date of the next passover
-Latest release (Version 1.6). Refactoring. Added exclusion functionality, and macros for _year start_ and _year end_. Changed the calls for days of the week: You now need to enter _next mon_ to get the date for next Monday, but you can also now type _prev mon_ to get the date for last Monday. Huzzah!
-Increased the accuracy of the date intervals. If you select _y_ for the date format then you will get _11.5 years_. But if you select _ym_ then you get _11 years, 6 months_. Trust me, it’s better this way.
+So now
-Latest release (Version 1.5). Refactoring. Rewrote the code for date subtraction arithmetic.
-Now it’s a lot more accurate, even when working with uneven months and weeks. Minor bug fixes.
+**dcalc \***
-Last release (Version 1.4) Fixed bug that caused inaccuracies when calculating anniversaries.
-Refactored code to make it easier to add new date functions and date formatters. General tidy-up
+will give you the current date.
-Last release (Version 1.3) Adds extra formatting functions (day of week) and bug fixes.
+And
-Last release (Version 1.2) was an improvement to add user-defined macros.
+**dcalc \*+6d**
-Last release (Version 1.1) was on the 01.07.2014. This included a new anniversary list function,
-and the addition of the international date format (yyyy-mm-dd).
-
-Last release (Version 1.0) was on the 27.06.2014. This included an improved date parser,
-added macros (days of week, christmas and easter) and a general tidy up.
-The symbol for getting the week number for a particular date has changed
-from ‘^’ to ‘!’ or ‘wn’. Why? Because I seemed to be struggling to find ‘^’ on the keyboard.
-
-### License
-Well, I guess the [MIT](http://opensource.org/licenses/MIT) one will do. :-)
-
-The MIT License (MIT)
-Copyright (c) 2014 MuppetGate Media
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in
-all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
-THE SOFTWARE.
+will give you the date six days from now.
uidata
0B14F62B-EEC4-460E-A1B4-6DFF6705E5FA
xpos
- 500
+ 500
ypos
1760
0D06D18F-E39D-49F3-BF9C-D8919BC950B7
xpos
- 300
+ 300
ypos
1400
19E610C7-B40E-4C9A-BFBC-2779322FA99B
xpos
- 700
+ 700
ypos
1640
308D6AD9-DB3C-4021-9318-F162FF0E4254
xpos
- 300
+ 300
ypos
530
325B8F31-17CE-427F-ABB6-9D77B34CE8B7
xpos
- 300
+ 300
ypos
1280
42E3993D-0D36-40CD-89F8-562E443F4BCF
xpos
- 500
+ 500
ypos
650
4B49B105-733E-4F5D-A690-B7B76C0B3B1D
xpos
- 500
+ 500
ypos
1040
52C696F5-80D3-4235-92F9-6830E819A88D
xpos
- 700
+ 700
ypos
60
52DA2602-1085-48CD-BDA1-8BF4F5005B57
xpos
- 500
+ 505
ypos
- 920
+ 905
56D0C077-A984-4BCD-B4B7-BF789A8C69FB
xpos
- 500
+ 500
ypos
1280
5F6FEA98-E805-408A-A1F4-A8A5FC49DC81
xpos
- 700
+ 700
ypos
1520
6344C161-C077-4BB5-800B-6BCF7A98F450
xpos
- 300
+ 300
ypos
650
6A04F044-39CB-4830-8CAF-6E471F570AE8
xpos
- 300
+ 300
ypos
320
7205A144-D946-40B6-BF86-C19518026D45
xpos
- 500
+ 500
ypos
1400
78DDDF2F-629A-4313-95EE-1BB4A7AB3C4A
xpos
- 500
+ 500
ypos
200
7F570625-0CC5-4B6E-A1BF-2F3169943C33
xpos
- 700
+ 700
ypos
530
8BB3905A-8C58-4F09-B871-9CF756226504
xpos
- 500
+ 500
ypos
1520
8F4747B0-FA9D-4FCB-B828-4B37602854B5
xpos
- 500
+ 500
ypos
60
93F1AC54-E8DD-416A-BA06-74779BDA2668
xpos
- 700
+ 700
ypos
320
9A630331-69C6-40E1-9F7B-7B782D30236E
xpos
- 500
+ 500
ypos
770
AC56E0A1-82E8-4C9C-B6CF-2B53EBD02ABF
xpos
- 500
+ 500
ypos
410
B222BD5C-5A0E-4EC1-9D9E-E308621BC7C8
xpos
- 300
+ 300
ypos
60
BFDF2A5E-8F79-4B66-9297-4FC3A926B30A
xpos
- 300
+ 300
ypos
1520
C0DB0242-54B1-475E-A327-B61C54C7B668
xpos
- 700
+ 700
ypos
200
C5269892-166A-4776-9B18-6B0A72E66364
xpos
- 700
+ 700
ypos
1400
C762CD13-0320-40F8-8A88-BBBC6304759E
xpos
- 500
+ 500
ypos
1640
CC4BA615-8C01-40D0-A08E-E29034EE6FAA
xpos
- 500
+ 500
ypos
530
E4238A84-F102-401E-A26E-ABC81E1B1E9E
xpos
- 300
+ 300
ypos
1640
F7EC7A12-0BA0-4294-A84C-A144CF6DFCCF
xpos
- 500
+ 500
ypos
1160
FA8E241A-392E-41E0-8B29-F72B273A293F
xpos
- 300
+ 300
ypos
1760
FC254D99-C731-4315-B760-9452FF77AC53
xpos
- 300
+ 300
ypos
200
+ userconfigurationconfig
+
+
+ config
+
+ default
+ dcalc
+ placeholder
+
+ required
+
+ trim
+
+
+ description
+
+ label
+ Keyword
+ type
+ textfield
+ variable
+ mainkeyword
+
+
+ variablesdontexport
+
version
- 3.3
+ 4.1
webaddress
- http://muppetgate.github.io/pages/date-calculator-help-page.html
+ https://github.com/giovannicoppola/alfred-DateCalculator
diff --git a/isoweek.py b/src/isoweek.py
similarity index 100%
rename from isoweek.py
rename to src/isoweek.py
diff --git a/macros_parser.py b/src/macros_parser.py
similarity index 100%
rename from macros_parser.py
rename to src/macros_parser.py
diff --git a/src/packal/muppet.gate.net.DateCalculator.pub b/src/packal/muppet.gate.net.DateCalculator.pub
new file mode 100644
index 0000000..eda017a
--- /dev/null
+++ b/src/packal/muppet.gate.net.DateCalculator.pub
@@ -0,0 +1,9 @@
+-----BEGIN PUBLIC KEY-----
+MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAvukUrt5XRx6Lh0VYrFNt
+qqccFA5nrafUi/eYaPTMWRUcmi5omrHPw2EllsMbEDYgnDj0SQ2UeGa2zTuvvWIr
+zq1rSXVPjGHsAzJzFnxYe3WfE/P/v0ombH3bE0whGcWhdo2ejoo/C6O8eYwRDEHp
+Sqwd9ZyTo6rs/CJrKJJIGxFqutZKYGsYeBJvt6Xu3v9RR0dgAW3NUFArz1FHte/p
+TCE5CEXOF6luMxO+p5TNoZF8gT6/80Gp35C1Zn5ZBWE0C7PNgOFA2EW1tPxJfVAQ
+XXbmvAl0Zm2JMAHf2KOsfv03XHuM407Wzn0ZX+7IvO4hdb1I73FGE7oWzPk4FE8U
+KQIDAQAB
+-----END PUBLIC KEY-----
diff --git a/src/packal/package.xml b/src/packal/package.xml
new file mode 100644
index 0000000..8846f51
--- /dev/null
+++ b/src/packal/package.xml
@@ -0,0 +1,8 @@
+
+
+ Date Calculator
+ 3.3
+ muppet.gate.net.DateCalculator
+ 1540192818
+ date_calculator.alfredworkflow
+
diff --git a/src/requirements.txt b/src/requirements.txt
new file mode 100755
index 0000000..c25156e
--- /dev/null
+++ b/src/requirements.txt
@@ -0,0 +1,5 @@
+arrow==1.2.2
+parsedatetime==2.6
+python-dateutil==2.8.2
+pyPEG2==2.15.2
+
diff --git a/set_anniversary.py b/src/set_anniversary.py
similarity index 100%
rename from set_anniversary.py
rename to src/set_anniversary.py
diff --git a/set_date_format.py b/src/set_date_format.py
similarity index 100%
rename from set_date_format.py
rename to src/set_date_format.py
diff --git a/set_date_time_format.py b/src/set_date_time_format.py
similarity index 100%
rename from set_date_time_format.py
rename to src/set_date_time_format.py
diff --git a/set_time_format.py b/src/set_time_format.py
similarity index 100%
rename from set_time_format.py
rename to src/set_time_format.py
diff --git a/show_date_format.py b/src/show_date_format.py
similarity index 100%
rename from show_date_format.py
rename to src/show_date_format.py
diff --git a/show_time_format.py b/src/show_time_format.py
similarity index 100%
rename from show_time_format.py
rename to src/show_time_format.py
diff --git a/time_format_list.py b/src/time_format_list.py
similarity index 100%
rename from time_format_list.py
rename to src/time_format_list.py
diff --git a/utils.py b/src/utils.py
similarity index 90%
rename from utils.py
rename to src/utils.py
index 18808fd..b18a88d 100644
--- a/utils.py
+++ b/src/utils.py
@@ -7,6 +7,11 @@
from dateutil.rrule import rrule, YEARLY
import dateutil.parser
+import sys
+def log(s, *args):
+ if args:
+ s = s % args
+ print(s, file=sys.stderr)
# package for general utility stuff
from isoweek import Week
@@ -111,6 +116,16 @@ def convert_date_time(date_time, settings):
date_format = get_date_format(settings)
time_format = get_time_format(settings)
full_format = get_full_format(settings)
+<<<<<<< Updated upstream
+ log ('========================DATE FORMAT ==============')
+ log (date_format)
+ log ('========================FULL FORMAT ==============')
+
+ log (full_format)
+=======
+>>>>>>> Stashed changes
+ if date_format == '%-d.%-m.%Y':
+ date_format = '%d.%m.%Y'
# Okay, Does the date command start with a " symbol?
if date_time[0] == "\"":
@@ -126,7 +141,6 @@ def convert_date_time(date_time, settings):
return DATE_FUNCTION_MAP[date_time_str.lower()](settings)
anniversary_date = process_macros(date_time_str.lower(), settings['anniversaries'])
-
if anniversary_date is not None:
return datetime.combine(anniversary_date, datetime.max.time()), date_format
@@ -148,8 +162,13 @@ def convert_date_time(date_time, settings):
except ValueError:
try:
+ log ('========================DATE STRING ==============')
+ log (date_time_str)
process_date = datetime.strptime(date_time_str.upper(), date_format)
+ log ('========================PROCESS DATE ==============')
+ log (process_date)
+
date_and_time = datetime.combine(process_date, datetime.max.time())
return date_and_time, date_format
diff --git a/versioning.py b/src/versioning.py
similarity index 100%
rename from versioning.py
rename to src/versioning.py
diff --git a/workflow/.alfredversionchecked b/src/workflow/.alfredversionchecked
similarity index 100%
rename from workflow/.alfredversionchecked
rename to src/workflow/.alfredversionchecked
diff --git a/workflow/Notify.tgz b/src/workflow/Notify.tgz
similarity index 100%
rename from workflow/Notify.tgz
rename to src/workflow/Notify.tgz
diff --git a/src/workflow/__init__.py b/src/workflow/__init__.py
new file mode 100644
index 0000000..f93fb60
--- /dev/null
+++ b/src/workflow/__init__.py
@@ -0,0 +1,104 @@
+#!/usr/bin/env python
+# encoding: utf-8
+#
+# Copyright (c) 2014 Dean Jackson
+#
+# MIT Licence. See http://opensource.org/licenses/MIT
+#
+# Created on 2014-02-15
+#
+
+"""A helper library for `Alfred `_ workflows."""
+
+import os
+
+# Filter matching rules
+# Icons
+# Exceptions
+# Workflow objects
+from .workflow import (
+ ICON_ACCOUNT,
+ ICON_BURN,
+ ICON_CLOCK,
+ ICON_COLOR,
+ ICON_COLOUR,
+ ICON_EJECT,
+ ICON_ERROR,
+ ICON_FAVORITE,
+ ICON_FAVOURITE,
+ ICON_GROUP,
+ ICON_HELP,
+ ICON_HOME,
+ ICON_INFO,
+ ICON_NETWORK,
+ ICON_NOTE,
+ ICON_SETTINGS,
+ ICON_SWIRL,
+ ICON_SWITCH,
+ ICON_SYNC,
+ ICON_TRASH,
+ ICON_USER,
+ ICON_WARNING,
+ ICON_WEB,
+ MATCH_ALL,
+ MATCH_ALLCHARS,
+ MATCH_ATOM,
+ MATCH_CAPITALS,
+ MATCH_INITIALS,
+ MATCH_INITIALS_CONTAIN,
+ MATCH_INITIALS_STARTSWITH,
+ MATCH_STARTSWITH,
+ MATCH_SUBSTRING,
+ KeychainError,
+ PasswordNotFound,
+ Workflow,
+ manager,
+)
+from .workflow3 import Variables, Workflow3
+
+__title__ = "Alfred-Workflow"
+__version__ = open(os.path.join(os.path.dirname(__file__), "version")).read()
+__author__ = "Dean Jackson"
+__licence__ = "MIT"
+__copyright__ = "Copyright 2014-2019 Dean Jackson"
+
+__all__ = [
+ "Variables",
+ "Workflow",
+ "Workflow3",
+ "manager",
+ "PasswordNotFound",
+ "KeychainError",
+ "ICON_ACCOUNT",
+ "ICON_BURN",
+ "ICON_CLOCK",
+ "ICON_COLOR",
+ "ICON_COLOUR",
+ "ICON_EJECT",
+ "ICON_ERROR",
+ "ICON_FAVORITE",
+ "ICON_FAVOURITE",
+ "ICON_GROUP",
+ "ICON_HELP",
+ "ICON_HOME",
+ "ICON_INFO",
+ "ICON_NETWORK",
+ "ICON_NOTE",
+ "ICON_SETTINGS",
+ "ICON_SWIRL",
+ "ICON_SWITCH",
+ "ICON_SYNC",
+ "ICON_TRASH",
+ "ICON_USER",
+ "ICON_WARNING",
+ "ICON_WEB",
+ "MATCH_ALL",
+ "MATCH_ALLCHARS",
+ "MATCH_ATOM",
+ "MATCH_CAPITALS",
+ "MATCH_INITIALS",
+ "MATCH_INITIALS_CONTAIN",
+ "MATCH_INITIALS_STARTSWITH",
+ "MATCH_STARTSWITH",
+ "MATCH_SUBSTRING",
+]
diff --git a/workflow/background.py b/src/workflow/background.py
similarity index 75%
rename from workflow/background.py
rename to src/workflow/background.py
index cd5400b..2001856 100644
--- a/workflow/background.py
+++ b/src/workflow/background.py
@@ -1,4 +1,3 @@
-#!/usr/bin/env python
# encoding: utf-8
#
# Copyright (c) 2014 deanishe@deanishe.net
@@ -8,8 +7,8 @@
# Created on 2014-04-06
#
-"""
-This module provides an API to run commands in background processes.
+"""This module provides an API to run commands in background processes.
+
Combine with the :ref:`caching API ` to work from cached data
while you fetch fresh data in the background.
@@ -17,17 +16,16 @@
and examples.
"""
-from __future__ import print_function, unicode_literals
-import signal
-import sys
import os
-import subprocess
import pickle
+import signal
+import subprocess
+import sys
from workflow import Workflow
-__all__ = ['is_running', 'run_in_background']
+__all__ = ["is_running", "run_in_background"]
_wf = None
@@ -52,7 +50,7 @@ def _arg_cache(name):
:rtype: ``unicode`` filepath
"""
- return wf().cachefile(name + '.argcache')
+ return wf().cachefile(name + ".argcache")
def _pid_file(name):
@@ -64,7 +62,7 @@ def _pid_file(name):
:rtype: ``unicode`` filepath
"""
- return wf().cachefile(name + '.pid')
+ return wf().cachefile(name + ".pid")
def _process_exists(pid):
@@ -96,16 +94,16 @@ def _job_pid(name):
if not os.path.exists(pidfile):
return
- with open(pidfile, 'rb') as fp:
- pid = int(fp.read())
+ with open(pidfile, "rb") as fp:
+ read = fp.read()
+ # print(str(read))
+ pid = int.from_bytes(read, sys.byteorder)
+ # print(pid)
if _process_exists(pid):
return pid
- try:
- os.unlink(pidfile)
- except Exception: # pragma: no cover
- pass
+ os.unlink(pidfile)
def is_running(name):
@@ -123,8 +121,9 @@ def is_running(name):
return False
-def _background(pidfile, stdin='/dev/null', stdout='/dev/null',
- stderr='/dev/null'): # pragma: no cover
+def _background(
+ pidfile, stdin="/dev/null", stdout="/dev/null", stderr="/dev/null"
+): # pragma: no cover
"""Fork the current process into a background daemon.
:param pidfile: file to write PID of daemon process to.
@@ -137,42 +136,43 @@ def _background(pidfile, stdin='/dev/null', stdout='/dev/null',
:type stderr: filepath
"""
+
def _fork_and_exit_parent(errmsg, wait=False, write=False):
try:
pid = os.fork()
if pid > 0:
if write: # write PID of child process to `pidfile`
- tmp = pidfile + '.tmp'
- with open(tmp, 'wb') as fp:
- fp.write(str(pid))
+ tmp = pidfile + ".tmp"
+ with open(tmp, "wb") as fp:
+ fp.write(pid.to_bytes(4, sys.byteorder))
os.rename(tmp, pidfile)
if wait: # wait for child process to exit
os.waitpid(pid, 0)
os._exit(0)
except OSError as err:
- _log().critical('%s: (%d) %s', errmsg, err.errno, err.strerror)
+ _log().critical("%s: (%d) %s", errmsg, err.errno, err.strerror)
raise err
# Do first fork and wait for second fork to finish.
- _fork_and_exit_parent('fork #1 failed', wait=True)
+ _fork_and_exit_parent("fork #1 failed", wait=True)
# Decouple from parent environment.
os.chdir(wf().workflowdir)
os.setsid()
# Do second fork and write PID to pidfile.
- _fork_and_exit_parent('fork #2 failed', write=True)
+ _fork_and_exit_parent("fork #2 failed", write=True)
# Now I am a daemon!
# Redirect standard file descriptors.
- si = open(stdin, 'r', 0)
- so = open(stdout, 'a+', 0)
- se = open(stderr, 'a+', 0)
- if hasattr(sys.stdin, 'fileno'):
+ si = open(stdin, "r", 1)
+ so = open(stdout, "a+", 1)
+ se = open(stderr, "a+", 1)
+ if hasattr(sys.stdin, "fileno"):
os.dup2(si.fileno(), sys.stdin.fileno())
- if hasattr(sys.stdout, 'fileno'):
+ if hasattr(sys.stdout, "fileno"):
os.dup2(so.fileno(), sys.stdout.fileno())
- if hasattr(sys.stderr, 'fileno'):
+ if hasattr(sys.stderr, "fileno"):
os.dup2(se.fileno(), sys.stderr.fileno())
@@ -222,25 +222,25 @@ def run_in_background(name, args, **kwargs):
"""
if is_running(name):
- _log().info('[%s] job already running', name)
+ _log().info("[%s] job already running", name)
return
argcache = _arg_cache(name)
# Cache arguments
- with open(argcache, 'wb') as fp:
- pickle.dump({'args': args, 'kwargs': kwargs}, fp)
- _log().debug('[%s] command cached: %s', name, argcache)
+ with open(argcache, "wb") as fp:
+ pickle.dump({"args": args, "kwargs": kwargs}, fp)
+ _log().debug("[%s] command cached: %s", name, argcache)
# Call this script
- cmd = ['/usr/bin/python', __file__, name]
- _log().debug('[%s] passing job to background runner: %r', name, cmd)
+ cmd = [sys.executable, "-m", "workflow.background", name]
+ _log().debug("[%s] passing job to background runner: %r", name, cmd)
retcode = subprocess.call(cmd)
if retcode: # pragma: no cover
- _log().error('[%s] background runner failed with %d', name, retcode)
+ _log().error("[%s] background runner failed with %d", name, retcode)
else:
- _log().debug('[%s] background job started', name)
+ _log().debug("[%s] background job started", name)
return retcode
@@ -256,7 +256,7 @@ def main(wf): # pragma: no cover
name = wf.args[0]
argcache = _arg_cache(name)
if not os.path.exists(argcache):
- msg = '[{0}] command cache not found: {1}'.format(name, argcache)
+ msg = "[{0}] command cache not found: {1}".format(name, argcache)
log.critical(msg)
raise IOError(msg)
@@ -265,29 +265,29 @@ def main(wf): # pragma: no cover
_background(pidfile)
# Load cached arguments
- with open(argcache, 'rb') as fp:
+ with open(argcache, "rb") as fp:
data = pickle.load(fp)
# Cached arguments
- args = data['args']
- kwargs = data['kwargs']
+ args = data["args"]
+ kwargs = data["kwargs"]
# Delete argument cache file
os.unlink(argcache)
try:
# Run the command
- log.debug('[%s] running command: %r', name, args)
+ log.debug("[%s] running command: %r", name, args)
retcode = subprocess.call(args, **kwargs)
if retcode:
- log.error('[%s] command failed with status %d', name, retcode)
+ log.error("[%s] command failed with status %d", name, retcode)
finally:
os.unlink(pidfile)
- log.debug('[%s] job complete', name)
+ log.debug("[%s] job complete", name)
-if __name__ == '__main__': # pragma: no cover
+if __name__ == "__main__": # pragma: no cover
wf().run(main)
diff --git a/workflow/notify.py b/src/workflow/notify.py
similarity index 61%
rename from workflow/notify.py
rename to src/workflow/notify.py
index 4542c78..1de25ec 100644
--- a/workflow/notify.py
+++ b/src/workflow/notify.py
@@ -11,9 +11,10 @@
# TODO: Exclude this module from test and code coverage in py2.6
"""
-Post notifications via the macOS Notification Center. This feature
-is only available on Mountain Lion (10.8) and later. It will
-silently fail on older systems.
+Post notifications via the macOS Notification Center.
+
+This feature is only available on Mountain Lion (10.8) and later.
+It will silently fail on older systems.
The main API is a single function, :func:`~workflow.notify.notify`.
@@ -22,7 +23,6 @@
icon and then calls the application to post notifications.
"""
-from __future__ import print_function, unicode_literals
import os
import plistlib
@@ -32,9 +32,9 @@
import tarfile
import tempfile
import uuid
+from typing import List
-import workflow
-
+from . import workflow
_wf = None
_log = None
@@ -42,20 +42,20 @@
#: Available system sounds from System Preferences > Sound > Sound Effects
SOUNDS = (
- 'Basso',
- 'Blow',
- 'Bottle',
- 'Frog',
- 'Funk',
- 'Glass',
- 'Hero',
- 'Morse',
- 'Ping',
- 'Pop',
- 'Purr',
- 'Sosumi',
- 'Submarine',
- 'Tink',
+ "Basso",
+ "Blow",
+ "Bottle",
+ "Frog",
+ "Funk",
+ "Glass",
+ "Hero",
+ "Morse",
+ "Ping",
+ "Pop",
+ "Purr",
+ "Sosumi",
+ "Submarine",
+ "Tink",
)
@@ -89,7 +89,7 @@ def notifier_program():
Returns:
unicode: Path to Notify.app ``applet`` executable.
"""
- return wf().datafile('Notify.app/Contents/MacOS/applet')
+ return wf().datafile("Notify.app/Contents/MacOS/applet")
def notifier_icon_path():
@@ -98,7 +98,7 @@ def notifier_icon_path():
Returns:
unicode: Path to ``applet.icns`` within the app bundle.
"""
- return wf().datafile('Notify.app/Contents/Resources/applet.icns')
+ return wf().datafile("Notify.app/Contents/Resources/applet.icns")
def install_notifier():
@@ -107,21 +107,21 @@ def install_notifier():
Changes the bundle ID of the installed app and gives it the
workflow's icon.
"""
- archive = os.path.join(os.path.dirname(__file__), 'Notify.tgz')
+ archive = os.path.join(os.path.dirname(__file__), "Notify.tgz")
destdir = wf().datadir
- app_path = os.path.join(destdir, 'Notify.app')
+ app_path = os.path.join(destdir, "Notify.app")
n = notifier_program()
- log().debug('installing Notify.app to %r ...', destdir)
+ log().debug("installing Notify.app to %r ...", destdir)
# z = zipfile.ZipFile(archive, 'r')
# z.extractall(destdir)
- tgz = tarfile.open(archive, 'r:gz')
+ tgz = tarfile.open(archive, "r:gz")
tgz.extractall(destdir)
- assert os.path.exists(n), \
- 'Notify.app could not be installed in %s' % destdir
+ if not os.path.exists(n): # pragma: nocover
+ raise RuntimeError("Notify.app could not be installed in " + destdir)
# Replace applet icon
icon = notifier_icon_path()
- workflow_icon = wf().workflowfile('icon.png')
+ workflow_icon = wf().workflowfile("icon.png")
if os.path.exists(icon):
os.unlink(icon)
@@ -133,7 +133,7 @@ def install_notifier():
# until I figure out a better way of excluding this module
# from coverage in py2.6.
if sys.version_info >= (2, 7): # pragma: no cover
- from AppKit import NSWorkspace, NSImage
+ from AppKit import NSImage, NSWorkspace
ws = NSWorkspace.sharedWorkspace()
img = NSImage.alloc().init()
@@ -141,12 +141,12 @@ def install_notifier():
ws.setIcon_forFile_options_(img, app_path, 0)
# Change bundle ID of installed app
- ip_path = os.path.join(app_path, 'Contents/Info.plist')
- bundle_id = '{0}.{1}'.format(wf().bundleid, uuid.uuid4().hex)
- data = plistlib.readPlist(ip_path)
- log().debug('changing bundle ID to %r', bundle_id)
- data['CFBundleIdentifier'] = bundle_id
- plistlib.writePlist(data, ip_path)
+ ip_path = os.path.join(app_path, "Contents/Info.plist")
+ bundle_id = "{0}.{1}".format(wf().bundleid, uuid.uuid4().hex)
+ data = plistlib.load(ip_path)
+ log().debug("changing bundle ID to %r", bundle_id)
+ data["CFBundleIdentifier"] = bundle_id
+ plistlib.dump(data, ip_path)
def validate_sound(sound):
@@ -171,7 +171,7 @@ def validate_sound(sound):
return None
-def notify(title='', text='', sound=None):
+def notify(title="", text="", sound=None):
"""Post notification via Notify.app helper.
Args:
@@ -185,10 +185,10 @@ def notify(title='', text='', sound=None):
Returns:
bool: ``True`` if notification was posted, else ``False``.
"""
- if title == text == '':
- raise ValueError('Empty notification')
+ if title == text == "":
+ raise ValueError("Empty notification")
- sound = validate_sound(sound) or ''
+ sound = validate_sound(sound) or ""
n = notifier_program()
@@ -196,19 +196,23 @@ def notify(title='', text='', sound=None):
install_notifier()
env = os.environ.copy()
- enc = 'utf-8'
- env['NOTIFY_TITLE'] = title.encode(enc)
- env['NOTIFY_MESSAGE'] = text.encode(enc)
- env['NOTIFY_SOUND'] = sound.encode(enc)
+ enc = "utf-8"
+ env["NOTIFY_TITLE"] = title.encode(enc)
+ env["NOTIFY_MESSAGE"] = text.encode(enc)
+ env["NOTIFY_SOUND"] = sound.encode(enc)
cmd = [n]
retcode = subprocess.call(cmd, env=env)
if retcode == 0:
return True
- log().error('Notify.app exited with status {0}.'.format(retcode))
+ log().error("Notify.app exited with status {0}.".format(retcode))
return False
+def usr_bin_env(*args: str) -> List[str]:
+ return ["/usr/bin/env", f'PATH={os.environ["PATH"]}'] + list(args)
+
+
def convert_image(inpath, outpath, size):
"""Convert an image file using ``sips``.
@@ -220,17 +224,15 @@ def convert_image(inpath, outpath, size):
Raises:
RuntimeError: Raised if ``sips`` exits with non-zero status.
"""
- cmd = [
- b'sips',
- b'-z', str(size), str(size),
- inpath,
- b'--out', outpath]
+ cmd = ["sips", "-z", str(size), str(size), inpath, "--out", outpath]
# log().debug(cmd)
- with open(os.devnull, 'w') as pipe:
- retcode = subprocess.call(cmd, stdout=pipe, stderr=subprocess.STDOUT)
+ with open(os.devnull, "w") as pipe:
+ retcode = subprocess.call(
+ cmd, shell=True, stdout=pipe, stderr=subprocess.STDOUT
+ )
if retcode != 0:
- raise RuntimeError('sips exited with %d' % retcode)
+ raise RuntimeError("sips exited with %d" % retcode)
def png_to_icns(png_path, icns_path):
@@ -247,24 +249,25 @@ def png_to_icns(png_path, icns_path):
Raises:
RuntimeError: Raised if ``iconutil`` or ``sips`` fail.
"""
- tempdir = tempfile.mkdtemp(prefix='aw-', dir=wf().datadir)
+ tempdir = tempfile.mkdtemp(prefix="aw-", dir=wf().datadir)
try:
- iconset = os.path.join(tempdir, 'Icon.iconset')
+ iconset = os.path.join(tempdir, "Icon.iconset")
+
+ if os.path.exists(iconset): # pragma: nocover
+ raise RuntimeError("iconset already exists: " + iconset)
- assert not os.path.exists(iconset), \
- 'iconset already exists: ' + iconset
os.makedirs(iconset)
# Copy source icon to icon set and generate all the other
# sizes needed
configs = []
for i in (16, 32, 128, 256, 512):
- configs.append(('icon_{0}x{0}.png'.format(i), i))
- configs.append((('icon_{0}x{0}@2x.png'.format(i), i * 2)))
+ configs.append(("icon_{0}x{0}.png".format(i), i))
+ configs.append((("icon_{0}x{0}@2x.png".format(i), i * 2)))
- shutil.copy(png_path, os.path.join(iconset, 'icon_256x256.png'))
- shutil.copy(png_path, os.path.join(iconset, 'icon_128x128@2x.png'))
+ shutil.copy(png_path, os.path.join(iconset, "icon_256x256.png"))
+ shutil.copy(png_path, os.path.join(iconset, "icon_128x128@2x.png"))
for name, size in configs:
outpath = os.path.join(iconset, name)
@@ -272,18 +275,14 @@ def png_to_icns(png_path, icns_path):
continue
convert_image(png_path, outpath, size)
- cmd = [
- b'iconutil',
- b'-c', b'icns',
- b'-o', icns_path,
- iconset]
+ cmd = ["iconutil", "-c", "icns", "-o", icns_path, iconset]
retcode = subprocess.call(cmd)
if retcode != 0:
- raise RuntimeError('iconset exited with %d' % retcode)
+ raise RuntimeError("iconset exited with %d" % retcode)
- assert os.path.exists(icns_path), \
- 'generated ICNS file not found: ' + repr(icns_path)
+ if not os.path.exists(icns_path): # pragma: nocover
+ raise ValueError("generated ICNS file not found: " + repr(icns_path))
finally:
try:
shutil.rmtree(tempdir)
@@ -291,29 +290,29 @@ def png_to_icns(png_path, icns_path):
pass
-if __name__ == '__main__': # pragma: nocover
+if __name__ == "__main__": # pragma: nocover
# Simple command-line script to test module with
# This won't work on 2.6, as `argparse` isn't available
# by default.
import argparse
-
from unicodedata import normalize
def ustr(s):
"""Coerce `s` to normalised Unicode."""
- return normalize('NFD', s.decode('utf-8'))
+ return normalize("NFD", s.decode("utf-8"))
p = argparse.ArgumentParser()
- p.add_argument('-p', '--png', help="PNG image to convert to ICNS.")
- p.add_argument('-l', '--list-sounds', help="Show available sounds.",
- action='store_true')
- p.add_argument('-t', '--title',
- help="Notification title.", type=ustr,
- default='')
- p.add_argument('-s', '--sound', type=ustr,
- help="Optional notification sound.", default='')
- p.add_argument('text', type=ustr,
- help="Notification body text.", default='', nargs='?')
+ p.add_argument("-p", "--png", help="PNG image to convert to ICNS.")
+ p.add_argument(
+ "-l", "--list-sounds", help="Show available sounds.", action="store_true"
+ )
+ p.add_argument("-t", "--title", help="Notification title.", type=ustr, default="")
+ p.add_argument(
+ "-s", "--sound", type=ustr, help="Optional notification sound.", default=""
+ )
+ p.add_argument(
+ "text", type=ustr, help="Notification body text.", default="", nargs="?"
+ )
o = p.parse_args()
# List available sounds
@@ -326,20 +325,20 @@ def ustr(s):
if o.png:
icns = os.path.join(
os.path.dirname(o.png),
- os.path.splitext(os.path.basename(o.png))[0] + '.icns')
+ os.path.splitext(os.path.basename(o.png))[0] + ".icns",
+ )
- print('converting {0!r} to {1!r} ...'.format(o.png, icns),
- file=sys.stderr)
+ print("converting {0!r} to {1!r} ...".format(o.png, icns), file=sys.stderr)
- assert not os.path.exists(icns), \
- 'destination file already exists: ' + icns
+ if os.path.exists(icns):
+ raise ValueError("destination file already exists: " + icns)
png_to_icns(o.png, icns)
sys.exit(0)
# Post notification
- if o.title == o.text == '':
- print('ERROR: empty notification.', file=sys.stderr)
+ if o.title == o.text == "":
+ print("ERROR: empty notification.", file=sys.stderr)
sys.exit(1)
else:
notify(o.title, o.text, o.sound)
diff --git a/src/workflow/update.py b/src/workflow/update.py
new file mode 100644
index 0000000..dc40c4b
--- /dev/null
+++ b/src/workflow/update.py
@@ -0,0 +1,581 @@
+#!/usr/bin/env python
+# encoding: utf-8
+#
+# Copyright (c) 2014 Fabio Niephaus ,
+# Dean Jackson
+#
+# MIT Licence. See http://opensource.org/licenses/MIT
+#
+# Created on 2014-08-16
+#
+
+"""Self-updating from GitHub.
+
+.. versionadded:: 1.9
+
+.. note::
+
+ This module is not intended to be used directly. Automatic updates
+ are controlled by the ``update_settings`` :class:`dict` passed to
+ :class:`~workflow.workflow.Workflow` objects.
+
+"""
+
+
+import json
+import os
+import re
+import subprocess
+import tempfile
+from collections import defaultdict
+from functools import total_ordering
+from itertools import zip_longest
+from urllib import request
+
+from workflow.util import atomic_writer
+
+from . import workflow
+
+# __all__ = []
+
+
+RELEASES_BASE = "https://api.github.com/repos/{}/releases"
+match_workflow = re.compile(r"\.alfred(\d+)?workflow$").search
+
+_wf = None
+
+
+def wf():
+ """Lazy `Workflow` object."""
+ global _wf
+ if _wf is None:
+ _wf = workflow.Workflow()
+ return _wf
+
+
+@total_ordering
+class Download(object):
+ """A workflow file that is available for download.
+
+ .. versionadded: 1.37
+
+ Attributes:
+ url (str): URL of workflow file.
+ filename (str): Filename of workflow file.
+ version (Version): Semantic version of workflow.
+ prerelease (bool): Whether version is a pre-release.
+ alfred_version (Version): Minimum compatible version
+ of Alfred.
+
+ """
+
+ @classmethod
+ def from_dict(cls, d):
+ """Create a `Download` from a `dict`."""
+ return cls(
+ url=d["url"],
+ filename=d["filename"],
+ version=Version(d["version"]),
+ prerelease=d["prerelease"],
+ )
+
+ @classmethod
+ def from_releases(cls, js):
+ """Extract downloads from GitHub releases.
+
+ Searches releases with semantic tags for assets with
+ file extension .alfredworkflow or .alfredXworkflow where
+ X is a number.
+
+ Files are returned sorted by latest version first. Any
+ releases containing multiple files with the same (workflow)
+ extension are rejected as ambiguous.
+
+ Args:
+ js (str): JSON response from GitHub's releases endpoint.
+
+ Returns:
+ list: Sequence of `Download`.
+ """
+ releases = json.loads(js)
+ downloads = []
+ for release in releases:
+ tag = release["tag_name"]
+ dupes = defaultdict(int)
+ try:
+ version = Version(tag)
+ except ValueError as err:
+ wf().logger.debug('ignored release: bad version "%s": %s', tag, err)
+ continue
+
+ dls = []
+ for asset in release.get("assets", []):
+ url = asset.get("browser_download_url")
+ filename = os.path.basename(url)
+ m = match_workflow(filename)
+ if not m:
+ wf().logger.debug("unwanted file: %s", filename)
+ continue
+
+ ext = m.group(0)
+ dupes[ext] = dupes[ext] + 1
+ dls.append(Download(url, filename, version, release["prerelease"]))
+
+ valid = True
+ for ext, n in list(dupes.items()):
+ if n > 1:
+ wf().logger.debug(
+ 'ignored release "%s": multiple assets ' 'with extension "%s"',
+ tag,
+ ext,
+ )
+ valid = False
+ break
+
+ if valid:
+ downloads.extend(dls)
+
+ downloads.sort(reverse=True)
+ return downloads
+
+ def __init__(self, url, filename, version, prerelease=False):
+ """Create a new Download.
+
+ Args:
+ url (str): URL of workflow file.
+ filename (str): Filename of workflow file.
+ version (Version): Version of workflow.
+ prerelease (bool, optional): Whether version is
+ pre-release. Defaults to False.
+
+ """
+ if isinstance(version, str):
+ version = Version(version)
+
+ self.url = url
+ self.filename = filename
+ self.version = version
+ self.prerelease = prerelease
+
+ @property
+ def alfred_version(self):
+ """Minimum Alfred version based on filename extension."""
+ m = match_workflow(self.filename)
+ if not m or not m.group(1):
+ return Version("0")
+ return Version(m.group(1))
+
+ @property
+ def dict(self):
+ """Convert `Download` to `dict`."""
+ return dict(
+ url=self.url,
+ filename=self.filename,
+ version=str(self.version),
+ prerelease=self.prerelease,
+ )
+
+ def __str__(self):
+ """Format `Download` for printing."""
+ return (
+ "Download("
+ "url={dl.url!r}, "
+ "filename={dl.filename!r}, "
+ "version={dl.version!r}, "
+ "prerelease={dl.prerelease!r}"
+ ")"
+ ).format(dl=self)
+
+ def __repr__(self):
+ """Code-like representation of `Download`."""
+ return str(self)
+
+ def __eq__(self, other):
+ """Compare Downloads based on version numbers."""
+ if (
+ self.url != other.url
+ or self.filename != other.filename
+ or self.version != other.version
+ or self.prerelease != other.prerelease
+ ):
+ return False
+ return True
+
+ def __ne__(self, other):
+ """Compare Downloads based on version numbers."""
+ return not self.__eq__(other)
+
+ def __lt__(self, other):
+ """Compare Downloads based on version numbers."""
+ if self.version != other.version:
+ return self.version < other.version
+ return self.alfred_version < other.alfred_version
+
+
+class Version(object):
+ """Mostly semantic versioning.
+
+ The main difference to proper :ref:`semantic versioning `
+ is that this implementation doesn't require a minor or patch version.
+
+ Version strings may also be prefixed with "v", e.g.:
+
+ >>> v = Version('v1.1.1')
+ >>> v.tuple
+ (1, 1, 1, '')
+
+ >>> v = Version('2.0')
+ >>> v.tuple
+ (2, 0, 0, '')
+
+ >>> Version('3.1-beta').tuple
+ (3, 1, 0, 'beta')
+
+ >>> Version('1.0.1') > Version('0.0.1')
+ True
+ """
+
+ #: Match version and pre-release/build information in version strings
+ match_version = re.compile(r"([0-9][0-9\.]*)(.+)?").match
+
+ def __init__(self, vstr):
+ """Create new `Version` object.
+
+ Args:
+ vstr (basestring): Semantic version string.
+ """
+ if not vstr:
+ raise ValueError("invalid version number: {!r}".format(vstr))
+
+ self.vstr = vstr
+ self.major = 0
+ self.minor = 0
+ self.patch = 0
+ self.suffix = ""
+ self.build = ""
+ self._parse(vstr)
+
+ def _parse(self, vstr):
+ vstr = str(vstr)
+ if vstr.startswith("v"):
+ m = self.match_version(vstr[1:])
+ else:
+ m = self.match_version(vstr)
+ if not m:
+ raise ValueError("invalid version number: " + vstr)
+
+ version, suffix = m.groups()
+ parts = self._parse_dotted_string(version)
+ self.major = parts.pop(0)
+ if len(parts):
+ self.minor = parts.pop(0)
+ if len(parts):
+ self.patch = parts.pop(0)
+ if not len(parts) == 0:
+ raise ValueError("version number too long: " + vstr)
+
+ if suffix:
+ # Build info
+ idx = suffix.find("+")
+ if idx > -1:
+ self.build = suffix[idx + 1 :]
+ suffix = suffix[:idx]
+ if suffix:
+ if not suffix.startswith("-"):
+ raise ValueError("suffix must start with - : " + suffix)
+ self.suffix = suffix[1:]
+
+ def _parse_dotted_string(self, s):
+ """Parse string ``s`` into list of ints and strings."""
+ parsed = []
+ parts = s.split(".")
+ for p in parts:
+ if p.isdigit():
+ p = int(p)
+ parsed.append(p)
+ return parsed
+
+ @property
+ def tuple(self):
+ """Version number as a tuple of major, minor, patch, pre-release."""
+ return (self.major, self.minor, self.patch, self.suffix)
+
+ def __lt__(self, other):
+ """Implement comparison."""
+ if not isinstance(other, Version):
+ raise ValueError("not a Version instance: {0!r}".format(other))
+ t = self.tuple[:3]
+ o = other.tuple[:3]
+ if t < o:
+ return True
+ if t == o: # We need to compare suffixes
+ if self.suffix and not other.suffix:
+ return True
+ if other.suffix and not self.suffix:
+ return False
+
+ self_suffix = self._parse_dotted_string(self.suffix)
+ other_suffix = self._parse_dotted_string(other.suffix)
+
+ for s, o in zip_longest(self_suffix, other_suffix):
+ if s is None: # shorter value wins
+ return True
+ elif o is None: # longer value loses
+ return False
+ elif type(s) != type(o): # type coersion
+ s, o = str(s), str(o)
+ if s == o: # next if the same compare
+ continue
+ return s < o # finally compare
+ # t > o
+ return False
+
+ def __eq__(self, other):
+ """Implement comparison."""
+ if not isinstance(other, Version):
+ raise ValueError("not a Version instance: {0!r}".format(other))
+ return self.tuple == other.tuple
+
+ def __ne__(self, other):
+ """Implement comparison."""
+ return not self.__eq__(other)
+
+ def __gt__(self, other):
+ """Implement comparison."""
+ if not isinstance(other, Version):
+ raise ValueError("not a Version instance: {0!r}".format(other))
+ return other.__lt__(self)
+
+ def __le__(self, other):
+ """Implement comparison."""
+ if not isinstance(other, Version):
+ raise ValueError("not a Version instance: {0!r}".format(other))
+ return not other.__lt__(self)
+
+ def __ge__(self, other):
+ """Implement comparison."""
+ return not self.__lt__(other)
+
+ def __str__(self):
+ """Return semantic version string."""
+ vstr = "{0}.{1}.{2}".format(self.major, self.minor, self.patch)
+ if self.suffix:
+ vstr = "{0}-{1}".format(vstr, self.suffix)
+ if self.build:
+ vstr = "{0}+{1}".format(vstr, self.build)
+ return vstr
+
+ def __repr__(self):
+ """Return 'code' representation of `Version`."""
+ return "Version('{0}')".format(str(self))
+
+
+def retrieve_download(dl):
+ """Saves a download to a temporary file and returns path.
+
+ .. versionadded: 1.37
+
+ Args:
+ url (unicode): URL to .alfredworkflow file in GitHub repo
+
+ Returns:
+ unicode: path to downloaded file
+
+ """
+ if not match_workflow(dl.filename):
+ raise ValueError("attachment not a workflow: " + dl.filename)
+
+ path = os.path.join(tempfile.gettempdir(), dl.filename)
+ wf().logger.debug("downloading update from " "%r to %r ...", dl.url, path)
+
+ r = request.urlopen(dl.url)
+
+ with atomic_writer(path, "wb") as file_obj:
+ file_obj.write(r.read())
+
+ return path
+
+
+def build_api_url(repo):
+ """Generate releases URL from GitHub repo.
+
+ Args:
+ repo (unicode): Repo name in form ``username/repo``
+
+ Returns:
+ unicode: URL to the API endpoint for the repo's releases
+
+ """
+ if len(repo.split("/")) != 2:
+ raise ValueError("invalid GitHub repo: {!r}".format(repo))
+
+ return RELEASES_BASE.format(repo)
+
+
+def get_downloads(repo):
+ """Load available ``Download``s for GitHub repo.
+
+ .. versionadded: 1.37
+
+ Args:
+ repo (unicode): GitHub repo to load releases for.
+
+ Returns:
+ list: Sequence of `Download` contained in GitHub releases.
+ """
+ url = build_api_url(repo)
+
+ def _fetch():
+ wf().logger.info("retrieving releases for %r ...", repo)
+ r = request.urlopen(url)
+ return r.read()
+
+ key = "github-releases-" + repo.replace("/", "-")
+ js = wf().cached_data(key, _fetch, max_age=60)
+
+ return Download.from_releases(js)
+
+
+def latest_download(dls, alfred_version=None, prereleases=False):
+ """Return newest `Download`."""
+ alfred_version = alfred_version or os.getenv("alfred_version")
+ version = None
+ if alfred_version:
+ version = Version(alfred_version)
+
+ dls.sort(reverse=True)
+ for dl in dls:
+ if dl.prerelease and not prereleases:
+ wf().logger.debug("ignored prerelease: %s", dl.version)
+ continue
+ if version and dl.alfred_version > version:
+ wf().logger.debug(
+ "ignored incompatible (%s > %s): %s",
+ dl.alfred_version,
+ version,
+ dl.filename,
+ )
+ continue
+
+ wf().logger.debug("latest version: %s (%s)", dl.version, dl.filename)
+ return dl
+
+ return None
+
+
+def check_update(repo, current_version, prereleases=False, alfred_version=None):
+ """Check whether a newer release is available on GitHub.
+
+ Args:
+ repo (unicode): ``username/repo`` for workflow's GitHub repo
+ current_version (unicode): the currently installed version of the
+ workflow. :ref:`Semantic versioning ` is required.
+ prereleases (bool): Whether to include pre-releases.
+ alfred_version (unicode): version of currently-running Alfred.
+ if empty, defaults to ``$alfred_version`` environment variable.
+
+ Returns:
+ bool: ``True`` if an update is available, else ``False``
+
+ If an update is available, its version number and download URL will
+ be cached.
+
+ """
+ key = "__workflow_latest_version"
+ # data stored when no update is available
+ no_update = {"available": False, "download": None, "version": None}
+ current = Version(current_version)
+
+ dls = get_downloads(repo)
+ if not len(dls):
+ wf().logger.warning("no valid downloads for %s", repo)
+ wf().cache_data(key, no_update)
+ return False
+
+ wf().logger.info("%d download(s) for %s", len(dls), repo)
+
+ dl = latest_download(dls, alfred_version, prereleases)
+
+ if not dl:
+ wf().logger.warning("no compatible downloads for %s", repo)
+ wf().cache_data(key, no_update)
+ return False
+
+ wf().logger.debug("latest=%r, installed=%r", dl.version, current)
+
+ if dl.version > current:
+ wf().cache_data(
+ key, {"version": str(dl.version), "download": dl.dict, "available": True}
+ )
+ return True
+
+ wf().cache_data(key, no_update)
+ return False
+
+
+def install_update():
+ """If a newer release is available, download and install it.
+
+ :returns: ``True`` if an update is installed, else ``False``
+
+ """
+ key = "__workflow_latest_version"
+ # data stored when no update is available
+ no_update = {"available": False, "download": None, "version": None}
+ status = wf().cached_data(key, max_age=0)
+
+ if not status or not status.get("available"):
+ wf().logger.info("no update available")
+ return False
+
+ dl = status.get("download")
+ if not dl:
+ wf().logger.info("no download information")
+ return False
+
+ path = retrieve_download(Download.from_dict(dl))
+
+ wf().logger.info("installing updated workflow ...")
+ subprocess.call(["open", path]) # nosec
+
+ wf().cache_data(key, no_update)
+ return True
+
+
+if __name__ == "__main__": # pragma: nocover
+ import sys
+
+ prereleases = False
+
+ def show_help(status=0):
+ """Print help message."""
+ print("usage: update.py (check|install) " "[--prereleases] ")
+ sys.exit(status)
+
+ argv = sys.argv[:]
+ if "-h" in argv or "--help" in argv:
+ show_help()
+
+ if "--prereleases" in argv:
+ argv.remove("--prereleases")
+ prereleases = True
+
+ if len(argv) != 4:
+ show_help(1)
+
+ action = argv[1]
+ repo = argv[2]
+ version = argv[3]
+
+ try:
+
+ if action == "check":
+ check_update(repo, version, prereleases)
+ elif action == "install":
+ install_update()
+ else:
+ show_help(1)
+
+ except Exception as err: # ensure traceback is in log file
+ wf().logger.exception(err)
+ raise err
diff --git a/src/workflow/util.py b/src/workflow/util.py
new file mode 100644
index 0000000..998456b
--- /dev/null
+++ b/src/workflow/util.py
@@ -0,0 +1,647 @@
+#!/usr/bin/env python
+# encoding: utf-8
+#
+# Copyright (c) 2017 Dean Jackson
+#
+# MIT Licence. See http://opensource.org/licenses/MIT
+#
+# Created on 2017-12-17
+#
+
+"""A selection of helper functions useful for building workflows."""
+
+
+import atexit
+import errno
+import fcntl
+import functools
+import json
+import os
+import signal
+import subprocess
+import sys
+import time
+from collections import namedtuple
+from contextlib import contextmanager
+from threading import Event
+
+# JXA scripts to call Alfred's API via the Scripting Bridge
+# {app} is automatically replaced with "Alfred 3" or
+# "com.runningwithcrayons.Alfred" depending on version.
+#
+# Open Alfred in search (regular) mode
+JXA_SEARCH = "Application({app}).search({arg});"
+# Open Alfred's File Actions on an argument
+JXA_ACTION = "Application({app}).action({arg});"
+# Open Alfred's navigation mode at path
+JXA_BROWSE = "Application({app}).browse({arg});"
+# Set the specified theme
+JXA_SET_THEME = "Application({app}).setTheme({arg});"
+# Call an External Trigger
+JXA_TRIGGER = "Application({app}).runTrigger({arg}, {opts});"
+# Save a variable to the workflow configuration sheet/info.plist
+JXA_SET_CONFIG = "Application({app}).setConfiguration({arg}, {opts});"
+# Delete a variable from the workflow configuration sheet/info.plist
+JXA_UNSET_CONFIG = "Application({app}).removeConfiguration({arg}, {opts});"
+# Tell Alfred to reload a workflow from disk
+JXA_RELOAD_WORKFLOW = "Application({app}).reloadWorkflow({arg});"
+
+
+class AcquisitionError(Exception):
+ """Raised if a lock cannot be acquired."""
+
+
+AppInfo = namedtuple("AppInfo", ["name", "path", "bundleid"])
+"""Information about an installed application.
+
+Returned by :func:`appinfo`. All attributes are Unicode.
+
+.. py:attribute:: name
+
+ Name of the application, e.g. ``u'Safari'``.
+
+.. py:attribute:: path
+
+ Path to the application bundle, e.g. ``u'/Applications/Safari.app'``.
+
+.. py:attribute:: bundleid
+
+ Application's bundle ID, e.g. ``u'com.apple.Safari'``.
+
+"""
+
+
+def jxa_app_name():
+ """Return name of application to call currently running Alfred.
+
+ .. versionadded: 1.37
+
+ Returns 'Alfred 3' or 'com.runningwithcrayons.Alfred' depending
+ on which version of Alfred is running.
+
+ This name is suitable for use with ``Application(name)`` in JXA.
+
+ Returns:
+ unicode: Application name or ID.
+
+ """
+ if os.getenv("alfred_version", "").startswith("3"):
+ # Alfred 3
+ return "Alfred 3"
+ # Alfred 4+
+ return "com.runningwithcrayons.Alfred"
+
+
+def unicodify(s, encoding="utf-8", norm=None):
+ """Ensure string is Unicode.
+
+ .. versionadded:: 1.31
+
+ Decode encoded strings using ``encoding`` and normalise Unicode
+ to form ``norm`` if specified.
+
+ Args:
+ s (str): String to decode. May also be Unicode.
+ encoding (str, optional): Encoding to use on bytestrings.
+ norm (None, optional): Normalisation form to apply to Unicode string.
+
+ Returns:
+ unicode: Decoded, optionally normalised, Unicode string.
+
+ """
+ if not isinstance(s, str):
+ s = str(s, encoding)
+
+ if norm:
+ from unicodedata import normalize
+
+ s = normalize(norm, s)
+
+ return s
+
+
+def utf8ify(s):
+ """Ensure string is a bytestring.
+
+ .. versionadded:: 1.31
+
+ Returns `str` objects unchanced, encodes `unicode` objects to
+ UTF-8, and calls :func:`str` on anything else.
+
+ Args:
+ s (object): A Python object
+
+ Returns:
+ str: UTF-8 string or string representation of s.
+
+ """
+ if isinstance(s, str):
+ return s
+
+ if isinstance(s, str):
+ return s.encode("utf-8")
+
+ return str(s)
+
+
+def applescriptify(s):
+ """Escape string for insertion into an AppleScript string.
+
+ .. versionadded:: 1.31
+
+ Replaces ``"`` with `"& quote &"`. Use this function if you want
+ to insert a string into an AppleScript script:
+
+ >>> applescriptify('g "python" test')
+ 'g " & quote & "python" & quote & "test'
+
+ Args:
+ s (unicode): Unicode string to escape.
+
+ Returns:
+ unicode: Escaped string.
+
+ """
+ return s.replace('"', '" & quote & "')
+
+
+def run_command(cmd, **kwargs):
+ """Run a command and return the output.
+
+ .. versionadded:: 1.31
+
+ A thin wrapper around :func:`subprocess.check_output` that ensures
+ all arguments are encoded to UTF-8 first.
+
+ Args:
+ cmd (list): Command arguments to pass to :func:`~subprocess.check_output`.
+ **kwargs: Keyword arguments to pass to :func:`~subprocess.check_output`.
+
+ Returns:
+ str: Output returned by :func:`~subprocess.check_output`.
+
+ """
+ cmd = [str(s) for s in cmd]
+ return subprocess.check_output(cmd, **kwargs).decode()
+
+
+def run_applescript(script, *args, **kwargs):
+ """Execute an AppleScript script and return its output.
+
+ .. versionadded:: 1.31
+
+ Run AppleScript either by filepath or code. If ``script`` is a valid
+ filepath, that script will be run, otherwise ``script`` is treated
+ as code.
+
+ Args:
+ script (str, optional): Filepath of script or code to run.
+ *args: Optional command-line arguments to pass to the script.
+ **kwargs: Pass ``lang`` to run a language other than AppleScript.
+ Any other keyword arguments are passed to :func:`run_command`.
+
+ Returns:
+ str: Output of run command.
+
+ """
+ lang = "AppleScript"
+ if "lang" in kwargs:
+ lang = kwargs["lang"]
+ del kwargs["lang"]
+
+ cmd = ["/usr/bin/osascript", "-l", lang]
+
+ if os.path.exists(script):
+ cmd += [script]
+ else:
+ cmd += ["-e", script]
+
+ cmd.extend(args)
+
+ return run_command(cmd, **kwargs)
+
+
+def run_jxa(script, *args):
+ """Execute a JXA script and return its output.
+
+ .. versionadded:: 1.31
+
+ Wrapper around :func:`run_applescript` that passes ``lang=JavaScript``.
+
+ Args:
+ script (str): Filepath of script or code to run.
+ *args: Optional command-line arguments to pass to script.
+
+ Returns:
+ str: Output of script.
+
+ """
+ return run_applescript(script, *args, lang="JavaScript")
+
+
+def run_trigger(name, bundleid=None, arg=None):
+ """Call an Alfred External Trigger.
+
+ .. versionadded:: 1.31
+
+ If ``bundleid`` is not specified, the bundle ID of the calling
+ workflow is used.
+
+ Args:
+ name (str): Name of External Trigger to call.
+ bundleid (str, optional): Bundle ID of workflow trigger belongs to.
+ arg (str, optional): Argument to pass to trigger.
+
+ """
+ bundleid = bundleid or os.getenv("alfred_workflow_bundleid")
+ appname = jxa_app_name()
+ opts = {"inWorkflow": bundleid}
+ if arg:
+ opts["withArgument"] = arg
+
+ script = JXA_TRIGGER.format(
+ app=json.dumps(appname),
+ arg=json.dumps(name),
+ opts=json.dumps(opts, sort_keys=True),
+ )
+
+ run_applescript(script, lang="JavaScript")
+
+
+def set_theme(theme_name):
+ """Change Alfred's theme.
+
+ .. versionadded:: 1.39.0
+
+ Args:
+ theme_name (unicode): Name of theme Alfred should use.
+
+ """
+ appname = jxa_app_name()
+ script = JXA_SET_THEME.format(app=json.dumps(appname), arg=json.dumps(theme_name))
+ run_applescript(script, lang="JavaScript")
+
+
+def set_config(name, value, bundleid=None, exportable=False):
+ """Set a workflow variable in ``info.plist``.
+
+ .. versionadded:: 1.33
+
+ If ``bundleid`` is not specified, the bundle ID of the calling
+ workflow is used.
+
+ Args:
+ name (str): Name of variable to set.
+ value (str): Value to set variable to.
+ bundleid (str, optional): Bundle ID of workflow variable belongs to.
+ exportable (bool, optional): Whether variable should be marked
+ as exportable (Don't Export checkbox).
+
+ """
+ bundleid = bundleid or os.getenv("alfred_workflow_bundleid")
+ appname = jxa_app_name()
+ opts = {"toValue": value, "inWorkflow": bundleid, "exportable": exportable}
+
+ script = JXA_SET_CONFIG.format(
+ app=json.dumps(appname),
+ arg=json.dumps(name),
+ opts=json.dumps(opts, sort_keys=True),
+ )
+
+ run_applescript(script, lang="JavaScript")
+
+
+def unset_config(name, bundleid=None):
+ """Delete a workflow variable from ``info.plist``.
+
+ .. versionadded:: 1.33
+
+ If ``bundleid`` is not specified, the bundle ID of the calling
+ workflow is used.
+
+ Args:
+ name (str): Name of variable to delete.
+ bundleid (str, optional): Bundle ID of workflow variable belongs to.
+
+ """
+ bundleid = bundleid or os.getenv("alfred_workflow_bundleid")
+ appname = jxa_app_name()
+ opts = {"inWorkflow": bundleid}
+
+ script = JXA_UNSET_CONFIG.format(
+ app=json.dumps(appname),
+ arg=json.dumps(name),
+ opts=json.dumps(opts, sort_keys=True),
+ )
+
+ run_applescript(script, lang="JavaScript")
+
+
+def search_in_alfred(query=None):
+ """Open Alfred with given search query.
+
+ .. versionadded:: 1.39.0
+
+ Omit ``query`` to simply open Alfred's main window.
+
+ Args:
+ query (unicode, optional): Search query.
+
+ """
+ query = query or ""
+ appname = jxa_app_name()
+ script = JXA_SEARCH.format(app=json.dumps(appname), arg=json.dumps(query))
+ run_applescript(script, lang="JavaScript")
+
+
+def browse_in_alfred(path):
+ """Open Alfred's filesystem navigation mode at ``path``.
+
+ .. versionadded:: 1.39.0
+
+ Args:
+ path (unicode): File or directory path.
+
+ """
+ appname = jxa_app_name()
+ script = JXA_BROWSE.format(app=json.dumps(appname), arg=json.dumps(path))
+ run_applescript(script, lang="JavaScript")
+
+
+def action_in_alfred(paths):
+ """Action the give filepaths in Alfred.
+
+ .. versionadded:: 1.39.0
+
+ Args:
+ paths (list): Unicode paths to files/directories to action.
+
+ """
+ appname = jxa_app_name()
+ script = JXA_ACTION.format(app=json.dumps(appname), arg=json.dumps(paths))
+ run_applescript(script, lang="JavaScript")
+
+
+def reload_workflow(bundleid=None):
+ """Tell Alfred to reload a workflow from disk.
+
+ .. versionadded:: 1.39.0
+
+ If ``bundleid`` is not specified, the bundle ID of the calling
+ workflow is used.
+
+ Args:
+ bundleid (unicode, optional): Bundle ID of workflow to reload.
+
+ """
+ bundleid = bundleid or os.getenv("alfred_workflow_bundleid")
+ appname = jxa_app_name()
+ script = JXA_RELOAD_WORKFLOW.format(
+ app=json.dumps(appname), arg=json.dumps(bundleid)
+ )
+
+ run_applescript(script, lang="JavaScript")
+
+
+def appinfo(name):
+ """Get information about an installed application.
+
+ .. versionadded:: 1.31
+
+ Args:
+ name (str): Name of application to look up.
+
+ Returns:
+ AppInfo: :class:`AppInfo` tuple or ``None`` if app isn't found.
+
+ """
+ cmd = [
+ "mdfind",
+ "-onlyin",
+ "/Applications",
+ "-onlyin",
+ "/System/Applications",
+ "-onlyin",
+ os.path.expanduser("~/Applications"),
+ "(kMDItemContentTypeTree == com.apple.application &&"
+ '(kMDItemDisplayName == "{0}" || kMDItemFSName == "{0}.app"))'.format(name),
+ ]
+
+ output = run_command(cmd).strip()
+ if not output:
+ return None
+
+ path = output.split("\n")[0]
+
+ cmd = ["mdls", "-raw", "-name", "kMDItemCFBundleIdentifier", path]
+ bid = run_command(cmd).strip()
+ if not bid: # pragma: no cover
+ return None
+
+ return AppInfo(name, path, bid)
+
+
+@contextmanager
+def atomic_writer(fpath, mode):
+ """Atomic file writer.
+
+ .. versionadded:: 1.12
+
+ Context manager that ensures the file is only written if the write
+ succeeds. The data is first written to a temporary file.
+
+ :param fpath: path of file to write to.
+ :type fpath: ``unicode``
+ :param mode: sames as for :func:`open`
+ :type mode: string
+
+ """
+ suffix = ".{}.tmp".format(os.getpid())
+ temppath = fpath + suffix
+ with open(temppath, mode) as fp:
+ try:
+ yield fp
+ os.rename(temppath, fpath)
+ finally:
+ try:
+ os.remove(temppath)
+ except OSError:
+ pass
+
+
+class LockFile(object):
+ """Context manager to protect filepaths with lockfiles.
+
+ .. versionadded:: 1.13
+
+ Creates a lockfile alongside ``protected_path``. Other ``LockFile``
+ instances will refuse to lock the same path.
+
+ >>> path = '/path/to/file'
+ >>> with LockFile(path):
+ >>> with open(path, 'w') as fp:
+ >>> fp.write(data)
+
+ Args:
+ protected_path (unicode): File to protect with a lockfile
+ timeout (float, optional): Raises an :class:`AcquisitionError`
+ if lock cannot be acquired within this number of seconds.
+ If ``timeout`` is 0 (the default), wait forever.
+ delay (float, optional): How often to check (in seconds) if
+ lock has been released.
+
+ Attributes:
+ delay (float): How often to check (in seconds) whether the lock
+ can be acquired.
+ lockfile (unicode): Path of the lockfile.
+ timeout (float): How long to wait to acquire the lock.
+
+ """
+
+ def __init__(self, protected_path, timeout=0.0, delay=0.05):
+ """Create new :class:`LockFile` object."""
+ self.lockfile = protected_path + ".lock"
+ self._lockfile = None
+ self.timeout = timeout
+ self.delay = delay
+ self._lock = Event()
+ atexit.register(self.release)
+
+ @property
+ def locked(self):
+ """``True`` if file is locked by this instance."""
+ return self._lock.is_set()
+
+ def acquire(self, blocking=True):
+ """Acquire the lock if possible.
+
+ If the lock is in use and ``blocking`` is ``False``, return
+ ``False``.
+
+ Otherwise, check every :attr:`delay` seconds until it acquires
+ lock or exceeds attr:`timeout` and raises an :class:`AcquisitionError`.
+
+ """
+ if self.locked and not blocking:
+ return False
+
+ start = time.time()
+ while True:
+ # Raise error if we've been waiting too long to acquire the lock
+ if self.timeout and (time.time() - start) >= self.timeout:
+ raise AcquisitionError("lock acquisition timed out")
+
+ # If already locked, wait then try again
+ if self.locked:
+ time.sleep(self.delay)
+ continue
+
+ # Create in append mode so we don't lose any contents
+ if self._lockfile is None:
+ self._lockfile = open(self.lockfile, "a")
+
+ # Try to acquire the lock
+ try:
+ fcntl.lockf(self._lockfile, fcntl.LOCK_EX | fcntl.LOCK_NB)
+ self._lock.set()
+ break
+ except IOError as err: # pragma: no cover
+ if err.errno not in (errno.EACCES, errno.EAGAIN):
+ raise
+
+ # Don't try again
+ if not blocking: # pragma: no cover
+ return False
+
+ # Wait, then try again
+ time.sleep(self.delay)
+
+ return True
+
+ def release(self):
+ """Release the lock by deleting `self.lockfile`."""
+ if not self._lock.is_set():
+ return False
+
+ try:
+ fcntl.lockf(self._lockfile, fcntl.LOCK_UN)
+ except IOError: # pragma: no cover
+ pass
+ finally:
+ self._lock.clear()
+ self._lockfile = None
+ try:
+ os.unlink(self.lockfile)
+ except OSError: # pragma: no cover
+ pass
+
+ return True # noqa: B012
+
+ def __enter__(self):
+ """Acquire lock."""
+ self.acquire()
+ return self
+
+ def __exit__(self, typ, value, traceback):
+ """Release lock."""
+ self.release()
+
+ def __del__(self):
+ """Clear up `self.lockfile`."""
+ self.release() # pragma: no cover
+
+
+class uninterruptible(object):
+ """Decorator that postpones SIGTERM until wrapped function returns.
+
+ .. versionadded:: 1.12
+
+ .. important:: This decorator is NOT thread-safe.
+
+ As of version 2.7, Alfred allows Script Filters to be killed. If
+ your workflow is killed in the middle of critical code (e.g.
+ writing data to disk), this may corrupt your workflow's data.
+
+ Use this decorator to wrap critical functions that *must* complete.
+ If the script is killed while a wrapped function is executing,
+ the SIGTERM will be caught and handled after your function has
+ finished executing.
+
+ Alfred-Workflow uses this internally to ensure its settings, data
+ and cache writes complete.
+
+ """
+
+ def __init__(self, func, class_name=""):
+ """Decorate `func`."""
+ self.func = func
+ functools.update_wrapper(self, func)
+ self._caught_signal = None
+
+ def signal_handler(self, signum, frame):
+ """Called when process receives SIGTERM."""
+ self._caught_signal = (signum, frame)
+
+ def __call__(self, *args, **kwargs):
+ """Trap ``SIGTERM`` and call wrapped function."""
+ self._caught_signal = None
+ # Register handler for SIGTERM, then call `self.func`
+ self.old_signal_handler = signal.getsignal(signal.SIGTERM)
+ signal.signal(signal.SIGTERM, self.signal_handler)
+
+ self.func(*args, **kwargs)
+
+ # Restore old signal handler
+ signal.signal(signal.SIGTERM, self.old_signal_handler)
+
+ # Handle any signal caught during execution
+ if self._caught_signal is not None:
+ signum, frame = self._caught_signal
+ if callable(self.old_signal_handler):
+ self.old_signal_handler(signum, frame)
+ elif self.old_signal_handler == signal.SIG_DFL:
+ sys.exit(0)
+
+ def __get__(self, obj=None, klass=None):
+ """Decorator API."""
+ return self.__class__(self.func.__get__(obj, klass), klass.__name__)
diff --git a/src/workflow/version b/src/workflow/version
new file mode 100644
index 0000000..ebc91b4
--- /dev/null
+++ b/src/workflow/version
@@ -0,0 +1 @@
+1.40.0
\ No newline at end of file
diff --git a/workflow/web.py b/src/workflow/web.py
similarity index 80%
rename from workflow/web.py
rename to src/workflow/web.py
index d64bb6f..921ab8b 100644
--- a/workflow/web.py
+++ b/src/workflow/web.py
@@ -4,11 +4,13 @@
#
# MIT Licence. See http://opensource.org/licenses/MIT
#
-# Created on 2014-02-15
+# modified on 2022-02-04 by Kyeongwon Lee
#
"""Lightweight HTTP library with a requests-like interface."""
+from __future__ import absolute_import, print_function
+
import codecs
import json
import mimetypes
@@ -19,12 +21,14 @@
import string
import unicodedata
import urllib
-import urllib2
-import urlparse
+import urllib.parse as urlparse
+import urllib.request as request3
import zlib
+__version__ = open(os.path.join(os.path.dirname(__file__), 'version')).read()
-USER_AGENT = u'Alfred-Workflow/1.19 (+http://www.deanishe.net/alfred-workflow)'
+USER_AGENT = (u'Alfred-Workflow/' + __version__ +
+ ' (+http://www.deanishe.net/alfred-workflow)')
# Valid characters for multipart form data boundaries
BOUNDARY_CHARS = string.digits + string.ascii_letters
@@ -88,18 +92,18 @@ def str_dict(dic):
else:
dic2 = {}
for k, v in dic.items():
- if isinstance(k, unicode):
+ if isinstance(k, str):
k = k.encode('utf-8')
- if isinstance(v, unicode):
+ if isinstance(v, str):
v = v.encode('utf-8')
dic2[k] = v
return dic2
-
-class NoRedirectHandler(urllib2.HTTPRedirectHandler):
+class NoRedirectHandler(request3.HTTPRedirectHandler):
"""Prevent redirections."""
def redirect_request(self, *args):
+ """Ignore redirect."""
return None
@@ -119,7 +123,7 @@ class CaseInsensitiveDictionary(dict):
def __init__(self, initval=None):
"""Create new case-insensitive dictionary."""
if isinstance(initval, dict):
- for key, value in initval.iteritems():
+ for key, value in initval.items():
self.__setitem__(key, value)
elif isinstance(initval, list):
@@ -136,6 +140,7 @@ def __setitem__(self, key, value):
return dict.__setitem__(self, key.lower(), {'key': key, 'val': value})
def get(self, key, default=None):
+ """Return value for case-insensitive key or default."""
try:
v = dict.__getitem__(self, key.lower())
except KeyError:
@@ -144,31 +149,50 @@ def get(self, key, default=None):
return v['val']
def update(self, other):
+ """Update values from other ``dict``."""
for k, v in other.items():
self[k] = v
def items(self):
- return [(v['key'], v['val']) for v in dict.itervalues(self)]
+ """Return ``(key, value)`` pairs."""
+ return [(v['key'], v['val']) for v in iter(dict(self).values())]
def keys(self):
- return [v['key'] for v in dict.itervalues(self)]
+ """Return original keys."""
+ return [v['key'] for v in iter(dict(self).values())]
def values(self):
- return [v['val'] for v in dict.itervalues(self)]
+ """Return all values."""
+ return [v['val'] for v in iter(dict(self).values())]
def iteritems(self):
- for v in dict.itervalues(self):
+ """Iterate over ``(key, value)`` pairs."""
+ for v in iter(dict(self).values()):
yield v['key'], v['val']
def iterkeys(self):
- for v in dict.itervalues(self):
+ """Iterate over original keys."""
+ for v in iter(dict(self).values()):
yield v['key']
def itervalues(self):
- for v in dict.itervalues(self):
+ """Interate over values."""
+ for v in iter(dict(self).values()):
yield v['val']
+class Request(request3.Request):
+ """Subclass of :class:`request3.Request` that supports custom methods."""
+
+ def __init__(self, *args, **kwargs):
+ """Create a new :class:`Request`."""
+ self._method = kwargs.pop('method', None)
+ request3.Request.__init__(self, *args, **kwargs)
+
+ def get_method(self):
+ return self._method.upper()
+
+
class Response(object):
"""
Returned by :func:`request` / :func:`get` / :func:`post` functions.
@@ -191,7 +215,7 @@ class Response(object):
def __init__(self, request, stream=False):
"""Call `request` with :mod:`urllib2` and process results.
- :param request: :class:`urllib2.Request` instance
+ :param request: :class:`Request` instance
:param stream: Whether to stream response or retrieve it all at once
:type stream: bool
@@ -211,8 +235,8 @@ def __init__(self, request, stream=False):
# Execute query
try:
- self.raw = urllib2.urlopen(request)
- except urllib2.HTTPError as err:
+ self.raw = request3.urlopen(request)
+ except request3.HTTPError as err:
self.error = err
try:
self.url = err.geturl()
@@ -231,8 +255,8 @@ def __init__(self, request, stream=False):
# Parse additional info if request succeeded
if not self.error:
headers = self.raw.info()
- self.transfer_encoding = headers.getencoding()
- self.mimetype = headers.gettype()
+ self.transfer_encoding = headers.get_content_charset()
+ self.mimetype = headers.get("content-type")
for key in headers.keys():
self.headers[key.lower()] = headers.get(key)
@@ -240,8 +264,8 @@ def __init__(self, request, stream=False):
# Transfer-Encoding appears to not be used in the wild
# (contrary to the HTTP standard), but no harm in testing
# for it
- if ('gzip' in headers.get('content-encoding', '') or
- 'gzip' in headers.get('transfer-encoding', '')):
+ if 'gzip' in headers.get('content-encoding', '') or \
+ 'gzip' in headers.get('transfer-encoding', ''):
self._gzipped = True
@property
@@ -250,6 +274,7 @@ def stream(self):
Returns:
bool: `True` if response is streamed.
+
"""
return self._stream
@@ -268,7 +293,7 @@ def json(self):
:rtype: list, dict or unicode
"""
- return json.loads(self.content, self.encoding or 'utf-8')
+ return json.loads(self.content)
@property
def encoding(self):
@@ -317,8 +342,7 @@ def text(self):
"""
if self.encoding:
- return unicodedata.normalize('NFC', unicode(self.content,
- self.encoding))
+ return unicodedata.normalize('NFC', str(self.content))
return self.content
def iter_content(self, chunk_size=4096, decode_unicode=False):
@@ -343,20 +367,18 @@ def iter_content(self, chunk_size=4096, decode_unicode=False):
"`content` has already been read from this Response.")
def decode_stream(iterator, r):
-
- decoder = codecs.getincrementaldecoder(r.encoding)(errors='replace')
+ dec = codecs.getincrementaldecoder(r.encoding)(errors='replace')
for chunk in iterator:
- data = decoder.decode(chunk)
+ data = dec.decode(chunk)
if data:
yield data
- data = decoder.decode(b'', final=True)
+ data = dec.decode(b'', final=True)
if data: # pragma: no cover
yield data
def generate():
-
if self._gzipped:
decoder = zlib.decompressobj(16 + zlib.MAX_WBITS)
@@ -399,7 +421,7 @@ def save_to_path(self, filepath):
def raise_for_status(self):
"""Raise stored error if one occurred.
- error will be instance of :class:`urllib2.HTTPError`
+ error will be instance of :class:`request3.HTTPError`
"""
if self.error is not None:
raise self.error
@@ -415,27 +437,21 @@ def _get_encoding(self):
headers = self.raw.info()
encoding = None
- if headers.getparam('charset'):
- encoding = headers.getparam('charset')
-
- # HTTP Content-Type header
- for param in headers.getplist():
- if param.startswith('charset='):
- encoding = param[8:]
- break
+ if headers.get_param('charset'):
+ encoding = headers.get_param('charset')
if not self.stream: # Try sniffing response content
# Encoding declared in document should override HTTP headers
if self.mimetype == 'text/html': # sniff HTML headers
- m = re.search("""""",
+ m = re.search(r"""""",
self.content)
if m:
encoding = m.group(1)
- elif ((self.mimetype.startswith('application/') or
- self.mimetype.startswith('text/')) and
- 'xml' in self.mimetype):
- m = re.search("""]*\?>""",
+ elif ((self.mimetype.startswith('application/')
+ or self.mimetype.startswith('text/'))
+ and 'xml' in self.mimetype):
+ m = re.search(r"""]*\?>""",
self.content)
if m:
encoding = m.group(1)
@@ -504,21 +520,21 @@ def request(method, url, params=None, data=None, headers=None, cookies=None,
socket.setdefaulttimeout(timeout)
# Default handlers
- openers = []
+ openers = [request3.ProxyHandler(request3.getproxies())]
if not allow_redirects:
openers.append(NoRedirectHandler())
if auth is not None: # Add authorisation handler
username, password = auth
- password_manager = urllib2.HTTPPasswordMgrWithDefaultRealm()
+ password_manager = request3.HTTPPasswordMgrWithDefaultRealm()
password_manager.add_password(None, url, username, password)
- auth_manager = urllib2.HTTPBasicAuthHandler(password_manager)
+ auth_manager = request3.HTTPBasicAuthHandler(password_manager)
openers.append(auth_manager)
# Install our custom chain of openers
- opener = urllib2.build_opener(*openers)
- urllib2.install_opener(opener)
+ opener = request3.build_opener(*openers)
+ request3.install_opener(opener)
if not headers:
headers = CaseInsensitiveDictionary()
@@ -536,23 +552,19 @@ def request(method, url, params=None, data=None, headers=None, cookies=None,
headers['accept-encoding'] = ', '.join(encodings)
- # Force POST by providing an empty data string
- if method == 'POST' and not data:
- data = ''
-
if files:
if not data:
data = {}
new_headers, data = encode_multipart_formdata(data, files)
headers.update(new_headers)
elif data and isinstance(data, dict):
- data = urllib.urlencode(str_dict(data))
+ data = urlparse.urlencode(str_dict(data))
# Make sure everything is encoded text
headers = str_dict(headers)
- if isinstance(url, unicode):
- url = url.encode('utf-8')
+ # if isinstance(url, str):
+ # url = url.encode('utf-8')
if params: # GET args (POST args are handled in encode_multipart_formdata)
@@ -564,10 +576,10 @@ def request(method, url, params=None, data=None, headers=None, cookies=None,
url_params.update(params)
params = url_params
- query = urllib.urlencode(str_dict(params), doseq=True)
+ query = urlparse.urlencode(str_dict(params), doseq=True)
url = urlparse.urlunsplit((scheme, netloc, path, query, fragment))
- req = urllib2.Request(url, data, headers)
+ req = Request(url, data, headers, method=method)
return Response(req, stream)
@@ -583,6 +595,18 @@ def get(url, params=None, headers=None, cookies=None, auth=None,
stream=stream)
+def delete(url, params=None, data=None, headers=None, cookies=None, auth=None,
+ timeout=60, allow_redirects=True, stream=False):
+ """Initiate a DELETE request. Arguments as for :func:`request`.
+
+ :returns: :class:`Response` instance
+
+ """
+ return request('DELETE', url, params, data, headers=headers,
+ cookies=cookies, auth=auth, timeout=timeout,
+ allow_redirects=allow_redirects, stream=stream)
+
+
def post(url, params=None, data=None, headers=None, cookies=None, files=None,
auth=None, timeout=60, allow_redirects=False, stream=False):
"""Initiate a POST request. Arguments as for :func:`request`.
@@ -594,6 +618,17 @@ def post(url, params=None, data=None, headers=None, cookies=None, files=None,
timeout, allow_redirects, stream)
+def put(url, params=None, data=None, headers=None, cookies=None, files=None,
+ auth=None, timeout=60, allow_redirects=False, stream=False):
+ """Initiate a PUT request. Arguments as for :func:`request`.
+
+ :returns: :class:`Response` instance
+
+ """
+ return request('PUT', url, params, data, headers, cookies, files, auth,
+ timeout, allow_redirects, stream)
+
+
def encode_multipart_formdata(fields, files):
"""Encode form data (``fields``) and ``files`` for POST request.
@@ -628,7 +663,6 @@ def get_content_type(filename):
:rtype: str
"""
-
return mimetypes.guess_type(filename)[0] or 'application/octet-stream'
boundary = '-----' + ''.join(random.choice(BOUNDARY_CHARS)
@@ -638,9 +672,9 @@ def get_content_type(filename):
# Normal form fields
for (name, value) in fields.items():
- if isinstance(name, unicode):
+ if isinstance(name, str):
name = name.encode('utf-8')
- if isinstance(value, unicode):
+ if isinstance(value, str):
value = value.encode('utf-8')
output.append('--' + boundary)
output.append('Content-Disposition: form-data; name="%s"' % name)
@@ -655,11 +689,11 @@ def get_content_type(filename):
mimetype = d[u'mimetype']
else:
mimetype = get_content_type(filename)
- if isinstance(name, unicode):
+ if isinstance(name, str):
name = name.encode('utf-8')
- if isinstance(filename, unicode):
+ if isinstance(filename, str):
filename = filename.encode('utf-8')
- if isinstance(mimetype, unicode):
+ if isinstance(mimetype, str):
mimetype = mimetype.encode('utf-8')
output.append('--' + boundary)
output.append('Content-Disposition: form-data; '
diff --git a/workflow/workflow.py b/src/workflow/workflow.py
similarity index 68%
rename from workflow/workflow.py
rename to src/workflow/workflow.py
index 488ae3c..c33bdf8 100644
--- a/workflow/workflow.py
+++ b/src/workflow/workflow.py
@@ -19,14 +19,8 @@
"""
-from __future__ import print_function, unicode_literals
-import atexit
import binascii
-from contextlib import contextmanager
-import cPickle
-from copy import deepcopy
-import errno
import json
import logging
import logging.handlers
@@ -35,18 +29,25 @@
import plistlib
import re
import shutil
-import signal
import string
import subprocess
import sys
import time
import unicodedata
+from contextlib import contextmanager
+from copy import deepcopy
+from typing import Optional
try:
import xml.etree.cElementTree as ET
except ImportError: # pragma: no cover
import xml.etree.ElementTree as ET
+# imported to maintain API
+from workflow.util import AcquisitionError # noqa: F401
+from workflow.util import LockFile, atomic_writer, uninterruptible
+
+assert sys.version_info[0] == 3
#: Sentinel for properties that haven't been set yet (that might
#: correctly have the value ``None``)
@@ -65,32 +66,32 @@
# The system icons are all in this directory. There are many more than
# are listed here
-ICON_ROOT = '/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources'
+ICON_ROOT = "/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources"
-ICON_ACCOUNT = os.path.join(ICON_ROOT, 'Accounts.icns')
-ICON_BURN = os.path.join(ICON_ROOT, 'BurningIcon.icns')
-ICON_CLOCK = os.path.join(ICON_ROOT, 'Clock.icns')
-ICON_COLOR = os.path.join(ICON_ROOT, 'ProfileBackgroundColor.icns')
+ICON_ACCOUNT = os.path.join(ICON_ROOT, "Accounts.icns")
+ICON_BURN = os.path.join(ICON_ROOT, "BurningIcon.icns")
+ICON_CLOCK = os.path.join(ICON_ROOT, "Clock.icns")
+ICON_COLOR = os.path.join(ICON_ROOT, "ProfileBackgroundColor.icns")
ICON_COLOUR = ICON_COLOR # Queen's English, if you please
-ICON_EJECT = os.path.join(ICON_ROOT, 'EjectMediaIcon.icns')
+ICON_EJECT = os.path.join(ICON_ROOT, "EjectMediaIcon.icns")
# Shown when a workflow throws an error
-ICON_ERROR = os.path.join(ICON_ROOT, 'AlertStopIcon.icns')
-ICON_FAVORITE = os.path.join(ICON_ROOT, 'ToolbarFavoritesIcon.icns')
+ICON_ERROR = os.path.join(ICON_ROOT, "AlertStopIcon.icns")
+ICON_FAVORITE = os.path.join(ICON_ROOT, "ToolbarFavoritesIcon.icns")
ICON_FAVOURITE = ICON_FAVORITE
-ICON_GROUP = os.path.join(ICON_ROOT, 'GroupIcon.icns')
-ICON_HELP = os.path.join(ICON_ROOT, 'HelpIcon.icns')
-ICON_HOME = os.path.join(ICON_ROOT, 'HomeFolderIcon.icns')
-ICON_INFO = os.path.join(ICON_ROOT, 'ToolbarInfo.icns')
-ICON_NETWORK = os.path.join(ICON_ROOT, 'GenericNetworkIcon.icns')
-ICON_NOTE = os.path.join(ICON_ROOT, 'AlertNoteIcon.icns')
-ICON_SETTINGS = os.path.join(ICON_ROOT, 'ToolbarAdvanced.icns')
-ICON_SWIRL = os.path.join(ICON_ROOT, 'ErasingIcon.icns')
-ICON_SWITCH = os.path.join(ICON_ROOT, 'General.icns')
-ICON_SYNC = os.path.join(ICON_ROOT, 'Sync.icns')
-ICON_TRASH = os.path.join(ICON_ROOT, 'TrashIcon.icns')
-ICON_USER = os.path.join(ICON_ROOT, 'UserIcon.icns')
-ICON_WARNING = os.path.join(ICON_ROOT, 'AlertCautionIcon.icns')
-ICON_WEB = os.path.join(ICON_ROOT, 'BookmarkIcon.icns')
+ICON_GROUP = os.path.join(ICON_ROOT, "GroupIcon.icns")
+ICON_HELP = os.path.join(ICON_ROOT, "HelpIcon.icns")
+ICON_HOME = os.path.join(ICON_ROOT, "HomeFolderIcon.icns")
+ICON_INFO = os.path.join(ICON_ROOT, "ToolbarInfo.icns")
+ICON_NETWORK = os.path.join(ICON_ROOT, "GenericNetworkIcon.icns")
+ICON_NOTE = os.path.join(ICON_ROOT, "AlertNoteIcon.icns")
+ICON_SETTINGS = os.path.join(ICON_ROOT, "ToolbarAdvanced.icns")
+ICON_SWIRL = os.path.join(ICON_ROOT, "ErasingIcon.icns")
+ICON_SWITCH = os.path.join(ICON_ROOT, "General.icns")
+ICON_SYNC = os.path.join(ICON_ROOT, "Sync.icns")
+ICON_TRASH = os.path.join(ICON_ROOT, "TrashIcon.icns")
+ICON_USER = os.path.join(ICON_ROOT, "UserIcon.icns")
+ICON_WARNING = os.path.join(ICON_ROOT, "AlertCautionIcon.icns")
+ICON_WEB = os.path.join(ICON_ROOT, "BookmarkIcon.icns")
####################################################################
# non-ASCII to ASCII diacritic folding.
@@ -98,241 +99,241 @@
####################################################################
ASCII_REPLACEMENTS = {
- 'À': 'A',
- 'Á': 'A',
- 'Â': 'A',
- 'Ã': 'A',
- 'Ä': 'A',
- 'Å': 'A',
- 'Æ': 'AE',
- 'Ç': 'C',
- 'È': 'E',
- 'É': 'E',
- 'Ê': 'E',
- 'Ë': 'E',
- 'Ì': 'I',
- 'Í': 'I',
- 'Î': 'I',
- 'Ï': 'I',
- 'Ð': 'D',
- 'Ñ': 'N',
- 'Ò': 'O',
- 'Ó': 'O',
- 'Ô': 'O',
- 'Õ': 'O',
- 'Ö': 'O',
- 'Ø': 'O',
- 'Ù': 'U',
- 'Ú': 'U',
- 'Û': 'U',
- 'Ü': 'U',
- 'Ý': 'Y',
- 'Þ': 'Th',
- 'ß': 'ss',
- 'à': 'a',
- 'á': 'a',
- 'â': 'a',
- 'ã': 'a',
- 'ä': 'a',
- 'å': 'a',
- 'æ': 'ae',
- 'ç': 'c',
- 'è': 'e',
- 'é': 'e',
- 'ê': 'e',
- 'ë': 'e',
- 'ì': 'i',
- 'í': 'i',
- 'î': 'i',
- 'ï': 'i',
- 'ð': 'd',
- 'ñ': 'n',
- 'ò': 'o',
- 'ó': 'o',
- 'ô': 'o',
- 'õ': 'o',
- 'ö': 'o',
- 'ø': 'o',
- 'ù': 'u',
- 'ú': 'u',
- 'û': 'u',
- 'ü': 'u',
- 'ý': 'y',
- 'þ': 'th',
- 'ÿ': 'y',
- 'Ł': 'L',
- 'ł': 'l',
- 'Ń': 'N',
- 'ń': 'n',
- 'Ņ': 'N',
- 'ņ': 'n',
- 'Ň': 'N',
- 'ň': 'n',
- 'Ŋ': 'ng',
- 'ŋ': 'NG',
- 'Ō': 'O',
- 'ō': 'o',
- 'Ŏ': 'O',
- 'ŏ': 'o',
- 'Ő': 'O',
- 'ő': 'o',
- 'Œ': 'OE',
- 'œ': 'oe',
- 'Ŕ': 'R',
- 'ŕ': 'r',
- 'Ŗ': 'R',
- 'ŗ': 'r',
- 'Ř': 'R',
- 'ř': 'r',
- 'Ś': 'S',
- 'ś': 's',
- 'Ŝ': 'S',
- 'ŝ': 's',
- 'Ş': 'S',
- 'ş': 's',
- 'Š': 'S',
- 'š': 's',
- 'Ţ': 'T',
- 'ţ': 't',
- 'Ť': 'T',
- 'ť': 't',
- 'Ŧ': 'T',
- 'ŧ': 't',
- 'Ũ': 'U',
- 'ũ': 'u',
- 'Ū': 'U',
- 'ū': 'u',
- 'Ŭ': 'U',
- 'ŭ': 'u',
- 'Ů': 'U',
- 'ů': 'u',
- 'Ű': 'U',
- 'ű': 'u',
- 'Ŵ': 'W',
- 'ŵ': 'w',
- 'Ŷ': 'Y',
- 'ŷ': 'y',
- 'Ÿ': 'Y',
- 'Ź': 'Z',
- 'ź': 'z',
- 'Ż': 'Z',
- 'ż': 'z',
- 'Ž': 'Z',
- 'ž': 'z',
- 'ſ': 's',
- 'Α': 'A',
- 'Β': 'B',
- 'Γ': 'G',
- 'Δ': 'D',
- 'Ε': 'E',
- 'Ζ': 'Z',
- 'Η': 'E',
- 'Θ': 'Th',
- 'Ι': 'I',
- 'Κ': 'K',
- 'Λ': 'L',
- 'Μ': 'M',
- 'Ν': 'N',
- 'Ξ': 'Ks',
- 'Ο': 'O',
- 'Π': 'P',
- 'Ρ': 'R',
- 'Σ': 'S',
- 'Τ': 'T',
- 'Υ': 'U',
- 'Φ': 'Ph',
- 'Χ': 'Kh',
- 'Ψ': 'Ps',
- 'Ω': 'O',
- 'α': 'a',
- 'β': 'b',
- 'γ': 'g',
- 'δ': 'd',
- 'ε': 'e',
- 'ζ': 'z',
- 'η': 'e',
- 'θ': 'th',
- 'ι': 'i',
- 'κ': 'k',
- 'λ': 'l',
- 'μ': 'm',
- 'ν': 'n',
- 'ξ': 'x',
- 'ο': 'o',
- 'π': 'p',
- 'ρ': 'r',
- 'ς': 's',
- 'σ': 's',
- 'τ': 't',
- 'υ': 'u',
- 'φ': 'ph',
- 'χ': 'kh',
- 'ψ': 'ps',
- 'ω': 'o',
- 'А': 'A',
- 'Б': 'B',
- 'В': 'V',
- 'Г': 'G',
- 'Д': 'D',
- 'Е': 'E',
- 'Ж': 'Zh',
- 'З': 'Z',
- 'И': 'I',
- 'Й': 'I',
- 'К': 'K',
- 'Л': 'L',
- 'М': 'M',
- 'Н': 'N',
- 'О': 'O',
- 'П': 'P',
- 'Р': 'R',
- 'С': 'S',
- 'Т': 'T',
- 'У': 'U',
- 'Ф': 'F',
- 'Х': 'Kh',
- 'Ц': 'Ts',
- 'Ч': 'Ch',
- 'Ш': 'Sh',
- 'Щ': 'Shch',
- 'Ъ': "'",
- 'Ы': 'Y',
- 'Ь': "'",
- 'Э': 'E',
- 'Ю': 'Iu',
- 'Я': 'Ia',
- 'а': 'a',
- 'б': 'b',
- 'в': 'v',
- 'г': 'g',
- 'д': 'd',
- 'е': 'e',
- 'ж': 'zh',
- 'з': 'z',
- 'и': 'i',
- 'й': 'i',
- 'к': 'k',
- 'л': 'l',
- 'м': 'm',
- 'н': 'n',
- 'о': 'o',
- 'п': 'p',
- 'р': 'r',
- 'с': 's',
- 'т': 't',
- 'у': 'u',
- 'ф': 'f',
- 'х': 'kh',
- 'ц': 'ts',
- 'ч': 'ch',
- 'ш': 'sh',
- 'щ': 'shch',
- 'ъ': "'",
- 'ы': 'y',
- 'ь': "'",
- 'э': 'e',
- 'ю': 'iu',
- 'я': 'ia',
+ "À": "A",
+ "Á": "A",
+ "Â": "A",
+ "Ã": "A",
+ "Ä": "A",
+ "Å": "A",
+ "Æ": "AE",
+ "Ç": "C",
+ "È": "E",
+ "É": "E",
+ "Ê": "E",
+ "Ë": "E",
+ "Ì": "I",
+ "Í": "I",
+ "Î": "I",
+ "Ï": "I",
+ "Ð": "D",
+ "Ñ": "N",
+ "Ò": "O",
+ "Ó": "O",
+ "Ô": "O",
+ "Õ": "O",
+ "Ö": "O",
+ "Ø": "O",
+ "Ù": "U",
+ "Ú": "U",
+ "Û": "U",
+ "Ü": "U",
+ "Ý": "Y",
+ "Þ": "Th",
+ "ß": "ss",
+ "à": "a",
+ "á": "a",
+ "â": "a",
+ "ã": "a",
+ "ä": "a",
+ "å": "a",
+ "æ": "ae",
+ "ç": "c",
+ "è": "e",
+ "é": "e",
+ "ê": "e",
+ "ë": "e",
+ "ì": "i",
+ "í": "i",
+ "î": "i",
+ "ï": "i",
+ "ð": "d",
+ "ñ": "n",
+ "ò": "o",
+ "ó": "o",
+ "ô": "o",
+ "õ": "o",
+ "ö": "o",
+ "ø": "o",
+ "ù": "u",
+ "ú": "u",
+ "û": "u",
+ "ü": "u",
+ "ý": "y",
+ "þ": "th",
+ "ÿ": "y",
+ "Ł": "L",
+ "ł": "l",
+ "Ń": "N",
+ "ń": "n",
+ "Ņ": "N",
+ "ņ": "n",
+ "Ň": "N",
+ "ň": "n",
+ "Ŋ": "ng",
+ "ŋ": "NG",
+ "Ō": "O",
+ "ō": "o",
+ "Ŏ": "O",
+ "ŏ": "o",
+ "Ő": "O",
+ "ő": "o",
+ "Œ": "OE",
+ "œ": "oe",
+ "Ŕ": "R",
+ "ŕ": "r",
+ "Ŗ": "R",
+ "ŗ": "r",
+ "Ř": "R",
+ "ř": "r",
+ "Ś": "S",
+ "ś": "s",
+ "Ŝ": "S",
+ "ŝ": "s",
+ "Ş": "S",
+ "ş": "s",
+ "Š": "S",
+ "š": "s",
+ "Ţ": "T",
+ "ţ": "t",
+ "Ť": "T",
+ "ť": "t",
+ "Ŧ": "T",
+ "ŧ": "t",
+ "Ũ": "U",
+ "ũ": "u",
+ "Ū": "U",
+ "ū": "u",
+ "Ŭ": "U",
+ "ŭ": "u",
+ "Ů": "U",
+ "ů": "u",
+ "Ű": "U",
+ "ű": "u",
+ "Ŵ": "W",
+ "ŵ": "w",
+ "Ŷ": "Y",
+ "ŷ": "y",
+ "Ÿ": "Y",
+ "Ź": "Z",
+ "ź": "z",
+ "Ż": "Z",
+ "ż": "z",
+ "Ž": "Z",
+ "ž": "z",
+ "ſ": "s",
+ "Α": "A",
+ "Β": "B",
+ "Γ": "G",
+ "Δ": "D",
+ "Ε": "E",
+ "Ζ": "Z",
+ "Η": "E",
+ "Θ": "Th",
+ "Ι": "I",
+ "Κ": "K",
+ "Λ": "L",
+ "Μ": "M",
+ "Ν": "N",
+ "Ξ": "Ks",
+ "Ο": "O",
+ "Π": "P",
+ "Ρ": "R",
+ "Σ": "S",
+ "Τ": "T",
+ "Υ": "U",
+ "Φ": "Ph",
+ "Χ": "Kh",
+ "Ψ": "Ps",
+ "Ω": "O",
+ "α": "a",
+ "β": "b",
+ "γ": "g",
+ "δ": "d",
+ "ε": "e",
+ "ζ": "z",
+ "η": "e",
+ "θ": "th",
+ "ι": "i",
+ "κ": "k",
+ "λ": "l",
+ "μ": "m",
+ "ν": "n",
+ "ξ": "x",
+ "ο": "o",
+ "π": "p",
+ "ρ": "r",
+ "ς": "s",
+ "σ": "s",
+ "τ": "t",
+ "υ": "u",
+ "φ": "ph",
+ "χ": "kh",
+ "ψ": "ps",
+ "ω": "o",
+ "А": "A",
+ "Б": "B",
+ "В": "V",
+ "Г": "G",
+ "Д": "D",
+ "Е": "E",
+ "Ж": "Zh",
+ "З": "Z",
+ "И": "I",
+ "Й": "I",
+ "К": "K",
+ "Л": "L",
+ "М": "M",
+ "Н": "N",
+ "О": "O",
+ "П": "P",
+ "Р": "R",
+ "С": "S",
+ "Т": "T",
+ "У": "U",
+ "Ф": "F",
+ "Х": "Kh",
+ "Ц": "Ts",
+ "Ч": "Ch",
+ "Ш": "Sh",
+ "Щ": "Shch",
+ "Ъ": "'",
+ "Ы": "Y",
+ "Ь": "'",
+ "Э": "E",
+ "Ю": "Iu",
+ "Я": "Ia",
+ "а": "a",
+ "б": "b",
+ "в": "v",
+ "г": "g",
+ "д": "d",
+ "е": "e",
+ "ж": "zh",
+ "з": "z",
+ "и": "i",
+ "й": "i",
+ "к": "k",
+ "л": "l",
+ "м": "m",
+ "н": "n",
+ "о": "o",
+ "п": "p",
+ "р": "r",
+ "с": "s",
+ "т": "t",
+ "у": "u",
+ "ф": "f",
+ "х": "kh",
+ "ц": "ts",
+ "ч": "ch",
+ "ш": "sh",
+ "щ": "shch",
+ "ъ": "'",
+ "ы": "y",
+ "ь": "'",
+ "э": "e",
+ "ю": "iu",
+ "я": "ia",
# 'ᴀ': '',
# 'ᴁ': '',
# 'ᴂ': '',
@@ -371,18 +372,18 @@
# 'ᴣ': '',
# 'ᴤ': '',
# 'ᴥ': '',
- 'ᴦ': 'G',
- 'ᴧ': 'L',
- 'ᴨ': 'P',
- 'ᴩ': 'R',
- 'ᴪ': 'PS',
- 'ẞ': 'Ss',
- 'Ỳ': 'Y',
- 'ỳ': 'y',
- 'Ỵ': 'Y',
- 'ỵ': 'y',
- 'Ỹ': 'Y',
- 'ỹ': 'y',
+ "ᴦ": "G",
+ "ᴧ": "L",
+ "ᴨ": "P",
+ "ᴩ": "R",
+ "ᴪ": "PS",
+ "ẞ": "Ss",
+ "Ỳ": "Y",
+ "ỳ": "y",
+ "Ỵ": "Y",
+ "ỵ": "y",
+ "Ỹ": "Y",
+ "ỹ": "y",
}
####################################################################
@@ -390,14 +391,14 @@
####################################################################
DUMB_PUNCTUATION = {
- '‘': "'",
- '’': "'",
- '‚': "'",
- '“': '"',
- '”': '"',
- '„': '"',
- '–': '-',
- '—': '-'
+ "‘": "'",
+ "’": "'",
+ "‚": "'",
+ "“": '"',
+ "”": '"',
+ "„": '"',
+ "–": "-",
+ "—": "-",
}
@@ -410,7 +411,7 @@
INITIALS = string.ascii_uppercase + string.digits
#: Split on non-letters, numbers
-split_on_delimiters = re.compile('[^a-zA-Z0-9]').split
+split_on_delimiters = re.compile("[^a-zA-Z0-9]").split
# Match filter flags
#: Match items that start with ``query``
@@ -443,12 +444,9 @@
####################################################################
-# Lockfile and Keychain access errors
+# Keychain access errors
####################################################################
-class AcquisitionError(Exception):
- """Raised if a lock cannot be acquired."""
-
class KeychainError(Exception):
"""Raised for unknown Keychain errors.
@@ -483,6 +481,7 @@ class PasswordExists(KeychainError):
# Helper functions
####################################################################
+
def isascii(text):
"""Test if ``text`` contains only ASCII characters.
@@ -493,7 +492,7 @@ def isascii(text):
"""
try:
- text.encode('ascii')
+ text.encode("ascii")
except UnicodeEncodeError:
return False
return True
@@ -503,6 +502,7 @@ def isascii(text):
# Implementation classes
####################################################################
+
class SerializerManager(object):
"""Contains registered serializers.
@@ -540,8 +540,8 @@ def register(self, name, serializer):
"""
# Basic validation
- getattr(serializer, 'load')
- getattr(serializer, 'dump')
+ serializer.load
+ serializer.dump
self._serializers[name] = serializer
@@ -568,8 +568,7 @@ def unregister(self, name):
"""
if name not in self._serializers:
- raise ValueError('No such serializer registered : {0}'.format(
- name))
+ raise ValueError("No such serializer registered : {0}".format(name))
serializer = self._serializers[name]
del self._serializers[name]
@@ -582,86 +581,72 @@ def serializers(self):
return sorted(self._serializers.keys())
-class JSONSerializer(object):
- """Wrapper around :mod:`json`. Sets ``indent`` and ``encoding``.
-
- .. versionadded:: 1.8
-
- Use this serializer if you need readable data files. JSON doesn't
- support Python objects as well as ``cPickle``/``pickle``, so be
- careful which data you try to serialize as JSON.
-
- """
+class BaseSerializer:
+ is_binary: Optional[bool] = None
@classmethod
- def load(cls, file_obj):
- """Load serialized object from open JSON file.
-
- .. versionadded:: 1.8
-
- :param file_obj: file handle
- :type file_obj: ``file`` object
- :returns: object loaded from JSON file
- :rtype: object
-
- """
- return json.load(file_obj)
+ def binary_mode(cls):
+ return "b" if cls.is_binary else ""
@classmethod
- def dump(cls, obj, file_obj):
- """Serialize object ``obj`` to open JSON file.
+ def _opener(cls, opener, path, mode="r"):
+ with opener(path, mode + cls.binary_mode()) as fp:
+ yield fp
- .. versionadded:: 1.8
-
- :param obj: Python object to serialize
- :type obj: JSON-serializable data structure
- :param file_obj: file handle
- :type file_obj: ``file`` object
+ @classmethod
+ @contextmanager
+ def atomic_writer(cls, path, mode):
+ yield from cls._opener(atomic_writer, path, mode)
- """
- return json.dump(obj, file_obj, indent=2, encoding='utf-8')
+ @classmethod
+ @contextmanager
+ def open(cls, path, mode):
+ yield from cls._opener(open, path, mode)
-class CPickleSerializer(object):
- """Wrapper around :mod:`cPickle`. Sets ``protocol``.
+class JSONSerializer(BaseSerializer):
+ """Wrapper around :mod:`json`. Sets ``indent`` and ``encoding``.
.. versionadded:: 1.8
- This is the default serializer and the best combination of speed and
- flexibility.
+ Use this serializer if you need readable data files. JSON doesn't
+ support Python objects as well as ``pickle``, so be
+ careful which data you try to serialize as JSON.
"""
+ is_binary = False
+
@classmethod
def load(cls, file_obj):
- """Load serialized object from open pickle file.
+ """Load serialized object from open JSON file.
.. versionadded:: 1.8
:param file_obj: file handle
:type file_obj: ``file`` object
- :returns: object loaded from pickle file
+ :returns: object loaded from JSON file
:rtype: object
"""
- return cPickle.load(file_obj)
+ return json.load(file_obj)
@classmethod
def dump(cls, obj, file_obj):
- """Serialize object ``obj`` to open pickle file.
+ """Serialize object ``obj`` to open JSON file.
.. versionadded:: 1.8
:param obj: Python object to serialize
- :type obj: Python object
+ :type obj: JSON-serializable data structure
:param file_obj: file handle
:type file_obj: ``file`` object
"""
- return cPickle.dump(obj, file_obj, protocol=-1)
+ return json.dump(obj, file_obj, indent=2)
-class PickleSerializer(object):
+class PickleSerializer(BaseSerializer):
"""Wrapper around :mod:`pickle`. Sets ``protocol``.
.. versionadded:: 1.8
@@ -670,6 +655,8 @@ class PickleSerializer(object):
"""
+ is_binary = True
+
@classmethod
def load(cls, file_obj):
"""Load serialized object from open pickle file.
@@ -701,9 +688,8 @@ def dump(cls, obj, file_obj):
# Set up default manager and register built-in serializers
manager = SerializerManager()
-manager.register('cpickle', CPickleSerializer)
-manager.register('pickle', PickleSerializer)
-manager.register('json', JSONSerializer)
+manager.register("pickle", PickleSerializer)
+manager.register("json", JSONSerializer)
class Item(object):
@@ -717,10 +703,22 @@ class Item(object):
"""
- def __init__(self, title, subtitle='', modifier_subtitles=None,
- arg=None, autocomplete=None, valid=False, uid=None,
- icon=None, icontype=None, type=None, largetext=None,
- copytext=None, quicklookurl=None):
+ def __init__(
+ self,
+ title,
+ subtitle="",
+ modifier_subtitles=None,
+ arg=None,
+ autocomplete=None,
+ valid=False,
+ uid=None,
+ icon=None,
+ icontype=None,
+ type=None,
+ largetext=None,
+ copytext=None,
+ quicklookurl=None,
+ ):
"""Same arguments as :meth:`Workflow.add_item`."""
self.title = title
self.subtitle = subtitle
@@ -747,35 +745,36 @@ def elem(self):
# Attributes on - element
attr = {}
if self.valid:
- attr['valid'] = 'yes'
+ attr["valid"] = "yes"
else:
- attr['valid'] = 'no'
+ attr["valid"] = "no"
# Allow empty string for autocomplete. This is a useful value,
# as TABing the result will revert the query back to just the
# keyword
if self.autocomplete is not None:
- attr['autocomplete'] = self.autocomplete
+ attr["autocomplete"] = self.autocomplete
# Optional attributes
- for name in ('uid', 'type'):
+ for name in ("uid", "type"):
value = getattr(self, name, None)
if value:
attr[name] = value
- root = ET.Element('item', attr)
- ET.SubElement(root, 'title').text = self.title
- ET.SubElement(root, 'subtitle').text = self.subtitle
+ root = ET.Element("item", attr)
+ ET.SubElement(root, "title").text = self.title
+ ET.SubElement(root, "subtitle").text = self.subtitle
# Add modifier subtitles
- for mod in ('cmd', 'ctrl', 'alt', 'shift', 'fn'):
+ for mod in ("cmd", "ctrl", "alt", "shift", "fn"):
if mod in self.modifier_subtitles:
- ET.SubElement(root, 'subtitle',
- {'mod': mod}).text = self.modifier_subtitles[mod]
+ ET.SubElement(
+ root, "subtitle", {"mod": mod}
+ ).text = self.modifier_subtitles[mod]
# Add arg as element instead of attribute on
- , as it's more
# flexible (newlines aren't allowed in attributes)
if self.arg:
- ET.SubElement(root, 'arg').text = self.arg
+ ET.SubElement(root, "arg").text = self.arg
# Add icon if there is one
if self.icon:
@@ -783,221 +782,20 @@ def elem(self):
attr = dict(type=self.icontype)
else:
attr = {}
- ET.SubElement(root, 'icon', attr).text = self.icon
+ ET.SubElement(root, "icon", attr).text = self.icon
if self.largetext:
- ET.SubElement(root, 'text',
- {'type': 'largetype'}).text = self.largetext
+ ET.SubElement(root, "text", {"type": "largetype"}).text = self.largetext
if self.copytext:
- ET.SubElement(root, 'text',
- {'type': 'copy'}).text = self.copytext
+ ET.SubElement(root, "text", {"type": "copy"}).text = self.copytext
if self.quicklookurl:
- ET.SubElement(root, 'quicklookurl').text = self.quicklookurl
+ ET.SubElement(root, "quicklookurl").text = self.quicklookurl
return root
-class LockFile(object):
- """Context manager to protect filepaths with lockfiles.
-
- .. versionadded:: 1.13
-
- Creates a lockfile alongside ``protected_path``. Other ``LockFile``
- instances will refuse to lock the same path.
-
- >>> path = '/path/to/file'
- >>> with LockFile(path):
- >>> with open(path, 'wb') as fp:
- >>> fp.write(data)
-
- Args:
- protected_path (unicode): File to protect with a lockfile
- timeout (int, optional): Raises an :class:`AcquisitionError`
- if lock cannot be acquired within this number of seconds.
- If ``timeout`` is 0 (the default), wait forever.
- delay (float, optional): How often to check (in seconds) if
- lock has been released.
-
- """
-
- def __init__(self, protected_path, timeout=0, delay=0.05):
- """Create new :class:`LockFile` object."""
- self.lockfile = protected_path + '.lock'
- self.timeout = timeout
- self.delay = delay
- self._locked = False
- atexit.register(self.release)
-
- @property
- def locked(self):
- """`True` if file is locked by this instance."""
- return self._locked
-
- def acquire(self, blocking=True):
- """Acquire the lock if possible.
-
- If the lock is in use and ``blocking`` is ``False``, return
- ``False``.
-
- Otherwise, check every `self.delay` seconds until it acquires
- lock or exceeds `self.timeout` and raises an `~AcquisitionError`.
-
- """
- start = time.time()
- while True:
-
- self._validate_lockfile()
-
- try:
- fd = os.open(self.lockfile, os.O_CREAT | os.O_EXCL | os.O_RDWR)
- with os.fdopen(fd, 'w') as fd:
- fd.write(str(os.getpid()))
- break
- except OSError as err:
- if err.errno != errno.EEXIST: # pragma: no cover
- raise
-
- if self.timeout and (time.time() - start) >= self.timeout:
- raise AcquisitionError('lock acquisition timed out')
- if not blocking:
- return False
- time.sleep(self.delay)
-
- self._locked = True
- return True
-
- def _validate_lockfile(self):
- """Check existence and validity of lockfile.
-
- If the lockfile exists, but contains an invalid PID
- or the PID of a non-existant process, it is removed.
-
- """
- try:
- with open(self.lockfile) as fp:
- s = fp.read()
- except Exception:
- return
-
- try:
- pid = int(s)
- except ValueError:
- return self.release()
-
- from background import _process_exists
- if not _process_exists(pid):
- self.release()
-
- def release(self):
- """Release the lock by deleting `self.lockfile`."""
- self._locked = False
- try:
- os.unlink(self.lockfile)
- except (OSError, IOError) as err: # pragma: no cover
- if err.errno != 2:
- raise err
-
- def __enter__(self):
- """Acquire lock."""
- self.acquire()
- return self
-
- def __exit__(self, typ, value, traceback):
- """Release lock."""
- self.release()
-
- def __del__(self):
- """Clear up `self.lockfile`."""
- if self._locked: # pragma: no cover
- self.release()
-
-
-@contextmanager
-def atomic_writer(file_path, mode):
- """Atomic file writer.
-
- .. versionadded:: 1.12
-
- Context manager that ensures the file is only written if the write
- succeeds. The data is first written to a temporary file.
-
- :param file_path: path of file to write to.
- :type file_path: ``unicode``
- :param mode: sames as for :func:`open`
- :type mode: string
-
- """
- temp_suffix = '.aw.temp'
- temp_file_path = file_path + temp_suffix
- with open(temp_file_path, mode) as file_obj:
- try:
- yield file_obj
- os.rename(temp_file_path, file_path)
- finally:
- try:
- os.remove(temp_file_path)
- except (OSError, IOError):
- pass
-
-
-class uninterruptible(object):
- """Decorator that postpones SIGTERM until wrapped function returns.
-
- .. versionadded:: 1.12
-
- .. important:: This decorator is NOT thread-safe.
-
- As of version 2.7, Alfred allows Script Filters to be killed. If
- your workflow is killed in the middle of critical code (e.g.
- writing data to disk), this may corrupt your workflow's data.
-
- Use this decorator to wrap critical functions that *must* complete.
- If the script is killed while a wrapped function is executing,
- the SIGTERM will be caught and handled after your function has
- finished executing.
-
- Alfred-Workflow uses this internally to ensure its settings, data
- and cache writes complete.
-
- """
-
- def __init__(self, func, class_name=''):
- """Decorate `func`."""
- self.func = func
- self._caught_signal = None
-
- def signal_handler(self, signum, frame):
- """Called when process receives SIGTERM."""
- self._caught_signal = (signum, frame)
-
- def __call__(self, *args, **kwargs):
- """Trap ``SIGTERM`` and call wrapped function."""
- self._caught_signal = None
- # Register handler for SIGTERM, then call `self.func`
- self.old_signal_handler = signal.getsignal(signal.SIGTERM)
- signal.signal(signal.SIGTERM, self.signal_handler)
-
- self.func(*args, **kwargs)
-
- # Restore old signal handler
- signal.signal(signal.SIGTERM, self.old_signal_handler)
-
- # Handle any signal caught during execution
- if self._caught_signal is not None:
- signum, frame = self._caught_signal
- if callable(self.old_signal_handler):
- self.old_signal_handler(signum, frame)
- elif self.old_signal_handler == signal.SIG_DFL:
- sys.exit(0)
-
- def __get__(self, obj=None, klass=None):
- """Decorator API."""
- return self.__class__(self.func.__get__(obj, klass),
- klass.__name__)
-
-
class Settings(dict):
"""A dictionary that saves itself when changed.
@@ -1025,19 +823,21 @@ def __init__(self, filepath, defaults=None):
if os.path.exists(self._filepath):
self._load()
elif defaults:
- for key, val in defaults.items():
+ for key, val in list(defaults.items()):
self[key] = val
self.save() # save default settings
def _load(self):
"""Load cached settings from JSON file `self._filepath`."""
+ data = {}
+ with LockFile(self._filepath, 0.5):
+ with open(self._filepath, "r") as fp:
+ data.update(json.load(fp))
+
+ self._original = deepcopy(data)
+
self._nosave = True
- d = {}
- with open(self._filepath, 'rb') as file_obj:
- for key, value in json.load(file_obj, encoding='utf-8').items():
- d[key] = value
- self.update(d)
- self._original = deepcopy(d)
+ self.update(data)
self._nosave = False
@uninterruptible
@@ -1050,14 +850,13 @@ def save(self):
"""
if self._nosave:
return
+
data = {}
data.update(self)
- # for key, value in self.items():
- # data[key] = value
- with LockFile(self._filepath):
- with atomic_writer(self._filepath, 'wb') as file_obj:
- json.dump(data, file_obj, sort_keys=True, indent=2,
- encoding='utf-8')
+
+ with LockFile(self._filepath, 0.5):
+ with atomic_writer(self._filepath, "w") as fp:
+ json.dump(data, fp, sort_keys=True, indent=2)
# dict methods
def __setitem__(self, key, value):
@@ -1090,9 +889,9 @@ class Workflow(object):
storing & caching data, using Keychain, and generating Script
Filter feedback.
- ``Workflow`` is compatible with both Alfred 2 and 3. The
- :class:`~workflow.Workflow3` subclass provides additional,
- Alfred 3-only features, such as workflow variables.
+ ``Workflow`` is compatible with Alfred 2+. Subclass
+ :class:`~workflow.Workflow3` provides additional features,
+ only available in Alfred 3+, such as workflow variables.
:param default_settings: default workflow settings. If no settings file
exists, :class:`Workflow.settings` will be pre-populated with
@@ -1133,11 +932,20 @@ class Workflow(object):
# won't want to change this
item_class = Item
- def __init__(self, default_settings=None, update_settings=None,
- input_encoding='utf-8', normalization='NFC',
- capture_args=True, libraries=None,
- help_url=None):
+ def __init__(
+ self,
+ default_settings=None,
+ update_settings=None,
+ input_encoding="utf-8",
+ normalization="NFC",
+ capture_args=True,
+ libraries=None,
+ help_url=None,
+ ):
"""Create new :class:`Workflow` object."""
+
+ seralizer = "pickle"
+
self._default_settings = default_settings or {}
self._update_settings = update_settings or {}
self._input_encoding = input_encoding
@@ -1150,8 +958,8 @@ def __init__(self, default_settings=None, update_settings=None,
self._bundleid = None
self._debugging = None
self._name = None
- self._cache_serializer = 'cpickle'
- self._data_serializer = 'cpickle'
+ self._cache_serializer = seralizer
+ self._data_serializer = seralizer
self._info = None
self._info_loaded = False
self._logger = None
@@ -1163,9 +971,10 @@ def __init__(self, default_settings=None, update_settings=None,
self._last_version_run = UNSET
# Cache for regex patterns created for filter keys
self._search_pattern_cache = {}
- # Magic arguments
- #: The prefix for all magic arguments. Default is ``workflow:``
- self.magic_prefix = 'workflow:'
+ #: Prefix for all magic arguments.
+ #: The default value is ``workflow:`` so keyword
+ #: ``config`` would match user query ``workflow:config``.
+ self.magic_prefix = "workflow:"
#: Mapping of available magic arguments. The built-in magic
#: arguments are registered by default. To add your own magic arguments
#: (or override built-ins), add a key:value pair where the key is
@@ -1192,8 +1001,9 @@ def __init__(self, default_settings=None, update_settings=None,
@property
def alfred_version(self):
"""Alfred version as :class:`~workflow.update.Version` object."""
- from update import Version
- return Version(self.alfred_env.get('version'))
+ from .update import Version
+
+ return Version(self.alfred_env.get("version"))
@property
def alfred_env(self):
@@ -1248,31 +1058,34 @@ def alfred_env(self):
data = {}
for key in (
- 'alfred_debug',
- 'alfred_preferences',
- 'alfred_preferences_localhash',
- 'alfred_theme',
- 'alfred_theme_background',
- 'alfred_theme_subtext',
- 'alfred_version',
- 'alfred_version_build',
- 'alfred_workflow_bundleid',
- 'alfred_workflow_cache',
- 'alfred_workflow_data',
- 'alfred_workflow_name',
- 'alfred_workflow_uid',
- 'alfred_workflow_version'):
-
- value = os.getenv(key)
-
- if isinstance(value, str):
- if key in ('alfred_debug', 'alfred_version_build',
- 'alfred_theme_subtext'):
- value = int(value)
+ "debug",
+ "preferences",
+ "preferences_localhash",
+ "theme",
+ "theme_background",
+ "theme_subtext",
+ "version",
+ "version_build",
+ "workflow_bundleid",
+ "workflow_cache",
+ "workflow_data",
+ "workflow_name",
+ "workflow_uid",
+ "workflow_version",
+ ):
+
+ value = os.getenv("alfred_" + key, "")
+
+ if value:
+ if key in ("debug", "version_build", "theme_subtext"):
+ if value.isdigit():
+ value = int(value)
+ else:
+ value = False
else:
value = self.decode(value)
- data[key[7:]] = value
+ data[key] = value
self._alfred_env = data
@@ -1294,10 +1107,10 @@ def bundleid(self):
"""
if not self._bundleid:
- if self.alfred_env.get('workflow_bundleid'):
- self._bundleid = self.alfred_env.get('workflow_bundleid')
+ if self.alfred_env.get("workflow_bundleid"):
+ self._bundleid = self.alfred_env.get("workflow_bundleid")
else:
- self._bundleid = unicode(self.info['bundleid'], 'utf-8')
+ self._bundleid = self.info["bundleid"]
return self._bundleid
@@ -1309,12 +1122,9 @@ def debugging(self):
:rtype: ``bool``
"""
- if self._debugging is None:
- if self.alfred_env.get('debug') == 1:
- self._debugging = True
- else:
- self._debugging = False
- return self._debugging
+ return bool(
+ self.alfred_env.get("debug") == 1 or os.environ.get("PYTEST_RUNNING")
+ )
@property
def name(self):
@@ -1325,10 +1135,10 @@ def name(self):
"""
if not self._name:
- if self.alfred_env.get('workflow_name'):
- self._name = self.decode(self.alfred_env.get('workflow_name'))
+ if self.alfred_env.get("workflow_name"):
+ self._name = self.decode(self.alfred_env.get("workflow_name"))
else:
- self._name = self.decode(self.info['name'])
+ self._name = self.decode(self.info["name"])
return self._name
@@ -1353,27 +1163,28 @@ def version(self):
version = None
# environment variable has priority
- if self.alfred_env.get('workflow_version'):
- version = self.alfred_env['workflow_version']
+ if self.alfred_env.get("workflow_version"):
+ version = self.alfred_env["workflow_version"]
# Try `update_settings`
elif self._update_settings:
- version = self._update_settings.get('version')
+ version = self._update_settings.get("version")
# `version` file
if not version:
- filepath = self.workflowfile('version')
+ filepath = self.workflowfile("version")
if os.path.exists(filepath):
- with open(filepath, 'rb') as fileobj:
+ with open(filepath, "r") as fileobj:
version = fileobj.read()
# info.plist
if not version:
- version = self.info.get('version')
+ version = self.info.get("version")
if version:
- from update import Version
+ from .update import Version
+
version = Version(version)
self._version = version
@@ -1406,7 +1217,7 @@ def args(self):
# Handle magic args
if len(args) and self._capture_args:
for name in self.magic_arguments:
- key = '{0}{1}'.format(self.magic_prefix, name)
+ key = "{0}{1}".format(self.magic_prefix, name)
if key in args:
msg = self.magic_arguments[name]()
@@ -1423,18 +1234,22 @@ def cachedir(self):
"""Path to workflow's cache directory.
The cache directory is a subdirectory of Alfred's own cache directory
- in ``~/Library/Caches``. The full path is:
+ in ``~/Library/Caches``. The full path is in Alfred 4+ is:
+
+ ``~/Library/Caches/com.runningwithcrayons.Alfred/Workflow Data/``
+
+ For earlier versions:
``~/Library/Caches/com.runningwithcrayons.Alfred-X/Workflow Data/``
- ``Alfred-X`` may be ``Alfred-2`` or ``Alfred-3``.
+ where ``Alfred-X`` may be ``Alfred-2`` or ``Alfred-3``.
- :returns: full path to workflow's cache directory
- :rtype: ``unicode``
+ Returns:
+ unicode: full path to workflow's cache directory
"""
- if self.alfred_env.get('workflow_cache'):
- dirpath = self.alfred_env.get('workflow_cache')
+ if self.alfred_env.get("workflow_cache"):
+ dirpath = self.alfred_env.get("workflow_cache")
else:
dirpath = self._default_cachedir
@@ -1446,25 +1261,32 @@ def _default_cachedir(self):
"""Alfred 2's default cache directory."""
return os.path.join(
os.path.expanduser(
- '~/Library/Caches/com.runningwithcrayons.Alfred-2/'
- 'Workflow Data/'),
- self.bundleid)
+ "~/Library/Caches/com.runningwithcrayons.Alfred-2/" "Workflow Data/"
+ ),
+ self.bundleid,
+ )
@property
def datadir(self):
"""Path to workflow's data directory.
The data directory is a subdirectory of Alfred's own data directory in
- ``~/Library/Application Support``. The full path is:
+ ``~/Library/Application Support``. The full path for Alfred 4+ is:
- ``~/Library/Application Support/Alfred 2/Workflow Data/``
+ ``~/Library/Application Support/Alfred/Workflow Data/``
- :returns: full path to workflow data directory
- :rtype: ``unicode``
+ For earlier versions, the path is:
+
+ ``~/Library/Application Support/Alfred X/Workflow Data/``
+
+ where ``Alfred X` is ``Alfred 2`` or ``Alfred 3``.
+
+ Returns:
+ unicode: full path to workflow data directory
"""
- if self.alfred_env.get('workflow_data'):
- dirpath = self.alfred_env.get('workflow_data')
+ if self.alfred_env.get("workflow_data"):
+ dirpath = self.alfred_env.get("workflow_data")
else:
dirpath = self._default_datadir
@@ -1474,16 +1296,17 @@ def datadir(self):
@property
def _default_datadir(self):
"""Alfred 2's default data directory."""
- return os.path.join(os.path.expanduser(
- '~/Library/Application Support/Alfred 2/Workflow Data/'),
- self.bundleid)
+ return os.path.join(
+ os.path.expanduser("~/Library/Application Support/Alfred 2/Workflow Data/"),
+ self.bundleid,
+ )
@property
def workflowdir(self):
"""Path to workflow's root directory (where ``info.plist`` is).
- :returns: full path to workflow root directory
- :rtype: ``unicode``
+ Returns:
+ unicode: full path to workflow root directory
"""
if not self._workflowdir:
@@ -1491,8 +1314,9 @@ def workflowdir(self):
# the library is in. CWD will be the workflow root if
# a workflow is being run in Alfred
candidates = [
- os.path.abspath(os.getcwdu()),
- os.path.dirname(os.path.abspath(os.path.dirname(__file__)))]
+ os.path.abspath(os.getcwd()),
+ os.path.dirname(os.path.abspath(os.path.dirname(__file__))),
+ ]
# climb the directory tree until we find `info.plist`
for dirpath in candidates:
@@ -1501,11 +1325,11 @@ def workflowdir(self):
dirpath = self.decode(dirpath)
while True:
- if os.path.exists(os.path.join(dirpath, 'info.plist')):
+ if os.path.exists(os.path.join(dirpath, "info.plist")):
self._workflowdir = dirpath
break
- elif dirpath == '/':
+ elif dirpath == "/":
# no `info.plist` found
break
@@ -1568,7 +1392,7 @@ def logfile(self):
:rtype: ``unicode``
"""
- return self.cachefile('%s.log' % self.bundleid)
+ return self.cachefile("%s.log" % self.bundleid)
@property
def logger(self):
@@ -1586,19 +1410,21 @@ def logger(self):
return self._logger
# Initialise new logger and optionally handlers
- logger = logging.getLogger('workflow')
+ logger = logging.getLogger("")
- if not len(logger.handlers): # Only add one set of handlers
+ # Only add one set of handlers
+ # Exclude from coverage, as pytest will have configured the
+ # root logger already
+ if not len(logger.handlers): # pragma: no cover
fmt = logging.Formatter(
- '%(asctime)s %(filename)s:%(lineno)s'
- ' %(levelname)-8s %(message)s',
- datefmt='%H:%M:%S')
+ "%(asctime)s %(filename)s:%(lineno)s" " %(levelname)-8s %(message)s",
+ datefmt="%H:%M:%S",
+ )
logfile = logging.handlers.RotatingFileHandler(
- self.logfile,
- maxBytes=1024 * 1024,
- backupCount=1)
+ self.logfile, maxBytes=1024 * 1024, backupCount=1
+ )
logfile.setFormatter(fmt)
logger.addHandler(logfile)
@@ -1634,7 +1460,7 @@ def settings_path(self):
"""
if not self._settings_path:
- self._settings_path = self.datafile('settings.json')
+ self._settings_path = self.datafile("settings.json")
return self._settings_path
@property
@@ -1654,9 +1480,8 @@ def settings(self):
"""
if not self._settings:
- self.logger.debug('reading settings from %s', self.settings_path)
- self._settings = Settings(self.settings_path,
- self._default_settings)
+ self.logger.debug("reading settings from %s", self.settings_path)
+ self._settings = Settings(self.settings_path, self._default_settings)
return self._settings
@property
@@ -1695,10 +1520,11 @@ def cache_serializer(self, serializer_name):
"""
if manager.serializer(serializer_name) is None:
raise ValueError(
- 'Unknown serializer : `{0}`. Register your serializer '
- 'with `manager` first.'.format(serializer_name))
+ "Unknown serializer : `{0}`. Register your serializer "
+ "with `manager` first.".format(serializer_name)
+ )
- self.logger.debug('default cache serializer: %s', serializer_name)
+ self.logger.debug("default cache serializer: %s", serializer_name)
self._cache_serializer = serializer_name
@@ -1737,10 +1563,11 @@ def data_serializer(self, serializer_name):
"""
if manager.serializer(serializer_name) is None:
raise ValueError(
- 'Unknown serializer : `{0}`. Register your serializer '
- 'with `manager` first.'.format(serializer_name))
+ "Unknown serializer : `{0}`. Register your serializer "
+ "with `manager` first.".format(serializer_name)
+ )
- self.logger.debug('default data serializer: %s', serializer_name)
+ self.logger.debug("default data serializer: %s", serializer_name)
self._data_serializer = serializer_name
@@ -1754,39 +1581,40 @@ def stored_data(self, name):
:param name: name of datastore
"""
- metadata_path = self.datafile('.{0}.alfred-workflow'.format(name))
+ metadata_path = self.datafile(".{0}.alfred-workflow".format(name))
if not os.path.exists(metadata_path):
- self.logger.debug('no data stored for `%s`', name)
+ self.logger.debug("no data stored for `%s`", name)
return None
- with open(metadata_path, 'rb') as file_obj:
+ with open(metadata_path, "r") as file_obj:
serializer_name = file_obj.read().strip()
serializer = manager.serializer(serializer_name)
if serializer is None:
raise ValueError(
- 'Unknown serializer `{0}`. Register a corresponding '
- 'serializer with `manager.register()` '
- 'to load this data.'.format(serializer_name))
+ "Unknown serializer `{0}`. Register a corresponding "
+ "serializer with `manager.register()` "
+ "to load this data.".format(serializer_name)
+ )
- self.logger.debug('data `%s` stored as `%s`', name, serializer_name)
+ self.logger.debug("data `%s` stored as `%s`", name, serializer_name)
- filename = '{0}.{1}'.format(name, serializer_name)
+ filename = "{0}.{1}".format(name, serializer_name)
data_path = self.datafile(filename)
if not os.path.exists(data_path):
- self.logger.debug('no data stored: %s', name)
+ self.logger.debug("no data stored: %s", name)
if os.path.exists(metadata_path):
os.unlink(metadata_path)
return None
- with open(data_path, 'rb') as file_obj:
+ with open(data_path, "rb") as file_obj:
data = serializer.load(file_obj)
- self.logger.debug('stored data loaded: %s', data_path)
+ self.logger.debug("stored data loaded: %s", data_path)
return data
@@ -1815,47 +1643,52 @@ def delete_paths(paths):
for path in paths:
if os.path.exists(path):
os.unlink(path)
- self.logger.debug('deleted data file: %s', path)
+ self.logger.debug("deleted data file: %s", path)
serializer_name = serializer or self.data_serializer
# In order for `stored_data()` to be able to load data stored with
# an arbitrary serializer, yet still have meaningful file extensions,
# the format (i.e. extension) is saved to an accompanying file
- metadata_path = self.datafile('.{0}.alfred-workflow'.format(name))
- filename = '{0}.{1}'.format(name, serializer_name)
+ metadata_path = self.datafile(".{0}.alfred-workflow".format(name))
+ filename = "{0}.{1}".format(name, serializer_name)
data_path = self.datafile(filename)
if data_path == self.settings_path:
raise ValueError(
- 'Cannot save data to' +
- '`{0}` with format `{1}`. '.format(name, serializer_name) +
- "This would overwrite Alfred-Workflow's settings file.")
+ "Cannot save data to"
+ + "`{0}` with format `{1}`. ".format(name, serializer_name)
+ + "This would overwrite Alfred-Workflow's settings file."
+ )
serializer = manager.serializer(serializer_name)
if serializer is None:
raise ValueError(
- 'Invalid serializer `{0}`. Register your serializer with '
- '`manager.register()` first.'.format(serializer_name))
+ "Invalid serializer `{0}`. Register your serializer with "
+ "`manager.register()` first.".format(serializer_name)
+ )
if data is None: # Delete cached data
delete_paths((metadata_path, data_path))
return
+ if isinstance(data, str):
+ data = bytearray(data)
+
# Ensure write is not interrupted by SIGTERM
@uninterruptible
def _store():
# Save file extension
- with atomic_writer(metadata_path, 'wb') as file_obj:
+ with atomic_writer(metadata_path, "w") as file_obj:
file_obj.write(serializer_name)
- with atomic_writer(data_path, 'wb') as file_obj:
+ with serializer.atomic_writer(data_path, "w") as file_obj:
serializer.dump(data, file_obj)
_store()
- self.logger.debug('saved data: %s', data_path)
+ self.logger.debug("saved data: %s", data_path)
def cached_data(self, name, data_func=None, max_age=60):
"""Return cached data if younger than ``max_age`` seconds.
@@ -1875,13 +1708,13 @@ def cached_data(self, name, data_func=None, max_age=60):
"""
serializer = manager.serializer(self.cache_serializer)
- cache_path = self.cachefile('%s.%s' % (name, self.cache_serializer))
+ cache_path = self.cachefile("%s.%s" % (name, self.cache_serializer))
age = self.cached_data_age(name)
if (age < max_age or max_age == 0) and os.path.exists(cache_path):
- with open(cache_path, 'rb') as file_obj:
- self.logger.debug('loading cached data: %s', cache_path)
+ with open(cache_path, "rb") as file_obj:
+ self.logger.debug("loading cached data: %s", cache_path)
return serializer.load(file_obj)
if not data_func:
@@ -1905,18 +1738,18 @@ def cache_data(self, name, data):
"""
serializer = manager.serializer(self.cache_serializer)
- cache_path = self.cachefile('%s.%s' % (name, self.cache_serializer))
+ cache_path = self.cachefile("%s.%s" % (name, self.cache_serializer))
if data is None:
if os.path.exists(cache_path):
os.unlink(cache_path)
- self.logger.debug('deleted cache file: %s', cache_path)
+ self.logger.debug("deleted cache file: %s", cache_path)
return
- with atomic_writer(cache_path, 'wb') as file_obj:
+ with serializer.atomic_writer(cache_path, "w") as file_obj:
serializer.dump(data, file_obj)
- self.logger.debug('cached data: %s', cache_path)
+ self.logger.debug("cached data: %s", cache_path)
def cached_data_fresh(self, name, max_age):
"""Whether cache `name` is less than `max_age` seconds old.
@@ -1944,16 +1777,25 @@ def cached_data_age(self, name):
:rtype: ``int``
"""
- cache_path = self.cachefile('%s.%s' % (name, self.cache_serializer))
+ cache_path = self.cachefile("%s.%s" % (name, self.cache_serializer))
if not os.path.exists(cache_path):
return 0
return time.time() - os.stat(cache_path).st_mtime
- def filter(self, query, items, key=lambda x: x, ascending=False,
- include_score=False, min_score=0, max_results=0,
- match_on=MATCH_ALL, fold_diacritics=True):
+ def filter(
+ self,
+ query,
+ items,
+ key=lambda x: x,
+ ascending=False,
+ include_score=False,
+ min_score=0,
+ max_results=0,
+ match_on=MATCH_ALL,
+ fold_diacritics=True,
+ ):
"""Fuzzy search filter. Returns list of ``items`` that match ``query``.
``query`` is case-insensitive. Any item that does not contain the
@@ -2062,23 +1904,23 @@ def filter(self, query, items, key=lambda x: x, ascending=False,
return items
# Use user override if there is one
- fold_diacritics = self.settings.get('__workflow_diacritic_folding',
- fold_diacritics)
+ fold_diacritics = self.settings.get(
+ "__workflow_diacritic_folding", fold_diacritics
+ )
results = []
for item in items:
skip = False
score = 0
- words = [s.strip() for s in query.split(' ')]
+ words = [s.strip() for s in query.split(" ")]
value = key(item).strip()
- if value == '':
+ if value == "":
continue
for word in words:
- if word == '':
+ if word == "":
continue
- s, rule = self._filter_item(value, word, match_on,
- fold_diacritics)
+ s, rule = self._filter_item(value, word, match_on, fold_diacritics)
if not s: # Skip items that don't match part of the query
skip = True
@@ -2091,8 +1933,9 @@ def filter(self, query, items, key=lambda x: x, ascending=False,
# use "reversed" `score` (i.e. highest becomes lowest) and
# `value` as sort key. This means items with the same score
# will be sorted in alphabetical not reverse alphabetical order
- results.append(((100.0 / score, value.lower(), score),
- (item, score, rule)))
+ results.append(
+ ((100.0 / score, value.lower(), score), (item, score, rule))
+ )
# sort on keys, then discard the keys
results.sort(reverse=ascending)
@@ -2139,7 +1982,7 @@ def _filter_item(self, value, query, match_on, fold_diacritics):
# query matches capitalised letters in item,
# e.g. of = OmniFocus
if match_on & MATCH_CAPITALS:
- initials = ''.join([c for c in value if c in INITIALS])
+ initials = "".join([c for c in value if c in INITIALS])
if initials.lower().startswith(query):
score = 100.0 - (len(initials) / len(query))
@@ -2147,13 +1990,15 @@ def _filter_item(self, value, query, match_on, fold_diacritics):
# split the item into "atoms", i.e. words separated by
# spaces or other non-word characters
- if (match_on & MATCH_ATOM or
- match_on & MATCH_INITIALS_CONTAIN or
- match_on & MATCH_INITIALS_STARTSWITH):
+ if (
+ match_on & MATCH_ATOM
+ or match_on & MATCH_INITIALS_CONTAIN
+ or match_on & MATCH_INITIALS_STARTSWITH
+ ):
atoms = [s.lower() for s in split_on_delimiters(value)]
# print('atoms : %s --> %s' % (value, atoms))
# initials of the atoms
- initials = ''.join([s[0] for s in atoms if s])
+ initials = "".join([s[0] for s in atoms if s])
if match_on & MATCH_ATOM:
# is `query` one of the atoms in item?
@@ -2168,16 +2013,14 @@ def _filter_item(self, value, query, match_on, fold_diacritics):
# atoms, e.g. ``himym`` matches "How I Met Your Mother"
# *and* "how i met your mother" (the ``capitals`` rule only
# matches the former)
- if (match_on & MATCH_INITIALS_STARTSWITH and
- initials.startswith(query)):
+ if match_on & MATCH_INITIALS_STARTSWITH and initials.startswith(query):
score = 100.0 - (len(initials) / len(query))
return (score, MATCH_INITIALS_STARTSWITH)
# `query` is a substring of initials, e.g. ``doh`` matches
# "The Dukes of Hazzard"
- elif (match_on & MATCH_INITIALS_CONTAIN and
- query in initials):
+ elif match_on & MATCH_INITIALS_CONTAIN and query in initials:
score = 95.0 - (len(initials) / len(query))
return (score, MATCH_INITIALS_CONTAIN)
@@ -2194,8 +2037,9 @@ def _filter_item(self, value, query, match_on, fold_diacritics):
search = self._search_for_query(query)
match = search(value)
if match:
- score = 100.0 / ((1 + match.start()) *
- (match.end() - match.start() + 1))
+ score = 100.0 / (
+ (1 + match.start()) * (match.end() - match.start() + 1)
+ )
return (score, MATCH_ALLCHARS)
@@ -2210,8 +2054,8 @@ def _search_for_query(self, query):
pattern = []
for c in query:
# pattern.append('[^{0}]*{0}'.format(re.escape(c)))
- pattern.append('.*?{0}'.format(re.escape(c)))
- pattern = ''.join(pattern)
+ pattern.append(".*?{0}".format(re.escape(c)))
+ pattern = "".join(pattern)
search = re.compile(pattern, re.IGNORECASE).search
self._search_pattern_cache[query] = search
@@ -2239,21 +2083,25 @@ def run(self, func, text_errors=False):
"""
start = time.time()
+ # Write to debugger to ensure "real" output starts on a new line
+ print(".", file=sys.stderr)
+
# Call workflow's entry function/method within a try-except block
# to catch any errors and display an error message in Alfred
try:
if self.version:
- self.logger.debug('---------- %s (%s) ----------',
- self.name, self.version)
+ self.logger.debug(
+ "---------- %s (%s) ----------", self.name, self.version
+ )
else:
- self.logger.debug('---------- %s ----------', self.name)
+ self.logger.debug("---------- %s ----------", self.name)
# Run update check if configured for self-updates.
# This call has to go in the `run` try-except block, as it will
# initialise `self.settings`, which will raise an exception
# if `settings.json` isn't valid.
- if self._update_settings:
- self.check_update()
+ #if self._update_settings:
+ # self.check_update()
# Run workflow's entry function/method
func(self)
@@ -2265,11 +2113,11 @@ def run(self, func, text_errors=False):
except Exception as err:
self.logger.exception(err)
if self.help_url:
- self.logger.info('for assistance, see: %s', self.help_url)
+ self.logger.info("for assistance, see: %s", self.help_url)
if not sys.stdout.isatty(): # Show error in Alfred
if text_errors:
- print(unicode(err).encode('utf-8'), end='')
+ print(str(err).encode("utf-8"), end="")
else:
self._items = []
if self._name:
@@ -2278,24 +2126,37 @@ def run(self, func, text_errors=False):
name = self._bundleid
else: # pragma: no cover
name = os.path.dirname(__file__)
- self.add_item("Error in workflow '%s'" % name,
- unicode(err),
- icon=ICON_ERROR)
+ self.add_item(
+ "Error in workflow '%s'" % name, str(err), icon=ICON_ERROR
+ )
self.send_feedback()
return 1
finally:
- self.logger.debug('---------- finished in %0.3fs ----------',
- time.time() - start)
+ self.logger.debug(
+ "---------- finished in %0.3fs ----------", time.time() - start
+ )
return 0
# Alfred feedback methods ------------------------------------------
- def add_item(self, title, subtitle='', modifier_subtitles=None, arg=None,
- autocomplete=None, valid=False, uid=None, icon=None,
- icontype=None, type=None, largetext=None, copytext=None,
- quicklookurl=None):
+ def add_item(
+ self,
+ title,
+ subtitle="",
+ modifier_subtitles=None,
+ arg=None,
+ autocomplete=None,
+ valid=False,
+ uid=None,
+ icon=None,
+ icontype=None,
+ type=None,
+ largetext=None,
+ copytext=None,
+ quicklookurl=None,
+ ):
"""Add an item to be output to Alfred.
:param title: Title shown in Alfred
@@ -2353,19 +2214,31 @@ def add_item(self, title, subtitle='', modifier_subtitles=None, arg=None,
edit it or do something with it other than send it to Alfred.
"""
- item = self.item_class(title, subtitle, modifier_subtitles, arg,
- autocomplete, valid, uid, icon, icontype, type,
- largetext, copytext, quicklookurl)
+ item = self.item_class(
+ title,
+ subtitle,
+ modifier_subtitles,
+ arg,
+ autocomplete,
+ valid,
+ uid,
+ icon,
+ icontype,
+ type,
+ largetext,
+ copytext,
+ quicklookurl,
+ )
self._items.append(item)
return item
def send_feedback(self):
"""Print stored items to console/Alfred as XML."""
- root = ET.Element('items')
+ root = ET.Element("items")
for item in self._items:
root.append(item.elem)
sys.stdout.write('\n')
- sys.stdout.write(ET.tostring(root).encode('utf-8'))
+ sys.stdout.write(ET.tostring(root, encoding="unicode"))
sys.stdout.flush()
####################################################################
@@ -2382,7 +2255,7 @@ def first_run(self):
"""
if not self.version:
- raise ValueError('No workflow version set')
+ raise ValueError("No workflow version set")
if not self.last_version_run:
return True
@@ -2401,14 +2274,15 @@ def last_version_run(self):
"""
if self._last_version_run is UNSET:
- version = self.settings.get('__workflow_last_version')
+ version = self.settings.get("__workflow_last_version")
if version:
- from update import Version
+ from .update import Version
+
version = Version(version)
self._last_version_run = version
- self.logger.debug('last run version: %s', self._last_version_run)
+ self.logger.debug("last run version: %s", self._last_version_run)
return self._last_version_run
@@ -2425,19 +2299,19 @@ def set_last_version(self, version=None):
"""
if not version:
if not self.version:
- self.logger.warning(
- "Can't save last version: workflow has no version")
+ self.logger.warning("Can't save last version: workflow has no version")
return False
version = self.version
- if isinstance(version, basestring):
- from update import Version
+ if isinstance(version, str):
+ from .update import Version
+
version = Version(version)
- self.settings['__workflow_last_version'] = str(version)
+ self.settings["__workflow_last_version"] = str(version)
- self.logger.debug('set last run version: %s', version)
+ self.logger.debug("set last run version: %s", version)
return True
@@ -2453,17 +2327,16 @@ def update_available(self):
:returns: ``True`` if an update is available, else ``False``
"""
+ key = "__workflow_latest_version"
# Create a new workflow object to ensure standard serialiser
# is used (update.py is called without the user's settings)
- update_data = Workflow().cached_data('__workflow_update_status',
- max_age=0)
-
- self.logger.debug('update_data: %r', update_data)
+ status = Workflow().cached_data(key, max_age=0)
- if not update_data or not update_data.get('available'):
+ # self.logger.debug('update status: %r', status)
+ if not status or not status.get("available"):
return False
- return update_data['available']
+ return status["available"]
@property
def prereleases(self):
@@ -2476,10 +2349,10 @@ def prereleases(self):
``False``.
"""
- if self._update_settings.get('prereleases'):
+ if self._update_settings.get("prereleases"):
return True
- return self.settings.get('__workflow_prereleases') or False
+ return self.settings.get("__workflow_prereleases") or False
def check_update(self, force=False):
"""Call update script if it's time to check for a new release.
@@ -2496,39 +2369,34 @@ def check_update(self, force=False):
:type force: ``Boolean``
"""
- frequency = self._update_settings.get('frequency',
- DEFAULT_UPDATE_FREQUENCY)
+ key = "__workflow_latest_version"
+ frequency = self._update_settings.get("frequency", DEFAULT_UPDATE_FREQUENCY)
- if not force and not self.settings.get('__workflow_autoupdate', True):
- self.logger.debug('Auto update turned off by user')
+ if not force and not self.settings.get("__workflow_autoupdate", True):
+ self.logger.debug("Auto update turned off by user")
return
# Check for new version if it's time
- if (force or not self.cached_data_fresh(
- '__workflow_update_status', frequency * 86400)):
-
- github_slug = self._update_settings['github_slug']
+ if force or not self.cached_data_fresh(key, frequency * 86400):
+ repo = self._update_settings["github_slug"]
# version = self._update_settings['version']
version = str(self.version)
- from background import run_in_background
+ from .background import run_in_background
# update.py is adjacent to this file
- update_script = os.path.join(os.path.dirname(__file__),
- b'update.py')
-
- cmd = ['/usr/bin/python', update_script, 'check', github_slug,
- version]
+ update_script = os.path.join(os.path.dirname(__file__), "update.py")
+ cmd = [sys.executable, update_script, "check", repo, version]
if self.prereleases:
- cmd.append('--prereleases')
+ cmd.append("--prereleases")
- self.logger.info('checking for update ...')
+ self.logger.info("checking for update ...")
- run_in_background('__workflow_update_check', cmd)
+ run_in_background("__workflow_update_check", cmd)
else:
- self.logger.debug('update check not due')
+ self.logger.debug("update check not due")
def start_update(self):
"""Check for update and download and install new workflow file.
@@ -2542,29 +2410,27 @@ def start_update(self):
installed, else ``False``
"""
- import update
+ from . import update
- github_slug = self._update_settings['github_slug']
+ repo = self._update_settings["github_slug"]
# version = self._update_settings['version']
version = str(self.version)
- if not update.check_update(github_slug, version, self.prereleases):
+ if not update.check_update(repo, version, self.prereleases):
return False
- from background import run_in_background
+ from .background import run_in_background
# update.py is adjacent to this file
- update_script = os.path.join(os.path.dirname(__file__),
- b'update.py')
+ update_script = os.path.join(os.path.dirname(__file__), "update.py")
- cmd = ['/usr/bin/python', update_script, 'install', github_slug,
- version]
+ cmd = [sys.executable, update_script, "install", repo, version]
if self.prereleases:
- cmd.append('--prereleases')
+ cmd.append("--prereleases")
- self.logger.debug('downloading update ...')
- run_in_background('__workflow_update_install', cmd)
+ self.logger.debug("downloading update ...")
+ run_in_background("__workflow_update_install", cmd)
return True
@@ -2595,22 +2461,24 @@ def save_password(self, account, password, service=None):
service = self.bundleid
try:
- self._call_security('add-generic-password', service, account,
- '-w', password)
- self.logger.debug('saved password : %s:%s', service, account)
+ self._call_security(
+ "add-generic-password", service, account, "-w", password
+ )
+ self.logger.debug("saved password : %s:%s", service, account)
except PasswordExists:
- self.logger.debug('password exists : %s:%s', service, account)
+ self.logger.debug("password exists : %s:%s", service, account)
current_password = self.get_password(account, service)
if current_password == password:
- self.logger.debug('password unchanged')
+ self.logger.debug("password unchanged")
else:
self.delete_password(account, service)
- self._call_security('add-generic-password', service,
- account, '-w', password)
- self.logger.debug('save_password : %s:%s', service, account)
+ self._call_security(
+ "add-generic-password", service, account, "-w", password
+ )
+ self.logger.debug("save_password : %s:%s", service, account)
def get_password(self, account, service=None):
"""Retrieve the password saved at ``service/account``.
@@ -2630,24 +2498,23 @@ def get_password(self, account, service=None):
if not service:
service = self.bundleid
- output = self._call_security('find-generic-password', service,
- account, '-g')
+ output = self._call_security("find-generic-password", service, account, "-g")
# Parsing of `security` output is adapted from python-keyring
# by Jason R. Coombs
# https://pypi.python.org/pypi/keyring
m = re.search(
- r'password:\s*(?:0x(?P[0-9A-F]+)\s*)?(?:"(?P.*)")?',
- output)
+ r'password:\s*(?:0x(?P[0-9A-F]+)\s*)?(?:"(?P.*)")?', output
+ )
if m:
groups = m.groupdict()
- h = groups.get('hex')
- password = groups.get('pw')
+ h = groups.get("hex")
+ password = groups.get("pw")
if h:
- password = unicode(binascii.unhexlify(h), 'utf-8')
+ password = str(binascii.unhexlify(h), "utf-8")
- self.logger.debug('got password : %s:%s', service, account)
+ self.logger.debug("got password : %s:%s", service, account)
return password
@@ -2667,15 +2534,15 @@ def delete_password(self, account, service=None):
if not service:
service = self.bundleid
- self._call_security('delete-generic-password', service, account)
+ self._call_security("delete-generic-password", service, account)
- self.logger.debug('deleted password : %s:%s', service, account)
+ self.logger.debug("deleted password : %s:%s", service, account)
####################################################################
# Methods for workflow:* magic args
####################################################################
- def _register_default_magic(self):
+ def _register_default_magic(self): # noqa: C901
"""Register the built-in magic arguments."""
# TODO: refactor & simplify
# Wrap callback and message with callable
@@ -2686,91 +2553,98 @@ def wrapper():
return wrapper
- self.magic_arguments['delcache'] = callback(self.clear_cache,
- 'Deleted workflow cache')
- self.magic_arguments['deldata'] = callback(self.clear_data,
- 'Deleted workflow data')
- self.magic_arguments['delsettings'] = callback(
- self.clear_settings, 'Deleted workflow settings')
- self.magic_arguments['reset'] = callback(self.reset,
- 'Reset workflow')
- self.magic_arguments['openlog'] = callback(self.open_log,
- 'Opening workflow log file')
- self.magic_arguments['opencache'] = callback(
- self.open_cachedir, 'Opening workflow cache directory')
- self.magic_arguments['opendata'] = callback(
- self.open_datadir, 'Opening workflow data directory')
- self.magic_arguments['openworkflow'] = callback(
- self.open_workflowdir, 'Opening workflow directory')
- self.magic_arguments['openterm'] = callback(
- self.open_terminal, 'Opening workflow root directory in Terminal')
+ self.magic_arguments["delcache"] = callback(
+ self.clear_cache, "Deleted workflow cache"
+ )
+ self.magic_arguments["deldata"] = callback(
+ self.clear_data, "Deleted workflow data"
+ )
+ self.magic_arguments["delsettings"] = callback(
+ self.clear_settings, "Deleted workflow settings"
+ )
+ self.magic_arguments["reset"] = callback(self.reset, "Reset workflow")
+ self.magic_arguments["openlog"] = callback(
+ self.open_log, "Opening workflow log file"
+ )
+ self.magic_arguments["opencache"] = callback(
+ self.open_cachedir, "Opening workflow cache directory"
+ )
+ self.magic_arguments["opendata"] = callback(
+ self.open_datadir, "Opening workflow data directory"
+ )
+ self.magic_arguments["openworkflow"] = callback(
+ self.open_workflowdir, "Opening workflow directory"
+ )
+ self.magic_arguments["openterm"] = callback(
+ self.open_terminal, "Opening workflow root directory in Terminal"
+ )
# Diacritic folding
def fold_on():
- self.settings['__workflow_diacritic_folding'] = True
- return 'Diacritics will always be folded'
+ self.settings["__workflow_diacritic_folding"] = True
+ return "Diacritics will always be folded"
def fold_off():
- self.settings['__workflow_diacritic_folding'] = False
- return 'Diacritics will never be folded'
+ self.settings["__workflow_diacritic_folding"] = False
+ return "Diacritics will never be folded"
def fold_default():
- if '__workflow_diacritic_folding' in self.settings:
- del self.settings['__workflow_diacritic_folding']
- return 'Diacritics folding reset'
+ if "__workflow_diacritic_folding" in self.settings:
+ del self.settings["__workflow_diacritic_folding"]
+ return "Diacritics folding reset"
- self.magic_arguments['foldingon'] = fold_on
- self.magic_arguments['foldingoff'] = fold_off
- self.magic_arguments['foldingdefault'] = fold_default
+ self.magic_arguments["foldingon"] = fold_on
+ self.magic_arguments["foldingoff"] = fold_off
+ self.magic_arguments["foldingdefault"] = fold_default
# Updates
def update_on():
- self.settings['__workflow_autoupdate'] = True
- return 'Auto update turned on'
+ self.settings["__workflow_autoupdate"] = True
+ return "Auto update turned on"
def update_off():
- self.settings['__workflow_autoupdate'] = False
- return 'Auto update turned off'
+ self.settings["__workflow_autoupdate"] = False
+ return "Auto update turned off"
def prereleases_on():
- self.settings['__workflow_prereleases'] = True
- return 'Prerelease updates turned on'
+ self.settings["__workflow_prereleases"] = True
+ return "Prerelease updates turned on"
def prereleases_off():
- self.settings['__workflow_prereleases'] = False
- return 'Prerelease updates turned off'
+ self.settings["__workflow_prereleases"] = False
+ return "Prerelease updates turned off"
def do_update():
if self.start_update():
- return 'Downloading and installing update ...'
+ return "Downloading and installing update ..."
else:
- return 'No update available'
+ return "No update available"
- self.magic_arguments['autoupdate'] = update_on
- self.magic_arguments['noautoupdate'] = update_off
- self.magic_arguments['prereleases'] = prereleases_on
- self.magic_arguments['noprereleases'] = prereleases_off
- self.magic_arguments['update'] = do_update
+ self.magic_arguments["autoupdate"] = update_on
+ self.magic_arguments["noautoupdate"] = update_off
+ self.magic_arguments["prereleases"] = prereleases_on
+ self.magic_arguments["noprereleases"] = prereleases_off
+ self.magic_arguments["update"] = do_update
# Help
def do_help():
if self.help_url:
self.open_help()
- return 'Opening workflow help URL in browser'
+ return "Opening workflow help URL in browser"
else:
- return 'Workflow has no help URL'
+ return "Workflow has no help URL"
def show_version():
if self.version:
- return 'Version: {0}'.format(self.version)
+ return "Version: {0}".format(self.version)
else:
- return 'This workflow has no version number'
+ return "This workflow has no version number"
def list_magic():
"""Display all available magic args in Alfred."""
isatty = sys.stderr.isatty()
for name in sorted(self.magic_arguments.keys()):
- if name == 'magic':
+ if name == "magic":
continue
arg = self.magic_prefix + name
self.logger.debug(arg)
@@ -2781,9 +2655,9 @@ def list_magic():
if not isatty:
self.send_feedback()
- self.magic_arguments['help'] = do_help
- self.magic_arguments['magic'] = list_magic
- self.magic_arguments['version'] = show_version
+ self.magic_arguments["help"] = do_help
+ self.magic_arguments["magic"] = list_magic
+ self.magic_arguments["version"] = show_version
def clear_cache(self, filter_func=lambda f: True):
"""Delete all files in workflow's :attr:`cachedir`.
@@ -2813,7 +2687,7 @@ def clear_settings(self):
"""Delete workflow's :attr:`settings_path`."""
if os.path.exists(self.settings_path):
os.unlink(self.settings_path)
- self.logger.debug('deleted : %r', self.settings_path)
+ self.logger.debug("deleted : %r", self.settings_path)
def reset(self):
"""Delete workflow settings, cache and data.
@@ -2828,30 +2702,29 @@ def reset(self):
def open_log(self):
"""Open :attr:`logfile` in default app (usually Console.app)."""
- subprocess.call(['open', self.logfile])
+ subprocess.call(["open", self.logfile]) # nosec
def open_cachedir(self):
"""Open the workflow's :attr:`cachedir` in Finder."""
- subprocess.call(['open', self.cachedir])
+ subprocess.call(["open", self.cachedir]) # nosec
def open_datadir(self):
"""Open the workflow's :attr:`datadir` in Finder."""
- subprocess.call(['open', self.datadir])
+ subprocess.call(["open", self.datadir]) # nosec
def open_workflowdir(self):
"""Open the workflow's :attr:`workflowdir` in Finder."""
- subprocess.call(['open', self.workflowdir])
+ subprocess.call(["open", self.workflowdir]) # nosec
def open_terminal(self):
"""Open a Terminal window at workflow's :attr:`workflowdir`."""
- subprocess.call(['open', '-a', 'Terminal',
- self.workflowdir])
+ subprocess.call(["open", "-a", "Terminal", self.workflowdir]) # nosec
def open_help(self):
"""Open :attr:`help_url` in default browser."""
- subprocess.call(['open', self.help_url])
+ subprocess.call(["open", self.help_url]) # nosec
- return 'Opening workflow help URL in browser'
+ return "Opening workflow help URL in browser"
####################################################################
# Helper methods
@@ -2887,8 +2760,8 @@ def decode(self, text, encoding=None, normalization=None):
"""
encoding = encoding or self._input_encoding
normalization = normalization or self._normalizsation
- if not isinstance(text, unicode):
- text = unicode(text, encoding)
+ if not isinstance(text, str):
+ text = str(text, encoding)
return unicodedata.normalize(normalization, text)
def fold_to_ascii(self, text):
@@ -2906,9 +2779,8 @@ def fold_to_ascii(self, text):
"""
if isascii(text):
return text
- text = ''.join([ASCII_REPLACEMENTS.get(c, c) for c in text])
- return unicode(unicodedata.normalize('NFKD',
- text).encode('ascii', 'ignore'))
+ text = "".join([ASCII_REPLACEMENTS.get(c, c) for c in text])
+ return unicodedata.normalize("NFKD", text)
def dumbify_punctuation(self, text):
"""Convert non-ASCII punctuation to closest ASCII equivalent.
@@ -2928,7 +2800,7 @@ def dumbify_punctuation(self, text):
if isascii(text):
return text
- text = ''.join([DUMB_PUNCTUATION.get(c, c) for c in text])
+ text = "".join([DUMB_PUNCTUATION.get(c, c) for c in text])
return text
def _delete_directory_contents(self, dirpath, filter_func):
@@ -2950,12 +2822,13 @@ def _delete_directory_contents(self, dirpath, filter_func):
shutil.rmtree(path)
else:
os.unlink(path)
- self.logger.debug('deleted : %r', path)
+ self.logger.debug("deleted : %r", path)
def _load_info_plist(self):
"""Load workflow info from ``info.plist``."""
# info.plist should be in the directory above this one
- self._info = plistlib.readPlist(self.workflowfile('info.plist'))
+ with open(self.workflowfile("info.plist"), "rb") as file_obj:
+ self._info = plistlib.load(file_obj)
self._info_loaded = True
def _create(self, dirpath):
@@ -2995,16 +2868,15 @@ def _call_security(self, action, service, account, *args):
:rtype: `tuple` (`int`, ``unicode``)
"""
- cmd = ['security', action, '-s', service, '-a', account] + list(args)
- p = subprocess.Popen(cmd, stdout=subprocess.PIPE,
- stderr=subprocess.STDOUT)
+ cmd = ["security", action, "-s", service, "-a", account] + list(args)
+ p = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
stdout, _ = p.communicate()
if p.returncode == 44: # password does not exist
raise PasswordNotFound()
elif p.returncode == 45: # password already exists
raise PasswordExists()
elif p.returncode > 0:
- err = KeychainError('Unknown Keychain error : %s' % stdout)
+ err = KeychainError("Unknown Keychain error : %s" % stdout)
err.retcode = p.returncode
raise err
- return stdout.strip().decode('utf-8')
+ return stdout.strip().decode("utf-8")
diff --git a/workflow/workflow3.py b/src/workflow/workflow3.py
similarity index 72%
rename from workflow/workflow3.py
rename to src/workflow/workflow3.py
index e800b60..3a06e33 100644
--- a/workflow/workflow3.py
+++ b/src/workflow/workflow3.py
@@ -7,11 +7,11 @@
# Created on 2016-06-25
#
-"""An Alfred 3-only version of :class:`~workflow.Workflow`.
+"""An Alfred 3+ version of :class:`~workflow.Workflow`.
-:class:`~workflow.Workflow3` supports Alfred 3's new features, such as
+:class:`~workflow.Workflow3` supports new features, such as
setting :ref:`workflow-variables` and
-:class:`the more advanced modifiers ` supported by Alfred 3.
+:class:`the more advanced modifiers ` supported by Alfred 3+.
In order for the feedback mechanism to work correctly, it's important
to create :class:`Item3` and :class:`Modifier` objects via the
@@ -23,13 +23,12 @@
"""
-from __future__ import print_function, unicode_literals, absolute_import
import json
import os
import sys
-from .workflow import Workflow
+from .workflow import ICON_WARNING, Workflow
class Variables(dict):
@@ -50,12 +49,16 @@ class Variables(dict):
information.
Args:
- arg (unicode, optional): Main output/``{query}``.
+ arg (unicode or list, optional): Main output/``{query}``.
**variables: Workflow variables to set.
+ In Alfred 4.1+ and Alfred-Workflow 1.40+, ``arg`` may also be a
+ :class:`list` or :class:`tuple`.
Attributes:
- arg (unicode): Output value (``{query}``).
+ arg (unicode or list): Output value (``{query}``).
+ In Alfred 4.1+ and Alfred-Workflow 1.40+, ``arg`` may also be a
+ :class:`list` or :class:`tuple`.
config (dict): Configuration for downstream workflow element.
"""
@@ -68,23 +71,23 @@ def __init__(self, arg=None, **variables):
@property
def obj(self):
- """Return ``alfredworkflow`` `dict`."""
+ """``alfredworkflow`` :class:`dict`."""
o = {}
if self:
d2 = {}
- for k, v in self.items():
+ for k, v in list(self.items()):
d2[k] = v
- o['variables'] = d2
+ o["variables"] = d2
if self.config:
- o['config'] = self.config
+ o["config"] = self.config
if self.arg is not None:
- o['arg'] = self.arg
+ o["arg"] = self.arg
- return {'alfredworkflow': o}
+ return {"alfredworkflow": o}
- def __unicode__(self):
+ def __str__(self):
"""Convert to ``alfredworkflow`` JSON object.
Returns:
@@ -92,22 +95,13 @@ def __unicode__(self):
"""
if not self and not self.config:
- if self.arg:
+ if not self.arg:
+ return ""
+ if isinstance(self.arg, str):
return self.arg
- else:
- return u''
return json.dumps(self.obj)
- def __str__(self):
- """Convert to ``alfredworkflow`` JSON object.
-
- Returns:
- str: UTF-8 encoded ``alfredworkflow`` JSON object
-
- """
- return unicode(self).encode('utf-8')
-
class Modifier(object):
"""Modify :class:`Item3` arg/icon/variables when modifier key is pressed.
@@ -149,8 +143,9 @@ class Modifier(object):
"""
- def __init__(self, key, subtitle=None, arg=None, valid=None, icon=None,
- icontype=None):
+ def __init__(
+ self, key, subtitle=None, arg=None, valid=None, icon=None, icontype=None
+ ):
"""Create a new :class:`Modifier`.
Don't use this class directly (as it won't be associated with any
@@ -212,23 +207,23 @@ def obj(self):
o = {}
if self.subtitle is not None:
- o['subtitle'] = self.subtitle
+ o["subtitle"] = self.subtitle
if self.arg is not None:
- o['arg'] = self.arg
+ o["arg"] = self.arg
if self.valid is not None:
- o['valid'] = self.valid
+ o["valid"] = self.valid
if self.variables:
- o['variables'] = self.variables
+ o["variables"] = self.variables
if self.config:
- o['config'] = self.config
+ o["config"] = self.config
icon = self._icon()
if icon:
- o['icon'] = icon
+ o["icon"] = icon
return o
@@ -241,16 +236,16 @@ def _icon(self):
"""
icon = {}
if self.icon is not None:
- icon['path'] = self.icon
+ icon["path"] = self.icon
if self.icontype is not None:
- icon['type'] = self.icontype
+ icon["type"] = self.icontype
return icon
class Item3(object):
- """Represents a feedback item for Alfred 3.
+ """Represents a feedback item for Alfred 3+.
Generates Alfred-compliant JSON for a single item.
@@ -261,9 +256,22 @@ class Item3(object):
"""
- def __init__(self, title, subtitle='', arg=None, autocomplete=None,
- match=None, valid=False, uid=None, icon=None, icontype=None,
- type=None, largetext=None, copytext=None, quicklookurl=None):
+ def __init__(
+ self,
+ title,
+ subtitle="",
+ arg=None,
+ autocomplete=None,
+ match=None,
+ valid=False,
+ uid=None,
+ icon=None,
+ icontype=None,
+ type=None,
+ largetext=None,
+ copytext=None,
+ quicklookurl=None,
+ ):
"""Create a new :class:`Item3` object.
Use same arguments as for
@@ -314,8 +322,9 @@ def getvar(self, name, default=None):
"""
return self.variables.get(name, default)
- def add_modifier(self, key, subtitle=None, arg=None, valid=None, icon=None,
- icontype=None):
+ def add_modifier(
+ self, key, subtitle=None, arg=None, valid=None, icon=None, icontype=None
+ ):
"""Add alternative values for a modifier key.
Args:
@@ -328,14 +337,17 @@ def add_modifier(self, key, subtitle=None, arg=None, valid=None, icon=None,
:meth:`Workflow.add_item() `
for valid values.
+ In Alfred 4.1+ and Alfred-Workflow 1.40+, ``arg`` may also be a
+ :class:`list` or :class:`tuple`.
+
Returns:
Modifier: Configured :class:`Modifier`.
"""
mod = Modifier(key, subtitle, arg, valid, icon, icontype)
- for k in self.variables:
- mod.setvar(k, self.variables[k])
+ # Add Item variables to Modifier
+ mod.variables.update(self.variables)
self.modifiers[key] = mod
@@ -350,50 +362,46 @@ def obj(self):
"""
# Required values
- o = {
- 'title': self.title,
- 'subtitle': self.subtitle,
- 'valid': self.valid,
- }
+ o = {"title": self.title, "subtitle": self.subtitle, "valid": self.valid}
# Optional values
if self.arg is not None:
- o['arg'] = self.arg
+ o["arg"] = self.arg
if self.autocomplete is not None:
- o['autocomplete'] = self.autocomplete
+ o["autocomplete"] = self.autocomplete
if self.match is not None:
- o['match'] = self.match
+ o["match"] = self.match
if self.uid is not None:
- o['uid'] = self.uid
+ o["uid"] = self.uid
if self.type is not None:
- o['type'] = self.type
+ o["type"] = self.type
if self.quicklookurl is not None:
- o['quicklookurl'] = self.quicklookurl
+ o["quicklookurl"] = self.quicklookurl
if self.variables:
- o['variables'] = self.variables
+ o["variables"] = self.variables
if self.config:
- o['config'] = self.config
+ o["config"] = self.config
# Largetype and copytext
text = self._text()
if text:
- o['text'] = text
+ o["text"] = text
icon = self._icon()
if icon:
- o['icon'] = icon
+ o["icon"] = icon
# Modifiers
mods = self._modifiers()
if mods:
- o['mods'] = mods
+ o["mods"] = mods
return o
@@ -406,10 +414,10 @@ def _icon(self):
"""
icon = {}
if self.icon is not None:
- icon['path'] = self.icon
+ icon["path"] = self.icon
if self.icontype is not None:
- icon['type'] = self.icontype
+ icon["type"] = self.icontype
return icon
@@ -422,10 +430,10 @@ def _text(self):
"""
text = {}
if self.largetext is not None:
- text['largetype'] = self.largetext
+ text["largetype"] = self.largetext
if self.copytext is not None:
- text['copy'] = self.copytext
+ text["copy"] = self.copytext
return text
@@ -438,7 +446,7 @@ def _modifiers(self):
"""
if self.modifiers:
mods = {}
- for k, mod in self.modifiers.items():
+ for k, mod in list(self.modifiers.items()):
mods[k] = mod.obj
return mods
@@ -447,10 +455,10 @@ def _modifiers(self):
class Workflow3(Workflow):
- """Workflow class that generates Alfred 3 feedback.
+ """Workflow class that generates Alfred 3+ feedback.
- ``Workflow3`` is a subclass of :class:`~workflow.Workflow` and
- most of its methods are documented there.
+ It is a subclass of :class:`~workflow.Workflow` and most of its
+ methods are documented there.
Attributes:
item_class (class): Class used to generate feedback items.
@@ -470,25 +478,27 @@ def __init__(self, **kwargs):
self.variables = {}
self._rerun = 0
# Get session ID from environment if present
- self._session_id = os.getenv('_WF_SESSION_ID') or None
+ self._session_id = os.getenv("_WF_SESSION_ID") or None
if self._session_id:
- self.setvar('_WF_SESSION_ID', self._session_id)
+ self.setvar("_WF_SESSION_ID", self._session_id)
@property
def _default_cachedir(self):
- """Alfred 3's default cache directory."""
+ """Alfred 4's default cache directory."""
return os.path.join(
os.path.expanduser(
- '~/Library/Caches/com.runningwithcrayons.Alfred-3/'
- 'Workflow Data/'),
- self.bundleid)
+ "~/Library/Caches/com.runningwithcrayons.Alfred/" "Workflow Data/"
+ ),
+ self.bundleid,
+ )
@property
def _default_datadir(self):
- """Alfred 3's default data directory."""
- return os.path.join(os.path.expanduser(
- '~/Library/Application Support/Alfred 3/Workflow Data/'),
- self.bundleid)
+ """Alfred 4's default data directory."""
+ return os.path.join(
+ os.path.expanduser("~/Library/Application Support/Alfred/Workflow Data/"),
+ self.bundleid,
+ )
@property
def rerun(self):
@@ -517,14 +527,17 @@ def session_id(self):
"""
if not self._session_id:
from uuid import uuid4
+
self._session_id = uuid4().hex
- self.setvar('_WF_SESSION_ID', self._session_id)
+ self.setvar("_WF_SESSION_ID", self._session_id)
return self._session_id
- def setvar(self, name, value):
+ def setvar(self, name, value, persist=False):
"""Set a "global" workflow variable.
+ .. versionchanged:: 1.33
+
These variables are always passed to downstream workflow objects.
If you have set :attr:`rerun`, these variables are also passed
@@ -533,9 +546,17 @@ def setvar(self, name, value):
Args:
name (unicode): Name of variable.
value (unicode): Value of variable.
+ persist (bool, optional): Also save variable to ``info.plist``?
"""
self.variables[name] = value
+ if persist:
+ from .util import set_config
+
+ set_config(name, value, self.bundleid)
+ self.logger.debug(
+ "saved variable %r with value %r to info.plist", name, value
+ )
def getvar(self, name, default=None):
"""Return value of workflow variable for ``name`` or ``default``.
@@ -550,9 +571,22 @@ def getvar(self, name, default=None):
"""
return self.variables.get(name, default)
- def add_item(self, title, subtitle='', arg=None, autocomplete=None,
- valid=False, uid=None, icon=None, icontype=None, type=None,
- largetext=None, copytext=None, quicklookurl=None, match=None):
+ def add_item(
+ self,
+ title,
+ subtitle="",
+ arg=None,
+ autocomplete=None,
+ valid=False,
+ uid=None,
+ icon=None,
+ icontype=None,
+ type=None,
+ largetext=None,
+ copytext=None,
+ quicklookurl=None,
+ match=None,
+ ):
"""Add an item to be output to Alfred.
Args:
@@ -560,6 +594,9 @@ def add_item(self, title, subtitle='', arg=None, autocomplete=None,
turned on for your Script Filter, Alfred (version 3.5 and
above) will filter against this field, not ``title``.
+ In Alfred 4.1+ and Alfred-Workflow 1.40+, ``arg`` may also be a
+ :class:`list` or :class:`tuple`.
+
See :meth:`Workflow.add_item() ` for
the main documentation and other parameters.
@@ -571,9 +608,24 @@ def add_item(self, title, subtitle='', arg=None, autocomplete=None,
Item3: Alfred feedback item.
"""
- item = self.item_class(title, subtitle, arg, autocomplete,
- match, valid, uid, icon, icontype, type,
- largetext, copytext, quicklookurl)
+ item = self.item_class(
+ title,
+ subtitle,
+ arg,
+ autocomplete,
+ match,
+ valid,
+ uid,
+ icon,
+ icontype,
+ type,
+ largetext,
+ copytext,
+ quicklookurl,
+ )
+
+ # Add variables to child item
+ item.variables.update(self.variables)
self._items.append(item)
return item
@@ -581,7 +633,7 @@ def add_item(self, title, subtitle='', arg=None, autocomplete=None,
@property
def _session_prefix(self):
"""Filename prefix for current session."""
- return '_wfsess-{0}-'.format(self.session_id)
+ return "_wfsess-{0}-".format(self.session_id)
def _mk_session_name(self, name):
"""New cache name/key based on session ID."""
@@ -651,11 +703,13 @@ def clear_session_cache(self, current=False):
current session.
"""
+
def _is_session_file(filename):
if current:
- return filename.startswith('_wfsess-')
- return filename.startswith('_wfsess-') \
- and not filename.startswith(self._session_prefix)
+ return filename.startswith("_wfsess-")
+ return filename.startswith("_wfsess-") and not filename.startswith(
+ self._session_prefix
+ )
self.clear_cache(_is_session_file)
@@ -671,14 +725,43 @@ def obj(self):
for item in self._items:
items.append(item.obj)
- o = {'items': items}
+ o = {"items": items}
if self.variables:
- o['variables'] = self.variables
+ o["variables"] = self.variables
if self.rerun:
- o['rerun'] = self.rerun
+ o["rerun"] = self.rerun
return o
+ def warn_empty(self, title, subtitle="", icon=None):
+ """Add a warning to feedback if there are no items.
+
+ .. versionadded:: 1.31
+
+ Add a "warning" item to Alfred feedback if no other items
+ have been added. This is a handy shortcut to prevent Alfred
+ from showing its fallback searches, which is does if no
+ items are returned.
+
+ Args:
+ title (unicode): Title of feedback item.
+ subtitle (unicode, optional): Subtitle of feedback item.
+ icon (str, optional): Icon for feedback item. If not
+ specified, ``ICON_WARNING`` is used.
+
+ Returns:
+ Item3: Newly-created item.
+
+ """
+ if len(self._items):
+ return
+
+ icon = icon or ICON_WARNING
+ return self.add_item(title, subtitle, icon=icon)
+
def send_feedback(self):
"""Print stored items to console/Alfred as JSON."""
- json.dump(self.obj, sys.stdout)
+ if self.debugging:
+ json.dump(self.obj, sys.stdout, indent=2, separators=(",", ": "))
+ else:
+ json.dump(self.obj, sys.stdout)
sys.stdout.flush()
diff --git a/utils.pyc b/utils.pyc
deleted file mode 100644
index 51460d9..0000000
Binary files a/utils.pyc and /dev/null differ
diff --git a/workflow/__init__.py b/workflow/__init__.py
deleted file mode 100644
index 2c4f8c0..0000000
--- a/workflow/__init__.py
+++ /dev/null
@@ -1,108 +0,0 @@
-#!/usr/bin/env python
-# encoding: utf-8
-#
-# Copyright (c) 2014 Dean Jackson
-#
-# MIT Licence. See http://opensource.org/licenses/MIT
-#
-# Created on 2014-02-15
-#
-
-"""A helper library for `Alfred `_ workflows."""
-
-import os
-
-# Workflow objects
-from .workflow import Workflow, manager
-from .workflow3 import Variables, Workflow3
-
-# Exceptions
-from .workflow import PasswordNotFound, KeychainError
-
-# Icons
-from .workflow import (
- ICON_ACCOUNT,
- ICON_BURN,
- ICON_CLOCK,
- ICON_COLOR,
- ICON_COLOUR,
- ICON_EJECT,
- ICON_ERROR,
- ICON_FAVORITE,
- ICON_FAVOURITE,
- ICON_GROUP,
- ICON_HELP,
- ICON_HOME,
- ICON_INFO,
- ICON_NETWORK,
- ICON_NOTE,
- ICON_SETTINGS,
- ICON_SWIRL,
- ICON_SWITCH,
- ICON_SYNC,
- ICON_TRASH,
- ICON_USER,
- ICON_WARNING,
- ICON_WEB,
-)
-
-# Filter matching rules
-from .workflow import (
- MATCH_ALL,
- MATCH_ALLCHARS,
- MATCH_ATOM,
- MATCH_CAPITALS,
- MATCH_INITIALS,
- MATCH_INITIALS_CONTAIN,
- MATCH_INITIALS_STARTSWITH,
- MATCH_STARTSWITH,
- MATCH_SUBSTRING,
-)
-
-
-__title__ = 'Alfred-Workflow'
-__version__ = open(os.path.join(os.path.dirname(__file__), 'version')).read()
-__author__ = 'Dean Jackson'
-__licence__ = 'MIT'
-__copyright__ = 'Copyright 2014-2017 Dean Jackson'
-
-__all__ = [
- 'Variables',
- 'Workflow',
- 'Workflow3',
- 'manager',
- 'PasswordNotFound',
- 'KeychainError',
- 'ICON_ACCOUNT',
- 'ICON_BURN',
- 'ICON_CLOCK',
- 'ICON_COLOR',
- 'ICON_COLOUR',
- 'ICON_EJECT',
- 'ICON_ERROR',
- 'ICON_FAVORITE',
- 'ICON_FAVOURITE',
- 'ICON_GROUP',
- 'ICON_HELP',
- 'ICON_HOME',
- 'ICON_INFO',
- 'ICON_NETWORK',
- 'ICON_NOTE',
- 'ICON_SETTINGS',
- 'ICON_SWIRL',
- 'ICON_SWITCH',
- 'ICON_SYNC',
- 'ICON_TRASH',
- 'ICON_USER',
- 'ICON_WARNING',
- 'ICON_WEB',
- 'MATCH_ALL',
- 'MATCH_ALLCHARS',
- 'MATCH_ATOM',
- 'MATCH_CAPITALS',
- 'MATCH_INITIALS',
- 'MATCH_INITIALS_CONTAIN',
- 'MATCH_INITIALS_STARTSWITH',
- 'MATCH_STARTSWITH',
- 'MATCH_SUBSTRING',
-]
diff --git a/workflow/__init__.pyc b/workflow/__init__.pyc
deleted file mode 100644
index 90c01a2..0000000
Binary files a/workflow/__init__.pyc and /dev/null differ
diff --git a/workflow/update.py b/workflow/update.py
deleted file mode 100644
index 37569bb..0000000
--- a/workflow/update.py
+++ /dev/null
@@ -1,426 +0,0 @@
-#!/usr/bin/env python
-# encoding: utf-8
-#
-# Copyright (c) 2014 Fabio Niephaus ,
-# Dean Jackson
-#
-# MIT Licence. See http://opensource.org/licenses/MIT
-#
-# Created on 2014-08-16
-#
-
-"""Self-updating from GitHub.
-
-.. versionadded:: 1.9
-
-.. note::
-
- This module is not intended to be used directly. Automatic updates
- are controlled by the ``update_settings`` :class:`dict` passed to
- :class:`~workflow.workflow.Workflow` objects.
-
-"""
-
-from __future__ import print_function, unicode_literals
-
-import os
-import tempfile
-import re
-import subprocess
-
-import workflow
-import web
-
-# __all__ = []
-
-
-RELEASES_BASE = 'https://api.github.com/repos/{0}/releases'
-
-
-_wf = None
-
-
-def wf():
- """Lazy `Workflow` object."""
- global _wf
- if _wf is None:
- _wf = workflow.Workflow()
- return _wf
-
-
-class Version(object):
- """Mostly semantic versioning.
-
- The main difference to proper :ref:`semantic versioning `
- is that this implementation doesn't require a minor or patch version.
-
- Version strings may also be prefixed with "v", e.g.:
-
- >>> v = Version('v1.1.1')
- >>> v.tuple
- (1, 1, 1, '')
-
- >>> v = Version('2.0')
- >>> v.tuple
- (2, 0, 0, '')
-
- >>> Version('3.1-beta').tuple
- (3, 1, 0, 'beta')
-
- >>> Version('1.0.1') > Version('0.0.1')
- True
- """
-
- #: Match version and pre-release/build information in version strings
- match_version = re.compile(r'([0-9\.]+)(.+)?').match
-
- def __init__(self, vstr):
- """Create new `Version` object.
-
- Args:
- vstr (basestring): Semantic version string.
- """
- self.vstr = vstr
- self.major = 0
- self.minor = 0
- self.patch = 0
- self.suffix = ''
- self.build = ''
- self._parse(vstr)
-
- def _parse(self, vstr):
- if vstr.startswith('v'):
- m = self.match_version(vstr[1:])
- else:
- m = self.match_version(vstr)
- if not m:
- raise ValueError('invalid version number: {0}'.format(vstr))
-
- version, suffix = m.groups()
- parts = self._parse_dotted_string(version)
- self.major = parts.pop(0)
- if len(parts):
- self.minor = parts.pop(0)
- if len(parts):
- self.patch = parts.pop(0)
- if not len(parts) == 0:
- raise ValueError('invalid version (too long) : {0}'.format(vstr))
-
- if suffix:
- # Build info
- idx = suffix.find('+')
- if idx > -1:
- self.build = suffix[idx+1:]
- suffix = suffix[:idx]
- if suffix:
- if not suffix.startswith('-'):
- raise ValueError(
- 'suffix must start with - : {0}'.format(suffix))
- self.suffix = suffix[1:]
-
- # wf().logger.debug('version str `{}` -> {}'.format(vstr, repr(self)))
-
- def _parse_dotted_string(self, s):
- """Parse string ``s`` into list of ints and strings."""
- parsed = []
- parts = s.split('.')
- for p in parts:
- if p.isdigit():
- p = int(p)
- parsed.append(p)
- return parsed
-
- @property
- def tuple(self):
- """Version number as a tuple of major, minor, patch, pre-release."""
- return (self.major, self.minor, self.patch, self.suffix)
-
- def __lt__(self, other):
- """Implement comparison."""
- if not isinstance(other, Version):
- raise ValueError('not a Version instance: {0!r}'.format(other))
- t = self.tuple[:3]
- o = other.tuple[:3]
- if t < o:
- return True
- if t == o: # We need to compare suffixes
- if self.suffix and not other.suffix:
- return True
- if other.suffix and not self.suffix:
- return False
- return (self._parse_dotted_string(self.suffix) <
- self._parse_dotted_string(other.suffix))
- # t > o
- return False
-
- def __eq__(self, other):
- """Implement comparison."""
- if not isinstance(other, Version):
- raise ValueError('not a Version instance: {0!r}'.format(other))
- return self.tuple == other.tuple
-
- def __ne__(self, other):
- """Implement comparison."""
- return not self.__eq__(other)
-
- def __gt__(self, other):
- """Implement comparison."""
- if not isinstance(other, Version):
- raise ValueError('not a Version instance: {0!r}'.format(other))
- return other.__lt__(self)
-
- def __le__(self, other):
- """Implement comparison."""
- if not isinstance(other, Version):
- raise ValueError('not a Version instance: {0!r}'.format(other))
- return not other.__lt__(self)
-
- def __ge__(self, other):
- """Implement comparison."""
- return not self.__lt__(other)
-
- def __str__(self):
- """Return semantic version string."""
- vstr = '{0}.{1}.{2}'.format(self.major, self.minor, self.patch)
- if self.suffix:
- vstr = '{0}-{1}'.format(vstr, self.suffix)
- if self.build:
- vstr = '{0}+{1}'.format(vstr, self.build)
- return vstr
-
- def __repr__(self):
- """Return 'code' representation of `Version`."""
- return "Version('{0}')".format(str(self))
-
-
-def download_workflow(url):
- """Download workflow at ``url`` to a local temporary file.
-
- :param url: URL to .alfredworkflow file in GitHub repo
- :returns: path to downloaded file
-
- """
- filename = url.split('/')[-1]
-
- if (not filename.endswith('.alfredworkflow') and
- not filename.endswith('.alfred3workflow')):
- raise ValueError('attachment not a workflow: {0}'.format(filename))
-
- local_path = os.path.join(tempfile.gettempdir(), filename)
-
- wf().logger.debug(
- 'downloading updated workflow from `%s` to `%s` ...', url, local_path)
-
- response = web.get(url)
-
- with open(local_path, 'wb') as output:
- output.write(response.content)
-
- return local_path
-
-
-def build_api_url(slug):
- """Generate releases URL from GitHub slug.
-
- :param slug: Repo name in form ``username/repo``
- :returns: URL to the API endpoint for the repo's releases
-
- """
- if len(slug.split('/')) != 2:
- raise ValueError('invalid GitHub slug: {0}'.format(slug))
-
- return RELEASES_BASE.format(slug)
-
-
-def _validate_release(release):
- """Return release for running version of Alfred."""
- alf3 = wf().alfred_version.major == 3
-
- downloads = {'.alfredworkflow': [], '.alfred3workflow': []}
- dl_count = 0
- version = release['tag_name']
-
- for asset in release.get('assets', []):
- url = asset.get('browser_download_url')
- if not url: # pragma: nocover
- continue
-
- ext = os.path.splitext(url)[1].lower()
- if ext not in downloads:
- continue
-
- # Ignore Alfred 3-only files if Alfred 2 is running
- if ext == '.alfred3workflow' and not alf3:
- continue
-
- downloads[ext].append(url)
- dl_count += 1
-
- # download_urls.append(url)
-
- if dl_count == 0:
- wf().logger.warning(
- 'invalid release (no workflow file): %s', version)
- return None
-
- for k in downloads:
- if len(downloads[k]) > 1:
- wf().logger.warning(
- 'invalid release (multiple %s files): %s', k, version)
- return None
-
- # Prefer .alfred3workflow file if there is one and Alfred 3 is
- # running.
- if alf3 and len(downloads['.alfred3workflow']):
- download_url = downloads['.alfred3workflow'][0]
-
- else:
- download_url = downloads['.alfredworkflow'][0]
-
- wf().logger.debug('release %s: %s', version, download_url)
-
- return {
- 'version': version,
- 'download_url': download_url,
- 'prerelease': release['prerelease']
- }
-
-
-def get_valid_releases(github_slug, prereleases=False):
- """Return list of all valid releases.
-
- :param github_slug: ``username/repo`` for workflow's GitHub repo
- :param prereleases: Whether to include pre-releases.
- :returns: list of dicts. Each :class:`dict` has the form
- ``{'version': '1.1', 'download_url': 'http://github.com/...',
- 'prerelease': False }``
-
-
- A valid release is one that contains one ``.alfredworkflow`` file.
-
- If the GitHub version (i.e. tag) is of the form ``v1.1``, the leading
- ``v`` will be stripped.
-
- """
- api_url = build_api_url(github_slug)
- releases = []
-
- wf().logger.debug('retrieving releases list: %s', api_url)
-
- def retrieve_releases():
- wf().logger.info(
- 'retrieving releases: %s', github_slug)
- return web.get(api_url).json()
-
- slug = github_slug.replace('/', '-')
- for release in wf().cached_data('gh-releases-' + slug, retrieve_releases):
-
- release = _validate_release(release)
- if release is None:
- wf().logger.debug('invalid release: %r', release)
- continue
-
- elif release['prerelease'] and not prereleases:
- wf().logger.debug('ignoring prerelease: %s', release['version'])
- continue
-
- wf().logger.debug('release: %r', release)
-
- releases.append(release)
-
- return releases
-
-
-def check_update(github_slug, current_version, prereleases=False):
- """Check whether a newer release is available on GitHub.
-
- :param github_slug: ``username/repo`` for workflow's GitHub repo
- :param current_version: the currently installed version of the
- workflow. :ref:`Semantic versioning ` is required.
- :param prereleases: Whether to include pre-releases.
- :type current_version: ``unicode``
- :returns: ``True`` if an update is available, else ``False``
-
- If an update is available, its version number and download URL will
- be cached.
-
- """
- releases = get_valid_releases(github_slug, prereleases)
-
- if not len(releases):
- raise ValueError('no valid releases for %s', github_slug)
-
- wf().logger.info('%d releases for %s', len(releases), github_slug)
-
- # GitHub returns releases newest-first
- latest_release = releases[0]
-
- # (latest_version, download_url) = get_latest_release(releases)
- vr = Version(latest_release['version'])
- vl = Version(current_version)
- wf().logger.debug('latest=%r, installed=%r', vr, vl)
- if vr > vl:
-
- wf().cache_data('__workflow_update_status', {
- 'version': latest_release['version'],
- 'download_url': latest_release['download_url'],
- 'available': True
- })
-
- return True
-
- wf().cache_data('__workflow_update_status', {'available': False})
- return False
-
-
-def install_update():
- """If a newer release is available, download and install it.
-
- :returns: ``True`` if an update is installed, else ``False``
-
- """
- update_data = wf().cached_data('__workflow_update_status', max_age=0)
-
- if not update_data or not update_data.get('available'):
- wf().logger.info('no update available')
- return False
-
- local_file = download_workflow(update_data['download_url'])
-
- wf().logger.info('installing updated workflow ...')
- subprocess.call(['open', local_file])
-
- update_data['available'] = False
- wf().cache_data('__workflow_update_status', update_data)
- return True
-
-
-if __name__ == '__main__': # pragma: nocover
- import sys
-
- def show_help(status=0):
- """Print help message."""
- print('Usage : update.py (check|install) '
- '[--prereleases] ')
- sys.exit(status)
-
- argv = sys.argv[:]
- if '-h' in argv or '--help' in argv:
- show_help()
-
- prereleases = '--prereleases' in argv
-
- if prereleases:
- argv.remove('--prereleases')
-
- if len(argv) != 4:
- show_help(1)
-
- action, github_slug, version = argv[1:]
-
- if action == 'check':
- check_update(github_slug, version, prereleases)
- elif action == 'install':
- install_update()
- else:
- show_help(1)
diff --git a/workflow/version b/workflow/version
deleted file mode 100644
index 476d2ce..0000000
--- a/workflow/version
+++ /dev/null
@@ -1 +0,0 @@
-1.29
\ No newline at end of file
diff --git a/workflow/workflow.pyc b/workflow/workflow.pyc
deleted file mode 100644
index 2427cf5..0000000
Binary files a/workflow/workflow.pyc and /dev/null differ