[TOC]
-
버킷 (Bucket)
-
기수 (Radix)
-
선택 (Selection)
-
교환 ( Exchange ) , 버블 (Bubble)
-
삽입 (Insert)
-
셀 (Shell)
-
병합 (Merge) - Divide and Conquer
-
퀵 (Quick) - 중앙값 ,Divide and Conquer, **C언어 STL(표준라이브러리)**로 제공하는 정렬
-
힙 (Heap)
https://www.growingwiththeweb.com/2015/06/bucket-sort.html
- auxiliary memory : 보조기억장치
-
자료를 버킷이라는 단위 기억장소에 정렬하고 버킷별 키 값에 따라 다시 정렬하는 알고리즘
-
데이터가 특정 범위 내에 확률적으로 균등하게 분포한다고 가정할 수 있을 때 적용.
(그림출처 : http://egloos.zum.com/Duckkk/v/668549 )
https://ratsgo.github.io/data%20structure&algorithm/2017/10/18/bucketsort/
두번째 그림과 같이 10개의 데이터 A가 주어졌을 때 같은 크기의 버킷 B를 만듭니다. 만약 A의 분포가 균등하다면 각 버킷에는 1
2개의 요소만 속해 있을 것입니다. 이렇게 12개 값들만 있는 버킷 하나를 정렬하는 데 필요한 계산복잡성은 O(1)이 될 것이고, 이 작업을 n개 버킷에 모두 수행한다고 하면 전체적인 계산복잡성은 O(n)이 될 것입니다. 이것이 바로 버킷 정렬이 노리는 바입니다.


-
데이터 nn개가 주어졌을 때 데이터의 범위를 n개로 나누고 이에 해당하는 n개의 버킷을 만든다.
-
각각의 데이터를 해당하는 버킷에 집어 넣는다. (C 등에서는 연결리스트를 사용하며 새로운 데이터는 연결리스트의 head에 insert한다)
-
버킷별로 정렬한다.
-
이를 전체적으로 합친다.
- 버킷 정렬의 한계? 모양에 따른 제한. 즉, 데이터가 1, 1000이면 1000개의 데이터 공간이 필요한 문제. 이를 개선한 것이 기수정렬
- 각 자릿수별로 버킷 정렬을 반복 수행하는 방법
-
정렬할 데이터 확보
-
각자릿수는 0-9값을 가짐
-
데이터 1의 자릿수를 기준으로 버킷정렬
-
데이터 2의 자릿수를 기준으로 버킷정렬
-
데이터 3의 자릿수를 기준으로 버킷정렬
-
Queue(FIFO) 를 이용해 pop하면 최종적으로 정렬된 결과를 얻을 수 있다!
-
가장 작은 데이터를 찾아(선택) 가장 앞에 있는 데이터화 교환하는 알고리즘
-
자료 이동 횟수가 미리 결정된다. (장)
-
안정성 만족하지 않는다. - > 같은 레코드가 있는 경우 상대적인 위치가 변경될 수 있다(단)
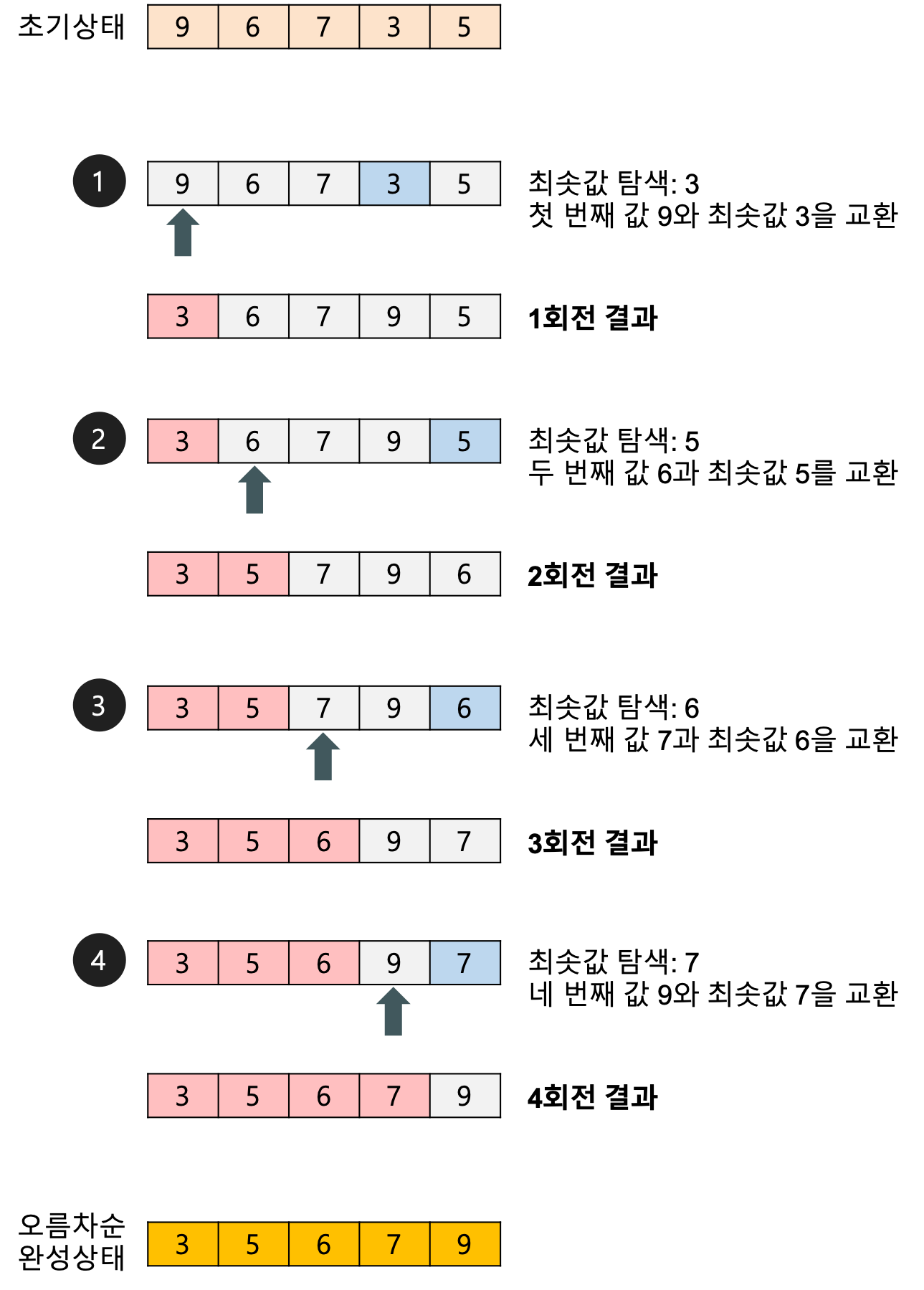
https://gmlwjd9405.github.io/2018/05/06/algorithm-selection-sort.html
-
비교횟수
- 외부루프 (n-1)
- 내부루프 : n-1, n-2 .. 1번
-
교환 횟수
- 외부 루프의 실행횟수와 동일 즉, 상수시간 작업
- 한 번 교환하기 위해 3번의 이동 (swarp) : 3(n-1)번
-
T(n) = (n-1) + (n-2) + ... + 2 + 1 = n(n-1)/2 = O(n^2)
- 첫번째 요소와 다른 요소들을 비교하고 교환하는 방식으로 진행
- 책에서는 bubble과 혼란이 오니 책 내용은 보지 말 것.
http://blog.naver.com/PostView.nhn?blogId=ryutuna&logNo=100123462798
How is the exchange sort different from the bubble sort?
-
요소들을 비교하는 방법에 차이가 있음
-
교환정렬은 첫번째 요소와 다른 요소들을 비교하고 교환하는 방식으로 진행
-
버블정렬은 인접한 요소들끼리만 비교하며 교환 -> 모든 정렬이 끝난 후에도 반드시 final pass가 한번 더 돌아서 정렬됐는지 체크해야한다.
-
교환정렬 : 첫번째 요소에 대한 sort가 끝나면 두번째 요소에 대해 비교시작하고, 모든 배열이 올바르게 정렬되면 끝난다
Exchange sort (https://www.youtube.com/watch?v=KKdKhSd2MPE)


Bubble
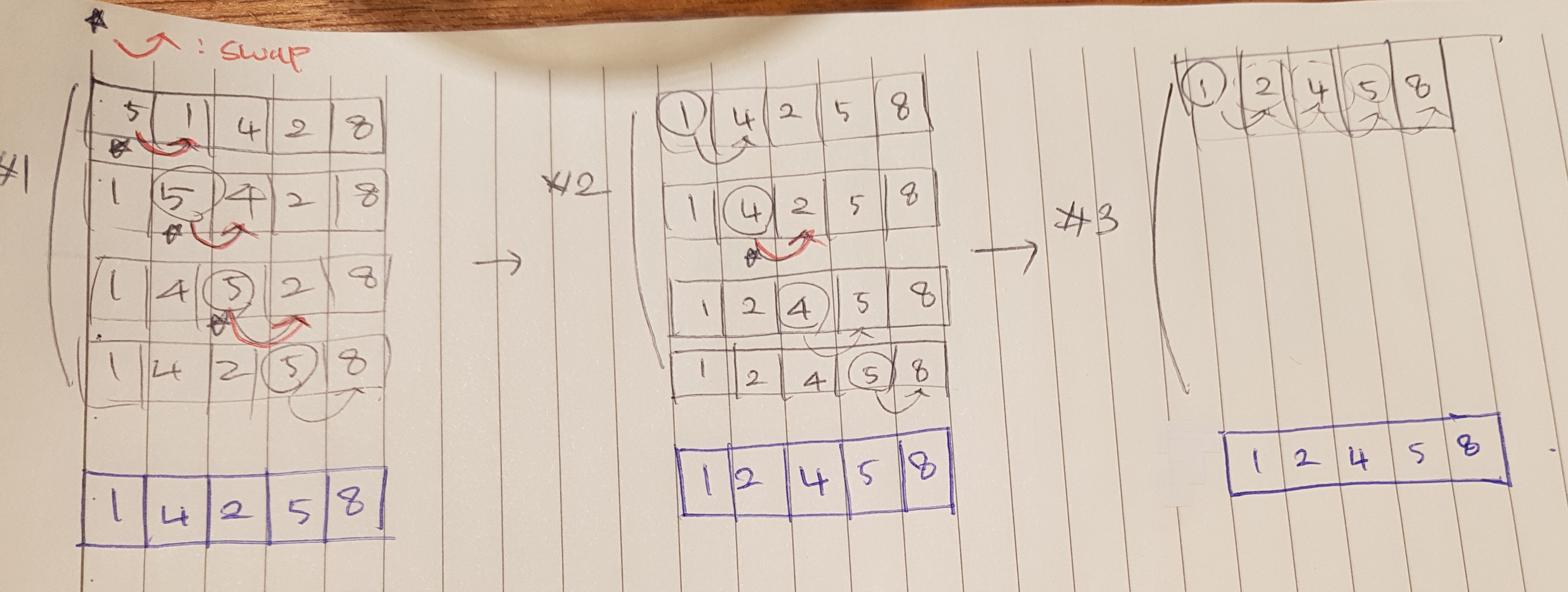
- 구현이 간단하기 때문에 사용한다
-
모든 대상항목을 비교하므로 정렬 알고리즘 중에서 가장 많은 시간이 소요 (버블/교환 마찬가지)
-
n(n-1)/2
-
O(n^2)
- 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성
- 이미 정렬된 자료구조에 자료를 하나씩 삽입/제거하는 경우에 현실적으로 최고의 정렬 알고리즘
- 탐색을 제외한 오버헤드가 매우 적기때문이다.
- 선택정렬이나 거품정렬과 같은 O(n^2) 알고리즘에 비교하여 빠르다.
- 내부 반복문이 생각보다 빠르기때문에 데이터 수가 8~20개 근처일 때 가장 빠른 정렬 알고리즘이다.
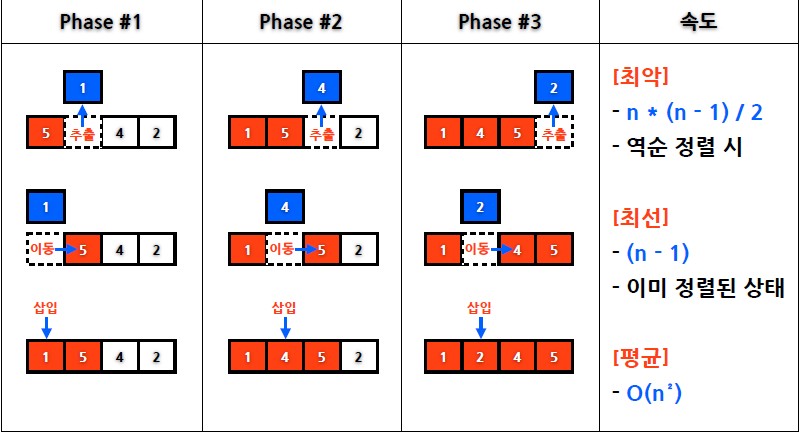
-
어느 정도 정렬된 배열에 대해서는 대단히 빠르지만 데이터가 많은 경우 삽입 한 번에 많은 이동이 발생.
ex) 11 33 44 55 . . . . . 22 99 에서 22가 11과 33사이에 들어갈 때, 엄청나게 많은 이동이 발생!
void insertion_sort(int list[], int n){
int i, j, key;
// 인텍스 0은 이미 정렬된 것으로 볼 수 있다.
for(i=1; i<n; i++){
key = list[i]; // 현재 삽입될 숫자인 i번째 정수를 key 변수로 복사
// 현재 정렬된 배열은 i-1까지이므로 i-1번째부터 역순으로 조사한다.
// j 값은 음수가 아니어야 되고
// key 값보다 정렬된 배열에 있는 값이 크면 j번째를 j+1번째로 이동
for(j=i-1; j>=0 && list[j]>key; j--){
list[j+1] = list[j]; // 레코드의 오른쪽으로 이동
}
list[j+1] = key;
}
}
// https://gmlwjd9405.github.io/2018/05/06/algorithm-insertion-sort.html-
Best
-
비교횟수 : 이동없이 1번의 비교만 이루어진다
-
외부루프 : (n-1)번
-
-
Worst (입력자료가 역순)
-
비교횟수 : 외부 루프 안의 각 반복마다 i번의 비교 수행
- 외부루프 : (n-1) + (n-2) + .... + 2 + 1 = n(n-1)/2 = O(n^2)
-
교환횟수(if) : 외부 루프의 각 단계마다 (i+2)번의 이동 발생
- n(n-1)/2 + 2(n-1) = (n^2 + 3n - 4) / 2 = O(n^2)
-
https://gmlwjd9405.github.io/2018/05/08/algorithm-shell-sort.html
- 삽입 정렬의 느린 속도 보완 (데이터가 많을 때 )
- 데이터의 그룹을 나누어 그룹 안에서 쉘 정렬을 수행하고 마지막에 삽입정렬을 수행
- 연속적이지 않은 부분 리스트에서 자료의 교환이 일어나면 한번에 더 큰 거리를 이동한다. 따라서 교환되는 요소들이 삽입정렬보다는 최종 위치에 있을 가능성이 높아진다.
- 부분 리스트는 어느 정도 정렬이 된 상태이기 때문에 부분 리스트의 개수가 1이 되게 되면 기본적으로 삽입정렬을 수행하지만, 삽입 정렬보다 빠르게 수행된다.
- 알고리즘 간단해서 쉽게 구현
-
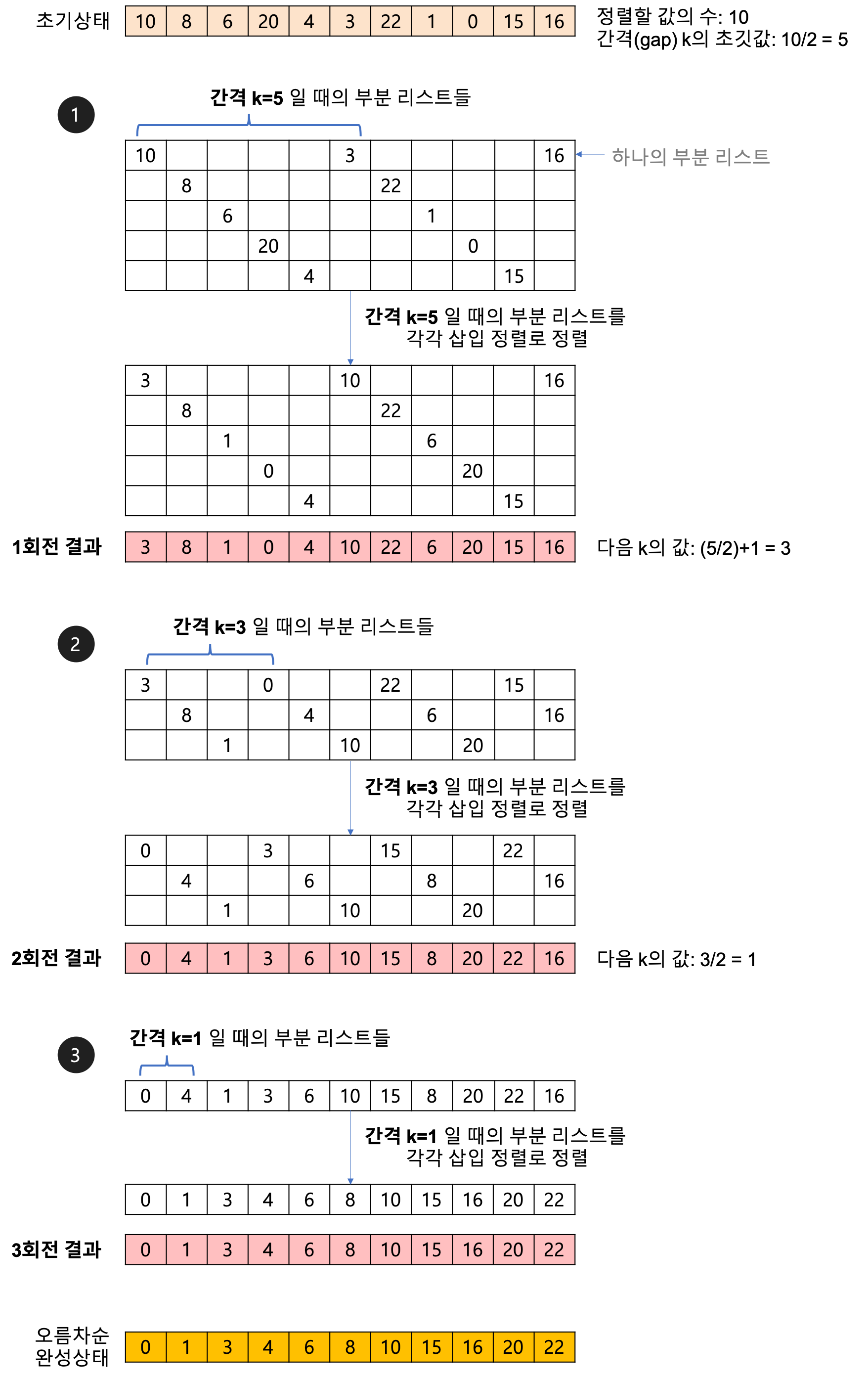
정렬해야 할 리스트의 각 k번째 요소를 추출해서 부분리스트를 만든다. 이때, k를 '간격(gap)'이라고 한다.
- 간격의 초깃값 :( 정렬할 값의 수 ) / 2
- 생성된 부분 리스트의 개수는 gap과 같다.
-
[예제] 10 8 6 20 4 3 22 1 0 15 16
-
1회전 : 처음 간격(gap)을 k = 10/2 = 5로 하고, 다섯 번째 요소를 추출해서 부분 리스트를 만든다.
만들어진 5개의 부분 리스트를 '삽입' 정렬로 정렬한다.
-
2회전 : 다음 간격은 k = (5/2:짝수)+1 = 3 으로 하고, 1회전 정렬한 리스트에서 세 번째 요소를 추출해서 부분리스트를 만든다. 만들어진 3개의 부분 리스트를 삽입 정렬로 정렬한다.
-
3회전 : 다음 간격은 k = 3/2 = 1 로 하고 간격 k가 1이므로 마지막으로 정렬을 수행한다. 만들어진 1개의 부분 리스트를 삽입 정렬로 정렬한다.
-
https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html
- 최소 단위 (1개) 까지 쪼갠 후 합치면서 정렬.
- 안정 정렬, 분할 정복 알고리즘 (devide and conquer)
- 분할 정복 알고리즘? (Devide and Conquer)
- 문제를 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제 해결
- 분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
- 분할 정복 알고리즘? (Devide and Conquer)
-
단계
-
분할(Divide) : 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
-
정복(Conquer) : 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
-
결합(Combine) : 정렬된 부분 배열들을 하나의 배열에 합병
- [merge] 과정
-
2개의 리스트의 값들을 처음부터 하나씩 비교하여 두 개의 리스트의 값 중에서 더 작은 값을 새로운 리스트로 옮긴다.
-
둘 중에서 하나가 끝날 때까지 이 과정을 되풀이한다.
-
만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 나머지 리스트의 값들을 전부 새로운 리스트(sorted)로 복사한다.
-
새로운 리스트(sorted)를 원래의 리스트로 옮긴다.
-
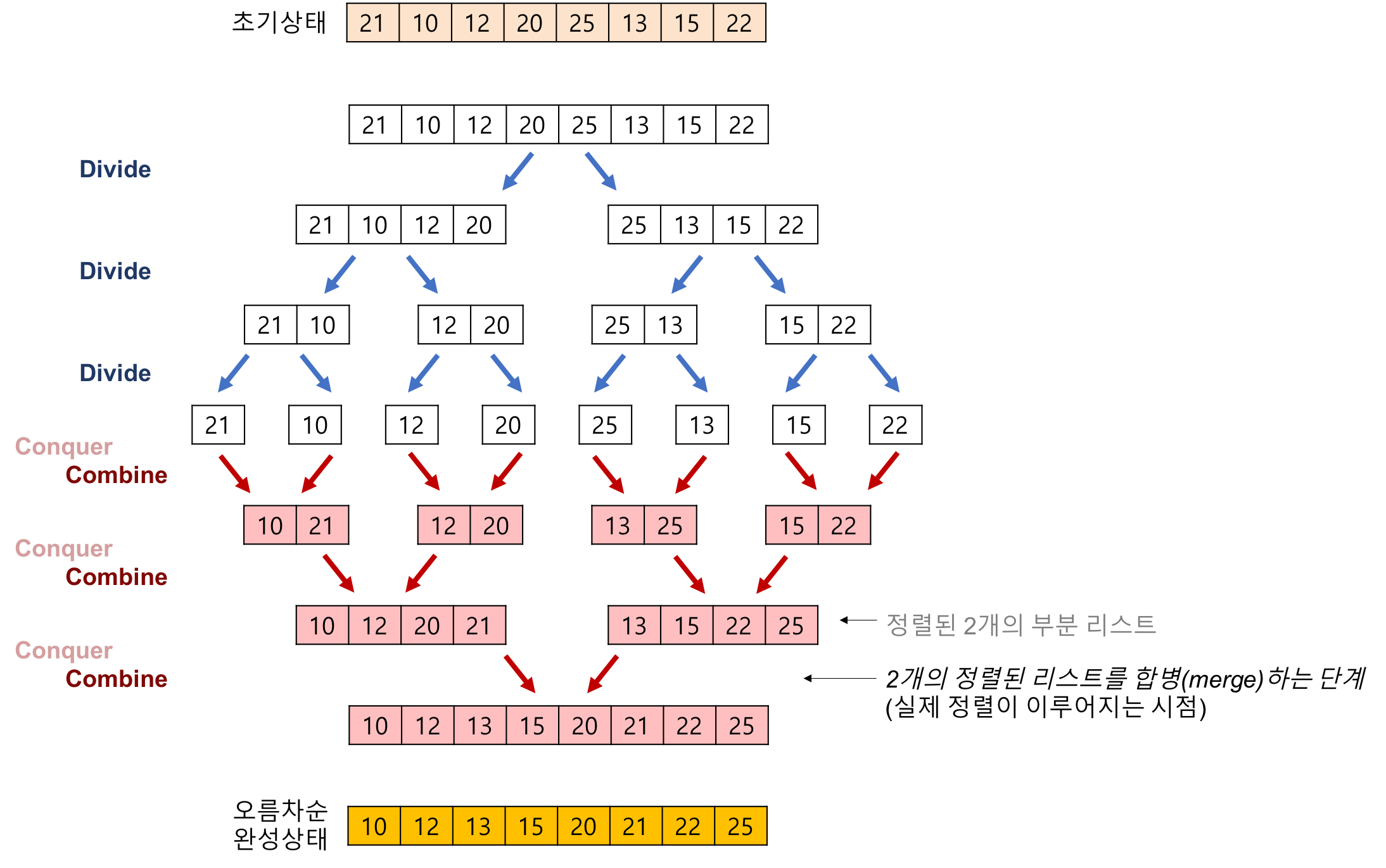
[ Example ]
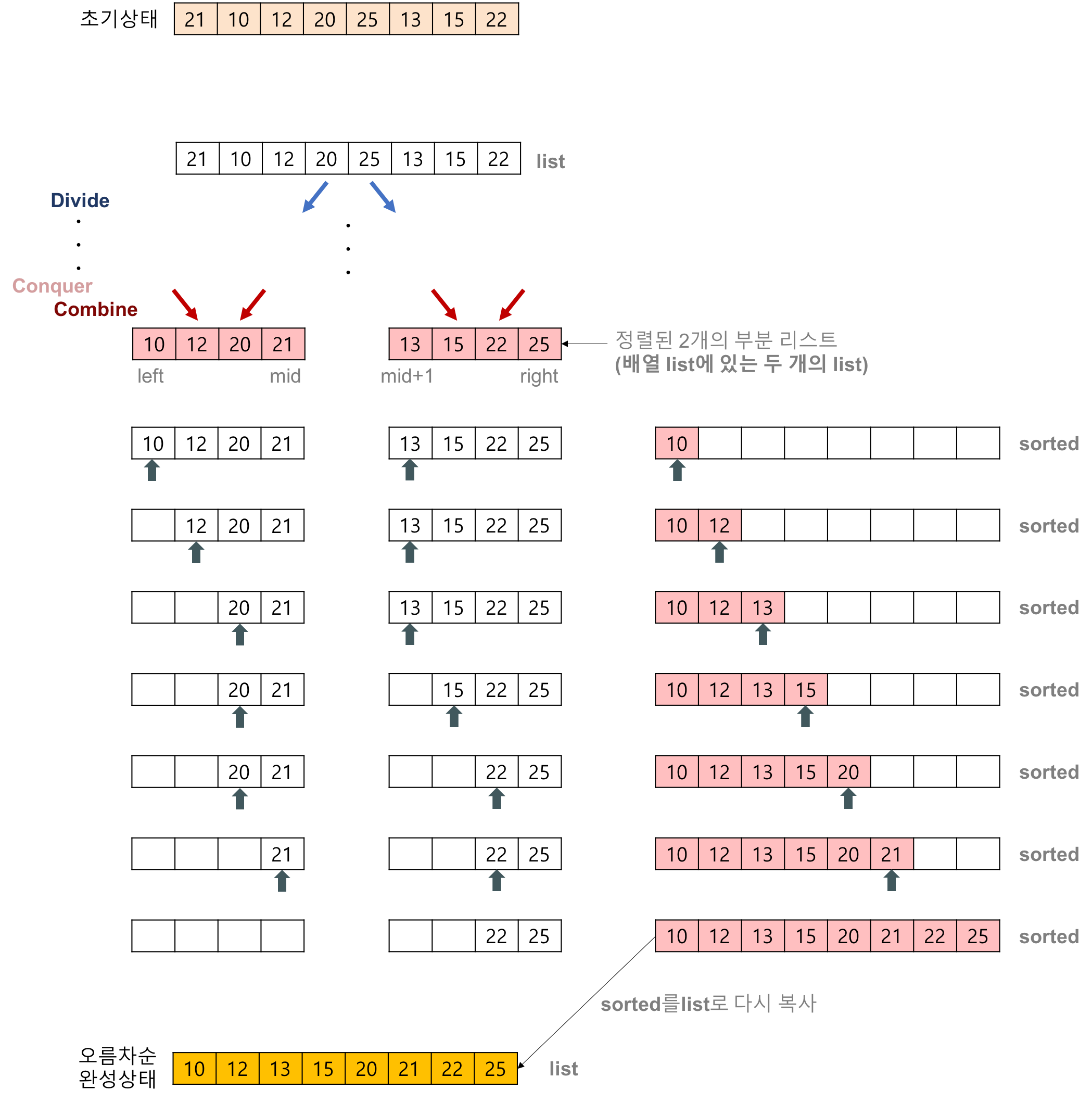
-
단점
-
레코드를 **배열(Array)**로 구성하면 임시 배열이 필요하다. -> **제자리 정렬(in-place sorging)**이 아니다.
-
레코드들의 크기가 큰 경우에는 이동 횟수가 많으므로 매우 큰 시간적 낭비
-
-
장점
-
안정적인 정렬방법
-
데이터 분포에 영향을 덜 받는다. -> 입력 데이터가 무엇이든 간에 정렬되는 시간 동일(O(nlog₂n))
-
만약 레코드를 **연결리스트(Linked List)**로 구성하면, 링크 인덱스만 변경되므로 데이터의 이동은 무시할 수 있을 정도로 작아진다 -> **제자리 정렬(in-place sorging)**이 아니다.
-
크기가 큰 레코드를 정렬할 경우 연결 리스트를 사용한다면, 합병정렬은 퀵정렬을 포함한 다른 어떤 정렬 방법보다 효율적이다.
-
-
- Java나 python의 sort.. 대부분 언어의 내장 sort함수는 퀵정렬이다!
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
- 중앙값 정렬 방식을 확장해서 개발한 방식
- 불안정 정렬, 비교 정렬 - 다른 원소와의 비교만으로 정렬을 수행
- 분할 정복 알고리즘, 평균적으로 매우 빠른 수행 속도
- merge sort와 달리 퀵정렬은 리스트를 비균등하게 분할한다.
- 분할 : 입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열 ( 보다 작은 애들 <- (pivot) -> 보다 큰 애들)로 분할한다.
- 정복 : 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용, 반복
- 결합 : 합병.
- 순환 호출이 한 번 진행될 때마다 최소한 하나의 원소(피벗)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
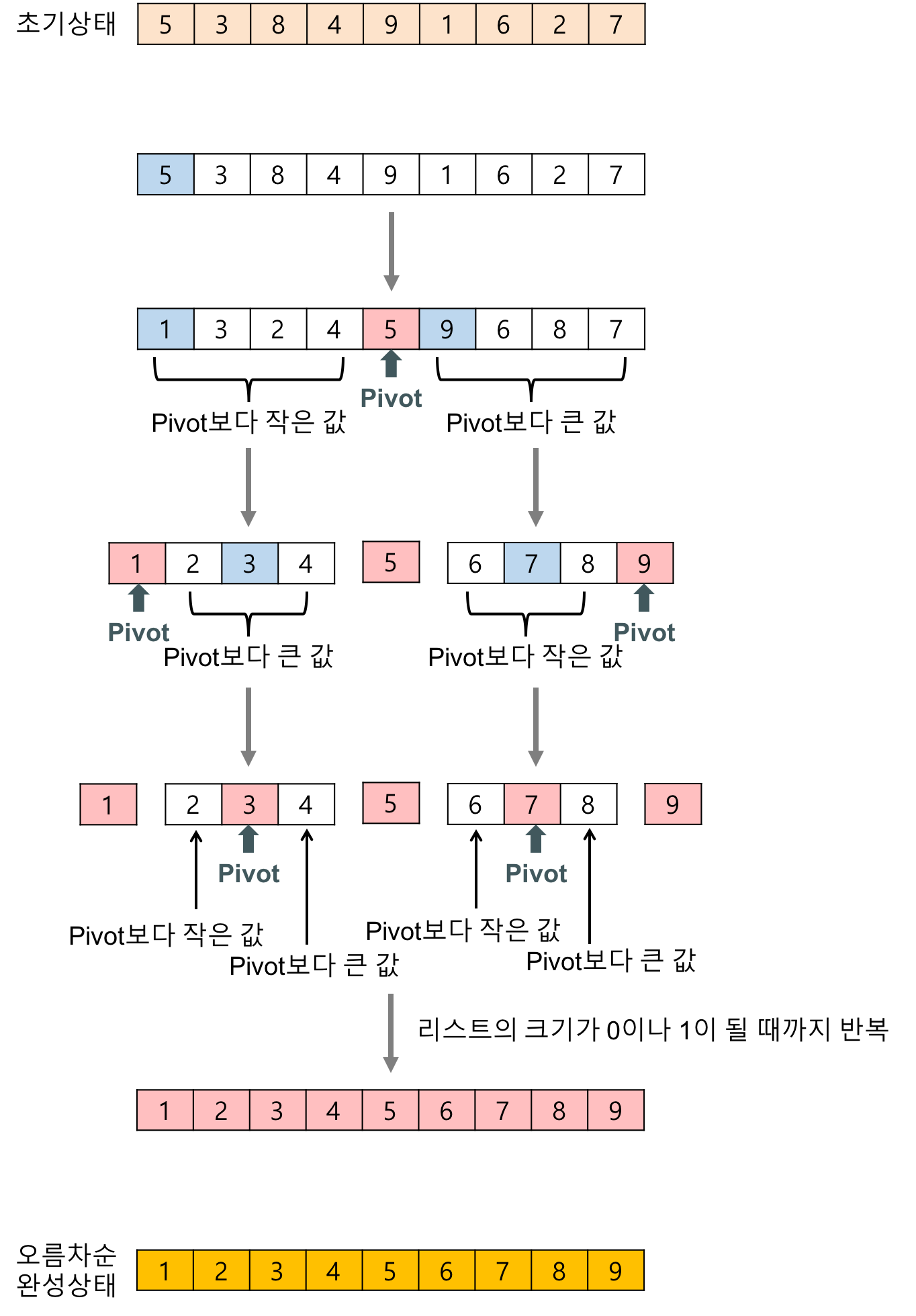
[ Example ]
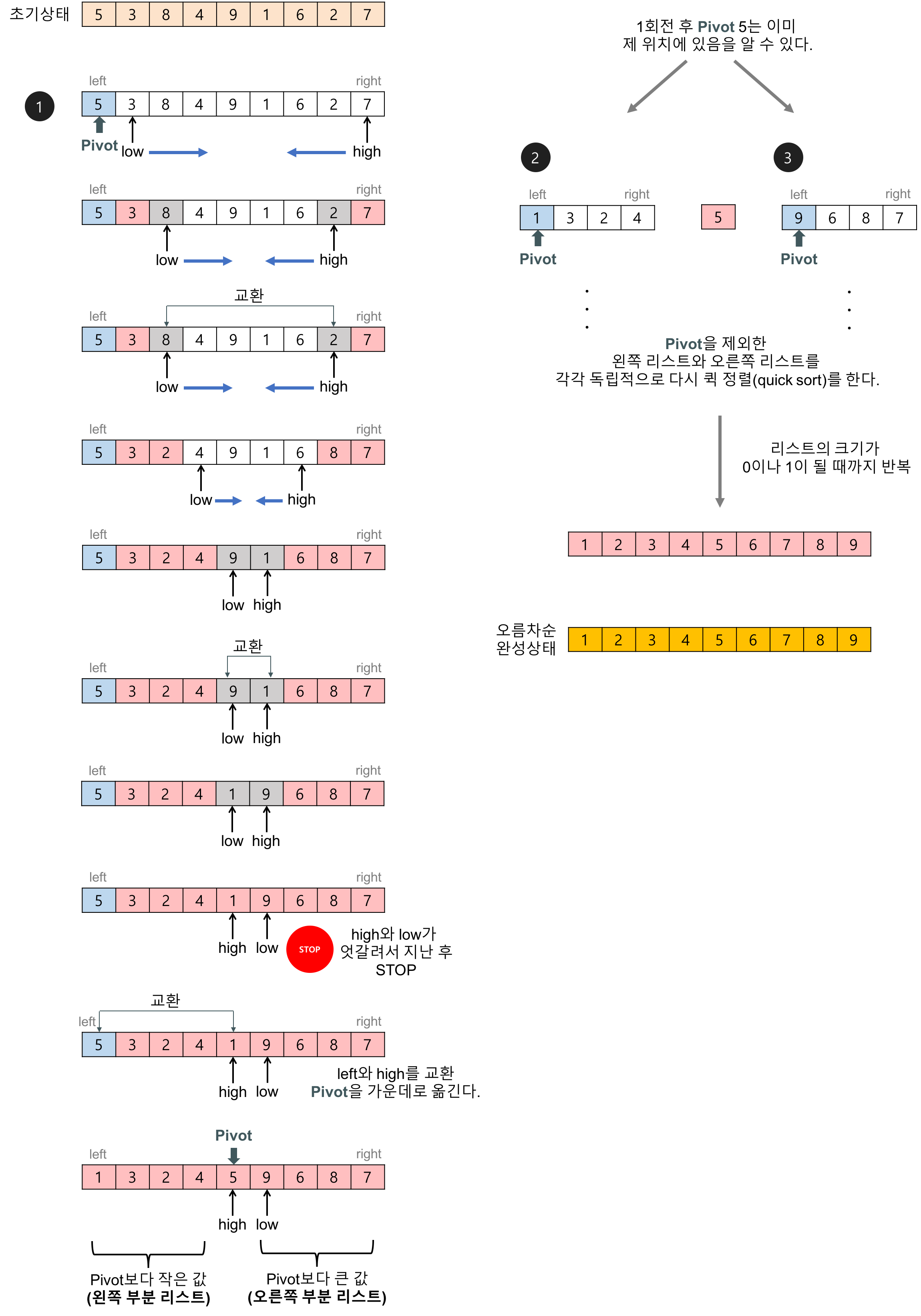
-
장점
- 속도가 빠르다. 시간 복잡도가 O( nlog₂n )를 가지는 다른 알고리즘과 비교했을 때도 가장 빠르다.
- 추가 메모리 공간이 필요하지 않다. O( log n ) 만큼의 메모리를 필요로 한다.
-
단점
-
정렬된 리스트에 대해서는 불리 - 퀵정렬의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
-> 퀵 정렬의 불균형 분할을 방지하기 위하여 피벗을 선택할 때 더욱 리스트를 균등하게 분할할 수 있는 데이터를 선택한다. ex) 리스트 내의 몇 개의 데이터 중에서 크기 순으로 중간값을 피벗으로 선택한다.
-> 궁금증?
정렬된 리스트가 더 유리할거 같은데... 중간값을 갖는 피벗을 어떻게 잘 선택하지??
-
-
퀵 정렬의 실행 시간은 O(NlgN)에서 최대 O(N^2) 까지 걸릴 수 있다.
-
Worst-case에서 가장 첫번째 원소나 가장 마지막 원소로 지정하는 것.
[WorstCase]
- 이미 정렬되어 있는 배열 (또는 거의 정렬된 배열)
- 반대로 정렬되어 있는 배열
-
각 단계마다 '원소 1개' 와 '나머지 원소 전부' 로 쪼개진다 (devide and conquer 이점 없음)
-
-
소개된 선택법 2가지
-
random
-
median of three
-
random index 3개를 뽑는다.
-
이 3개가 가리키는 원소들의 median값으로 pivot을 설정한다.
-
-
https://smartstore.naver.com/sechorom/category/1168f31e593047528eba10ef11b4c624?cp=1
-
최대힙트리(내림차순) 또는 최소힙트리(오름차순)를 구성해 정렬
-
완전 이진 트리로 최대힙/최소힙을 만든 후 한 번에 하나씩 꺼내서 배열의 뒤에서부터 저장
- 장점
- 시간 복잡도가 좋은 편
- 전체 자료를 정렬하는 것이 아니라 가장 큰 값 몇개만 필요할 때 유용하다.


- 단순(구현 간단)하지만 비효율적인 방법: 삽입 / 선택 / 버블
- 복잡하지만 효율적인 방법 : 퀵 / 힙 / 합병 / 기수