diff --git a/source/_posts/DPA4_05_22_2026.md b/source/_posts/DPA4_05_22_2026.md
new file mode 100644
index 0000000..f84008a
--- /dev/null
+++ b/source/_posts/DPA4_05_22_2026.md
@@ -0,0 +1,84 @@
+---
+title: "DPA4 Tops Matbench Discovery: A Single RTX 5090 Delivers SOTA-Level Large Atomic Models in One Day"
+date: 2026-05-22
+categories:
+- DPA
+---
+
+Recently, the OpenLAM Team of the Beijing Academy of Artificial Intelligence for Science, Peking University, DeepModeling Technology, and the Institute of Applied Physics and Computational Mathematics have jointly launched DPA4, a new-generation model architecture tailored for the era of Large Atomic Models (LAMs). DPA4 claimed the top spot worldwide with its comprehensive performance score (CPS) on Matbench Discovery, an authoritative global benchmark for materials discovery, emerging as the latest State-of-the-Art (SOTA) model.
+
+What makes DPA4 particularly remarkable is that it achieved this milestone not by expanding model parameters or relying on massive computing power. The previous leading model eSEN required over 300 GPU days for training, while DPA4 can theoretically reach the same accuracy with just a single consumer-grade RTX 5090 running for approximately one day. Meanwhile, its parameter count is less than one-tenth of that of eSEN.
+
+In short, the SOTA-level accuracy that once demanded exorbitant supercomputing budgets can now be achieved using a single consumer graphics card. DPA4 is redefining the Pareto frontier between accuracy and efficiency for large atomic models.
+
+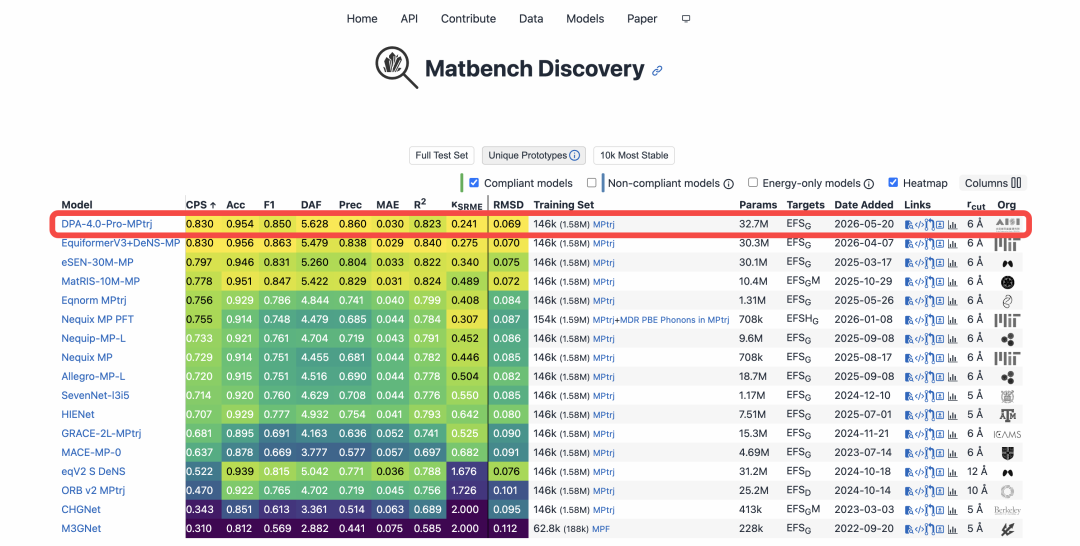 +
+*Official Screenshot of Matbench Discovery (Data as of May 22, 2026)*
+
+
+
+Adopting SO(2) equivariant linear operators combined with attention mechanisms under local coordinate systems, DPA4 strictly complies with translation, rotation, permutation symmetries and energy conservation while drastically cutting the overhead of equivariant computations. It has also pioneered compile-enabled training for machine learning potential functions globally, boosting training speed by 2 to 3 times. DPA4 secured new SOTA results and ranked first worldwide on both Matbench Discovery, the leading benchmark for materials discovery, and SPICE-MACE-OFF, a benchmark for small molecules. It sets a brand-new Pareto frontier in terms of prediction accuracy and training costs: a single RTX 5090 can finish training in around one day to match the accuracy achieved by eSEN after more than 300 GPU days. Its parameter volume is less than one-tenth of eSEN’s, and under equivalent accuracy, its training efficiency is roughly 10 times higher than that of its predecessor DPA3.
+
+
+
+*Official Screenshot of Matbench Discovery (Data as of May 22, 2026)*
+
+
+
+Adopting SO(2) equivariant linear operators combined with attention mechanisms under local coordinate systems, DPA4 strictly complies with translation, rotation, permutation symmetries and energy conservation while drastically cutting the overhead of equivariant computations. It has also pioneered compile-enabled training for machine learning potential functions globally, boosting training speed by 2 to 3 times. DPA4 secured new SOTA results and ranked first worldwide on both Matbench Discovery, the leading benchmark for materials discovery, and SPICE-MACE-OFF, a benchmark for small molecules. It sets a brand-new Pareto frontier in terms of prediction accuracy and training costs: a single RTX 5090 can finish training in around one day to match the accuracy achieved by eSEN after more than 300 GPU days. Its parameter volume is less than one-tenth of eSEN’s, and under equivalent accuracy, its training efficiency is roughly 10 times higher than that of its predecessor DPA3.
+
+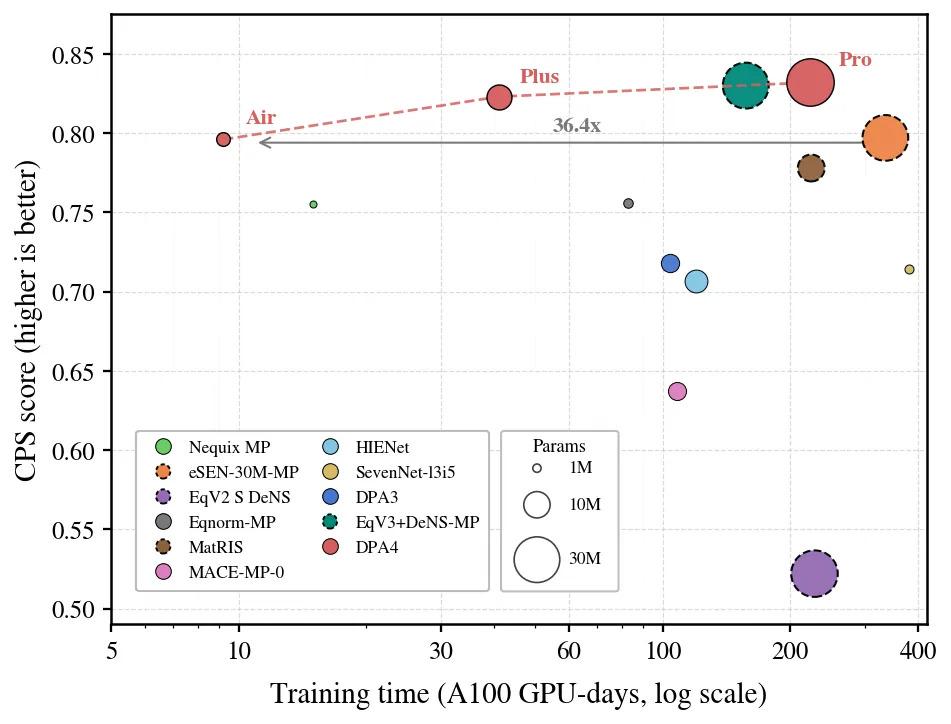 +
+*DPA4 Redefining the Accuracy-Efficiency Pareto Frontier for Large Atomic Models (Including Other Direct Force Pre-trained Models)*
+
+Currently, DPA4 is available for early access within the DeepModeling community. Its research paper and official full version will be open-sourced in due course. Researchers are welcome to stay tuned and join the WeChat group at the end of this article for exchanges. Below is a detailed introduction to DPA4.
+
+## 1. DPA4 Model Architecture: SO(2) Equivalent Design Under Local Coordinate Systems
+
+For a long time, to maintain rotational symmetry in global coordinate systems, equivariant models had to adopt Clebsch–Gordan tensor products to couple geometric features of different orders. The computational complexity surges sharply with the increase of angular momentum order, which is the fundamental reason why high-precision equivariant models incur enormous computational costs.
+
+The core design philosophy of DPA4 is to reduce symmetry processing to simpler subgroups instead of performing costly tensor product operations in global coordinate systems. Specifically, DPA4 constructs a smooth local coordinate system for each interatomic bond and aligns the direction of the bond to a unified reference axis. In such local coordinate systems, the rotational equivariance that originally needed to be processed across the entire SO(3) group is simplified to processing on the SO(2) subgroup for axial rotation. As an abelian group, SO(2) enables equivariant linear mappings with an extremely concise block structure. Consequently, the computationally expensive SO(3) tensor products are replaced with highly efficient SO(2) equivariant linear operators. While fully preserving complete rotational equivariance, this design drastically reduces the computational overhead for angular calculations.
+
+On this basis, DPA4 further incorporates attention mechanisms to aggregate information from neighboring atoms. The model can adaptively focus on the most critical atomic interactions for the central atom according to local geometric and chemical environments, thus delivering strong expressive power with a compact parameter scale. The entire model strictly adheres to translation, rotation, permutation symmetries and energy conservation, ensuring full physical consistency.
+
+Beyond algorithmic innovations, DPA4 is also optimized for efficiency in engineering implementation:
+1. Native torch.compile Support: The model is designed to be compiler-friendly from the ground up. It can leverage torch.compile for end-to-end acceleration without additional code modifications.
+2. Native ZBL Short-range Potential: DPA4 natively integrates the ZBL repulsive potential, which smoothly describes physical behaviors at short interatomic distances and enhances the model’s robustness under extreme configurations such as high pressure, irradiation and material defects.
+
+
+
+*DPA4 Redefining the Accuracy-Efficiency Pareto Frontier for Large Atomic Models (Including Other Direct Force Pre-trained Models)*
+
+Currently, DPA4 is available for early access within the DeepModeling community. Its research paper and official full version will be open-sourced in due course. Researchers are welcome to stay tuned and join the WeChat group at the end of this article for exchanges. Below is a detailed introduction to DPA4.
+
+## 1. DPA4 Model Architecture: SO(2) Equivalent Design Under Local Coordinate Systems
+
+For a long time, to maintain rotational symmetry in global coordinate systems, equivariant models had to adopt Clebsch–Gordan tensor products to couple geometric features of different orders. The computational complexity surges sharply with the increase of angular momentum order, which is the fundamental reason why high-precision equivariant models incur enormous computational costs.
+
+The core design philosophy of DPA4 is to reduce symmetry processing to simpler subgroups instead of performing costly tensor product operations in global coordinate systems. Specifically, DPA4 constructs a smooth local coordinate system for each interatomic bond and aligns the direction of the bond to a unified reference axis. In such local coordinate systems, the rotational equivariance that originally needed to be processed across the entire SO(3) group is simplified to processing on the SO(2) subgroup for axial rotation. As an abelian group, SO(2) enables equivariant linear mappings with an extremely concise block structure. Consequently, the computationally expensive SO(3) tensor products are replaced with highly efficient SO(2) equivariant linear operators. While fully preserving complete rotational equivariance, this design drastically reduces the computational overhead for angular calculations.
+
+On this basis, DPA4 further incorporates attention mechanisms to aggregate information from neighboring atoms. The model can adaptively focus on the most critical atomic interactions for the central atom according to local geometric and chemical environments, thus delivering strong expressive power with a compact parameter scale. The entire model strictly adheres to translation, rotation, permutation symmetries and energy conservation, ensuring full physical consistency.
+
+Beyond algorithmic innovations, DPA4 is also optimized for efficiency in engineering implementation:
+1. Native torch.compile Support: The model is designed to be compiler-friendly from the ground up. It can leverage torch.compile for end-to-end acceleration without additional code modifications.
+2. Native ZBL Short-range Potential: DPA4 natively integrates the ZBL repulsive potential, which smoothly describes physical behaviors at short interatomic distances and enhances the model’s robustness under extreme configurations such as high pressure, irradiation and material defects.
+
+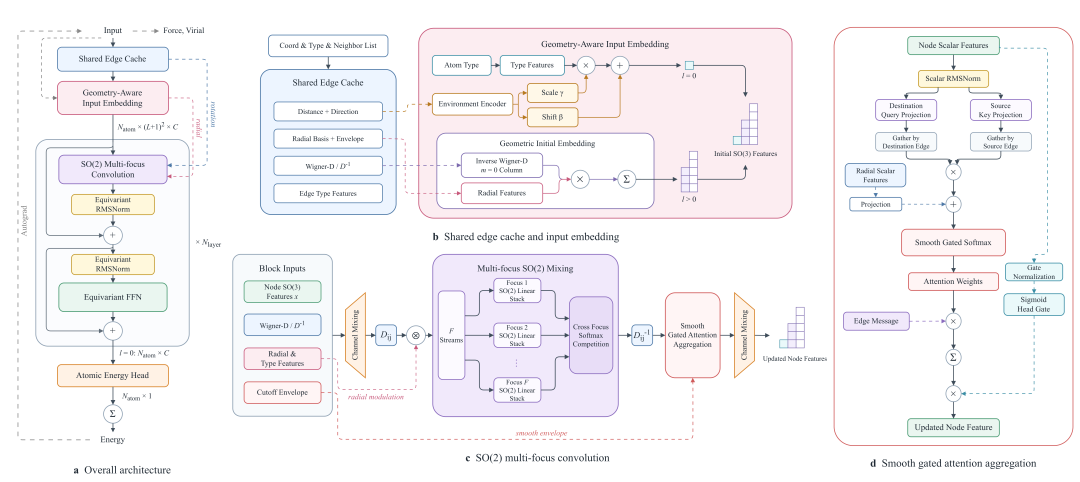 +
+*DPA4 Model Structure Diagram*
+
+## 2. Benchmark Performance: Double Championship on Matbench Discovery and SPICE-MACE-OFF
+
+Materials Discovery: World’s No.1 on Matbench Discovery. Initiated by top-tier institutions including the University of California, Berkeley and the University of Cambridge, Matbench Discovery is the most influential dynamic benchmark for AI-driven inorganic materials discovery worldwide and is widely recognized as the global gold standard for evaluating intelligent models in materials science. Different from simple static data fitting, it adopts a forward-looking testing mechanism that requires models to predict the thermodynamic stability of hundreds of thousands of unknown crystals, truly replicating the whole process of scientific research and exploration. Its evaluation system takes multiple metrics into account, including prediction accuracy of energy and force, F1 score and discovery acceleration factor, which are finally integrated into the comprehensive performance score CPS. Competing against state-of-the-art models from Meta, Microsoft and world-leading universities, DPA4 claimed the global top rank by its outstanding CPS score and became the new SOTA model.
+
+Small Molecules: Leading Performance on SPICE-MACE-OFF. DPA4’s advantages extend far beyond inorganic crystals. It achieved a new SOTA record on SPICE-MACE-OFF, a leading benchmark for molecular research. With a smaller parameter size, it outperformed the former leading model eSEN to take the first place. DPA4 demonstrates consistent superior performance across inorganic crystals and organic small molecules, as well as in energy and force prediction, further proving its potential as a general-purpose potential energy surface model.
+
+
+
+*DPA4 Model Structure Diagram*
+
+## 2. Benchmark Performance: Double Championship on Matbench Discovery and SPICE-MACE-OFF
+
+Materials Discovery: World’s No.1 on Matbench Discovery. Initiated by top-tier institutions including the University of California, Berkeley and the University of Cambridge, Matbench Discovery is the most influential dynamic benchmark for AI-driven inorganic materials discovery worldwide and is widely recognized as the global gold standard for evaluating intelligent models in materials science. Different from simple static data fitting, it adopts a forward-looking testing mechanism that requires models to predict the thermodynamic stability of hundreds of thousands of unknown crystals, truly replicating the whole process of scientific research and exploration. Its evaluation system takes multiple metrics into account, including prediction accuracy of energy and force, F1 score and discovery acceleration factor, which are finally integrated into the comprehensive performance score CPS. Competing against state-of-the-art models from Meta, Microsoft and world-leading universities, DPA4 claimed the global top rank by its outstanding CPS score and became the new SOTA model.
+
+Small Molecules: Leading Performance on SPICE-MACE-OFF. DPA4’s advantages extend far beyond inorganic crystals. It achieved a new SOTA record on SPICE-MACE-OFF, a leading benchmark for molecular research. With a smaller parameter size, it outperformed the former leading model eSEN to take the first place. DPA4 demonstrates consistent superior performance across inorganic crystals and organic small molecules, as well as in energy and force prediction, further proving its potential as a general-purpose potential energy surface model.
+
+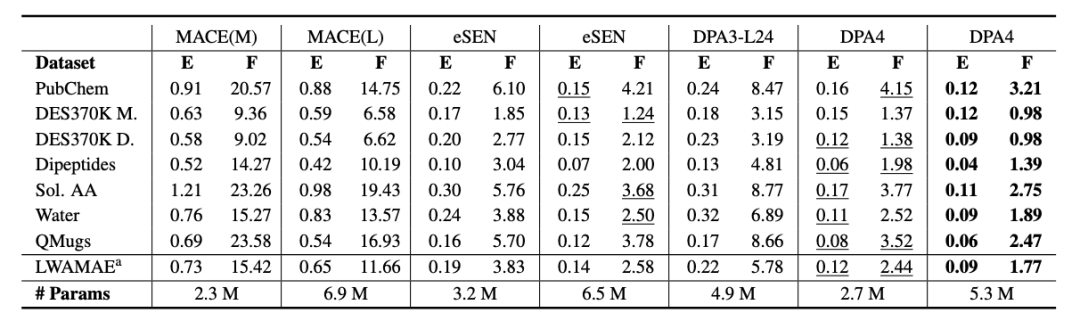 +
+*Performance on SPICE-MACE-OFF*
+
+## 3. Efficiency Comparison: Redefining the Accuracy-Cost Pareto Frontier
+
+While the double championship across benchmarks validates DPA4’s exceptional accuracy, its true distinction lies in the remarkably low computational cost required to achieve such performance.
+
+Traditionally, topping benchmark leaderboards has always been associated with larger parameter sizes and higher training costs. DPA4, however, sets a new Pareto frontier in both accuracy and training cost:
+- Training Cost: Theoretically, a single consumer-grade RTX 5090 graphics card running for about one day can help DPA4 reach the accuracy level that eSEN, the previous SOTA model, attained after more than 300 GPU days of training.
+- Parameter Scale: Under the same CPS performance, DPA4’s parameter count is less than one-tenth of eSEN’s.
+- Generational Improvement: With equivalent prediction accuracy, DPA4’s training efficiency is approximately 10 times higher than its predecessor DPA3.
+
+Such substantial efficiency gains rely on multi-level engineering optimizations. While torch.compile can bring free performance boosts to conventional AI model training, machine learning potential training involves double backward computation since force is the derivative of energy. Given that compile does not support double backward, researchers had long been forced to expand batch sizes to maximize GPU utilization in potential function training. DPA4 is the first model worldwide to support compile-enabled training for machine learning potentials. Combined with automatic mixed precision (autocast) to bf16, it drastically reduces video memory consumption, laying a solid foundation for training larger models on a single graphics card.
+
+
+
+*Performance on SPICE-MACE-OFF*
+
+## 3. Efficiency Comparison: Redefining the Accuracy-Cost Pareto Frontier
+
+While the double championship across benchmarks validates DPA4’s exceptional accuracy, its true distinction lies in the remarkably low computational cost required to achieve such performance.
+
+Traditionally, topping benchmark leaderboards has always been associated with larger parameter sizes and higher training costs. DPA4, however, sets a new Pareto frontier in both accuracy and training cost:
+- Training Cost: Theoretically, a single consumer-grade RTX 5090 graphics card running for about one day can help DPA4 reach the accuracy level that eSEN, the previous SOTA model, attained after more than 300 GPU days of training.
+- Parameter Scale: Under the same CPS performance, DPA4’s parameter count is less than one-tenth of eSEN’s.
+- Generational Improvement: With equivalent prediction accuracy, DPA4’s training efficiency is approximately 10 times higher than its predecessor DPA3.
+
+Such substantial efficiency gains rely on multi-level engineering optimizations. While torch.compile can bring free performance boosts to conventional AI model training, machine learning potential training involves double backward computation since force is the derivative of energy. Given that compile does not support double backward, researchers had long been forced to expand batch sizes to maximize GPU utilization in potential function training. DPA4 is the first model worldwide to support compile-enabled training for machine learning potentials. Combined with automatic mixed precision (autocast) to bf16, it drastically reduces video memory consumption, laying a solid foundation for training larger models on a single graphics card.
+
+ +
+*Comparison of Training Time and Peak Video Memory Usage with DPA4’s Compile and AMP Enabled*
+
+This breakthrough means researchers can complete model training and iteration faster, and simulate microscopic processes at larger scales and over longer time spans with the same computing budget. DPA4 has transformed large-scale, high-throughput atomic simulation from a "computing luxury" into a universally accessible tool, which holds significant application value for research and development in battery materials, catalyst design, semiconductor exploration and other fields.
+
+## Summary
+
+DPA4 is a new-generation general-purpose potential function architecture built for the era of Large Atomic Models (LAMs). By combining SO(2) equivariant linear operators under local coordinate systems with attention mechanisms, it maintains full physical symmetry and energy conservation while greatly lowering the overhead of equivariant computations. Further optimized via native torch.compile acceleration and built-in ZBL potential, it delivers enhanced performance at the engineering level.
+
+DPA4 claimed the top position on both Matbench Discovery (materials discovery) and SPICE-MACE-OFF (small molecules). It establishes a brand-new Pareto frontier balancing accuracy and training cost: it matches or surpasses previous high-cost large models with less than one-tenth of the parameters and just one day of training on a single consumer graphics card. DPA4 fully proves that high accuracy and high efficiency are no longer mutually exclusive.
+
+At present, DPA4 is open for early access within the DeepModeling community. Its research paper and official full release will be open-sourced sequentially in the future. On the journey toward the era of Large Atomic Models, we will always adhere to the principle of open-source and open collaboration. We welcome researchers to keep track of our progress, join our community and explore together.
+
+## Core Developers & Affiliated Institutions
+Li Tiancheng (Peking University, AISI)
+Xue Jianming (Peking University)
+Zhang Linfeng (DP Technology, AISI)
+Zhang Duo (Peking University, AISI)
+Wang Han (Institute of Applied Physics and Computational Mathematics)
+
+*Comparison of Training Time and Peak Video Memory Usage with DPA4’s Compile and AMP Enabled*
+
+This breakthrough means researchers can complete model training and iteration faster, and simulate microscopic processes at larger scales and over longer time spans with the same computing budget. DPA4 has transformed large-scale, high-throughput atomic simulation from a "computing luxury" into a universally accessible tool, which holds significant application value for research and development in battery materials, catalyst design, semiconductor exploration and other fields.
+
+## Summary
+
+DPA4 is a new-generation general-purpose potential function architecture built for the era of Large Atomic Models (LAMs). By combining SO(2) equivariant linear operators under local coordinate systems with attention mechanisms, it maintains full physical symmetry and energy conservation while greatly lowering the overhead of equivariant computations. Further optimized via native torch.compile acceleration and built-in ZBL potential, it delivers enhanced performance at the engineering level.
+
+DPA4 claimed the top position on both Matbench Discovery (materials discovery) and SPICE-MACE-OFF (small molecules). It establishes a brand-new Pareto frontier balancing accuracy and training cost: it matches or surpasses previous high-cost large models with less than one-tenth of the parameters and just one day of training on a single consumer graphics card. DPA4 fully proves that high accuracy and high efficiency are no longer mutually exclusive.
+
+At present, DPA4 is open for early access within the DeepModeling community. Its research paper and official full release will be open-sourced sequentially in the future. On the journey toward the era of Large Atomic Models, we will always adhere to the principle of open-source and open collaboration. We welcome researchers to keep track of our progress, join our community and explore together.
+
+## Core Developers & Affiliated Institutions
+Li Tiancheng (Peking University, AISI)
+Xue Jianming (Peking University)
+Zhang Linfeng (DP Technology, AISI)
+Zhang Duo (Peking University, AISI)
+Wang Han (Institute of Applied Physics and Computational Mathematics)