Git es un sistema de control de versiones (Source Code Mananagement) distribuido. En los sistemas centralizados, el codigo fuente está en un servidor y los desarrolladores, cada vez que requieren realizar una operación, deben de estar conectados a ese servidor. Git, sin embargo, funciona de manera diferente. Tú te clonas el repositorio, que es una copia exacta del repositorio del servidor, realizas tus cambios en local, y vas sincronizando tu repositorio local con el repositorio remoto.
Pero... ¿qué es un repositorio? Según wikipedia es un espacio centralizado donde se almacena, organiza, mantiene y difunde información digital. Vamos, como si fuera una carpeta de dropbox o google drive, pero con facilidades para llevar el control de cambios.
Para usar git en local necesitaras instalarlo. En windows, yo lo que suelo usar es Cmder. Cualquiera de ellos te permitirá utilizar el interprete de comandos para interactuar con tus repositorios.
Situarse en la carpeta correspondiente e iniciar el repositorio
git init
Ejemplo de crear un fichero readme.md, editarlo, guardarlo y visualizarlo
touch readme.md -> Crea un fichero
vim readme.md -> abre vim para editarlo
[esc] :ws -> Guarda los cambios y sales
cat readme.md -> Visualizar el fichero
Necesitarás una cuenta en algún proveedor en la nube, como github, bitbucket, gitlab, azure repos... (o montarte tu propio servidor git) para almacenar el repositorio. Con esto podrás volcar los cambios que hagas en el código y recoger los cambios que hagan otros. A este repositorio en git se le llama remote.
Para sincronizar un repositorio creado en local, primero deberás crear un repositorio vació en tu plataforma (github, bitbucket, etc) y luego ejecutar:
git remote add origin url-del-repositorio -> Añado un repositorio remoto con que me sincronizaré. Como nombre le pongo origin (así se le suele llamar en git)
git push origin master -> Vuelco los cambios (push) que tengo en local al repositorio remoto (llamado origin) para la rama master
Si quieres revisar los remotos que tiene un repositorio:
git remote -v
Una alternativa para más sencilla para cuando empiezas, sería crearte el repositorio directamente en github, y con la url del repo recién creado, clonartelo en local:
git clone url-del-repositorio
git status -> Muestra el estado del repositorio
git status -s -> Muestra el estado del repositorio de forma resumida
git log -> Muestra los commits del repositorio
git log -> Muestra los commits del repositorio con el gráfico
git log --graph --abbrev-commit --oneline -> Muestra los commits del repositorio con el gráfico pero abreviado
git log --one-line -> Muestra los commits del repositorio en una linea
git show identificador-commit -> Muestra el detalle de un commmit
git blame fichero -> Historia de cambios de un fichero y quien lo ha hecho
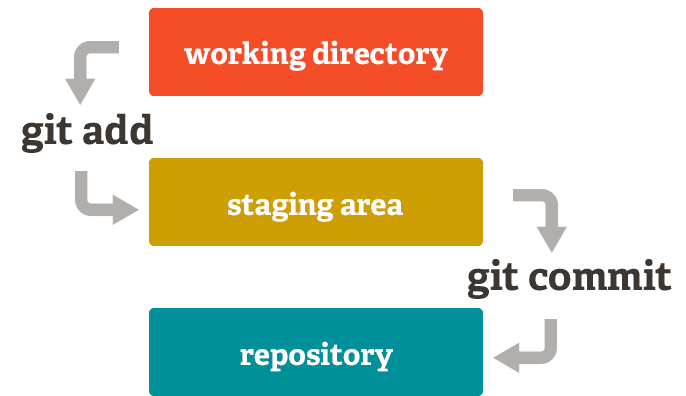
El working tree se corresponde con los cambios que se hacen en el directorio local, antes de ser añadidos al área de staging. El area de staging es la zona donde se añaden los cambios en los ficheros que están listos para ser commiteados definitivamente.
git add readme.md -> Añade el fichero readme.md al area de staging
git add . -> Añade todos los ficheros añadidos, cambiados y borrados al area de staging
git add -A -> Añade todos los cambios al área de staging
El comando commit guarda el estado del repositorio, añadiendo todos los cambios añadidos a la zona de staging
git commit -m "mensaje"
git commit -am "mensaje" -> Si incluimos la a añade al area de staging todos los ficheros modificados (No así los creados). Esto sería para hacer en el mismo paso add y commit
El area de stash es como un agujero en el suelo donde guardas los cambios que tienes en el working tree, para recuperarlos más tarde. En vez de hacer commit, haces stash.
git stash -> Añade los ficheros del area de staging a la zona de stash
git stash pop -> Recupera los ficheros de stash
git stash pop n -> Donde n es el índice numerico. Si has hecho varios stash, el último será 0, el anterior 1, etc
git stash list -> Muestra la lista de stash
Estas trabajando desarrollando una funcionalidad y, sin haberla terminado, debes resolver otra cuestión más prioritaria en ese mismo repositorio. Haces "stash" de los cambios que tienes sin subir, resuelves la cuestión más prioritaria, y una vez que has finalizado con ella, recuperas lo cambios que guardaste en el "stash".
Se pueden tagear los commits para identificarlos
git tag v1.0.0 -> Aplicar el tag v1.0.0 al commit actual
Deshacer un commit. Crea otro commit con el proceso inverso
git revert identificadorCommit -> El identificador del commit es el hash del commit sobre el que se quiere aplicar el revert
git branch -> Lita todas las ramas del repositorio local
git branch -a -> Lista todas las ramas del repositorio local y remoto
git branch rama1 -> Crea una rama con nombre rama1
git checkout rama1 -> Te posiciona en la rama rama1
git checkout -b rama1 -> Crea la rama rama1 y te posiciona en ella
git branch -d rama1 -> Borra la rama rama1
git push -> Vuelca todos los cambios de local sobre el remoto
git push origin master -> Vuelca los cambios sobre el remoto (llamado origin) de la rama master
En vez de añadir los cambios al repositorio remoto, si se necesita validarlo, se puede hacer una pull request, Se crea la pull-request y con ella una nueva rama. Una vez que se ve que los cambios son correctos, se valida la pull request, se mergean esos cambios, y se borra la rama (Esto se puede hacer desde github)
Estos comandos sirven para traerse cambios del repositorio remoto. Fetch trae los commits y las ramas, digamos la estructura Merge trae los cambios en los ficheros Pull es un comando que combina ambos
git fetch origin -> Trae la información de origin (el repositorio remoto)
git pull -> Trae los cambios del remoto
git fetch -ap -> Trae los cambios en el índice -a (todos los remotos) y -p de prume (Borra las ramas que ya no existan)
Ejemplos y ayuda sobre un comando en concreto (Too long didn't read). Puedes instalarlo globalmente con npm (npm install -g tldr)
tldr comando