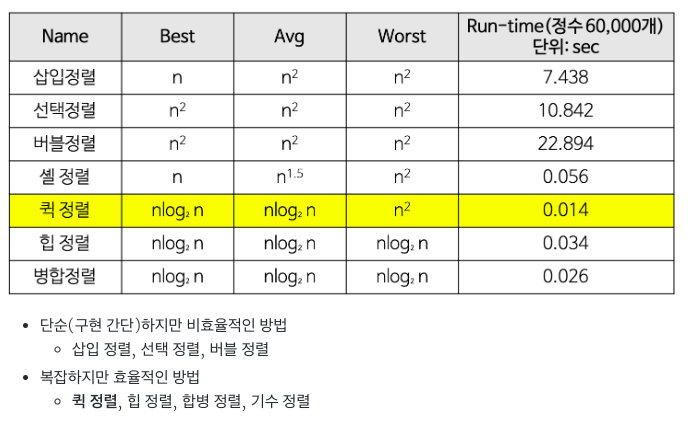
- 버블 정렬 ✔️
- 삽입 정렬 ✔️
- 선택 정렬 ✔️
- 합병 정렬 (merge sort) ✔️
- 퀵 정렬 ✔️
- 이진탐색 ✔️
- BFS ✔️
- DFS ✔️
서로 인접한 두 요소를 검사하여 정렬하는 알고리즘이다. 인접한 두 요소가 순서대로 되어있지 않으면 서로 교환한다.
구현이 간단하지만 비효율적이다.
최선 : n^2 / 평균 n^2 / 최악 n^2
앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여 자신의 위치를 찾아 삽입하는 정렬이다.
두번째 요소부터 시작하여 자신보다 큰 요소를 발견하였으면 그 요소를 뒤로 이동 시키고, 자신보다 작은 요소를 발견하였으면 바로 뒷자리에 자신을 넣어준다.
구현이 간단하지만 비효율적이다.
최선 - n 이동 없이 1번의 비교만 이루어지는 경우
최악 - n^2 모든 요소마다 비교를 진행하는 경우
평균 - n^2
정렬되지 않은 부분에서 최솟값을 찾아 정렬된 부분 끝에 추가해준다. 앞에서부터 정렬이 된다.
자료 이동 횟수가 미리 결정되지만 안정성을 만족하지 않는다. 같은 값이 있는 경우 상대적인 위치가 변경될 수 있다.
항상 최솟값의 위치를 찾아 변경해줘야 하므로,, n^2
최선 : n^2 / 평균 n^2 / 최악 n^2
분할 정복 알고리즘의 하나이다.
하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한다. 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다. 실제로 정렬이 이루어지는 시점은 2개의 리스트를 합병하는 단계다.
배열로 구성하면 임시 배열이 필요하다. 리스트 크기가 큰 경우에는 이동 횟수가 많으므로 큰 시간 낭비를 초래한다. 하지만 입력 데이터가 무엇이든 정렬되는 시간이 동일한 안정적인 방법이다.
순환 호출 logn * 비교 n
최선 : nlogn / 평균 nlogn / 최악 nlogn
분할 정복 알고리즘의 하나로, 매우 빠른 수행 속도를 자랑한다.
- 리스트 안에 한 요소를 선택한다. 이 요소를 피벗이라고 한다.
- 피벗을 기준으로 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮기고, 피벗보다 큰 요소들은 모두 피벗의 오른쪽으로 옮긴다.
- 피벗을 제외한 양쪽 리스트를 순환 호출 하면서 정렬을 반복한다.
- 리스트 크기가 0이나 1이 될 때까지 반복한다.
최선 nlogn
최악의 경우 - 리스트가 계속 불균형하게 나누어지는 경우 n^2. 이미 정렬 된 리스트에서 나타날 수 있다.
평균 nlogn
데이터가 정렬돼 있는 상태에서 특정한 값을 찾아내는 알고리즘.
배열의 중간에 있는 값을 선택하여 찾고자 하는 값 X와 비교한다. X가 중간 값보다 작으면 중간 값을 기준으로 좌측의 데이터들을 대상으로 탐색하고, 중간 값보다 크면 배열의 우측을 대상으로 다시 탐색한다. 동일한 방법으로 다시 중간의 값을 임의로 선택하고 비교한다. 해당 값을 찾을 때 까지 이 과정을 반복한다.
logN 의 시간 복잡도를 갖는다.
그래프 탐색으로 인접한 노드를 먼저 탐색하는 방법
시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법
두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
너비 우선 탐색이 깊이 우선 탐색보다 좀 더 복잡하다.
방문한 노드를 차례대로 저장한 후 꺼낼 수 있는 자료 구조인 큐를 사용한다.
재귀적으로 동작하지 않는다
자식 노드를 다 방문하고 인접 노드로 넘어가는 방법
모든 노드를 방문 하고자 하는 경우에 이 방법을 선택한다. 스택이나 재귀호출을 사용한다
BFS에 비해 좀 더 간단하다. 검색 속도 자체는 느리다.
인접한 두 요소를 비교하면서 정렬해 나가는 알고리즘입니다. 구현이 간단하지만 시간 복잡도가 항상 n^2으로 비효율적입니다.
정렬된 부분에서 자신의 위치를 찾아 삽입하는 알고리즘입니다. 오름차순의 경우, 정렬된 부분에서 자신보다 큰 값을 만나면 뒤로 미루고 자신보다 작은 값을 만나면 바로 뒤에 넣어주면 됩니다. 구현이 간단하지만 비효율적입니다. 시간 복잡도는 최선은 n, 최악의 경우는 n^2 입니다.
정렬되지 않은 부분에서 최솟값을 찾아 정렬된 부분에 추가해주는 알고리즘입니다. 앞에서부터 정렬되며, 자료 이동 횟수가 미리 결정되지만 같은 수가 있는 경우 상대적인 위치가 변경될 수 있어 안정적이지 않습니다. 시간 복잡도는 항상 n^2 입니다.
분할 정복 알고리즘의 하나입니다. 하나의 리스트를 균등한 두 개의 크기로 분할합니다. 분할된 리스트를 정렬하고 다시 하나로 합하여 정렬하는 방법입니다. 임시 배열이 필요하고 리스트 크기가 큰 경우에는 이동 횟수가 많지만 입력 데이터 값이 무엇이든 정렬되는 시간이 nlogn으로 동일한 안정적인 방법입니다.
분할 정복 알고리즘 중의 하나입니다. 속도가 굉장히 빠른 알고리즘 입니다. 리스트 안에 하나의 pivot을 잡고 피벗을 기준으로 작은 값들은 왼쪽에, 큰 값들은 오른쪽에 위치하게 됩니다. 이 후 피벗을 기준으로 왼쪽과 오른쪽 리스트를 순환 호출을 통해 이 과정을 반복하면서 정렬해가는 알고리즘 입니다. 시간 복잡도는 최선의 경우 nlogn이고, 최악의 경우는 n^2입니다.
데이터가 정렬 된 상태에서 특정 값을 찾는 알고리즘입니다. 배열의 중간 값을 선택하여 찾고자 하는 값과 비교를 합니다. 중간 값이 찾고자 하는 값보다 작을 경우 왼쪽을, 중간 값이 찾고자 하는 값보다 큰 경우 오른쪽을 동일한 방법으로 탐색합니다. 해당 값을 찾을 때 까지 이 과정을 반복합니다. logn의 시간 복잡도를 가집니다.
BFS는 너비 우선 탐색으로 인접한 노드를 먼저 탐색하는 알고리즘입니다. 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 사용하고, 큐를 사용합니다.
DFS는 깊이 우선 탐색으로 자식 노드를 다 방문하고 인접한 노드로 넘어가는 알고리즘입니다. 모든 노드를 방문하는 경우 사용합니다. 재귀 호출이나 스택을 사용합니다.