Today’s target
+The aim of this tutorial is to show how we can measure and map +degree, betweenness, closeness, eigenvector, and other types of +centrality, explore their distributions and calculate the corresponding +centralisation.
+
Setting up
+For this exercise, we’ll use the ison_brandes dataset in
+{manynet}. This dataset is in a ‘tidygraph’ format, but
+manynet makes it easy to coerce this into other forms to be
+compatible with other packages. We can create a two-mode version of the
+dataset by renaming the nodal attribute “twomode_type” to just “type”.
+Let’s begin by graphing these datasets using graphr().
# Let's graph the one-mode version
+graphr(____)# Now, let's create a two-mode version 'ison_brandes2' and graph it.
+ison_brandes2 <- ison_brandes %>% rename(type = twomode_type)
+graphr(____)# plot the one-mode version
+graphr(ison_brandes)
+ison_brandes2 <- ison_brandes %>% rename(type = twomode_type)
+# plot the two-mode version
+graphr(ison_brandes2, layout = "bipartite")The network is anonymous, but I think it would be nice to add some
+names, even if it’s just pretend. Luckily, {manynet} has a
+function for this: to_named(). This makes plotting the
+network just a wee bit more accessible and interpretable:
ison_brandes <- to_named(ison_brandes)# Now, let's graph using the object names: "ison_brandes"
+graphr(____)ison_brandes <- to_named(ison_brandes)
+# plot network with names
+graphr(ison_brandes)Note that you will likely get a different set of names (though still +alphabetical), as they are assigned randomly from a pool of (American) +first names.
+Degree centrality
+
Let’s start with calculating + +degree . Remember that degree centrality is just the number +of incident edges/ties to each node. It is therefore easy to calculate +yourself. Just sum the rows or columns of the matrix!
+# We can calculate degree centrality like this:
+(mat <- as_matrix(ison_brandes))
+(degrees <- rowSums(mat))
+rowSums(mat) == colSums(mat)# Or by using a built in command in manynet like this:
+node_degree(ison_brandes, normalized = FALSE)# manually calculate degree centrality
+mat <- as_matrix(ison_brandes)
+degrees <- rowSums(mat)
+rowSums(mat) == colSums(mat)
+# You can also just use a built in command in manynet though:
+node_degree(ison_brandes, normalized = FALSE)Degree distributions
+
Often we are interested in the distribution of (degree) centrality in
+a network. {autograph} offers a way to get a pretty good
+first look at this
+
+distribution , though there are more elaborate ways to do
+this in base and grid graphics.
# distribution of degree centrality scores of nodes
+plot(node_degree(ison_brandes))What’s plotted here by default is both the degree distribution as a +histogram, as well as a density plot overlaid on it in red.
+Other centralities
+Other measures of centrality can be a little trickier to calculate by
+hand. Fortunately, we can use functions from {manynet} to
+help calculate the
+
+betweenness ,
+
+closeness , and
+
+eigenvector centralities for each node in the network.
+Let’s collect the vectors of these centralities for the
+ison_brandes dataset:
# Use the node_betweenness() function to calculate the
+# betweenness centralities of nodes in a network
+node_betweenness(ison_brandes)# Use the node_closeness() function to calculate the
+# closeness centrality of nodes in a network
+node_closeness(ison_brandes)# Use the node_eigenvector() function to calculate
+# the eigenvector centrality of nodes in a network
+node_eigenvector(ison_brandes)node_betweenness(ison_brandes)
+node_closeness(ison_brandes)
+node_eigenvector(ison_brandes)What is returned here are vectors of betweenness, closeness, and +eigenvector scores for the nodes in the network. But what do they +mean?
+Try to answer the following questions for yourself:
+-
+
- what does Bonacich mean when he says that + +power and influence are not the same thing? +
- can you think of a real-world example when an actor might be central +but not powerful, or powerful but not central? +
Note that all centrality measures in {manynet} return
+normalized scores by default – for the raw scores, include
+normalized = FALSE in the function as an extra
+argument.
Now, can you create degree distributions for each of these?
+plot(node_betweenness(ison_brandes))
+plot(node_closeness(ison_brandes))
+plot(node_eigenvector(ison_brandes))Plotting centrality
+It is straightforward in {autograph} to highlight nodes
+and ties with maximum or minimum (e.g. degree) scores. If the vector is
+numeric (i.e. a “measure”), then this can be easily converted into a
+logical vector that identifies the node/tie with the maximum/minimum
+score using e.g. node_is_max() or
+tie_is_min(). By passing this attribute to the
+graphr() argument “node_color” we can highlight which node
+or nodes hold the maximum score in red.
# plot the network, highlighting the node with the highest centrality score with a different colour
+ison_brandes %>%
+ mutate_nodes(color = node_is_max(node_degree())) %>%
+ graphr(node_color = "color")
+
+ison_brandes %>%
+ mutate_nodes(color = node_is_max(node_betweenness())) %>%
+ graphr(node_color = "color")
+
+ison_brandes %>%
+ mutate_nodes(color = node_is_max(node_closeness())) %>%
+ graphr(node_color = "color")
+
+ison_brandes %>%
+ mutate_nodes(color = node_is_max(node_eigenvector())) %>%
+ graphr(node_color = "color")How neat! Try it with the two-mode version. What can you see?
+# Instead of "ison_brandes", use "ison_brandes2"ison_brandes2 %>%
+ add_node_attribute("color", node_is_max(node_degree(ison_brandes2))) %>%
+ graphr(node_color = "color", layout = "bipartite")
+
+ison_brandes2 %>%
+ add_node_attribute("color", node_is_max(node_betweenness(ison_brandes2))) %>%
+ graphr(node_color = "color", layout = "bipartite")
+
+ison_brandes2 %>%
+ add_node_attribute("color", node_is_max(node_closeness(ison_brandes2))) %>%
+ graphr(node_color = "color", layout = "bipartite")
+
+ison_brandes2 %>%
+ add_node_attribute("color", node_is_max(node_eigenvector(ison_brandes2))) %>%
+ graphr(node_color = "color", layout = "bipartite")Centralization
+
{manynet} also implements network
+
+centralization functions. Here we are no longer interested
+in the level of the node, but in the level of the whole network, so the
+syntax replaces node_ with net_:
net_degree(ison_brandes)
+net_betweenness(ison_brandes)
+net_closeness(ison_brandes)
+print(net_eigenvector(ison_brandes), digits = 5)By default, scores are printed up to 3 decimal places, but this can +be modified and, in any case, the unrounded values are retained +internally. This means that even if rounded values are printed (to +respect console space), as much precision as is available is used in +further calculations.
+Note that for centralization in two-mode networks, two values are +given (as a named vector), since normalization typically depends on the +(asymmetric) number of nodes in each mode.
+What if we want to have a single image/figure with multiple plots?
+This can be a little tricky with gg-based plots, but fortunately the
+{patchwork} package is here to help.
ison_brandes <- ison_brandes %>%
+ add_node_attribute("degree", node_is_max(node_degree(ison_brandes))) %>%
+ add_node_attribute("betweenness", node_is_max(node_betweenness(ison_brandes))) %>%
+ add_node_attribute("closeness", node_is_max(node_closeness(ison_brandes))) %>%
+ add_node_attribute("eigenvector", node_is_max(node_eigenvector(ison_brandes)))
+gd <- graphr(ison_brandes, node_color = "degree") +
+ ggtitle("Degree", subtitle = round(net_degree(ison_brandes), 2))
+gc <- graphr(ison_brandes, node_color = "closeness") +
+ ggtitle("Closeness", subtitle = round(net_closeness(ison_brandes), 2))
+gb <- graphr(ison_brandes, node_color = "betweenness") +
+ ggtitle("Betweenness", subtitle = round(net_betweenness(ison_brandes), 2))
+ge <- graphr(ison_brandes, node_color = "eigenvector") +
+ ggtitle("Eigenvector", subtitle = round(net_eigenvector(ison_brandes), 2))
+(gd | gb) / (gc | ge)
+# ggsave("brandes-centralities.pdf")Free play
+
Choose another dataset included in {manynet}. Name a
+plausible research question you could ask of the dataset relating to
+each of the four main centrality measures (degree, betweenness,
+closeness, eigenvector). Plot the network with nodes sized by each
+centrality measure, using titles or subtitles to record the question
+and/or centralization measure.
Glossary
+Here are some of the terms that we have covered in this module:
+-
+
- +Betweenness + +
- +The betweenness centrality of a node is the proportion of shortest paths +between all pairs of nodes that pass through that node. + +
- +Centralization + +
- +A measure of how unequal the centralities of the nodes in a network are. + +
- +Closeness + +
- +The closeness centrality of a node is the reciprocal of the sum of its +distances to all other nodes. + +
- +Degree + +
- +The degree of a node is the number of connections it has. + +
- +Distribution + +
- +A degree distribution is the frequency distribution of the degrees of +the nodes in a network. + +
- +Eigenvector + +
- +The eigenvector centrality of a node is the corresponding value in the +dominant eigenvector of the adjacency matrix. + +
- +Power + +
- +An eigenvector-style centrality that allows being connected to more +peripheral nodes to contribute centrality. + +
+ + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + +
+ + + + + + + +
+
+
+
+
+
+
+
+
+The data we're going to use here, "ison_algebra", is included in the `{manynet}` package.
+Do you remember how to call the data?
+Can you find out some more information about it?
+
+```{r data, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r data-hint-1, purl = FALSE}
+# Let's call and load the 'ison_algebra' dataset
+data("ison_algebra", package = "manynet")
+# Or you can retrieve like this:
+ison_algebra <- manynet::ison_algebra
+```
+
+```{r data-hint-2, purl = FALSE}
+# If you want to learn more about the 'ison_algebra' dataset, use the following function (below)
+?manynet::ison_algebra
+```
+
+```{r data-solution}
+data("ison_algebra", package = "manynet")
+?manynet::ison_algebra
+# If you want to see the network object, you can run the name of the object
+ison_algebra
+# or print the code with brackets at the front and end of the code
+(ison_algebra <- manynet::ison_algebra)
+```
+
+We can see after printing the object that the dataset is multiplex,
+meaning that it contains several different types of ties:
+friendship (friends), social (social) and task interactions (tasks).
+
+### Adding names
+
+The network is also anonymous, but I think it would be nice to add some names,
+even if it's just pretend.
+Luckily, `{manynet}` has a function for this, `to_named()`.
+This makes plotting the network just a wee bit more accessible and interpretable.
+Let's try adding names and graphing the network now:
+
+```{r addingnames, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r addingnames-hint-1, purl = FALSE}
+ison_algebra <- to_named(ison_algebra)
+```
+
+```{r addingnames-hint-2, purl = FALSE}
+graphr(ison_algebra)
+```
+
+```{r addingnames-solution}
+ison_algebra <- to_named(ison_algebra)
+graphr(ison_algebra)
+```
+
+Note that you will likely get a different set of names,
+as they are assigned randomly from a pool of (American) first names.
+
+### Separating multiplex networks
+
+As a multiplex network,
+there are actually three different types of ties (friends, social, and tasks)
+in this network.
+We can extract them and graph them separately using `to_uniplex()`:
+
+```{r separatingnets, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r separatingnets-hint-1, purl = FALSE}
+# to_uniplex extracts ties of a single type,
+# focusing on the 'friends' tie attribute here
+friends <- to_uniplex(ison_algebra, "friends")
+gfriend <- graphr(friends) + ggtitle("Friendship")
+```
+
+```{r separatingnets-hint-2, purl = FALSE}
+# now let's focus on the 'social' tie attribute
+social <- to_uniplex(ison_algebra, "social")
+gsocial <- graphr(social) + ggtitle("Social")
+```
+
+```{r separatingnets-hint-3, purl = FALSE}
+# and the 'tasks' tie attribute
+tasks <- to_uniplex(ison_algebra, "tasks")
+gtask <- graphr(tasks) + ggtitle("Task")
+```
+
+```{r separatingnets-hint-4, purl = FALSE}
+# now, let's compare each attribute's graph, side-by-side
+gfriend + gsocial + gtask
+# if you get an error here, you may need to install and load
+# the package 'patchwork'.
+# It's highly recommended for assembling multiple plots together.
+# Otherwise you can just plot them separately on different lines.
+```
+
+```{r separatingnets-solution}
+friends <- to_uniplex(ison_algebra, "friends")
+gfriend <- graphr(friends) + ggtitle("Friendship")
+
+social <- to_uniplex(ison_algebra, "social")
+gsocial <- graphr(social) + ggtitle("Social")
+
+tasks <- to_uniplex(ison_algebra, "tasks")
+gtask <- graphr(tasks) + ggtitle("Task")
+
+# We now have three separate networks depicting each type of tie from the ison_algebra network:
+gfriend + gsocial + gtask
+```
+
+Note also that these are weighted networks.
+`graphr()` automatically recognises these different weights and plots them.
+Where useful (less dense directed networks),
+`graphr()` also bends reciprocated arcs.
+What (else) can we say about these three networks?
+
+## Cohesion
+
+Let's concentrate on the **task** network for now and calculate a few basic measures of cohesion:
+density, reciprocity, transitivity, and components.
+
+### Density
+
+Density represents a generalised measure of cohesion,
+characterising how cohesive the network is in terms of how many
+potential ties (i.e. dyads) are actualised.
+Recall that there are different equations depending on the type of network.
+Below are three equations:
+
+$$A: \frac{|T|}{|N|(|N|-1)}$$
+$$B: \frac{2|T|}{|N|(|N|-1)}$$
+$$C: \frac{|T|}{|N||M|}$$
+
+where $|T|$ is the number of ties in the network,
+and $|N|$ and $|M|$ are the number of nodes in the first and second mode respectively.
+
+```{r densq, echo=FALSE, purl = FALSE}
+question("Which equation is used for measuring density for a directed network:",
+ answer("A",
+ correct = TRUE,
+ message = '
+
+
+
+
+
+
+
+
+
+The data we're going to use here, "ison_algebra", is included in the `{manynet}` package.
+Do you remember how to call the data?
+Can you find out some more information about it?
+
+```{r data, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r data-hint-1, purl = FALSE}
+# Let's call and load the 'ison_algebra' dataset
+data("ison_algebra", package = "manynet")
+# Or you can retrieve like this:
+ison_algebra <- manynet::ison_algebra
+```
+
+```{r data-hint-2, purl = FALSE}
+# If you want to learn more about the 'ison_algebra' dataset, use the following function (below)
+?manynet::ison_algebra
+```
+
+```{r data-solution}
+data("ison_algebra", package = "manynet")
+?manynet::ison_algebra
+# If you want to see the network object, you can run the name of the object
+ison_algebra
+# or print the code with brackets at the front and end of the code
+(ison_algebra <- manynet::ison_algebra)
+```
+
+We can see after printing the object that the dataset is multiplex,
+meaning that it contains several different types of ties:
+friendship (friends), social (social) and task interactions (tasks).
+
+### Adding names
+
+The network is also anonymous, but I think it would be nice to add some names,
+even if it's just pretend.
+Luckily, `{manynet}` has a function for this, `to_named()`.
+This makes plotting the network just a wee bit more accessible and interpretable.
+Let's try adding names and graphing the network now:
+
+```{r addingnames, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r addingnames-hint-1, purl = FALSE}
+ison_algebra <- to_named(ison_algebra)
+```
+
+```{r addingnames-hint-2, purl = FALSE}
+graphr(ison_algebra)
+```
+
+```{r addingnames-solution}
+ison_algebra <- to_named(ison_algebra)
+graphr(ison_algebra)
+```
+
+Note that you will likely get a different set of names,
+as they are assigned randomly from a pool of (American) first names.
+
+### Separating multiplex networks
+
+As a multiplex network,
+there are actually three different types of ties (friends, social, and tasks)
+in this network.
+We can extract them and graph them separately using `to_uniplex()`:
+
+```{r separatingnets, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r separatingnets-hint-1, purl = FALSE}
+# to_uniplex extracts ties of a single type,
+# focusing on the 'friends' tie attribute here
+friends <- to_uniplex(ison_algebra, "friends")
+gfriend <- graphr(friends) + ggtitle("Friendship")
+```
+
+```{r separatingnets-hint-2, purl = FALSE}
+# now let's focus on the 'social' tie attribute
+social <- to_uniplex(ison_algebra, "social")
+gsocial <- graphr(social) + ggtitle("Social")
+```
+
+```{r separatingnets-hint-3, purl = FALSE}
+# and the 'tasks' tie attribute
+tasks <- to_uniplex(ison_algebra, "tasks")
+gtask <- graphr(tasks) + ggtitle("Task")
+```
+
+```{r separatingnets-hint-4, purl = FALSE}
+# now, let's compare each attribute's graph, side-by-side
+gfriend + gsocial + gtask
+# if you get an error here, you may need to install and load
+# the package 'patchwork'.
+# It's highly recommended for assembling multiple plots together.
+# Otherwise you can just plot them separately on different lines.
+```
+
+```{r separatingnets-solution}
+friends <- to_uniplex(ison_algebra, "friends")
+gfriend <- graphr(friends) + ggtitle("Friendship")
+
+social <- to_uniplex(ison_algebra, "social")
+gsocial <- graphr(social) + ggtitle("Social")
+
+tasks <- to_uniplex(ison_algebra, "tasks")
+gtask <- graphr(tasks) + ggtitle("Task")
+
+# We now have three separate networks depicting each type of tie from the ison_algebra network:
+gfriend + gsocial + gtask
+```
+
+Note also that these are weighted networks.
+`graphr()` automatically recognises these different weights and plots them.
+Where useful (less dense directed networks),
+`graphr()` also bends reciprocated arcs.
+What (else) can we say about these three networks?
+
+## Cohesion
+
+Let's concentrate on the **task** network for now and calculate a few basic measures of cohesion:
+density, reciprocity, transitivity, and components.
+
+### Density
+
+Density represents a generalised measure of cohesion,
+characterising how cohesive the network is in terms of how many
+potential ties (i.e. dyads) are actualised.
+Recall that there are different equations depending on the type of network.
+Below are three equations:
+
+$$A: \frac{|T|}{|N|(|N|-1)}$$
+$$B: \frac{2|T|}{|N|(|N|-1)}$$
+$$C: \frac{|T|}{|N||M|}$$
+
+where $|T|$ is the number of ties in the network,
+and $|N|$ and $|M|$ are the number of nodes in the first and second mode respectively.
+
+```{r densq, echo=FALSE, purl = FALSE}
+question("Which equation is used for measuring density for a directed network:",
+ answer("A",
+ correct = TRUE,
+ message = ' '
+),
+ answer("B",
+ message = "This is the equation for an undirected network."),
+ answer("C",
+ message = "This is the equation for a two-mode network."),
+ allow_retry = TRUE
+)
+```
+
+One can calculate the density of the network using the number of nodes
+and the number of ties using the functions `net_nodes()` and `net_ties()`,
+respectively:
+
+```{r dens-explicit, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r dens-explicit-solution}
+# calculating network density manually according to equation
+net_ties(tasks)/(net_nodes(tasks)*(net_nodes(tasks)-1))
+```
+
+but we can also just use the `{manynet}` function for calculating the density,
+which always uses the equation appropriate for the type of network...
+
+```{r dens, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r dens-solution}
+net_density(tasks)
+```
+
+Note that the various measures in `{manynet}` print results to three decimal points
+by default, but the underlying result retains the same recurrence.
+So same result...
+
+```{r dens-qa, echo=FALSE, purl = FALSE}
+question("Is this network's density high or low in absolute terms?",
+ answer("High",
+ message = "The closer the value is to 1, the more dense the network and the more cohesive the network is as a whole."),
+ answer("Low",
+ correct = TRUE,
+ message = 'The closer the value is to 0, the sparser the network and the less cohesive the network is as a whole. But this is still quite typical density for a relatively small, social network like this one.
'
+),
+ answer("B",
+ message = "This is the equation for an undirected network."),
+ answer("C",
+ message = "This is the equation for a two-mode network."),
+ allow_retry = TRUE
+)
+```
+
+One can calculate the density of the network using the number of nodes
+and the number of ties using the functions `net_nodes()` and `net_ties()`,
+respectively:
+
+```{r dens-explicit, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r dens-explicit-solution}
+# calculating network density manually according to equation
+net_ties(tasks)/(net_nodes(tasks)*(net_nodes(tasks)-1))
+```
+
+but we can also just use the `{manynet}` function for calculating the density,
+which always uses the equation appropriate for the type of network...
+
+```{r dens, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r dens-solution}
+net_density(tasks)
+```
+
+Note that the various measures in `{manynet}` print results to three decimal points
+by default, but the underlying result retains the same recurrence.
+So same result...
+
+```{r dens-qa, echo=FALSE, purl = FALSE}
+question("Is this network's density high or low in absolute terms?",
+ answer("High",
+ message = "The closer the value is to 1, the more dense the network and the more cohesive the network is as a whole."),
+ answer("Low",
+ correct = TRUE,
+ message = 'The closer the value is to 0, the sparser the network and the less cohesive the network is as a whole. But this is still quite typical density for a relatively small, social network like this one.  '),
+ allow_retry = TRUE
+)
+```
+
+Density offers an important baseline measure for characterising
+the network as a whole.
+
+## Closure
+
+In this section we're going to move from generalised measures of cohesion,
+like density, to more localised measures of cohesion.
+These are not only measures of cohesion though,
+but are also often associated with certain mechanisms of closure.
+Closure involves ties being more likely because other ties are present.
+There are two common examples of this in the literature:
+`gloss("reciprocity")`, where a directed tie is often likely to prompt a reciprocating tie,
+and `gloss("transitivity")`, where a directed two-path is likely to be shortened
+by an additional arc connecting the first and third nodes on that path.
+
+
'),
+ allow_retry = TRUE
+)
+```
+
+Density offers an important baseline measure for characterising
+the network as a whole.
+
+## Closure
+
+In this section we're going to move from generalised measures of cohesion,
+like density, to more localised measures of cohesion.
+These are not only measures of cohesion though,
+but are also often associated with certain mechanisms of closure.
+Closure involves ties being more likely because other ties are present.
+There are two common examples of this in the literature:
+`gloss("reciprocity")`, where a directed tie is often likely to prompt a reciprocating tie,
+and `gloss("transitivity")`, where a directed two-path is likely to be shortened
+by an additional arc connecting the first and third nodes on that path.
+
+ +
+### Reciprocity
+
+First, let's calculate
+`r gloss("reciprocity")`
+in the task network.
+While one could do this by hand,
+it's more efficient to do this using the `{manynet}` package.
+Can you guess the correct name of the function?
+
+```{r recip, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r recip-solution}
+net_reciprocity(tasks)
+# this function calculates the amount of reciprocity in the whole network
+```
+
+Wow, this seems quite high based on what we observed visually!
+But if we look closer, this makes sense.
+We can use `tie_is_reciprocated()` to identify those ties that are
+reciprocated and not.
+
+```{r recip-explanation, exercise = TRUE}
+tasks %>% mutate_ties(rec = tie_is_reciprocated(tasks)) %>% graphr(edge_color = "rec")
+net_indegree(tasks)
+```
+
+So we can see that indeed there are very few asymmetric ties,
+and yet node 16 is both the sender and receiver of most of the task activity.
+So our reciprocity measure has taught us something about this network
+that might not have been obvious visually.
+
+### Transitivity
+
+And let's calculate
+`r gloss("transitivity")`
+in the task network.
+Again, can you guess the correct name of this function?
+
+```{r trans, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r trans-solution}
+net_transitivity(tasks)
+# this function calculates the amount of transitivity in the whole network
+```
+
+```{r trans-interp, echo=FALSE, purl = FALSE}
+question("What can we say about task closure in this network? Choose all that apply.",
+ answer("Transitivity for the task network is 0.568",
+ correct = TRUE,
+ message = '
+
+### Reciprocity
+
+First, let's calculate
+`r gloss("reciprocity")`
+in the task network.
+While one could do this by hand,
+it's more efficient to do this using the `{manynet}` package.
+Can you guess the correct name of the function?
+
+```{r recip, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r recip-solution}
+net_reciprocity(tasks)
+# this function calculates the amount of reciprocity in the whole network
+```
+
+Wow, this seems quite high based on what we observed visually!
+But if we look closer, this makes sense.
+We can use `tie_is_reciprocated()` to identify those ties that are
+reciprocated and not.
+
+```{r recip-explanation, exercise = TRUE}
+tasks %>% mutate_ties(rec = tie_is_reciprocated(tasks)) %>% graphr(edge_color = "rec")
+net_indegree(tasks)
+```
+
+So we can see that indeed there are very few asymmetric ties,
+and yet node 16 is both the sender and receiver of most of the task activity.
+So our reciprocity measure has taught us something about this network
+that might not have been obvious visually.
+
+### Transitivity
+
+And let's calculate
+`r gloss("transitivity")`
+in the task network.
+Again, can you guess the correct name of this function?
+
+```{r trans, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r trans-solution}
+net_transitivity(tasks)
+# this function calculates the amount of transitivity in the whole network
+```
+
+```{r trans-interp, echo=FALSE, purl = FALSE}
+question("What can we say about task closure in this network? Choose all that apply.",
+ answer("Transitivity for the task network is 0.568",
+ correct = TRUE,
+ message = ' '),
+ answer("Transitivity for the task network is -0.568",
+ message = "Transivitity must be between 0 and 1."),
+ answer("Transitivity is quite low in this network",
+ message = "Transitivity is often around 0.3 in most social networks."),
+ answer("Transitivity is quite high in this network",
+ correct = TRUE),
+ answer("Transitivity is likely higher in the task network than the friendship network",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Projection
+
+### A two-mode network
+
+The next dataset, 'ison_southern_women', is also available in `{manynet}`.
+It's a classic two-mode network about the attendance of 18 women
+at 14 social events in the 1930s American South.
+For more details see `?ison_southern_women` for documentation in your R/RStudio.
+Let's load and graph the data.
+
+```{r setup-women, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r setup-women-hint-1, purl = FALSE}
+# let's load the data and analyze it
+data("ison_southern_women")
+ison_southern_women
+```
+
+```{r setup-women-hint-2, purl = FALSE}
+graphr(ison_southern_women, node_color = "type")
+graphr(ison_southern_women, "railway", node_color = "type")
+```
+
+```{r setup-women-solution}
+data("ison_southern_women")
+ison_southern_women
+graphr(ison_southern_women, node_color = "type")
+```
+
+### Project two-mode network into two one-mode networks
+
+Now what if we are only interested in one part of the network?
+For that, we can obtain a 'projection' of the two-mode network.
+There are two ways of doing this.
+The hard way...
+
+```{r hardway, exercise=TRUE, exercise.setup = "setup-women", purl = FALSE}
+
+```
+
+```{r hardway-solution}
+twomode_matrix <- as_matrix(ison_southern_women)
+women_matrix <- twomode_matrix %*% t(twomode_matrix)
+event_matrix <- t(twomode_matrix) %*% twomode_matrix
+```
+
+Or the easy way:
+
+```{r easyway, exercise=TRUE, exercise.setup = "setup-women"}
+# women-graph
+# to_mode1(): Results in a weighted one-mode object that retains the row nodes from
+# a two-mode object, and weights the ties between them on the basis of their joint
+# ties to nodes in the second mode (columns)
+
+women_graph <- to_mode1(ison_southern_women)
+graphr(women_graph)
+
+# note that projection `to_mode1` involves keeping one type of nodes
+# this is different from to_uniplex above, which keeps one type of ties in the network
+
+# event-graph
+# to_mode2(): Results in a weighted one-mode object that retains the column nodes from
+# a two-mode object, and weights the ties between them on the basis of their joint ties
+# to nodes in the first mode (rows)
+
+event_graph <- to_mode2(ison_southern_women)
+graphr(event_graph)
+```
+
+### Projection options
+
+`{manynet}` also includes several other options for how to construct the projection.
+The default ("count") might be interpreted as indicating the degree or amount of
+shared ties to the other mode.
+"jaccard" divides this count by the number of nodes in the other mode
+to which either of the nodes are tied.
+It can thus be interpreted as opportunity weighted by participation.
+"rand" instead counts both shared ties and shared absences,
+and can thus be interpreted as the degree of behavioural mirroring between the
+nodes.
+Lastly, "pearson" (Pearson's coefficient) and "yule" (Yule's Q) produce
+correlations in ties for valued and binary data respectively.
+
+```{r otherway, exercise=TRUE, exercise.setup = "setup-women", purl = FALSE}
+
+```
+
+```{r otherway-solution}
+tie_weights(to_mode1(ison_southern_women, similarity = "count"))
+tie_weights(to_mode1(ison_southern_women, similarity = "jaccard"))
+tie_weights(to_mode1(ison_southern_women, similarity = "rand"))
+tie_weights(to_mode1(ison_southern_women, similarity = "pearson"))
+tie_weights(to_mode1(ison_southern_women, similarity = "yule"))
+```
+
+Practically speaking, most projection is conducted using the "count" method,
+as it reflects the absolute overlap, the frequency of co-occurrence.
+As such, it is most commonly used in social and organisational network analysis,
+reflecting shared group membership or collaboration intensity.
+But it is sensitive to asymmetries in the number of nodes in each node set and
+the degree distribution of each node set, and ignores the absence of ties as
+uninformative.
+To normalise for these effects, "jaccard" and "rand" are often used.
+"pearson" and "yule" are less commonly used, but can be useful when
+interested in the correlation of ties between nodes.
+
+### Closure in two-mode networks
+
+Let's return to the question of closure.
+First try one of the closure measures we have already treated that gives us
+a sense of shared partners for one-mode networks.
+Then compare this with `net_equivalency()`, which can be used on the original
+two-mode network.
+
+```{r twomode-cohesion, exercise=TRUE, exercise.setup = "easyway", purl = FALSE}
+
+```
+
+```{r twomode-cohesion-hint-1, purl = FALSE}
+# net_transitivity(): Calculate transitivity in a network
+
+net_transitivity(women_graph)
+net_transitivity(event_graph)
+```
+
+```{r twomode-cohesion-hint-2, purl = FALSE}
+# net_equivalency(): Calculate equivalence or reinforcement in a (usually two-mode) network
+
+net_equivalency(ison_southern_women)
+```
+
+```{r twomode-cohesion-solution}
+net_transitivity(women_graph)
+net_transitivity(event_graph)
+net_equivalency(ison_southern_women)
+```
+
+```{r equil-interp, echo=FALSE, purl = FALSE}
+question("What do we learn from this? Choose all that apply.",
+ answer("Transitivity in the women projection is very high.",
+ correct = TRUE),
+ answer("Transitivity in the event projection is very high.",
+ correct = TRUE),
+ answer("Equivalence for the two-mode Southern Women dataset is moderate.",
+ correct = TRUE,
+ message = '
'),
+ answer("Transitivity for the task network is -0.568",
+ message = "Transivitity must be between 0 and 1."),
+ answer("Transitivity is quite low in this network",
+ message = "Transitivity is often around 0.3 in most social networks."),
+ answer("Transitivity is quite high in this network",
+ correct = TRUE),
+ answer("Transitivity is likely higher in the task network than the friendship network",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Projection
+
+### A two-mode network
+
+The next dataset, 'ison_southern_women', is also available in `{manynet}`.
+It's a classic two-mode network about the attendance of 18 women
+at 14 social events in the 1930s American South.
+For more details see `?ison_southern_women` for documentation in your R/RStudio.
+Let's load and graph the data.
+
+```{r setup-women, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r setup-women-hint-1, purl = FALSE}
+# let's load the data and analyze it
+data("ison_southern_women")
+ison_southern_women
+```
+
+```{r setup-women-hint-2, purl = FALSE}
+graphr(ison_southern_women, node_color = "type")
+graphr(ison_southern_women, "railway", node_color = "type")
+```
+
+```{r setup-women-solution}
+data("ison_southern_women")
+ison_southern_women
+graphr(ison_southern_women, node_color = "type")
+```
+
+### Project two-mode network into two one-mode networks
+
+Now what if we are only interested in one part of the network?
+For that, we can obtain a 'projection' of the two-mode network.
+There are two ways of doing this.
+The hard way...
+
+```{r hardway, exercise=TRUE, exercise.setup = "setup-women", purl = FALSE}
+
+```
+
+```{r hardway-solution}
+twomode_matrix <- as_matrix(ison_southern_women)
+women_matrix <- twomode_matrix %*% t(twomode_matrix)
+event_matrix <- t(twomode_matrix) %*% twomode_matrix
+```
+
+Or the easy way:
+
+```{r easyway, exercise=TRUE, exercise.setup = "setup-women"}
+# women-graph
+# to_mode1(): Results in a weighted one-mode object that retains the row nodes from
+# a two-mode object, and weights the ties between them on the basis of their joint
+# ties to nodes in the second mode (columns)
+
+women_graph <- to_mode1(ison_southern_women)
+graphr(women_graph)
+
+# note that projection `to_mode1` involves keeping one type of nodes
+# this is different from to_uniplex above, which keeps one type of ties in the network
+
+# event-graph
+# to_mode2(): Results in a weighted one-mode object that retains the column nodes from
+# a two-mode object, and weights the ties between them on the basis of their joint ties
+# to nodes in the first mode (rows)
+
+event_graph <- to_mode2(ison_southern_women)
+graphr(event_graph)
+```
+
+### Projection options
+
+`{manynet}` also includes several other options for how to construct the projection.
+The default ("count") might be interpreted as indicating the degree or amount of
+shared ties to the other mode.
+"jaccard" divides this count by the number of nodes in the other mode
+to which either of the nodes are tied.
+It can thus be interpreted as opportunity weighted by participation.
+"rand" instead counts both shared ties and shared absences,
+and can thus be interpreted as the degree of behavioural mirroring between the
+nodes.
+Lastly, "pearson" (Pearson's coefficient) and "yule" (Yule's Q) produce
+correlations in ties for valued and binary data respectively.
+
+```{r otherway, exercise=TRUE, exercise.setup = "setup-women", purl = FALSE}
+
+```
+
+```{r otherway-solution}
+tie_weights(to_mode1(ison_southern_women, similarity = "count"))
+tie_weights(to_mode1(ison_southern_women, similarity = "jaccard"))
+tie_weights(to_mode1(ison_southern_women, similarity = "rand"))
+tie_weights(to_mode1(ison_southern_women, similarity = "pearson"))
+tie_weights(to_mode1(ison_southern_women, similarity = "yule"))
+```
+
+Practically speaking, most projection is conducted using the "count" method,
+as it reflects the absolute overlap, the frequency of co-occurrence.
+As such, it is most commonly used in social and organisational network analysis,
+reflecting shared group membership or collaboration intensity.
+But it is sensitive to asymmetries in the number of nodes in each node set and
+the degree distribution of each node set, and ignores the absence of ties as
+uninformative.
+To normalise for these effects, "jaccard" and "rand" are often used.
+"pearson" and "yule" are less commonly used, but can be useful when
+interested in the correlation of ties between nodes.
+
+### Closure in two-mode networks
+
+Let's return to the question of closure.
+First try one of the closure measures we have already treated that gives us
+a sense of shared partners for one-mode networks.
+Then compare this with `net_equivalency()`, which can be used on the original
+two-mode network.
+
+```{r twomode-cohesion, exercise=TRUE, exercise.setup = "easyway", purl = FALSE}
+
+```
+
+```{r twomode-cohesion-hint-1, purl = FALSE}
+# net_transitivity(): Calculate transitivity in a network
+
+net_transitivity(women_graph)
+net_transitivity(event_graph)
+```
+
+```{r twomode-cohesion-hint-2, purl = FALSE}
+# net_equivalency(): Calculate equivalence or reinforcement in a (usually two-mode) network
+
+net_equivalency(ison_southern_women)
+```
+
+```{r twomode-cohesion-solution}
+net_transitivity(women_graph)
+net_transitivity(event_graph)
+net_equivalency(ison_southern_women)
+```
+
+```{r equil-interp, echo=FALSE, purl = FALSE}
+question("What do we learn from this? Choose all that apply.",
+ answer("Transitivity in the women projection is very high.",
+ correct = TRUE),
+ answer("Transitivity in the event projection is very high.",
+ correct = TRUE),
+ answer("Equivalence for the two-mode Southern Women dataset is moderate.",
+ correct = TRUE,
+ message = ' '),
+ answer("Transitivity will often be very high in projected networks.",
+ correct = TRUE),
+ answer("Projection obscures which women are members of which events and vice versa.",
+ correct = TRUE),
+ # random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+Try to explain in no more than a paragraph why projection can lead to misleading transitivity measures and what some consequences of this might be.
+
+
+
+## Components
+
+Now let's look at the friendship network, 'friends'.
+We're interested here in how many
+`r gloss("components", "component")`
+there are.
+By default, the `net_components()` function will
+return the number of _strong_ components for directed networks.
+For _weak_ components, you will need to first make the network
+`r gloss("undirected")`.
+Remember the difference between weak and strong components?
+
+```{r weak-strong, echo = FALSE, purl = FALSE}
+question("Weak components...",
+ answer("don't care about tie direction when establishing components.",
+ correct = TRUE),
+ answer("care about tie direction when establishing components."),
+ allow_retry = TRUE
+)
+```
+
+```{r comp-no, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r comp-no-hint-1, purl = FALSE}
+net_components(friends)
+# note that friends is a directed network
+# you can see this by calling the object 'friends'
+# or by running `is_directed(friends)`
+```
+
+```{r comp-no-hint-2, purl = FALSE}
+# Now let's look at the number of components for objects connected by an undirected edge
+# Note: to_undirected() returns an object with all tie direction removed,
+# so any pair of nodes with at least one directed edge
+# will be connected by an undirected edge in the new network.
+net_components(to_undirected(friends))
+```
+
+```{r comp-no-solution}
+# note that friends is a directed network
+net_components(friends)
+net_components(to_undirected(friends))
+```
+
+```{r comp-interp, echo = FALSE, purl = FALSE}
+question("How many components are there?",
+ answer("2",
+ message = "There are more than 2 components."),
+ answer("3",
+ message = "There are 3 _weak_ components.",
+ correct = TRUE),
+ answer("4",
+ message = 'There are 4 _strong_ components.
'),
+ answer("Transitivity will often be very high in projected networks.",
+ correct = TRUE),
+ answer("Projection obscures which women are members of which events and vice versa.",
+ correct = TRUE),
+ # random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+Try to explain in no more than a paragraph why projection can lead to misleading transitivity measures and what some consequences of this might be.
+
+
+
+## Components
+
+Now let's look at the friendship network, 'friends'.
+We're interested here in how many
+`r gloss("components", "component")`
+there are.
+By default, the `net_components()` function will
+return the number of _strong_ components for directed networks.
+For _weak_ components, you will need to first make the network
+`r gloss("undirected")`.
+Remember the difference between weak and strong components?
+
+```{r weak-strong, echo = FALSE, purl = FALSE}
+question("Weak components...",
+ answer("don't care about tie direction when establishing components.",
+ correct = TRUE),
+ answer("care about tie direction when establishing components."),
+ allow_retry = TRUE
+)
+```
+
+```{r comp-no, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r comp-no-hint-1, purl = FALSE}
+net_components(friends)
+# note that friends is a directed network
+# you can see this by calling the object 'friends'
+# or by running `is_directed(friends)`
+```
+
+```{r comp-no-hint-2, purl = FALSE}
+# Now let's look at the number of components for objects connected by an undirected edge
+# Note: to_undirected() returns an object with all tie direction removed,
+# so any pair of nodes with at least one directed edge
+# will be connected by an undirected edge in the new network.
+net_components(to_undirected(friends))
+```
+
+```{r comp-no-solution}
+# note that friends is a directed network
+net_components(friends)
+net_components(to_undirected(friends))
+```
+
+```{r comp-interp, echo = FALSE, purl = FALSE}
+question("How many components are there?",
+ answer("2",
+ message = "There are more than 2 components."),
+ answer("3",
+ message = "There are 3 _weak_ components.",
+ correct = TRUE),
+ answer("4",
+ message = 'There are 4 _strong_ components.  ',
+ correct = TRUE),
+ answer("5",
+ message = "There are fewer than 5 components."),
+ allow_retry = TRUE
+)
+```
+
+So we know how many components there are,
+but maybe we're also interested in which nodes are members of which components?
+`node_components()` returns a membership vector
+that can be used to color nodes in `graphr()`:
+
+```{r comp-memb, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r comp-memb-hint-1, purl = FALSE}
+friends <- friends %>%
+ mutate(weak_comp = node_components(to_undirected(friends)),
+ strong_comp = node_components(friends))
+# node_components returns a vector of nodes' memberships to components in the network
+# here, we are adding the nodes' membership to components as an attribute in the network
+# alternatively, we can also use the function `add_node_attribute()`
+# eg. `add_node_attribute(friends, "weak_comp", node_components(to_undirected(friends)))`
+```
+
+```{r comp-memb-hint-2, purl = FALSE}
+graphr(friends, node_color = "weak_comp") + ggtitle("Weak components") +
+graphr(friends, node_color = "strong_comp") + ggtitle("Strong components")
+# by using the 'node_color' argument, we are telling graphr to colour
+# the nodes in the graph according to the values of the 'weak_comp' attribute in the network
+```
+
+```{r comp-memb-solution}
+friends <- friends %>%
+ mutate(weak_comp = node_components(to_undirected(friends)),
+ strong_comp = node_components(friends))
+graphr(friends, node_color = "weak_comp") + ggtitle("Weak components") +
+graphr(friends, node_color = "strong_comp") + ggtitle("Strong components")
+```
+
+```{r node-comp-interp, echo = FALSE, purl = FALSE}
+question("Why is there a difference between the weak and strong components results?",
+ answer("Because one node has only incoming ties.",
+ correct = TRUE),
+ answer("Because three nodes cannot reach any other nodes.",
+ correct = TRUE),
+ answer("Because there is an extra isolate."),
+ answer("Because the tie strength matters."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Factions
+
+Components offer a precise way of understanding groups in a network.
+However, they can also ignore some 'groupiness' that is obvious to even a
+cursory examination of the graph.
+The `irps_blogs` network concerns the url links between political blogs
+in the 2004 election.
+It is a big network (you can check below).
+In our experience, it can take a few seconds
+
+```{r blogsize, exercise = TRUE}
+# This is a large network
+net_nodes(irps_blogs)
+# Let's concentrate on just a sample of 240
+# (by deleting a random sample of 1250)
+blogs <- delete_nodes(irps_blogs, sample(1:1490, 1250))
+graphr(blogs)
+```
+
+But are they all actually linked?
+Even among the smaller sample, there seems to be a number of isolates.
+We can calculate the number of isolates by simply summing `node_is_isolate()`.
+
+```{r blogisolates, exercise = TRUE, exercise.setup = "blogsize"}
+sum(node_is_isolate(blogs))
+```
+
+Since there are many isolates, there will be many components,
+even if we look at weak components and not just strong components.
+
+```{r blogcomp, exercise = TRUE, exercise.setup = "blogsize"}
+net_components(blogs)
+net_components(to_undirected(blogs))
+```
+
+### Giant component
+
+So, it looks like most of the (weak) components are due to isolates!
+How do we concentrate on the main component of this network?
+Well, the main/largest component in a network is called the
+`r gloss("giant component", "giant")`.
+
+```{r blogtogiant, exercise=TRUE, warning=FALSE, fig.width=9, exercise.setup = "blogsize"}
+blogs <- blogs %>% to_giant()
+sum(node_is_isolate(blogs))
+graphr(blogs)
+```
+
+Finally, we have a single 'giant' component to examine.
+However, now we have a different kind of challenge:
+everything is one big hairball.
+And yet, if we think about what we might expect of the structure of a network
+of political blogs, we might not think it is so undifferentiated.
+We might hypothesise that, despite the _graphical_ presentation of a hairball,
+there is actually a reasonable partition of the network into two factions.
+
+### Finding a partition
+
+To find a partition in a network, we use the `node_in_partition()` function.
+All `node_in_*()` functions return a string vector the length of the number
+of nodes in the network.
+It is a string vector because this is how a categorical result is obtained.
+We can assign the result of this function to the nodes in the network
+(because it is the length of the nodes in the network),
+and graph the network using this result.
+
+```{r bloggraph, exercise=TRUE, exercise.setup = "blogtogiant", warning=FALSE, fig.width=9}
+blogs %>% mutate_nodes(part = node_in_partition()) %>%
+ graphr(node_color = "part")
+```
+
+We see from this graph that indeed there seems to be an obvious separation
+between the left and right 'hemispheres' of the network.
+
+## Modularity
+
+But what is the 'fit' of this assignment of the blog nodes into two partitions?
+The most common measure of the fit of a community assignment in a network is
+`r gloss("modularity")`.
+
+```{r blogmod, exercise=TRUE, exercise.setup = "blogtogiant"}
+net_modularity(blogs, membership = node_in_partition(blogs))
+```
+
+Remember that modularity ranges between 1 and -1.
+How can we interpret this result?
+
+```{r blogQ, echo = FALSE, purl = FALSE}
+question("Which statements about modularity are true?",
+ answer("A community assignment with modularity > 0 means there are more ties within communities than between communities.",
+ correct = TRUE),
+ answer("A community assignment with modularity = 0 means any tie is as likely to occur within a community as between assigned communities.",
+ correct = TRUE),
+ answer("In a community assignment with modularity = 1, every community must have an internal density of 1 and an external density of 0."),
+ answer("A community assignment with modularity = -1 is impossible."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+While the partition algorithm is useful for deriving a partition of the network
+into the number of factions assigned,
+it is still an algorithm that tries to maximise modularity.
+Other times we might instead have an empirically collected grouping,
+and we are keen to see how 'modular' the network is around this attribute.
+This only works on categorical attributes, of course,
+but is otherwise quite flexible.
+
+```{r blogmodassign, exercise=TRUE, exercise.setup = "blogtogiant", warning=FALSE, fig.width=9}
+graphr(blogs, node_color = "Leaning")
+net_modularity(blogs, membership = node_attribute(blogs, "Leaning"))
+```
+
+
',
+ correct = TRUE),
+ answer("5",
+ message = "There are fewer than 5 components."),
+ allow_retry = TRUE
+)
+```
+
+So we know how many components there are,
+but maybe we're also interested in which nodes are members of which components?
+`node_components()` returns a membership vector
+that can be used to color nodes in `graphr()`:
+
+```{r comp-memb, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r comp-memb-hint-1, purl = FALSE}
+friends <- friends %>%
+ mutate(weak_comp = node_components(to_undirected(friends)),
+ strong_comp = node_components(friends))
+# node_components returns a vector of nodes' memberships to components in the network
+# here, we are adding the nodes' membership to components as an attribute in the network
+# alternatively, we can also use the function `add_node_attribute()`
+# eg. `add_node_attribute(friends, "weak_comp", node_components(to_undirected(friends)))`
+```
+
+```{r comp-memb-hint-2, purl = FALSE}
+graphr(friends, node_color = "weak_comp") + ggtitle("Weak components") +
+graphr(friends, node_color = "strong_comp") + ggtitle("Strong components")
+# by using the 'node_color' argument, we are telling graphr to colour
+# the nodes in the graph according to the values of the 'weak_comp' attribute in the network
+```
+
+```{r comp-memb-solution}
+friends <- friends %>%
+ mutate(weak_comp = node_components(to_undirected(friends)),
+ strong_comp = node_components(friends))
+graphr(friends, node_color = "weak_comp") + ggtitle("Weak components") +
+graphr(friends, node_color = "strong_comp") + ggtitle("Strong components")
+```
+
+```{r node-comp-interp, echo = FALSE, purl = FALSE}
+question("Why is there a difference between the weak and strong components results?",
+ answer("Because one node has only incoming ties.",
+ correct = TRUE),
+ answer("Because three nodes cannot reach any other nodes.",
+ correct = TRUE),
+ answer("Because there is an extra isolate."),
+ answer("Because the tie strength matters."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Factions
+
+Components offer a precise way of understanding groups in a network.
+However, they can also ignore some 'groupiness' that is obvious to even a
+cursory examination of the graph.
+The `irps_blogs` network concerns the url links between political blogs
+in the 2004 election.
+It is a big network (you can check below).
+In our experience, it can take a few seconds
+
+```{r blogsize, exercise = TRUE}
+# This is a large network
+net_nodes(irps_blogs)
+# Let's concentrate on just a sample of 240
+# (by deleting a random sample of 1250)
+blogs <- delete_nodes(irps_blogs, sample(1:1490, 1250))
+graphr(blogs)
+```
+
+But are they all actually linked?
+Even among the smaller sample, there seems to be a number of isolates.
+We can calculate the number of isolates by simply summing `node_is_isolate()`.
+
+```{r blogisolates, exercise = TRUE, exercise.setup = "blogsize"}
+sum(node_is_isolate(blogs))
+```
+
+Since there are many isolates, there will be many components,
+even if we look at weak components and not just strong components.
+
+```{r blogcomp, exercise = TRUE, exercise.setup = "blogsize"}
+net_components(blogs)
+net_components(to_undirected(blogs))
+```
+
+### Giant component
+
+So, it looks like most of the (weak) components are due to isolates!
+How do we concentrate on the main component of this network?
+Well, the main/largest component in a network is called the
+`r gloss("giant component", "giant")`.
+
+```{r blogtogiant, exercise=TRUE, warning=FALSE, fig.width=9, exercise.setup = "blogsize"}
+blogs <- blogs %>% to_giant()
+sum(node_is_isolate(blogs))
+graphr(blogs)
+```
+
+Finally, we have a single 'giant' component to examine.
+However, now we have a different kind of challenge:
+everything is one big hairball.
+And yet, if we think about what we might expect of the structure of a network
+of political blogs, we might not think it is so undifferentiated.
+We might hypothesise that, despite the _graphical_ presentation of a hairball,
+there is actually a reasonable partition of the network into two factions.
+
+### Finding a partition
+
+To find a partition in a network, we use the `node_in_partition()` function.
+All `node_in_*()` functions return a string vector the length of the number
+of nodes in the network.
+It is a string vector because this is how a categorical result is obtained.
+We can assign the result of this function to the nodes in the network
+(because it is the length of the nodes in the network),
+and graph the network using this result.
+
+```{r bloggraph, exercise=TRUE, exercise.setup = "blogtogiant", warning=FALSE, fig.width=9}
+blogs %>% mutate_nodes(part = node_in_partition()) %>%
+ graphr(node_color = "part")
+```
+
+We see from this graph that indeed there seems to be an obvious separation
+between the left and right 'hemispheres' of the network.
+
+## Modularity
+
+But what is the 'fit' of this assignment of the blog nodes into two partitions?
+The most common measure of the fit of a community assignment in a network is
+`r gloss("modularity")`.
+
+```{r blogmod, exercise=TRUE, exercise.setup = "blogtogiant"}
+net_modularity(blogs, membership = node_in_partition(blogs))
+```
+
+Remember that modularity ranges between 1 and -1.
+How can we interpret this result?
+
+```{r blogQ, echo = FALSE, purl = FALSE}
+question("Which statements about modularity are true?",
+ answer("A community assignment with modularity > 0 means there are more ties within communities than between communities.",
+ correct = TRUE),
+ answer("A community assignment with modularity = 0 means any tie is as likely to occur within a community as between assigned communities.",
+ correct = TRUE),
+ answer("In a community assignment with modularity = 1, every community must have an internal density of 1 and an external density of 0."),
+ answer("A community assignment with modularity = -1 is impossible."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+While the partition algorithm is useful for deriving a partition of the network
+into the number of factions assigned,
+it is still an algorithm that tries to maximise modularity.
+Other times we might instead have an empirically collected grouping,
+and we are keen to see how 'modular' the network is around this attribute.
+This only works on categorical attributes, of course,
+but is otherwise quite flexible.
+
+```{r blogmodassign, exercise=TRUE, exercise.setup = "blogtogiant", warning=FALSE, fig.width=9}
+graphr(blogs, node_color = "Leaning")
+net_modularity(blogs, membership = node_attribute(blogs, "Leaning"))
+```
+
+ +
+How interesting.
+Perhaps the partitioning algorithm is not the algorithm that maximises
+modularity after all...
+Perhaps we need to look further and see whether there is another solution here
+that returns an even greater modularity criterion.
+
+## Communities
+
+Ok, the friendship network has 3-4 components, but how many 'groups' are there?
+Visually, it looks like there are two denser clusters within the main component.
+
+Today we'll use the 'friends' subgraph for exploring community detection methods.
+For clarity and simplicity,
+we will concentrate on the main component (the so-called 'giant' component)
+and consider friendship undirected.
+
+```{r manip-fri, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+# to_giant() returns an object that includes only the main component without any smaller components or isolates
+(friends <- to_giant(friends))
+(friends <- to_undirected(friends))
+graphr(friends)
+```
+
+Comparing `friends` before and after these operations,
+you'll notice the number of ties decreases as reciprocated directed ties
+are consolidated into single undirected ties,
+and the number of nodes decreases as two isolates are removed.
+
+There is no one single best community detection algorithm.
+Instead there are several, each with their strengths and weaknesses.
+Since this is a rather small network, we'll focus on the following methods:
+walktrap, edge betweenness, and fast greedy.
+(Others are included in `{manynet}`/`{igraph}`)
+As you use them, consider how they portray communities and consider which one(s)
+afford a sensible view of the social world as cohesively organized.
+
+### Walktrap
+
+This algorithm detects communities through a series of short random walks,
+with the idea that nodes encountered on any given random `r gloss("walk")`
+are more likely to be within a community than not.
+It was proposed by Pons and Latapy (2005).
+
+The algorithm initially treats all nodes as communities of their own, then
+merges them into larger communities, still larger communities, and so on.
+In each step a new community is created from two other communities,
+and its ID will be one larger than the largest community ID so far.
+This means that before the first merge we have n communities
+(the number of vertices in the graph) numbered from zero to n-1.
+The first merge creates community n, the second community n+1, etc.
+This merge history is returned by the function:
+` # ?igraph::cluster_walktrap`
+
+Note the "steps=" argument that specifies the length of the random walks.
+While `{igraph}` sets this to 4 by default,
+which is what is recommended by Pons and Latapy,
+Waugh et al (2009) found that for many groups (Congresses),
+these lengths did not provide the maximum modularity score.
+To be thorough in their attempts to optimize modularity, they ran the walktrap
+algorithm 50 times for each group (using random walks of lengths 1–50) and
+selected the network partition with the highest modularity value from those 50.
+They call this the "maximum modularity partition" and insert the parenthetical
+"(though, strictly speaking, this cannot be proven to be the optimum without
+computationally-prohibitive exhaustive enumeration (Brandes et al. 2008))."
+
+So let's try and get a community classification using the walktrap algorithm, `node_in_walktrap()`,
+with path lengths of the random walks specified to be 50.
+
+```{r walk, exercise=TRUE, exercise.setup = "separatingnets"}
+friend_wt <- node_in_walktrap(friends, times=50)
+```
+
+```{r walk-hint-1, purl = FALSE}
+friend_wt # note that it prints pretty, but underlying its just a vector:
+c(friend_wt)
+```
+
+```{r walk-hint-2, purl = FALSE}
+# This says that dividing the graph into 2 communities maximises modularity,
+# one with the nodes
+which(friend_wt == 1)
+# and the other
+which(friend_wt == 2)
+```
+
+```{r walk-hint-3, purl = FALSE}
+# resulting in a modularity of
+net_modularity(friends, friend_wt)
+```
+
+```{r walk-solution}
+friend_wt <- node_in_walktrap(friends, times=50)
+# results in a modularity of
+net_modularity(friends, friend_wt)
+```
+
+We can also visualise the clusters on the original network
+How does the following look? Plausible?
+
+```{r walkplot, exercise=TRUE, exercise.setup = "walk", purl = FALSE}
+```
+
+```{r walkplot-hint-1, purl = FALSE}
+# plot 1: groups by node color
+
+friends <- friends %>%
+ mutate(walk_comm = friend_wt)
+graphr(friends, node_color = "walk_comm")
+```
+
+```{r walkplot-hint-2, purl = FALSE}
+#plot 2: groups by borders
+
+# to be fancy, we could even draw the group borders around the nodes using the node_group argument
+graphr(friends, node_group = "walk_comm")
+```
+
+```{r walkplot-hint-3, purl = FALSE}
+# plot 3: group and node colors
+
+# or both!
+graphr(friends,
+ node_color = "walk_comm",
+ node_group = "walk_comm") +
+ ggtitle("Walktrap",
+ subtitle = round(net_modularity(friends, friend_wt), 3))
+# the function `round()` rounds the values to a specified number of decimal places
+# here, we are telling it to round the net_modularity score to 3 decimal places,
+# but the score is exactly 0.27 so only two decimal places are printed.
+```
+
+```{r walkplot-solution}
+friends <- friends %>%
+ mutate(walk_comm = friend_wt)
+graphr(friends, node_color = "walk_comm")
+# to be fancy, we could even draw the group borders around the nodes using the node_group argument
+graphr(friends, node_group = "walk_comm")
+# or both!
+graphr(friends,
+ node_color = "walk_comm",
+ node_group = "walk_comm") +
+ ggtitle("Walktrap",
+ subtitle = round(net_modularity(friends, friend_wt), 3))
+```
+
+This can be helpful when polygons overlap to better identify membership
+Or you can use node color and size to indicate other attributes...
+
+### Edge Betweenness
+
+Edge betweenness is like `r gloss("betweenness")` centrality but for ties not nodes.
+The edge-betweenness score of an edge measures the number of
+shortest paths from one vertex to another that go through it.
+
+The idea of the edge-betweenness based community structure detection is that
+it is likely that edges connecting separate clusters have high edge-betweenness,
+as all the shortest paths from one cluster to another must traverse through them.
+So if we iteratively remove the edge with the highest edge-betweenness score
+we will get a hierarchical map (`r gloss("dendrogram")`) of the communities in the graph.
+
+The following works similarly to walktrap, but no need to set a step length.
+
+```{r eb, exercise=TRUE, exercise.setup = "separatingnets"}
+friend_eb <- node_in_betweenness(friends)
+friend_eb
+```
+
+How does community membership differ here from that found by walktrap?
+
+We can see how the edge betweenness community detection method works
+here: http://jfaganuk.github.io/2015/01/24/basic-network-analysis/
+
+To visualise the result:
+
+```{r ebplot, exercise=TRUE, exercise.setup = "eb", purl = FALSE}
+
+```
+
+```{r ebplot-hint-1, purl = FALSE}
+# create an object
+
+friends <- friends %>%
+ mutate(eb_comm = friend_eb)
+```
+
+```{r ebplot-hint-2, purl = FALSE}
+# create a graph with a title and subtitle returning the modularity score
+
+graphr(friends,
+ node_color = "eb_comm",
+ node_group = "eb_comm") +
+ ggtitle("Edge-betweenness",
+ subtitle = round(net_modularity(friends, friend_eb), 3))
+```
+
+```{r ebplot-solution}
+friends <- friends %>%
+ mutate(eb_comm = friend_eb)
+graphr(friends,
+ node_color = "eb_comm",
+ node_group = "eb_comm") +
+ ggtitle("Edge-betweenness",
+ subtitle = round(net_modularity(friends, friend_eb), 3))
+```
+
+For more on this algorithm, see M Newman and M Girvan: Finding and
+evaluating community structure in networks, Physical Review E 69, 026113
+(2004), https://arxiv.org/abs/cond-mat/0308217.
+
+### Fast Greedy
+
+This algorithm is the Clauset-Newman-Moore algorithm.
+Whereas edge betweenness was `r gloss("divisive")` (top-down),
+the fast greedy algorithm is `r gloss("agglomerative")` (bottom-up).
+
+At each step, the algorithm seeks a merge that would most increase modularity.
+This is very fast, but has the disadvantage of being a greedy algorithm,
+so it might not produce the best overall community partitioning,
+although I personally find it both useful and in many cases quite "accurate".
+
+```{r fg, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r fg-hint-1, purl = FALSE}
+friend_fg <- node_in_greedy(friends)
+friend_fg # Does this result in a different community partition?
+net_modularity(friends, friend_fg) # Compare this to the edge betweenness procedure
+```
+
+```{r fg-hint-2, purl = FALSE}
+# Again, we can visualise these communities in different ways:
+friends <- friends %>%
+ mutate(fg_comm = friend_fg)
+graphr(friends,
+ node_color = "fg_comm",
+ node_group = "fg_comm") +
+ ggtitle("Fast-greedy",
+ subtitle = round(net_modularity(friends, friend_fg), 3))
+#
+```
+
+```{r fg-solution}
+friend_fg <- node_in_greedy(friends)
+friend_fg # Does this result in a different community partition?
+net_modularity(friends, friend_fg) # Compare this to the edge betweenness procedure
+
+# Again, we can visualise these communities in different ways:
+friends <- friends %>%
+ mutate(fg_comm = friend_fg)
+graphr(friends,
+ node_color = "fg_comm",
+ node_group = "fg_comm") +
+ ggtitle("Fast-greedy",
+ subtitle = round(net_modularity(friends, friend_fg), 3))
+```
+
+See A Clauset, MEJ Newman, C Moore:
+Finding community structure in very large networks,
+https://arxiv.org/abs/cond-mat/0408187
+
+```{r comm-comp, echo=FALSE, purl = FALSE}
+question("What is the difference between communities and components?",
+ answer("Communities and components are just different terms for the same thing"),
+ answer("Communities are a stricter form of component"),
+ answer("Components are about paths whereas communities are about the relationship between within-group and between-group ties",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+### Communities
+
+Lastly, `{manynet}` includes a function to run through and find the membership
+assignment that maximises `r gloss("modularity")` across any of the applicable community
+detection procedures.
+This is helpfully called `node_in_community()`.
+This function pays attention to the size and other salient network properties,
+such as whether it is directed, weighted, or connected.
+It either uses the algorithm that maximises modularity by default
+(`node_in_optimal()`) for smaller networks, or surveys the approximations
+provided by other algorithms for the result that maximises the modularity.
+
+```{r incomm, exercise = TRUE, exercise.setup = "separatingnets"}
+node_in_community(friends)
+```
+
+It is important to name _which_ algorithm produced the membership assignment
+that is then subsequently analysed though.
+
+```{r alg-comp, echo=FALSE, purl = FALSE}
+question("Which algorithm provides the 'best' membership assignment here?",
+ answer("Walktrap"),
+ answer("Edge betweenness"),
+ answer("Leiden"),
+ answer("Louvain"),
+ answer("Infomap"),
+ answer("Fluid"),
+ answer("Fast Greedy"),
+ answer("Eigenvector"),
+ answer("Spinglass"),
+ answer("Partition"),
+ answer("Optimal",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+## Free play
+
+
+
+How interesting.
+Perhaps the partitioning algorithm is not the algorithm that maximises
+modularity after all...
+Perhaps we need to look further and see whether there is another solution here
+that returns an even greater modularity criterion.
+
+## Communities
+
+Ok, the friendship network has 3-4 components, but how many 'groups' are there?
+Visually, it looks like there are two denser clusters within the main component.
+
+Today we'll use the 'friends' subgraph for exploring community detection methods.
+For clarity and simplicity,
+we will concentrate on the main component (the so-called 'giant' component)
+and consider friendship undirected.
+
+```{r manip-fri, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+# to_giant() returns an object that includes only the main component without any smaller components or isolates
+(friends <- to_giant(friends))
+(friends <- to_undirected(friends))
+graphr(friends)
+```
+
+Comparing `friends` before and after these operations,
+you'll notice the number of ties decreases as reciprocated directed ties
+are consolidated into single undirected ties,
+and the number of nodes decreases as two isolates are removed.
+
+There is no one single best community detection algorithm.
+Instead there are several, each with their strengths and weaknesses.
+Since this is a rather small network, we'll focus on the following methods:
+walktrap, edge betweenness, and fast greedy.
+(Others are included in `{manynet}`/`{igraph}`)
+As you use them, consider how they portray communities and consider which one(s)
+afford a sensible view of the social world as cohesively organized.
+
+### Walktrap
+
+This algorithm detects communities through a series of short random walks,
+with the idea that nodes encountered on any given random `r gloss("walk")`
+are more likely to be within a community than not.
+It was proposed by Pons and Latapy (2005).
+
+The algorithm initially treats all nodes as communities of their own, then
+merges them into larger communities, still larger communities, and so on.
+In each step a new community is created from two other communities,
+and its ID will be one larger than the largest community ID so far.
+This means that before the first merge we have n communities
+(the number of vertices in the graph) numbered from zero to n-1.
+The first merge creates community n, the second community n+1, etc.
+This merge history is returned by the function:
+` # ?igraph::cluster_walktrap`
+
+Note the "steps=" argument that specifies the length of the random walks.
+While `{igraph}` sets this to 4 by default,
+which is what is recommended by Pons and Latapy,
+Waugh et al (2009) found that for many groups (Congresses),
+these lengths did not provide the maximum modularity score.
+To be thorough in their attempts to optimize modularity, they ran the walktrap
+algorithm 50 times for each group (using random walks of lengths 1–50) and
+selected the network partition with the highest modularity value from those 50.
+They call this the "maximum modularity partition" and insert the parenthetical
+"(though, strictly speaking, this cannot be proven to be the optimum without
+computationally-prohibitive exhaustive enumeration (Brandes et al. 2008))."
+
+So let's try and get a community classification using the walktrap algorithm, `node_in_walktrap()`,
+with path lengths of the random walks specified to be 50.
+
+```{r walk, exercise=TRUE, exercise.setup = "separatingnets"}
+friend_wt <- node_in_walktrap(friends, times=50)
+```
+
+```{r walk-hint-1, purl = FALSE}
+friend_wt # note that it prints pretty, but underlying its just a vector:
+c(friend_wt)
+```
+
+```{r walk-hint-2, purl = FALSE}
+# This says that dividing the graph into 2 communities maximises modularity,
+# one with the nodes
+which(friend_wt == 1)
+# and the other
+which(friend_wt == 2)
+```
+
+```{r walk-hint-3, purl = FALSE}
+# resulting in a modularity of
+net_modularity(friends, friend_wt)
+```
+
+```{r walk-solution}
+friend_wt <- node_in_walktrap(friends, times=50)
+# results in a modularity of
+net_modularity(friends, friend_wt)
+```
+
+We can also visualise the clusters on the original network
+How does the following look? Plausible?
+
+```{r walkplot, exercise=TRUE, exercise.setup = "walk", purl = FALSE}
+```
+
+```{r walkplot-hint-1, purl = FALSE}
+# plot 1: groups by node color
+
+friends <- friends %>%
+ mutate(walk_comm = friend_wt)
+graphr(friends, node_color = "walk_comm")
+```
+
+```{r walkplot-hint-2, purl = FALSE}
+#plot 2: groups by borders
+
+# to be fancy, we could even draw the group borders around the nodes using the node_group argument
+graphr(friends, node_group = "walk_comm")
+```
+
+```{r walkplot-hint-3, purl = FALSE}
+# plot 3: group and node colors
+
+# or both!
+graphr(friends,
+ node_color = "walk_comm",
+ node_group = "walk_comm") +
+ ggtitle("Walktrap",
+ subtitle = round(net_modularity(friends, friend_wt), 3))
+# the function `round()` rounds the values to a specified number of decimal places
+# here, we are telling it to round the net_modularity score to 3 decimal places,
+# but the score is exactly 0.27 so only two decimal places are printed.
+```
+
+```{r walkplot-solution}
+friends <- friends %>%
+ mutate(walk_comm = friend_wt)
+graphr(friends, node_color = "walk_comm")
+# to be fancy, we could even draw the group borders around the nodes using the node_group argument
+graphr(friends, node_group = "walk_comm")
+# or both!
+graphr(friends,
+ node_color = "walk_comm",
+ node_group = "walk_comm") +
+ ggtitle("Walktrap",
+ subtitle = round(net_modularity(friends, friend_wt), 3))
+```
+
+This can be helpful when polygons overlap to better identify membership
+Or you can use node color and size to indicate other attributes...
+
+### Edge Betweenness
+
+Edge betweenness is like `r gloss("betweenness")` centrality but for ties not nodes.
+The edge-betweenness score of an edge measures the number of
+shortest paths from one vertex to another that go through it.
+
+The idea of the edge-betweenness based community structure detection is that
+it is likely that edges connecting separate clusters have high edge-betweenness,
+as all the shortest paths from one cluster to another must traverse through them.
+So if we iteratively remove the edge with the highest edge-betweenness score
+we will get a hierarchical map (`r gloss("dendrogram")`) of the communities in the graph.
+
+The following works similarly to walktrap, but no need to set a step length.
+
+```{r eb, exercise=TRUE, exercise.setup = "separatingnets"}
+friend_eb <- node_in_betweenness(friends)
+friend_eb
+```
+
+How does community membership differ here from that found by walktrap?
+
+We can see how the edge betweenness community detection method works
+here: http://jfaganuk.github.io/2015/01/24/basic-network-analysis/
+
+To visualise the result:
+
+```{r ebplot, exercise=TRUE, exercise.setup = "eb", purl = FALSE}
+
+```
+
+```{r ebplot-hint-1, purl = FALSE}
+# create an object
+
+friends <- friends %>%
+ mutate(eb_comm = friend_eb)
+```
+
+```{r ebplot-hint-2, purl = FALSE}
+# create a graph with a title and subtitle returning the modularity score
+
+graphr(friends,
+ node_color = "eb_comm",
+ node_group = "eb_comm") +
+ ggtitle("Edge-betweenness",
+ subtitle = round(net_modularity(friends, friend_eb), 3))
+```
+
+```{r ebplot-solution}
+friends <- friends %>%
+ mutate(eb_comm = friend_eb)
+graphr(friends,
+ node_color = "eb_comm",
+ node_group = "eb_comm") +
+ ggtitle("Edge-betweenness",
+ subtitle = round(net_modularity(friends, friend_eb), 3))
+```
+
+For more on this algorithm, see M Newman and M Girvan: Finding and
+evaluating community structure in networks, Physical Review E 69, 026113
+(2004), https://arxiv.org/abs/cond-mat/0308217.
+
+### Fast Greedy
+
+This algorithm is the Clauset-Newman-Moore algorithm.
+Whereas edge betweenness was `r gloss("divisive")` (top-down),
+the fast greedy algorithm is `r gloss("agglomerative")` (bottom-up).
+
+At each step, the algorithm seeks a merge that would most increase modularity.
+This is very fast, but has the disadvantage of being a greedy algorithm,
+so it might not produce the best overall community partitioning,
+although I personally find it both useful and in many cases quite "accurate".
+
+```{r fg, exercise=TRUE, exercise.setup = "separatingnets", purl = FALSE}
+
+```
+
+```{r fg-hint-1, purl = FALSE}
+friend_fg <- node_in_greedy(friends)
+friend_fg # Does this result in a different community partition?
+net_modularity(friends, friend_fg) # Compare this to the edge betweenness procedure
+```
+
+```{r fg-hint-2, purl = FALSE}
+# Again, we can visualise these communities in different ways:
+friends <- friends %>%
+ mutate(fg_comm = friend_fg)
+graphr(friends,
+ node_color = "fg_comm",
+ node_group = "fg_comm") +
+ ggtitle("Fast-greedy",
+ subtitle = round(net_modularity(friends, friend_fg), 3))
+#
+```
+
+```{r fg-solution}
+friend_fg <- node_in_greedy(friends)
+friend_fg # Does this result in a different community partition?
+net_modularity(friends, friend_fg) # Compare this to the edge betweenness procedure
+
+# Again, we can visualise these communities in different ways:
+friends <- friends %>%
+ mutate(fg_comm = friend_fg)
+graphr(friends,
+ node_color = "fg_comm",
+ node_group = "fg_comm") +
+ ggtitle("Fast-greedy",
+ subtitle = round(net_modularity(friends, friend_fg), 3))
+```
+
+See A Clauset, MEJ Newman, C Moore:
+Finding community structure in very large networks,
+https://arxiv.org/abs/cond-mat/0408187
+
+```{r comm-comp, echo=FALSE, purl = FALSE}
+question("What is the difference between communities and components?",
+ answer("Communities and components are just different terms for the same thing"),
+ answer("Communities are a stricter form of component"),
+ answer("Components are about paths whereas communities are about the relationship between within-group and between-group ties",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+### Communities
+
+Lastly, `{manynet}` includes a function to run through and find the membership
+assignment that maximises `r gloss("modularity")` across any of the applicable community
+detection procedures.
+This is helpfully called `node_in_community()`.
+This function pays attention to the size and other salient network properties,
+such as whether it is directed, weighted, or connected.
+It either uses the algorithm that maximises modularity by default
+(`node_in_optimal()`) for smaller networks, or surveys the approximations
+provided by other algorithms for the result that maximises the modularity.
+
+```{r incomm, exercise = TRUE, exercise.setup = "separatingnets"}
+node_in_community(friends)
+```
+
+It is important to name _which_ algorithm produced the membership assignment
+that is then subsequently analysed though.
+
+```{r alg-comp, echo=FALSE, purl = FALSE}
+question("Which algorithm provides the 'best' membership assignment here?",
+ answer("Walktrap"),
+ answer("Edge betweenness"),
+ answer("Leiden"),
+ answer("Louvain"),
+ answer("Infomap"),
+ answer("Fluid"),
+ answer("Fast Greedy"),
+ answer("Eigenvector"),
+ answer("Spinglass"),
+ answer("Partition"),
+ answer("Optimal",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+## Free play
+
+ +
+We've looked here at the `irps_blogs` dataset.
+Now have a go at the `irps_books` dataset.
+What is the density? Does it make sense to investigate reciprocity,
+transitivity, or equivalence? How can we interpret the results?
+How many components in the network? Is there a strong factional structure?
+Which community detection algorithm returns the highest modularity score,
+or corresponds best to what is in the data or what you see in the graph?
+
+```{r freeplay, exercise = TRUE, fig.width=9}
+irps_books
+```
+
+
+
+## Glossary
+
+
+
+We've looked here at the `irps_blogs` dataset.
+Now have a go at the `irps_books` dataset.
+What is the density? Does it make sense to investigate reciprocity,
+transitivity, or equivalence? How can we interpret the results?
+How many components in the network? Is there a strong factional structure?
+Which community detection algorithm returns the highest modularity score,
+or corresponds best to what is in the data or what you see in the graph?
+
+```{r freeplay, exercise = TRUE, fig.width=9}
+irps_books
+```
+
+
+
+## Glossary
+
+ +
+Here are some of the terms that we have covered in this module:
+
+`r print_glossary()`
diff --git a/inst/tutorials/tutorial4/community.html b/inst/tutorials/tutorial4/community.html
new file mode 100644
index 0000000..fda2a0e
--- /dev/null
+++ b/inst/tutorials/tutorial4/community.html
@@ -0,0 +1,3679 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+Here are some of the terms that we have covered in this module:
+
+`r print_glossary()`
diff --git a/inst/tutorials/tutorial4/community.html b/inst/tutorials/tutorial4/community.html
new file mode 100644
index 0000000..fda2a0e
--- /dev/null
+++ b/inst/tutorials/tutorial4/community.html
@@ -0,0 +1,3679 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ +
+For this session, we're going to use the "ison_algebra" dataset included in the `{manynet}` package.
+Do you remember how to call the data?
+Can you find out some more information about it via its help file?
+
+```{r data, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r data-hint-1, purl = FALSE}
+# Let's call and load the 'ison_algebra' dataset
+data("ison_algebra", package = "manynet")
+# Or you can retrieve like this:
+ison_algebra <- manynet::ison_algebra
+```
+
+```{r data-hint-2, purl = FALSE}
+# If you want to learn more about the 'ison_algebra' dataset, use the following function (below)
+?manynet::ison_algebra
+```
+
+```{r data-solution}
+data("ison_algebra", package = "manynet")
+?manynet::ison_algebra
+# If you want to see the network object, you can run the name of the object
+# ison_algebra
+# or print the code with brackets at the front and end of the code
+# (ison_algebra <- manynet::ison_algebra)
+```
+
+We can see that the dataset is multiplex,
+meaning that it contains several different types of ties:
+friendship (friends), social (social) and task interactions (tasks).
+
+### Separating multiplex networks
+
+As a `r gloss("multiplex")` network,
+there are actually three different types of ties in this network.
+We can extract them and investigate them separately using `to_uniplex()`.
+Within the parentheses, put the multiplex object's name,
+and then as a second argument put the name of the tie attribute in quotation marks.
+Once you have extracted all three networks,
+graph them and add a descriptive title.
+
+```{r separatingnets, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r separatingnets-hint-1, purl = FALSE}
+# Here's the basic idea/code syntax you will need to extract each type of network
+# You will want to replace
+____ <- to_uniplex(ison_algebra, _____)
+```
+
+```{r separatingnets-hint-4, purl = FALSE}
+graphr(friends) + ggtitle("Friendship")
+```
+
+```{r separatingnets-solution}
+friends <- to_uniplex(ison_algebra, "friends")
+graphr(friends) + ggtitle("Friendship")
+
+social <- to_uniplex(ison_algebra, "social")
+graphr(social) + ggtitle("Social")
+
+tasks <- to_uniplex(ison_algebra, "tasks")
+graphr(tasks) + ggtitle("Task")
+```
+
+Note also that these are `r gloss("weighted")` networks.
+`graphr()` automatically recognises these different weights and plots them.
+
+```{r strongties-qa, echo=FALSE, purl = FALSE}
+question("If we interpret ties with higher weights as strong ties, and lesser weights as weak ties, then, according to network theory, where would we expect novel information to come from?",
+ answer("Weak ties",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Strong ties",
+ message = learnr::random_encouragement()),
+ answer("Isolates",
+ message = learnr::random_encouragement()),
+ answer("Highest degree nodes",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Structural Holes
+
+Our first question for this network, is where innovation and creative ideas
+might be expected to appear.
+There are a number of theories that associate innovation or novelty with
+structural position.
+
+```{r structinnov-qa, echo=FALSE, purl = FALSE}
+question("Which network concepts are associated with innovation?",
+ answer("Structural holes",
+ correct = TRUE,
+ message = "Being positioned in a structural hole is said to be a brokerage position that brings with it information arbitrage possibilities."),
+ answer("Structural folds",
+ correct = TRUE,
+ message = "Being positioned in a structural fold, with in-group membership in multiple groups, can provide not only information arbitrage possibilities, but also the standing in the target group to introduce novelty successfully."),
+ answer("Structural balance",
+ message = learnr::random_encouragement()),
+ answer("Structural equivalence",
+ message = '
+
+For this session, we're going to use the "ison_algebra" dataset included in the `{manynet}` package.
+Do you remember how to call the data?
+Can you find out some more information about it via its help file?
+
+```{r data, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r data-hint-1, purl = FALSE}
+# Let's call and load the 'ison_algebra' dataset
+data("ison_algebra", package = "manynet")
+# Or you can retrieve like this:
+ison_algebra <- manynet::ison_algebra
+```
+
+```{r data-hint-2, purl = FALSE}
+# If you want to learn more about the 'ison_algebra' dataset, use the following function (below)
+?manynet::ison_algebra
+```
+
+```{r data-solution}
+data("ison_algebra", package = "manynet")
+?manynet::ison_algebra
+# If you want to see the network object, you can run the name of the object
+# ison_algebra
+# or print the code with brackets at the front and end of the code
+# (ison_algebra <- manynet::ison_algebra)
+```
+
+We can see that the dataset is multiplex,
+meaning that it contains several different types of ties:
+friendship (friends), social (social) and task interactions (tasks).
+
+### Separating multiplex networks
+
+As a `r gloss("multiplex")` network,
+there are actually three different types of ties in this network.
+We can extract them and investigate them separately using `to_uniplex()`.
+Within the parentheses, put the multiplex object's name,
+and then as a second argument put the name of the tie attribute in quotation marks.
+Once you have extracted all three networks,
+graph them and add a descriptive title.
+
+```{r separatingnets, exercise=TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r separatingnets-hint-1, purl = FALSE}
+# Here's the basic idea/code syntax you will need to extract each type of network
+# You will want to replace
+____ <- to_uniplex(ison_algebra, _____)
+```
+
+```{r separatingnets-hint-4, purl = FALSE}
+graphr(friends) + ggtitle("Friendship")
+```
+
+```{r separatingnets-solution}
+friends <- to_uniplex(ison_algebra, "friends")
+graphr(friends) + ggtitle("Friendship")
+
+social <- to_uniplex(ison_algebra, "social")
+graphr(social) + ggtitle("Social")
+
+tasks <- to_uniplex(ison_algebra, "tasks")
+graphr(tasks) + ggtitle("Task")
+```
+
+Note also that these are `r gloss("weighted")` networks.
+`graphr()` automatically recognises these different weights and plots them.
+
+```{r strongties-qa, echo=FALSE, purl = FALSE}
+question("If we interpret ties with higher weights as strong ties, and lesser weights as weak ties, then, according to network theory, where would we expect novel information to come from?",
+ answer("Weak ties",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Strong ties",
+ message = learnr::random_encouragement()),
+ answer("Isolates",
+ message = learnr::random_encouragement()),
+ answer("Highest degree nodes",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Structural Holes
+
+Our first question for this network, is where innovation and creative ideas
+might be expected to appear.
+There are a number of theories that associate innovation or novelty with
+structural position.
+
+```{r structinnov-qa, echo=FALSE, purl = FALSE}
+question("Which network concepts are associated with innovation?",
+ answer("Structural holes",
+ correct = TRUE,
+ message = "Being positioned in a structural hole is said to be a brokerage position that brings with it information arbitrage possibilities."),
+ answer("Structural folds",
+ correct = TRUE,
+ message = "Being positioned in a structural fold, with in-group membership in multiple groups, can provide not only information arbitrage possibilities, but also the standing in the target group to introduce novelty successfully."),
+ answer("Structural balance",
+ message = learnr::random_encouragement()),
+ answer("Structural equivalence",
+ message = ' '),
+ answer("Structuralism",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Measuring structural holes
+
+```{r shmeasures-qa, echo=FALSE, purl = FALSE}
+question("There are a number of measures that might be used to approximate the concept of structural holes. Select all that apply.",
+ answer("Constraint",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Effective size",
+ correct = TRUE),
+ answer("Bridges",
+ correct = TRUE),
+ answer("Redundancy",
+ correct = TRUE),
+ answer("Efficiency",
+ correct = TRUE),
+ answer("Hierarchy",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Bridges
+
+One common way of thinking about how innovations and ideas might flow across
+the network is to think about where the bottlenecks are.
+Ties that are the bottlenecks for information to flow from one part of the
+network to another are called `r gloss("bridges", "bridge")`.
+Remember, this means that only ties can be bridges,
+though a node-based measure that tracks the count of bridges to which a node
+is adjacent is available.
+Unfortunately, if we take a closer look at the friends network,
+there are no bridges.
+
+```{r bridges, exercise = TRUE, exercise.setup = "objects-setup"}
+sum(tie_is_bridge(friends))
+any(node_bridges(friends)>0)
+```
+
+### Constraint
+
+But some nodes do seem more deeply embedded in the network than others.
+Let's take a look at which actors are least `r gloss("constrained", "constraint")`
+by their position in the *task* network.
+`{manynet}` makes this easy enough with the `node_constraint()` function.
+
+```{r objects-setup, purl=FALSE}
+alge <- to_named(ison_algebra)
+friends <- to_uniplex(alge, "friends")
+social <- to_uniplex(alge, "social")
+tasks <- to_uniplex(alge, "tasks")
+```
+
+```{r constraint, exercise = TRUE, exercise.setup = "objects-setup", purl = FALSE}
+
+```
+
+```{r constraint-hint, purl = FALSE}
+node_constraint(____)
+# Don't forget we want to look at which actors are least constrained by their position in the 'tasks' network
+```
+
+```{r constraint-solution}
+node_constraint(tasks)
+```
+
+This function returns a vector of constraint scores that can range between 0 and 1.
+Let's graph the network again, sizing the nodes according to this score.
+We can also identify the node with the minimum constraint score using `node_is_min()`.
+
+```{r constraintplot, exercise=TRUE, exercise.setup = "objects-setup", purl = FALSE}
+
+```
+
+```{r constraintplot-hint-1, purl = FALSE}
+tasks <- tasks %>%
+ mutate(constraint = node_constraint(____),
+ low_constraint = node_is_min(node_constraint(____)))
+
+# Don't forget, we are still looking at the 'tasks' network
+```
+
+```{r constraintplot-hint-3, purl = FALSE}
+# Now, let's graph the network
+# Note 1: we are looking at the 'tasks' network
+# Note 2: we are interested in the actors 'least constrained' by their position
+
+graphr(____, node_color = "____")
+```
+
+```{r constraintplot-hint-4, purl = FALSE}
+graphr(tasks, node_size = "constraint", node_color = "low_constraint")
+```
+
+```{r constraintplot-solution}
+tasks <- tasks %>%
+ mutate(constraint = node_constraint(tasks),
+ low_constraint = node_is_min(node_constraint(tasks)))
+graphr(tasks, node_size = "constraint", node_color = "low_constraint")
+```
+
+Why minimum?
+Because constraint measures how well connected each node's partners are,
+with the implication that having few partners that are already connected to each
+other puts a node in an advantageous position to identify and
+share novel solutions to problems.
+So what can we learn from this plot
+about where innovation might occur within this network?
+
+```{r constraintQ, echo=FALSE, purl = FALSE}
+question("Do bridges innovate?",
+ answer("No",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Yes",
+ message = "Bridges can be important conduits for information, but ties do not typically have agency. Nodes do. Nodes in structural holes are called brokers. Nodes that are located in structural holes that would be there but for the node and their ties can be identified through various measures such as the number of bridges they are adjacent to, or their constraint score."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Structural Equivalence
+
+
'),
+ answer("Structuralism",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Measuring structural holes
+
+```{r shmeasures-qa, echo=FALSE, purl = FALSE}
+question("There are a number of measures that might be used to approximate the concept of structural holes. Select all that apply.",
+ answer("Constraint",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Effective size",
+ correct = TRUE),
+ answer("Bridges",
+ correct = TRUE),
+ answer("Redundancy",
+ correct = TRUE),
+ answer("Efficiency",
+ correct = TRUE),
+ answer("Hierarchy",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Bridges
+
+One common way of thinking about how innovations and ideas might flow across
+the network is to think about where the bottlenecks are.
+Ties that are the bottlenecks for information to flow from one part of the
+network to another are called `r gloss("bridges", "bridge")`.
+Remember, this means that only ties can be bridges,
+though a node-based measure that tracks the count of bridges to which a node
+is adjacent is available.
+Unfortunately, if we take a closer look at the friends network,
+there are no bridges.
+
+```{r bridges, exercise = TRUE, exercise.setup = "objects-setup"}
+sum(tie_is_bridge(friends))
+any(node_bridges(friends)>0)
+```
+
+### Constraint
+
+But some nodes do seem more deeply embedded in the network than others.
+Let's take a look at which actors are least `r gloss("constrained", "constraint")`
+by their position in the *task* network.
+`{manynet}` makes this easy enough with the `node_constraint()` function.
+
+```{r objects-setup, purl=FALSE}
+alge <- to_named(ison_algebra)
+friends <- to_uniplex(alge, "friends")
+social <- to_uniplex(alge, "social")
+tasks <- to_uniplex(alge, "tasks")
+```
+
+```{r constraint, exercise = TRUE, exercise.setup = "objects-setup", purl = FALSE}
+
+```
+
+```{r constraint-hint, purl = FALSE}
+node_constraint(____)
+# Don't forget we want to look at which actors are least constrained by their position in the 'tasks' network
+```
+
+```{r constraint-solution}
+node_constraint(tasks)
+```
+
+This function returns a vector of constraint scores that can range between 0 and 1.
+Let's graph the network again, sizing the nodes according to this score.
+We can also identify the node with the minimum constraint score using `node_is_min()`.
+
+```{r constraintplot, exercise=TRUE, exercise.setup = "objects-setup", purl = FALSE}
+
+```
+
+```{r constraintplot-hint-1, purl = FALSE}
+tasks <- tasks %>%
+ mutate(constraint = node_constraint(____),
+ low_constraint = node_is_min(node_constraint(____)))
+
+# Don't forget, we are still looking at the 'tasks' network
+```
+
+```{r constraintplot-hint-3, purl = FALSE}
+# Now, let's graph the network
+# Note 1: we are looking at the 'tasks' network
+# Note 2: we are interested in the actors 'least constrained' by their position
+
+graphr(____, node_color = "____")
+```
+
+```{r constraintplot-hint-4, purl = FALSE}
+graphr(tasks, node_size = "constraint", node_color = "low_constraint")
+```
+
+```{r constraintplot-solution}
+tasks <- tasks %>%
+ mutate(constraint = node_constraint(tasks),
+ low_constraint = node_is_min(node_constraint(tasks)))
+graphr(tasks, node_size = "constraint", node_color = "low_constraint")
+```
+
+Why minimum?
+Because constraint measures how well connected each node's partners are,
+with the implication that having few partners that are already connected to each
+other puts a node in an advantageous position to identify and
+share novel solutions to problems.
+So what can we learn from this plot
+about where innovation might occur within this network?
+
+```{r constraintQ, echo=FALSE, purl = FALSE}
+question("Do bridges innovate?",
+ answer("No",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Yes",
+ message = "Bridges can be important conduits for information, but ties do not typically have agency. Nodes do. Nodes in structural holes are called brokers. Nodes that are located in structural holes that would be there but for the node and their ties can be identified through various measures such as the number of bridges they are adjacent to, or their constraint score."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Structural Equivalence
+
+ +
+Next we might ask ourselves what (other) roles there are in the network?
+We want to know who plays what role in this algebra class.
+Let us begin with `r gloss("structural equivalence", "structeq")`.
+
+```{r equiv-qa, echo=FALSE, purl = FALSE}
+question("Structural equivalence means identifying classes of nodes with...",
+ answer("same/similar tie partners.",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("same/similar pattern of ties.",
+ message = "This is the definition for regular equivalence."),
+ answer("same/similar distance from all others.",
+ message = "This is the definition for automorphic equivalence."),
+ allow_retry = TRUE,
+ random_answer_order = TRUE
+)
+```
+
+We're going to identify structurally equivalent positions
+across all the data that we have, including 'task', 'social', and 'friend' ties.
+So that is, we are using the multiplex `ison_algebra` dataset again and not
+a uniplex subgraph thereof.
+
+### Finding structurally equivalent classes
+
+In `{manynet}`, finding how the nodes of a network can be partitioned
+into structurally equivalent classes can be as easy as:
+
+```{r find-se, exercise = TRUE, exercise.setup = "data"}
+node_in_structural(ison_algebra)
+
+ison_algebra %>%
+ mutate(se = node_in_structural(ison_algebra)) %>%
+ graphr(node_color = "se")
+```
+
+That is all.
+But actually, a lot is going on behind the scenes here that we can unpack.
+Understanding what is going on behind the scenes is important for understanding
+how these classes are identified and how to interpret them.
+
+### Step one: starting with a census
+
+All equivalence classes are based on nodes' similarity across some profile of motifs.
+In `{manynet}`, we call these motif *censuses*.
+Any kind of census can be used, and `{manynet}` includes a few options,
+but `node_in_structural()` is based off of the census of all the nodes' ties,
+both outgoing and incoming ties, to characterise their relationships to tie partners.
+
+```{r construct-cor, exercise = TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r construct-cor-hint-1, purl = FALSE}
+# Let's use the node_by_tie() function
+# The function accepts an object such as a dataset
+# Hint: Which dataset are we using in this tutorial?
+node_by_tie(____)
+```
+
+```{r construct-cor-hint-2, purl = FALSE}
+node_by_tie(ison_algebra)
+```
+
+```{r construct-cor-hint-3, purl = FALSE}
+# Now, let's get the dimensions of an object via the dim() function
+dim(node_by_tie(ison_algebra))
+```
+
+```{r construct-cor-solution}
+node_by_tie(ison_algebra)
+dim(node_by_tie(ison_algebra))
+```
+
+We can see that the result is a matrix of 16 rows and 96 columns,
+because we want to catalogue or take a census of all the different
+incoming/outgoing partners our 16 nodes might have across these three networks.
+Note also that the result is a weighted matrix;
+what would you do if you wanted it to be binary?
+
+```{r construct-binary, exercise = TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r construct-binary-hint, purl = FALSE}
+# we could convert the result using as.matrix, returning the ties
+as.matrix((node_by_tie(ison_algebra)>0)+0)
+
+```
+
+```{r construct-binary-solution}
+# But it's easier to simplify the network by removing the classification into different types of ties.
+# Note that this also reduces the total number of possible paths between nodes
+ison_algebra %>%
+ select_ties(-type) %>%
+ node_by_tie()
+```
+
+Note that `node_by_tie()` does not need to be passed to `node_in_structural()` ---
+this is done automatically!
+However, the more generic `node_in_equivalence()` is available and can be used
+with whichever census (`node_by_*()` output) is desired.
+Feel free to explore using some of the other censuses available in `{manynet}`,
+though some common ones are already used in the other equivalence convenience functions,
+e.g. `node_by_triad()` in `node_in_regular()`
+and `node_by_path()` in `node_in_automorphic()`.
+
+### Step two: growing a tree of similarity
+
+The next part takes this census and creates a `r gloss("dendrogram")` based on
+distance or dissimilarity among the nodes' census profiles.
+This is all done internally within e.g. `node_in_structural()`,
+though there are two important parameters that can be set to obtain different results.
+
+First, users can set the type of distance measure used.
+For enthusiasts, this is passed on to `stats::dist()`,
+so that help page should be consulted for more details.
+By default `"euclidean"` is used.
+
+Second, we can also set the type of clustering algorithm employed.
+By default, `{manynet}`'s equivalence functions use `r gloss("hierarchical clustering","hierclust")`, `"hier"`,
+but for compatibility and enthusiasts, we also offer `"concor"`,
+which implements a CONCOR (CONvergence of CORrelations) algorithm.
+
+We can see the difference from varying the clustering algorithm and/or distance
+by plotting the dendrograms (hidden) in the output from `node_in_structural()`:
+
+```{r varyclust, exercise = TRUE, exercise.setup = "data"}
+alge <- to_named(ison_algebra) # fake names to make comparison clearer
+plot(node_in_structural(alge, cluster = "hier", distance = "euclidean"))
+
+# changing the type of distance used
+plot(node_in_structural(alge, cluster = "hier", distance = "manhattan"))
+
+# changing the clustering algorithm
+plot(node_in_structural(alge, cluster = "concor", distance = "euclidean"))
+```
+
+```{r scale-interp, echo = FALSE, purl = FALSE}
+question("Do you see any differences?",
+ answer("Yes", correct = TRUE, message = learnr::random_praise()),
+ answer("No"),
+ allow_retry = TRUE)
+```
+
+So plotting a `membership` vector from `{manynet}` returns a dendrogram
+with the names of the nodes on the _y_-axis and the distance between them on the _x_-axis.
+Using the census as material, the distances between the nodes
+is used to create a dendrogram of (dis)similarity among the nodes.
+Basically, as we move to the right, we're allowing for
+more and more dissimilarity among those we cluster together.
+A fork or branching point indicates the level of dissimilarity
+at which those two or more nodes would be said to be equivalent.
+Where two nodes' branches join/fork represents the maximum distance among all their leaves,
+so more similar nodes' branches fork closer to the tree's canopy,
+and less similar (groups of) nodes don't join until they form basically the trunk.
+
+Note that with the results using the hierarchical clustering algorithm,
+the distance directly affects the structure of the tree (and the results).
+
+The CONCOR dendrogram operates a bit differently to hierarchical clustering though.
+Instead it represents how converging correlations repeatedly bifurcate
+the nodes into one of two partitions.
+As such the 'distance' is really just the (inverse) number of steps
+of bifurcations until nodes belong to the same class.
+
+### Step three: identifying the number of clusters
+
+Another bit of information represented in the dendrogram
+is where the tree should be cut (the dashed red line) and
+how the nodes are assigned to the branches (clusters) present at that cut-point.
+
+But where does this red line come from?
+Or, more technically, how do we identify the number of clusters
+into which to assign nodes?
+
+`{manynet}` includes several different ways of establishing `k`,
+or the number of clusters.
+Remember, the further to the right the red line is
+(the lower on the tree the cut point is)
+the more dissimilar we're allowing nodes in the same cluster to be.
+We could set this ourselves by just passing `k` an integer, say `k = 2`.
+What we are saying here is that we want to partition the nodes
+into two clusters, no matter how dissimilar they are.
+
+```{r k-discrete, exercise = TRUE, exercise.setup = "varyclust"}
+plot(node_in_structural(alge, k = 2))
+```
+
+But we're really just guessing. Maybe 2 is not the best `k`?
+To establish what the best `k` is for this clustering exercise,
+we need to iterate through a number of potential `k`
+and consider their fitness by some metric.
+There are a couple of options here.
+
+One is to consider, for each `k`,
+how correlated this partition is with the observed network.
+When there is one cluster for each vertex in the network,
+cell values will be identical to the observed correlation matrix,
+and when there is one cluster for the whole network,
+the values will all be equal to the average correlation
+across the observed matrix.
+So the correlations in each by-cluster matrix are correlated with the observed
+correlation matrix to see how well each by-cluster matrix fits the data.
+
+Of course, the perfect partition would then be
+where all nodes are in their own cluster,
+which is hardly 'clustering' at all.
+Also, increasing `k` will always improve the correlation.
+But if one were to plot these correlations as a line graph,
+then we might expect there to be a relatively rapid increase
+in correlation as we move from, for example, 3 clusters to 4 clusters,
+but a relatively small increase from, for example, 13 clusters to 14 clusters.
+By identifying the inflection point in this line graph,
+`{manynet}` selects a number of clusters that represents a trade-off
+between fit and parsimony.
+This is the `k = "elbow"` method.
+
+The other option is to evaluate a candidate for `k` based
+not on correlation but on a metric of
+how similar each node in a cluster is to others in its cluster
+_and_ how dissimilar each node is to those in a neighbouring cluster.
+When averaged over all nodes and all clusters,
+this provides a 'silhouette coefficient' for a candidate of `k`.
+Choosing the number of clusters that maximizes this coefficient,
+which is what `k = "silhouette"` does,
+can return a somewhat different result to the elbow method.
+See what we have here, with all other arguments held the same:
+
+```{r elbowsil, exercise = TRUE, exercise.setup = "varyclust"}
+plot(node_in_structural(alge, k = "elbow"))
+plot(node_in_structural(alge, k = "silhouette"))
+```
+
+Ok, so it looks like the elbow method returns `k == 3` as a good trade-off
+between fit and parsimony.
+The silhouette method, by contrast, sees `k == 4` as maximising cluster
+similarity and dissimilarity.
+Either is probably fine here,
+and there is much debate around how to select the number of clusters anyway.
+However, the silhouette method seems to do a better job of identifying
+how unique the 16th node is.
+The silhouette method is also the default in `{manynet}`.
+
+Note that there is a somewhat hidden parameter here, `range`.
+Since testing across all possible numbers of clusters can get
+computationally expensive (not to mention uninterpretable) for large networks,
+`{manynet}` only considers up to 8 clusters by default.
+This however can be modified to be higher or lower, e.g. `range = 16`.
+
+Finally, one last option is `k = "strict"`,
+which only assigns nodes to the same partition
+if there is zero distance between them.
+This is quick and rigorous solution,
+however oftentimes this misses the point in finding clusters of nodes that,
+despite some variation, can be considered as similar on some dimension.
+
+```{r strict, exercise = TRUE, exercise.setup = "varyclust"}
+plot(node_in_structural(alge, k = "strict"))
+```
+
+Here for example, no two nodes have precisely the same tie-profile,
+otherwise their branches would join/fork at a distance of 0.
+As such, `k = "strict"` partitions the network into 16 clusters.
+Where networks have a number of nodes with strictly the same profiles,
+such a k-selection method might be helpful to recognise nodes in exactly
+the same structural position,
+but here it essentially just reports nodes' identity.
+
+## Blockmodelling
+
+
+
+Next we might ask ourselves what (other) roles there are in the network?
+We want to know who plays what role in this algebra class.
+Let us begin with `r gloss("structural equivalence", "structeq")`.
+
+```{r equiv-qa, echo=FALSE, purl = FALSE}
+question("Structural equivalence means identifying classes of nodes with...",
+ answer("same/similar tie partners.",
+ correct = TRUE,
+ message = learnr::random_praise()),
+ answer("same/similar pattern of ties.",
+ message = "This is the definition for regular equivalence."),
+ answer("same/similar distance from all others.",
+ message = "This is the definition for automorphic equivalence."),
+ allow_retry = TRUE,
+ random_answer_order = TRUE
+)
+```
+
+We're going to identify structurally equivalent positions
+across all the data that we have, including 'task', 'social', and 'friend' ties.
+So that is, we are using the multiplex `ison_algebra` dataset again and not
+a uniplex subgraph thereof.
+
+### Finding structurally equivalent classes
+
+In `{manynet}`, finding how the nodes of a network can be partitioned
+into structurally equivalent classes can be as easy as:
+
+```{r find-se, exercise = TRUE, exercise.setup = "data"}
+node_in_structural(ison_algebra)
+
+ison_algebra %>%
+ mutate(se = node_in_structural(ison_algebra)) %>%
+ graphr(node_color = "se")
+```
+
+That is all.
+But actually, a lot is going on behind the scenes here that we can unpack.
+Understanding what is going on behind the scenes is important for understanding
+how these classes are identified and how to interpret them.
+
+### Step one: starting with a census
+
+All equivalence classes are based on nodes' similarity across some profile of motifs.
+In `{manynet}`, we call these motif *censuses*.
+Any kind of census can be used, and `{manynet}` includes a few options,
+but `node_in_structural()` is based off of the census of all the nodes' ties,
+both outgoing and incoming ties, to characterise their relationships to tie partners.
+
+```{r construct-cor, exercise = TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r construct-cor-hint-1, purl = FALSE}
+# Let's use the node_by_tie() function
+# The function accepts an object such as a dataset
+# Hint: Which dataset are we using in this tutorial?
+node_by_tie(____)
+```
+
+```{r construct-cor-hint-2, purl = FALSE}
+node_by_tie(ison_algebra)
+```
+
+```{r construct-cor-hint-3, purl = FALSE}
+# Now, let's get the dimensions of an object via the dim() function
+dim(node_by_tie(ison_algebra))
+```
+
+```{r construct-cor-solution}
+node_by_tie(ison_algebra)
+dim(node_by_tie(ison_algebra))
+```
+
+We can see that the result is a matrix of 16 rows and 96 columns,
+because we want to catalogue or take a census of all the different
+incoming/outgoing partners our 16 nodes might have across these three networks.
+Note also that the result is a weighted matrix;
+what would you do if you wanted it to be binary?
+
+```{r construct-binary, exercise = TRUE, exercise.setup = "data", purl = FALSE}
+
+```
+
+```{r construct-binary-hint, purl = FALSE}
+# we could convert the result using as.matrix, returning the ties
+as.matrix((node_by_tie(ison_algebra)>0)+0)
+
+```
+
+```{r construct-binary-solution}
+# But it's easier to simplify the network by removing the classification into different types of ties.
+# Note that this also reduces the total number of possible paths between nodes
+ison_algebra %>%
+ select_ties(-type) %>%
+ node_by_tie()
+```
+
+Note that `node_by_tie()` does not need to be passed to `node_in_structural()` ---
+this is done automatically!
+However, the more generic `node_in_equivalence()` is available and can be used
+with whichever census (`node_by_*()` output) is desired.
+Feel free to explore using some of the other censuses available in `{manynet}`,
+though some common ones are already used in the other equivalence convenience functions,
+e.g. `node_by_triad()` in `node_in_regular()`
+and `node_by_path()` in `node_in_automorphic()`.
+
+### Step two: growing a tree of similarity
+
+The next part takes this census and creates a `r gloss("dendrogram")` based on
+distance or dissimilarity among the nodes' census profiles.
+This is all done internally within e.g. `node_in_structural()`,
+though there are two important parameters that can be set to obtain different results.
+
+First, users can set the type of distance measure used.
+For enthusiasts, this is passed on to `stats::dist()`,
+so that help page should be consulted for more details.
+By default `"euclidean"` is used.
+
+Second, we can also set the type of clustering algorithm employed.
+By default, `{manynet}`'s equivalence functions use `r gloss("hierarchical clustering","hierclust")`, `"hier"`,
+but for compatibility and enthusiasts, we also offer `"concor"`,
+which implements a CONCOR (CONvergence of CORrelations) algorithm.
+
+We can see the difference from varying the clustering algorithm and/or distance
+by plotting the dendrograms (hidden) in the output from `node_in_structural()`:
+
+```{r varyclust, exercise = TRUE, exercise.setup = "data"}
+alge <- to_named(ison_algebra) # fake names to make comparison clearer
+plot(node_in_structural(alge, cluster = "hier", distance = "euclidean"))
+
+# changing the type of distance used
+plot(node_in_structural(alge, cluster = "hier", distance = "manhattan"))
+
+# changing the clustering algorithm
+plot(node_in_structural(alge, cluster = "concor", distance = "euclidean"))
+```
+
+```{r scale-interp, echo = FALSE, purl = FALSE}
+question("Do you see any differences?",
+ answer("Yes", correct = TRUE, message = learnr::random_praise()),
+ answer("No"),
+ allow_retry = TRUE)
+```
+
+So plotting a `membership` vector from `{manynet}` returns a dendrogram
+with the names of the nodes on the _y_-axis and the distance between them on the _x_-axis.
+Using the census as material, the distances between the nodes
+is used to create a dendrogram of (dis)similarity among the nodes.
+Basically, as we move to the right, we're allowing for
+more and more dissimilarity among those we cluster together.
+A fork or branching point indicates the level of dissimilarity
+at which those two or more nodes would be said to be equivalent.
+Where two nodes' branches join/fork represents the maximum distance among all their leaves,
+so more similar nodes' branches fork closer to the tree's canopy,
+and less similar (groups of) nodes don't join until they form basically the trunk.
+
+Note that with the results using the hierarchical clustering algorithm,
+the distance directly affects the structure of the tree (and the results).
+
+The CONCOR dendrogram operates a bit differently to hierarchical clustering though.
+Instead it represents how converging correlations repeatedly bifurcate
+the nodes into one of two partitions.
+As such the 'distance' is really just the (inverse) number of steps
+of bifurcations until nodes belong to the same class.
+
+### Step three: identifying the number of clusters
+
+Another bit of information represented in the dendrogram
+is where the tree should be cut (the dashed red line) and
+how the nodes are assigned to the branches (clusters) present at that cut-point.
+
+But where does this red line come from?
+Or, more technically, how do we identify the number of clusters
+into which to assign nodes?
+
+`{manynet}` includes several different ways of establishing `k`,
+or the number of clusters.
+Remember, the further to the right the red line is
+(the lower on the tree the cut point is)
+the more dissimilar we're allowing nodes in the same cluster to be.
+We could set this ourselves by just passing `k` an integer, say `k = 2`.
+What we are saying here is that we want to partition the nodes
+into two clusters, no matter how dissimilar they are.
+
+```{r k-discrete, exercise = TRUE, exercise.setup = "varyclust"}
+plot(node_in_structural(alge, k = 2))
+```
+
+But we're really just guessing. Maybe 2 is not the best `k`?
+To establish what the best `k` is for this clustering exercise,
+we need to iterate through a number of potential `k`
+and consider their fitness by some metric.
+There are a couple of options here.
+
+One is to consider, for each `k`,
+how correlated this partition is with the observed network.
+When there is one cluster for each vertex in the network,
+cell values will be identical to the observed correlation matrix,
+and when there is one cluster for the whole network,
+the values will all be equal to the average correlation
+across the observed matrix.
+So the correlations in each by-cluster matrix are correlated with the observed
+correlation matrix to see how well each by-cluster matrix fits the data.
+
+Of course, the perfect partition would then be
+where all nodes are in their own cluster,
+which is hardly 'clustering' at all.
+Also, increasing `k` will always improve the correlation.
+But if one were to plot these correlations as a line graph,
+then we might expect there to be a relatively rapid increase
+in correlation as we move from, for example, 3 clusters to 4 clusters,
+but a relatively small increase from, for example, 13 clusters to 14 clusters.
+By identifying the inflection point in this line graph,
+`{manynet}` selects a number of clusters that represents a trade-off
+between fit and parsimony.
+This is the `k = "elbow"` method.
+
+The other option is to evaluate a candidate for `k` based
+not on correlation but on a metric of
+how similar each node in a cluster is to others in its cluster
+_and_ how dissimilar each node is to those in a neighbouring cluster.
+When averaged over all nodes and all clusters,
+this provides a 'silhouette coefficient' for a candidate of `k`.
+Choosing the number of clusters that maximizes this coefficient,
+which is what `k = "silhouette"` does,
+can return a somewhat different result to the elbow method.
+See what we have here, with all other arguments held the same:
+
+```{r elbowsil, exercise = TRUE, exercise.setup = "varyclust"}
+plot(node_in_structural(alge, k = "elbow"))
+plot(node_in_structural(alge, k = "silhouette"))
+```
+
+Ok, so it looks like the elbow method returns `k == 3` as a good trade-off
+between fit and parsimony.
+The silhouette method, by contrast, sees `k == 4` as maximising cluster
+similarity and dissimilarity.
+Either is probably fine here,
+and there is much debate around how to select the number of clusters anyway.
+However, the silhouette method seems to do a better job of identifying
+how unique the 16th node is.
+The silhouette method is also the default in `{manynet}`.
+
+Note that there is a somewhat hidden parameter here, `range`.
+Since testing across all possible numbers of clusters can get
+computationally expensive (not to mention uninterpretable) for large networks,
+`{manynet}` only considers up to 8 clusters by default.
+This however can be modified to be higher or lower, e.g. `range = 16`.
+
+Finally, one last option is `k = "strict"`,
+which only assigns nodes to the same partition
+if there is zero distance between them.
+This is quick and rigorous solution,
+however oftentimes this misses the point in finding clusters of nodes that,
+despite some variation, can be considered as similar on some dimension.
+
+```{r strict, exercise = TRUE, exercise.setup = "varyclust"}
+plot(node_in_structural(alge, k = "strict"))
+```
+
+Here for example, no two nodes have precisely the same tie-profile,
+otherwise their branches would join/fork at a distance of 0.
+As such, `k = "strict"` partitions the network into 16 clusters.
+Where networks have a number of nodes with strictly the same profiles,
+such a k-selection method might be helpful to recognise nodes in exactly
+the same structural position,
+but here it essentially just reports nodes' identity.
+
+## Blockmodelling
+
+ +
+### Summarising profiles
+
+Ok, so now we have a result from establishing nodes' membership in
+structurally equivalent classes.
+We can graph this of course, as above:
+
+```{r strplot, exercise = TRUE, exercise.setup = "varyclust"}
+alge %>%
+ mutate(se = node_in_structural(alge)) %>%
+ graphr(node_color = "se")
+```
+
+While this plot adds the structurally equivalent classes information to our
+earlier graph, it doesn't really help us understand how the classes relate.
+That is, we might be less interested in how the individuals in the different
+classes relate, and more interested in how the different classes relate in aggregate.
+
+
+
+### Summarising profiles
+
+Ok, so now we have a result from establishing nodes' membership in
+structurally equivalent classes.
+We can graph this of course, as above:
+
+```{r strplot, exercise = TRUE, exercise.setup = "varyclust"}
+alge %>%
+ mutate(se = node_in_structural(alge)) %>%
+ graphr(node_color = "se")
+```
+
+While this plot adds the structurally equivalent classes information to our
+earlier graph, it doesn't really help us understand how the classes relate.
+That is, we might be less interested in how the individuals in the different
+classes relate, and more interested in how the different classes relate in aggregate.
+
+ +
+One option that can be useful for characterising what
+the profile of ties (partners) is for each position/equivalence class
+is to use `summary()`.
+It summarises some census result by a partition (equivalence/membership) assignment.
+By default it takes the average of ties (values),
+but this can be tweaked by assigning some other summary statistic as `FUN = `.
+
+```{r summ, exercise = TRUE, exercise.setup = "strplot", purl = FALSE}
+
+```
+
+```{r summ-hint, purl = FALSE}
+# Let's wrap node_by_tie inside the summary() function
+# and pass it a membership result
+summary(node_by_tie(____),
+ membership = ____)
+```
+
+```{r summ-solution}
+summary(node_by_tie(alge),
+ membership = node_in_structural(alge))
+```
+
+This node census produces 96 columns,
+$16 \text{nodes} * 2 \text{directions} * 3 \text{edge types}$,
+it takes a bit to look through what varies between the different classes
+as 'blocked'.
+But only four rows (the four structurally equivalent classes, according to the default).
+
+Another way to do this is to plot the `gloss("blockmodel")` as a whole.
+Passing the `plot()` function an adjacency/incidence matrix
+along with a membership vector allows the matrix to be sorted and framed
+(without the membership vector, just the adjacency/incidence matrix is plotted):
+
+```{r block, exercise = TRUE, exercise.setup = "strplot", purl = FALSE}
+
+```
+
+```{r block-hint, purl = FALSE}
+# Let's plot the blockmodel using the plot() function we used for the dendrograms
+# Instead of node_tie_census() let's us as_matrix()
+
+plot(as_matrix(____),
+ membership = ____)
+```
+
+```{r block-solution}
+# plot the blockmodel for the whole network
+plot(as_matrix(alge),
+ membership = node_in_structural(alge))
+
+# plot the blockmodel for the friends, tasks, and social networks separately
+plot(as_matrix(to_uniplex(alge, "friends")),
+ membership = node_in_structural(alge))
+plot(as_matrix(to_uniplex(alge, "tasks")),
+ membership = node_in_structural(alge))
+plot(as_matrix(to_uniplex(alge, "social")),
+ membership = node_in_structural(alge))
+```
+
+By passing the membership argument our structural equivalence results,
+the matrix is re-sorted to cluster or 'block' nodes from the same class together.
+This can help us interpret the general relationships between classes.
+For example, when we plot the friends, tasks, and social networks using the structural equivalence results,
+we might characterise them like so:
+
+- The first group (of 6) are a bit of a mix: there seem to be two popular friends,
+one that strongly reciprocates and the other that nominates no friendships but
+seems to nominate others in the group as social contacts instead.
+The first group rely heavily on the nerd for advice.
+- The second group (of 5) seem to be strongly reciprocal in friendship and
+social together, lightly advise each other but mostly go to the nerd for advice.
+- The third group (of 4) are also strongly reciprocal in friendship,
+but also sometimes nominate some in groups one and two as friends too.
+There is at least a pair that often hang out together socially,
+but this group do not hang out with the nerd much nor ask them for advice
+as much as members of the other groups.
+- The nerd is a loner, no friends,
+but everyone hangs out with them for task advice.
+
+## Reduced graphs
+
+Lastly, we can consider how _classes_ of nodes relate to one another in a blockmodel.
+Let's use the 4-cluster solution on the valued network (though binary is possible too)
+to create a `r gloss("reduced graph","reduced")`.
+A reduced graph is a transformation of a network such that
+the nodes are no longer the individual nodes but the groups of one or more nodes as a class,
+and the ties between these blocked nodes can represent the sum or average tie between these classes.
+Of course, this means that there can be self-ties or loops,
+because even if the original network was simple (not `r gloss("complex")`),
+any within-class ties will end up becoming loops and thus the network will be complex.
+
+```{r structblock, exercise = TRUE, exercise.setup = "varyclust", warning=FALSE}
+(bm <- to_blocks(alge, node_in_structural(alge)))
+
+bm <- bm %>% as_tidygraph %>%
+ mutate(name = c("Freaks", "Squares", "Nerds", "Geek"))
+graphr(bm)
+```
+
+## Free play
+
+Now try to find the regularly equivalent classes in the `ison_lawfirm` dataset.
+As this is a multiplex network, you can make this a uniplex network first.
+
+```{r freeplay, exercise = TRUE}
+
+```
+
+An extension can be to also explore `r gloss("regularly equivalent","regulareq")`
+or `r gloss("automorphically equivalent","automorphiceq")` classes.
+
+## Glossary
+
+Here are some of the terms that we have covered in this module:
+
+`r print_glossary()`
+
+
diff --git a/inst/tutorials/tutorial5/position.html b/inst/tutorials/tutorial5/position.html
new file mode 100644
index 0000000..54a6232
--- /dev/null
+++ b/inst/tutorials/tutorial5/position.html
@@ -0,0 +1,2274 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+One option that can be useful for characterising what
+the profile of ties (partners) is for each position/equivalence class
+is to use `summary()`.
+It summarises some census result by a partition (equivalence/membership) assignment.
+By default it takes the average of ties (values),
+but this can be tweaked by assigning some other summary statistic as `FUN = `.
+
+```{r summ, exercise = TRUE, exercise.setup = "strplot", purl = FALSE}
+
+```
+
+```{r summ-hint, purl = FALSE}
+# Let's wrap node_by_tie inside the summary() function
+# and pass it a membership result
+summary(node_by_tie(____),
+ membership = ____)
+```
+
+```{r summ-solution}
+summary(node_by_tie(alge),
+ membership = node_in_structural(alge))
+```
+
+This node census produces 96 columns,
+$16 \text{nodes} * 2 \text{directions} * 3 \text{edge types}$,
+it takes a bit to look through what varies between the different classes
+as 'blocked'.
+But only four rows (the four structurally equivalent classes, according to the default).
+
+Another way to do this is to plot the `gloss("blockmodel")` as a whole.
+Passing the `plot()` function an adjacency/incidence matrix
+along with a membership vector allows the matrix to be sorted and framed
+(without the membership vector, just the adjacency/incidence matrix is plotted):
+
+```{r block, exercise = TRUE, exercise.setup = "strplot", purl = FALSE}
+
+```
+
+```{r block-hint, purl = FALSE}
+# Let's plot the blockmodel using the plot() function we used for the dendrograms
+# Instead of node_tie_census() let's us as_matrix()
+
+plot(as_matrix(____),
+ membership = ____)
+```
+
+```{r block-solution}
+# plot the blockmodel for the whole network
+plot(as_matrix(alge),
+ membership = node_in_structural(alge))
+
+# plot the blockmodel for the friends, tasks, and social networks separately
+plot(as_matrix(to_uniplex(alge, "friends")),
+ membership = node_in_structural(alge))
+plot(as_matrix(to_uniplex(alge, "tasks")),
+ membership = node_in_structural(alge))
+plot(as_matrix(to_uniplex(alge, "social")),
+ membership = node_in_structural(alge))
+```
+
+By passing the membership argument our structural equivalence results,
+the matrix is re-sorted to cluster or 'block' nodes from the same class together.
+This can help us interpret the general relationships between classes.
+For example, when we plot the friends, tasks, and social networks using the structural equivalence results,
+we might characterise them like so:
+
+- The first group (of 6) are a bit of a mix: there seem to be two popular friends,
+one that strongly reciprocates and the other that nominates no friendships but
+seems to nominate others in the group as social contacts instead.
+The first group rely heavily on the nerd for advice.
+- The second group (of 5) seem to be strongly reciprocal in friendship and
+social together, lightly advise each other but mostly go to the nerd for advice.
+- The third group (of 4) are also strongly reciprocal in friendship,
+but also sometimes nominate some in groups one and two as friends too.
+There is at least a pair that often hang out together socially,
+but this group do not hang out with the nerd much nor ask them for advice
+as much as members of the other groups.
+- The nerd is a loner, no friends,
+but everyone hangs out with them for task advice.
+
+## Reduced graphs
+
+Lastly, we can consider how _classes_ of nodes relate to one another in a blockmodel.
+Let's use the 4-cluster solution on the valued network (though binary is possible too)
+to create a `r gloss("reduced graph","reduced")`.
+A reduced graph is a transformation of a network such that
+the nodes are no longer the individual nodes but the groups of one or more nodes as a class,
+and the ties between these blocked nodes can represent the sum or average tie between these classes.
+Of course, this means that there can be self-ties or loops,
+because even if the original network was simple (not `r gloss("complex")`),
+any within-class ties will end up becoming loops and thus the network will be complex.
+
+```{r structblock, exercise = TRUE, exercise.setup = "varyclust", warning=FALSE}
+(bm <- to_blocks(alge, node_in_structural(alge)))
+
+bm <- bm %>% as_tidygraph %>%
+ mutate(name = c("Freaks", "Squares", "Nerds", "Geek"))
+graphr(bm)
+```
+
+## Free play
+
+Now try to find the regularly equivalent classes in the `ison_lawfirm` dataset.
+As this is a multiplex network, you can make this a uniplex network first.
+
+```{r freeplay, exercise = TRUE}
+
+```
+
+An extension can be to also explore `r gloss("regularly equivalent","regulareq")`
+or `r gloss("automorphically equivalent","automorphiceq")` classes.
+
+## Glossary
+
+Here are some of the terms that we have covered in this module:
+
+`r print_glossary()`
+
+
diff --git a/inst/tutorials/tutorial5/position.html b/inst/tutorials/tutorial5/position.html
new file mode 100644
index 0000000..54a6232
--- /dev/null
+++ b/inst/tutorials/tutorial5/position.html
@@ -0,0 +1,2274 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ +
+In this tutorial, we'll explore:
+
+- how to create or generate different network topologies
+- the core-periphery structure of a network
+- features of a network related to its resilience
+
+This tutorial covers a range of different network topologies:
+trees, lattices, random, small-world, scale-free, and core-periphery
+networks.
+These ideal networks exaggerate centrality, clustering, and randomness features,
+and are thus great for theory-building and investigating the relationship between rules and structure.
+
+
+
+In this tutorial, we'll explore:
+
+- how to create or generate different network topologies
+- the core-periphery structure of a network
+- features of a network related to its resilience
+
+This tutorial covers a range of different network topologies:
+trees, lattices, random, small-world, scale-free, and core-periphery
+networks.
+These ideal networks exaggerate centrality, clustering, and randomness features,
+and are thus great for theory-building and investigating the relationship between rules and structure.
+
+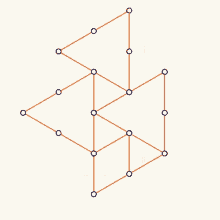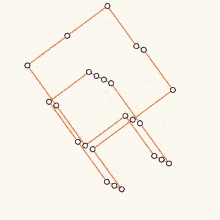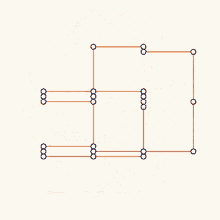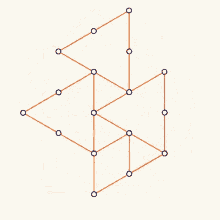 +
+In this practical, we're going to create/generate
+a number of ideal-typical network topologies and plot them.
+We'll first look at some deterministic algorithms for _creating_ networks
+of different structures,
+and then look at how the introduction of some randomness can _generate_ a variety of network structures.
+
+## Creating networks
+
+To begin with, let's create a few 'empty' and full/'complete' graphs.
+You will want to use some of the `create_*()` group of functions from `{manynet}`,
+because they create graphs following some strict rule(s).
+The two functions you will want to use here are `create_empty()` and `create_filled()`.
+`create_empty()` creates an empty graph with the given number of nodes,
+in this case 50 nodes.
+For `create_filled()` we're creating a full graph,
+where all of the nodes are connected to all of the other nodes.
+
+Let's say that we want to explore networks of fifty nodes in this script.
+Graph one empty and one complete network with 50 nodes each,
+give them an informative title, and plot the graphs together.
+What would a complete network with half the nodes look like?
+Add that too.
+
+```{r empty, exercise=TRUE, purl = FALSE}
+
+```
+
+```{r empty-solution}
+(graphr(create_empty(50), "circle") + ggtitle("Empty graph"))
+(graphr(create_filled(50)) + ggtitle("Complete graph"))
+(graphr(create_filled(50/2)) + ggtitle("Complete graph (smaller)"))
+```
+
+#### Stars
+
+In a `r gloss("star", "star")` network, there is one node to which all other nodes are connected,
+otherwise known as the `r gloss("universal", "universal")` node.
+There is no transitivity.
+The maximum path length is two.
+And `r gloss("degree", "degree")` centrality is maximised!^[In fact, all centrality measures are maximised, as one node acts as the sole bridge connecting one part of the network to the other.]
+
+Use the `create_star()` function to graph three star networks:
+
+- an undirected star network
+- a out-directed star network
+- and an in-directed star network
+
+```{r star, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r star-solution}
+(graphr(create_star(50)) + ggtitle("Star graph"))
+(graphr(create_star(50, directed = TRUE)) + ggtitle("Star out"))
+(graphr(to_redirected(create_star(50, directed = TRUE))) + ggtitle("Star in"))
+```
+
+#### Trees
+
+Trees, or regular trees, are networks with branching nodes.
+They can be directed or undirected, and tend to indicate strong hierarchy.
+Again graph three networks:
+
+- one undirected with 2 branches per node
+- a directed network with 2 branches per node
+- the same as above, but graphed using the "tree" layout
+
+```{r tree, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r tree-solution}
+# width argument specifies the breadth of the branches
+(graphr(create_tree(50, width = 2)) + ggtitle("Tree graph"))
+(graphr(create_tree(50, width = 2, directed = TRUE)) + ggtitle("Tree out"))
+(graphr(create_tree(50, width = 2, directed = TRUE), "tree") + ggtitle("Tree layout"))
+```
+
+Try varying the `width` argument to see the result.
+
+#### Lattices
+
+`r gloss("Lattices","lattice")` reflect highly clustered networks
+where there is a high likelihood that interaction partners also interact.
+They are used to show how clustering facilitates or limits diffusion
+or makes pockets of behaviour stable.
+
+```{r lat-qa, echo=FALSE, purl = FALSE}
+question("Why are lattices considered highly clustered?",
+ answer("Because neighbours are likely also neighbours of each other",
+ message = learnr::random_praise(),
+ correct = TRUE),
+ answer("Because all nodes are directly connected to each other",
+ message = learnr::random_encouragement()),
+ answer("Because there is a single component",
+ message = learnr::random_encouragement()),
+ answer("Because there is a single community",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+Note that `create_lattice()` in `{manynet}` works a little differently
+to how it works in `{igraph}`.
+In `{igraph}` the number or vector passed to the function indicates
+the length of each dimension.
+So `c(50)` would be a one-dimensional lattice,
+essentially a chain of 50 nodes connected to their neighbours.
+`c(50,50)` would be a two-dimensional lattice,
+of 50 nodes long and 50 nodes wide.
+`c(50,50,50)` would be a three-dimensional lattice,
+of 50 nodes long, 50 nodes wide, and 50 nodes deep, etc.
+
+_But_ this doesn't help us when we want to see what a lattice representation
+with the same order (number of nodes) as a given network would be.
+For example, perhaps we just want to know what a lattice with 50 nodes
+would look like.
+So `{manynet}` instead tries to find the most even or balanced
+two-dimensional representation with a given number of nodes.
+
+Graph two lattices, one with 50 nodes,
+and another with half the number of nodes.
+
+```{r lattices, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r lattices-solution}
+(graphr(create_lattice(50)) + ggtitle("One-mode lattice graph"))
+(graphr(create_lattice(50/2)) + ggtitle("Smaller lattice graph"))
+```
+
+#### Rings
+
+This creates a graph where each node has two separate neighbours
+which creates a ring graph.
+Graph three ring networks:
+
+- one with 50 nodes
+- one with 50 nodes where they are connected to neighbours two steps away,
+ on a "circle" layout
+- the same as above, but on a "stress" layout
+
+```{r rings, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r rings-solution}
+(graphr(create_ring(50)) + ggtitle("Ring graph", subtitle = "Starring Naomi Watts"))
+# width argument specifies the width of the ring
+(graphr(create_ring(50, width = 2), "circle") + ggtitle("The Ring Two", subtitle = "No different?"))
+(graphr(create_ring(50, width = 2), "stress") + ggtitle("The Ring Two v2.0"))
+```
+
+## Generating networks
+
+Next we are going to take a look at some probabilistic graphs.
+These involve some random element, perhaps in addition to specific rules,
+to stochastically 'generate' networks of certain types of topologies.
+As such, we'll be using the `generate_*()` group of functions from `{manynet}`.
+
+#### Random graphs
+
+An Erdös-Renyi graph is simply a random graph.
+You will need to specify the probability of a tie
+in addition to the number of nodes.
+An Erdos-Renyi graph on the vertex set $V$ is a random graph
+which connects each pair of nodes ${i,j}$ with probability $p$, independent.
+Note that for a “sparse” ER graphs, $p$ must decrease as $N$ goes up.
+Generate three random networks of 50 nodes and a density of 0.08:
+
+```{r random, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r random-solution}
+(graphr(generate_random(50, 0.08)) + ggtitle("Random 1 graph"))
+(graphr(generate_random(50, 0.08)) + ggtitle("Random 2 graph"))
+(graphr(generate_random(50, 0.08)) + ggtitle("Random 3 graph"))
+```
+
+Keep going if you like... it will be a little different every time.
+Note that you can also pass the second argument an integer,
+in which case the function will interpret that as the number of ties/edges rather than the probability that a tie is present.
+Try generating a random graph with 200 edges/ties now:
+
+```{r randomno, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r randomno-solution}
+(erdren4 <- graphr(generate_random(50, 200)) + ggtitle("Random 1 graph"))
+```
+
+#### Small-world graphs
+
+Remember the ring graph from above?
+What if we rewire (change) some of the edges at a certain probability?
+This is how `r gloss("small-world","smallworld")` networks are generated.
+Graph three small-world networks, all with 50 nodes and a rewiring probability of 0.025.
+
+```{r smallw, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r smallw-solution}
+(graphr(generate_smallworld(50, 0.025)) + ggtitle("Smallworld 1 graph"))
+(graphr(generate_smallworld(50, 0.025)) + ggtitle("Smallworld 2 graph"))
+(graphr(generate_smallworld(50, 0.025)) + ggtitle("Smallworld 3 graph"))
+```
+
+With on average 2.5 ties randomly rewired, does the structure look different?
+This is a small-world network, where clustering/transitivity remains high
+but path lengths are much lower than they would otherwise be.
+Remember that in a small-world network, the shortest-path distance between nodes
+increases sufficiently slowly as a function of the number of nodes in the network.
+You can also call these networks a Watts–Strogatz toy network.
+If you want to review this, go back to the reading by Watts (2004).
+
+There is also such a thing as a network's small-world coefficient.
+See the help page for more details,
+but with the default equation ('omega'),
+the coefficient typically ranges between 0 and 1,
+where 1 is as close to a small-world as possible.
+Try it now on a small-world generated network,
+but with a rewiring probability of 0.25:
+
+```{r smallwtest, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r smallwtest-solution}
+net_smallworld(generate_smallworld(50, 0.25))
+```
+
+#### Scale-free graphs
+
+There is another famous model in network science: the `r gloss("scale-free","scalefree")` model.
+Remember:
+"In many real-world networks, the distribution of the number of network neighbours
+the degree distribution is typically right-skewed with a "heavy tail".
+A majority of the nodes have less-than-average `r gloss("degree","degree")` and
+a small fraction of hubs are many times better connected than average (2004, p. 250).
+
+The following generates a scale-free graph according to the Barabasi-Albert (BA) model
+that rests upon the mechanism of preferential attachment.
+More on this in the Watts paper (2005, p.51) and Merton (1968).
+The BA model rests on two mechanisms:
+population growth and preferential attachment.
+Population growth: real networks grow in time as new members join the population.
+Preferential/cumulative attachment means that newly arriving nodes will tend to
+connect to already well-connected nodes rather than poorly connected ones.
+
+Generate and graph three scale-free networks,
+with alpha parameters of 0.5, 1, and 1.5.
+
+```{r scalef, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r scalef-solution}
+(graphr(generate_scalefree(50, 0.5)) +
+ ggtitle("Scalefree 1 graph", subtitle = "Power = .5"))
+(graphr(generate_scalefree(50, 1)) +
+ ggtitle("Scalefree 2 graph", subtitle = "Power = 1"))
+(graphr(generate_scalefree(50, 1.5)) +
+ ggtitle("Scalefree 3 graph", subtitle = "Power = 1.5"))
+```
+
+You can also the degree to which a network has a degree distribution that fits
+a power-law distribution.
+With an alpha/power-law exponent between 2 and 3,
+one generally cannot reject the hypothesis that the observed data
+comes from a power-law distribution.
+
+```{r scaleftest, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r scaleftest-solution}
+net_scalefree(generate_scalefree(50, 2))
+```
+
+## Core-Periphery
+
+### Core-periphery graphs
+
+Lastly, we'll take a look at some `r gloss("core-periphery","core")` graphs.
+The most common definition of a core-periphery network
+is one in which the network can be partitioned into two groups
+such that one group of nodes (the core) has
+dense interactions among themselves,
+moderately dense interactions with the second group,
+and the second group (the periphery) has
+sparse interactions among themselves.
+
+```{r corevcomm-qa, echo=FALSE, purl = FALSE}
+question("Can a single network have both a community structure and a core-periphery structure?",
+ answer("No", message = learnr::random_encouragement()),
+ answer("Yes",
+ message = "That's right. For example, the core and periphery might represent two or more communities.",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+We can visualise extreme versions of such a network
+using the `create_core()` function.
+Graph a core-periphery network of 50 nodes
+(which, unless a core-periphery membership assignment is given,
+will be split evenly between core and periphery partitions).
+
+```{r core, exercise=TRUE, purl = FALSE, fig.width=9}
+
+```
+
+```{r core-solution}
+(graphr(create_core(50)) + ggtitle("Core"))
+```
+
+### Core-periphery assignment
+
+Let's consider identifying the core and peripheral nodes in a network.
+Let's use the `ison_lawfirm` dataset from `{manynet}`.
+This dataset involves relations between partners in a corporate law firm in New England.
+First of all, graph the data and see whether you can guess which nodes
+might be part of the core and which are part of the periphery.
+Color the nodes by Gender, Office, Practice, and School.
+Any you might think correlate with core status?
+
+```{r gnet, exercise=TRUE, purl = FALSE, fig.width=9}
+lawfirm <- ison_lawfirm |> to_uniplex("friends") |> to_undirected()
+```
+
+```{r gnet-solution}
+lawfirm <- ison_lawfirm |> to_uniplex("friends") |> to_undirected()
+graphr(lawfirm, node_color = "school", edge_color = "darkgray")
+graphr(lawfirm, node_color = "gender", edge_color = "darkgray")
+graphr(lawfirm, node_color = "office", edge_color = "darkgray")
+graphr(lawfirm, node_color = "practice", edge_color = "darkgray")
+```
+
+Next, let's assign nodes to the core and periphery blocks
+using the `node_is_core()` function.
+It works pretty straightforwardly.
+By default it runs down the rank order of nodes by their degree,
+at each step working out whether including the next highest degree node
+in the core will maximise the core-periphery structure of the network.
+
+```{r nodecore, exercise=TRUE, purl = FALSE, fig.width=9, exercise.setup="gnet"}
+
+```
+
+```{r nodecore-solution}
+lawfirm %>%
+ mutate(nc = node_is_core()) %>%
+ graphr(node_color = "nc", edge_color = "gray")
+```
+
+This graph suggests that there is a core and a periphery.
+There might even be two cores here,
+one on the left and one on the right.
+
+But is it really all that much of a core-periphery structure?
+We can establish how correlated our network is compared to
+a core-periphery model of the same dimension using `net_core()`.
+
+```{r netcore, exercise=TRUE, purl = FALSE, exercise.setup="gnet"}
+
+```
+
+```{r netcore-solution}
+net_core(lawfirm, node_is_core(lawfirm))
+```
+
+```{r corecorr-qa, echo=FALSE, purl = FALSE}
+question("What can we say about this correlation.",
+ answer("It is a perfect negative relationship",
+ message = learnr::random_encouragement()),
+ answer("It is fairly strong",
+ message = learnr::random_encouragement()),
+ answer("It is positive",
+ message = learnr::random_encouragement()),
+ answer("There is absolutely no correlation",
+ message = learnr::random_encouragement()),
+ answer("None of the above", correct = TRUE,
+ message = learnr::random_praise()),
+ allow_retry = TRUE
+)
+```
+
+Note that `node_is_core()` also includes a method that descends through
+the rank order of nodes' eigenvector centralities instead of degree centralities.
+Why might that not be such a good choice here?
+
+Now let's see whether our core-periphery membership vector correlates with any of the three
+categorical attributes we looked at before.
+Since we're doing this on categorical variables, we'll use the Chi-squared test in base R.
+Take a look and see whether there is a statistically significant association
+between gender and core (or periphery) status.
+
+```{r chisq, exercise=TRUE, purl=FALSE, exercise.setup="gnet"}
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "gender")))
+```
+
+```{r chisq-solution}
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "gender")))
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "office")))
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "school")))
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "practice")))
+```
+
+```{r chisq-qa, echo=FALSE, purl = FALSE}
+question("There a statistically significant association between the core assignment and...",
+ answer("gender.",
+ message = learnr::random_encouragement()),
+ answer("office.",
+ message = learnr::random_encouragement()),
+ answer("school.",
+ message = learnr::random_encouragement()),
+ answer("practice.",
+ message = learnr::random_encouragement()),
+ answer("none of the above variables.", correct = TRUE,
+ message = "That's right. The p-value for office is close, but no cigar."),
+ allow_retry = TRUE
+)
+```
+
+### Coreness
+
+An alternative route is to identify 'core' nodes
+depending on their `r gloss("k-coreness","kcoreness")`.
+In `{manynet}`, we can return nodes _k_-coreness
+with `node_coreness()` instead of
+the `node_is_core()` used for core-periphery.
+
+```{r nodecoren, exercise=TRUE, purl = FALSE, exercise.setup="gnet"}
+lawfirm %>%
+ mutate(ncn = node_kcoreness()) %>%
+ graphr(node_color = "ncn")
+```
+
+```{r dich-qa, echo=FALSE, purl = FALSE}
+question("Which has more than two classes/groups.",
+ answer("node_kcoreness()", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("node_is_core()",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+```{r ness-qa, echo=FALSE, purl = FALSE}
+question("Select the correct definitions:",
+ answer("The k-core of a network is a maximal subgraph in which each vertex has at least degree k.", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("The coreness of a node is k if it belongs to the k-core but not to the (k+1)-core.", correct = TRUE),
+ answer("The coreness of a node is equal to its degree.",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Hierarchy
+
+What sometimes drives our interest in whether a network resembles a
+core-periphery network is that it offers a generalisation of hierarchy:
+the core are the rule-makers; the periphery are the rule-takers.
+But where we have a directed network,
+we may be able to measure hierarchy explicitly.
+
+### Graph theoretic dimensions of hierarchy
+
+Recall that measuring hierarchy directly is difficult,
+as the concept incorporates several different aspects.
+Can you recall which of the following are aspects of
+the graph theoretic dimensions of hierarchy?
+
+```{r gtdh-qa, echo=FALSE, purl = FALSE}
+question("Select the measures included in the graph theoretic dimensions of hierarchy:",
+ answer("reciprocity", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("connectedness", correct = TRUE),
+ answer("efficiency", correct = TRUE),
+ answer("least upper bound", correct = TRUE),
+ answer("components", message = learnr::random_encouragement()),
+ answer("degree", message = learnr::random_encouragement()),
+ answer("density", message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Measuring GTDH
+
+Ok, so let's now take a closer look at how to investigate the degree of
+hierarchy in a given network.
+The classic example would be to look at a tree network,
+like the one constructed earlier.
+Let's try the function `net_by_hierarchy()` on a tree network of 12 nodes.
+
+```{r treeh, exercise = TRUE, purl = FALSE}
+treeleven <- create_tree(11, directed = TRUE)
+net_by_hierarchy(treeleven)
+rowMeans(net_by_hierarchy(treeleven))
+```
+
+We see here four different measures of hierarchy:
+
+- **connectedness**: the proportion of dyads that can reach each other
+- **reciprocity**: the proportion of ties that are reciprocated (inverse)
+- **efficiency**: the minimum indegrees required to connect the network over
+the actual indegrees present
+- **least upper bound**: all nodes in a hierarchy should have a node that can
+reach both of them
+
+Note that to get an overall score, we can take the average of these four measures.
+
+### Comparing GTDH
+
+Because some of these measures (reciprocity), only make sense for a directed
+network, we'll switch to a couple of directed networks for this exercise.
+Which one would you consider is more hierarchical:
+`ison_emotions`, a directed network of emotional transitions,
+or `fict_thrones`, a directed network of kinship ties?
+
+```{r hierarchy, exercise = TRUE, warning=FALSE}
+graphr(ison_emotions)
+graphr(fict_thrones)
+```
+
+```{r hierarchy-solution}
+graphr(ison_emotions)
+net_by_hierarchy(ison_emotions)
+graphr(fict_thrones)
+net_by_hierarchy(fict_thrones)
+```
+
+Actually, these two networks have the same average hierarchy score of around 0.525.
+But they have quite different profiles.
+Can you make sense of these results?
+
+```{r gtdhcompare-qa, echo=FALSE, purl = FALSE}
+question("Compared to the emotional transitions network, the Game of Thrones kinship network has:",
+ answer("more nodes able to reach each other",
+ message = learnr::random_encouragement()),
+ answer("fewer reciprocated ties", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("fewer redundant ties", correct = TRUE),
+ answer("at least one boss for all pairs"),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Resilience
+
+### How cohesive is the network?
+
+When investigating a network's resilience,
+we might think of whether the network will remain connected despite some nodes or ties dropping out.
+Let's explore how resilient a (core) network of adolescents (`ison_adolescents`) might be.
+First, we might be interested in whether the network is `r gloss("connected","connected")` at all.
+
+```{r connected, exercise=TRUE, purl = FALSE}
+
+```
+
+```{r connected-solution}
+net_connectedness(ison_adolescents)
+```
+
+This measure gets at the proportion of dyads that can reach each other in the network.
+In this case, the proportion is 1, i.e. all nodes can reach every other node.
+Another way to get at this would be to see how many `r gloss("components","component")` there are in the network.
+
+```{r connect-qa, echo=FALSE, purl=FALSE}
+question("But counting the number of components instead of connectedness can overemphasise:",
+ answer("Isolates", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Small components", correct = TRUE,
+ message = learnr::random_encouragement()),
+ answer("Density",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+A dropped tie can have severe consequences to the topology of a network
+if it is a bridge, say.
+The more ties you would need to remove to fragment the network,
+the greater the `r gloss("adhesion","adhesion")` of the network.
+But a dropped node can be even more consequential, as it will take any ties it has with it.
+Find out the `r gloss("cohesion","cohesion")`,
+or how many dropped nodes it would take to (further) fragment the network.
+
+```{r cohesion, exercise=TRUE, purl = FALSE}
+
+```
+
+```{r cohesion-solution}
+net_cohesion(ison_adolescents)
+```
+
+```{r cohesion-qa, echo=FALSE, purl = FALSE}
+question("The result of this function represents...",
+ answer("the minimum number of nodes necessary to remove from the network to increase the number of components.", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("the number of strong components in the network.",
+ message = learnr::random_encouragement()),
+ answer("the minimum number of ties necessary to remove from the network to increase the number of components.",
+ message = "This is actually the definition of `node_adhesion()`."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+```{r res-qa, echo=FALSE, purl = FALSE}
+question("The higher the minimum number of nodes to remove...",
+ answer("the more resilient is the network.", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("the less resilient the network.",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Identifying cutpoints
+
+But which are these nodes? Is there more than one?
+Nodes that endanger fragmentation of the network are called `r gloss("cutpoints","cutpoint")`.
+Find and use a function to identify which, if any, of the nodes in the `ison_adolescents`
+network are cutpoints.
+
+```{r idcuts, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r idcuts-solution}
+node_is_cutpoint(ison_adolescents)
+```
+
+Ok, so this results in a vector identifying which nodes are cutpoints (TRUE) or not (FALSE).
+Somewhat more useful though would be to highlight these nodes on the network.
+Can you add a node attribute that highlights which nodes are cutpoints?
+
+```{r closerlook, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r closerlook-solution}
+ison_adolescents |> mutate(cut = node_is_cutpoint(ison_adolescents)) |>
+ graphr(node_color = "cut")
+```
+
+### Identifying bridges
+
+Let's do something similar now, but with respect to ties rather than nodes.
+Here we are interested in identifying which ties are `r gloss("bridges","bridge")`.
+
+```{r tieside, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r tieside-solution}
+net_adhesion(ison_adolescents)
+ison_adolescents |> mutate_ties(cut = tie_is_bridge(ison_adolescents)) |>
+ graphr(edge_color = "cut")
+```
+
+We could also investigate the opposite of a bridge,
+the degree to which ties are deeply embedded in triangles.
+This is called (rather confusingly) tie cohesion.
+
+```{r tiecoh, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r tiecoh-solution}
+ison_adolescents |> mutate_ties(coh = tie_cohesion(ison_adolescents)) |>
+ graphr(edge_size = "coh")
+```
+
+Where would you target your efforts if you wanted to fragment this network?
+
+## Free play
+
+```{r freeplay, exercise = TRUE}
+
+```
+
+## Glossary
+
+Here are some of the terms that we have covered in this module:
+
+`r print_glossary()`
+
+
diff --git a/inst/tutorials/tutorial6/topology.html b/inst/tutorials/tutorial6/topology.html
new file mode 100644
index 0000000..3fc5d78
--- /dev/null
+++ b/inst/tutorials/tutorial6/topology.html
@@ -0,0 +1,2992 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+In this practical, we're going to create/generate
+a number of ideal-typical network topologies and plot them.
+We'll first look at some deterministic algorithms for _creating_ networks
+of different structures,
+and then look at how the introduction of some randomness can _generate_ a variety of network structures.
+
+## Creating networks
+
+To begin with, let's create a few 'empty' and full/'complete' graphs.
+You will want to use some of the `create_*()` group of functions from `{manynet}`,
+because they create graphs following some strict rule(s).
+The two functions you will want to use here are `create_empty()` and `create_filled()`.
+`create_empty()` creates an empty graph with the given number of nodes,
+in this case 50 nodes.
+For `create_filled()` we're creating a full graph,
+where all of the nodes are connected to all of the other nodes.
+
+Let's say that we want to explore networks of fifty nodes in this script.
+Graph one empty and one complete network with 50 nodes each,
+give them an informative title, and plot the graphs together.
+What would a complete network with half the nodes look like?
+Add that too.
+
+```{r empty, exercise=TRUE, purl = FALSE}
+
+```
+
+```{r empty-solution}
+(graphr(create_empty(50), "circle") + ggtitle("Empty graph"))
+(graphr(create_filled(50)) + ggtitle("Complete graph"))
+(graphr(create_filled(50/2)) + ggtitle("Complete graph (smaller)"))
+```
+
+#### Stars
+
+In a `r gloss("star", "star")` network, there is one node to which all other nodes are connected,
+otherwise known as the `r gloss("universal", "universal")` node.
+There is no transitivity.
+The maximum path length is two.
+And `r gloss("degree", "degree")` centrality is maximised!^[In fact, all centrality measures are maximised, as one node acts as the sole bridge connecting one part of the network to the other.]
+
+Use the `create_star()` function to graph three star networks:
+
+- an undirected star network
+- a out-directed star network
+- and an in-directed star network
+
+```{r star, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r star-solution}
+(graphr(create_star(50)) + ggtitle("Star graph"))
+(graphr(create_star(50, directed = TRUE)) + ggtitle("Star out"))
+(graphr(to_redirected(create_star(50, directed = TRUE))) + ggtitle("Star in"))
+```
+
+#### Trees
+
+Trees, or regular trees, are networks with branching nodes.
+They can be directed or undirected, and tend to indicate strong hierarchy.
+Again graph three networks:
+
+- one undirected with 2 branches per node
+- a directed network with 2 branches per node
+- the same as above, but graphed using the "tree" layout
+
+```{r tree, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r tree-solution}
+# width argument specifies the breadth of the branches
+(graphr(create_tree(50, width = 2)) + ggtitle("Tree graph"))
+(graphr(create_tree(50, width = 2, directed = TRUE)) + ggtitle("Tree out"))
+(graphr(create_tree(50, width = 2, directed = TRUE), "tree") + ggtitle("Tree layout"))
+```
+
+Try varying the `width` argument to see the result.
+
+#### Lattices
+
+`r gloss("Lattices","lattice")` reflect highly clustered networks
+where there is a high likelihood that interaction partners also interact.
+They are used to show how clustering facilitates or limits diffusion
+or makes pockets of behaviour stable.
+
+```{r lat-qa, echo=FALSE, purl = FALSE}
+question("Why are lattices considered highly clustered?",
+ answer("Because neighbours are likely also neighbours of each other",
+ message = learnr::random_praise(),
+ correct = TRUE),
+ answer("Because all nodes are directly connected to each other",
+ message = learnr::random_encouragement()),
+ answer("Because there is a single component",
+ message = learnr::random_encouragement()),
+ answer("Because there is a single community",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+Note that `create_lattice()` in `{manynet}` works a little differently
+to how it works in `{igraph}`.
+In `{igraph}` the number or vector passed to the function indicates
+the length of each dimension.
+So `c(50)` would be a one-dimensional lattice,
+essentially a chain of 50 nodes connected to their neighbours.
+`c(50,50)` would be a two-dimensional lattice,
+of 50 nodes long and 50 nodes wide.
+`c(50,50,50)` would be a three-dimensional lattice,
+of 50 nodes long, 50 nodes wide, and 50 nodes deep, etc.
+
+_But_ this doesn't help us when we want to see what a lattice representation
+with the same order (number of nodes) as a given network would be.
+For example, perhaps we just want to know what a lattice with 50 nodes
+would look like.
+So `{manynet}` instead tries to find the most even or balanced
+two-dimensional representation with a given number of nodes.
+
+Graph two lattices, one with 50 nodes,
+and another with half the number of nodes.
+
+```{r lattices, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r lattices-solution}
+(graphr(create_lattice(50)) + ggtitle("One-mode lattice graph"))
+(graphr(create_lattice(50/2)) + ggtitle("Smaller lattice graph"))
+```
+
+#### Rings
+
+This creates a graph where each node has two separate neighbours
+which creates a ring graph.
+Graph three ring networks:
+
+- one with 50 nodes
+- one with 50 nodes where they are connected to neighbours two steps away,
+ on a "circle" layout
+- the same as above, but on a "stress" layout
+
+```{r rings, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r rings-solution}
+(graphr(create_ring(50)) + ggtitle("Ring graph", subtitle = "Starring Naomi Watts"))
+# width argument specifies the width of the ring
+(graphr(create_ring(50, width = 2), "circle") + ggtitle("The Ring Two", subtitle = "No different?"))
+(graphr(create_ring(50, width = 2), "stress") + ggtitle("The Ring Two v2.0"))
+```
+
+## Generating networks
+
+Next we are going to take a look at some probabilistic graphs.
+These involve some random element, perhaps in addition to specific rules,
+to stochastically 'generate' networks of certain types of topologies.
+As such, we'll be using the `generate_*()` group of functions from `{manynet}`.
+
+#### Random graphs
+
+An Erdös-Renyi graph is simply a random graph.
+You will need to specify the probability of a tie
+in addition to the number of nodes.
+An Erdos-Renyi graph on the vertex set $V$ is a random graph
+which connects each pair of nodes ${i,j}$ with probability $p$, independent.
+Note that for a “sparse” ER graphs, $p$ must decrease as $N$ goes up.
+Generate three random networks of 50 nodes and a density of 0.08:
+
+```{r random, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r random-solution}
+(graphr(generate_random(50, 0.08)) + ggtitle("Random 1 graph"))
+(graphr(generate_random(50, 0.08)) + ggtitle("Random 2 graph"))
+(graphr(generate_random(50, 0.08)) + ggtitle("Random 3 graph"))
+```
+
+Keep going if you like... it will be a little different every time.
+Note that you can also pass the second argument an integer,
+in which case the function will interpret that as the number of ties/edges rather than the probability that a tie is present.
+Try generating a random graph with 200 edges/ties now:
+
+```{r randomno, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r randomno-solution}
+(erdren4 <- graphr(generate_random(50, 200)) + ggtitle("Random 1 graph"))
+```
+
+#### Small-world graphs
+
+Remember the ring graph from above?
+What if we rewire (change) some of the edges at a certain probability?
+This is how `r gloss("small-world","smallworld")` networks are generated.
+Graph three small-world networks, all with 50 nodes and a rewiring probability of 0.025.
+
+```{r smallw, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r smallw-solution}
+(graphr(generate_smallworld(50, 0.025)) + ggtitle("Smallworld 1 graph"))
+(graphr(generate_smallworld(50, 0.025)) + ggtitle("Smallworld 2 graph"))
+(graphr(generate_smallworld(50, 0.025)) + ggtitle("Smallworld 3 graph"))
+```
+
+With on average 2.5 ties randomly rewired, does the structure look different?
+This is a small-world network, where clustering/transitivity remains high
+but path lengths are much lower than they would otherwise be.
+Remember that in a small-world network, the shortest-path distance between nodes
+increases sufficiently slowly as a function of the number of nodes in the network.
+You can also call these networks a Watts–Strogatz toy network.
+If you want to review this, go back to the reading by Watts (2004).
+
+There is also such a thing as a network's small-world coefficient.
+See the help page for more details,
+but with the default equation ('omega'),
+the coefficient typically ranges between 0 and 1,
+where 1 is as close to a small-world as possible.
+Try it now on a small-world generated network,
+but with a rewiring probability of 0.25:
+
+```{r smallwtest, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r smallwtest-solution}
+net_smallworld(generate_smallworld(50, 0.25))
+```
+
+#### Scale-free graphs
+
+There is another famous model in network science: the `r gloss("scale-free","scalefree")` model.
+Remember:
+"In many real-world networks, the distribution of the number of network neighbours
+the degree distribution is typically right-skewed with a "heavy tail".
+A majority of the nodes have less-than-average `r gloss("degree","degree")` and
+a small fraction of hubs are many times better connected than average (2004, p. 250).
+
+The following generates a scale-free graph according to the Barabasi-Albert (BA) model
+that rests upon the mechanism of preferential attachment.
+More on this in the Watts paper (2005, p.51) and Merton (1968).
+The BA model rests on two mechanisms:
+population growth and preferential attachment.
+Population growth: real networks grow in time as new members join the population.
+Preferential/cumulative attachment means that newly arriving nodes will tend to
+connect to already well-connected nodes rather than poorly connected ones.
+
+Generate and graph three scale-free networks,
+with alpha parameters of 0.5, 1, and 1.5.
+
+```{r scalef, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r scalef-solution}
+(graphr(generate_scalefree(50, 0.5)) +
+ ggtitle("Scalefree 1 graph", subtitle = "Power = .5"))
+(graphr(generate_scalefree(50, 1)) +
+ ggtitle("Scalefree 2 graph", subtitle = "Power = 1"))
+(graphr(generate_scalefree(50, 1.5)) +
+ ggtitle("Scalefree 3 graph", subtitle = "Power = 1.5"))
+```
+
+You can also the degree to which a network has a degree distribution that fits
+a power-law distribution.
+With an alpha/power-law exponent between 2 and 3,
+one generally cannot reject the hypothesis that the observed data
+comes from a power-law distribution.
+
+```{r scaleftest, exercise = TRUE, purl = FALSE}
+
+```
+
+```{r scaleftest-solution}
+net_scalefree(generate_scalefree(50, 2))
+```
+
+## Core-Periphery
+
+### Core-periphery graphs
+
+Lastly, we'll take a look at some `r gloss("core-periphery","core")` graphs.
+The most common definition of a core-periphery network
+is one in which the network can be partitioned into two groups
+such that one group of nodes (the core) has
+dense interactions among themselves,
+moderately dense interactions with the second group,
+and the second group (the periphery) has
+sparse interactions among themselves.
+
+```{r corevcomm-qa, echo=FALSE, purl = FALSE}
+question("Can a single network have both a community structure and a core-periphery structure?",
+ answer("No", message = learnr::random_encouragement()),
+ answer("Yes",
+ message = "That's right. For example, the core and periphery might represent two or more communities.",
+ correct = TRUE),
+ random_answer_order = TRUE,
+ allow_retry = TRUE)
+```
+
+We can visualise extreme versions of such a network
+using the `create_core()` function.
+Graph a core-periphery network of 50 nodes
+(which, unless a core-periphery membership assignment is given,
+will be split evenly between core and periphery partitions).
+
+```{r core, exercise=TRUE, purl = FALSE, fig.width=9}
+
+```
+
+```{r core-solution}
+(graphr(create_core(50)) + ggtitle("Core"))
+```
+
+### Core-periphery assignment
+
+Let's consider identifying the core and peripheral nodes in a network.
+Let's use the `ison_lawfirm` dataset from `{manynet}`.
+This dataset involves relations between partners in a corporate law firm in New England.
+First of all, graph the data and see whether you can guess which nodes
+might be part of the core and which are part of the periphery.
+Color the nodes by Gender, Office, Practice, and School.
+Any you might think correlate with core status?
+
+```{r gnet, exercise=TRUE, purl = FALSE, fig.width=9}
+lawfirm <- ison_lawfirm |> to_uniplex("friends") |> to_undirected()
+```
+
+```{r gnet-solution}
+lawfirm <- ison_lawfirm |> to_uniplex("friends") |> to_undirected()
+graphr(lawfirm, node_color = "school", edge_color = "darkgray")
+graphr(lawfirm, node_color = "gender", edge_color = "darkgray")
+graphr(lawfirm, node_color = "office", edge_color = "darkgray")
+graphr(lawfirm, node_color = "practice", edge_color = "darkgray")
+```
+
+Next, let's assign nodes to the core and periphery blocks
+using the `node_is_core()` function.
+It works pretty straightforwardly.
+By default it runs down the rank order of nodes by their degree,
+at each step working out whether including the next highest degree node
+in the core will maximise the core-periphery structure of the network.
+
+```{r nodecore, exercise=TRUE, purl = FALSE, fig.width=9, exercise.setup="gnet"}
+
+```
+
+```{r nodecore-solution}
+lawfirm %>%
+ mutate(nc = node_is_core()) %>%
+ graphr(node_color = "nc", edge_color = "gray")
+```
+
+This graph suggests that there is a core and a periphery.
+There might even be two cores here,
+one on the left and one on the right.
+
+But is it really all that much of a core-periphery structure?
+We can establish how correlated our network is compared to
+a core-periphery model of the same dimension using `net_core()`.
+
+```{r netcore, exercise=TRUE, purl = FALSE, exercise.setup="gnet"}
+
+```
+
+```{r netcore-solution}
+net_core(lawfirm, node_is_core(lawfirm))
+```
+
+```{r corecorr-qa, echo=FALSE, purl = FALSE}
+question("What can we say about this correlation.",
+ answer("It is a perfect negative relationship",
+ message = learnr::random_encouragement()),
+ answer("It is fairly strong",
+ message = learnr::random_encouragement()),
+ answer("It is positive",
+ message = learnr::random_encouragement()),
+ answer("There is absolutely no correlation",
+ message = learnr::random_encouragement()),
+ answer("None of the above", correct = TRUE,
+ message = learnr::random_praise()),
+ allow_retry = TRUE
+)
+```
+
+Note that `node_is_core()` also includes a method that descends through
+the rank order of nodes' eigenvector centralities instead of degree centralities.
+Why might that not be such a good choice here?
+
+Now let's see whether our core-periphery membership vector correlates with any of the three
+categorical attributes we looked at before.
+Since we're doing this on categorical variables, we'll use the Chi-squared test in base R.
+Take a look and see whether there is a statistically significant association
+between gender and core (or periphery) status.
+
+```{r chisq, exercise=TRUE, purl=FALSE, exercise.setup="gnet"}
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "gender")))
+```
+
+```{r chisq-solution}
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "gender")))
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "office")))
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "school")))
+chisq.test(as.factor(node_is_core(lawfirm)),
+ as.factor(node_attribute(lawfirm, "practice")))
+```
+
+```{r chisq-qa, echo=FALSE, purl = FALSE}
+question("There a statistically significant association between the core assignment and...",
+ answer("gender.",
+ message = learnr::random_encouragement()),
+ answer("office.",
+ message = learnr::random_encouragement()),
+ answer("school.",
+ message = learnr::random_encouragement()),
+ answer("practice.",
+ message = learnr::random_encouragement()),
+ answer("none of the above variables.", correct = TRUE,
+ message = "That's right. The p-value for office is close, but no cigar."),
+ allow_retry = TRUE
+)
+```
+
+### Coreness
+
+An alternative route is to identify 'core' nodes
+depending on their `r gloss("k-coreness","kcoreness")`.
+In `{manynet}`, we can return nodes _k_-coreness
+with `node_coreness()` instead of
+the `node_is_core()` used for core-periphery.
+
+```{r nodecoren, exercise=TRUE, purl = FALSE, exercise.setup="gnet"}
+lawfirm %>%
+ mutate(ncn = node_kcoreness()) %>%
+ graphr(node_color = "ncn")
+```
+
+```{r dich-qa, echo=FALSE, purl = FALSE}
+question("Which has more than two classes/groups.",
+ answer("node_kcoreness()", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("node_is_core()",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+```{r ness-qa, echo=FALSE, purl = FALSE}
+question("Select the correct definitions:",
+ answer("The k-core of a network is a maximal subgraph in which each vertex has at least degree k.", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("The coreness of a node is k if it belongs to the k-core but not to the (k+1)-core.", correct = TRUE),
+ answer("The coreness of a node is equal to its degree.",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Hierarchy
+
+What sometimes drives our interest in whether a network resembles a
+core-periphery network is that it offers a generalisation of hierarchy:
+the core are the rule-makers; the periphery are the rule-takers.
+But where we have a directed network,
+we may be able to measure hierarchy explicitly.
+
+### Graph theoretic dimensions of hierarchy
+
+Recall that measuring hierarchy directly is difficult,
+as the concept incorporates several different aspects.
+Can you recall which of the following are aspects of
+the graph theoretic dimensions of hierarchy?
+
+```{r gtdh-qa, echo=FALSE, purl = FALSE}
+question("Select the measures included in the graph theoretic dimensions of hierarchy:",
+ answer("reciprocity", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("connectedness", correct = TRUE),
+ answer("efficiency", correct = TRUE),
+ answer("least upper bound", correct = TRUE),
+ answer("components", message = learnr::random_encouragement()),
+ answer("degree", message = learnr::random_encouragement()),
+ answer("density", message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Measuring GTDH
+
+Ok, so let's now take a closer look at how to investigate the degree of
+hierarchy in a given network.
+The classic example would be to look at a tree network,
+like the one constructed earlier.
+Let's try the function `net_by_hierarchy()` on a tree network of 12 nodes.
+
+```{r treeh, exercise = TRUE, purl = FALSE}
+treeleven <- create_tree(11, directed = TRUE)
+net_by_hierarchy(treeleven)
+rowMeans(net_by_hierarchy(treeleven))
+```
+
+We see here four different measures of hierarchy:
+
+- **connectedness**: the proportion of dyads that can reach each other
+- **reciprocity**: the proportion of ties that are reciprocated (inverse)
+- **efficiency**: the minimum indegrees required to connect the network over
+the actual indegrees present
+- **least upper bound**: all nodes in a hierarchy should have a node that can
+reach both of them
+
+Note that to get an overall score, we can take the average of these four measures.
+
+### Comparing GTDH
+
+Because some of these measures (reciprocity), only make sense for a directed
+network, we'll switch to a couple of directed networks for this exercise.
+Which one would you consider is more hierarchical:
+`ison_emotions`, a directed network of emotional transitions,
+or `fict_thrones`, a directed network of kinship ties?
+
+```{r hierarchy, exercise = TRUE, warning=FALSE}
+graphr(ison_emotions)
+graphr(fict_thrones)
+```
+
+```{r hierarchy-solution}
+graphr(ison_emotions)
+net_by_hierarchy(ison_emotions)
+graphr(fict_thrones)
+net_by_hierarchy(fict_thrones)
+```
+
+Actually, these two networks have the same average hierarchy score of around 0.525.
+But they have quite different profiles.
+Can you make sense of these results?
+
+```{r gtdhcompare-qa, echo=FALSE, purl = FALSE}
+question("Compared to the emotional transitions network, the Game of Thrones kinship network has:",
+ answer("more nodes able to reach each other",
+ message = learnr::random_encouragement()),
+ answer("fewer reciprocated ties", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("fewer redundant ties", correct = TRUE),
+ answer("at least one boss for all pairs"),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+## Resilience
+
+### How cohesive is the network?
+
+When investigating a network's resilience,
+we might think of whether the network will remain connected despite some nodes or ties dropping out.
+Let's explore how resilient a (core) network of adolescents (`ison_adolescents`) might be.
+First, we might be interested in whether the network is `r gloss("connected","connected")` at all.
+
+```{r connected, exercise=TRUE, purl = FALSE}
+
+```
+
+```{r connected-solution}
+net_connectedness(ison_adolescents)
+```
+
+This measure gets at the proportion of dyads that can reach each other in the network.
+In this case, the proportion is 1, i.e. all nodes can reach every other node.
+Another way to get at this would be to see how many `r gloss("components","component")` there are in the network.
+
+```{r connect-qa, echo=FALSE, purl=FALSE}
+question("But counting the number of components instead of connectedness can overemphasise:",
+ answer("Isolates", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("Small components", correct = TRUE,
+ message = learnr::random_encouragement()),
+ answer("Density",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+A dropped tie can have severe consequences to the topology of a network
+if it is a bridge, say.
+The more ties you would need to remove to fragment the network,
+the greater the `r gloss("adhesion","adhesion")` of the network.
+But a dropped node can be even more consequential, as it will take any ties it has with it.
+Find out the `r gloss("cohesion","cohesion")`,
+or how many dropped nodes it would take to (further) fragment the network.
+
+```{r cohesion, exercise=TRUE, purl = FALSE}
+
+```
+
+```{r cohesion-solution}
+net_cohesion(ison_adolescents)
+```
+
+```{r cohesion-qa, echo=FALSE, purl = FALSE}
+question("The result of this function represents...",
+ answer("the minimum number of nodes necessary to remove from the network to increase the number of components.", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("the number of strong components in the network.",
+ message = learnr::random_encouragement()),
+ answer("the minimum number of ties necessary to remove from the network to increase the number of components.",
+ message = "This is actually the definition of `node_adhesion()`."),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+```{r res-qa, echo=FALSE, purl = FALSE}
+question("The higher the minimum number of nodes to remove...",
+ answer("the more resilient is the network.", correct = TRUE,
+ message = learnr::random_praise()),
+ answer("the less resilient the network.",
+ message = learnr::random_encouragement()),
+ random_answer_order = TRUE,
+ allow_retry = TRUE
+)
+```
+
+### Identifying cutpoints
+
+But which are these nodes? Is there more than one?
+Nodes that endanger fragmentation of the network are called `r gloss("cutpoints","cutpoint")`.
+Find and use a function to identify which, if any, of the nodes in the `ison_adolescents`
+network are cutpoints.
+
+```{r idcuts, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r idcuts-solution}
+node_is_cutpoint(ison_adolescents)
+```
+
+Ok, so this results in a vector identifying which nodes are cutpoints (TRUE) or not (FALSE).
+Somewhat more useful though would be to highlight these nodes on the network.
+Can you add a node attribute that highlights which nodes are cutpoints?
+
+```{r closerlook, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r closerlook-solution}
+ison_adolescents |> mutate(cut = node_is_cutpoint(ison_adolescents)) |>
+ graphr(node_color = "cut")
+```
+
+### Identifying bridges
+
+Let's do something similar now, but with respect to ties rather than nodes.
+Here we are interested in identifying which ties are `r gloss("bridges","bridge")`.
+
+```{r tieside, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r tieside-solution}
+net_adhesion(ison_adolescents)
+ison_adolescents |> mutate_ties(cut = tie_is_bridge(ison_adolescents)) |>
+ graphr(edge_color = "cut")
+```
+
+We could also investigate the opposite of a bridge,
+the degree to which ties are deeply embedded in triangles.
+This is called (rather confusingly) tie cohesion.
+
+```{r tiecoh, exercise = TRUE, purl=FALSE}
+
+```
+
+```{r tiecoh-solution}
+ison_adolescents |> mutate_ties(coh = tie_cohesion(ison_adolescents)) |>
+ graphr(edge_size = "coh")
+```
+
+Where would you target your efforts if you wanted to fragment this network?
+
+## Free play
+
+```{r freeplay, exercise = TRUE}
+
+```
+
+## Glossary
+
+Here are some of the terms that we have covered in this module:
+
+`r print_glossary()`
+
+
diff --git a/inst/tutorials/tutorial6/topology.html b/inst/tutorials/tutorial6/topology.html
new file mode 100644
index 0000000..3fc5d78
--- /dev/null
+++ b/inst/tutorials/tutorial6/topology.html
@@ -0,0 +1,2992 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+