Selecting the right Large Language Model (LLM) backend is no longer just an infrastructure decision — it directly impacts latency, throughput, operational cost, scalability, and developer velocity. The choice of inference engine determines how quickly your models respond under load, how efficiently your GPU resources are utilized, and how much operational overhead your team must absorb on an ongoing basis. Getting this decision wrong can mean over-provisioning expensive hardware for a workload that doesn't need it, or under-serving users with an engine that can't keep up with production traffic.
-
Cube AI is intentionally designed with backend modularity at its core, allowing teams to switch between inference engines without changing any application logic, rewriting API integrations, or modifying client SDKs. Whether you prioritize GPU-accelerated performance for high-concurrency production workloads or lightweight local deployments for development, edge computing, and confidential environments, Cube AI supports both paradigms through two production-ready backends:
-
-- vLLM — optimized for high-throughput, GPU-driven inference with continuous batching and explicit memory management
-- Ollama — a flexible, developer-friendly runtime designed for local, hybrid, and resource-constrained environments
-
-
The architectural takeaway is simple:
-
-In Cube AI, the LLM backend is a swappable module behind a single environment variable.
-
-
-
Backend Selection Architecture
-
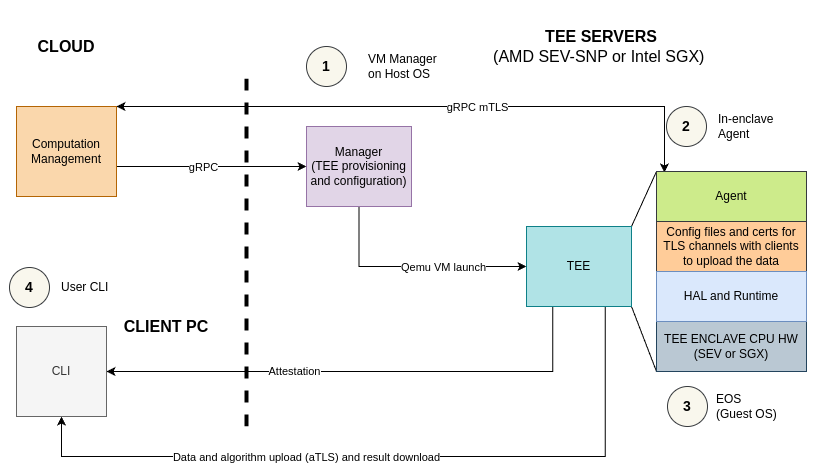
Cube AI routes all inference traffic through a backend-agnostic agent proxy. Rather than coupling application code directly to a specific inference engine's API, the proxy sits between the application layer and the backend, forwarding requests to whichever inference engine is currently configured. This means the entire system — from the frontend client to the guardrails pipeline — remains completely unaware of whether it is talking to vLLM or Ollama on the other side.
-
The backend target is controlled by a single environment variable:
-
UV_CUBE_AGENT_TARGET_URL=http://ollama:11434
-# OR
-UV_CUBE_AGENT_TARGET_URL=http://vllm:8000
-
This variable defaults to http://localhost:11434 (Ollama). The Makefile provides convenient targets that automatically update this variable and launch the appropriate Docker Compose profile, so switching backends is operationally trivial:
-
up-ollama: config-ollama
-up-vllm: config-vllm
-
There is no need for application rewrites, routing changes, or SDK updates. The swap happens entirely at the infrastructure level. You simply reconfigure the environment variable and redeploy — the application continues to function exactly as before, now backed by a different inference engine.
-
Why This Matters Architecturally
-
This design creates a clean separation between four distinct layers of the system, each of which can evolve independently:
-
-- Application layer — the user-facing services and clients that consume LLM responses
-- Guardrails — the NeMo Guardrails pipeline that enforces safety policies, sensitive data detection, and content filtering
-- Proxy routing — the dynamic router that directs traffic based on configurable rules such as headers, paths, and priority levels
-- Inference engine — the actual LLM backend (vLLM or Ollama) that performs model inference
-
-
The agent service acts as a reverse proxy, forwarding requests to the configured backend. It handles authentication at the proxy boundary and maintains efficient connection management under load, so the backend remains completely invisible to the application. Whether the underlying engine is vLLM processing requests with continuous batching on a GPU cluster or Ollama running sequentially on a CPU-only node, the API contract remains identical.
-
This separation is critical for several real-world operational scenarios: multi-environment deployments where staging runs Ollama and production runs vLLM, gradual GPU rollouts where teams incrementally shift traffic to GPU-backed inference, cost optimization experiments where teams compare per-token costs across backends, and performance experimentation where teams benchmark different engines under realistic workloads.
-
-
-
While exact performance numbers will vary depending on the specific model, GPU class, input sequence length, and concurrency level, the underlying architecture of each engine reveals clear and predictable performance behavior. Understanding these architectural characteristics helps teams make informed backend decisions before committing to expensive hardware.
-
Throughput
-
vLLM
-
vLLM was purpose-built for high-throughput inference. Its continuous batching engine dynamically groups incoming requests together and processes them in parallel on the GPU, which dramatically increases the number of tokens generated per second compared to sequential processing. This design means that vLLM actually becomes more efficient as concurrency increases — the GPU stays saturated with useful work rather than idling between requests. For production APIs serving many concurrent users, this translates directly into lower cost per token and higher overall system utilization.
-
Ollama
-
Ollama uses a sequential processing model, handling one request at a time through the inference pipeline. While this approach is simpler and more predictable, it means that throughput scales linearly with hardware rather than benefiting from batching efficiencies. That said, Ollama performs excellently for low-to-moderate concurrency workloads, and its predictable performance characteristics make it easier to reason about resource requirements on smaller nodes.
-
Expected Winner: vLLM (by design — continuous batching is fundamentally more throughput-efficient than sequential processing)
-
Latency
-
When measuring single-request latency in isolation, Ollama performs well for individual prompts because there is no batching overhead. The request goes directly into the model and comes back with minimal scheduling delay. However, this advantage diminishes rapidly as concurrency increases.
-
vLLM shines under load due to its batching efficiency. Because it processes multiple requests simultaneously, the amortized latency per request can actually decrease as more requests arrive — the GPU processes a batch of requests in roughly the same time it would take to process a single one.
-
Important Insight:
-If your system experiences burst traffic patterns — where many requests arrive in a short window — vLLM's latency often improves relative to sequential engines. While a sequential engine queues requests and processes them one at a time (leading to linearly increasing wait times), vLLM absorbs the burst into a batch and processes it as a unit.
-
Memory Usage
-
vLLM
-
vLLM provides explicit, fine-grained control over GPU memory allocation. In the Cube AI Docker Compose configuration (docker/vllm-compose.yml), this is configured with:
-
--gpu-memory-utilization 0.85
---max-model-len 1024
-
-
The --gpu-memory-utilization 0.85 flag tells vLLM to use up to 85% of available GPU memory, reserving the remaining 15% as a safety margin. The --max-model-len 1024 flag caps the maximum sequence length, which directly controls the KV-cache memory footprint. This level of explicit control is extremely valuable for capacity planning, because you can precisely predict how much GPU memory your deployment will consume and plan your infrastructure accordingly.
-
Ollama
-
Ollama takes a different approach, handling memory management automatically based on the loaded model's requirements. The memory footprint is model-dependent, and Ollama dynamically allocates and releases memory as models are loaded and unloaded. While this means less operational tuning overhead — you don't need to carefully configure memory utilization percentages — it also means less predictability in resource consumption, which can complicate capacity planning in tightly constrained environments.
-
Trade-off:
-
-
-
-| Goal |
-Better Choice |
-
-
-
-
-| Deterministic GPU planning |
-vLLM |
-
-
-| Operational simplicity |
-Ollama |
-
-
-
-
-
-
Cube AI deploys vLLM using the official OpenAI-compatible container image:
-
vllm/vllm-openai:v0.10.2
-
This image provides an OpenAI-compatible API server out of the box, which means any client or SDK that speaks the OpenAI protocol (specifically the /v1/chat/completions and /v1/models endpoints) can interact with vLLM without modification. The deployment requires the NVIDIA container runtime, as vLLM is designed exclusively for GPU-accelerated inference — it leverages CUDA for all compute operations and is not intended for CPU-only environments.
-
Under the hood, vLLM implements continuous batching, which dynamically groups incoming requests for parallel processing on the GPU. It loads models directly from HuggingFace by model identifier, caching them in a persistent Docker volume (vllm-cache) so that subsequent restarts don't require re-downloading the model weights. The model is defined at startup time through the VLLM_MODEL environment variable:
-
VLLM_MODEL=microsoft/DialoGPT-medium
-
-
-Model changes require a container restart — this is a deliberate design choice that stabilizes production behavior. By binding the model to the container lifecycle, vLLM ensures that the loaded model is always consistent and predictable, avoiding the complexity of runtime model swapping in performance-critical deployments.
-
-
When vLLM Is the Right Choice
-
Choose vLLM when your system demands high tokens-per-second throughput, multi-tenant inference where many users share a single GPU-backed endpoint, or maximum GPU utilization for cost efficiency. vLLM is particularly well-suited for production-scale APIs where predictable latency under load is a hard requirement, because the continuous batching engine ensures that response times remain stable even as request concurrency increases.
-
Typical environments where vLLM excels include enterprise AI platforms serving thousands of internal users, internal copilot systems integrated into developer workflows, retrieval-augmented generation (RAG) pipelines that need fast inference alongside document retrieval, and customer-facing LLM APIs where SLA commitments require consistent performance characteristics.
-
-
Ollama: Lightweight and Operationally Flexible
-
Cube AI ships Ollama using the official container image, tracking the latest stable release:
-
ollama/ollama:latest
-
When the Ollama profile starts, Cube AI automatically pulls a curated set of default models through sidecar containers that execute ollama pull against the running Ollama instance. These default models provide a ready-to-use baseline for chat, code generation, and text embedding:
-
-llama3.2:3b — a general-purpose conversational modelstarcoder2:3b — a code-oriented model for programming tasksnomic-embed-text:v1.5 — a text embedding model for semantic search and RAG pipelines
-
Major Strength: Runtime Model Management
-
One of Ollama's most significant advantages over vLLM is its ability to manage models at runtime without requiring a service restart. While vLLM binds its model to the container lifecycle (the model is loaded at startup and cannot be changed without restarting), Ollama provides a full model management API that allows you to pull new models from the Ollama registry on the fly, delete unused models to reclaim disk space, and push custom or fine-tuned models to a private registry. This capability dramatically improves developer velocity, because teams can experiment with different models — swapping between Llama, Mistral, CodeLlama, and others — without any downtime or infrastructure changes.
-
Hardware Flexibility
-
Ollama is designed to run across a wide range of hardware configurations, which makes it far more versatile than vLLM in terms of deployment targets:
-
-
-
-| Capability |
-Ollama |
-
-
-
-
-| CPU-only |
-Supported |
-
-
-| NVIDIA GPU |
-Supported |
-
-
-| AMD GPU (ROCm) |
-Supported |
-
-
-| Edge devices |
-Supported |
-
-
-
-
This broad hardware compatibility makes Ollama extremely attractive for deployment scenarios where GPU availability cannot be guaranteed. Confidential Virtual Machines (CVMs) running in Trusted Execution Environments may not have GPU passthrough configured, edge inference nodes may be running on commodity ARM hardware, on-premises deployments may need to operate on whatever hardware is available, and secure or air-gapped environments may have strict procurement constraints that limit GPU options. In all of these cases, Ollama's ability to run on CPU-only nodes provides a viable path to deploying LLM inference without GPU dependencies.
-
-
Deployment Scenarios and Trade-offs
-
To make the backend choice more concrete, here are four common deployment scenarios and the reasoning behind each recommendation.
-
Scenario 1 — Enterprise Production API
-
Recommended: vLLM
-
When you're building a production API that serves multiple teams, departments, or external customers, vLLM is the clear choice. Continuous batching ensures that the GPU stays efficiently utilized even under variable load patterns, and the OpenAI-compatible API means that existing client integrations — whether they use the official OpenAI SDK, LangChain, or custom HTTP clients — work without modification. The predictable scaling behavior of vLLM allows infrastructure teams to capacity-plan with confidence, knowing exactly how the system will behave as request volumes grow.
-
Scenario 2 — Confidential / Air-Gapped Environment
-
Recommended: Ollama
-
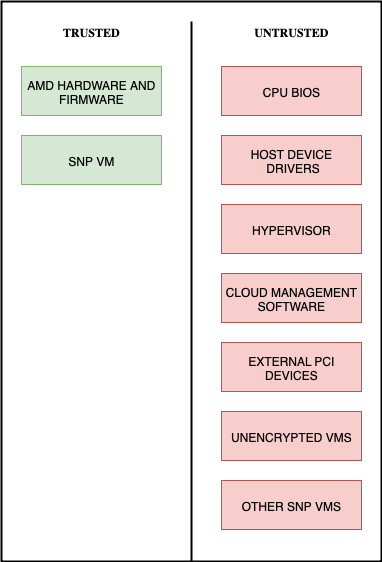
In confidential computing environments — such as CVMs running inside Trusted Execution Environments (TEEs) — or air-gapped networks where external connectivity is restricted, Ollama's operational characteristics become decisive advantages. Its runtime model management means that models can be pre-loaded, swapped, or updated without restarting the service, which is particularly important in environments where service restarts trigger re-attestation or security re-validation. Ollama's hardware flexibility means it can run on whatever compute is available inside the secure enclave, and its simpler dependency chain makes offline deployment and model provisioning significantly easier to manage.
-
Scenario 3 — Developer Sandbox
-
Recommended: Ollama
-
For development and experimentation environments, Ollama's minimal startup friction makes it the natural choice. Developers can spin up a local Ollama instance in seconds, pull different models to test against, and iterate rapidly without needing access to GPU infrastructure. The ability to dynamically swap models at runtime is especially valuable during the prototyping phase, where teams are evaluating which model best fits their use case before committing to a production deployment.
-
Scenario 4 — High-Concurrency SaaS
-
Recommended: vLLM
-
When building a multi-tenant SaaS product where hundreds or thousands of concurrent users are generating inference requests simultaneously, sequential processing engines become bottlenecks almost immediately. Each new concurrent request adds to the queue, and response times degrade linearly. vLLM's continuous batching architecture is specifically designed for this scenario — it absorbs concurrent requests into batches and processes them in parallel, maintaining stable response times even as concurrency scales.
-
-
Cost Analysis and Resource Requirements
-
Understanding the cost profile of each backend is essential for making financially sound infrastructure decisions, especially as LLM workloads grow from experimental to production scale.
-
-
-
-| Dimension |
-vLLM |
-Ollama |
-
-
-
-
-| Upfront Cost |
-High (requires NVIDIA GPUs, GPU orchestration) |
-Low (runs on CPU, standard instances) |
-
-
-| Cost per Token |
-Lower at scale (continuous batching) |
-Higher under load (sequential processing) |
-
-
-| Idle Cost |
-Expensive (reserved GPU capacity) |
-Minimal (standard compute) |
-
-
-| Best For |
-Sustained high traffic, predictable workloads |
-Early-stage, sporadic traffic, PoC |
-
-
-| Scaling Model |
-Vertical (GPU utilization) |
-Horizontal (more instances) |
-
-
-| Infrastructure |
-Specialized (NVIDIA runtime, GPU drivers) |
-Standard (no specialized requirements) |
-
-
-
-
vLLM Cost Profile
-
vLLM carries a higher upfront infrastructure cost because it requires dedicated NVIDIA GPUs, GPU-aware container orchestration (the Docker Compose configuration specifies runtime: nvidia with all GPU capabilities reserved), and careful capacity planning to ensure GPU memory is allocated efficiently. However, the cost per token at scale is significantly lower than sequential engines, because continuous batching maximizes GPU utilization — you're extracting more useful inference work from each dollar of GPU compute.
-
The key consideration is utilization: idle GPUs are expensive. If your vLLM instance sits idle for large portions of the day because traffic is light or sporadic, you're paying for reserved GPU capacity that isn't generating value. vLLM is most cost-effective when GPU utilization is consistently high, which typically means production workloads with steady or predictable traffic patterns.
-
Ollama Cost Profile
-
Ollama offers a much lower entry cost because it can run on standard CPU nodes, mixed GPU fleets (including AMD GPUs via ROCm), and smaller cloud instances. There is no requirement for specialized GPU drivers, NVIDIA container runtime, or dedicated GPU reservations. This makes Ollama an excellent choice for early-stage projects, proof-of-concept deployments, and environments where budget constraints preclude GPU infrastructure.
-
The trade-off is that the marginal cost per token under heavy load is higher than vLLM, because Ollama's sequential processing model cannot achieve the same throughput per hardware unit. As traffic grows, you'll need to scale horizontally (more Ollama instances) rather than relying on the batching efficiency of a single GPU-backed vLLM deployment.
-
Strategic Insight
-
Start with Ollama. Move to vLLM when concurrency justifies GPU spend.
-
This migration path is one of Cube AI's core design advantages. Because the backend is abstracted behind the agent proxy and a single environment variable, graduating from Ollama to vLLM is a configuration change — not a rewrite. Teams can validate their LLM use case with minimal infrastructure investment, then scale to GPU-accelerated inference when the workload demands it.
-
-
Integration Patterns with Cube AI
-
Proxy-Level API Exposure
-
The Cube AI proxy exposes inference endpoints in two API formats, giving clients flexibility in how they interact with the system.
-
OpenAI-Compatible
-
POST /{domainID}/v1/chat/completions
-GET /{domainID}/v1/models
-
-
These endpoints work with both vLLM and Ollama backends. vLLM natively speaks the OpenAI protocol, while Ollama also supports OpenAI-compatible endpoints. The {domainID} prefix allows the proxy to route requests to the correct domain-scoped backend instance, enabling multi-tenant deployments where different organizations or teams use separate inference endpoints.
-
Ollama-Native
-
POST /api/chat
-POST /api/generate
-GET /api/tags
-
-
These Ollama-native endpoints are available when Ollama is the active backend. Regardless of which backend is active, Cube AI provides OpenAI-compatible endpoints, so clients interact with a consistent API regardless of whether the underlying engine is vLLM or Ollama.
-
Guardrails Integration
-
Cube AI includes a guardrails pipeline built on NVIDIA's NeMo Guardrails framework, providing safety policies, sensitive data detection, and content filtering for all inference traffic. The guardrails system works seamlessly with both vLLM and Ollama backends — because the guardrails sit upstream of the agent proxy, they are completely backend-agnostic. Regardless of which inference engine is active, all chat traffic passes through the same guardrails pipeline before reaching the LLM, ensuring consistent safety and compliance enforcement across backend configurations.
-
HAL: Beyond Containers
-
Cube AI doesn't stop at Docker containers. Both vLLM and Ollama are fully packaged inside the Hardware Abstraction Layer (HAL), which is built on Buildroot to produce minimal Linux images for bare-metal and CVM deployments. Each backend includes:
-
-- Systemd service units —
ollama.service and vllm.service provide proper service lifecycle management with automatic restart, journal logging, and dedicated service users (ollama and vllm respectively)
-- SysV init scripts —
S96ollama and S96vllm provide backward-compatible init support for environments that don't use systemd
-- Auto model provisioning — the Ollama HAL package includes a
pull-models.sh script that automatically pulls configured models on first boot, with retry logic (up to 20 attempts with 5-second backoff) to handle slow network conditions in CVM environments
-
-
This HAL integration enables bare-metal CVM deployments where Docker is not available or not permitted — a critical advantage for confidential AI environments where the entire software stack must run inside a hardware-attested Trusted Execution Environment.
-
-
Side-by-Side Comparison
-
-
-
-| Dimension |
-Ollama |
-vLLM |
-
-
-
-
-| Version |
-0.12.3 |
-0.10.2 |
-
-
-| API |
-Native /api/* |
-OpenAI /v1/* |
-
-
-| GPU |
-Optional |
-Required (NVIDIA) |
-
-
-| CPU Support |
-Yes |
-No |
-
-
-| Model Mgmt |
-Runtime |
-Startup |
-
-
-| Batching |
-Sequential |
-Continuous |
-
-
-| Default Model |
-llama3.2:3b |
-DialoGPT-medium |
-
-
-| Memory Config |
-Automatic |
-Explicit |
-
-
-| Guardrails |
-Native adapter |
-Via OpenAI |
-
-
-| Compose Profile |
-default |
-vllm |
-
-
-
-
-
The Architectural Insight That Matters Most
-
Cube AI treats inference engines like infrastructure plugins — not hard dependencies, not vendor lock-in points, but interchangeable modules that can be swapped, upgraded, or replaced without rippling changes through the rest of the system.
-
This is possible because the agent proxy creates a clean abstraction boundary between the application and the inference engine. The proxy handles authentication, header management, connection pooling, and request forwarding, while the dynamic router directs traffic based on configurable rules. The application code, the guardrails pipeline, and the client SDKs never communicate directly with vLLM or Ollama — they talk to the proxy, and the proxy talks to whatever backend is currently configured.
-
The practical consequence of this design is significant: your application never needs to know which backend is running. This dramatically reduces platform risk, because you're never locked into a single inference engine's API, deployment model, or hardware requirements. If a better engine emerges, or if your requirements change, the migration is a configuration change — not an architecture overhaul.
-
-
Decision Framework
-
Choose vLLM if:
-
-- You are operating at production scale with sustained or growing traffic, where GPU efficiency translates directly into cost savings
-- Latency consistency under concurrent load is a hard requirement, such as customer-facing APIs with SLA commitments
-- GPU clusters are available and you have the operational expertise to manage GPU-aware orchestration
-- You need maximum throughput per hardware unit and are willing to invest in the infrastructure to achieve it
-
-
Choose Ollama if:
-
-- You value operational flexibility and the ability to experiment with different models without infrastructure changes
-- You deploy to edge nodes, Confidential Virtual Machines (CVMs), or other environments where GPU availability is uncertain
-- You need runtime model control — the ability to pull, swap, and delete models without restarting the inference service
-- You are cost-sensitive in the early stages of your AI deployment and want to validate your use case before committing to GPU infrastructure
-
-
-
Key Takeaway
-
Cube AI eliminates the traditional trade-off between performance and flexibility by treating the LLM backend as an infrastructure plugin behind a clean proxy abstraction.
-
You do not need to commit to an inference engine early in your project. You can start with Ollama for development and proof-of-concept, validate your use case with real users and real data, and then evolve your backend to vLLM when concurrency and throughput requirements justify the GPU investment — all without changing a single line of application code.
-
Start lightweight. Scale when necessary. Switch without friction.
-
That is the power of backend modularity, and it is built into the foundation of Cube AI's architecture.
-
-
Explore Cube AI's backend architecture in the Deployment Guide or learn more about Cube AI Architecture.
-
 -
- 

 -
-
-
-
-
-  -
-
-
-
-
-  -
-
-
-
-
-  -
-
-
-
-
- 
 -
- 

 -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-
-
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+