A verifiable autonomous coding agent (CLI). Built with TypeScript on the Bun runtime.

Real engine, real bun test verify gate, real HMAC ledger — only the model is scripted (ALFRED_MOCK_SCRIPTS), so the demo is keyless and deterministic. Reproduce it: bun run demo. Regenerate the GIF: vhs docs/demo.tape (tape).
Alfred is not another Claude Code clone. Its thesis: the long-running harness is executable, "done" is a machine-enforced gate, memory is agent-curated but inspectable, and every hands-off run leaves a signed, replayable receipt. Where the field is ahead on streaming/sandbox/caching parity, Alfred leans into the one thing it designs better — enforced, auditable autonomy — while still adopting the best ideas from across the ecosystem (docs/improvement-proposal.md).
Status: 955 tests passing ·
tsc --noEmitclean · zero runtime dependencies beyond@anthropic-ai/sdk,commander,zod.
📖 Full documentation: beamuswayne.github.io/Alfred — built from docs/ with VitePress (bun run docs:dev to preview locally, deployed by .github/workflows/docs.yml). Jump to Quickstart · CLI reference · Subsystems · Architecture.
📦 Install — one line, runtime included (installs Bun if missing, then alfred-agent; macOS/Linux/WSL2):
curl -fsSL https://raw.githubusercontent.com/BeamusWayne/Alfred/main/install.sh | bashAlready on Bun ≥ 1.3? bun install -g alfred-agent (the command is alfred) — or bunx alfred-agent one-shot. This is a Bun CLI, not a Node one. After installing: alfred demo (30-second offline proof, no key) → alfred init (interactive provider setup) → alfred doctor (check everything). Clone the repo for the docs, tests, bench, and the demo below.
# No clone, no key — the same offline proof ships in the npm package:
bunx alfred-agent demo
bun install
# Zero-key offline demo: a scripted model drives the REAL harness end-to-end —
# engine, tools, verify gate and signed ledger all run for real (no API calls)
bun run demo # implement → verify gate exit 0 → rubric 2/2 → signed ledger
bun run demo:verify # ✓ ledger intact — then flip one byte and watch it fail
# One-shot agent run (text → stdout, traces → stderr)
export ANTHROPIC_API_KEY=sk-ant-...
bun run src/index.ts -p "explain what this repo does"
# Autonomous harness: drive a feature_list.json to green under a verify gate
ALFRED_LEDGER_SECRET=$(openssl rand -hex 32) \
bun run src/index.ts run --verify "bun test" --max-features 5
# Replay recorded trajectories as regression tests (CI gating)
bun run src/index.ts eval ./my-cases.ts
bun test tests # 797 tests
bun run typecheck # tsc --noEmit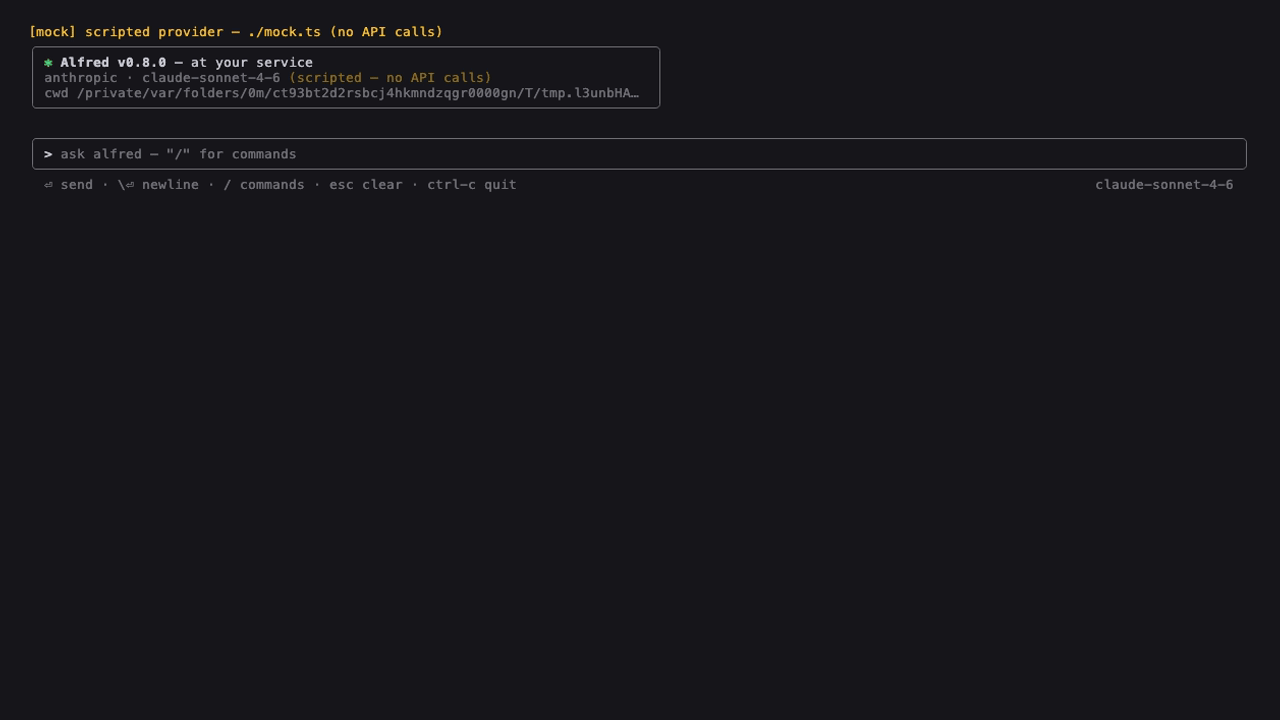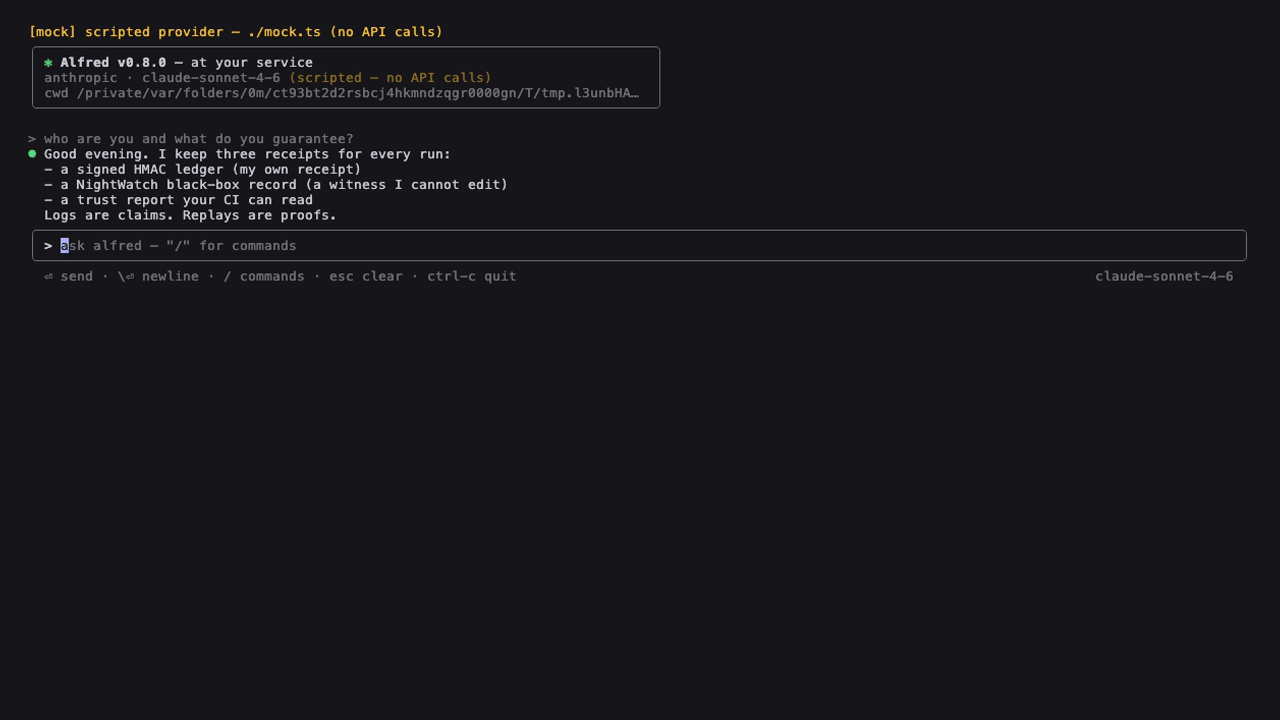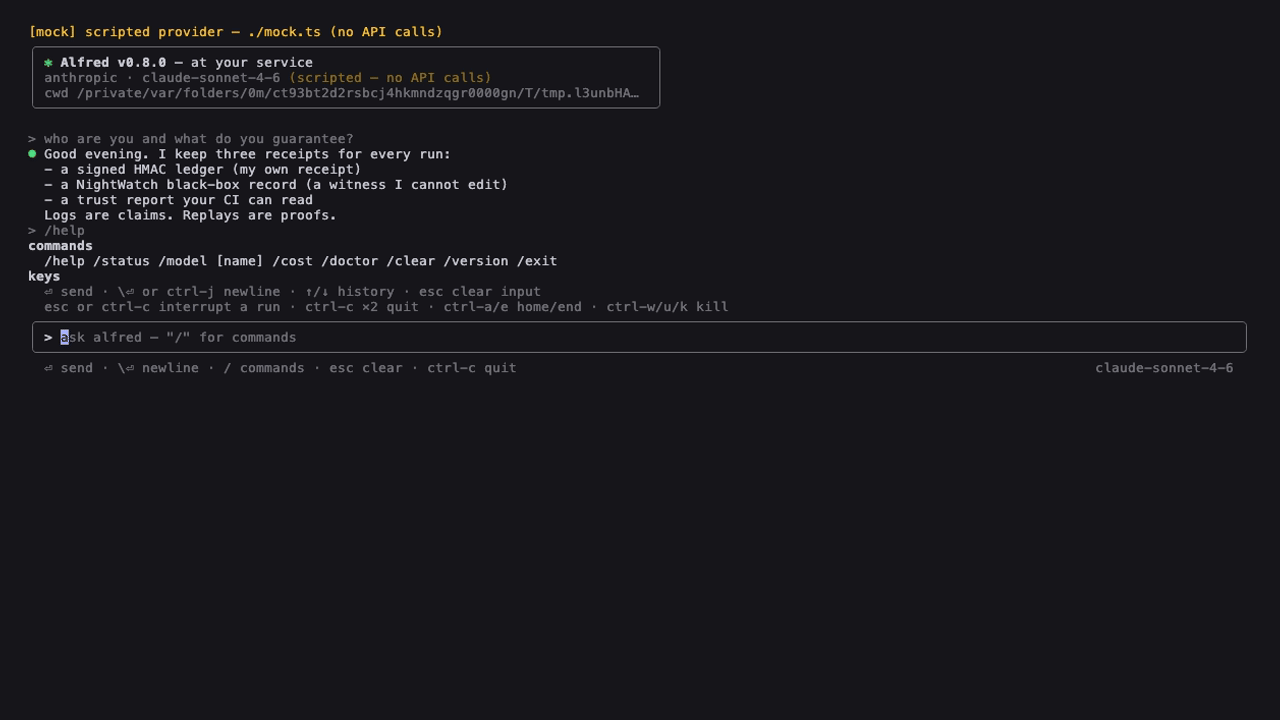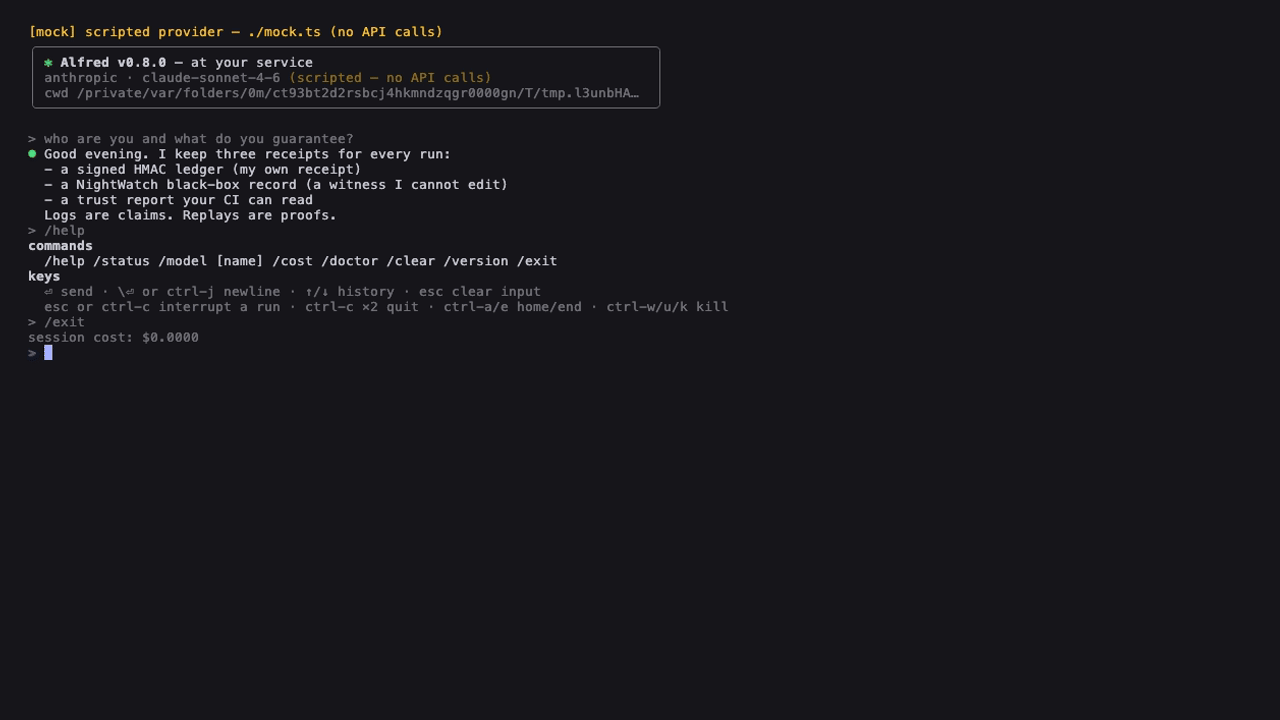
The interactive TUI (alfred on a TTY, 0.8+) — keyless demo via the scripted provider. Regenerate: vhs docs/tui.tape.
| Command | What it does |
|---|---|
alfred |
Bare: an interactive TUI on a TTY — bordered input box, streaming ⏺ responses with tool beats, slash-command menu (/ + ↑/↓/Tab), arrow-key tool approval, prompt history, esc interrupts. Zero new deps (hand-rolled ANSI, CJK-correct). ALFRED_TUI=0 falls back to the 0.3 thin REPL; the status screen everywhere else. |
alfred [prompt] |
One-shot agent run. -p print mode (reads stdin when piped); --model, --permission-mode, --max-turns, --yes. |
alfred run |
The autonomous harness as a workflow: a feature_list.json state machine → verify-fix loop → rubric gate → signed run ledger. Human progress by default, --json for the raw event stream. Flags: --feature-list, --verify, --max-features, --rollback-on-block, --budget-usd. |
alfred demo |
30-second offline proof in a temp sandbox: RED gate → scripted model drives the real harness → signed ledger → one-byte tamper drill. No API key. |
alfred init |
Scaffold feature_list.json (+ .gitignore entry) — and, on a TTY, interactive provider setup: endpoint / API key (masked) / model → ./.env (chmod 600, gitignored, auto-loaded by Bun). Rerun any time to reconfigure. |
alfred why [runId] |
Explain a run from its receipts: blocked features, verify exits, rubric reasoning (--json). |
alfred watch [path] |
Follow a run's journal + ledger as a read-only live panel — attach from another terminal, or replay a finished run. Sticky status line: elapsed · features · spend. |
alfred eval <file> |
Replay recorded MockProvider trajectories through the real engine and assert tool-sequence / status / text regressions. Exits non-zero on failure. |
alfred ledger verify [path] |
Recompute a run ledger's HMAC hash chain + signed head anchor (defaults to the latest run). Exit 2 on any tamper — flip one byte and it fails. --trust-report <file> also writes the verdict as a cross-tool Trust Report v0. |
alfred ledger show [--md] |
Render the receipt as a table; --md is paste-ready for a PR description. |
alfred status |
Provider/key · feature_list · last run · next steps, at a glance. |
alfred doctor |
One-pass setup diagnosis: runtime, key, hooks, feature_list, ledger secret, last receipt, git, recorder. Every warn/fail comes with the fix. |
alfred update |
Self-update to the latest published release. |
alfred completion <shell> |
bash/zsh completion script. |
Exit codes, everywhere: 0 success · 1 failure / not found · 2 ledger tampered.
Layers over a clean agent loop — each new piece is additive, not a rewrite. The mapping to the architecture decision records lives in docs/adr/.
alfred run / exec ─▶ ORCHESTRATION (src/orchestrator) ──── agent()/parallel()/pipeline()
journal (resume/replay) · token budget · HMAC ledger
│ drives
AUTONOMY HARNESS (src/harness) ─────── feature_list state machine ·
verify gate · rubric · checkpoint/rollback workflows/autonomousRun
│ uses
AGENT LOOP (src/query) ── MEMORY (src/memory) ── TOOLS · PERMISSIONS · SANDBOX · CONTEXT
retry · fallback · file-first, FTS5, fs/bash/glob/grep/web_fetch/memory/skill
stream · compaction · episodes, GC spawn_subagent (depth-capped fan-out)
typed status · cost fuzzy-edit · syntax check · hooks · MCP · LSP
└──────── PROVIDERS (anthropic / openai / mock) ────────┘
cross-cutting: security (taint/egress/redact/quarantine) · telemetry (OTel) · routing
- Agent loop (
src/query/) — async-generator loop with retry/backoff + model fallback chain, typed terminal status, permission gating, parallel read-only tools, token streaming, context compaction, OTel spans + running cost. - Memory v2 (
src/memory/, ADR 0001 §4) — file-first tiered store (USER.md+MEMORY.mdindex +facts/*.md+episodes/), SQLite FTS5 search, staleness/contradiction GC. Model-facingmemory_search/upsert/forgettools. - Orchestrator (
src/orchestrator/, ADR 0001 §5) —agent()/parallel()/pipeline()/log()runtime over the engine, append-only journal (resume + replay tape), token budget, and an HMAC hash-chained ledger (the Proof Receipt).best-of-Ninference-time scaling. - Harness (
src/harness/, ADR 0001 §7.7) —feature_list.jsonstate machine, an objective verify gate (trusts only an exit code), a rubric self-eval gate, git checkpoint/rollback.workflows/autonomousRun.tsis the flagship. - Code intelligence (ADR 0002) — repo map (
src/context/repomap.ts, PageRank into a token budget), post-edit tree-sitter-style syntax check infile_edit, and an LSP client (src/tools/lsp/). - Agent-layer security (
src/security/, ADR 0003) — taint fence, egress allow-list (default-deny), secret redaction, and a dual-LLM quarantine for untrusted content.web_fetchis the model citizen for all three. - Observability (
src/telemetry/,src/cost/, ADR 0004) — OTel GenAI semantic-convention spans, a cost tracker, and an eval harness (src/eval/). - Model routing (
src/config/roles.ts, ADR 0005) — architect/editor/subagent role→model map + fallback chain. Providers: Anthropic + OpenAI + a scriptable mock. - Extensibility — hooks (
src/hooks/, six lifecycle events with Claude Code-compatible payloads — see the trust-layer section below), OS sandbox (src/sandbox/, macOS seatbelt), MCP client (src/mcp/), 3-level skills (src/skills/).
| Env var | Effect |
|---|---|
ANTHROPIC_API_KEY / OPENAI_API_KEY |
Provider credentials. |
ALFRED_PROVIDER |
anthropic (default) or openai. |
ALFRED_BASE_URL |
Override the provider base URL — point at any Anthropic-compatible endpoint (e.g. Zhipu GLM). |
ALFRED_MODEL |
Default model. ALFRED_MODEL_{ARCHITECT,EDITOR,SUBAGENT} for role routing — a bare model id, or provider:model (e.g. openai:gpt-5.2) to pin a role to another provider. |
ALFRED_EFFORT |
Reasoning effort on supporting models: low/medium/high/xhigh/max. Defaults per role (architect xhigh, editor medium, subagent low). |
ALFRED_THINKING=none |
Opt out of adaptive thinking (on by default for models that support it, e.g. Claude Fable 5 / Opus 4.6+ / Sonnet 4.6). |
ALFRED_MEMORY=1 |
Inject agent memory Core + run staleness GC on session end. |
ALFRED_REPOMAP=1 |
Inject a repo map into the system prompt. |
ALFRED_SANDBOX=1 |
Run bash inside an OS sandbox (macOS seatbelt; no-op elsewhere). |
ALFRED_OTEL_FILE=path.jsonl |
Export OTel GenAI spans. |
ALFRED_EGRESS_ALLOW=host1,*.host2 |
web_fetch egress allow-list (default-deny). |
ALFRED_LEDGER_SECRET |
HMAC secret for the autonomous run ledger. |
ALFRED_VERIFY_CMD |
Default verify command for alfred run (default bun test). |
ALFRED_VERIFY_FAST_CMD |
Optional fast pre-gate (affected tests / tsc / lint). Failures short-circuit the fix loop; only the full gate can pass a feature. |
ALFRED_SERVER_COMPACT=0 |
Opt out of server-side context compaction (on by default for supporting Anthropic models). |
The anthropic provider speaks the Messages API, so any compatible gateway works by pointing ALFRED_BASE_URL at it — no code change. Zhipu GLM works out of the box (and is exercised end-to-end in this repo's dogfood):
export ALFRED_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_API_KEY="<your-zhipu-key>"
bun run src/index.ts -p --model glm-5.1 "hello"
# the same env applies to `alfred run`Pricing for glm-4.5 / glm-4.6 / glm-5.1 ships in the cost table; unknown models fall back to a default estimate.
.alfred/
memory/ USER.md · MEMORY.md · facts/<slug>.md · episodes/ · index.db
skills/ <name>/SKILL.md (Level-1 index auto-injected; load_skill loads bodies)
hooks.json (hook matchers — six events, CC-compatible payloads)
models.json (model capability overrides — see below)
workflows/<runId>/journal.jsonl (resume/replay tape)
workflows/<runId>/ledger.jsonl (HMAC hash-chained Proof Receipt)
.alfred/hooks.json matchers fire at six lifecycle events — SessionStart,
UserPromptSubmit, PreToolUse, PostToolUse, Stop, SessionEnd — in every
surface, including unattended alfred run. Each hook receives a Claude
Code-compatible JSON payload on stdin (session_id, cwd,
hook_event_name, tool_name, tool_input, tool_response, prompt,
source, model; the pre-0.7 toolName/input keys remain), so tooling
built for that hooks ecosystem works on Alfred unchanged. Exit 2 blocks on
PreToolUse and UserPromptSubmit; stdout {"updatedInput":{…}} rewrites tool
input; everything else is observe-only.
{
"hooks": [
{ "event": "PreToolUse", "toolPattern": "bash", "command": "./guard.sh", "timeoutMs": 5000 }
]
}Alfred is the Run leg of the Agent Trust Layer — three tools that replace "the agent said so" with verifiable evidence:
- Record — NightWatch is a
black-box flight recorder that plugs straight into Alfred's hooks:
One run, two independent witnesses: Alfred's own HMAC-signed receipt (signed with a secret the agent never sees) and NightWatch's external hash-chained ledger (a record the agent cannot edit).
npm i -g nightwatch-agent nightwatch init --agent alfred # wires .alfred/hooks.json (idempotent) alfred run --verify "bun test" # the night happens nightwatch debrief # the morning: claims re-verified, not retold
- Gate — trace-vault replays recorded agent runs offline in CI and scores determinism and faithfulness separately.
- One verdict format — all three emit Agent Trust Report v0:
alfred ledger verify --trust-report r.jsonhere,nightwatch attest --trust-reportandvault gate --trust-reportthere. One CI consumer for every gate. A real dual-witness run, raw ledgers included, is committed in the spec repo's examples.
The capability catalog (src/config/modelCatalog.ts) drives context ceilings,
max_tokens defaults, and which parameters each model may receive. Unknown
models get a conservative default; to unlock a new model's real capabilities
without forking, add a partial entry keyed by model-id prefix:
{
"gemini-3.1-pro": {
"contextWindow": 1000000,
"maxOutput": 65536,
"supportsEffort": true,
"tier": "frontier"
}
}Unset fields inherit the built-in entry with the same key (if any), else the conservative default. Invalid files warn and are ignored.
Two orthogonal axes (ADR 0001 §7.3, ADR 0003): a tiered approval policy (allow/ask/deny — a hard DENY and the bash kill-list beat even bypass) and a content-trust boundary. Untrusted tool output (web_fetch, MCP) is tainted and fenced as data-not-instructions; egress is allow-listed; secrets are redacted; and untrusted content can be routed through a quarantined, tool-less sub-agent (dual-LLM). No mainstream harness ships this lethal-trifecta defense — it is Alfred's most on-brand differentiator.
| Phase | Scope | Status |
|---|---|---|
| 0 | Foundations (wired prompt, retry, permissions, fuzzy edit, typed status, syntax check) | ✅ |
| 1 | Memory v2 + repo-map + security primitives + model routing + compaction | ✅ |
| 2 | Orchestrator + harness-as-workflow + alfred run (signed ledger) |
✅ |
| 3 | Parity + extensibility: streaming, caching, hooks, sandbox, MCP, skills, OpenAI, LSP, eval, best-of-N | ✅ |
| 4 | Alfred-Bench — rebuild itself from an empty src/ under held-out verification |
scaffolded — see docs/alfred-bench.md |
Known follow-ups (libraries built + tested, startup wiring pending): MCP/LSP server bootstrap from .alfred/{mcp,lsp}.json; cross-provider fallback (model→provider routing).
Design docs: docs/improvement-proposal.md (the best-of-breed synthesis) and docs/adr/0001–0005.
MIT