

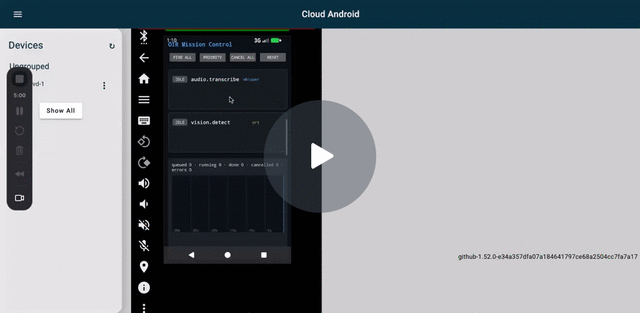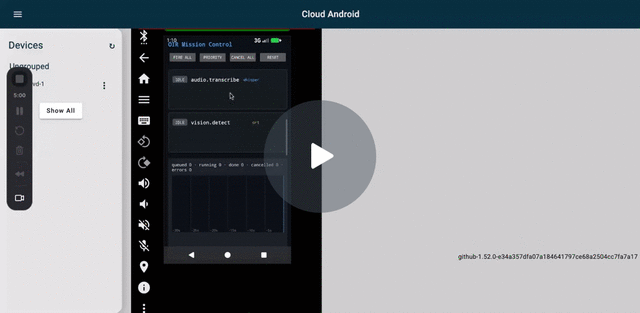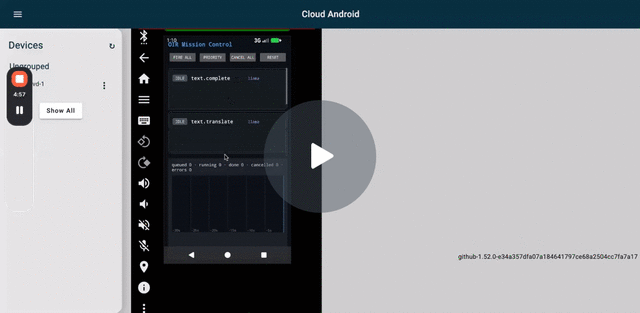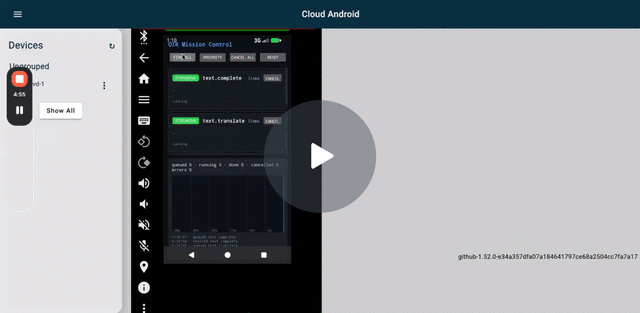
v0.6.9 Fire All on Cuttlefish — 5 capabilities streaming concurrently through the OIR platform service.
▶ Watch the full ~2 min demo
🚧 Active clean-clone validation in progress (2026-04-26) — the public repos were migrated from a private monorepo and are being shaken down for first-time-user build issues right now. If you hit a build error, check the issues tracker or the
#clean-clonediscussions. Fixes are landing within 24 hours.
An Android 16 fork where AI is a platform primitive, not an app feature.
Twelve AI capabilities — text completion, translation, embeddings, classification, rerank, transcription, synthesis, VAD, image embeddings, description, detection, OCR — exposed to every app on the device through a single binder AIDL. One system service. One native daemon. Four pluggable backends. Pooled residency. Per-UID rate limits. Priority-aware scheduling. OEM-configurable per capability. Models load once at the platform tier and are shared across every app that asks.
This is runtime infrastructure, not a chatbot. The closest mental model is "a kernel for on-device inference" — the OS owns the hardware (well, the model + the KV cache), schedules access, enforces permissions, accounts memory. Apps make system calls (well, binder calls) and get answers.
Named after Puerto Rico's jíbaros — rural folk, known for resilience and self-sufficiency. Models and runtime live on the device, work offline, no cloud account required.
⭐ Star this repo — it's the cheapest signal that on-device AI belongs at the platform tier, and it helps the right contributors find the project.
Every new AI feature on Android today means an app bundles its own model, its own runtime, its own tokenizer — easily 300+ MB of duplication per app. When three apps ship LLM assistants, the user pays the cost three times over. When the device has 8 GB RAM, two resident LLMs already push the budget.
JibarOS flips that. Load once, serve many. An app calls OpenIntelligence.text.completeStream("…") and the runtime figures out the rest — which model, which context pool, priority relative to other in-flight requests, memory budget, cancellation. Shipping this at the platform tier is the only way on-device AI scales past the first couple of apps.
OEMs pick the actual backing model per capability (small VLM for a thin phone, 7B LLM for a flagship). Apps targeting the capability surface don't change.
Google's AICore (the system AI service on Pixel and select Samsung devices) is the right architecture — AI as a platform service — with the wrong governance. AICore ships closed-source: Google-served models (Gemini Nano), signed by Google, app access gated by an allowlist, single-vendor control. OEMs not in Google's program either build their own parallel stack (Samsung Gauss, etc.) or wait. Third-party developers wanting on-device AI today either pick a vendor lock-in (AICore APIs, ML Kit GenAI), bundle their own model + runtime per app (300+ MB duplicated), or both.
JibarOS keeps the platform-service shape and trades the gatekeeping for openness:
| AICore | JibarOS | |
|---|---|---|
| Source | Closed | Apache 2.0 |
| Model selection | Google-curated (Gemini Nano) | Any GGUF / ONNX / GGUF mtmd |
| Per-OEM bake-in | Google-approved only | Any OEM, any model per capability |
| App access | Allowlist | oir.permission.USE_* |
| Backends | Single Google runtime | llama.cpp / whisper.cpp / ONNX Runtime / libmtmd |
| Capability surface | Curated (sumarize, image-describe, …) | 12 capabilities, OEM-extensible via <capability> |
Same conviction (on-device AI is platform infrastructure), opposite governance.
JibarOS is mechanism, not policy — but here's what the mechanism enables. None of these are promised features; they're shapes of products people could build once on-device AI is shared platform infrastructure rather than a Google-curated cloud API or a per-app duplicated runtime. Half of these are the reason the architecture exists.
- Connectivity-denied rugged devices — defense, maritime, mining, oil & gas, search-and-rescue. Tablets and handhelds where backhaul is intermittent, jammable, or simply absent. The runtime is the whole AI stack; nothing leaves the device.
- Privacy-regulated workflows — clinical scribes generating structured notes from doctor-patient conversations, therapy + coaching companions, clinical translation in multilingual care, legal-discovery tooling. Patient / client utterance never crosses a network.
- Body-worn cameras and dashcams — record + transcribe + redact (faces, plates) on-device before footage ever reaches the evidence locker. Privacy by design, no cloud chain-of-custody surface area.
- Latency-critical interaction — AR translation overlays, live captioning for deaf users, voice-controlled vehicles, robot safety-stops. Anywhere a 200 ms cloud round-trip is the difference between "natural" and "broken."
- Robotics — warehouse pick-and-place, last-mile delivery, eldercare service robots. Multimodal sensing + reasoning where the actuators are physical and the network is a liability, not an asset.
- Industrial-floor and field tools — air-gapped manufacturing HMIs, agricultural drones and tractors, EV charging kiosks, smart vending. The device maker picks the model bake-in for the workload — not Google, not Samsung, not us.
- Personal-data consumer apps — journaling, education aids, mental-health companions. Things people choose precisely because their content doesn't leave the device.
If you're prototyping in any of these spaces — open an issue in the main repo or start a discussion. Real use cases shape the runtime more than any roadmap.
┌────────────────────────────────────────────────────────────────┐
│ Apps (any UID) │
│ OpenIntelligence.text.completeStream(...) / OpenIntelligence.audio.transcribeStream(...)│
│ │ OpenIntelligence.vision.describe(...) / OpenIntelligence.vision.detect(...) │
│ ▼ │
├────────────────────────────────────────────────────────────────┤
│ OIRService (system_server) │
│ ├─ enforces oir.permission.USE_TEXT / USE_AUDIO / USE_VISION │
│ ├─ per-UID rate limiting (token bucket) │
│ ├─ capability registry (capabilities.xml + OEM fragments) │
│ └─ dispatches to oird over IOirWorker AIDL │
├────────────────────────────────────────────────────────────────┤
│ oird (native daemon, /system_ext/bin/oird, u:r:oird:s0) │
│ ├─ shared model residency — one load per capability │
│ ├─ ContextPool / WhisperPool (priority-aware wait queues) │
│ ├─ KV-cache memory accounting + LRU eviction │
│ └─ cross-backend scheduler with per-capability priority │
├────────────────────────────────────────────────────────────────┤
│ Backends │
│ llama.cpp │ whisper.cpp │ ONNX Runtime │ libmtmd │
│ (GGUFs) │ (.bin) │ (.onnx) │ (VLMs) │
└────────────────────────────────────────────────────────────────┘
Three load-bearing ideas:
- Capability, not tensor. Apps ask for
text.completeorvision.describe. They never touch tensors, runtimes, or tokenizers. The platform owns the inference graph. - One loaded model per capability, shared across every caller. If three apps want
text.complete, the GGUF loads once. KV cache is budgeted. Contexts are pooled. Concurrent inference interleaves at the pool-slot level. - Mechanism, not policy. The runtime does inference, residency, and scheduling. Agent orchestration, memory tiers, tool dispatch, conversation state — those are not in OIR. They sit above.
| Capability | Shape | Reference backend | Permission |
|---|---|---|---|
text.complete |
TokenStream | Qwen 2.5 0.5B Q4_K_M (llama.cpp) | USE_TEXT |
text.translate |
TokenStream | shared with text.complete |
USE_TEXT |
text.embed |
Vector | all-MiniLM-L6-v2 Q8_0 (llama.cpp) | USE_TEXT |
text.classify |
Vector | OEM-supplied ONNX classifier | USE_TEXT |
text.rerank |
Vector | OEM-supplied (ms-marco-MiniLM-style) | USE_TEXT |
audio.transcribe |
TokenStream | whisper-tiny.en Q5 (whisper.cpp) | USE_AUDIO |
audio.synthesize |
AudioStream | OEM-supplied Piper voice + G2P sidecar (ONNX Runtime) | USE_AUDIO |
audio.vad |
RealtimeBoolean | Silero VAD (ONNX Runtime) | USE_AUDIO |
vision.embed |
Vector | SigLIP-base-patch16-224 (ONNX Runtime) | USE_VISION |
vision.describe |
TokenStream | OEM-supplied VLM via libmtmd (LLaVA / SmolVLM / …) | USE_VISION |
vision.detect |
BoundingBoxes | RT-DETR-R50vd-COCO (ONNX Runtime) | USE_VISION |
vision.ocr |
BoundingBoxes | OEM-supplied det+rec pair (ONNX Runtime) | USE_VISION |
Full details: docs/CAPABILITIES.md.
JibarOS declares the capability contract; OEMs pick the backing model. Two mechanisms:
Platform bake-in — the reference Cuttlefish build ships 3 permissive-license models via oir-vendor-models (Qwen 2.5 0.5B + MiniLM + whisper-tiny-en, Apache 2.0 + MIT) plus a CC0 voice-sample WAV for the demo. PRODUCT_PACKAGES += oir_default_model oir_minilm_model oir_whisper_tiny_en_model oir_voice_sample_wav installs them to /product/etc/oir/ at build time. Together they cover 4 of the 5 OirDemo capabilities (text.complete + text.translate share Qwen). vision.detect needs an OEM-supplied detector (RT-DETR Apache 2.0 is the recommended permissive option).
Per-OEM override — drop /vendor/etc/oir/oir_config.xml on your image:
<oir_config>
<capability_tuning>
<capability name="vision.describe">
<default_model>/product/etc/oir/mmproj.gguf|/product/etc/oir/llm.gguf</default_model>
</capability>
</capability_tuning>
</oir_config>Swap LLaVA-1.5-7B for SmolVLM-500M on a thin device. No framework changes, no app changes. Full guide: docs/MODELS.md.
Shared residency. Every app calling OpenIntelligence.text.completeStream hits the SAME loaded model. That model has a context pool with N slots (default 4 for text.complete); each slot is an independent llama_context with its own KV cache. Concurrent submits interleave at the slot level.
Budget accounting. Every loaded model reports weights + pool KV cache in its resident footprint. When a new load would exceed the configured memory budget, LRU eviction runs — skipping models that are in-flight or inside a warm() TTL window.
Priority-aware queues. audio.* capabilities default to AUDIO_REALTIME; everything else to NORMAL. Queued audio submits jump ahead of queued text submits within a shared pool. Priority is queue-order, not preemption — a long in-flight completion runs to completion.
Concurrency proof. v0.6.9 Fire All validated on Cuttlefish: 5 concurrent submits across 3 backends (text.complete + text.translate + text.embed via llama; audio.transcribe via whisper; vision.detect via ONNX Runtime), 4 distinct loaded models (Qwen shared by complete + translate). All resolved without hangs. See the Loom above.
OEMs tune per-capability behavior via /vendor/etc/oir/oir_config.xml. Global knobs: memory budget, warm TTL, inference timeout, rate limits. Per-capability: context window, max tokens, contexts-per-model, acquire timeout, priority, temperature, top-p, preprocess sizes, detection thresholds.
Full reference: docs/KNOBS.md.
Apps consume OIR via the oir-sdk Kotlin library. Structured concurrency, typed errors, Java interop.
import com.oir.OpenIntelligence
OpenIntelligence.text.completeStream("Summarize this in one sentence: …")
.collect { chunk -> print(chunk.text) }
val vector: FloatArray = OpenIntelligence.text.embed("vector me")
OpenIntelligence.audio.transcribeStream("/sdcard/voice.wav")
.collect { chunk -> println(chunk.text) }
val boxes = OpenIntelligence.vision.detect("/sdcard/photo.jpg")Full guide: docs/SDK.md.
Builds directly on AAOSP — the earlier Android 15 fork that first put an LLM inside system_server as a platform service (LlmManagerService) and introduced MCP tool-calling at the manifest layer.
AAOSP proved the core insight: on-device AI belongs at the platform tier, not bundled per-app. Any app with an <mcp-server> declaration becomes reachable by the platform LLM. HITL consent + audit is a platform invariant.
JibarOS extends that pattern to a broader runtime surface on Android 16. Where AAOSP's LlmManagerService is purpose-built for MCP tool-calling with one llama.cpp LLM, OIR is the general inference layer: 12 capabilities across text/audio/vision, four pluggable backends (llama.cpp / whisper.cpp / ONNX Runtime / libmtmd), pooled residency, KV budget, cross-backend priority scheduler. An AAOSP-style MCP agent, or any other agent framework, could sit on top of OIR and use it as the inference substrate — that's what "mechanism, not policy" means in practice.
Complementary, not competitive.
mkdir jibar-os && cd jibar-os
repo init -u https://github.com/Jibar-OS/JibarOS -b main
repo sync -c -j8
./.repo/manifests/tools/jibar-os-bake.sh
cd vendor/oir-models && ./tools/fetch-models.sh # pull reference models
cd ../..
source build/envsetup.sh
lunch aosp_cf_x86_64_phone-trunk_staging-userdebug
m
launch_cvd --start_webrtcFull guide: docs/BUILD.md.
See docs/OVERVIEW.md#repos for the full list. Core:
jibar-os— this repo (manifest + docs)oird— native inference daemonoir-framework-addons— OIRService + AIDLoir-patches— 5 small patches to upstream AOSPoir-sdk— Kotlin SDK for appsoir-demo— OirDemo Mission Controloir-vendor-models— reference model bundle + fetch scriptdevice_google_cuttlefish— reference device tree
External backend forks: platform_external_llamacpp, platform_external_whispercpp, platform_external_onnxruntime.
Pre-1.0. Validated on Android 16 Cuttlefish with SELinux Enforcing. No real-device ports yet. Looking for device contributors — see CONTRIBUTING.md. Public roadmap: docs/ROADMAP.md.
JibarOS is pre-1.0 and small. The two things we need most:
A real device to port to. v0.6.9 is validated on Cuttlefish (the AOSP emulator). The next milestone is a real-device port — Pixel 8 / 8a / 9 are the most tractable targets because their device trees are well-documented and the AOSP cuttlefish → pixel diff is contained. If you have a Pixel sitting in a drawer (or want to chip in toward one), open a discussion — that's the single biggest accelerator on the v0.8 roadmap right now.
Code + docs contributions. Capability backends, device tree ports, test harnesses, OEM bake-in playbooks. See CONTRIBUTING.md. Lowest-barrier first commits: oir-demo (Kotlin demo app), docs/ (clarify whatever confused you), oir-vendor-models (curate permissively-licensed model recipes).
Funding: GitHub Sponsors button is on the way (pending GitHub's org-application approval). Once live, sponsor tiers map to concrete things — a Pixel dev unit, a month of build-host VM, a backend integration sprint. Until then, the most useful contribution is a starred repo + a discussion post about your use case.
Phones are measured by clock speed, GPU triangles, photon counts, and battery hours. None of those answer the question on-device AI now forces us to ask:
How much intelligence can a device orchestrate at once, in real time?
The numbers we'd love to see standardized:
- Resident capability count — how many models can load simultaneously without thermal collapse or eviction thrash?
- See-think-speak latency — phone takes a photo, identifies what's in it, formulates a sentence, speaks it back. End-to-end, in seconds. (Probably ~2 s milestone on a flagship. What's the floor on a $200 device?)
- Concurrent agent capacity — how many independent on-device agent loops can the device sustain in parallel before the user notices?
- Intelligence bandwidth — total inferences per second the device serves across every app, every capability.
There's no "Geekbench for orchestrated intelligence" — and OEMs planning AI-as-a-system features have nothing to spec against. JibarOS makes the question askable: by exposing inference as a shared, scheduled, budgeted platform service, the runtime gives you something concrete to measure.
We don't have the benchmarks yet. We'd like to see "orchestrated intelligence" become the next axis OEMs compete on, alongside camera and battery. If you're building benchmarks that capture multi-capability concurrent inference — or if you're an OEM with a target device class and a list of limits you wish were standardized — open an issue.
Apache 2.0. See LICENSE in each repo.