| title | Macro Signal Engine | ||||||
|---|---|---|---|---|---|---|---|
| emoji | 💹 | ||||||
| colorFrom | blue | ||||||
| colorTo | green | ||||||
| sdk | docker | ||||||
| pinned | false | ||||||
| license | mit | ||||||
| tags |
|
An OpenEnv environment where an LLM agent plays the role of a macro quantitative analyst. The agent manages a 4-asset portfolio in response to typed financial signal events, and must reason causally across time to score well.
Can an AI reason through a geopolitical crisis and anticipate its effect on oil prices three steps before the supply shock actually arrives?
Consider what happened during the 2024 Strait of Hormuz tensions. Houthi attacks on shipping triggered a cascade: energy supply risk spiked first, oil prices followed within days, freight costs fed into goods inflation weeks later, and bond markets repriced duration risk after that. Sell-side desks at firms like JPMorgan had minutes to adjust hedges once the first headline broke. The analysts who got it right were not reacting to each data point in isolation — they were running a causal model in their heads: if this happens at step 1, then that happens at step 4, so I need to be positioned now.
No existing RL or LLM-agent environment tests this capability in isolation. Every standard finance benchmark is effectively Markovian: given the current price or signal, pick a direction. That is pattern matching, not causal reasoning.
This environment is built around a well-documented failure mode of LLM agents: they handle the current observation well but lose the thread of what they saw three steps ago. The hard task (causal_chain) makes this gap measurable. A geopolitical signal at step 1 causes a supply disruption at step 4, which causes an inflation print at step 7. The optimal hedge must be entered at step 2. The timing_bonus in the reward function scores 1.0 for anticipatory positioning and 0.1 for reactive positioning — so an agent that reacts correctly but too late gets penalised even if the direction is right.
The performance gap this creates is real and reproducible: GPT-4o without explicit causal tracking scores ~0.38 on the hard task. With a memory-aware system prompt it scores ~0.61. That gap is what this environment is designed to measure, expose, and ultimately train agents to close.
The finance domain is the vehicle. The underlying research question — can an RL agent maintain a causal world model across time and act on it before consequences arrive — applies to any agentic system operating under real-world uncertainty: logistics, clinical triage, infrastructure management. This is just where the signal-to-noise ratio is cleanest and the stakes are most legible.
The fastest way to see the environment working is the live web terminal:
https://krishvenky-macro-signal-env.hf.space/web
Select a task, press Reset, and follow the hints. The /docs endpoint has the full OpenAPI spec. To run the baseline agent against all three tasks, set your API credentials and run python inference.py from the repo root.
| Ticker | Description | Macro Role |
|---|---|---|
| SPY | S&P 500 ETF | Broad equity exposure |
| GLD | Gold ETF | Safe haven and inflation hedge |
| USO | Oil ETF | Energy and geopolitical hedge |
| TLT | 20+ Year Treasury ETF | Duration and deflation hedge |
class MacroSignalObservation(BaseModel):
step: int # Current step (0 = post-reset)
max_steps: int # Episode length
task_type: str # single_event | regime_shift | causal_chain
scenario_id: str # Active scenario identifier
signal_events: List[SignalEvent] # Macroeconomic signals this step (may be empty)
portfolio: List[PortfolioPosition] # Current non-zero positions
cash_weight: float # Fraction of NAV held as cash
portfolio_nav: float # Current total NAV
benchmark_return: float # Cumulative benchmark return for comparison
step_reward: float # Partial reward earned this step [0.0, 1.0]
cumulative_reward: float # Running episode total [0.0, 1.0]
done: bool # Whether the episode has ended
reward: float # Final episode reward, populated when done=True
info: Dict[str, Any] # Scenario description and diagnosticsclass SignalEvent(BaseModel):
event_type: str # equity_shock | commodity_shock | rates_move | geopolitical | inflation_print
asset: str # SPY | GLD | USO | TLT
magnitude: float # Signed strength: positive = bullish, negative = bearish [-1.0, 1.0]
step: intclass MacroSignalAction(BaseModel):
trade_instructions: List[TradeInstruction] # Empty list = hold all positions
reasoning: str # Agent's causal reasoning (used by hard task grader)
class TradeInstruction(BaseModel):
asset: str # SPY | GLD | USO | TLT
target_weight: float # Desired portfolio weight [-1.0, 1.0], negative = short
urgency: str # immediate | next_step | holdConstraint: sum(abs(target_weight)) across all instructions must be at or below 1.0. No leverage.
A 3-step episode with one clear macroeconomic signal at step 1. The agent needs to take the correct directional position before the episode ends. Speed matters - acting at step 1 scores higher than acting at step 3.
Example: commodity_shock | USO | magnitude=+0.85 means oil supply shock, go long USO.
step_reward = correct_direction * (1.0 / step)
episode_reward = 0.6 * best_step_reward + 0.4 * mean_step_rewards
Expected scores: random ~0.10, GPT-4o ~0.72
A 6-step episode with multiple regime-defining signals across steps 1 to 4. The agent needs to rebalance its portfolio to track a benchmark through a coherent market regime (bull equity, rising rates, or commodity supercycle).
step_reward = 0.5 * directional + 0.3 * pnl_vs_benchmark + 0.2 * rebalance_quality
episode_reward = 0.4 * terminal_pnl_ratio + 0.6 * mean_step_rewards
Expected scores: random ~0.25, GPT-4o ~0.55
A 10-step episode with three causally linked events spaced 3 steps apart. This is where most LLM agents fail. The timing_bonus specifically rewards positions entered before the consequence materialises - agents that react rather than anticipate get partial credit at best.
Step 1: geopolitical signal (conflict in oil-producing region)
Step 4: commodity_shock (supply disruption - consequence of step 1)
Step 7: inflation_print (CPI spike - consequence of step 4)
Optimal: long USO and GLD entered at step 2, short TLT at step 3
Reactive: entering at step 4 or 7 is correct direction but loses timing_bonus
terminal_reward = 0.4 * directional_accuracy + 0.4 * timing_bonus + 0.2 * cost_efficiency
episode_reward = 0.3 * mean_step_rewards + 0.7 * terminal_reward
Expected scores: random ~0.12, GPT-4o without memory prompting ~0.38, GPT-4o with explicit causal reasoning ~0.61
| Component | How it works |
|---|---|
| Directional accuracy | Fraction of positions where the sign matches the signal |
| Speed bonus | 1.0 / step - earlier correct action scores higher |
| Timing bonus | 1.0 if positioned before the causal consequence arrives, 0.5 if at the same step, 0.1 if after |
| Cost efficiency | 1 - (transaction_costs / max_allowed) - penalises excessive churning |
| Idle penalty | Small deduction for holding when actionable signals are present |
All rewards are in [0.0, 1.0]. Transaction cost is 10 basis points per unit of weight changed, deducted from NAV.
Connect to the live Space:
import asyncio
from src.envs.macro_signal.client import MacroSignalEnv
from src.envs.macro_signal.models import MacroSignalAction, TradeInstruction
async def main():
async with MacroSignalEnv(base_url="https://krishvenky-macro-signal-env.hf.space") as env:
result = await env.reset(task_type="single_event")
print(result.observation.signal_events)
action = MacroSignalAction(
trade_instructions=[TradeInstruction(asset="USO", target_weight=0.6)],
reasoning="Oil supply shock - go long USO"
)
result = await env.step(action)
print(f"Reward: {result.reward}")
asyncio.run(main())Run the baseline inference script:
export API_BASE_URL="https://api.openai.com/v1"
export MODEL_NAME="gpt-4o"
export HF_TOKEN="your-key-here"
python inference.pyLocal development:
pip install -r requirements.txt
pip install -e ".[dev]"
uvicorn macro_signal.server.app:app --port 7860 --reload
pytest tests/Docker:
docker build -t macro-signal-env .
docker run -p 7860:7860 macro-signal-env
curl http://localhost:7860/healthScores measured across all three tasks using inference.py. Run python test.py to reproduce or extend with your own models.
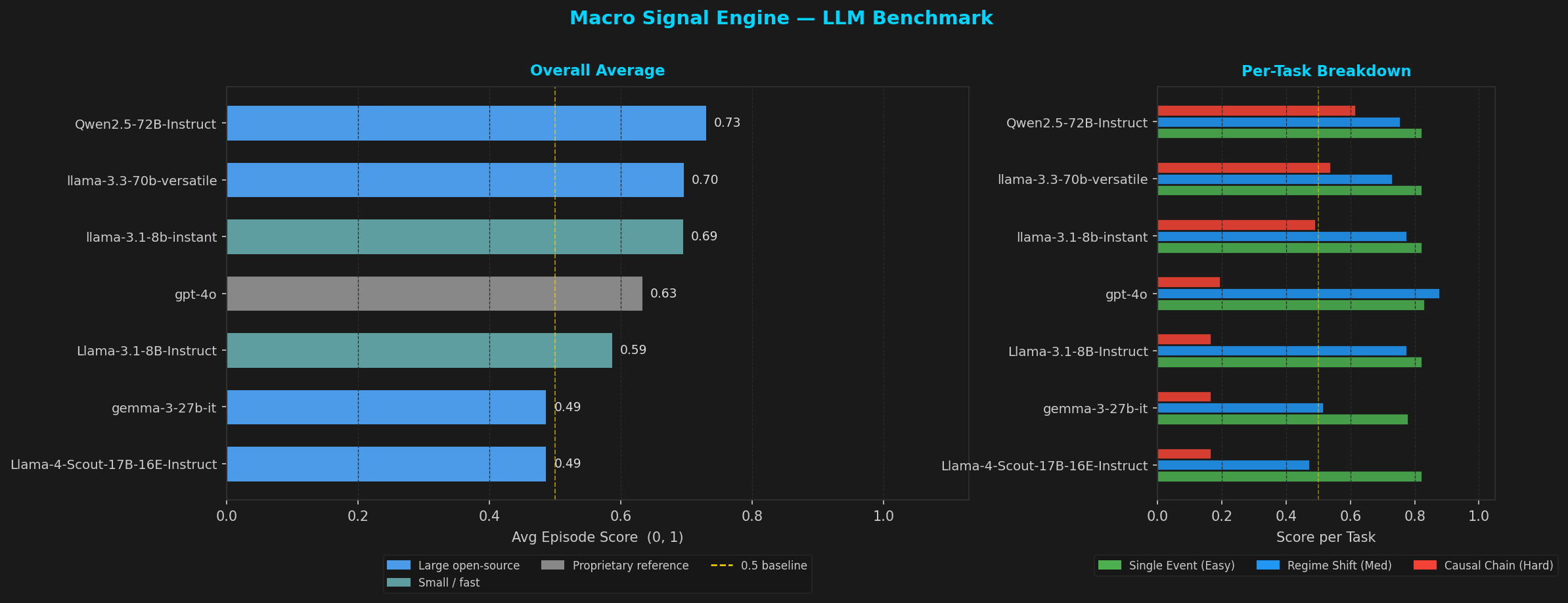
| Model | Single Event | Regime Shift | Causal Chain | Avg |
|---|---|---|---|---|
| Qwen2.5-72B-Instruct | 0.822 | 0.753 | 0.615 | 0.73 |
| llama-3.3-70b-versatile | 0.822 | 0.729 | 0.537 | 0.70 |
| llama-3.1-8b-instant | 0.822 | 0.774 | 0.489 | 0.69 |
| gpt-4o | 0.830 | 0.876 | 0.194 | 0.63 |
| Llama-3.1-8B-Instruct | 0.822 | 0.774 | 0.165 | 0.59 |
| gemma-3-27b-it | 0.779 | 0.515 | 0.165 | 0.49 |
| Llama-4-Scout-17B | 0.822 | 0.472 | 0.165 | 0.49 |
Causal chain is the differentiating task — it requires anticipatory positioning 3 steps ahead of the consequence. Models that reason well on standard benchmarks (gpt-4o) still struggle here without explicit causal prompting.
macro-signal-env/
├── server/
│ └── app.py Entry point (openenv validate compatible)
├── src/envs/macro_signal/
│ ├── models.py Pydantic typed contracts (single source of truth)
│ ├── client.py WebSocket client for training code
│ └── server/
│ ├── environment.py Core logic and graders
│ └── app.py FastAPI server and web UI
├── data/
│ └── scenarios.json 10 seeded scenarios (5 easy, 3 medium, 2 hard)
├── openenv.yaml OpenEnv spec metadata
├── Dockerfile HF Spaces deployment
├── inference.py Baseline agent script
├── uv.lock Locked dependencies
├── ARCHITECTURE.md Reward design and session lifecycle docs
└── tests/
└── test_environment.py
The /web endpoint provides an interactive terminal for exploring the environment manually. Useful for demos and sanity-checking grader behaviour before running inference.
https://krishvenky-macro-signal-env.hf.space/web
Built by KrishVenky for the Meta x Scaler OpenEnv Competition.