![]()

A Real-time and Light-weight Software for Generation of Non-Linguistic Behaviors in Conversational AIs
(Real-time Implementation of Voice Activity Projection)
📄 README: English | Japanese (日本語)
MaAI is a state-of-the-art and light-weight software that can generate (predict) non-linguistic behaviors in real time and continuously. It supports essential interaction elements such as (1) Turn-Taking, (2) Backchanneling, and (3) Head Nodding. Currently available for English, Chinese, and Japanese languages, MaAI will continue to expand its language coverage and non-linguistic behavior repertoire in the future. Designed specifically for conversational AI, including spoken dialogue systems and interactive robots, MaAI handles audio input effectively in either two-channels (user-system) or single-channel (user-only) settings🎙️ Thanks to its lightweight design, MaAI operates efficiently, even exclusively on CPU hardware⚡
The name MaAI is derived from the Japanese words Ma(間) or Maai(間合い), which refer to the subtle timing and spacing that humans adjust using various modalities during interactions.
The AI in MaAI literally stands for Artificial Intelligence, reflecting the aim to develop AI technologies related to these interactional dynamics.
The currently supported models are mainly based on the Voice Activity Projection (VAP) model and its extensions. Details about the VAP model can be found in the following repository: https://github.com/ErikEkstedt/VoiceActivityProjection
For system development or collaborative research using MaAI software, please contact Koji Inoue at Kyoto University.
Demo video on YouTube (https://www.youtube.com/watch?v=-uwB6yl2WtI)
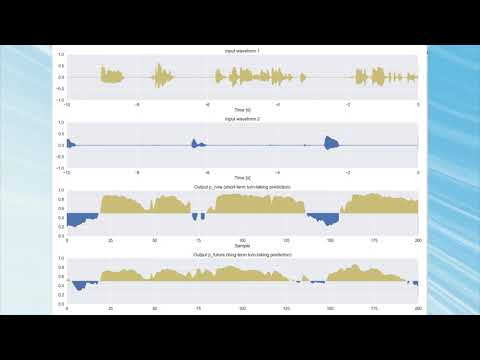
- We released a new version of MaAI (version 0.2.0) with a significant performance improvement (April 17th, 2026)
- Backchannel prediction model supporting three languages (English, Chinese, and Japanese) is now available (November 19th, 2025)
- Computational efficiency is improved in the long-context models (September 3rd, 2025)
- We launched the MaAI project and repository here! 🚀 (August 13th, 2025)
To quickly get started with MaAI, you can install it using pip:
pip install maai💡 Note: By default, the CPU version of PyTorch will be installed. If you wish to run MaAI on a GPU, please install the GPU version of PyTorch that matches your CUDA environment before proceeding.
You can run it as follows🏃♂️
The appropriate model for the task (mode) and parameters will be downloaded automatically.
Below is an example of using the turn-taking model (VAP) with the first channel as microphone input (user) and the second channel as silence (system).
from maai import Maai, MaaiInput, MaaiOutput
mic = MaaiInput.Mic()
zero = MaaiInput.Zero()
maai = Maai(mode="vap", lang="jp", frame_rate=10, audio_ch1=mic, audio_ch2=zero, device="cpu")
maai_output_bar = MaaiOutput.ConsoleBar()
maai.start()
while True:
result = maai.get_result()
maai_output_bar.update(result)Maai now accepts model_type to select the model variant.
"normal": the existing default model variant used in previous releases"normal-ver2": a new model variant that uses the Mimi encoder
We support the following models (behavior, language, audio setting, etc.), and more models will be added in the future. Currently available models can be found in our HuggingFace repository.
The turn-taking model uses the original VAP as is and predicts which participant will speak in the next moment.
- VAP Model
- Noise-Robust VAP Model (Recommended)
- [Single-Channel VAP Model] (In Preparation ...)
Backchannels are short listener responses such as yeah and oh, that are also related to turn-taking.
- VAP-based Backchannel Prediction Model - Timing
- VAP-based Backchannel Prediction Model - Timing for Two types
Nodding refers to the up-and-down movement of the head and is closely related to backchanneling. Unlike backchannels that involve vocal responses, nodding allows the listener to express their reaction non-verbally.
When several Maai models need to run on the same audio stream, the
MaaiMultiple class shares a single audio encoder across all of them so
the (relatively expensive) encoder runs only once per audio frame.
For input to the MaAI model, you can directly call the process method of a Maai class instance.
The MaaiInput class also provides flexible input options, supporting audio from WAV files, microphone input, and TCP communication.
- WAV file input:
Wavclass 📁 - Microphone input:
Micclass 🎙️ - TCP communication:
TCPReceiver/TCPTransmitterclasses 🌐 - Chunk input:
Chunkclass 📦
By using these classes, you can easily adapt the audio input method to your specific use case.
For output, you can retrieve the processing results using the get_result method of the Maai class instance.
The MaaiOutput class also supports several ways of visualization and also TCP communication.
- Console Dynamic Output:
ConsoleBarclass 📊 - GUI bar graph output:
GuiBarclass 🖼️ - GUI plot output:
GuiPlotclass 📈 - TCP communication:
TCPReceiver/TCPTransmitterclasses 🌐
For more details, please refer to the following README files:
You can find example implementations of MaAI models in the example directory of this repository.
-
Turn-Taking (VAP)
-
Noise-Robust Turn-Taking (VAP)
-
Backchannel
-
Nodding
- Prediction of three types of nodding
- Prediction of kinematic parameter of nodding
-
Multiple models sharing a single audio encoder
-
Output
Please cite the following paper, if you made any publications made with this repository🙏
Koji Inoue, Bing'er Jiang, Erik Ekstedt, Tatsuya Kawahara, Gabriel Skantze
Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection
International Workshop on Spoken Dialogue Systems Technology (IWSDS), 2024
https://arxiv.org/abs/2401.04868
@inproceedings{inoue2024iwsds,
author = {Koji Inoue and Bing'er Jiang and Erik Ekstedt and Tatsuya Kawahara and Gabriel Skantze},
title = {Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection},
booktitle = {International Workshop on Spoken Dialogue Systems Technology (IWSDS)},
year = {2024},
url = {https://arxiv.org/abs/2401.04868},
}
If you use the multi-lingual VAP model, please also cite the following paper.
Koji Inoue, Bing'er Jiang, Erik Ekstedt, Tatsuya Kawahara, Gabriel Skantze
Multilingual Turn-taking Prediction Using Voice Activity Projection
Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pages 11873-11883, 2024
https://aclanthology.org/2024.lrec-main.1036/
@inproceedings{inoue2024lreccoling,
author = {Koji Inoue and Bing'er Jiang and Erik Ekstedt and Tatsuya Kawahara and Gabriel Skantze},
title = {Multilingual Turn-taking Prediction Using Voice Activity Projection},
booktitle = {Proceedings of the Joint International Conference on Computational Linguistics and Language Resources and Evaluation (LREC-COLING)},
pages = {11873--11883},
year = {2024},
url = {https://aclanthology.org/2024.lrec-main.1036/},
}
If you also use the noise-robusst VAP model, please also cite the following paper.
Koji Inoue, Yuki Okafuji, Jun Baba, Yoshiki Ohira, Katsuya Hyodo, Tatsuya Kawahara
A Noise-Robust Turn-Taking System for Real-World Dialogue Robots: A Field Experiment
https://www.arxiv.org/abs/2503.06241
@misc{inoue2025noisevap,
author = {Koji Inoue and Yuki Okafuji and Jun Baba and Yoshiki Ohira and Katsuya Hyodo and Tatsuya Kawahara},
title = {A Noise-Robust Turn-Taking System for Real-World Dialogue Robots: A Field Experiment},
year = {2025},
note = {arXiv:2503.06241},
url = {https://www.arxiv.org/abs/2503.06241},
}
If you also use the backchannel VAP model, please also cite the following paper.
Koji Inoue, Divesh Lala, Gabriel Skantze, Tatsuya Kawaharaa
Yeah, Un, Oh: Continuous and Real-time Backchannel Prediction with Fine-tuning of Voice Activity Projection
https://aclanthology.org/2025.naacl-long.367/
@inproceedings{inoue2025vapbc,
author = {Koji Inoue and Divesh Lala and Gabriel Skantze and Tatsuya Kawahara},
title = {Yeah, Un, Oh: Continuous and Real-time Backchannel Prediction with Fine-tuning of Voice Activity Projection},
booktitle = {Proceedings of the Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL)},
pages = {7171--7181},
year = {2025},
url = {https://aclanthology.org/2025.naacl-long.367/},
}
When using model_type="normal-ver2" on a Windows machine with Anaconda, importing onnxruntime (used by the Mimi encoder) may fail with:
ImportError: DLL load failed while importing onnxruntime_pybind11_state:
A dynamic link library (DLL) initialization routine failed.
(On a Japanese-locale Windows the second line is shown as ダイナミック リンク ライブラリ (DLL) 初期化ルーチンの実行に失敗しました。)
This is caused by the Visual C++ runtime not being available in the conda environment. Installing the runtime via conda-forge resolves it:
conda install -c conda-forge vs2015_runtimeAfter this, model_type="normal-ver2" (and MaaiMultiple with the same setting) should work without modification.
The source code in this repository is licensed under the MIT License. For the trained models, please follow the license described in the README of each model or on Hugging Face repository.
When you use model_type="normal-ver2", MaAI uses the Mimi encoder.
Mimi is available at https://huggingface.co/kyutai/mimi and is licensed under CC BY 4.0.
MaAI uses Mimi as an encoder without modifying Mimi itself, and combines it with a separate downstream model.
The pre-trained CPC model is from the original CPC project and please follow its specific license. Refer to the original repository at https://github.com/facebookresearch/CPC_audio for more details.