You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
ProMoTe is under active development and evaluation from both the academic community and our industrial partners. If you intend to use this standard, feel free to reach out with questions and or feedback.
ProMoTe is a data Product Modelling Template for describing data products in a data mesh environment in a technology-independent manner. It was originally designed by researchers collaborating with large European companies that were looking to transition from a centralised, monolithic data landscape towards a more decentralised data-mesh (like) data landscape. ProMoTe is grounded in academic literature and industrial practice. It extends well-established ontologies (primarily DCAT) in a way that is intended to help create data products that achieve the DAUTNIVS+ non-functional requirements (Discoverability, Addressability, Understandability, Truthful & Trustworthy, Natively Accessible, Interoperable, Valuable and Secure + Feedback-Driven). The first eight of these are described extensively in the original data mesh book, published by Dehghani in 2020, whereas being Feedback-Driven originates from a desire to develop data products in an agile manner, akin to how DevOps has become standard practice for software development.
ProMoTe from a bird's-eye view
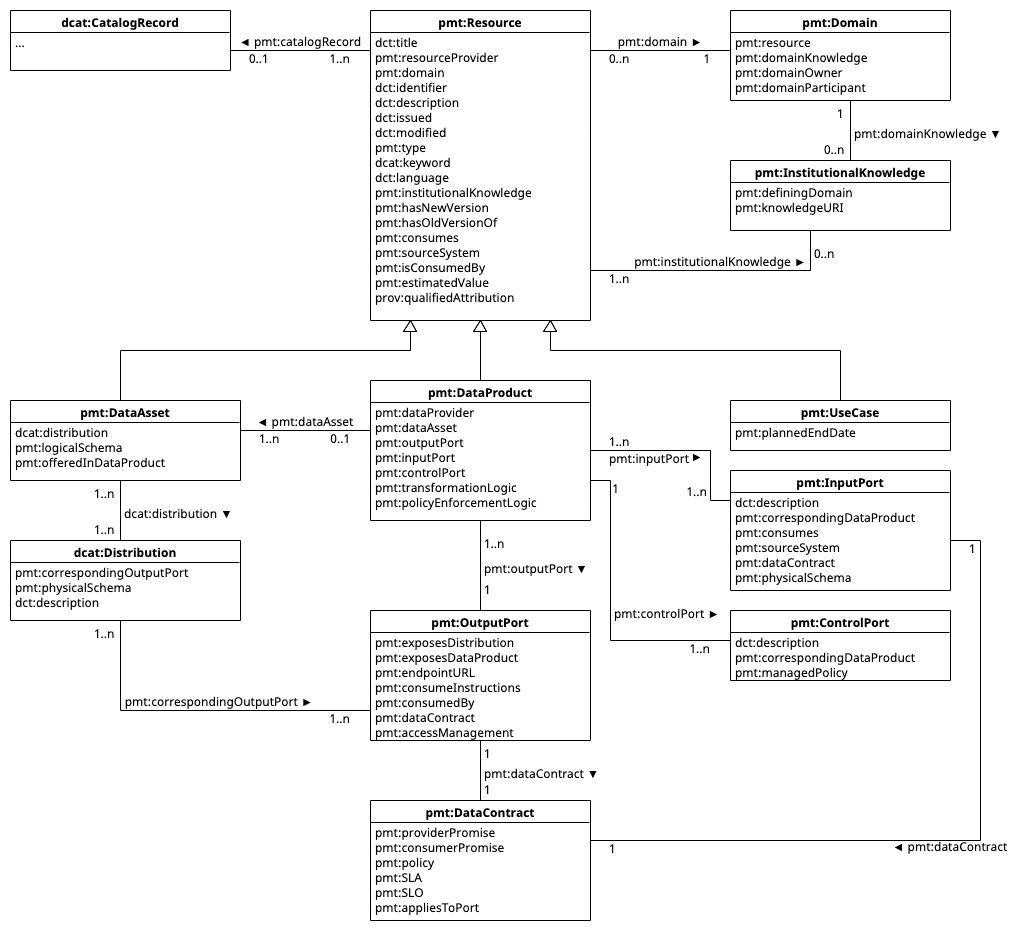
The figure below shows an overview in UML of the classes described in ProMoTe and the relations that can be used to describe them; the classes and relations are also described in detail below. Additionally, whenever relevant, we describe how the different classes and properties contribute to achieving DAUTNIVS+ in the "Motivation" field. At a high level ProMoTe extends the dcat:Resource class with a subclass: pmt:Resource. pmt:Resources come in three varieties: the pmt:DataAsset, which is a subclass of dct:Dataset; the pmt:Dataproduct, which is the architectural quantum of a data mesh and the main focus of ProMoTe; and the pmt:UseCase, that describes how the data is consumed. Data Products make available one or more data sets. Each data set has one or more physical representations (distributions), which are exposed throught output ports.
Each resource is managed within a pmt:Domain that maintains semantic domain knowledge in pmt:InstitutionalKnowledge. Data products ingest data through one or more pmt:InputPorts and are governed through policies that are managed through pmt:ControlPorts. Finally, data products make available one or more dct:Distributions of pmt:DataAssets through an associated pmt:OutputPort. For each output port, an associated pmt:DataContract establishes the conditions that apply when consuming the underlying data.
How to read and use this document.
With ProMoTe, you can help define metadata models to describe data products in the data catalogue of your data mesh, or it can help you determine what a data product should look like within your organisation and whether different maturity levels that contain various aspects exist. An academic paper illustrating these use cases of ProMoTe is underway. The core concepts of ProMoTe are also available as an ontology in a .owl-file, which can be found here.
The key words MAY, MUST, MUST NOT, and SHOULD in this document are to be interpreted as described in BCP 14RFC2119RFC8174 when, and only when, they appear in all capitals, as shown here.
External Documents
ProMoTe is compliant with and incorporates terms from the DCAT vocabulary, which in turn makes use of other vocabularies. This means that ProMoTe can both extend existing implementations using these standards and be extended with terminology from those vocabularies.
Descriptions make the resource more Understandable. Additionally, descriptions can contribute to Discoverability if they are indexed in a data catalog.
A newer version of the data product, which will eventually replace this version.
Comment:
This property is used for versioning, keeping an older version available helps consumers of the resources by giving them time to migrate to the new resource.
An older version of the data product, which this version is replacing.
Comment:
This property is used for versioning, keeping an older version available helps consumers of the resources by giving them time to migrate to the new resource.
In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
This property can be used to describe either where a specific data set or distribution lives, or give information on the input port of a data product.
Motivation:
In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
Linking consuming data products helps establish data lineage, whereas linking use cases to data products improves the discoverability, understandability of the data product and helps establish a pmt:estimatedValue
Motivation:
In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
An indication of the value the resource provides for the company.
Usage Note:
Ideally the estimated value is backed by a quantifier, such as money or manhours saved. Otherwise a qualitative description of the value provided can be provided.
Usage Note:
In commercial settings estimated value can be used as the price of the resource.
Motivation:
Explicitly including an estimated value is necessary for establishing that a resource is Valuable.
It is possible that a piece of institutional knowledge is maintained on an organisation-wide level, rather than on a domain-level, but there should still be a domain responsible for maintining organisation-wide knowledge.
A data product in a product oriented architecture. Data products consist of one or more owned data assets that have been optimised for consumption by external consumers.
Grouping one or more data assets together in a data product helps with Reusability, Discoverability, Addressability, Truthfulness and Trustworthiness, Understandability and Interoperability.
In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
Control ports are primarily used to monitor the Truthfulness & Trustworthiness of data products. They can also be used to enforce Interoperability and Security.
The logic or code used to transform data coming in from the input ports of the data product to the distributions that are exposerd through the output ports.
Motivation:
Transformation logic is necessary to create distributions that are Natively Accessible and guarantee a certain level of Truthfulness and Trustworthiness and/or Interoperability.
The date by which the use case plans to stop consuming data products.
Usage Note:
Keeping track of a planned end date helps with data product maintenance. There is no need to put effort into maintaining a data product if there are no active use cases.
Usage Note:
If there is no foreseeable end date, the planned end date can be indefinite.
Motivation:
Planned end dates of use cases are important for establishing Value and achieving Feedback-Driven development.
A collection of data that can be described by a single logical schema and be consumed in one or more techincal representations (distributions) through one or more output ports.
This class describes the conceptual dataset. One or more representations might be available, with differing schematic layouts and formats or serializations.
Usage Note:
A data asset can exist as a precursor to a data product and evolve to become a fully mature data produt over time. Not every data set needs to become a fully function data product however. Additionally, it is possible for a single data product to provide (access to) multiple data assets.
Motivation:
Grouping data together on a conceptual level helps grealy with Addressability and Discoverability. It can also contribute to Interoperability and Reusability.
A description of the data structure and internal relations at the data asset-level.
Usage Note:
Logical schemas describe the structure of data that holds true across different distributions of the data asset. Structural descriptions of different distributions are described in pmt:technicalSchema
Motivation:
Logical schemas contribute to Understandability and Interoperability.
A technical collection of data representating one or more data assets. Data assets might be available in multiple serializations that may differ in various ways, including natural language, media-type or format, schematic organization, temporal and spatial resolution, level of detail or profiles (which might specify any or all of the above). A distribution might also combine information from multiple data assets.
This represents a general availability of a dataset. It implies no information about the actual access method of the data, which is described in pmt:OutputPort.
Motivation:
Distributions make data assets Natively Accessible.
Output ports make different distributions of a data product's datasets Natively Accessible and Reusable. Additionally, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
A description of the data structure and internal relations at the distribution-level.
Usage Note:
Physical schemas describe the structure of data of a specific distribution of a pmt:DataAsset. Structural descriptions that hold true across all distributions of a data asset are described in pmt:logicalSchema
Motivation:
Physical schemas help with Understandability and Interoperability.
An output port of a data product that exposes a specific representation.
Usage Note:
Output ports represent the various ways in which data products expose their data. For example, data can be made available through a download link, a SQL-based API or a kafka-stream.
Motivation:
Output ports make different distributions of a data product's datasets Natively Accessible and Reusable.
Consume instructions can serve as the informal counterpart to the pmt:dataContract, which captures the formal promises and expectations of this output port.
Motivation:
Consume instructions help with making the data Natively Accessible, and, potentially, Interoperable.
Linking consumed data products and operational sources helps establish data lineage, as well a pmt:estimatedValue for the consumed data products.
Motivation:
Keeping track of who consumes what data contributes to determining Value, as well as establishing data lineage. In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
A data contract associated with an output port. If the output port is the input port of another data contract, the data contract regulates how the data flows into that data product.
Motivation:
Data Contracts contribute to Understandability, Truthfulness & Trustworthiness, Native Accessibility and Security.
A collection of enforceable promises concerning the delivery of a data product or use case.
Usage Note:
Data contracts are highly dependable on the requirements and culture of the organisation implementing a data mesh. External standards, can and should be used to establish and describe data contracts. Examples include the SCC for transferring data outside of the EU, ISO9001 for security purposes or the Linux foundation's standard for a data contract in a data mesh.
Motivation:
Data Contracts contribute to Understandability, Truthfulness & Trustworthiness, Native Accessibility and Security.
A policy that is explained and enforced in the data contract.
Usage Note:
A wide variety of policies may exist that manage different aspects of the data product such as: computational policies, data product standardized protocols, and automated tests and automated monitoring.
Usage Note:
Best practice is to use additional documentation to describe and manage the different types of policies that exist within a data mesh ecosystem.
Motivation:
Policies can contribute to one or more of Understandability, Truthfulness & Trustworthiness and Security.
An input port of a data product which relates to a source system or an output port of another data product.
Motivation:
Keeping track of who consumes what data contributes to determining Value, as well as establishing data lineage. In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
Keeping track of who consumes what data contributes to determining Value, as well as establishing data lineage. In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
Keeping track of who consumes what data contributes to determining Value, as well as establishing data lineage. In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
This property can be used to describe either where a specific data asset or distribution lives, or give information on the input port of a data product.
Motivation:
In addition to making data products Feedback-Driven, tracking lineage in general contributes to Discoverability, Addressability, Understandability, and Interoperability.
A control port through which a data product's policies can be managed by external parties such as the pmt:dataProvider or a federated governance team.
Usage Note:
Since control ports are highly dependent on the infrastructure provided in the data mesh, as well as the policies employed in the organisation, description of control ports SHOULD be extended with external documentation as the situation requires.
Motivation:
Control Ports allow external parties to observe and influence the management of the data product, effectively contributing to Truthfulness and Trustworthiness, as well as Security.
A policy that can be managed through this control port.
Usage Note:
A wide variety of policies may exist that manage different aspects of the data product such as: computational policies, data product standardized protocols, and automated tests and automated monitoring.
Usage Note:
Best practice is to use additional documentation to describe and manage the different types of policies that exist within a data mesh ecosystem.
About
Repository for maintaining the Data Product Model template
{kind=link}