v3.0.7 Update: New Motion Scale Advanced node with experimental theta control for >81 frame coherence. End-frame guidance added to Continuation Conditioning (thanks @onerok). See Nodes section.
Towards consistent motion and prompt adherence for Wan 2.2 video generation.
TL;DR:
- Primary value: Improved motion consistency within 81 frames - smoother trajectories, less reversal, better prompt adherence
- Chunked generation (best use case): Because each 81-frame chunk is more consistent, you get clean anchors and reliable continuation for unlimited length videos
- Single generation 81+ frames: May help sometimes, but results vary - the real benefit is consistency within the native window
Works with both i2v (image-to-video) and t2v (text-to-video), though i2v sees the most benefit due to anchor-based continuation.

If you find this useful:

Based on FreeLong (NeurIPS 2024), this implements frequency-aware attention blending that dramatically improves motion consistency:
| Without FreeLong | With FreeLong |
|---|---|
| More prone to motion reversal ("ping-pong") | More likely to maintain stable direction |
| More prone to subject drift between "scenes" | More likely to keep consistent appearance |
| More prone to ignoring motion in prompt | More likely to follow prompt intent |
| More prone to multiple distinct "scenes" | More likely to produce coherent sequence |
How it works:
- Global stream: Full-sequence attention captures overall motion direction
- Local stream: Windowed attention preserves sharp details
- Spectral blend: FFT combines low frequencies (motion) from global + high frequencies (detail) from local
This is essentially motion-level prompt enforcement - the model maintains its initial motion intent rather than "forgetting" mid-generation.
FreeLong's stable motion interpretation is what makes reliable chunk chaining possible:
[Chunk 1: 81 frames] → last frame → [Chunk 2: 81 frames] → last frame → [Chunk 3...] → ∞
Why this works:
Without FreeLong, chunk boundaries can often fail because:
- Motion may have reversed mid-chunk → last frame has wrong direction
- Subject drifted → last frame doesn't match earlier frames
- Ambiguous anchor → next chunk likely misinterprets intended motion
With FreeLong, each chunk has:
- Consistent motion direction throughout → last frame shows correct direction
- Stable subject interpretation → clean visual handoff
- Clear motion cues → next chunk far more likely to correctly continue
Two-sided benefit: FreeLong provides clean anchor frames AND makes the next generation far more likely to correctly interpret the motion direction. Clear input signals lead to better continuation.
Additional chunking benefits:
- Different prompts per chunk (scene evolution)
- Constant VRAM (no scaling with length)
- Fresh anchor resets any accumulated drift
Wan 2.2's attention mechanism struggles with temporal coherence:
- Native context is 81 frames (~5 seconds)
- Motion often reverses or drifts within that window
- Extending beyond 81 frames compounds these issues
- Clone into ComfyUI custom_nodes:
cd ComfyUI/custom_nodes
git clone https://github.com/shootthesound/comfyUI-LongLook.git-
Restart ComfyUI
-
Load example workflow from
examples/Car-Racing-Example.jsonand Single-Shot-Example.json
Just add WanFreeLong before your sampler:
Load Model → WanFreeLong → KSampler → VAE Decode
Even without chunking, you get more consistent motion within 81 frames.
[Chunk 1]
Image → WanImageToVideo → FreeLong → Sampler → VAE Decode
↓
[Last Frame]
↓
[Chunk 2]
FreeLong → WanContinuationConditioning → Sampler → VAE Decode
↑ ↓
[New Prompt] [Last Frame]
↓
[Chunk 3...] [Repeat]
Patches Wan model for FreeLong spectral blending.
| Parameter | Default | Description |
|---|---|---|
| enabled | true | Toggle for A/B testing |
| blend_strength | 0.8 | Spectral blend strength (0=off, 1=full) |
| low_freq_ratio | 0.8 | Portion of spectrum from global stream |
| local_window_frames | 33 | Video frames for detail window (~40% of total recommended) |
| blend_start_block | 0 | First transformer block to apply |
| blend_end_block | -1 | Last block (-1 = all) |
Experimental extension with stricter motion locking for complex motion scenes. Use this if standard FreeLong still shows motion drift or trajectory reversals.
| Parameter | Default | Description |
|---|---|---|
| enabled | true | Toggle for A/B testing |
| motion_lock_ratio | 0.15 | Ultra-low frequencies locked 100% to global (motion skeleton) |
| blend_strength | 0.8 | Overall effect strength |
| low_freq_ratio | 0.5 | Upper bound for blended zone |
| local_window_frames | 33 | Video frames for detail window |
| motion_lock_blocks | 5 | First N blocks use global-only (establishes motion early) |
How it differs from standard FreeLong:
- 3-tier frequency blending: Ultra-low (locked) + mid (blended) + high (local details)
- Early-block locking: First N blocks skip local processing entirely to establish motion trajectory
- Protected motion skeleton: Ultra-low frequencies cannot be overridden by local attention
When to use: Complex motion scenes (vehicles cornering, camera movement, choreographed action) where standard FreeLong still shows drift. Try standard FreeLong first.
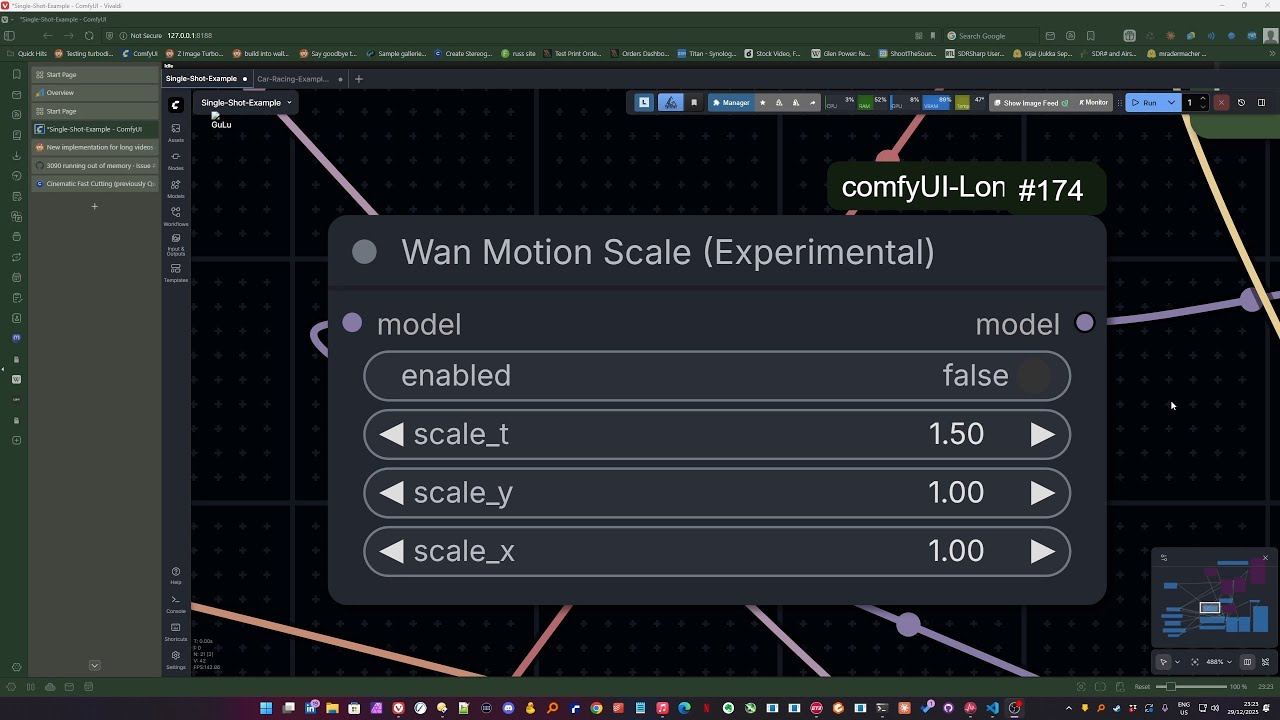
Control motion speed by scaling temporal position embeddings. Works with both i2v and t2v.
| Parameter | Default | Description |
|---|---|---|
| enabled | true | Toggle on/off |
| scale_t | 1.5 | Temporal scale: >1 = faster motion, <1 = slower, <0 = experimental reverse |
| scale_y | 1.0 | Height scale (optional) |
| scale_x | 1.0 | Width scale (optional) |
Recommended values for scale_t:
- 1.5 - Optimal for acceleration. Feels like ~2x motion speed, stable output
- 1.0-1.5 - Safe range for faster motion
- 0.75-1.0 - Slowdown range, works reliably
- Negative values - Can produce reverse movement, but inconsistent since it contradicts training data. May work better for certain scene types or i2v
Use case: Generate at scale_t=1.5 → RIFE 2x interpolation → effectively double video length with same motion coverage.
scale_x / scale_y notes:
- t2v: Can help adjust aspect ratio of generations
- i2v: Can produce wild spatial effects - experimental
Work in progress - not yet fully documented. Experimental node with additional RoPE controls including theta adjustment for potential >81 frame coherence improvements.
Creates i2v conditioning from previous chunk's last frame.
| Parameter | Default | Description |
|---|---|---|
| width | 512 | Output video width |
| height | 512 | Output video height |
| video_frames | 81 | Frames to generate |
Inputs: positive, negative, anchor_images (from previous VAE decode), vae, optional end_images
Multi-chunk continuation with different prompts per chunk for scene evolution.
Single generation with FreeLong for improved motion consistency. Includes A/B comparison with and without FreeLong. Note: For 81+ frame generations, results vary - FreeLong helps sometimes but not always. The consistent benefit is within 81 frames.
| Goal | Adjustment |
|---|---|
| More motion consistency | Increase blend_strength (0.7-0.9) |
| More detail/sharpness | Decrease blend_strength (0.4-0.6) |
| Smoother motion | Increase low_freq_ratio (0.5-0.7) |
| More dynamic motion | Decrease low_freq_ratio (0.3-0.4) |
| Less morphing | Increase local_window_frames (49-65) |
| Goal | Adjustment |
|---|---|
| Stronger motion lock | Increase motion_lock_ratio (0.2-0.3) |
| More natural/dynamic | Decrease motion_lock_ratio (0.05-0.1) |
| Earlier motion establishment | Increase motion_lock_blocks (8-12) |
| More detail influence | Decrease motion_lock_blocks (0-3) |
| Goal | Adjustment |
|---|---|
| Faster motion (for RIFE workflow) | scale_t = 1.5 (optimal) |
| Gentle speedup | scale_t = 1.2-1.3 |
| Slow motion effect | scale_t = 0.75-0.9 |
| Experimental reverse | scale_t < 0 (inconsistent) |
| Adjust t2v aspect ratio | Modify scale_x / scale_y |
- Dual-stream processing at transformer block level
- 50% overlapping windows with cosine crossfade
- Complementary FFT filters (low + high = 1.0)
- RoPE embeddings properly sliced per window
- Float32 FFT operations for numerical stability
- Single-FFT spectral blending: Blend computed in frequency domain before inverse FFT (faster + improved float16 precision)
- Cached temporal detection: Frame structure and blend ramps computed once, reused across all 40 blocks
- Reduced memory allocations: In-place operations and immediate tensor cleanup in window processing
- Enforcer early-block optimization: Global-only blocks skip windowed processing entirely (faster than standard FreeLong for those blocks)
- Last frame extracted from decoded video (float32, no 8-bit quantization)
- Re-encoded as i2v conditioning via VAE
- Proper mask format for Wan's conditioning system
- Each chunk processes independently
- Only last frame passed between chunks
- No VRAM accumulation across chains
- Unlimited chunk count
- 8GB+ VRAM compatible
While FreeLong was originally designed to extend beyond training length, results for single generations beyond 81 frames are inconsistent. You may see improvement, or you may not.
The primary value of this implementation is consistency within the 81-frame window - which is exactly why it makes chunked generation so reliable. Each chunk benefits from better motion consistency, giving you clean anchors for continuation.
If you need longer videos, chunking is the proven approach.
- ComfyUI
- Wan 2.2 models (i2v recommended)
- VideoHelperSuite (for video output)
- FreeLong paper: arxiv.org/abs/2407.19918
- Wan 2.2: Alibaba
- End-frame guidance (WanContinuationConditioning): @onerok
MIT