{kind=link}
A Python package for Eigen-Component Analysis (ECA) and Unsupervised Eigen-Component Analysis (uECA) for classification and clustering tasks without data centralization or standardization. ECA is a quantum theory-inspired linear model that provides interpretable feature-to-class mappings through eigencomponents.
- Scikit-learn Compatible: Implements the scikit-learn Estimator API with
fit,transform, andpredictmethods - Supervised & Unsupervised Learning: Supports both classification (ECA) and clustering (uECA) modes
- GPU Acceleration: PyTorch backend enables GPU acceleration when available
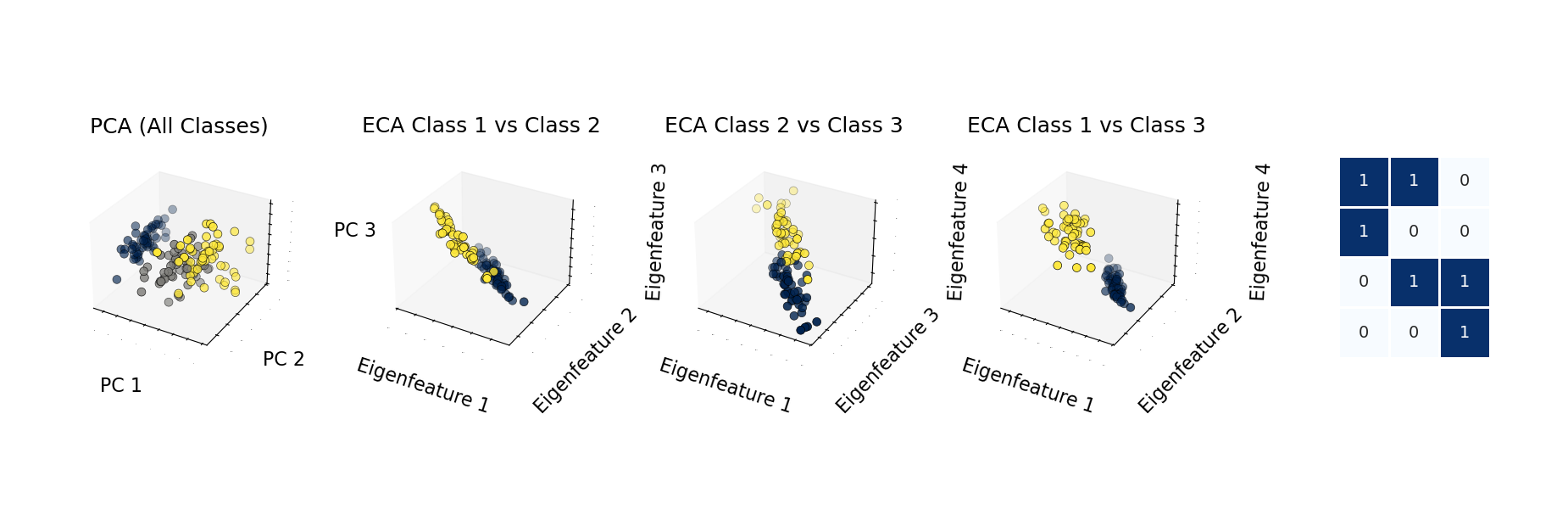
- Visualization Tools: Built-in methods to visualize eigenfeatures, mappings, and results
- Mathematical Foundation: Based on quantum theory principles with antisymmetric transformation matrices
pip install eigen-analysis# Clone the repository
git clone https://github.com/lachlanchen/eigen_analysis.git
cd eigen_analysis
pip install .
# Install in development mode
pip install -e .- numpy >= 1.18.0
- torch >= 1.7.0
- matplotlib >= 3.3.0
- seaborn >= 0.11.0
- scikit-learn >= 0.24.0
- scipy >= 1.6.0
The package provides a unified API that automatically selects between supervised and unsupervised modes:
from eigen_analysis import eigencomponent_analysis
# For classification (supervised)
model = eigencomponent_analysis(X, y, num_clusters=3)
# For clustering (unsupervised)
model = eigencomponent_analysis(X, num_clusters=3)import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from eigen_analysis import ECA
# Load Iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create and train ECA model
eca = ECA(num_clusters=3, num_epochs=10000, learning_rate=0.001)
eca.fit(X_train, y_train)
# Make predictions
y_pred = eca.predict(X_test)
# Evaluate accuracy
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f"Test accuracy: {accuracy:.4f}")
# Get transformed data
X_transformed = eca.transform(X_test)
# Access model components
P_matrix = eca.P_numpy_ # Eigenfeatures
L_matrix = eca.L_numpy_ # Feature-to-class mapping
# Visualize results
from eigen_analysis.visualization import visualize_clustering_results
visualize_clustering_results(
X_test, y_test, y_pred,
eca.loss_history_,
eca.transform(X_test),
eca.num_epochs,
eca.model_,
(eca.L_numpy_ > 0.5).astype(float),
eca.L_numpy_,
eca.P_numpy_,
"Iris",
output_dir="eca_classification_results"
)import numpy as np
from sklearn.datasets import make_blobs
from eigen_analysis import UECA
from sklearn.metrics import adjusted_rand_score
# Generate synthetic data
X, y_true = make_blobs(n_samples=300, centers=3, random_state=42)
# Train UECA model
ueca = UECA(num_clusters=3, learning_rate=0.01, num_epochs=3000)
ueca.fit(X, y_true) # y_true used only for evaluation
# Access clustering results
clusters = ueca.labels_
remapped_clusters = ueca.remapped_labels_ # Optimal mapping to ground truth
# Evaluate clustering quality
ari_score = adjusted_rand_score(y_true, clusters)
print(f"Adjusted Rand Index: {ari_score:.4f}")
# Visualize clustering results
from eigen_analysis.visualization import visualize_clustering_results
visualize_clustering_results(
X,
y_true,
ueca.remapped_labels_,
ueca.loss_history_,
ueca.transform(X),
ueca.num_epochs,
ueca.model_,
ueca.L_hard_numpy_,
ueca.L_numpy_,
ueca.P_numpy_,
"Custom Dataset",
output_dir="eca_clustering_results"
)# Customize visualization with feature and class names
visualize_clustering_results(
X, y, predictions,
loss_history, projections, num_epochs,
model, L_hard, L_soft, P_matrix,
dataset_name="Iris",
feature_names=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"],
class_names=["Setosa", "Versicolor", "Virginica"],
output_dir="custom_visualization"
)For MNIST visualization, there's a specialized function:
from torchvision import datasets, transforms
from eigen_analysis import ECA
from eigen_analysis.visualization import visualize_mnist_eigenfeatures
# Load MNIST
mnist_train = datasets.MNIST('data', train=True, download=True)
X_train = mnist_train.data.reshape(-1, 784).float() / 255.0
y_train = mnist_train.targets
# Train ECA model
eca = ECA(num_clusters=10, num_epochs=1000)
eca.fit(X_train, y_train)
# Visualize MNIST eigenfeatures
visualize_mnist_eigenfeatures(eca.model_, output_dir='mnist_results')num_clusters: Number of classeslearning_rate: Learning rate for optimizer (default: 0.001)num_epochs: Number of training epochs (default: 1000)temp: Temperature parameter for sigmoid (default: 10.0)random_state: Random seed for reproducibilitydevice: Device to use ('cpu' or 'cuda')
num_clusters: Number of clusterslearning_rate: Learning rate for optimizer (default: 0.01)num_epochs: Number of training epochs (default: 3000)random_state: Random seed for reproducibilitydevice: Device to use ('cpu' or 'cuda')
If you use this package in your research, please cite:
@inproceedings{chen2025eigen,
title={Eigen-Component Analysis: {A} Quantum Theory-Inspired Linear Model},
author={Chen, Rongzhou and Zhao, Yaping and Liu, Hanghang and Xu, Haohan and Ma, Shaohua and Lam, Edmund Y.},
booktitle={2025 IEEE International Symposium on Circuits and Systems (ISCAS)},
pages={},
year={2025},
publisher={IEEE},
doi={},
}MIT