
Fully Decentralized P2P Search Engine for LLMs
No credit card. No API key. No usage cap. Forever free.








Quick Start • Why InfoMesh • Features • What's New • Architecture • Security • Credits • Contributing • Docs
Tip
P2P Bootstrap Nodes Active InfoMesh ships with multiple bootstrap nodes across Azure regions — your node connects automatically on first start. To add more peers manually:
infomesh peer add /ip4/<IP>/tcp/4001/p2p/<PEER_ID>
infomesh peer testEvery AI assistant needs real-time web access — but that access is gated behind expensive, proprietary search APIs:
| Type | Typical Cost | Limitation |
|---|---|---|
| LLM-bundled web search | Hidden in token cost | Locked to one vendor's API, no standalone access |
| Custom search API | ~$3–5 / 1,000 queries | API key + billing account required, rate-limited |
| AI search SaaS | ~$0.01–0.05 / query | SaaS dependency, monthly usage caps |
| Search scraping proxy | ~$50+/month | Fragile, breaks on upstream changes |
| InfoMesh | $0 — Forever Free | None. You own the node, you own the index |
This creates a paywall barrier for independent AI developers, open-source assistants, and researchers. Small projects and local LLMs simply cannot afford real-time web search.
I started building AI agents and quickly hit a wall: there was no free web search API. Every provider wanted a credit card, a billing account, or a monthly subscription — just to let an AI agent look something up on the web. That felt wrong.
So I built InfoMesh — a decentralized search engine where the community is the infrastructure:
- No central server — every participant is both a crawler and a search node.
- No per-query cost — contribute crawling, earn search credits. The more you give, the more you can search.
- No vendor lock-in — standard MCP protocol integration, works offline with your local index.
- No data harvesting — search queries never leave your node. There is no central entity to collect them.
InfoMesh does not compete with existing commercial search providers. Those companies serve human search at massive scale with ads-based monetization. InfoMesh provides minimal, sufficient search capabilities for AI assistants — for free, via MCP — democratizing real-time web access without per-query billing.
I just wanted my AI agent to search the web without reaching for my wallet. If you've felt the same way, InfoMesh is for you.
| How you use it | Cost | Example |
|---|---|---|
| MCP (AI assistants) | Free | Claude, VS Code Copilot, any MCP client calls search() — zero API fees |
| CLI (terminal) | Free | uv run infomesh search "python asyncio" — instant results from your index |
| Python package (code) | Free | from infomesh.index.local_store import LocalStore — embed search in your app |
| Local API (HTTP) | Free | curl localhost:8080/search?q=... — REST endpoint for any language |
No API keys. No billing accounts. No usage caps. No rate limits per dollar. You run a node, you contribute to the network, and search is free — forever.
Looking for a free web search MCP server? Here's how InfoMesh compares to common alternatives:
| Feature | InfoMesh | API-based MCP servers | Scraper-based MCP servers | Meta-search engines |
|---|---|---|---|---|
| Free tier | ♾️ Unlimited (credit-based) | Limited (1,000–2,000/mo typical) | Unlimited (no API) | Unlimited |
| API key | ❌ Not required | ✅ Required (signup needed) | ❌ Not required | ❌ Not required |
| Decentralized | ✅ Fully P2P | ❌ Centralized | ❌ Centralized | ❌ Single instance |
| Offline search | ✅ Local index works offline | ❌ | ❌ | ❌ |
| Privacy | ✅ Queries never leave node | Varies | ✅ Self-hosted | |
| Self-hosted | ✅ You own everything | ❌ | ❌ | ✅ Docker required |
| Crawl your own URLs | ✅ crawl_url() tool |
❌ | ❌ | ❌ |
| Full page fetch | ✅ fetch_page() tool |
Varies | ❌ | ❌ |
| Install | pip install infomesh |
Varies | Varies | Docker Compose |
| Open source | ✅ MIT | Varies | Varies | Varies |
InfoMesh is the only web search MCP server that is fully decentralized, works offline, requires no API key, and lets you crawl and index your own content — all for free.
Most search engines ask you to trust them. InfoMesh asks you to trust math.
There is no central server that collects your queries. There is no company that stores your search history. There is no database of user behavior waiting to be breached. Your data never leaves your machine unless you choose to share it.
Contribute to the network → earn credits → search for free, forever, with no limits.
That's the entire deal. No catch.
| 🔑 | Ed25519 Cryptographic Identity | Every node generates a unique Ed25519 key pair on first launch. All actions — crawling, indexing, credit transactions — are cryptographically signed. No one can impersonate your node. Key rotation is supported via infomesh keys rotate with dual-signed DHT revocation. |
| 🔏 | Signed Content Attestation | Every crawled page is fingerprinted with SHA-256(raw_html) + SHA-256(extracted_text), then signed with the crawler's private key and published to the DHT. Tampering is mathematically detectable. |
| 🌳 | Merkle Tree Integrity | The entire index is secured by a Merkle Tree. Any node can request a membership proof for any document — if a single byte was altered, the proof fails. This is the same integrity model used by Git and blockchain. |
| 🔍 | Random Audits | ~1 audit per hour per node. Three independent auditors re-crawl a random URL and compare content_hash against the original. Mismatch → trust penalty. 3 consecutive failures → network isolation. |
| 🛡️ | Sybil Attack Defense | Proof-of-Work node ID generation (~30 seconds on avg CPU) prevents mass fake-node creation. Additionally, max 3 nodes per /24 subnet per DHT bucket limits coordinated attacks. |
| 🌐 | Eclipse Attack Defense | ≥3 independent bootstrap sources + routing table subnet diversity + periodic routing refresh. No single entity can surround your node with malicious peers. |
| 🚫 | DHT Poisoning Defense | Per-keyword publish rate limit (10/hr/node) + signed publications + content hash cross-verification. Injecting false search results is extremely difficult. |
| 🔒 | Encrypted Transport | All peer-to-peer communication runs through libp2p's Noise protocol — end-to-end encrypted. No eavesdropping on queries or results. |
| 🕵️ | Zero Query Logging | Search queries are processed locally or routed as hashed keywords through the DHT. No node — not even yours — records what other peers are searching for. There is no search history to subpoena. |
| 🧮 | Credit Proof Verification | Every credit entry is signed and includes a Merkle proof. Peers can independently verify credit claims without trusting the claimant. Farming detection + 24hr probation for new nodes prevent gaming. |
Every peer earns a continuously updated trust score based on behavior, not identity:
Trust = 0.15 × uptime + 0.25 × contribution + 0.40 × audit_pass_rate + 0.20 × summary_quality
| Tier | Score | What Happens |
|---|---|---|
| 🟢 Trusted | ≥ 0.8 | Priority routing, lowest search cost |
| 🔵 Normal | 0.5 – 0.8 | Standard operation |
| 🟡 Suspect | 0.3 – 0.5 | Higher audit frequency, limited features |
| 🔴 Untrusted | < 0.3 | Network isolation after 3× consecutive failures |
| Regulation | How InfoMesh Handles It |
|---|---|
| robots.txt | Strictly enforced — no exceptions, automatic blocklist |
| DMCA | Signed takedown requests propagated via DHT, 24hr compliance |
| GDPR | Distributed deletion records, right-to-be-forgotten support |
| Copyright | Full text stored as cache only; search returns snippets with attribution |
Bottom line: InfoMesh doesn't ask you to trust a company. It uses cryptography, audits, and game theory to make cheating harder than playing fair. Your queries are private, your data stays local, and your search is free — no strings attached.
All you need is a Linux terminal (Ubuntu, Debian, etc.). No prior Python or developer experience required.
Step 1 — Install uv (Python package manager, one-time setup):
curl -LsSf https://astral.sh/uv/install.sh | shAfter this finishes, close and reopen your terminal (or run source ~/.bashrc).
This ensures the uv and uvx commands are available.
Step 2 — Run InfoMesh:
uvx infomesh statusuvx automatically downloads and runs InfoMesh — no git clone, no pip install, no virtual environments.
On the first run it may take a few seconds to download; subsequent runs are instant.
# Crawl a webpage and index it
uvx infomesh crawl https://docs.python.org/3/library/asyncio.html
# Search your local index
uvx infomesh search "asyncio"
# View the node dashboard (works over SSH too)
uvx infomesh dashboard --textIf you use InfoMesh regularly, install it as a persistent tool so you don't need the uvx prefix:
uv tool install infomesh
# Now run directly:
infomesh status
infomesh crawl https://example.com
infomesh search "example"
infomesh dashboard --textAdd InfoMesh as an MCP server in VS Code (Copilot), Claude Desktop, Cursor, or Windsurf — no API key needed:
{
"mcpServers": {
"infomesh": {
"command": "uvx",
"args": ["infomesh", "mcp"]
}
}
}Your AI assistant can now search the web for free via MCP.
If you want to contribute code or run from source:
The P2P optional dependency (libp2p) includes C extensions (fastecdsa, coincurve, pynacl) that require native build tools. These are only needed if you install with pip install 'infomesh[p2p]'.
Linux (Debian / Ubuntu):
sudo apt-get update && sudo apt-get install -y build-essential python3-dev libgmp-devmacOS:
brew install gmp
# Xcode Command Line Tools are usually pre-installedWindows: Use WSL2 (recommended) or install Visual Studio Build Tools + GMP.
Note: These system packages are only required for the
p2poptional dependency. The base install (uv sync) does not need them.
# Clone and install with dev dependencies
git clone https://github.com/dotnetpower/infomesh.git
cd infomesh
uv sync
# Start InfoMesh with the TUI dashboard
uv run infomesh start
# Or run headless (servers / CI)
uv run infomesh start --no-dashboarddocker build -t infomesh .
docker run -d --name infomesh \
-p 4001:4001 -p 8080:8080 \
-v infomesh-data:/data \
infomesh# Search your local index
uvx infomesh search "python asyncio tutorial"
# Check node status
uvx infomesh status
# Crawl a specific URL on demand
uvx infomesh crawl https://docs.python.org/3/
# Export your index as a portable snapshot
uvx infomesh index export backup.zstReady-to-run Python scripts are available in the examples/ directory:
# Local search
uv run python examples/basic_search.py "python tutorial"
# Crawl → index → search pipeline
uv run python examples/crawl_and_search.py https://docs.python.org/3/
# Programmatic MCP client
uv run python examples/mcp_client.py "async programming"See examples/README.md for the full list.
| Feature | Description |
|---|---|
| 🌐 Fully Decentralized | No central server. Every node is both a hub and a participant — cooperative tit-for-tat architecture |
| 🤖 LLM-First Design | Pure text API via MCP, optimized for AI consumption. No browser UI needed |
| 🔍 Dual Search | Keyword search (SQLite FTS5 + BM25) and optional semantic vector search (ChromaDB) |
| 🕷️ Smart Crawler | Async crawling with robots.txt compliance, politeness delays, and 3-layer deduplication |
| 📡 P2P Network | libp2p-based with Kademlia DHT, mDNS local discovery, and encrypted transport |
| 💾 Offline-Capable | Your local index works without internet — search your crawled knowledge anytime |
| 🏆 Credit Incentives | Earn credits by crawling and serving peers. More contribution = more search quota |
| 🔐 Content Integrity | SHA-256 + Ed25519 attestation on every page. Random audits + Merkle proofs |
| 🤏 zstd Compression | Index snapshots and network transfers compressed with zstandard |
| 📊 Console Dashboard | Beautiful Textual TUI with 6 tabs: Overview, Crawl, Search, Network, Credits, Settings |
Most commercial search APIs charge per query or require a paid subscription. InfoMesh exposes 15 MCP tools completely free — no API key, no billing:
| Tool | Description |
|---|---|
search(query, limit) |
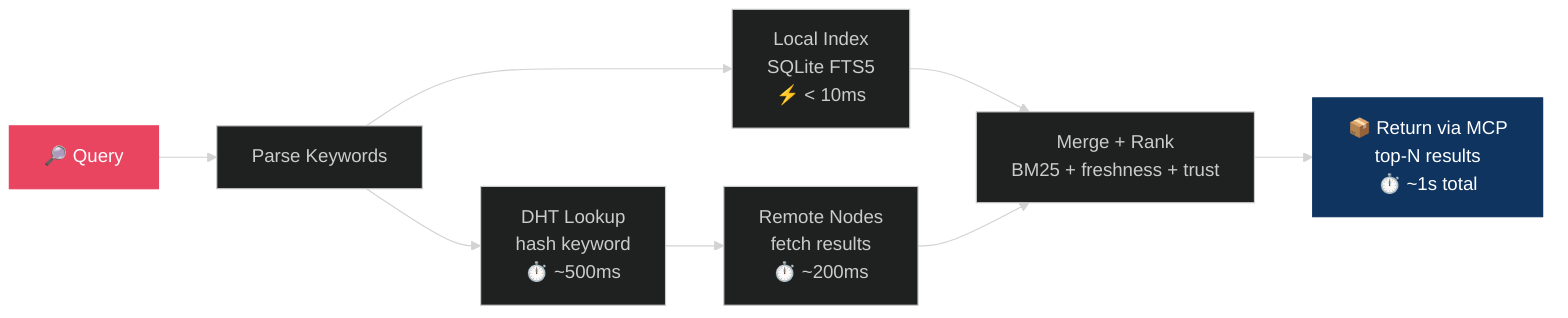
Full network search — merges local + remote results, ranked by BM25 + freshness + trust |
search_local(query, limit) |
Local-only search (works offline, < 10ms) |
fetch_page(url) |
Return full extracted text for a URL (from index cache or live crawl) |
crawl_url(url, depth) |
Submit a URL to be crawled and indexed by the network |
network_stats() |
Network status: peer count, index size, credit balance |
batch_search(queries) |
Run up to 10 search queries in one call |
suggest(prefix) |
Autocomplete / search suggestions |
register_webhook(url) |
Register webhook for crawl completion notifications |
analytics() |
Search/crawl/fetch counts and average latency |
explain(query) |
NEW — Score breakdown: BM25, freshness, trust components per result |
search_history(action) |
NEW — View or clear past search queries with latency stats |
search_rag(query) |
NEW — RAG-optimized chunked output with source attribution |
extract_answer(query) |
NEW — Direct answer extraction with confidence scores |
fact_check(claim) |
NEW — Cross-reference claims against indexed sources |
{
"mcpServers": {
"infomesh": {
"command": "uvx",
"args": ["infomesh", "mcp"]
}
}
}# Vector search with ChromaDB + sentence-transformers
uv sync --extra vector
# Local LLM summarization via Ollama
uv sync --extra llmv0.2.0 adds 100+ features across search intelligence, RAG support, security, observability, and developer experience. Here are the highlights:
| Feature | Description |
|---|---|
| 🧠 NLP Query Processing | Stop-word removal (9 languages), synonym expansion, natural language parsing |
| ✏️ Did-you-mean | Edit-distance spelling correction when no results found |
| 📊 Search Facets | Domain, language, and date-range facet counts per query |
| 🎯 Result Clustering | Groups results by domain for organized browsing |
| 🔦 Snippet Highlighting | Query terms highlighted in result snippets |
| 🧹 Smart Deduplication | Jaccard similarity-based near-duplicate removal |
| 🔍 Search Explain | Transparent score breakdowns for every result |
| Feature | Description |
|---|---|
| 📚 RAG Output | Chunked, source-attributed context windows for LLM consumption |
| 💡 Answer Extraction | Direct answers with confidence scores and source URLs |
| ✅ Fact Checking | Cross-reference claims against multiple indexed sources |
| 🏷️ Entity Extraction | Identifies persons, organizations, URLs, emails |
| 🛡️ Toxicity Filtering | Content safety scoring for search results |
| Feature | Description |
|---|---|
| 📄 PDF Extraction | Text extraction from crawled PDF documents |
| 🏗️ Structured Data | JSON-LD, OpenGraph, and meta tag parsing |
| 🌍 Language Detection | Script + word-frequency detection (9 languages) |
| 📡 RSS/Atom Feeds | Auto-discovery and parsing of feeds |
| 📝 Content Diffing | Change detection between crawl versions |
| 💻 Code Blocks | Extracts <pre><code> with language detection |
| 📊 Table Extraction | HTML tables → structured data (CSV/dict) |
| Feature | Description |
|---|---|
| 🔑 API Key Management | Create, validate, revoke, rotate keys |
| 👥 Role-Based Access | Admin/Reader/Crawler permission matrix |
| 📋 Audit Logging | SQLite-backed audit trail for all tool calls |
| 🔒 Webhook Signatures | HMAC-SHA256 payload verification |
| 📊 Prometheus Metrics | /metrics endpoint for monitoring |
| 📖 OpenAPI Spec | Auto-generated OpenAPI 3.1 at /openapi-spec |
| Feature | Description |
|---|---|
| 🐍 Python SDK | InfoMeshClient with sync/async search, crawl, suggest |
| 🔌 Plugin System | Register custom plugins with lifecycle hooks |
| 🦜 LangChain | InfoMeshRetriever integration |
| 🦙 LlamaIndex | InfoMeshReader integration |
| 🏗️ Haystack | InfoMeshDocumentStore integration |
| ⎈ Helm Chart | Kubernetes deployment with configurable resources |
| 🐳 Docker Compose | Multi-container setup with volumes |
See CHANGELOG.md for the complete list of changes.
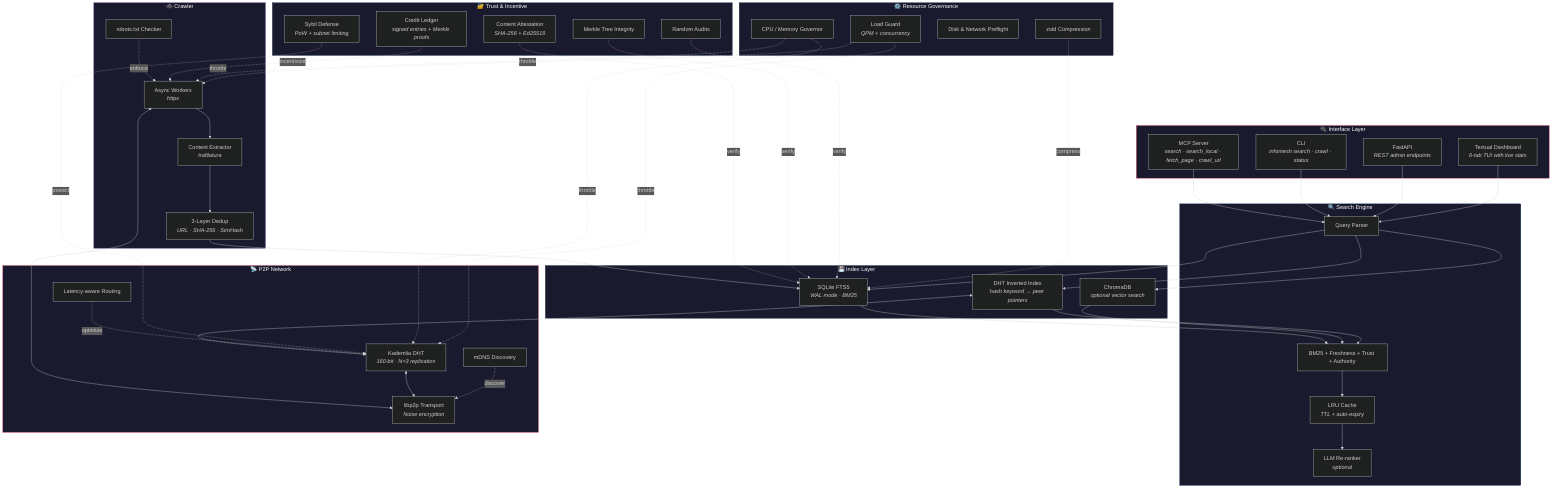
| Layer | Technology | Why |
|---|---|---|
| Language | Python 3.12+ | Modern async, type hints, match/case, StrEnum |
| P2P Network | libp2p (py-libp2p) | Battle-tested P2P stack with Kademlia DHT, Noise encryption |
| DHT | Kademlia (160-bit) | XOR distance-based routing, well-understood guarantees |
| Crawling | httpx + trafilatura | Best async HTTP + highest-accuracy content extraction |
| Keyword Search | SQLite FTS5 | Zero-install, embedded, BM25 out of the box |
| Vector Search | ChromaDB (optional) | Semantic / embedding search with all-MiniLM-L6-v2 |
| MCP Server | mcp-python-sdk | Standard protocol for LLM tool integration |
| Admin API | FastAPI | Local health, status, config endpoints |
| Serialization | msgpack | 2–5× faster and 30% smaller than JSON |
| Compression | zstandard | Level-tunable, dictionary mode for similar documents |
| Dashboard | Textual | Rich TUI with tabs, sparklines, EQ visualization, BGM |
| Local LLM | ollama / llama.cpp | On-node summarization (Qwen 2.5, Llama 3.x, Gemma 3) |
| Logging | structlog | Structured, machine-parseable logs |
| Packaging | uv | 10–100× faster than pip, handles everything |
InfoMesh is designed with a zero-trust assumption — every peer is potentially adversarial. The system provides multiple layers of defense:
| Mechanism | Description |
|---|---|
| Content Attestation | Every crawled page gets SHA-256(raw_html) + SHA-256(extracted_text), signed with the crawler's Ed25519 private key |
| Merkle Tree | Index-wide integrity proofs with membership verification — anyone can audit any document's inclusion |
| Random Audits | ~1/hr per node. 3 independent auditors re-crawl a random URL and compare content_hash. Mismatch = trust penalty |
| P2P Credit Verification | Signed credit entries with Merkle proofs, verifiable by any peer |
| Threat | Defense |
|---|---|
| Sybil Attack | Proof-of-Work node ID generation (~30s on avg CPU) + max 3 nodes per /24 subnet per DHT bucket |
| Eclipse Attack | ≥3 independent bootstrap sources + routing table subnet diversity + periodic refresh |
| DHT Poisoning | Per-keyword publish rate limit (10/hr/node) + signed publications + content hash verification |
| Credit Farming | 24hr probation for new nodes + statistical anomaly detection + raw HTTP hash audits |
| Man-in-the-Middle | All P2P transport encrypted via libp2p Noise protocol |
- Ed25519 key pairs stored in
~/.infomesh/keys/ - Key rotation:
infomesh keys rotate— generates new key pair, publishes dual-signed revocation record to DHT - Peer identity derived from public key hash (consistent with libp2p PeerId)
Every peer has a continuously updated trust score:
Trust = 0.15 × uptime + 0.25 × contribution + 0.40 × audit_pass_rate + 0.20 × summary_quality
| Tier | Score | Treatment |
|---|---|---|
| Trusted | ≥ 0.8 | Priority routing, lower search cost |
| Normal | 0.5 – 0.8 | Standard operation |
| Suspect | 0.3 – 0.5 | Higher audit frequency, limited features |
| Untrusted | < 0.3 | Network isolation after 3× consecutive audit failures |
InfoMesh is designed for production use, not just experimentation:
Enterprise environments can separate crawlers from indexers across network zones:
┌─────────── DMZ ──────────────┐ ┌──────── Private Network ────────┐
│ │ │ │
│ infomesh --role crawler ──────────────▶ infomesh --role search │
│ (crawls the public web) │ P2P │ (indexes + serves queries) │
│ │ auth │ │
│ infomesh --role crawler ──────────────▶ infomesh --role search │
│ │ │ │
└──────────────────────────────┘ └─────────────────────────────────┘
Three node roles:
| Role | Components | Use Case |
|---|---|---|
full (default) |
Crawler + Indexer + Search | Single-node or simple deployments |
crawler |
Crawler only, forwards pages to indexers | DMZ nodes with internet access |
search |
Indexer + Search only, accepts submissions | Private network, no internet needed |
Configuration example (~/.infomesh/config.toml):
# DMZ Crawler node
[node]
role = "crawler"
listen_address = "0.0.0.0"
[network]
index_submit_peers = ["/ip4/10.0.0.1/tcp/4001", "/ip4/10.0.0.2/tcp/4001"]# Private Search/Index node
[node]
role = "search"
listen_address = "10.0.0.1"
[network]
peer_acl = ["QmCrawler1PeerId...", "QmCrawler2PeerId..."]CLI usage:
# Start as DMZ crawler
infomesh start --role crawler --seeds tech-docs
# Start as private indexer
infomesh start --role search --no-dashboard- Resource Governor — CPU, memory, disk I/O, and bandwidth limits with 4 preset profiles (
minimal,balanced,contributor,dedicated). Dynamic throttling based on real-time system load - Pre-flight Checks — Disk space and network connectivity verified before startup
- Load Guard — QPM (queries per minute) + concurrency limiting to prevent node overload
- WAL Mode SQLite — Safe concurrent reads during dashboard refresh without locking crawl writes
- Structured Logging — All library code uses
structlogwith machine-parseable output - Docker Support — Production-ready
Dockerfilewith volume mounts for persistent data
- TOML Configuration (
~/.infomesh/config.toml) with environment variable overrides (INFOMESH_CRAWL_MAX_CONCURRENT=20) - Value Validation — All config values clamped to safe ranges with structured warnings
- Dashboard Settings — All configuration editable via the TUI Settings tab (no file editing required)
- Energy-aware Scheduling — LLM-heavy tasks preferentially scheduled during configured off-peak hours (1.5× credit multiplier)
- robots.txt strictly enforced — respects all crawl directives
- DMCA Takedown — Signed takedown requests propagated via DHT; nodes comply within 24 hours
- GDPR — Distributed deletion records for personal data; right-to-be-forgotten support
- Content Attribution — AI-generated summaries labeled with
content_hash+ source URL - Paywall Detection —
fetch_page()detects and respects paywalled content - Terms of Use — Clear TERMS_OF_USE.md covering crawler behavior and data handling
- Designed for thousands of nodes with Kademlia DHT routing
- 3-layer deduplication prevents index bloat (URL normalization → SHA-256 exact → SimHash near-duplicate)
- zstd-compressed snapshots for efficient index sharing between nodes
- Common Crawl data import for bootstrapping large indexes
Credits are the incentive mechanism that keeps the network healthy. They are tracked locally per node — no blockchain, no central ledger.
Credits Earned = Σ (Weight × Quantity × TimeMultiplier)
| Action | Weight | Category | How to Earn |
|---|---|---|---|
| Crawling | 1.0 /page | Base | Just run InfoMesh — it auto-crawls from seed URLs |
| Query Processing | 0.5 /query | Base | Other peers route search queries through your node |
| Document Hosting | 0.1 /hr | Base | Passive — your indexed documents serve the network |
| Network Uptime | 0.5 /hr | Base | Keep your node running. That's it |
| LLM Summarization | 1.5 /page | LLM | Enable local LLM to auto-summarize crawled content |
| LLM for Peers | 2.0 /request | LLM | Serve summarization requests from other nodes |
| PR — docs/typo | 1,000 /merged PR | Bonus | Fix a typo or improve documentation |
| PR — bug fix | 10,000 /merged PR | Bonus | Fix a bug with tests |
| PR — feature | 50,000 /merged PR | Bonus | Implement a new feature |
| PR — major | 100,000 /merged PR | Bonus | Core architecture or major feature |
- Base actions: Always
1.0× - LLM actions during off-peak hours (configurable, default 23:00–07:00):
1.5× - Off-peak scheduling is energy-conscious — the network preferentially routes batch LLM work to nodes currently in off-peak
| Tier | Contribution Score | Search Cost | Effective Ratio |
|---|---|---|---|
| Tier 1 | < 100 | 0.100 / query | 10 crawls → 100 searches |
| Tier 2 | 100 – 999 | 0.050 / query | 10 crawls → 200 searches |
| Tier 3 | ≥ 1,000 | 0.033 / query | 10 crawls → 300 searches |
- Non-LLM nodes are never starved: A node doing only crawling at 10 pages/hr earns 100 searches/hr at worst tier
- LLM earnings capped: LLM-related credits never exceed ~60% of total — LLM is a network bonus, not a participation requirement
- Uptime rewards: 0.5 credits/hr just for keeping your node online, regardless of hardware
- Search is never blocked: Even with zero credits, you can still search — see Zero-Dollar Debt below
What happens when your credits run out? You keep searching.
InfoMesh doesn't cut you off. There's no paywall, no "please enter your credit card," no upgrade button. Instead, there's a simple, human-friendly recovery path:
| Phase | Duration | What Happens |
|---|---|---|
| ✅ Normal | While balance > 0 | Search at normal cost. Business as usual. |
| ⏳ Grace Period | First 72 hours at zero | Search works exactly as before. Your balance goes negative, but there's no penalty. Take your time. |
| 📉 Debt Mode | After 72 hours | Search continues, but at 2× cost. Debt accumulates — incentivizing recovery, never blocking. |
| 🔄 Recovery | Whenever you want | Just run your node. Earn credits by crawling, hosting, or contributing. Once your balance is positive again, you're back to normal. |
Credits ran out
│
▼
┌─────────────────────────────────────┐
│ 🟢 Grace Period (72 hours) │
│ Search works normally. │
│ Balance goes negative — no penalty.│
└──────────────┬──────────────────────┘
│ 72h passed, still negative?
▼
┌─────────────────────────────────────┐
│ 🟡 Debt Mode │
│ Search continues at 2× cost. │
│ Debt accumulates. │
└──────────────┬──────────────────────┘
│ Earn credits → balance > 0
▼
┌─────────────────────────────────────┐
│ 🟢 Back to Normal │
│ Debt cleared. Grace reset. │
│ Full speed ahead. │
└─────────────────────────────────────┘
The key principle: Debt in InfoMesh is measured in credits, not money. You recover by contributing, not by paying. Run your node, crawl some pages, keep the network alive — and your debt disappears naturally.
No credit card. No dollars. No subscription. No "trial expired" popup. Just run your node, and you're back.
We welcome contributions of all kinds — code, documentation, bug reports, feature ideas, and seed URL lists.
# Clone and install
git clone https://github.com/dotnetpower/infomesh.git
cd infomesh
uv sync --dev
# Run the test suite (1,307 tests)
uv run pytest
# Run linter + formatter
uv run ruff check infomesh/ tests/
uv run ruff format .
# Run type checker
uv run mypy infomesh/| Contribution | Difficulty | Impact |
|---|---|---|
| 🐛 Report a bug | Easy | High — helps everyone |
| 📝 Improve docs / translations | Easy | High — lowers entry barrier |
| 🌱 Add seed URLs | Easy | Medium — expands crawl coverage |
| 🧪 Write tests | Medium | High — currently 1,307 tests, always need more |
| 🔧 Fix an issue | Medium | Direct impact |
| ✨ Implement a feature | Hard | Moves the project forward |
| 🔐 Security audit | Hard | Critical for trust |
- Formatter:
ruff format(black-compatible, 88 char lines) - Linter:
ruffwithE,F,I,UP,B,SIMrules - Type hints: Required on all public functions
- Docstrings: Required on all public classes and functions
- Tests: Every PR should include tests for new functionality
- No
print()in library code — usestructlog
- Fork the repository
- Create a feature branch:
git checkout -b feat/my-feature - Write code + tests
- Run
uv run pytest && uv run ruff check . - Submit a PR — you earn 1,000 – 100,000 credits per merged PR!
See CONTRIBUTING.md for the full guide.
Detailed documentation is available in the docs/ directory:
| Document | Description |
|---|---|
| Overview | Project vision, principles, and mission |
| Architecture | System design, data flow, and component interaction |
| Credit System | Full incentive mechanics and fairness analysis |
| Tech Stack | Technology choices and rationale |
| Legal | robots.txt, DMCA, GDPR, compliance |
| Trust & Integrity | Security model and threat analysis |
| Security Audit | Vulnerability analysis and enterprise hardening |
| Console Dashboard | TUI dashboard, tabs, widgets, shortcuts |
| MCP Integration | MCP server setup, IDE configuration guide |
| Publishing | PyPI packaging, CI/CD, release process |
📌 Documentation is also available in Korean (한국어).
| Metric | Value |
|---|---|
| Source modules | 130+ |
| Test files | 67 |
| Source lines | ~27,000 |
| Test lines | ~14,000 |
| Tests passing | 1,307 |
| MCP tools | 15 |
| Test coverage | Core modules fully tested |
| Development phases | 10 (Phase 0 → 6, all complete) |
| Python version | 3.12+ |
| License | MIT |
All core phases are complete. Current focus is on community growth and production hardening.
| Phase | Focus | Status |
|---|---|---|
| 0 | MVP — single-node crawl + index + MCP + CLI | ✅ Complete |
| 1 | Index sharing — snapshots, Common Crawl, vector search, SimHash | ✅ Complete |
| 2 | P2P network — libp2p, DHT, distributed crawl & index, Sybil/Eclipse defense | ✅ Complete |
| 3 | Quality + incentives — ranking, credits, trust, attestation, audits, LLM | ✅ Complete |
| 4 | Production — link graph, LLM re-ranking, attribution, legal compliance | ✅ Complete |
| 5A | Core stability — resource governor, auto-recrawl, query cache, load guard | ✅ Complete |
| 5B | Search quality — latency-aware routing, Merkle Tree integrity | ✅ Complete |
| 5C | Release readiness — Docker, key rotation, mDNS, LICENSE, CONTRIBUTING | ✅ Complete |
| 5D | Polish — LLM reputation, timezone verification, dashboard settings, P2P credit verification | ✅ Complete |
| 6 | Search intelligence, RAG, security, observability, SDK, integrations, DX | ✅ Complete |
- 🌍 Public bootstrap nodes — community-maintained seed nodes across multiple Azure regions
✅ Active: Bootstrap nodes are live in US East and US East 2. Your node connects automatically via
bootstrap/nodes.json. No manual configuration needed. - 🎭 JS rendering — Playwright-based SPA crawling for JS-heavy sites
- 📱 Web dashboard — optional browser UI alongside the TUI
- 🔍 Semantic search fusion — BM25 + vector hybrid ranking with RRF
- 🌐 Multi-language stemming — language-specific tokenization and stemming
- robots.txt: Strictly enforced. Sites that prohibit crawling are never crawled.
- Copyright: Full text stored as cache only; search results return snippets with source attribution.
- DMCA: Signed takedown requests propagated via DHT. All nodes must comply within 24 hours.
- GDPR: Distributed deletion records. Nodes can exclude pages with personal data.
- AI Summaries: Labeled as AI-generated, linked to source via
content_hash, original URL always provided. - Terms of Use: See TERMS_OF_USE.md for full terms.
InfoMesh stands on the shoulders of excellent open-source projects:
httpx • trafilatura • libp2p • SQLite • ChromaDB • Textual • FastAPI • mcp-python-sdk • uv • structlog • zstandard
MIT License — Copyright 2026 InfoMesh Contributors
If you find InfoMesh useful, consider ⭐ starring the repo — it helps others discover the project.