{kind=link}

Analytics Vidhya Hackathon to predict whether the policyholder will file a claim in the next 6 months or not.
This is my first attempt to a Hackathon and I used my Machine learning skills for this prediction task.
My private leaderboard rank : 164/2264
You are provided with information on policyholders containing the attributes like policy tenure, age of the car, age of the car owner, population density of the city, make and model of the car, power, engine type, etc and the target variable indicating whether the policyholder files a claim in the next 6 months or not
Predict whether the policyholder will file a claim in the next 6 months or not.
My approach towards the prediction problem:
- Perform data check
- Perfrom EDA
- Feature Engineering
- Check for Target Variable Imbalance.
- Dataset contains 58K observations out of which 54.8K belong to one class and 3.7K in other class.
- I used approach to resample the data.
- I used a lot of iterations and tried to build the model using all the observations, but due to low computational power, I was stuck in grid search for hours.
- To address this issue, I chose the path less travelled and went ahead with Undersampling of data to create a balanced dataset.
- But as we know, Undersampling comes with a disadvantage, and lesser data implies less accurate model, so I had to compromise accuracy for reaching model building conclusion.
- Undersampling resulted in 7.9K observations and with a balanced dataset.
- I had wasted a lot of time in creating models with the huge amount of data, so I wanted to experiment with this new framemwork PYCARET.
- I used pycaret to create several models, compare several models, used cross validation to find best parameters.
- Finally selected the gradient boosted trees algorithm for the dataset.
- F1 score on test data on Private leaderboard : 0.158145343845133
- This F1 score is achieved with the undersampled data, highest F1 score on the leaderboard was : 0.1820652174
- This is a good model considering that it has been trained on so less data.
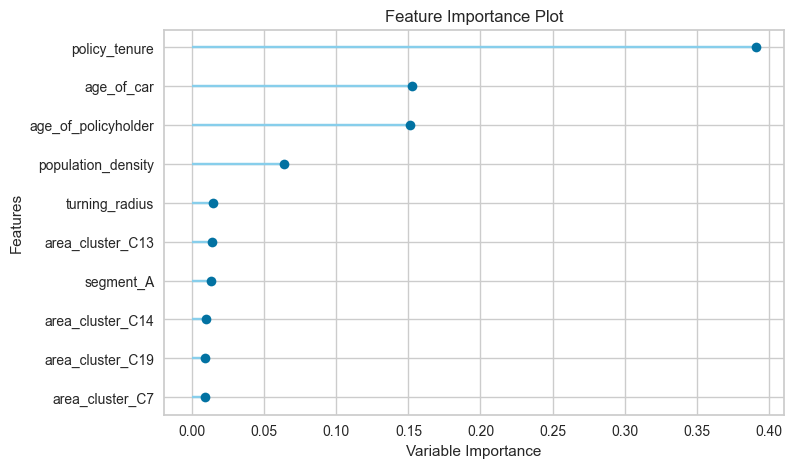
- Undersampling is not recommended for dataset as it leads to loss of data and we lose out on accuracy and predictions, there are other methods to use if the computational power is limited, but using undersampling should be the last resort.
- PyCaret can provide quick comparison of models.
No prizes won but this was a good learning experience where I could understand the need of computational power, understand data imbalance, understand how hackathons work, how to work under time constraints and try to know how other data science enthusiasts approach to the problem.