![]()

Raggify is a llama-index based Python library for building multimodal RAG(Retrieval-Augmented Generation) systems that run locally or as a service. It now ships with an asynchronous ingest pipeline for files, web pages, and URL lists, normalizes metadata, persists cache fingerprints to avoid redundant upserts, and keeps a document store in sync for BM25 / Vector hybrid retrieval.
Raggify is designed with the goal of natively handling multimodal data—including images, audio, video, and other unknown future modalities— from the outset, rather than repeatedly modifying systems based on text modality. It also serves to absorb various specification changes in the embedded models and client APIs provided by each AI provider.
raggify is currently in Beta. Core APIs are considered stable, but minor breaking changes may occur before the 1.0 release.
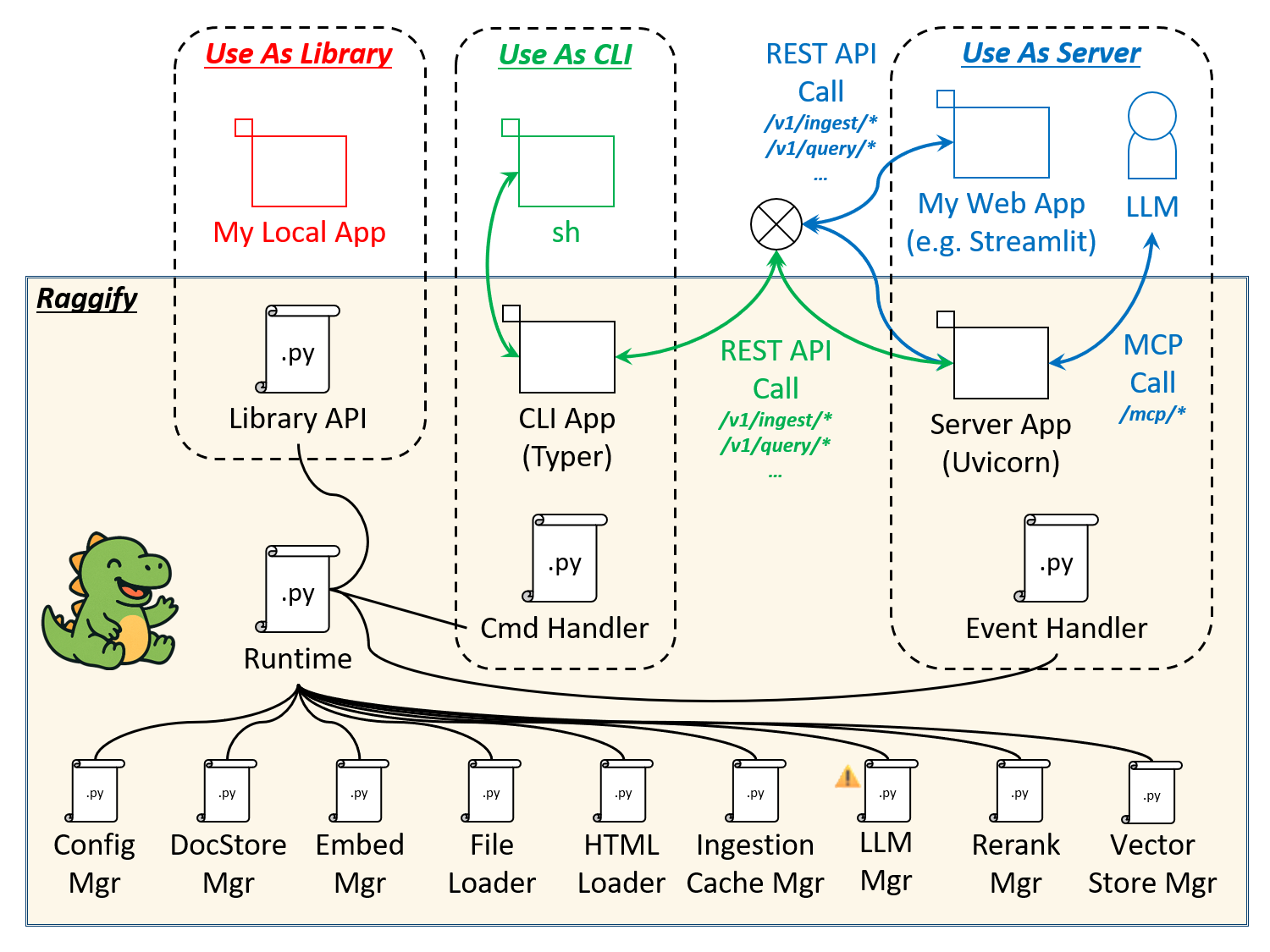
Raggify can be used in three ways: as a library, a CLI, and a server. Common to each usage scenario, the Runtime module acts as an intermediary between the various management modules and the configuration values in /etc/raggify/config.yaml (detail is at the end).
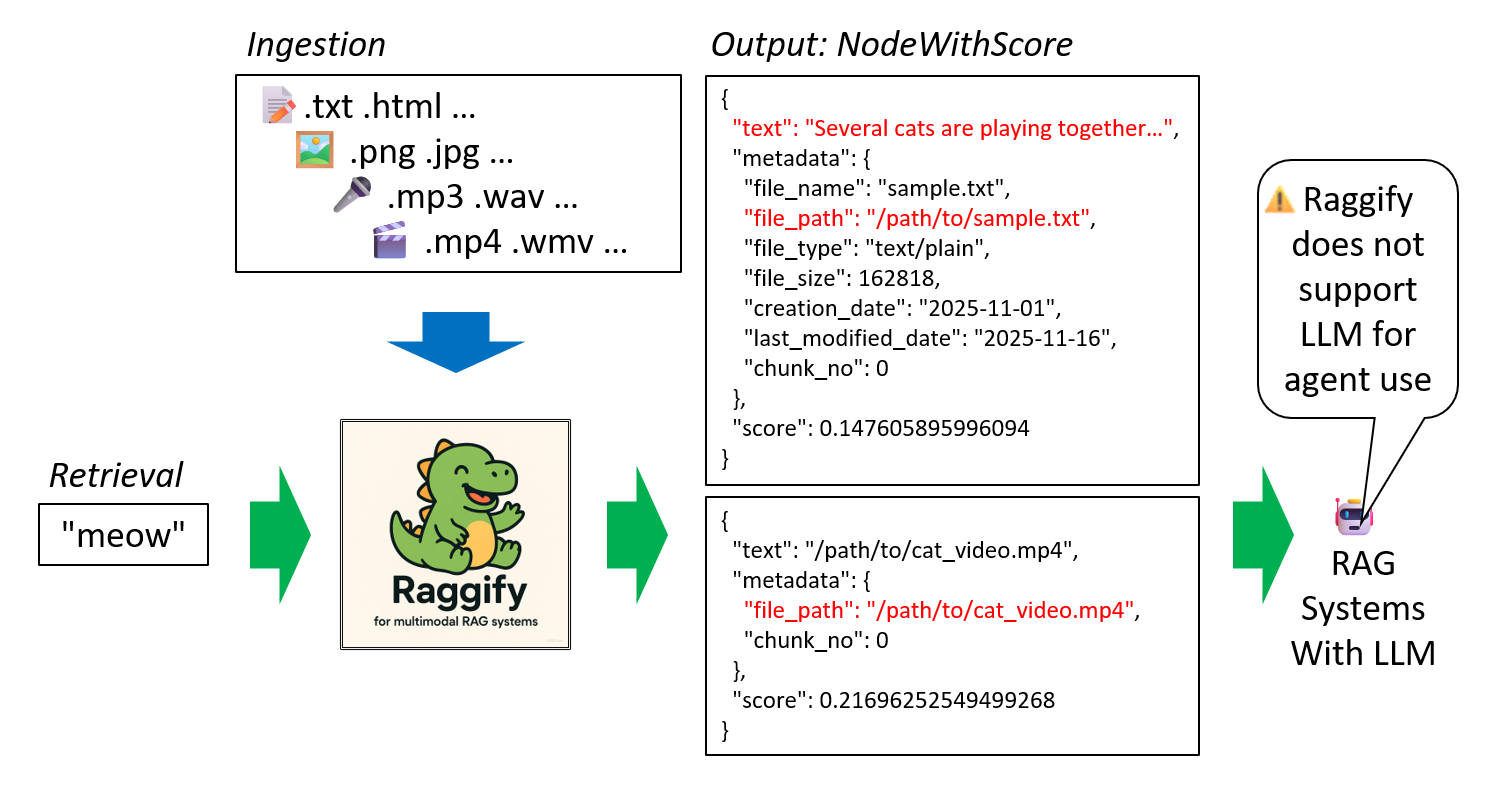
Ingestion Phase: Raggify ingests inputs from various modalities and file formats, accumulating them as a knowledge base.
Retrieval Phase: Searches documents across modalities (e.g., searching videos using audio) and returns results in NodeWithScore format (llama_index.core.schema).
Raggify is a tool for building multimodal RAG systems, but it does not directly support LLMs or agents. Instead, it focuses solely on the upstream processes of document ingestion and retrieval.
To install minimal, run:
pip install raggifyYou can also install with optional-dependencies:
pip install 'raggify[all]'is equal to
pip install 'raggify[text,image,audio,video,rerank,localmodel,postgres,redis,exam,dev]'- text, image, audio, video: to use embedding features
- rerank: to use reranking features
- localmodel: to use local embedding features (GPU usage recommended)
- postgres, redis: to use docstore, ingest cache, and vector store servers
- exam: to use examples/rag
- dev: to run tests
Then, put your required API-KEYs and credentials in .env file.
OPENAI_API_KEY="your-api-key"
COHERE_API_KEY="your-api-key"
VOYAGE_API_KEY="your-api-key"
AWS_ACCESS_KEY_ID="your-id"
AWS_SECRET_ACCESS_KEY="your-key"
AWS_REGION="us-east-1" # (default)
# AWS_PROFILE="your-profile" # (optional)
# AWS_SESSION_TOKEN = "your-token" # (optional)
# RG_CONFIG_PATH="/path/to/config.yaml" # (optional)
# RG_CLIENT_CONFIG_PATH="/path/to/client_config.yaml" # (optional)Default providers (configured at /etc/raggify/config.yaml) are:
raggify config | grep provider"vector_store_provider": "chroma",
"document_store_provider": "local",
"ingest_cache_provider": "local",
"text_embed_provider": "openai",
"image_embed_provider": null,
"audio_embed_provider": null,
"video_embed_provider": null,
"image_caption_transform_provider": null
"audio_caption_transform_provider": null
"video_caption_transform_provider": null
"rerank_provider": null,To use the following features, additional installation is required.
🖼️ local CLIP
pip install clip@git+https://github.com/openai/CLIP.git🎤🎬 ffmpeg
Example of Ubuntu
sudo apt-get update
sudo apt-get install ffmpegIngest from some web sites, then, search text documents by text query. For a list of interfaces available as library APIs, see main-modules.
import json
from raggify.ingest import ingest_url_list
from raggify.retrieve import query_text_text
urls = [
"https://en.wikipedia.org/wiki/Harry_Potter_(film_series)",
"https://en.wikipedia.org/wiki/Star_Wars_(film)",
"https://en.wikipedia.org/wiki/Forrest_Gump",
]
ingest_url_list(urls)
nodes = query_text_text("Half-Blood Prince")
for node in nodes:
print(
json.dumps(
obj={"text": node.text, "metadata": node.metadata, "score": node.score},
indent=2,
)
)Ingest from llamaindex wiki, then, search image documents by text query.
from raggify.ingest import ingest_url
from raggify.retrieve import query_text_image
url = "https://developers.llamaindex.ai/python/examples/multi_modal/multi_modal_retrieval/"
ingest_url(url)
nodes = query_text_image("what is the main character in Batman")Need to install:
pip install 'raggify[image,localmodel]'
pip install clip@git+https://github.com/openai/CLIP.gitand set image_embed_provider /etc/raggify/config.yaml:
image_embed_provider: CLIPIngest from some local files, then, search audio documents by text query.
from raggify.ingest import ingest_path_list
from raggify.retrieve import query_text_audio
paths = [
"/path/to/sound.mp3",
"/path/to/sound.wav",
"/path/to/sound.ogg",
]
ingest_path_list(paths)
nodes = query_text_audio("phone call")Need to install:
pip install 'raggify[audio,localmodel]'and set audio_embed_provider /etc/raggify/config.yaml:
audio_embed_provider: CLAPfrom raggify.ingest import ingest_path
from raggify.retrieve import query_image_video
knowledge_path = "/path/to/videos"
ingest_path(knowledge_path)
query_path = "/path/to/similar/image.png"
nodes = query_image_video(query_path)Need to install:
pip install 'raggify[video]'Currently, bedrock is the only provider that allows direct video embedding.
video_embed_provider: bedrockWhen using the video modality, please enter the following credentials in the .env file.
AWS_ACCESS_KEY_ID="your-id"
AWS_SECRET_ACCESS_KEY="your-key"
AWS_REGION="us-east-1" # (default)
# AWS_PROFILE="your-profile" # (optional)
# AWS_SESSION_TOKEN = "your-token" # (optional)- The video must be less than 30 seconds in length.
- The request body (video binary + JSON) must not exceed 100 MB.
You can use video_embed_provider: null and use_modality_fallback: true to ingest videos as images + audio.
Please note that using this fallback will result in, for example, hundreds frames of a single video being stored in the image modality store. use_modality_fallback is false in default.
After initial startup according to the /etc/raggify/config.yaml, hot-reload the config values.
from raggify.config.embed_config import EmbedProvider
from raggify.config.vector_store_config import VectorStoreProvider
from raggify.ingest import ingest_url
from raggify.logger import configure_logging
from raggify.runtime import get_runtime
configure_logging()
rt = get_runtime()
rt.cfg.general.vector_store_provider = VectorStoreProvider.PGVECTOR
rt.cfg.general.audio_embed_provider = EmbedProvider.CLAP
rt.cfg.ingest.text_chunk_size = 300
rt.cfg.ingest.same_origin = False
rt.rebuild()
ingest_url("http://some.site.com")To use pgvector, See also persisted data management.
Before using almost functions of the CLI, please start the server as follows:
raggify serverNow raggify server is online.

Accepted some commands via REST API.

Ctrl + c to shutdown.

After starting the server, you can send POST/GET requests using curl as follows.
# /status: Return server status.
curl -X GET http://localhost:8000/v1/status \
-H "Content-Type: application/json"
# /reload: Reload server configuration.
curl -X GET http://localhost:8000/v1/reload \
-H "Content-Type: application/json"
# /upload: Upload files (multipart/form-data).
curl -X POST http://localhost:8000/v1/upload \
-F "files=@/path/to/file1.pdf" \
-F "files=@/path/to/file2.png"
# /job: Inspect or remove background jobs.
curl -X POST http://localhost:8000/v1/job \
-H "Content-Type: application/json" \
-d '{"job_id": "", "rm": false}'
# /ingest/path: Ingest from a local path.
curl -X POST http://localhost:8000/v1/ingest/path \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/data"}'
# /ingest/path_list: Ingest paths listed in a file.
curl -X POST http://localhost:8000/v1/ingest/path_list \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/path_list.txt"}'
# /ingest/url: Ingest a single URL.
curl -X POST http://localhost:8000/v1/ingest/url \
-H "Content-Type: application/json" \
-d '{"url": "https://some.site.com"}'
# /ingest/url_list: Ingest URLs listed in a file.
curl -X POST http://localhost:8000/v1/ingest/url_list \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/url_list.txt"}'
# /query/text_text: Search text by text query.
curl -X POST http://localhost:8000/v1/query/text_text \
-H "Content-Type: application/json" \
-d '{"query": "Half-Blood Prince", "topk": 5, "mode": "fusion"}'
# /query/text_image: Search images by text query.
curl -X POST http://localhost:8000/v1/query/text_image \
-H "Content-Type: application/json" \
-d '{"query": "main character in Batman", "topk": 3}'
# /query/image_image: Search images by image file.
curl -X POST http://localhost:8000/v1/query/image_image \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/query.jpg", "topk": 3}'
# /query/text_audio: Search audio by text query.
curl -X POST http://localhost:8000/v1/query/text_audio \
-H "Content-Type: application/json" \
-d '{"query": "phone call", "topk": 3}'
# /query/audio_audio: Search audio by audio file.
curl -X POST http://localhost:8000/v1/query/audio_audio \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/query.wav", "topk": 3}'
# /query/text_video: Search videos by text query.
curl -X POST http://localhost:8000/v1/query/text_video \
-H "Content-Type: application/json" \
-d '{"query": "chainsaw cutting wood", "topk": 3}'
# /query/image_video: Search videos by image file.
curl -X POST http://localhost:8000/v1/query/image_video \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/frame.png", "topk": 3}'
# /query/audio_video: Search videos by audio file.
curl -X POST http://localhost:8000/v1/query/audio_video \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/query.mp3", "topk": 3}'
# /query/video_video: Search videos by video file.
curl -X POST http://localhost:8000/v1/query/video_video \
-H "Content-Type: application/json" \
-d '{"path": "/path/to/query.mp4", "topk": 3}'You can also use raggify_client.RestAPIClient module in your python app.
The raggify_client module can be installed separately as a distinct library named raggify-client.
The raggify library (server-side) includes raggify-client as a standard dependency package.
Sample RAG system is examples/rag. which uses raggify server as backend.
cd examples/rag
./run.shIf you haven't installed the dependency packages yet, please run the following.
pip install 'raggify[exam]'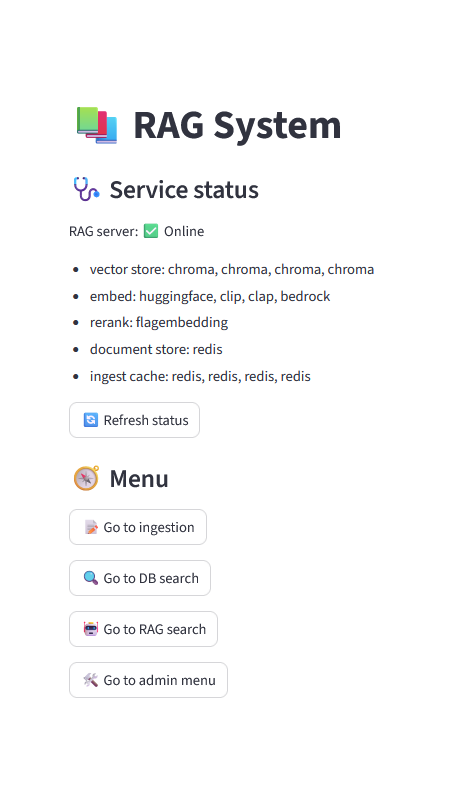
The server's startup status and various menus are displayed. Vector store, embed, and ingest caches are initialized for each modalities.
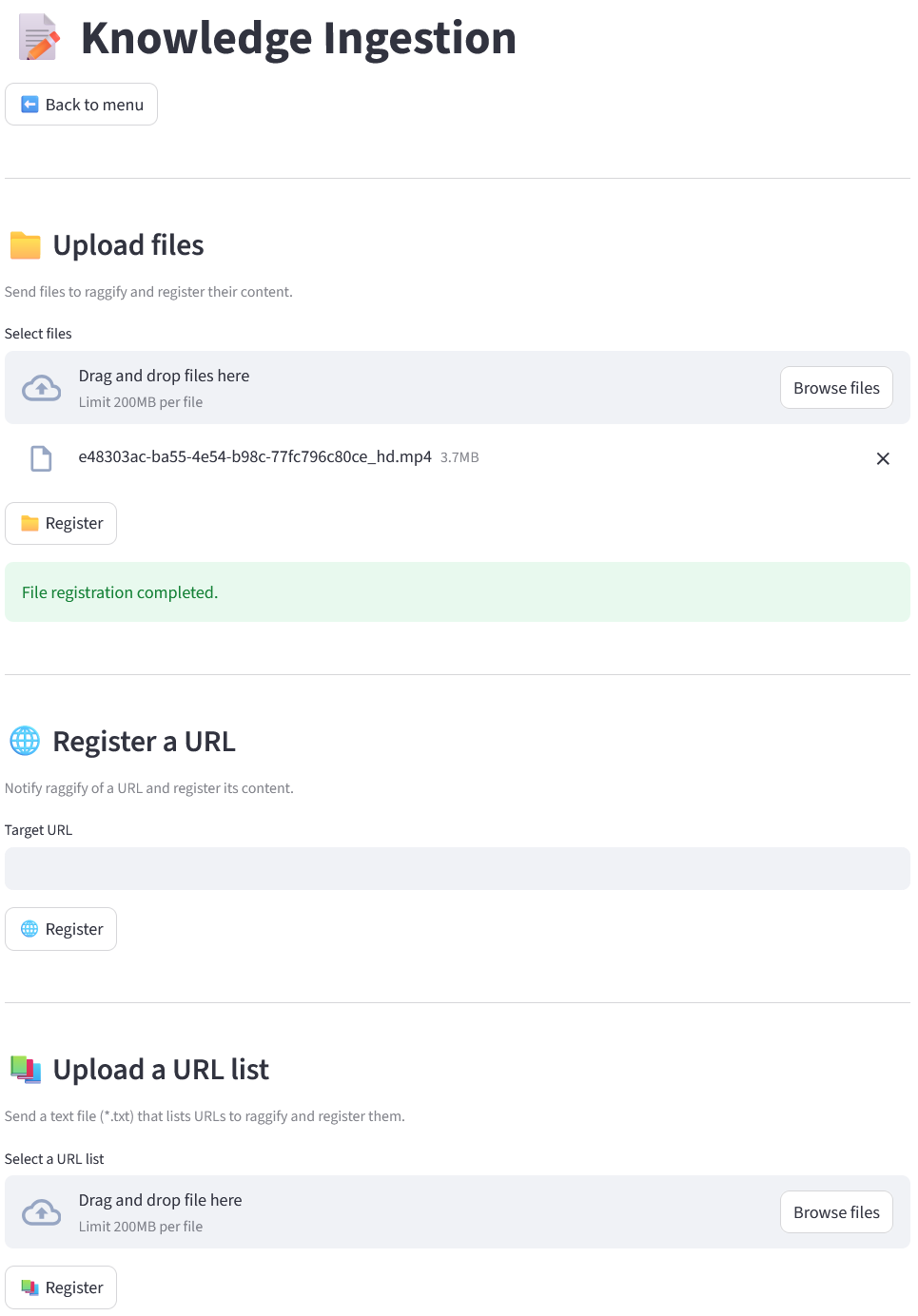
You can
- Upload files
- Register a URL
- Upload a URL list
in this menu.
A URL list follows the format below. Blank lines or comment lines starting with '#' are skipped.
http://some.site.com
http://hoge.site.com
# http://fuga.site.com
http://piyo.site.com/sitemap.xml
Sitemaps with the .xml extension are parsed by a dedicated parser, which recursively reads multiple URLs within the tree.
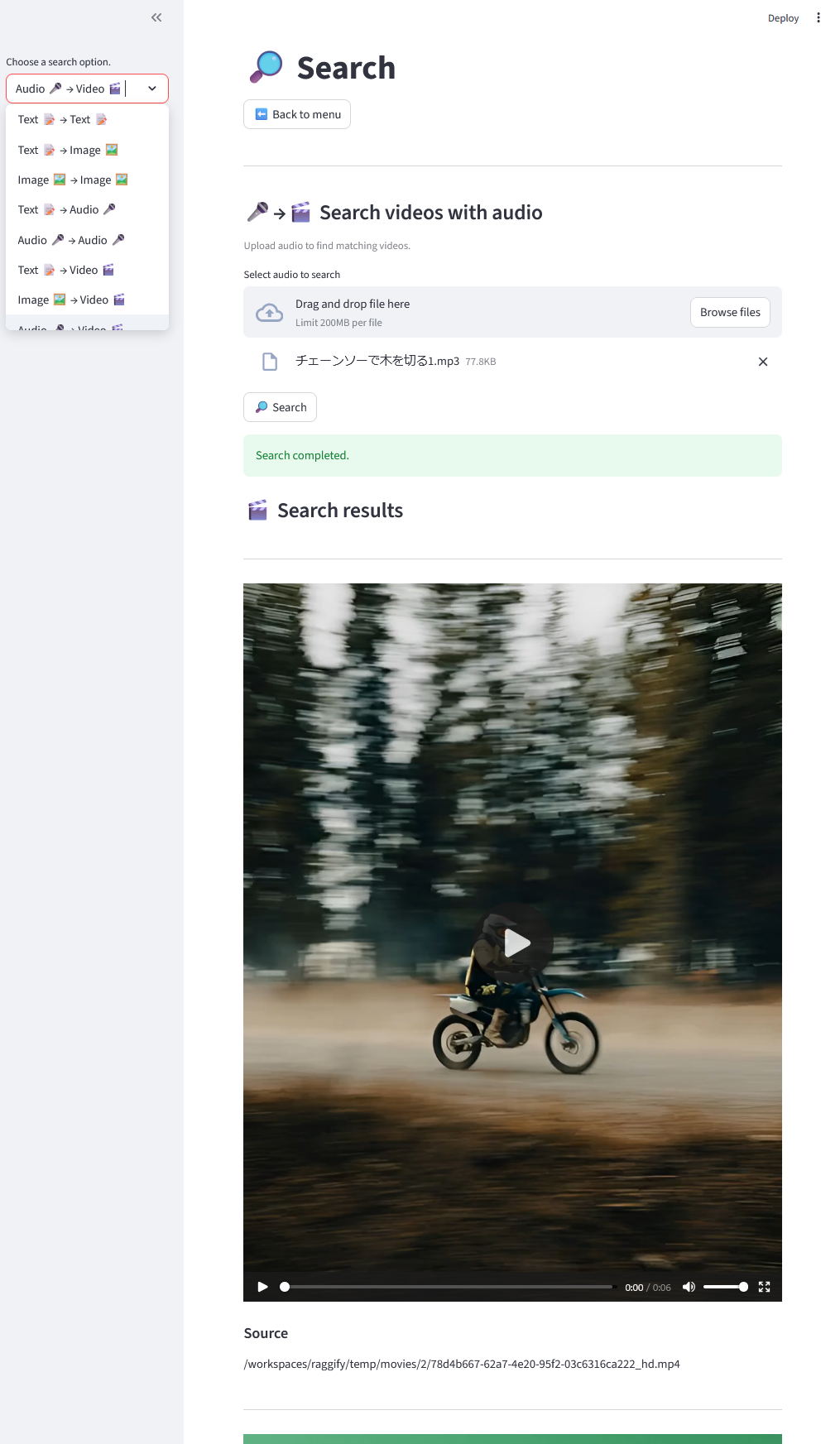
You can search for source information (file paths or URLs) across modalities. The image shows an example where an mp3 file containing the sound of a chainsaw cutting wood is used to search for footage of a motorcycle driving. (A buzzing sound can be heard in the video.)
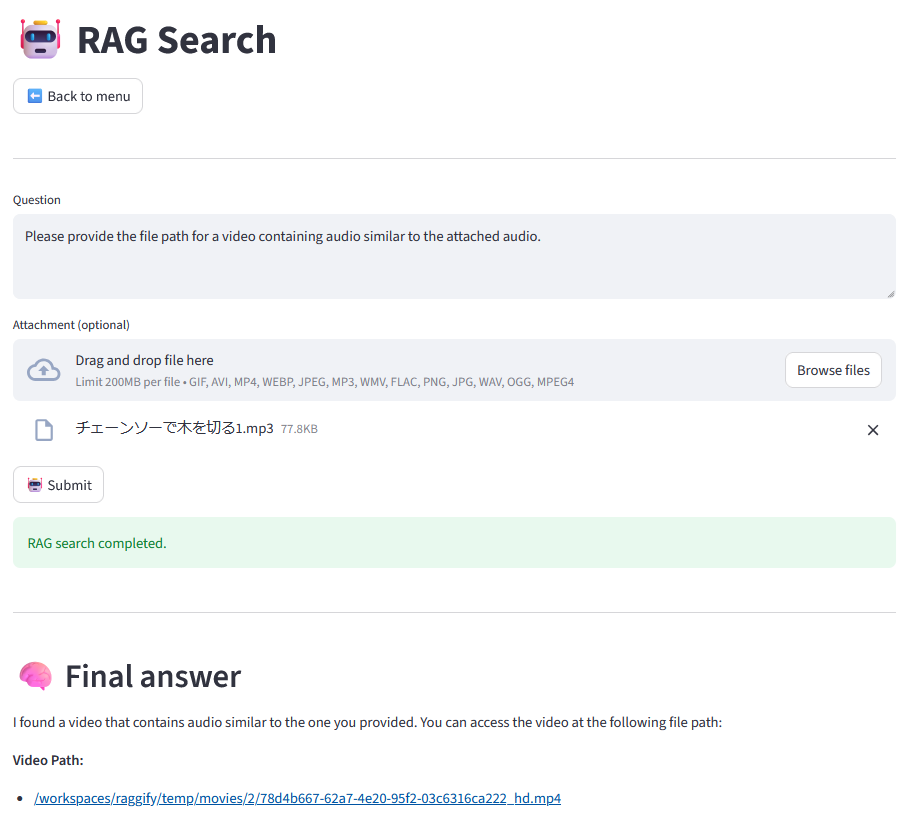
By feeding the previous search results to an LLM, you can complete this RAG search system.
At first, run:
raggify --help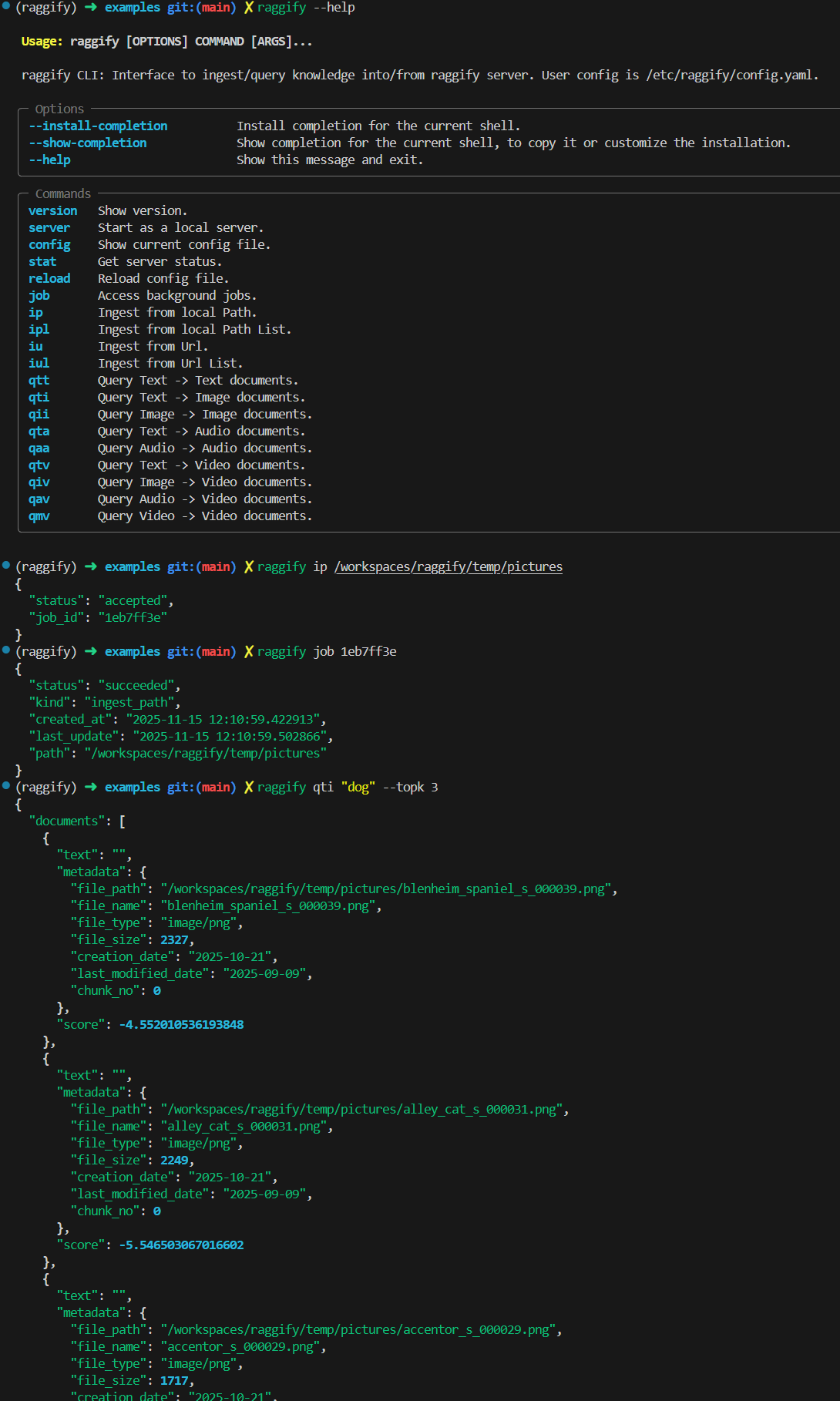
Some subcommands can be run independently, but all Ingest and Query subcommands require the Raggify server to be running. Therefore, you must first execute raggify server to start it.
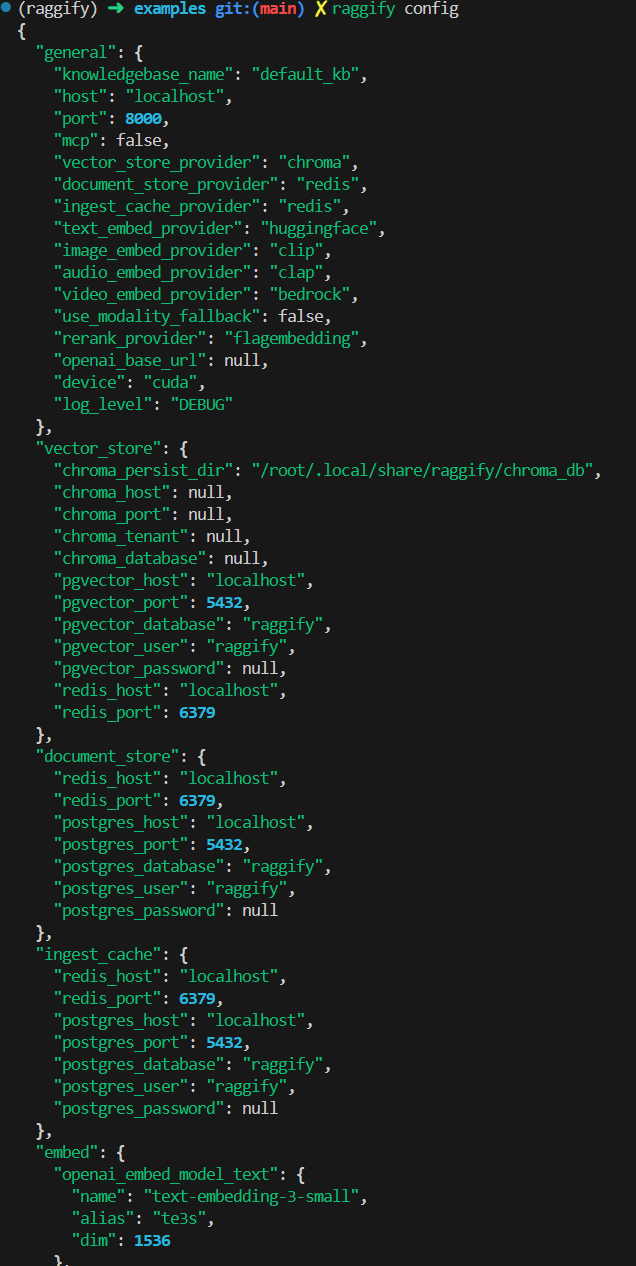
You can edit /etc/raggify/config.yaml to set default values, used by raggify runtime.
Note that if you run raggify config with the config.yaml file deleted, it will regenerate the files using the default settings.
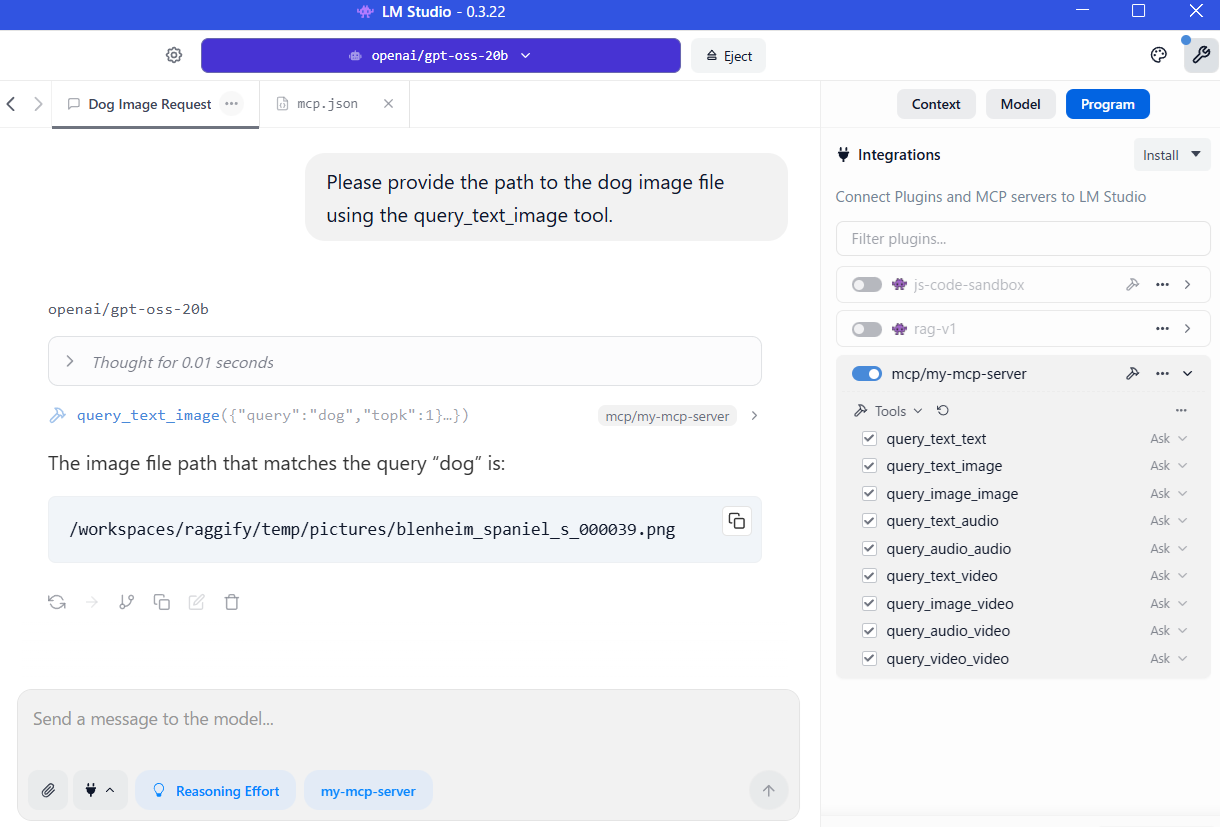
You can also specify --mcp option when you up server,
raggify server --mcpor edit config.yaml.
mcp: trueFor example, LM Studio mcp.json:
{
"mcpServers": {
"my_mcp_server": {
"url": "http://localhost:8000/mcp"
}
}
}We were able to have the LLM use the tool as an MCP server.
When using the following settings, ~/.local/share/raggify is used as the default persistent directory.
vector_store_provider: chroma
document_store_provider: local
ingest_cache_provider: localℹ️ To delete all data, using rm -rf ~/.local/share/raggify.
You can also edit persistent directory.
chroma_persist_dir: /root/.local/share/raggify/chroma_db
upload_dir: /root/.local/share/raggify/upload
pipe_persist_dir: /root/.local/share/raggify/default_kbWhen using the following settings, it is convenient to use a dedicated script init_pgdb.sh.
vector_store_provider: pgvector # Note: pgvector (not postgres)
document_store_provider: postgres
ingest_cache_provider: postgres- start postgresql server
- exec examples/init_pgdb.sh
- for the first time:
./init_pgdb.sh- If you use native postgresql (not use docker), you also need to exec at first:
sudo -u postgres psql -c "ALTER USER postgres WITH PASSWORD 'raggify';"
- If you use native postgresql (not use docker), you also need to exec at first:
- If you want to reset db (drop all tables):
./init_pgdb.sh --reset. Or manually execute DELETE queries against the database.
- for the first time:
- set
pgvector_passwordat /etc/raggify/config.yaml- init_pgdb.sh set
raggifyas default password, so write it.
- init_pgdb.sh set
vector_store:
pgvector_host: localhost,
pgvector_port: 5432,
pgvector_database: raggify,
pgvector_user: raggify,
pgvector_password: raggify # default is nulldocument_store:
postgres_host: localhost,
postgres_port: 5432,
postgres_database: raggify,
postgres_user: raggify,
postgres_password: raggify # default is null
ingest_cache:
# as aboveUsing Docker containers is easy.
docker run --name pgvector \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=raggify \
-e POSTGRES_DB=raggify \
-p 5432:5432 \
-d pgvector/pgvector:pg17When using the following settings, it is convenient to use a dedicated script init_redis.sh.
vector_store_provider: redis
document_store_provider: redis
ingest_cache_provider: redis- start redis server
- exec examples/init_redis.sh
- for the first time:
./init_redis.sh- Only connection check. Optional.
- If you want to reset db (drop all tables):
./init_redis.sh --reset. Or manually execute DELETE queries against the database.
- for the first time:
- set
redis_passwordat /etc/raggify/config.yaml- init_redis.sh set
raggifyas default password, so write it.
- init_redis.sh set
vector_store:
redis_host: localhost
redis_port: 6379
document_store:
ingest_cache:
# as aboveUsing Docker containers is easy.
docker run --rm -p 6379:6379 --name redis-stack redis/redis-stack-server:latestWe also provide Runtime.delete_all_persisted_data() to delete all data. However, unexpected omissions may occur due to document ID inconsistencies or other issues, so we recommend using the rm -rf ~/.local/share/raggify or ./init_*.sh --reset introduced in each chapter.
Generally, edit /etc/raggify/config.yaml before starting the server. You can also access the runtime to hot-reload configuration values, but this process is resource-intensive.
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
knowledgebase_name |
Identifier for the knowledge base. | default_kb |
Any string (e.g., project_a). |
host |
Hostname the FastAPI server binds to. | localhost |
Any hostname/IP (e.g., 0.0.0.0). |
port |
Port number for the FastAPI server. | 8000 |
Any integer port. |
mcp |
Enable MCP server alongside FastAPI. | false |
true / false. |
vector_store_provider |
Vector store backend. | chroma |
chroma, pgvector, redis. |
document_store_provider |
Document store backend. | local |
local, redis, postgres. |
ingest_cache_provider |
Ingest cache backend. | local |
local, redis, postgres. |
text_embed_provider |
Provider for text embeddings. | openai |
openai, cohere, clip(huggingface, voyage, bedrock, or null. |
image_embed_provider |
Provider for image embeddings. | cohere |
cohere, clip(huggingface, voyage, bedrock, or null. |
audio_embed_provider |
Provider for audio embeddings. | bedrock |
clap, bedrock, or null. |
video_embed_provider |
Provider for video embeddings. | bedrock |
bedrock or null. |
rerank_provider |
Provider for reranking. | cohere |
flagembedding, cohere, voyage, or null. |
parser_provider |
Parser backend for document ingestion. | local |
local, llama_cloud. |
use_modality_fallback |
Decompose unsupported media into lower modalities. | false |
true / false. |
openai_base_url |
Custom OpenAI-compatible endpoint. | null |
Any URL string or null. |
device |
Target device for embedding models. | cpu |
cpu, cuda, mps. |
log_level |
Logging verbosity. | DEBUG |
DEBUG, INFO, WARNING, ERROR, CRITICAL. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
chroma_persist_dir |
Chroma persistence directory. | ~/.local/share/raggify/chroma_db |
Any filesystem path. |
chroma_host |
External Chroma hostname. | null |
Any hostname or null. |
chroma_port |
External Chroma port. | null |
Any integer port or null. |
chroma_tenant |
Chroma tenant name. | null |
Any string or null. |
chroma_database |
Chroma database name. | null |
Any string or null. |
pgvector_host |
PGVector hostname. | localhost |
Any hostname. |
pgvector_port |
PGVector port. | 5432 |
Any integer port. |
pgvector_database |
PGVector database name. | raggify |
Any string. |
pgvector_user |
PGVector user. | raggify |
Any string. |
pgvector_password |
PGVector password. | null |
Any string (required when pgvector is selected). |
redis_host |
Redis host for vector search. | localhost |
Any hostname. |
redis_port |
Redis port for vector search. | 6379 |
Any integer port. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
redis_host |
Redis host for docstore. | localhost |
Any hostname. |
redis_port |
Redis port for docstore. | 6379 |
Any integer port. |
postgres_host |
Postgres host for docstore. | localhost |
Any hostname. |
postgres_port |
Postgres port for docstore. | 5432 |
Any integer port. |
postgres_database |
Postgres database name. | raggify |
Any string. |
postgres_user |
Postgres user. | raggify |
Any string. |
postgres_password |
Postgres password. | null |
Any string or null. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
redis_host |
Redis host for ingest cache. | localhost |
Any hostname. |
redis_port |
Redis port for ingest cache. | 6379 |
Any integer port. |
postgres_host |
Postgres host for ingest cache. | localhost |
Any hostname. |
postgres_port |
Postgres port for ingest cache. | 5432 |
Any integer port. |
postgres_database |
Postgres database name. | raggify |
Any string. |
postgres_user |
Postgres user. | raggify |
Any string. |
postgres_password |
Postgres password. | null |
Any string or null. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
batch_size |
Number of nodes processed per embed batch. | 1000 |
Any positive integer. |
batch_interval_sec |
Delay between embedding batches (seconds). | 1 |
Any non-negative integer. |
openai_embed_model_text.name |
OpenAI text embed model. | text-embedding-3-small |
Fixed model name. |
openai_embed_model_text.alias |
Alias for OpenAI text embed model. | te3s |
Any string. |
openai_embed_model_text.dim |
Dimension of OpenAI text embeddings. | 1536 |
Fixed value. |
cohere_embed_model_text.name |
Cohere text embed model. | embed-v4.0 |
Fixed model name. |
cohere_embed_model_text.alias |
Alias for Cohere text embed model. | emv4 |
Any string. |
cohere_embed_model_text.dim |
Dimension of Cohere text embeddings. | 1536 |
Fixed value. |
clip_embed_model_text.name |
CLIP text embed model. | ViT-B/32 |
Fixed model name. |
clip_embed_model_text.alias |
Alias for CLIP text embed model. | vi32 |
Any string. |
clip_embed_model_text.dim |
Dimension of CLIP text embeddings. | 512 |
Fixed value. |
clap_embed_model_text.name |
CLAP text embed model. | laion/clap-htsat-unfused |
Any Hugging Face CLAP checkpoint ID. |
clap_embed_model_text.alias |
Alias for CLAP text embed model. | lchu |
Any string. |
clap_embed_model_text.dim |
Dimension of CLAP text embeddings. | 512 |
Fixed value. |
huggingface_embed_model_text.name |
Hugging Face text embed model. | intfloat/multilingual-e5-base |
Fixed model name. |
huggingface_embed_model_text.alias |
Alias for Hugging Face text embed model. | imeb |
Any string. |
huggingface_embed_model_text.dim |
Dimension of Hugging Face text embeddings. | 768 |
Fixed value. |
voyage_embed_model_text.name |
Voyage text embed model. | voyage-3.5 |
Fixed model name. |
voyage_embed_model_text.alias |
Alias for Voyage text embed model. | vo35 |
Any string. |
voyage_embed_model_text.dim |
Dimension of Voyage text embeddings. | 2048 |
Fixed value. |
bedrock_embed_model_text.name |
Bedrock text embed model. | amazon.nova-2-multimodal-embeddings-v1:0 |
Fixed model name. |
bedrock_embed_model_text.alias |
Alias for Bedrock text embed model. | n2v1 |
Any string. |
bedrock_embed_model_text.dim |
Dimension of Bedrock text embeddings. | 1024 |
Fixed value. |
cohere_embed_model_image.name |
Cohere image embed model. | embed-v4.0 |
Fixed model name. |
cohere_embed_model_image.alias |
Alias for Cohere image embed model. | emv4 |
Any string. |
cohere_embed_model_image.dim |
Dimension of Cohere image embeddings. | 1536 |
Fixed value. |
clip_embed_model_image.name |
CLIP image embed model. | ViT-B/32 |
Fixed model name. |
clip_embed_model_image.alias |
Alias for CLIP image embed model. | vi32 |
Any string. |
clip_embed_model_image.dim |
Dimension of CLIP image embeddings. | 512 |
Fixed value. |
huggingface_embed_model_image.name |
Hugging Face image embed model. | llamaindex/vdr-2b-multi-v1 |
Fixed model name. |
huggingface_embed_model_image.alias |
Alias for Hugging Face image embed model. | v2m1 |
Any string. |
huggingface_embed_model_image.dim |
Dimension of Hugging Face image embeddings. | 1536 |
Fixed value. |
voyage_embed_model_image.name |
Voyage image embed model. | voyage-multimodal-3 |
Fixed model name. |
voyage_embed_model_image.alias |
Alias for Voyage image embed model. | vom3 |
Any string. |
voyage_embed_model_image.dim |
Dimension of Voyage image embeddings. | 1024 |
Fixed value. |
bedrock_embed_model_image.name |
Bedrock image embed model. | amazon.nova-2-multimodal-embeddings-v1:0 |
Fixed model name. |
bedrock_embed_model_image.alias |
Alias for Bedrock image embed model. | n2v1 |
Any string. |
bedrock_embed_model_image.dim |
Dimension of Bedrock image embeddings. | 1024 |
Fixed value. |
clap_embed_model_audio.name |
CLAP audio embed model. | laion/clap-htsat-unfused |
Any Hugging Face CLAP checkpoint ID. |
clap_embed_model_audio.alias |
Alias for CLAP audio embed model. | lchu |
Any string. |
clap_embed_model_audio.dim |
Dimension of CLAP audio embeddings. | 512 |
Fixed value. |
bedrock_embed_model_audio.name |
Bedrock audio embed model. | amazon.nova-2-multimodal-embeddings-v1:0 |
Fixed model name. |
bedrock_embed_model_audio.alias |
Alias for Bedrock audio embed model. | n2v1 |
Any string. |
bedrock_embed_model_audio.dim |
Dimension of Bedrock audio embeddings. | 1024 |
Fixed value. |
bedrock_embed_model_video.name |
Bedrock video embed model. | amazon.nova-2-multimodal-embeddings-v1:0 |
Fixed model name. |
bedrock_embed_model_video.alias |
Alias for Bedrock video embed model. | n2v1 |
Any string. |
bedrock_embed_model_video.dim |
Dimension of Bedrock video embeddings. | 1024 |
Fixed value. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
text_chunk_size |
Chunk size for text splitting. | 500 |
Any integer (e.g., 500, 1024). |
text_chunk_overlap |
Overlap between adjacent chunks. | 50 |
Any integer. |
hierarchy_chunk_sizes |
Chunk sizes for hierarchical text splitting. | [2048, 512, 256] |
List of integers, large to small (e.g., [2048, 512, 256]). |
upload_dir |
Directory for uploaded files. | ~/.local/share/raggify/upload |
Any filesystem path. |
audio_chunk_seconds |
Chunk length for audio splitting (seconds). | 15 |
Positive integer, or null to disable splitting. |
video_chunk_seconds |
Chunk length for video splitting (seconds). | 15 |
Positive integer, or null to disable splitting. |
additional_exts |
Extra whitelist extensions for local ingest. | [".c", ".py", ".rst"] |
List of dot-prefixed extensions. |
skip_known_sources |
Skip ingestion when the source already exists in the docstore. | false |
true / false. |
user_agent |
User-Agent header for web ingestion. | raggify |
Any string. |
load_asset |
Download linked assets during web ingestion. | true |
true / false. |
req_per_sec |
Request rate limit for web ingestion. | 2 |
Any integer. |
timeout_sec |
Timeout for web ingestion (seconds). | 30 |
Any integer. |
same_origin |
Restrict crawling to same origin. | true |
true / false. |
max_asset_bytes |
Maximum size per fetched asset (bytes). | 104857600 (100 MB) |
Any positive integer. |
include_selectors |
CSS selectors to prioritize when parsing HTML | ["article", "main", ...] |
List of selectors applied in order. |
exclude_selectors |
CSS selectors removed from parsed HTML. | ["nav", "footer", ...] |
List of selectors to drop. |
strip_tags |
HTML tags stripped entirely before parsing. | ["script", "style", ...] |
List of tag names. |
strip_query_keys |
Query parameters removed during URL normalization. | ["utm_source", "utm_medium", ...] |
List of query parameter keys. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
persist_dir |
Pipeline persistence root per KB. | ~/.local/share/raggify/default_kb |
Any filesystem path. |
batch_size |
Number of nodes processed per pipeline batch. | 10 |
Any positive integer. |
batch_retry_interval_sec |
Backoff schedule (seconds) between retries of a failed batch. | [1.0, 2.0, 4.0, 8.0, 16.0] |
List of floats. |
batch_interval_sec |
Delay (seconds) inserted between batches to throttle throughput. | 0.5 |
Any non-negative float. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
flagembedding_rerank_model |
FlagEmbedding reranker model name. | BAAI/bge-reranker-v2-m3 |
Fixed model name. |
cohere_rerank_model |
Cohere reranker model name. | rerank-multilingual-v3.0 |
Fixed model name. |
voyage_rerank_model |
Voyage reranker model name. | rerank-2.5 |
Fixed model name. |
topk |
Number of candidates considered for reranking. | 20 |
Any integer (e.g., 10, 20). |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
mode |
Retrieval strategy. | fusion |
vector_only, bm25_only, fusion. |
bm25_topk |
Number of docstore hits when using BM25. | 10 |
Any integer. |
fusion_lambda_vector |
Weight for vector retriever in QueryFusion. | 0.5 |
Float 0–1. |
fusion_lambda_bm25 |
Weight for BM25 retriever in QueryFusion. | 0.5 |
Float 0–1. |
auto_merge_ratio |
Threshold for AutoMergingRetriever merging. | 0.5 |
Float 0–1. |
| Parameter | Description | Default | Allowed values / examples |
|---|---|---|---|
openai_image_caption_transform_model |
OpenAI multimodal model for image captioning. | gpt-4o-mini |
Any OpenAI multimodal-capable model. |
openai_audio_caption_transform_model |
OpenAI multimodal model for audio captioning. | gpt-4o-mini |
Any OpenAI multimodal-capable model. |
openai_video_caption_transform_model |
OpenAI multimodal model for video captioning. | gpt-4o-mini |
Any OpenAI multimodal-capable model. |
vector_store_provider: chroma
document_store_provider: local
ingest_cache_provider: local
text_embed_provider: huggingface
image_embed_provider: clip
audio_embed_provider: clap
video_embed_provider: null
rerank_provider: flagembedding
use_modality_fallback: true
device: cudaNative video embedding is not supported yet in local (please tell us when a local model becomes available!).
You can use video_embed_provider: null and use_modality_fallback: true to ingest videos as images + audio.
Due to the heavy processing load, we recommend using a GPU (device: cuda).
vector_store_provider: chroma
document_store_provider: redis
ingest_cache_provider: redis
text_embed_provider: openai
image_embed_provider: voyage
audio_embed_provider: clap
video_embed_provider: bedrock
rerank_provider: cohere
device: cudauser_agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
same_origin: falselog_level: warning# For reference. Retrievers return this structure
from llama_index.core.schema import NodeWithScore
# For ingestion
from raggify.ingest import (
aingest_path,
aingest_path_list,
aingest_url,
aingest_url_list,
ingest_path,
ingest_path_list,
ingest_url,
ingest_url_list,
)
# For logging
from raggify.logger import configure_logging, logger
# For retrieval
from raggify.retrieve import (
aquery_audio_audio,
aquery_audio_video,
aquery_image_image,
aquery_image_video,
aquery_text_audio,
aquery_text_image,
aquery_text_text,
aquery_text_video,
aquery_video_video,
query_audio_audio,
query_audio_video,
query_image_image,
query_image_video,
query_text_audio,
query_text_image,
query_text_text,
query_text_video,
query_video_video,
)
# For hot reloading config
from raggify.runtime import get_runtime
from raggify.config import (
DocumentStoreProvider,
EmbedModel,
EmbedProvider,
IngestCacheProvider,
RerankProvider,
RetrieveMode,
VectorStoreProvider,
)# For REST API Call to the server
from raggify_client import RestAPIClient- Text:
.txt,.text,.md,.json,.html,.tex - Image:
.png,.jpg,.jpeg,.gif,.webp - Audio:
.mp3,.wav,.ogg - Video:
.mp4,.mov,.mkv,.webm,.flv,.mpeg,.mpg,.wmv,.3gp,
Additionally, any extensions added via the additional_exts configuration parameter are also supported.
- https://pypi.org/project/raggify/
- https://pypi.org/project/raggify-client/
- マルチモーダルでローカルな RAG 基盤ライブラリを作ってみた
- The predecessor of Raggify: マルチモーダルでローカルな RAG 基盤サーバを作ってみた
The Raggify logo © 2025 Jun.
You may use it to refer to the Raggify open-source project,
but commercial or misleading usage is not allowed.