{kind=link}
{kind=link}
{kind=link}
{kind=link}
AIMA, Inteligência Artificial. Capítulo 17 Interação de valor Algoritmo em Python
Suponha que um agente esteja situado no ambiente 4 x 3 mostrado na Figura 17.1(a). Começando no estado inicial, ele deve escolher uma ação em cada passo de tempo. A interação com o ambiente termina quando o agente alcança um dos estados objetivos, marcados com +1 ou –1. Assim como para problemas de busca, as ações disponíveis para o agente em cada estado são dadas por AÇÕES(s), algumas vezes abreviado como A(s); no ambiente 4 x 3, as ações em todos os estados são Acima, Abaixo, Esquerda e Direita. Vamos supor, por enquanto,que o ambiente seja completamente observável, de forma que o agente sempre saiba onde está.
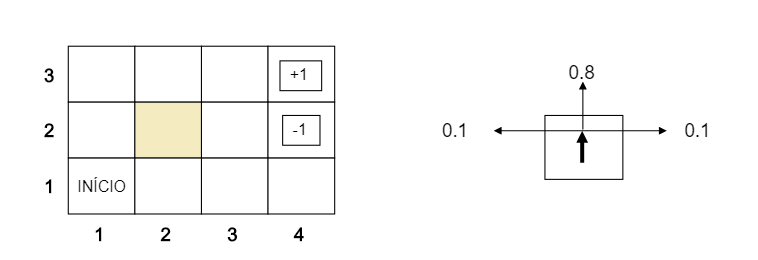
Figura 1: {(a) Um ambiente simples de 4 x 3 que apresenta ao agente um problema de decisão sequencial. (b) Ilustração do modelo de transição do ambiente: o resultado "pretendido" ocorre com probabilidade 0,8, mas com probabilidade 0,2 o agente se move em um ângulo reto em relação à direção pretendida. Uma colisão com uma parede resulta em nenhum movimento. Os dois estados terminais têm recompensa +1 e -1, respectivamente, e todos os outros estados têm recompensa –0,04
Nas Figuras 1 e 2 é possível visualizar as ações possíveis do agente estando no estado (0,0). Ao todo são quatro ações possíveis, sendo elas: Direita, Esquerda, Cima e Baixo. Como o agente está limitado a um espaço 4x3 as ações que violam esses espaço e ou o ambiente, resultam na permanência do agente no mesmo estado, sendo que, se existir mais de uma ação que não é possível por limitação do ambiente, as probabilidades são somadas. Por exemplo, na Figura 1 nota-se que a ação para esquerda não é possível, sendo que o agente tem a probabilidade de 0.8 de conseguir o estado alvo, nesse caso, 0.8 de permanecer no estado. Nota-se também que a ação de ir pra cima também não é possível, nesse caso é somado as probabilidades, então a probabilidade do agente ficar no estado (0,0) é igual a P(A=cima/a=esquerda)+P(A=esquerda/a=esquerda) = 0.1+0.8 = 0.9.
Image:
Figura 2: Representação de ações possíveis do agente estando no estado S=(0,0), nos sentidos da direita e esquerda.
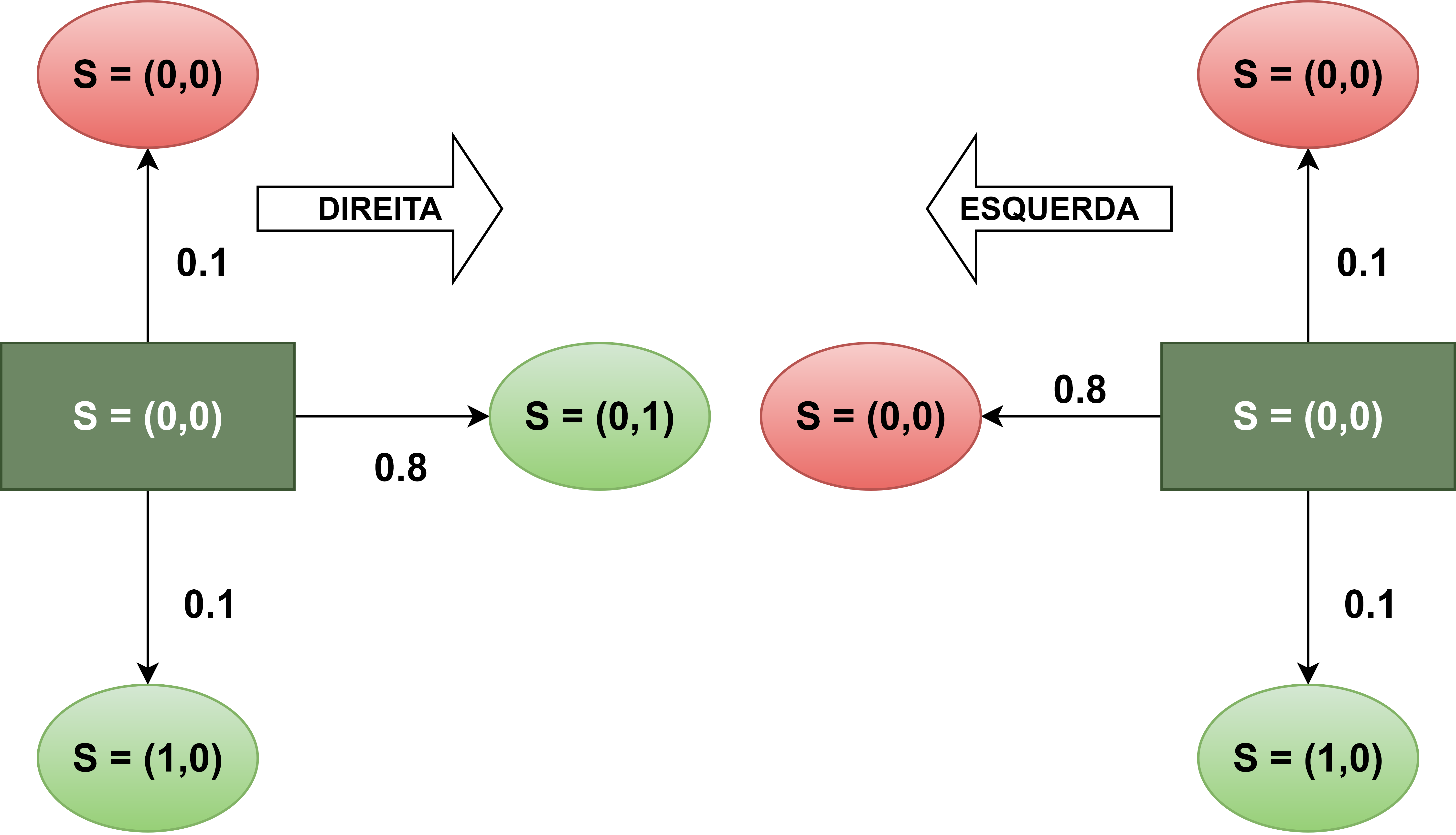
Figura 3: Representação de ações possíveis do agente estando no estado S=(0,0), pra cima ou pra baixo
O algoritmo de iteração de valor é baseado na equação \ref{belman}, onde é uma função que maximiza a ação, ou seja, das quatro ações possíves, por exemplo das Figuras \ref{direitaEsquerda} e \ref{cimaBaixo}, a função escolher a ação que maximiza sua a recompesa.
Abaixo é possível ver duas iterações, assumindo que
--------------------------------------------
iteracao 1
U(s) = -0.04 + y * max(
1 0.8*0+0.1*0 + 0.1*0, \#cima
2 0.9*0 + 0.1*0, \#esquerda
3 0.9*0+0.1*0, \#baixo
4 0.8*0+0.1*0 + 0.1*0, \#direita
)
U(s) = -0.04
--------------------------------------------
iteracao 2
U(s) = -0.04 + y * max(
1 0.8*-0.04 + 0.1*-0.04 + 0.1*-0.04, \#cima
2 0.9*-0.04 + 0.1*-0.04, \#esquerda
3 0.9*-0.04 + 0.1*-0.04, \#baixo
4 0.8*-0.04 + 0.1*-0.04 + 0.1*-0.04, \#direita
)
U(s) = -0.08
...