![]()
![]()
![]()
Detect I/O anti-patterns (N+1, redundant calls, slow SQL/HTTP, fanout) in OpenTelemetry traces. Run as a CI quality gate on captured traces, or as a long-running OTLP daemon with Prometheus metrics and a query API.
Read this first
- Prerequisite: your services must emit OpenTelemetry traces (SQL + HTTP spans). If they don't, perf-sentinel has nothing to analyze. See docs/INSTRUMENTATION.md for language-specific setup (Java/Quarkus/.NET/Rust).
- What it is: a self-hosted, single-binary (
<15 MB RSS) anti-pattern detector, runnable in batch mode on captured traces (local exploration, post-mortem, or a CI quality gate that exits 1 on threshold breach) or as a long-running daemon (OTLP ingestion, query API, live dashboard, Prometheus metrics).- What it is not: a full APM, a continuous profiler, or a standalone regulatory carbon accounting platform. See What perf-sentinel is not.
Terminal:
perf-sentinel analyze --input traces.json
HTML dashboard (single offline file):
perf-sentinel report --input traces.json --output report.html
Performance anti-patterns like N+1 queries exist in any application that does I/O, monoliths and microservices alike. In distributed architectures, a single user request cascades across multiple services, each with its own I/O, and nobody has visibility on the full path.
Existing tools each solve part of the problem. Hypersistence Utils covers JPA only, Datadog and New Relic are heavy proprietary agents you may not want in every pipeline, Sentry's detectors are solid but tied to its SDK and backend. None of them gives you a protocol-level anti-pattern detector you can self-host, runnable either as a CI quality gate on captured traces (exit 1 on threshold breach, SARIF for code scanning) or as a long-running OTLP daemon (gRPC + HTTP ingestion, Prometheus /metrics, live HTML dashboard, query API, runtime ack workflow) you place alongside or in front of your existing tracing backend.
perf-sentinel observes the traces your application already emits (SQL queries, HTTP calls) regardless of language or ORM. It doesn't need to understand JPA, EF Core or SeaORM, it sees the queries they generate.
Ten finding types, plus cross-trace correlations in daemon mode:
| Pattern | Trigger |
|---|---|
| N+1 SQL | Same query template fired ≥ N times in a single trace |
| N+1 HTTP | Same URL template called ≥ N times in a single trace |
| Redundant SQL | Identical query with identical params, same trace |
| Redundant HTTP | Identical call with identical params, same trace |
| Slow SQL | Query duration above configured threshold |
| Slow HTTP | Request duration above configured threshold |
| Excessive fanout | One span starts ≥ N children in parallel |
| Chatty service | Service A → B repeatedly within one user request |
| Pool saturation | Concurrent in-flight queries exceed configured pool size |
| Serialized calls | Sequential I/O that could be parallelized |
Each finding carries: type, severity, normalized template, occurrences, source endpoint, suggestion, source location (when OTel spans carry code.* attributes), and GreenOps impact (see below). For per-detector severity rules and tunable thresholds, see docs/design/04-DETECTION.md.
text(default): severity-grouped colored terminal output. Available onanalyze,diff,pg-stat,query,explain,ack.json: structured report. Available onanalyze,diff,pg-stat,query,explain,ack. Full schema in docs/SCHEMA.md, example fixtures in docs/schemas/examples/.sarif(SARIF v2.1.0): GitHub/GitLab code scanning with inline PR annotations viaphysicalLocations. Available onanalyzeanddiff. See docs/SARIF.md.- HTML dashboard: single-file offline report from
perf-sentinel report, click-through trace trees, dark/light theme, CSV export from Findings / pg_stat / Diff / Correlations tabs. See docs/HTML-REPORT.md. - Interactive TUI: 3-panel keyboard-driven view from
perf-sentinel inspect(orquery inspectfor live daemon data). See docs/INSPECT.md. - Live daemon: NDJSON findings on stdout, Prometheus
/metricswith Grafana Exemplars,/healthprobe, HTTP query API. See docs/METRICS.md and docs/QUERY-API.md. - Periodic disclosure (optional): hash-verifiable
perf-sentinel-report/v1.0JSON fromperf-sentinel disclose, signable via Sigstore. See docs/REPORTING.md.
The JSON io_intensity_band / io_waste_ratio_band enum values (healthy / moderate / high / critical) are stable across versions, numeric thresholds behind them may evolve. Reference table and rationale in docs/LIMITATIONS.md#score-interpretation.
| Metric | Result (v0.6.1) |
|---|---|
| Peak pipeline throughput | > 1.8 M events / sec |
| Sustained end-to-end throughput | ≈ 960 k events / sec |
| Resident memory at sustained peak load | < 250 MB |
The <15 MB RSS figure quoted in the TL;DR and the comparison table is the steady-state daemon footprint at low traffic (apples-to-apples with the idle-agent figures listed for the other tools). Under the sustained ~960 k events / sec load above, the same daemon stays under 250 MB.
Measured on a Mac Mini M4 Pro (12 cores, 24 GB unified memory, macOS 26.4.1), release build aarch64-unknown-linux-musl with mimalloc, running inside a Docker Desktop linux/arm64 VM provisioned with 15.6 GB. Rust 2024 edition, rustc 1.95.0 stable. Reproduce with perf-sentinel bench --help.
# from crates.io
cargo install perf-sentinel
# or download a prebuilt binary (Linux amd64/arm64, macOS arm64, Windows amd64)
curl -LO https://github.com/robintra/perf-sentinel/releases/latest/download/perf-sentinel-linux-amd64
chmod +x perf-sentinel-linux-amd64 && sudo mv perf-sentinel-linux-amd64 /usr/local/bin/perf-sentinel
# or run via Docker
docker run --rm -p 4317:4317 -p 4318:4318 \
ghcr.io/robintra/perf-sentinel:latest watch --listen-address 0.0.0.0Linux binaries target musl (fully static, run on any distro and FROM scratch images). A Helm chart is available under charts/perf-sentinel/. See docs/HELM-DEPLOYMENT.md.
Four environments, three deployment models. Full setup in docs/INTEGRATION.md, CI recipes in docs/CI.md, Prometheus metrics in docs/METRICS.md, sidecar example in examples/docker-compose-sidecar.yml.
Models: CI batch (analyze --ci on captured traces, exits 1 on threshold breach), central collector (OTel Collector forwards to watch daemon, Prometheus metrics and query API), sidecar (one daemon per service for isolated debugging).
Local dev

CI/CD

Staging

Production

GreenOps (cross-cutting)

End-to-end view: how the four environments fit together

The companion repo perf-sentinel-simulation-lab validates eight operational modes end to end on a real Kubernetes cluster, each shipping a Mermaid diagram, the exact inputs/outputs, and the gotchas hit during validation.
# 1. Try the bundled demo (no setup required)
perf-sentinel demo
# 2. Analyze a captured trace file
perf-sentinel analyze --input traces.json
# 3. Use as a CI quality gate (exits 1 on threshold breach)
perf-sentinel analyze --input traces.json --ci --config .perf-sentinel.toml
# 4. Stream traces from your apps (daemon mode)
perf-sentinel watchMinimal .perf-sentinel.toml at the repo root:
[thresholds]
n_plus_one_sql_critical_max = 0 # zero tolerance for N+1 SQL
io_waste_ratio_max = 0.30 # max 30% avoidable I/O
[detection]
n_plus_one_min_occurrences = 5
slow_query_threshold_ms = 500Full subcommand reference: perf-sentinel <cmd> --help, or docs/CLI.md.
Map of the perf-sentinel subcommands and the artifacts they consume or produce

One-liner cheat sheet for the rest of the surface
perf-sentinel explain --input traces.json --trace-id abc123 # tree view of one trace
perf-sentinel inspect --input traces.json # interactive TUI
perf-sentinel diff --before base.json --after head.json # PR regression diff
perf-sentinel pg-stat --input pg_stat.csv --traces traces.json # PostgreSQL hotspots
perf-sentinel tempo --endpoint http://tempo:3200 --trace-id <id> # pull from Grafana Tempo
perf-sentinel jaeger-query --endpoint http://jaeger:16686 --service order-svc
perf-sentinel calibrate --traces traces.json --measured-energy rapl.csv
perf-sentinel completions zsh > ~/.zfunc/_perf-sentinel # shell completions
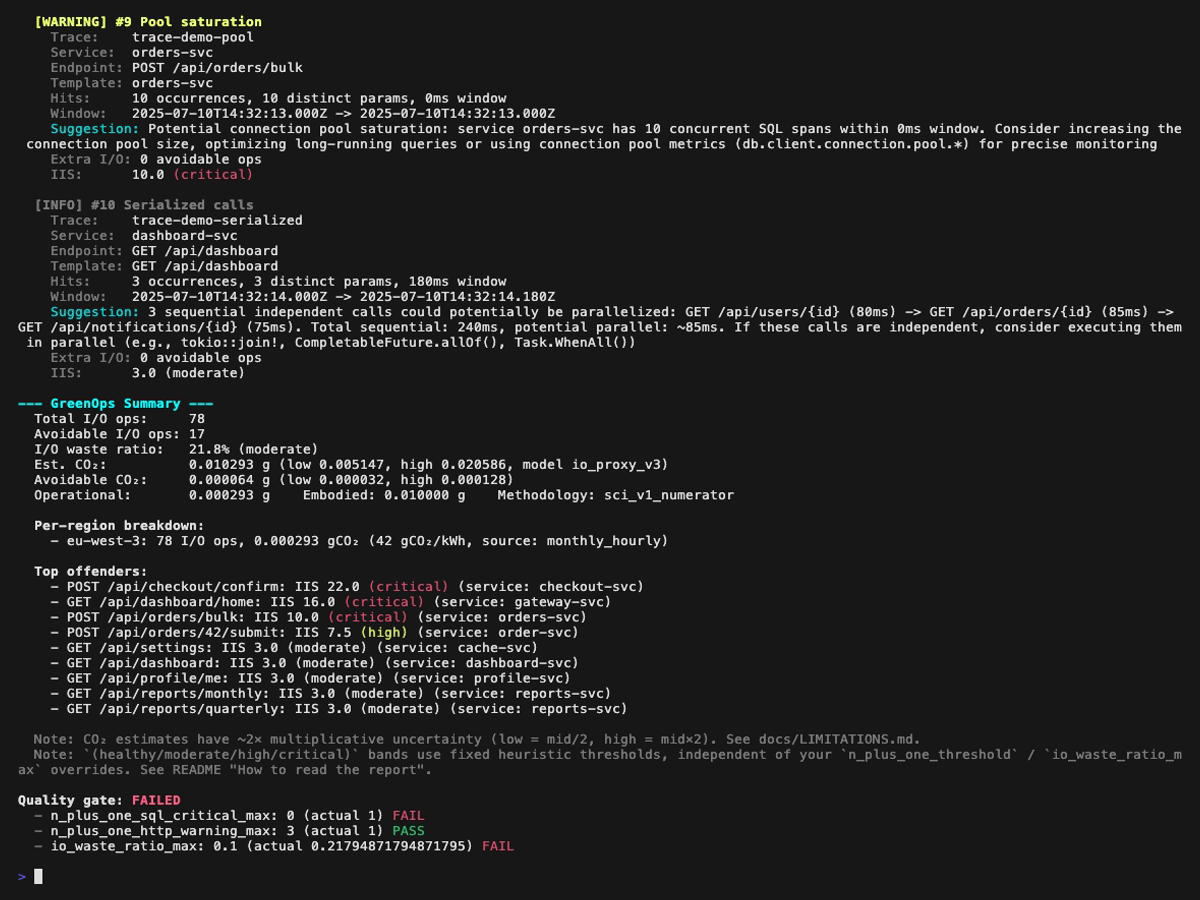
perf-sentinel query findings --service order-svc # talk to a running daemonEvery finding carries an I/O intensity score (IIS), total I/O ops for an endpoint divided by invocations, and an I/O waste ratio (avoidable ops / total ops). Reducing N+1 queries and redundant calls improves response times and energy use; these are not competing goals.
co2.total is reported as the Software Carbon Intensity v1.0 / ISO/IEC 21031:2024 numerator (E × I) + M, summed over analyzed traces. Multi-region scoring is automatic when OTel spans carry cloud.region. In daemon mode, energy can be refined via Scaphandre RAPL or cloud-native CPU% + SPECpower, and grid intensity pulled live from Electricity Maps.
perf-sentinel is a specialized carbon calculator for software / compute emissions, with an activity-based methodology, region-hourly grid intensity (Electricity Maps, ENTSO-E, RTE, National Grid ESO, EIA, ...), bottom-up embodied carbon (Boavizta + HotCarbon 2024) and Sigstore-signed, hash-verifiable disclosures.
It is suitable as a primary data source for a horizontal carbon accounting platform, or as an internal controlling tool for software-emissions KPIs and RGESN conformance.
It is not yet third-party verified for standalone CSRD / GHG Protocol Scope 2/3 inventory reporting, which requires audit by a qualified body and integration with non-IT scopes. CO₂ figures carry a
~2×uncertainty bracket in the default proxy mode (tighter with Scaphandre RAPL or cloud SPECpower + calibration). Methodology, sources and bounds: docs/LIMITATIONS.md#carbon-estimates-accuracy and docs/METHODOLOGY.md.
Concrete pairings: pass the I/O counts and per-region energy estimates to Watershed, Sweep, Greenly or Persefoni as activity data ; or use perf-sentinel directly to demonstrate RGESN (Référentiel Général d'Écoconception de Services Numériques, ARCEP/Ademe/DINUM 2024) software-optimization conformance, where N+1 detection, redundant calls, caching and fanout reduction map onto the corresponding criteria.
For organisations who still want to publish a non-regulatory periodic efficiency disclosure (quarterly/yearly JSON, optional Sigstore signature), the optional perf-sentinel disclose workflow is documented in docs/REPORTING.md. It is intentionally kept off the main quickstart path.
perf-sentinel's niche is being lightweight, protocol-agnostic, CI/CD-native and carbon-aware, not replacing a full observability suite.
| Capability | Hypersistence Optimizer | Datadog APM + DBM | New Relic APM | Sentry | Digma | Grafana Pyroscope | perf-sentinel |
|---|---|---|---|---|---|---|---|
| N+1 SQL detection | JPA only, test-time | Yes, automatic (DBM) | Yes, automatic | Yes, automatic OOTB | Yes, IDE-centric (JVM/.NET) | No (CPU/memory profiler, not a query analyzer) | Yes, protocol-level, any OTel runtime |
| N+1 HTTP detection | No | Yes, service maps | Yes, trace correlation | Yes, N+1 API Call detector | Partial | No | Yes |
| Polyglot support | Java only | Per-language agents | Per-language agents | Per-SDK, most languages | JVM + .NET (Rider beta) | eBPF host-wide + per-language SDKs | Any OTel-instrumented runtime |
| Cross-service correlation | No | Yes | Yes | Yes | Limited (local IDE) | Trace-to-profile via OTel exemplars | Via trace ID |
| GreenOps / SCI v1.0 scoring | No | No | No | No | No | No | Built-in (directional) |
| Runtime footprint | Library (no overhead) | Agent (~100-150 MB RSS) | Agent (~100-150 MB RSS) | SDK + backend | Local backend (Docker) | Agent + backend (~50-100 MB RSS depending on language) | Standalone binary (<15 MB RSS) |
| Native CI/CD quality gate | Manual test assertions | Alerts, no build gate | Alerts, no build gate | Alerts, no build gate | No | No | Yes (exit 1 on threshold breach) |
| License | Commercial (Optimizer) | Proprietary SaaS | Proprietary SaaS | FSL (converts to Apache-2 after 2y) | Freemium, proprietary | AGPL-3.0 | AGPL-3.0 |
| Pricing / self-hostable | One-time license fee | Usage-based SaaS (no self-host) | Usage-based SaaS (no self-host) | Free tier + SaaS plans (no self-host) | Freemium SaaS (no self-host) | Free, fully self-hostable | Free, fully self-hostable |
Agent footprint figures for commercial APMs are order-of-magnitude estimates from public deployment reports; actual overhead depends on instrumentation scope.
A fair comparison requires naming what perf-sentinel does not do:
- Not a full APM replacement. No dashboards, no alerting UI, no RUM, no log aggregation, no distributed profiling. If you need those, Datadog, New Relic and Sentry remain the right tools.
- Not a continuous profiler. It observes I/O patterns at the protocol level; it does not sample on-CPU time, allocations or stack traces. For flame graphs and language-aware CPU/memory profiling, Grafana Pyroscope is the open-source counterpart and pairs well: pyroscope tells you where compute time goes, perf-sentinel tells you which I/O patterns drive that time.
- Not a real-time monitoring solution. Daemon mode streams findings, but the project's center of gravity is CI quality gates and post-hoc trace analysis, not live prod observability.
- Not a standalone regulatory carbon accounting platform. perf-sentinel computes activity-based software-emissions numbers from audit-quality sources, but standalone CSRD or GHG Protocol Scope 2/3 reporting requires third-party verification and integration with non-IT scopes it does not cover. Pair it with a horizontal carbon platform (Watershed, Sweep, Greenly, Persefoni, ...) or use it directly for RGESN conformance and internal software-emissions KPIs.
- Not a replacement for measured energy. The I/O-to-energy model is an approximation. For accurate per-process power use Scaphandre (supported as an input) or cloud provider energy APIs. For what software-only attribution can and cannot cover on a typical server, see docs/LIMITATIONS.md § What software-only attribution covers.
- Not zero-config. Protocol-level detection requires OTel instrumentation in your apps. If your stack does not emit traces, perf-sentinel has nothing to analyze.
- Not an IDE plugin. For in-IDE feedback on JVM/.NET code as you type, Digma offers a well-integrated JetBrains experience.
Drop .perf-sentinel-acknowledgments.toml at your repo root to suppress findings the team has accepted; they are filtered from analyze / report / inspect / diff and do not count toward the quality gate. Runtime acks against a live daemon are exposed via the ack CLI, the live HTML dashboard, and the TUI. Full reference: docs/ACKNOWLEDGMENTS.md and docs/ACK-WORKFLOW.md.
The Quick look section at the top shows live GIFs. The frozen frames below let you zoom in on individual panels for readability.
Still frames (analyze, explain, inspect, pg-stat, calibrate, report)
Configuration (.perf-sentinel.toml):

Analysis report (perf-sentinel analyze) page by page, with a small overlap so every finding appears fully on at least one page:
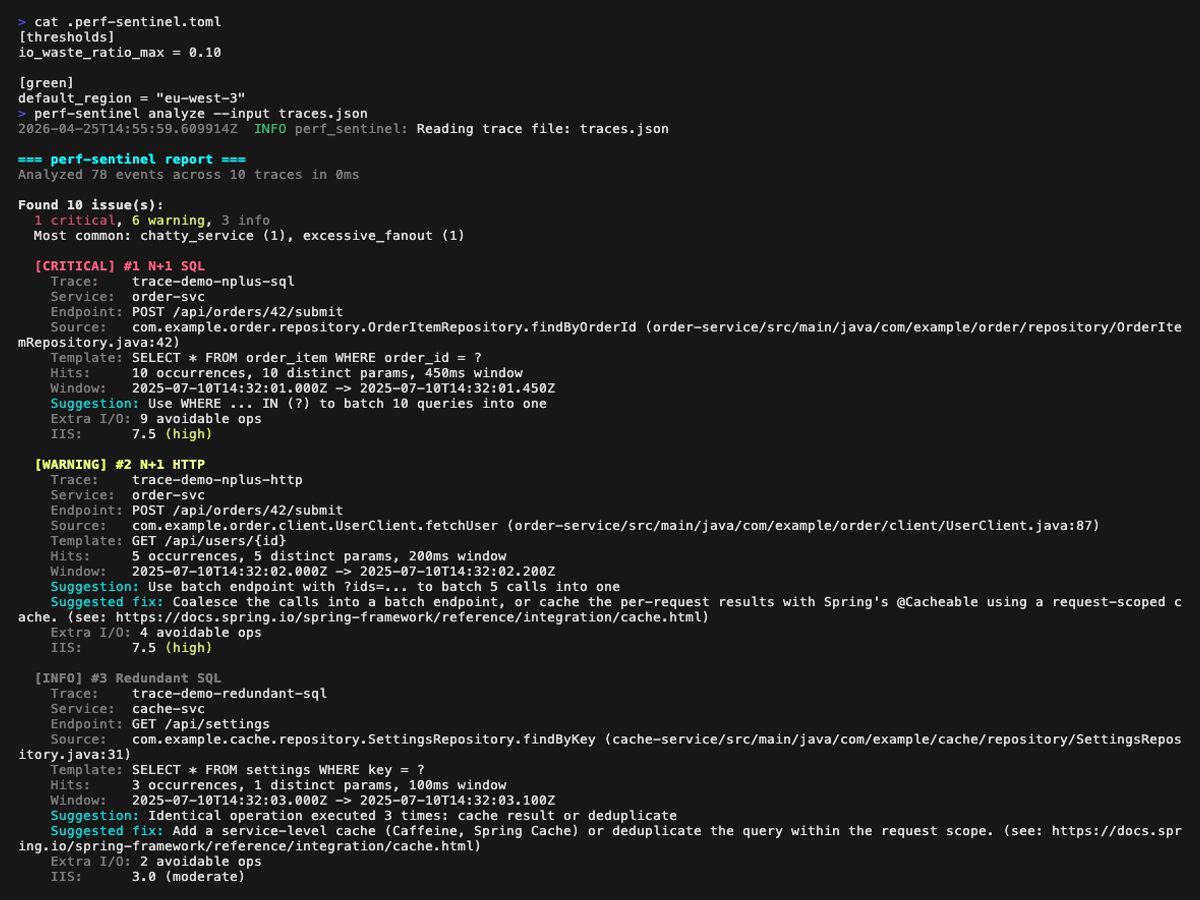
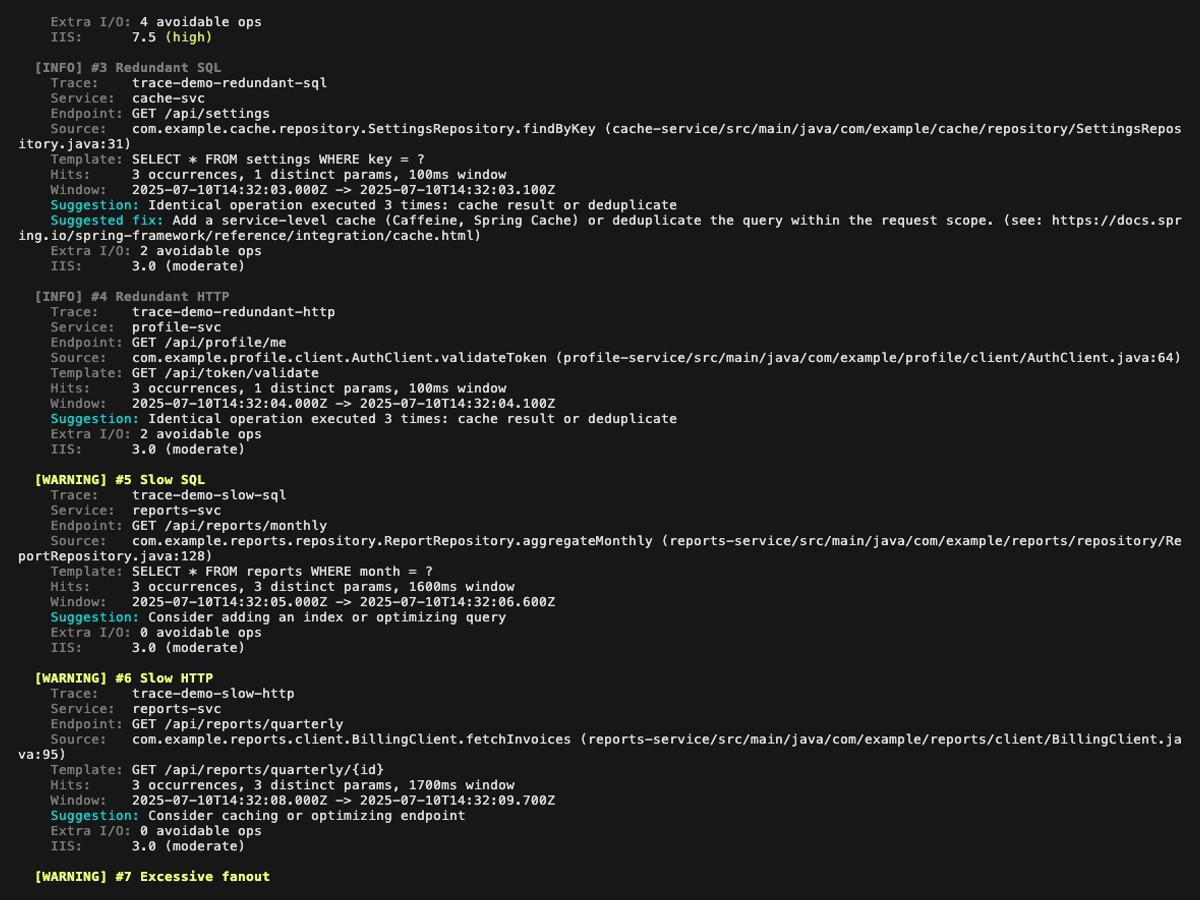
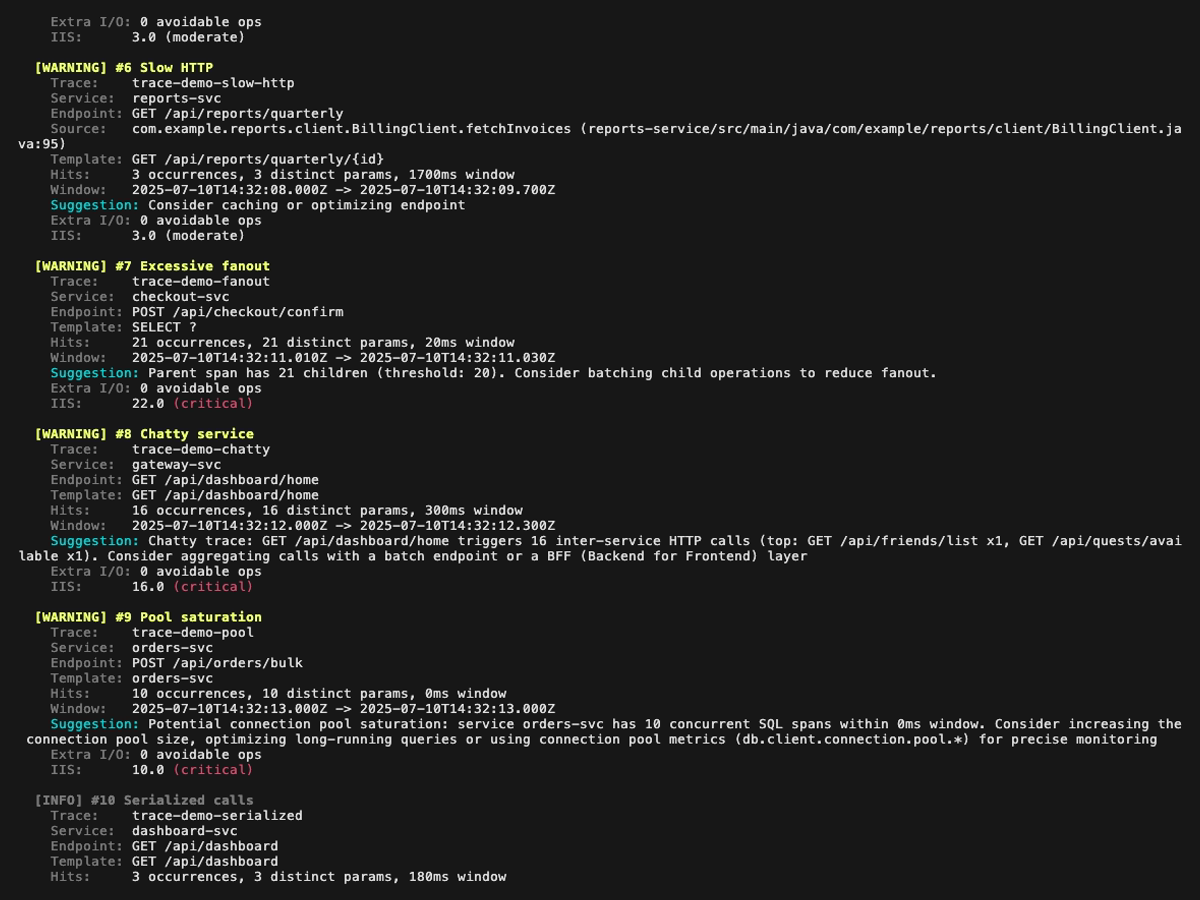
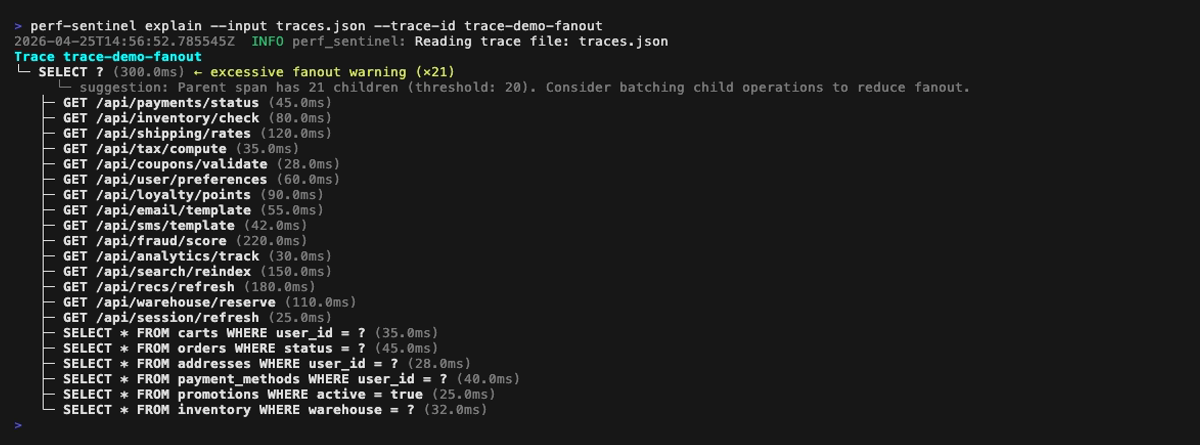
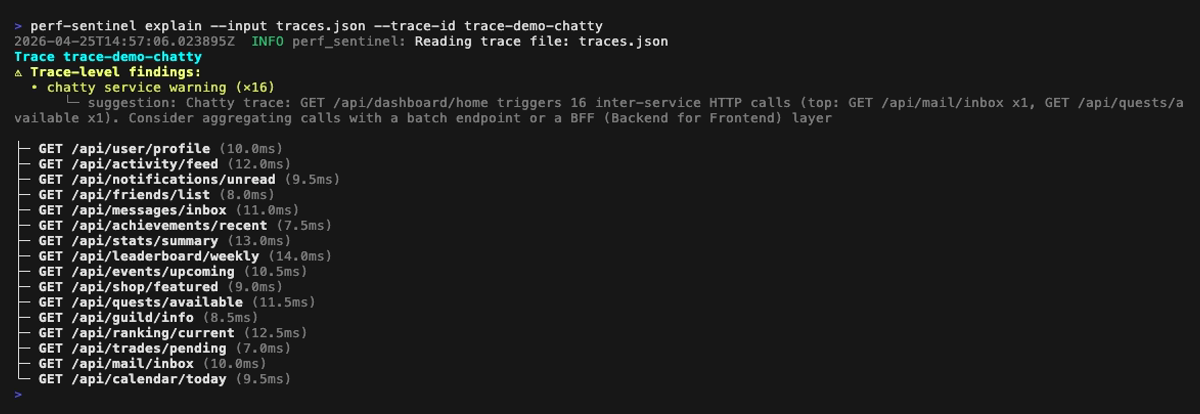
Explain mode (perf-sentinel explain --trace-id <id>). Span-anchored findings (N+1, redundant, slow, fanout) are rendered inline next to the offending spans; trace-level findings (chatty service, pool saturation, serialized calls) are surfaced in a dedicated header above the tree:
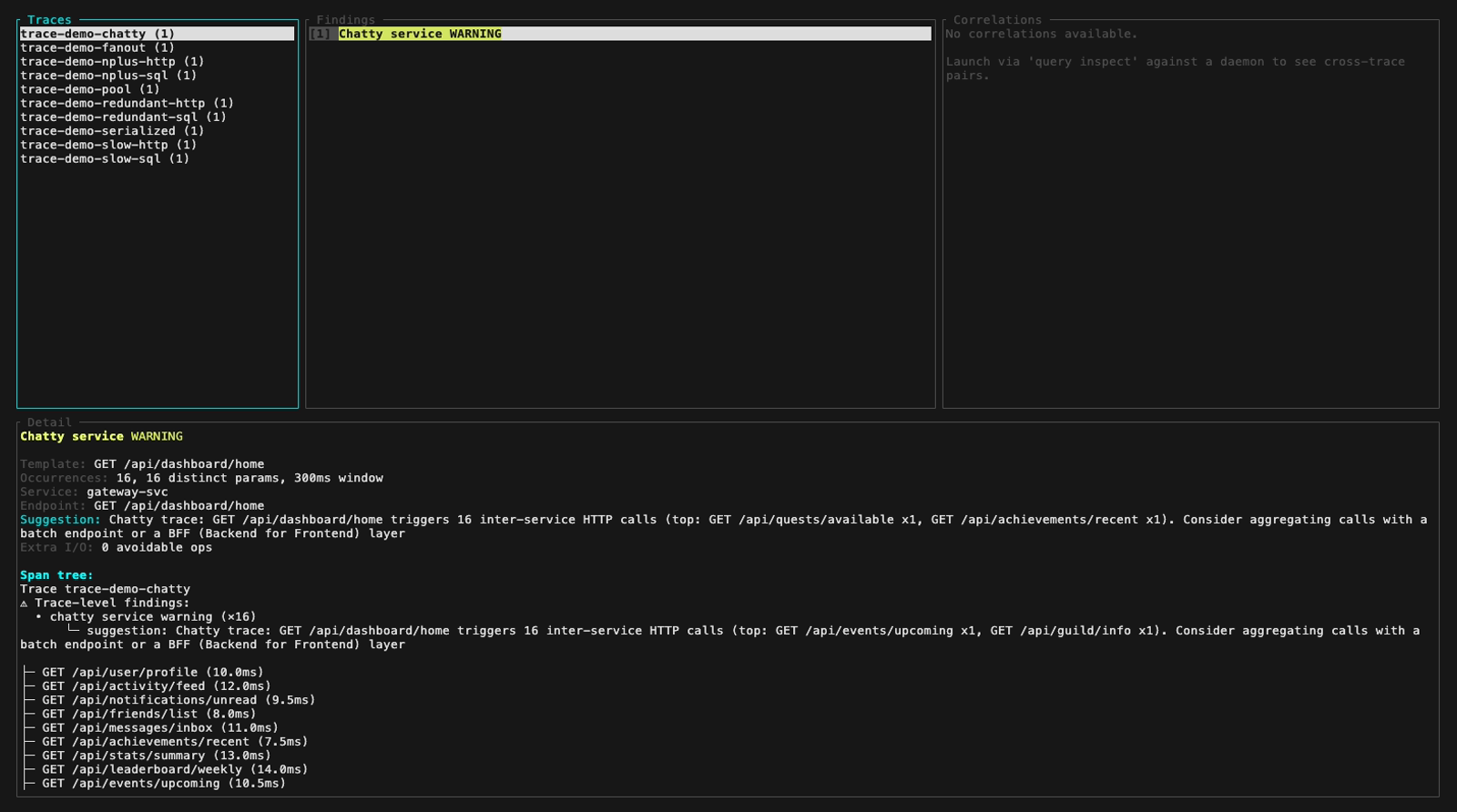
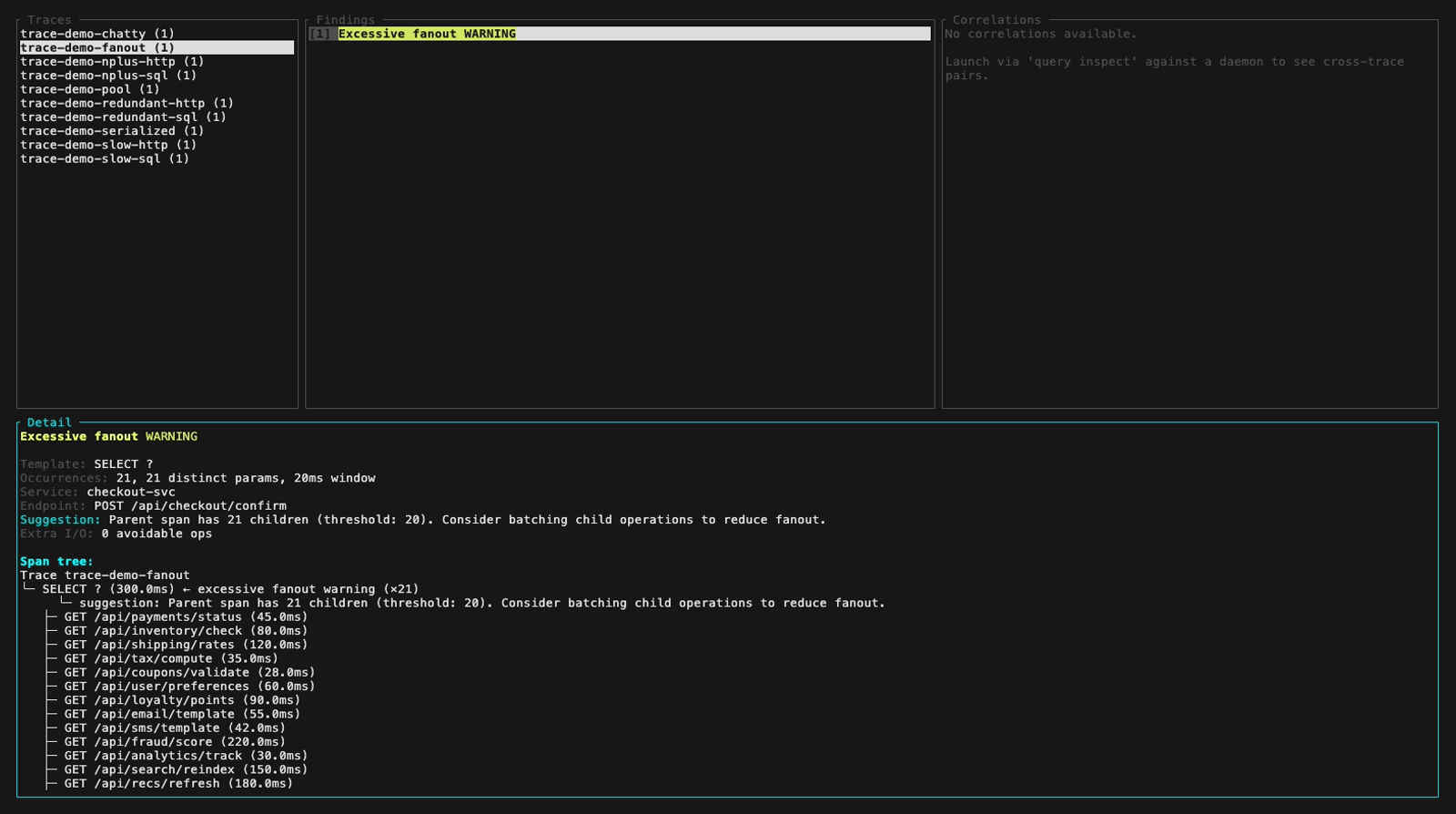
Inspect mode (perf-sentinel inspect). The findings panel header colors findings by severity, below are five frames walking the demo fixture across the three severity levels plus a detail-panel view with its scroll feature:
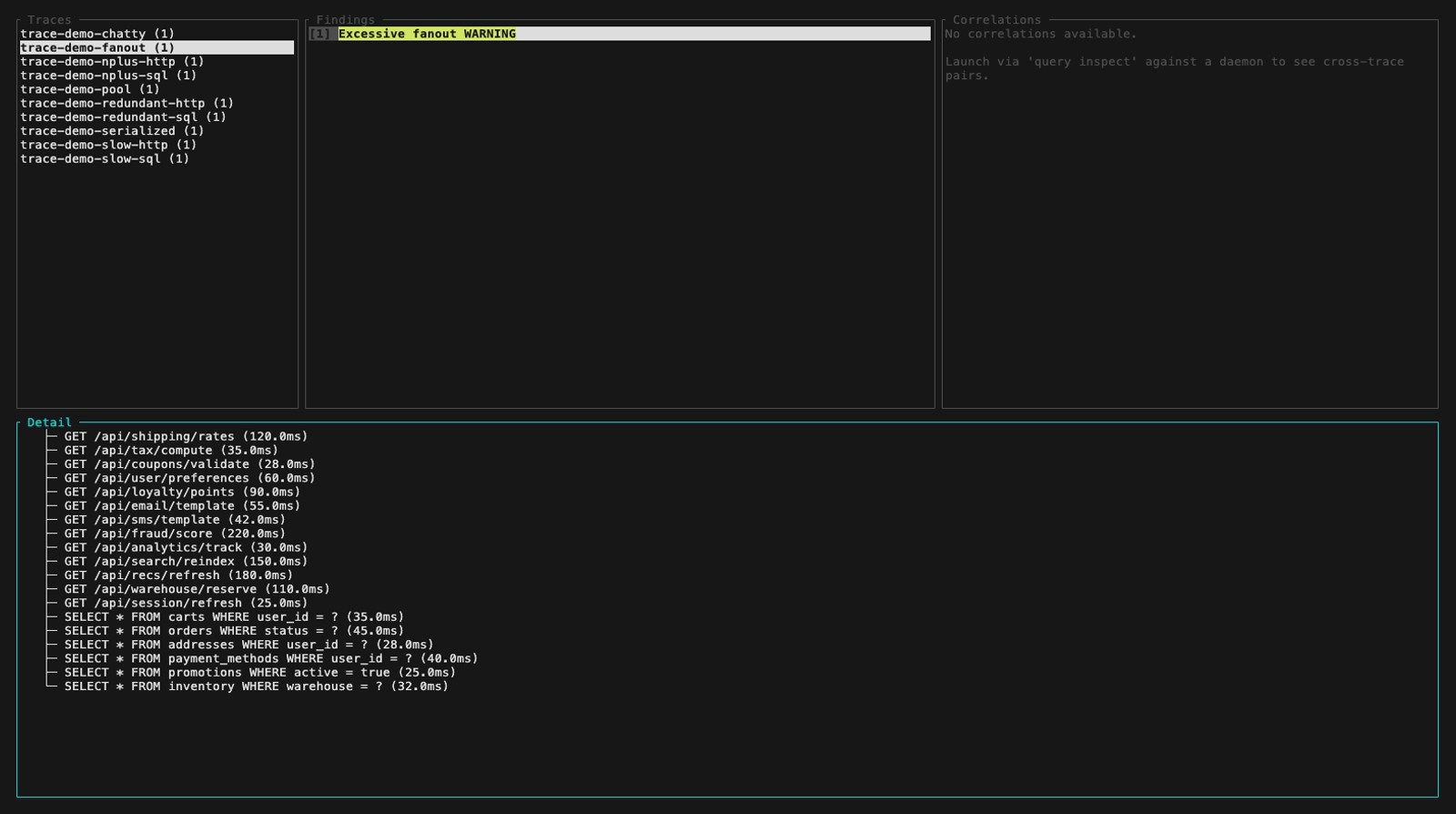
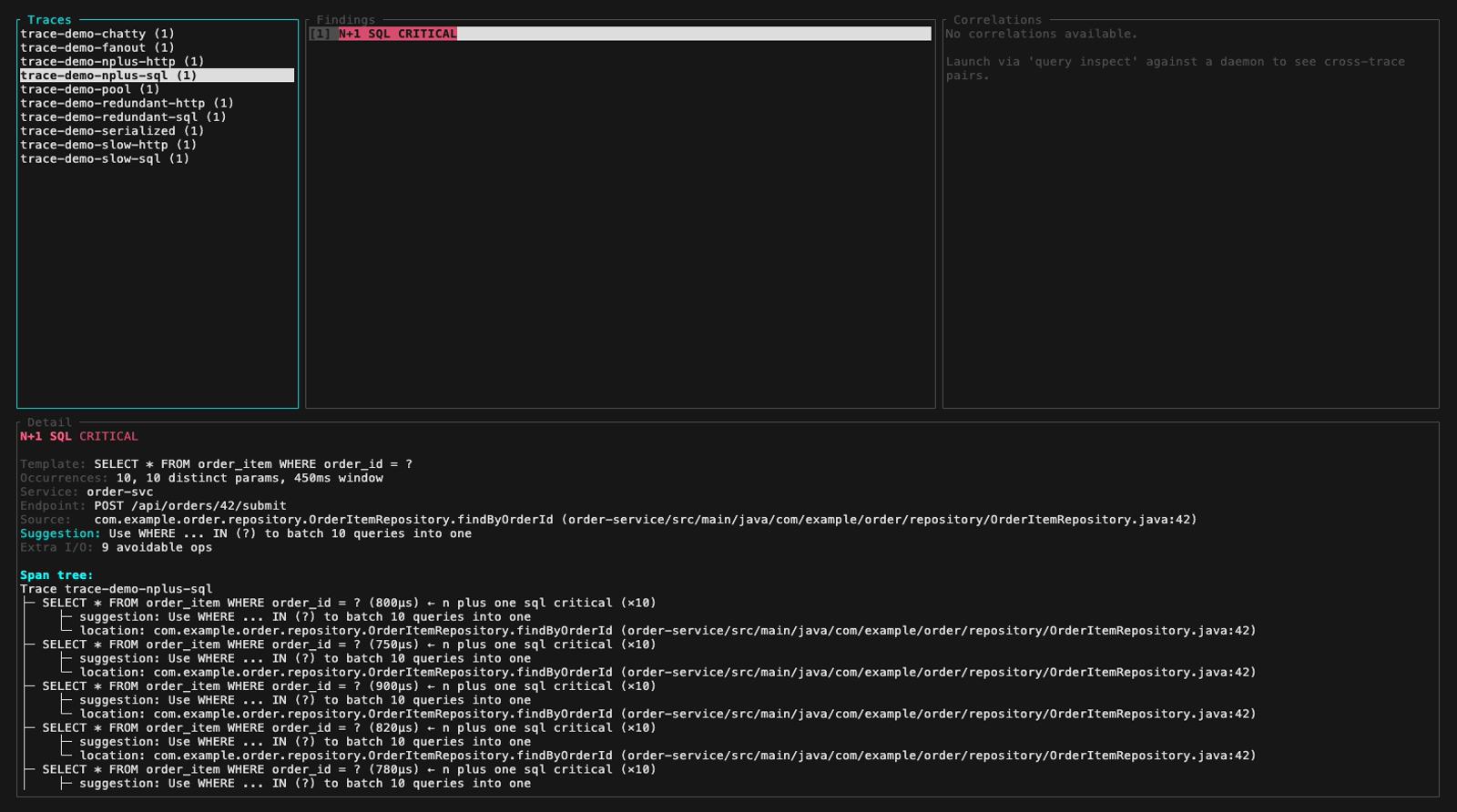
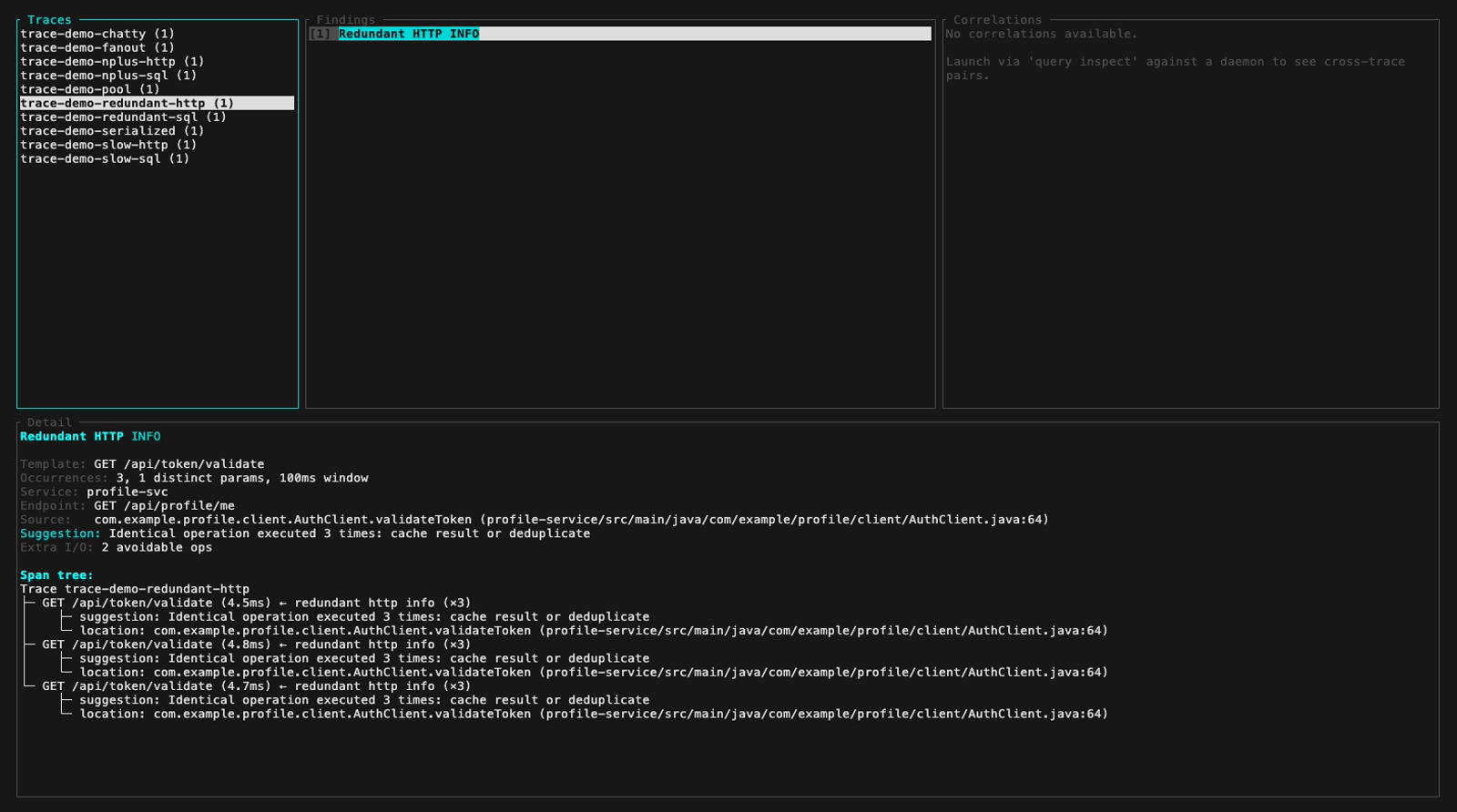
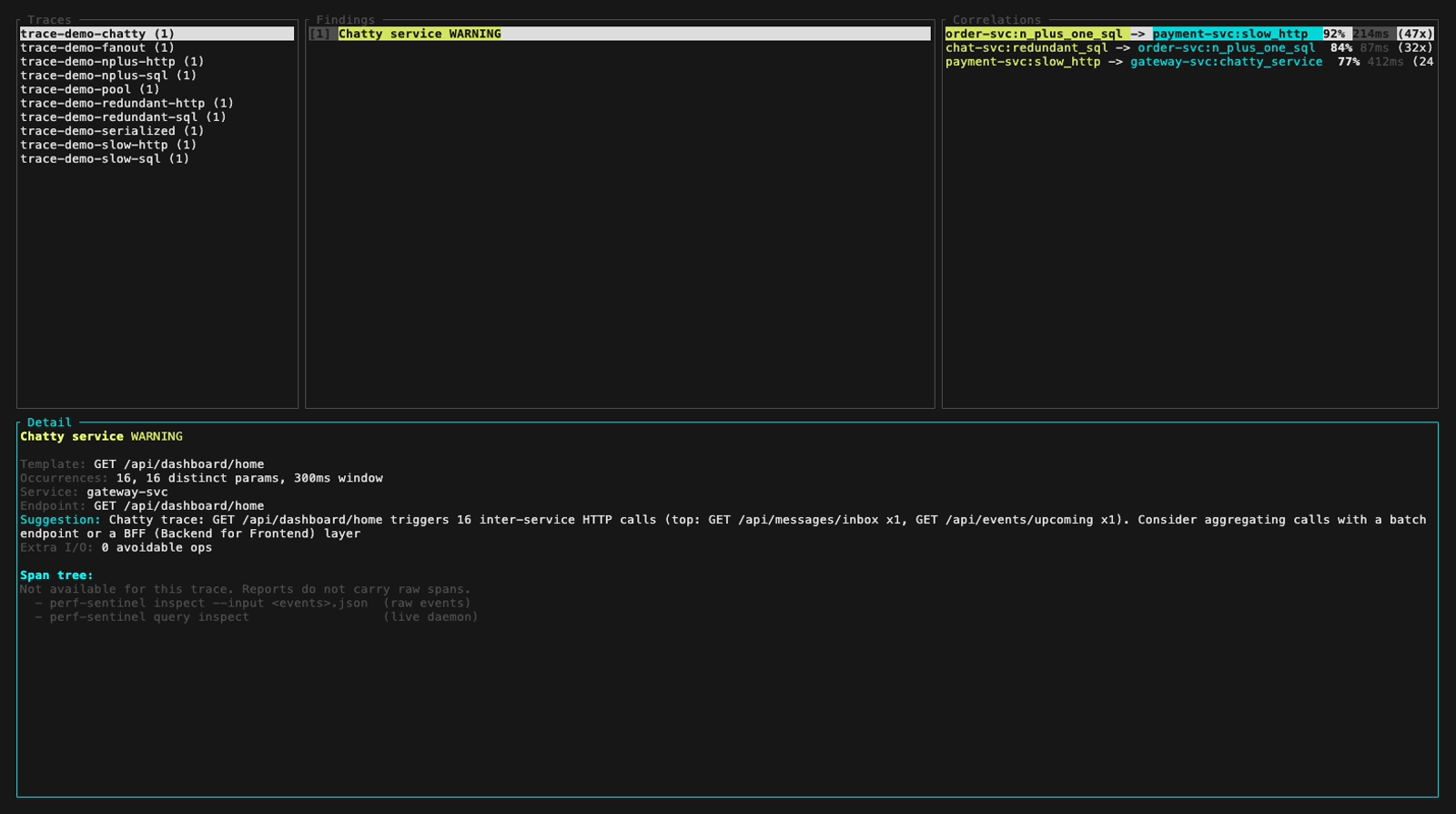
inspect --input also auto-detects a pre-computed Report JSON (e.g. a daemon snapshot from /api/export/report). Findings and Correlations panels light up fully, the Detail panel surfaces a span-tree-unavailable hint that points at the two paths which do carry raw spans:
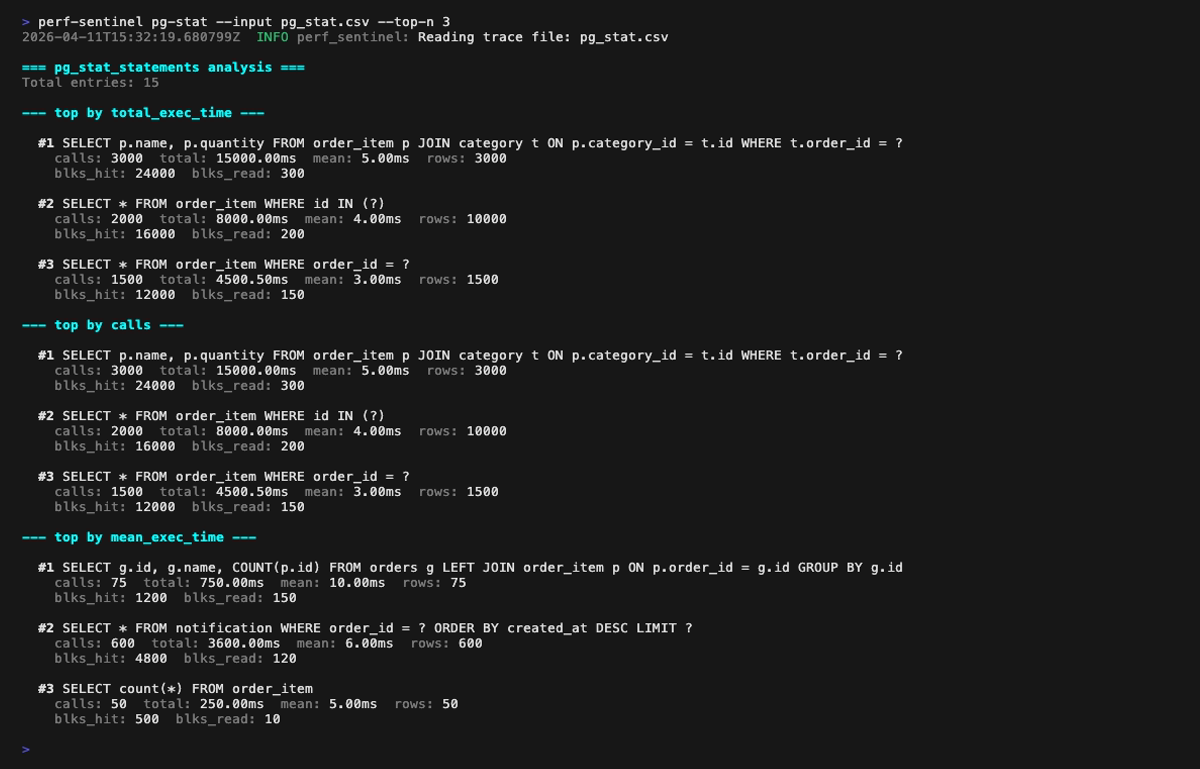
pg-stat mode (perf-sentinel pg-stat --input <pg_stat_statements.csv>): ranks SQL queries by total execution time, by call count, by mean latency. Cross-reference with your traces via --traces to spot queries that dominate the DB without showing up in instrumentation:
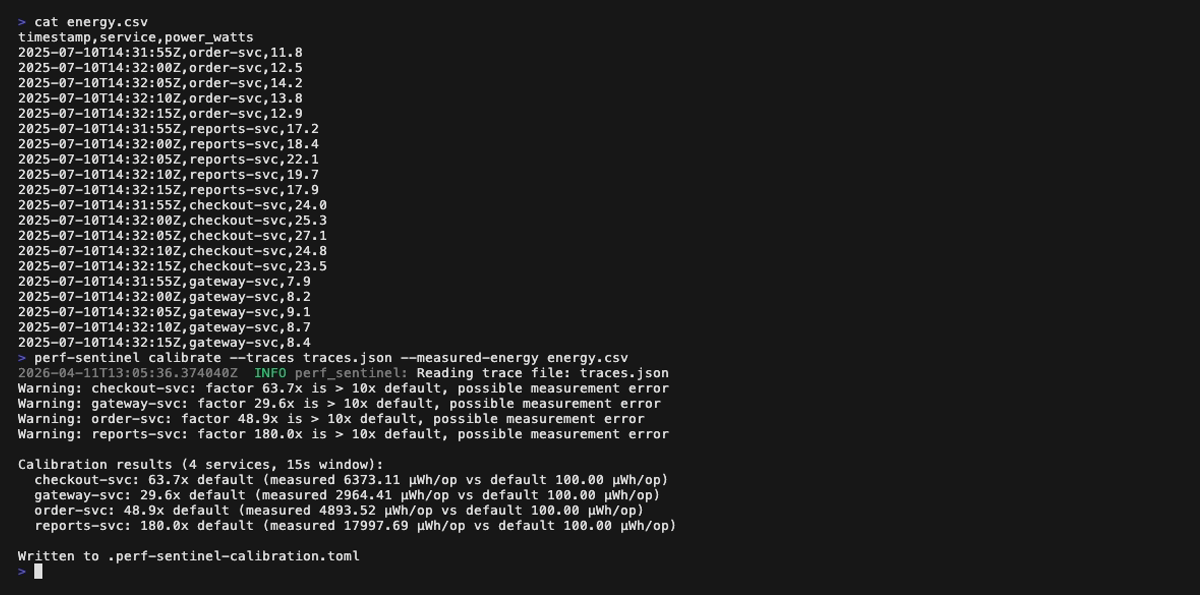
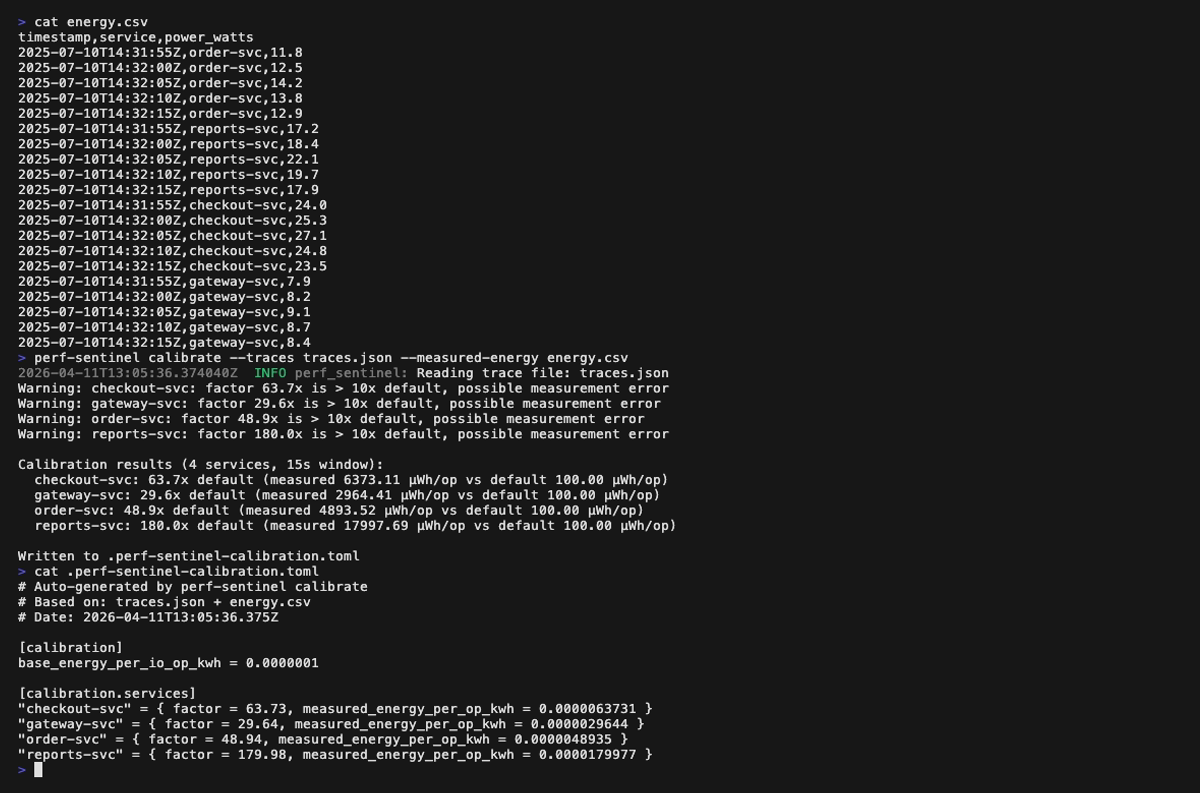
Calibrate mode (perf-sentinel calibrate --traces <traces.json> --measured-energy <energy.csv>):

Report dashboard (perf-sentinel report), one still per tab. Each <picture> serves the dark variant when your browser advertises prefers-color-scheme: dark:







| Topic | Document |
|---|---|
| CLI subcommand reference | docs/CLI.md |
| Architecture and pipeline | docs/ARCHITECTURE.md |
| Integration topologies (CI / prod / sidecar) | docs/INTEGRATION.md |
| OTel instrumentation per language | docs/INSTRUMENTATION.md |
| CI recipes and PR regression diff | docs/CI.md |
| Full configuration reference | docs/CONFIGURATION.md |
| JSON report schema | docs/SCHEMA.md |
| SARIF output | docs/SARIF.md |
| HTML dashboard | docs/HTML-REPORT.md |
| Interactive TUI | docs/INSPECT.md |
| Daemon HTTP query API | docs/QUERY-API.md |
| Acknowledgments workflow | docs/ACKNOWLEDGMENTS.md |
| GreenOps methodology and limitations | docs/METHODOLOGY.md, docs/LIMITATIONS.md |
| Periodic efficiency disclosures (optional) | docs/REPORTING.md |
| Helm deployment | docs/HELM-DEPLOYMENT.md |
| Operational runbook | docs/RUNBOOK.md |
| Supply-chain provenance (SLSA, Sigstore) | docs/SUPPLY-CHAIN.md |
| Design notes (deep dive) | docs/design/ |
Every GitHub Action is pinned to a 40-character commit SHA; the production image is FROM scratch; Cargo.lock is committed and audited daily by cargo audit; workflow GITHUB_TOKEN permissions default to contents: read. Dependabot opens weekly grouped PRs. Release binaries ship SLSA Build L3 provenance (Sigstore + Rekor). Full policy and verification commands: docs/SUPPLY-CHAIN.md.
Releases follow a documented procedure with a mandatory simulation-lab validation gate. Step-by-step in docs/RELEASE-PROCEDURE.md (FR).