This repository contains all the codes, course details, pdfs and examples to the AI and machine learning course. The main objective of this course is to give students the basic idea about AI and make the learning process simple and easy.

In this section, the focus is to give an introduction to the current AI revolution and the scope of AI. In recent years, some revolutionary changes happened in the field of Artificial intelligence and this is the perfect time for us to learn AI. Unlike the past few years, we now know the methods to learn AI and we have the hardware that is required in our personal computers. The introduction of GPU powered deep learning models revolutionized the entire industry. Now, It is time for us to learn AI. Before that, Let's see some examples.
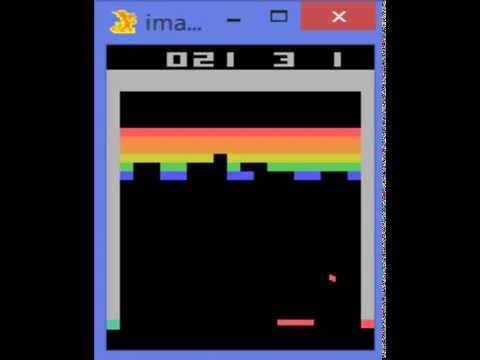
This particular example is Google DeepMind's Deep Q-learning playing Atari Breakout. This is using a concept called Reinforced learning.
When we try to throw a basket ball into the basket, after several attempts, we finally learn that throwing it in a particular angle at a particular speed, it is possible to put the ball inside the basket. Just like that, learning the environment and reconfiguring the artifcial neural networks, it is possible for the machine to learn the perfect way to solve problems, some times better than us. After the completion of this cource, The learner will be able to implement some most challenging AI problems.
[
for more examples, click here
The human brain is the most complex organ in our bodies. Scientists are working on the problem of knowing how the brain works. Even now, we only have a limitted knowledge about the working of human brain. But we can use the assumptions and some proofs by the discoverers of some details on how human brain works to learn about Artificial intelligence. The concept of artificial intelligence depends on some of the terms used in human intelligent system to better understand the concept, but even the greatest minds in the field of artificial intelligence like Andrew NG and Geoferry Hinton says that we are still pursuing the challenge to learn about the real working of human brain.
But as far as we know, The human brain is the central organ of the human nervous system, and with the spinal cord makes up the central nervous system. The brain consists of the cerebrum, the brainstem and the cerebellum. It controls most of the activities of the body, processing, integrating, and coordinating the information it receives from the sense organs, and making decisions as to the instructions sent to the rest of the body. The brain is contained in, and protected by, the skull bones of the head. The cerebrum is the largest part of the human brain. It is divided into two cerebral hemispheres. The cerebral cortex is an outer layer of grey matter, covering the core of white matter. The cortex is split into the neocortex and the much smaller allocortex. The neocortex is made up of six neuronal layers, while the allocortex has three or four. Each hemisphere is conventionally divided into four lobes – the frontal, temporal, parietal, and occipital lobes. The frontal lobe is associated with executive functions including self-control, planning, reasoning, and abstract thought, while the occipital lobe is dedicated to vision. Within each lobe, cortical areas are associated with specific functions, such as the sensory, motor and association regions. Although the left and right hemispheres are broadly similar in shape and function, some functions are associated with one side, such as language in the left and visual-spatial ability in the right. The hemispheres are connected by commissural nerve tracts, the largest being the corpus callosum >(Source wikipedia)
The human brain learns new things from it's surroundings. Imagine when a child touches fire for the first time, after getting the burn, he will not dare to touch something that is red and glows. This type of learning is natural. When we go to school and learns that 2 is a number and it is used to represent some value, This is learnt from the teacher who repeatedly shows this number and tells you that the number is Two. Human brain decodes the signal from the sensories and use them to find a meaning to that and learns it's features for the future. Hearing a pleasent music or good smell of food will make you feel comfortable and heavy traffic troubles makes you angry. Everything is learnt, memorized and used inorder to react to situations that lies ahead.
Artificial intelligence works similarly, but not as efficient as human brain. We were able to achieve more accuracy in predicting something from an image using computer vision than a normal human being, but the technology can be easily fooled. Human brain is still a highly complex system that works differently than what we are going to learn but knowing the concept of knowledge(Memory, structured information used at the right time), Information(Data arranged in a good manner) and Data is going to help us understand the theories of AI.
First computers were used to solve simple mathematical problems and they are good at it. Artificial intelligence as we know it is pure mathematics, but even for solving a small problem, it would take a normal human being his lifetime to do these calculations. But the truth is that we can process do much more things than a computer can, in terms of intelligence. Computers don't have the ability to imagine new things, it only knows the data that it got and that data is the main thing that drives it. An AI system might be able to solve a
The following details are from Wikipedia.
The history of Artificial Intelligence (AI) began in antiquity, with myths, stories and rumors of artificial beings endowed with intelligence or consciousness by master craftsmen; as Pamela McCorduck writes, AI began with "an ancient wish to forge the gods."
The seeds of modern AI were planted by classical philosophers who attempted to describe the process of human thinking as the mechanical manipulation of symbols. This work culminated in the invention of the programmable digital computer in the 1940s, a machine based on the abstract essence of mathematical reasoning. This device and the ideas behind it inspired a handful of scientists to begin seriously discussing the possibility of building an electronic brain.
The earliest research into thinking machines was inspired by a confluence of ideas that became prevalent in the late 1930s, 1940s, and early 1950s. Recent research in neurology had shown that the brain was an electrical network of neurons that fired in all-or-nothing pulses. Norbert Wiener's cybernetics described control and stability in electrical networks. Claude Shannon's information theory described digital signals (i.e., all-or-nothing signals). Alan Turing's theory of computation showed that any form of computation could be described digitally. The close relationship between these ideas suggested that it might be possible to construct an electronic brain.
In 1950 Alan Turing published a landmark paper in which he speculated about the possibility of creating machines that think. He noted that "thinking" is difficult to define and devised his famous Turing Test. If a machine could carry on a conversation (over a teleprinter) that was indistinguishable from a conversation with a human being, then it was reasonable to say that the machine was "thinking". This simplified version of the problem allowed Turing to argue convincingly that a "thinking machine" was at least plausible and the paper answered all the most common objections to the proposition. The Turing Test was the first serious proposal in the philosophy of artificial intelligence.
In 1951, using the Ferranti Mark 1 machine of the University of Manchester, Christopher Strachey wrote a checkers program and Dietrich Prinz wrote one for chess. Arthur Samuel's checkers program, developed in the middle 50s and early 60s, eventually achieved sufficient skill to challenge a respectable amateur.Game AI would continue to be used as a measure of progress in AI throughout its history.
In Japan, Waseda University initiated the WABOT project in 1967, and in 1972 completed the WABOT-1, the world's first full-scale intelligent humanoid robot, or android. Its limb control system allowed it to walk with the lower limbs, and to grip and transport objects with hands, using tactile sensors. Its vision system allowed it to measure distances and directions to objects using external receptors, artificial eyes and ears. And its conversation system allowed it to communicate with a person in Japanese, with an artificial mouth.
In the 1970s, AI was subject to critiques and financial setbacks. AI researchers had failed to appreciate the difficulty of the problems they faced. Their tremendous optimism had raised expectations impossibly high, and when the promised results failed to materialize, funding for AI disappeared. At the same time, the field of connectionism (or neural nets) was shut down almost completely for 10 years by Marvin Minsky's devastating criticism of perceptrons. Despite the difficulties with public perception of AI in the late 70s, new ideas were explored in logic programming, commonsense reasoning and many other areas.
In the early seventies, the capabilities of AI programs were limited. Even the most impressive could only handle trivial versions of the problems they were supposed to solve; all the programs were, in some sense, "toys". AI researchers had begun to run into several fundamental limits that could not be overcome in the 1970s. Although some of these limits would be conquered in later decades, others still stymie the field to this day.
problems faced by Ai during the early days are
-
Many important artificial intelligence applications like vision or natural language require simply enormous amounts of information about the world: the program needs to have some idea of what it might be looking at or what it is talking about. This requires that the program know most of the same things about the world that a child does. Researchers soon discovered that this was a truly vast amount of information. No one in 1970 could build a database so large and no one knew how a program might learn so much information.
-
Finding optimal solutions to these problems requires unimaginable amounts of computer time except when the problems are trivial. This almost certainly meant that many of the "toy" solutions used by AI would probably never scale up into useful systems.
-
There was not enough memory or processing speed to accomplish anything truly useful.
The agencies which funded AI research (such as the British government, DARPA and NRC) became frustrated with the lack of progress and eventually cut off almost all funding for undirected research into AI. The pattern began as early as 1966 when the ALPAC report appeared criticizing machine translation efforts. After spending 20 million dollars, the NRC ended all support.
A perceptron was a form of neural network introduced in 1958 by Frank Rosenblatt, who had been a schoolmate of Marvin Minsky at the Bronx High School of Science. Like most AI researchers, he was optimistic about their power, predicting that "perceptron may eventually be able to learn, make decisions, and translate languages." An active research program into the paradigm was carried out throughout the 1960s but came to a sudden halt with the publication of Minsky and Papert's 1969 book Perceptrons. It suggested that there were severe limitations to what perceptrons could do and that Frank Rosenblatt's predictions had been grossly exaggerated. The effect of the book was devastating: virtually no research at all was done in connectionism for 10 years. Eventually, a new generation of researchers would revive the field and thereafter it would become a vital and useful part of artificial intelligence. Rosenblatt would not live to see this, as he died in a boating accident shortly after the book was published.
On 11 May 1997, Deep Blue became the first computer chess-playing system to beat a reigning world chess champion, Garry Kasparov. The super computer was a specialized version of a framework produced by IBM, and was capable of processing twice as many moves per second as it had during the first match (which Deep Blue had lost), reportedly 200,000,000 moves per second. The event was broadcast live over the internet and received over 74 million hits.
In 2005, a Stanford robot won the DARPA Grand Challenge by driving autonomously for 131 miles along an unrehearsed desert trail. Two years later, a team from CMU won the DARPA Urban Challenge by autonomously navigating 55 miles in an Urban environment while adhering to traffic hazards and all traffic laws.In February 2011, in a Jeopardy! quiz show exhibition match, IBM's question answering system, Watson, defeated the two greatest Jeopardy! champions, Brad Rutter and Ken Jennings, by a significant margin.
These successes were not due to some revolutionary new paradigm, but mostly on the tedious application of engineering skill and on the tremendous power of computers today.In fact, Deep Blue's computer was 10 million times faster than the Ferranti Mark 1 that Christopher Strachey taught to play chess in 1951. This dramatic increase is measured by Moore's law, which predicts that the speed and memory capacity of computers doubles every two years. The fundamental problem of "raw computer power" was slowly being overcome.
Algorithms originally developed by AI researchers began to appear as parts of larger systems. AI had solved a lot of very difficult problems and their solutions proved to be useful throughout the technology industry, such as data mining, industrial robotics, logistics, speech recognition, banking software, medical diagnosis and Google's search engine. The field of AI received little or no credit for these successes in the 1990s and early 2000s. Many of AI's greatest innovations have been reduced to the status of just another item in the tool chest of computer science
Many researchers in AI in 1990s deliberately called their work by other names, such as informatics, knowledge-based systems, cognitive systems or computational intelligence. In part, this may be because they considered their field to be fundamentally different from AI, but also the new names help to procure funding. In the commercial world at least, the failed promises of the AI Winter continued to haunt AI research into the 2000s, as the New York Times reported in 2005: "Computer scientists and software engineers avoided the term artificial intelligence for fear of being viewed as wild-eyed dreamers."
In the first decades of the 21st century, access to large amounts of data (known as "big data"), faster computers and advanced machine learning techniques were successfully applied to many problems throughout the economy. In fact, McKinsey Global Institute estimated in their famous paper "Big data: The next frontier for innovation, competition, and productivity" that "by 2009, nearly all sectors in the US economy had at least an average of 200 terabytes of stored data".
By 2016, the market for AI-related products, hardware, and software reached more than 8 billion dollars, and the New York Times reported that interest in AI had reached a "frenzy". The applications of big data began to reach into other fields as well, such as training models in ecology and for various applications in economics. Advances in deep learning (particularly deep convolutional neural networks and recurrent neural networks) drove progress and research in image and video processing, text analysis, and even speech recognition.
In this session, basic introduction to the field of Artificial intelligence is explained. After this chapter, the learner will be able to successfully differentiate between the various fields of ARtificial intelligence.
Artificial Intelligence is a vast ground of academic and commercial work around, "it is the science of making an intelligence machine". It has many branches with many similarities and commmanalities among them.

Machine learning is an application of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. It is an algorithm that allows software applications to become more accurate in predicting the outcomes.
The basic premise of ML is to make algorithms to receive input data and statistically analyse it to predict the outcome, while updating the outcome as new data become available. These algorithms are catagorised into two, namely supervised and unsupervised. Supervised algorithms require a data scientist to provide input and output during the training of the algorithm. On the other hand unsupervised algorithms do not need any training, insted they uses an iterative approach called deep learning. These algorithms are also called neural networks and they are very complex compared to supervised learning systems.
Neural networks, a beautiful biologically-inspired programming paradigm which enables a computer to learn from observational data
Deep learning, a powerful set of techniques for learning in neural networks
Neural networks and deep learning currently provide the best solutions to many problems in image recognition, speech recognition, and natural language processing. This book will teach you many of the core concepts behind neural networks and deep learning. In the conventional approach to programming, we tell the computer what to do, breaking big problems up into many small, precisely defined tasks that the computer can easily perform. By contrast, in a neural network we don't tell the computer how to solve our problem. Instead, it learns from observational data, figuring out its own solution to the problem at hand. Automatically learning from data sounds promising. However, until 2006 we didn't know how to train neural networks to surpass more traditional approaches, except for a few specialized problems. What changed in 2006 was the discovery of techniques for learning in so-called deep neural networks. These techniques are now known as deep learning. They've been developed further, and today deep neural networks and deep learning achieve outstanding performance on many important problems in computer vision, speech recognition, and natural language processing. They're being deployed on a large scale by companies such as Google, Microsoft, and Facebook.
An Artificial Neural Network (ANN) is an information processing paradigm that is inspired by the way biological nervous systems, such as the brain, process information. The key element of this paradigm is the novel structure of the information processing system. It is composed of a large number of highly interconnected processing elements (neurones) working in unison to solve specific problems. ANNs, like people, learn by example. An ANN is configured for a specific application, such as pattern recognition or data classification, through a learning process. Learning in biological systems involves adjustments to the synaptic connections that exist between the neurones. This is true of ANNs as well.
Neural networks, with their remarkable ability to derive meaning from complicated or imprecise data, can be used to extract patterns and detect trends that are too complex to be noticed by either humans or other computer techniques. A trained neural network can be thought of as an "expert" in the category of information it has been given to analyse. This expert can then be used to provide projections given new situations of interest and answer "what if" questions. Other advantages include:
- Adaptive learning: An ability to learn how to do tasks based on the data given for training or initial experience.
- Self-Organisation: An ANN can create its own organisation or representation of the information it receives during learning time.
- Real Time Operation: ANN computations may be carried out in parallel, and special hardware devices are being designed and manufactured which take advantage of this capability.
- Fault Tolerance via Redundant Information Coding: Partial destruction of a network leads to the corresponding degradation of performance. However, some network capabilities may be retained even with major network damage.
Much is still unknown about how the brain trains itself to process information, so theories abound. In the human brain, a typical neuron collects signals from others through a host of fine structures called dendrites. The neuron sends out spikes of electrical activity through a long, thin stand known as an axon, which splits into thousands of branches. At the end of each branch, a structure called a synapse converts the activity from the axon into electrical effects that inhibit or excite activity from the axon into electrical effects that inhibit or excite activity in the connected neurones. When a neuron receives excitatory input that is sufficiently large compared with its inhibitory input, it sends a spike of electrical activity down its axon. Learning occurs by changing the effectiveness of the synapses so that the influence of one neuron on another changes.


We conduct these neural networks by first trying to deduce the essential features of neurones and their interconnections. We then typically program a computer to simulate these features. However because our knowledge of neurones is incomplete and our computing power is limited, our models are necessarily gross idealisations of real networks of neurones.

Referance:
1.
2.
Deep learning allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction. These methods have dramatically improved the state-of-the-art in speech recognition, visual object recognition, object detection and many other domains such as drug discovery and genomics. Deep learning discovers intricate structure in large data sets by using the backpropagation algorithm to indicate how a machine should change its internal parameters that are used to compute the representation in each layer from the representation in the previous layer. Deep convolutional nets have brought about breakthroughs in processing images, video, speech and audio, whereas recurrent nets have shone light on sequential data such as text and speech.

More details are available in the pdf that can be found in the directory-> documents/cnn.pdf
We will cover this part as we go indeapth in this document. Learning math is more interesting when you have an objective and idea of what you are working on. In this section, we will cover the things that needs to be learnt once we start building our networks.
The basic ideas such as what is a scalar, vector, Matrix, etc. are required to understand the next few chapters. This part is covered in a document located at documents/linearalgebra.pdf inside the repository since anyone with basic knowledge of the topic may skip the part. Will explain everything during the implementation phase.
Derivatives, partial derivation, integration, gradient descent, chain rules are required in this part. This part is covered in a document located at documents/calculus.pdf inside the repository since anyone with basic knowledge of the topic may skip the part. Will explain everything during the implementation phase.
The detailed document can be found inside the documentation folder and is saved as probability.pdf.
- Linear regression and applications
- Logistic regression and applications
- Least mean square
- Gradient descent
- Stochastic gradient descent
- Back propogation
This architecture was one of the first deep networks to push ImageNet Classification accuracy by a significant stride in comparison to traditional methodologies. It is composed of 5 convolutional layers followed by 3 fully connected layers, as depicted in Figure.

AlexNet, proposed by Alex Krizhevsky, uses ReLu(Rectified Linear Unit) for the non-linear part, instead of a Tanh or Sigmoid function which was the earlier standard for traditional neural networks. ReLu is given by
f(x) = max(0,x)
The advantage of the ReLu over sigmoid is that it trains much faster than the latter because the derivative of sigmoid becomes very small in the saturating region and therefore the updates to the weights almost vanish. This is called vanishing gradient problem.In the network, ReLu layer is put after each and every convolutional and fully-connected layers(FC).

Another problem that this architecture solved was reducing the over-fitting by using a Dropout layer after every FC layer. Dropout layer has a probability,(p), associated with it and is applied at every neuron of the response map separately. It randomly switches off the activation with the probability p, as can be seen in figure.

The idea behind the dropout is similar to the model ensembles. Due to the dropout layer, different sets of neurons which are switched off, represent a different architecture and all these different architectures are trained in parallel with weight given to each subset and the summation of weights being one. For n neurons attached to DropOut, the number of subset architectures formed is 2^n. So it amounts to prediction being averaged over these ensembles of models. This provides a structured model regularization which helps in avoiding the over-fitting. Another view of DropOut being helpful is that since neurons are randomly chosen, they tend to avoid developing co-adaptations among themselves thereby enabling them to develop meaningful features, independent of others.
This architecture is from VGG group, Oxford. It makes the improvement over AlexNet by replacing large kernel-sized filters(11 and 5 in the first and second convolutional layer, respectively) with multiple 3X3 kernel-sized filters one after another. With a given receptive field(the effective area size of input image on which output depends), multiple stacked smaller size kernel is better than the one with a larger size kernel because multiple non-linear layers increases the depth of the network which enables it to learn more complex features, and that too at a lower cost.
For example, three 3X3 filters on top of each other with stride 1 ha a receptive size of 7, but the number of parameters involved is 3*(9C^2) in comparison to 49C^2 parameters of kernels with a size of 7. Here, it is assumed that the number of input and output channel of layers is C.Also, 3X3 kernels help in retaining finer level properties of the image. The network architecture is given in the table.

The VGG convolutional layers are followed by 3 fully connected layers. The width of the network starts at a small value of 64 and increases by a factor of 2 after every sub-sampling/pooling layer. It achieves the top-5 accuracy of 92.3 % on ImageNet.
While VGG achieves a phenomenal accuracy on ImageNet dataset, its deployment on even the most modest sized GPUs is a problem because of huge computational requirements, both in terms of memory and time. It becomes inefficient due to large width of convolutional layers.
For instance, a convolutional layer with 3X3 kernel size which takes 512 channels as input and outputs 512 channels, the order of calculations is 9X512X512.
In a convolutional operation at one location, every output channel (512 in the example above), is connected to every input channel, and so we call it a dense connection architecture. The GoogLeNet builds on the idea that most of the activations in a deep network are either unnecessary(value of zero) or redundant because of correlations between them. Therefore the most efficient architecture of a deep network will have a sparse connection between the activations, which implies that all 512 output channels will not have a connection with all the 512 input channels. There are techniques to prune out such connections which would result in a sparse weight/connection. But kernels for sparse matrix multiplication are not optimized in BLAS or CuBlas(CUDA for GPU) packages which render them to be even slower than their dense counterparts.
So GoogLeNet devised a module called inception module that approximates a sparse CNN with a normal dense construction(shown in the figure). Since only a small number of neurons are effective as mentioned earlier, the width/number of the convolutional filters of a particular kernel size is kept small. Also, it uses convolutions of different sizes to capture details at varied scales(5X5, 3X3, 1X1).
Another salient point about the module is that it has a so-called bottleneck layer(1X1 convolutions in the figure). It helps in the massive reduction of the computation requirement as explained below.
Let us take the first inception module of GoogLeNet as an example which has 192 channels as input. It has just 128 filters of 3X3 kernel size and 32 filters of 5X5 size. The order of computation for 5X5 filters is 25X32X192 which can blow up as we go deeper into the network when the width of the network and the number of 5X5 filter further increases. In order to avoid this, the inception module uses 1X1 convolutions before applying larger sized kernels to reduce the dimension of the input channels, before feeding into those convolutions. So in the first inception module, the input to the module is first fed into 1X1 convolutions with just 16 filters before it is fed into 5X5 convolutions. This reduces the computations to 16X192 + 25X32X16. All these changes allow the network to have a large width and depth. Another change that GoogLeNet made, was to replace the fully-connected layers at the end with a simple global average pooling which averages out the channel values across the 2D feature map, after the last convolutional layer. This drastically reduces the total number of parameters. This can be understood from AlexNet, where FC layers contain approx. 90% of parameters. Use of a large network width and depth allows GoogLeNet to remove the FC layers without affecting the accuracy. It achieves 93.3% top-5 accuracy on ImageNet and is much faster than VGG.

As per what we have seen so far, increasing the depth should increase the accuracy of the network, as long as over-fitting is taken care of. But the problem with increased depth is that the signal required to change the weights, which arises from the end of the network by comparing ground-truth and prediction becomes very small at the earlier layers, because of increased depth. It essentially means that earlier layers are almost negligible learned. This is called vanishing gradient. The second problem with training the deeper networks is, performing the optimization on huge parameter space and therefore naively adding the layers leading to higher training error. Residual networks allow training of such deep networks by constructing the network through modules called residual models as shown in the figure. This is called degradation problem. The intuition around why it works can be seen as follows:

Imagine a network, A which produces x amount of training error. Construct a network B by adding few layers on top of A and put parameter values in those layers in such a way that they do nothing to the outputs from A. Let’s call the additional layer as C. This would mean the same x amount of training error for the new network. So while training network B, the training error should not be above the training error of A. And since it DOES happen, the only reason is that learning the identity mapping(doing nothing to inputs and just copying as it is) with the added layers-C is not a trivial problem, which the solver does not achieve. To solve this, the module shown above creates a direct path between the input and output to the module implying an identity mapping and the added layer-C just need to learn the features on top of already available input. Since C is learning only the residual, the whole module is called residual module.
Also, similar to GoogLeNet, it uses a global average pooling followed by the classification layer. Through the changes mentioned, ResNets were learned with network depth of as large as 152. It achieves better accuracy than VGGNet and GoogLeNet while being computationally more efficient than VGGNet. ResNet-152 achieves 95.51 top-5 accuracies.
The architecture is similar to the VGGNet consisting mostly of 3X3 filters. From the VGGNet, shortcut connection as described above is inserted to form a residual network. This can be seen in the figure which shows a small snippet of earlier layer synthesis from VGG-19.
The power of the residual networks can be judged from one of the experiments in paper 4. The plain 34 layer network had higher validation error than the 18 layers plain network. This is where we realize the degradation problem. And the same 34 layer network when converted into the residual network has much lesser training error than the 18 layer residual network.


Python is a cross-platform programming language, which means it runs on all the major operating systems. Any Python program you write should run on any modern computer that has Python installed. However, the methods for setting up Python on different operating systems vary slightly. In this section you’ll learn how to set up Python and run the Hello World program on your own system. You’ll first check whether Python is installed on your system and install it if it’s not. Then you’ll install a simple text edi- tor and save an empty Python file called hello_world.py. Finally, you’ll run the Hello World program and troubleshoot anything that didn’t work. I’ll walk you through this process for each operating system, so you’ll have a beginner-friendly Python programming environment.
Linux systems are designed for programming, so Python is already installed on most Linux computers. The people who write and maintain Linux expect you to do your own programming at some point and encourage you to do so. For this reason there’s very little you have to install and very few settings you have to change to start programming. Checking Your Version of Python Open a terminal window by running the Terminal application on your system (in Ubuntu, you can press ctrl- alt -T). To find out whether Python is installed, enter python with a lowercase p. You should see output telling you which version of Python is installed and a >>> prompt where you can start entering Python commands, like this:
$ python
Python 2.7.6 (default, Mar 22 2014, 22:59:38)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>This output tells you that Python 2.7.6 is currently the default version of Python installed on this computer. When you’ve seen this output, press ctrl-D or enter exit() to leave the Python prompt and return to a terminal prompt. Running Python Programs from a Terminal Most of the programs you write in your text editor you’ll run directly from the editor, but sometimes it’s useful to run programs from a terminal instead. For example, you might want to run an existing program without opening it for editing. You can do this on any system with Python installed if you know how to access the directory where you’ve stored your program file. To try this, make sure you’ve saved the hello_world.py file in the python_work folder on your desktop. Running a Python program from a terminal session is the same on Linux. The terminal command cd, for change directory, is used to navi-gate through your file system in a terminal session. The command ls, for list, shows you all the non-hidden files that exist in the current directory. Open a new terminal window and issue the following commands to run hello_world.py:
u ~$ cd Desktop/python_work/
v ~/Desktop/python_work$ ls
hello_world.py
w ~/Desktop/python_work$ python hello_world.py
Hello Python world!python hello_world.py It’s that simple. You just use the python (or python3) command to run Python programs.
We will discus about the different kinds of data you can work with in your Python programs. You’ll also learn how to store your data in variables and how to use those variables in your programs.
Let’s try using a variable in hello_world.py. Add a new line at the beginning of the file, and modify the second line:
message = "Hello Python world!"
print(message)Run this program to see what happens. You should see the same output you saw previously:
Hello Python world!We’ve added a variable named message. Every variable holds a value, which is the information associated with that variable. In this case the value is the text “Hello Python world!”.Adding a variable makes a little more work for the Python interpreter. When it processes the first line, it associates the text “Hello Python world!” with the variable message. When it reaches the second line, it prints the value associated with message to the screen. Let’s expand on this program by modifying hello_world.py to print a sec- ond message. Add a blank line to hello_world.py, and then add two new lines of code:
message = "Hello Python world!"
print(message)
message = "Hello Python Crash Course world!"
print(message)Now when you run hello_world.py, you should see two lines of output: Hello Python world! Hello Python Crash Course world! You can change the value of a variable in your program at any time, and Python will always keep track of its current value.
When you’re using variables in Python, you need to adhere to a few rules and guidelines. Breaking some of these rules will cause errors; other guide- lines just help you write code that’s easier to read and understand. Be sure to keep the following variable rules in mind:
- Variable names can contain only letters, numbers, and underscores. They can start with a letter or an underscore, but not with a number. For instance, you can call a variable message_1 but not 1_message.
- Spaces are not allowed in variable names, but underscores can be used to separate words in variable names. For example, greeting_message works, but greeting message will cause errors.
- Avoid using Python keywords and function names as variable names; that is, do not use words that Python has reserved for a particular pro- grammatic purpose, such as the word print.
- Variable names should be short but descriptive. For example, name is better than n, student_name is better than s_n, and name_length is better than length_of_persons_name.
- Be careful when using the lowercase letter l and the uppercase letter O because they could be confused with the numbers 1 and 0. It can take some practice to learn how to create good variable names, especially as your programs become more interesting and complicated. As you write more programs and start to read through other people’s code, you’ll get better at coming up with meaningful names. --Note The Python variables you’re using at this point should be lowercase. You won’t get errors if you use uppercase letters, but it’s a good idea to avoid using them for now.
Every programmer makes mistakes, and most make mistakes every day. Although good programmers might create errors, they also know how to respond to those errors efficiently. Let’s look at an error you’re likely to make early on and learn how to fix it. We’ll write some code that generates an error on purpose. Enter the following code, including the misspelled word mesage shown in bold:
message = "Hello Python Crash Course reader!"
print(mesage)When an error occurs in your program, the Python interpreter does its best to help you figure out where the problem is. The interpreter provides a traceback when a program cannot run successfully. A traceback is a record of where the interpreter ran into trouble when trying to execute your code. Here’s an example of the traceback that Python provides after you’ve accidentally misspelled a variable’s name:
Traceback (most recent call last):
File "hello_world.py", line 2, in <module>
print(mesage)
NameError: name 'mesage' is not definedThe output at u reports that an error occurs in line 2 of the file hello_world.py. The interpreter shows this line to help us spot the error quickly v and tells us what kind of error it found w. In this case it found a name error and reports that the variable being printed, mesage, has not been defined. Python can’t identify the variable name provided. A name error usually means we either forgot to set a variable’s value before using it, or we made a spelling mistake when entering the variable’s name. Of course, in this example we omitted the letter s in the variable name message in the second line. The Python interpreter doesn’t spellcheck your code, but it does ensure that variable names are spelled consistently. For example, watch what happens when we spell message incorrectly in another place in the code as well:
mesage = "Hello Python Crash Course reader!"
print(mesage)
In this case, the program runs successfully!
Hello Python Crash Course reader!Computers are strict, but they disregard good and bad spelling. As a result, you don’t need to consider English spelling and grammar rules when you’re trying to create variable names and writing code. Many programming errors are simple, single-character typos in one line of a program. If you’re spending a long time searching for one of these errors, know that you’re in good company. Many experienced and talented programmers spend hours hunting down these kinds of tiny errors. Try to laugh about it and move on, knowing it will happen frequently throughout your programming life.
Because most programs define and gather some sort of data, and then do something useful with it, it helps to classify different types of data. The first data type we’ll look at is the string. Strings are quite simple at first glance, but you can use them in many different ways. A string is simply a series of characters. Anything inside quotes is con- sidered a string in Python, and you can use single or double quotes around your strings like this:
"This is a string."
'This is also a string.'This flexibility allows you to use quotes and apostrophes within your strings: 'I told my friend, "Python is my favorite language!"' "The language 'Python' is named after Monty Python, not the snake." "One of Python's strengths is its diverse and supportive community."
One of the simplest tasks you can do with strings is change the case of the words in a string. Look at the following code, and try to determine what’s happening:
name = "ada lovelace"
print(name.title())Save this file as name.py, and then run it. You should see this output: Ada Lovelace In this example, the lowercase string "ada lovelace" is stored in the variable name. The method title() appears after the variable in the print() state- ment. A method is an action that Python can perform on a piece of data. The dot ( .) after name in name.title() tells Python to make the title() method act on the variable name. Every method is followed by a set of parentheses, because methods often need additional information to do their work. That information is provided inside the parentheses. The title() function doesn’t need any additional information, so its parentheses are empty. title() displays each word in title-case, where each word begins with a capital letter. This is useful because you’ll often want to think of a name as a piece of information. For example, you might want your program to recognize the input values Ada, ADA, and ada as the same name, and display all of them as Ada Several other useful methods are available for dealing with case as well. For example, you can change a string to all uppercase or all lowercase letters like this:
name = "Ada Lovelace"
print(name.upper())
print(name.lower())This will display the following:
ADA LOVELACE
ada lovelaceThe lower() method is particularly useful for storing data. Many times you won’t want to trust the capitalization that your users provide, so you’ll convert strings to lowercase before storing them. Then when you want to display the information, you’ll use the case that makes the most sense for each string.
It’s often useful to combine strings. For example, you might want to store a first name and a last name in separate variables, and then combine them when you want to display someone’s full name:
first_name = "ada"
last_name = "lovelace"
full_name = first_name + " " + last_name
print(full_name)Python uses the plus symbol (+) to combine strings. In this example, we use + to create a full name by combining a first_name, a space, and a last_name u, giving this result:
ada lovelaceThis method of combining strings is called concatenation. You can use concatenation to compose complete messages using the information you’ve stored in a variable. Let’s look at an example:
first_name = "ada"
last_name = "lovelace"
full_name = first_name + " " + last_name
u print("Hello, " + full_name.title() + "!")Here, the full name is used at u in a sentence that greets the user, and the title() method is used to format the name appropriately. This code returns a simple but nicely formatted greeting:
Hello, Ada Lovelace!You can use concatenation to compose a message and then store the entire message in a variable:
first_name = "ada"
last_name = "lovelace"
full_name = first_name + " " + last_name
u message = "Hello, " + full_name.title() + "!"
v print(message)This code displays the message “Hello, Ada Lovelace!” as well, but storing the message in a variable at u makes the final print statement at much simpler.
Numbers are used quite often in programming to keep score in games, rep- resent data in visualizations, store information in web applications, and so on. Python treats numbers in several different ways, depending on how they are being used. Let’s first look at how Python manages integers, because they are the simplest to work with.
You can add (+), subtract (-), multiply ( *), and divide ( /) integers in Python.
>>>
2 + 3
5
>>>
3 - 2
1
>>>
2 * 3
6
>>>
3 / 2
1.5In a terminal session, Python simply returns the result of the operation. Python uses two multiplication symbols to represent exponents:
>>> 3 ** 2
9
>>> 3 ** 3
27
>>> 10 ** 6
1000000Python supports the order of operations too, so you can use multiple operations in one expression. You can also use parentheses to modify the order of operations so Python can evaluate your expression in the order you specify. For example:
>>> 2 + 3*4
14
>>> (2 + 3) * 4
20The spacing in these examples has no effect on how Python evaluates the expressions; it simply helps you more quickly spot the operations that have priority when you’re reading through the code.
Python calls any number with a decimal point a float. This term is used in most programming languages, and it refers to the fact that a decimal point can appear at any position in a number. Every programming language must be carefully designed to properly manage decimal numbers so numbers behave appropriately no matter where the decimal point appears. For the most part, you can use decimals without worrying about how they behave. Simply enter the numbers you want to use, and Python will most likely do what you expect:
>>>
0.1 + 0.1
0.2
>>>
0.2 + 0.2
0.4
>>>
2 * 0.1
0.2
>>>
2 * 0.2
0.4But be aware that you can sometimes get an arbitrary number of decimal places in your answer:
>>> 0.2 + 0.1
0.30000000000000004
>>> 3 * 0.1
0.30000000000000004This happens in all languages and is of little concern. Python tries to find a way to represent the result as precisely as possible, which is sometimes difficult given how computers have to represent numbers internally.
A list is a collection of items in a particular order. You can make a list that includes the letters of the alphabet, the digits from 0–9, or the names of all the people in your family. You can put anything you want into a list, and bicycles.py the items in your list don’t have to be related in any particular way. Because a list usually contains more than one element, it’s a good idea to make the name of your list plural, such as letters, digits, or names.
In Python, square brackets ([]) indicate a list, and individual elements in the list are separated by commas. Here’s a simple example of a list that contains a few kinds of bicycles:
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
print(bicycles)If you ask Python to print a list, Python returns its representation of the list, including the square brackets:
['trek', 'cannondale', 'redline', 'specialized']Because this isn’t the output you want your users to see, let’s learn how to access the individual items in a list.
Lists are ordered collections, so you can access any element in a list by telling Python the position, or index, of the item desired. To access an ele- ment in a list, write the name of the list followed by the index of the item enclosed in square brackets. For example, let’s pull out the first bicycle in the list bicycles: ```sh bicycles = ['trek', 'cannondale', 'redline', 'specialized'] u print(bicycles[0])
The syntax for this is shown at u. When we ask for a single item from a list, Python returns just that element without square brackets or quotation marks: ```sh
trek
This is the result you want your users to see—clean, neatly formatted output. You can also use the string methods from Chapter 2 on any element in a list. For example, you can format the element 'trek' more neatly by using the title() method:
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
print(bicycles[0].title())This example produces the same output as the preceding example except 'Trek' is capitalized.
Python considers the first item in a list to be at position 0, not position 1. This is true of most programming languages, and the reason has to do with how the list operations are implemented at a lower level. If you’re receiving unexpected results, determine whether you are making a simple off-by-one error. The second item in a list has an index of 1. Using this simple counting system, you can get any element you want from a list by subtracting one from its position in the list. For instance, to access the fourth item in a list, you request the item at index 3. The following asks for the bicycles at index 1 and index 3:
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
print(bicycles[1])
print(bicycles[3])This code returns the second and fourth bicycles in the list:
cannondale
specializedPython has a special syntax for accessing the last element in a list. By asking for the item at index -1, Python always returns the last item in the list:
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
print(bicycles[-1])This code returns the value 'specialized'. This syntax is quite useful, because you’ll often want to access the last items in a list without knowing exactly how long the list is. This convention extends to other negative index values as well. The index -2 returns the second item from the end of the list, the index -3 returns the third item from the end, and so forth. Using Individual Values from a List You can use individual values from a list just as you would any other vari- able. For example, you can use concatenation to create a message based on a value from a list. Let’s try pulling the first bicycle from the list and composing a message using that value.
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
u message = "My first bicycle was a " + bicycles[0].title() + "."
print(message)we build a sentence using the value at bicycles[0] and store it in the variable message. The output is a simple sentence about the first bicycle in the list: My first bicycle was a Trek.
Try these short programs to get some firsthand experience with Python’s lists. You might want to create a new folder for each chapter’s exercises to keep them organized.
Names: Store the names of a few of your friends in a list called names. Print each person’s name by accessing each element in the list, one at a time.
Greetings: Start with the list you used in Exercise 3-1, but instead of just printing each person’s name, print a message to them. The text of each mes- sage should be the same, but each message should be personalized with the person’s name.
Your Own List: Think of your favorite mode of transportation, such as a motorcycle or a car, and make a list that stores several examples. Use your list to print a series of statements about these items, such as “I would like to own a Honda motorcycle.”
Most lists you create will be dynamic, meaning you’ll build a list and then add and remove elements from it as your program runs its course. For example, you might create a game in which a player has to shoot aliens out of the sky. You could store the initial set of aliens in a list and then remove an alien from the list each time one is shot down. Each time a new alien appears on the screen, you add it to the list. Your list of aliens will decrease and increase in length throughout the course of the game.
The syntax for modifying an element is similar to the syntax for accessing an element in a list. To change an element, use the name of the list followed by the index of the element you want to change, and then provide the new value you want that item to have. For example, let’s say we have a list of motorcycles, and the first item in the list is 'honda' . How would we change the value of this first item?
motorcycles.py u motorcycles = ['honda', 'yamaha', 'suzuki']
print(motorcycles)
v motorcycles[0] = 'ducati'
print(motorcycles)The code at u defines the original list, with 'honda' as the first element. The code at v changes the value of the first item to 'ducati'. The output shows that the first item has indeed been changed, and the rest of the list stays the same:
['honda', 'yamaha', 'suzuki']
['ducati', 'yamaha', 'suzuki']You can change the value of any item in a list, not just the first item. Adding Elements to a List You might want to add a new element to a list for many reasons. For example, you might want to make new aliens appear in a game, add new data to a visualization, or add new registered users to a website you’ve built. Python provides several ways to add new data to existing lists.
The simplest way to add a new element to a list is to append the item to the list. When you append an item to a list, the new element is added to the end of the list. Using the same list we had in the previous example, we’ll add the new element 'ducati' to the end of the list:
motorcycles = ['honda', 'yamaha', 'suzuki']
print(motorcycles)
umotorcycles.append('ducati')
print(motorcycles)The append() method at u adds 'ducati' to the end of the list without affecting any of the other elements in the list:
['honda', 'yamaha', 'suzuki']
['honda', 'yamaha', 'suzuki', 'ducati']The append() method makes it easy to build lists dynamically. For example, you can start with an empty list and then add items to the list using a series of append() statements. Using an empty list, let’s add the elements 'honda', 'yamaha', and 'suzuki' to the list:
motorcycles = []
motorcycles.append('honda')
motorcycles.append('yamaha')
motorcycles.append('suzuki')
print(motorcycles)The resulting list looks exactly the same as the lists in the previous examples:
['honda', 'yamaha', 'suzuki']Building lists this way is very common, because you often won’t know the data your users want to store in a program until after the program is running. To put your users in control, start by defining an empty list that will hold the users’ values. Then append each new value provided to the list you just created.
You can add a new element at any position in your list by using the insert() method. You do this by specifying the index of the new element and the value of the new item. ```sh motorcycles = ['honda', 'yamaha', 'suzuki'] u motorcycles.insert(0, 'ducati') print(motorcycles)
In this example, the code at u inserts the value 'ducati' at the begin- ning of the list. The insert() method opens a space at position 0 and stores the value 'ducati' at that location. This operation shifts every other value in the list one position to the right:
```sh
['ducati', 'honda', 'yamaha', 'suzuki']
Often, you’ll want to remove an item or a set of items from a list. For example, when a player shoots down an alien from the sky, you’ll most likely want to remove it from the list of active aliens. Or when a user decides to cancel their account on a web application you created, you’ll want to remove that user from the list of active users. You can remove an item according to its position in the list or according to its value.
If you know the position of the item you want to remove from a list, you can use the del statement.
motorcycles = ['honda', 'yamaha', 'suzuki']
print(motorcycles)
del motorcycles[0]
print(motorcycles)The code at u uses del to remove the first item, 'honda', from the list of motorcycles:
['honda', 'yamaha', 'suzuki']
['yamaha', 'suzuki']motorcycles = ['honda', 'yamaha', 'suzuki']
print(motorcycles)
popped_motorcycle = motorcycles.pop()
print(motorcycles)
print(popped_motorcycle)We start by defining and printing the list motorcycles at u. At v we pop a value from the list and store that value in the variable popped_motorcycle. We print the list at w to show that a value has been removed from the list. Then we print the popped value at x to prove that we still have access to the value that was removed. The output shows that the value 'suzuki' was removed from the end of the list and is now stored in the variable popped_motorcycle:
['honda', 'yamaha', 'suzuki']
['honda', 'yamaha']
suzukiComputer Vision can be defined as a discipline that explains how to reconstruct, interrupt, and understand a 3D scene from its 2D images, in terms of the properties of the structure present in the scene. It deals with modeling and replicating human vision using computer software and hardware. Computer Vision overlaps significantly with the following fields −ll
• Image Processing − It focuses on image manipulation.
• Pattern Recognition − It explains various techniques to classify patterns.
• Photogrammetry − It is concerned with obtaining accurate measurements from images.
Image processing deals with image-to-image transformation. The input and output of image processing are both images. Computer vision is the construction of explicit, meaningful descriptions of physical objects from their image. The output of computer vision is a description or an interpretation of structures in 3D scene. Applications of Computer Vision Here we have listed down some of major domains where Computer Vision is heavily used. Robotics Application
• Localization − Determine robot location automatically
• Navigation
• Obstacles avoidance
• Assembly (peg-in-hole, welding, painting)
• Manipulation (e.g. PUMA robot manipulator)
• Human Robot Interaction (HRI) − Intelligent robotics to interact with and serve people
• Classification and detection (e.g. lesion or cells classification and tumor detection)
• 2D/3D segmentation
• 3D human organ reconstruction (MRI or ultrasound)
• Vision-guided robotics surgery
• Industrial inspection (defect detection)
• Assembly
• Barcode and package label reading
• Object sorting
• Document understanding (e.g. OCR)
• Biometrics (iris, finger print, face recognition)
• Surveillance − Detecting certain suspicious activities or behaviors Transportation Application
• Autonomous vehicle
• Safety, e.g., driver vigilance monitoring Features of OpenCV Library
• Read and write images
• Capture and save videos
• Process images (filter, transform)
• Perform feature detection
• Detect specific objects such as faces, eyes, cars, in the videos or images.
• Analyze the video, i.e., estimate the motion in it, subtract the background, and track objects in it. OpenCV was originally developed in C++. In addition to it, Python and Java bindings were provided. OpenCV runs on various Operating Systems such as windows, Linux, OSx, FreeBSD, Net BSD, Open BSD, etc. This tutorial explains the concepts of OpenCV with examples using Java bindings. OpenCV Library Modules Following are the main library modules of the OpenCV library.
This module covers the basic data structures such as Scalar, Point, Range, etc., that are used to build OpenCV applications. In addition to these, it also includes the multidimensional array Mat, which is used to store the images. In the Java library of OpenCV, this module is included as a package with the name org.opencv.core.
This module covers various image processing operations such as image filtering, geometrical image transformations, color space conversion, histograms, etc. In the Java library of OpenCV, this module is included as a package with the name org.opencv.imgproc.
This module covers the video analysis concepts such as motion estimation, background subtraction, and object tracking. In the Java library of OpenCV, this module is included as a package with the name org.opencv.video.
This module explains the video capturing and video codecs using OpenCV library. In the Java library of OpenCV, this module is included as a package with the name org.opencv.videoio.
This module includes algorithms regarding basic multiple-view geometry algorithms, single and stereo camera calibration, object pose estimation, stereo correspondence and elements of 3D reconstruction. In the Java library of OpenCV, this module is included as a package with the name org.opencv.calib3d.
This module includes the concepts of feature detection and description. In the Java library of OpenCV, this module is included as a package with the name org.opencv.features2d.
This module includes the detection of objects and instances of the predefined classes such as faces, eyes, mugs, people, cars, etc. In the Java library of OpenCV, this module is included as a package with the name org.opencv.objdetect.
This is an easy-to-use interface with simple UI capabilities. In the Java library of OpenCV, the features of this module is included in two different packages namely, org.opencv.imgcodecs and org.opencv.videoio.