Agent Skill Harbor is a skill management platform for teams and organizations.
It helps teams collect, share, audit, and publish AI agent skills across repositories, with provenance tracking, governance support, and safety checks built in.
It is designed to be serverless, DB-less, and Git- and GitHub-native, because skills are mostly text artifacts that already fit naturally in Git.
| Card View | List View |
|---|---|
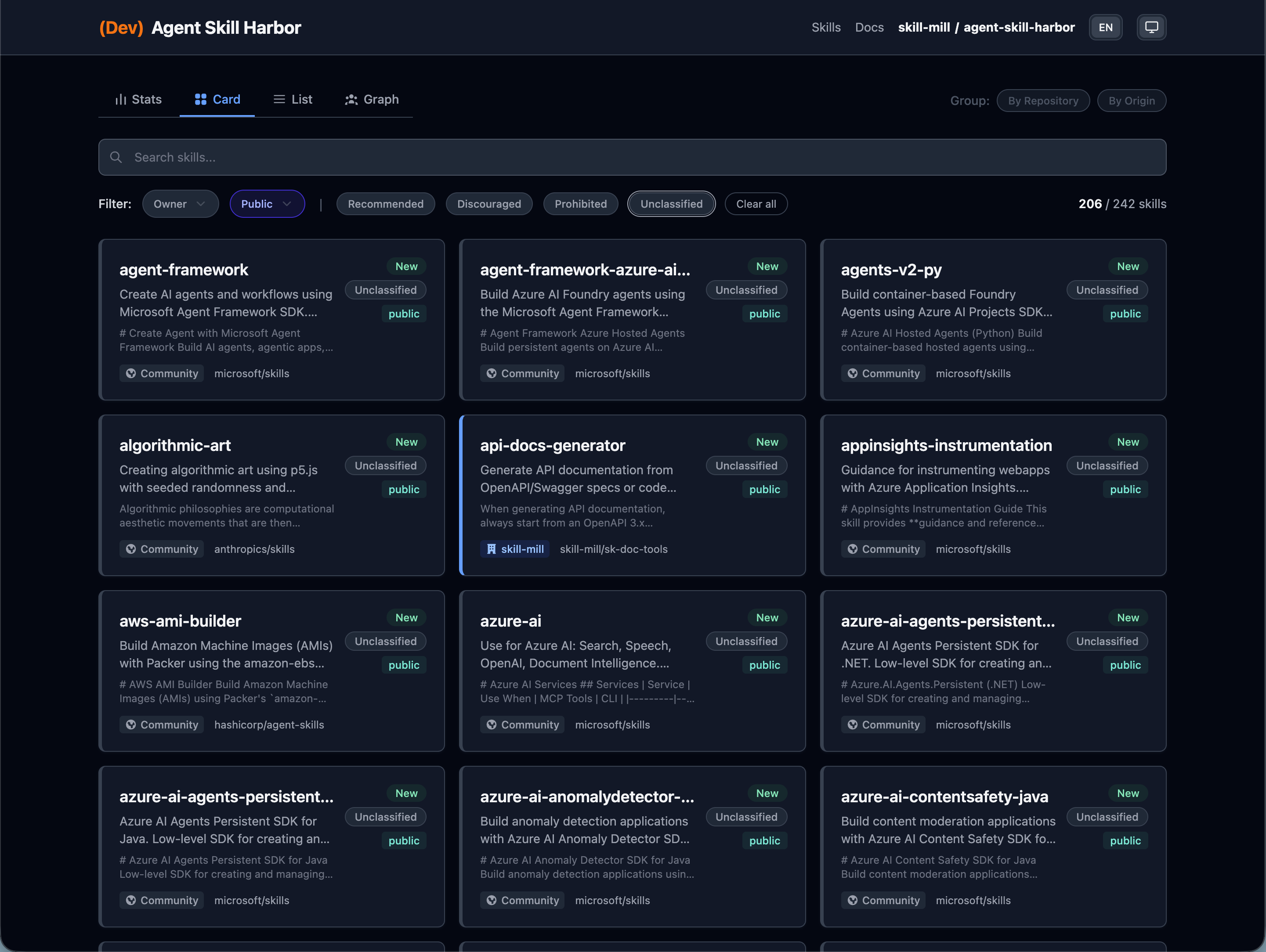 |
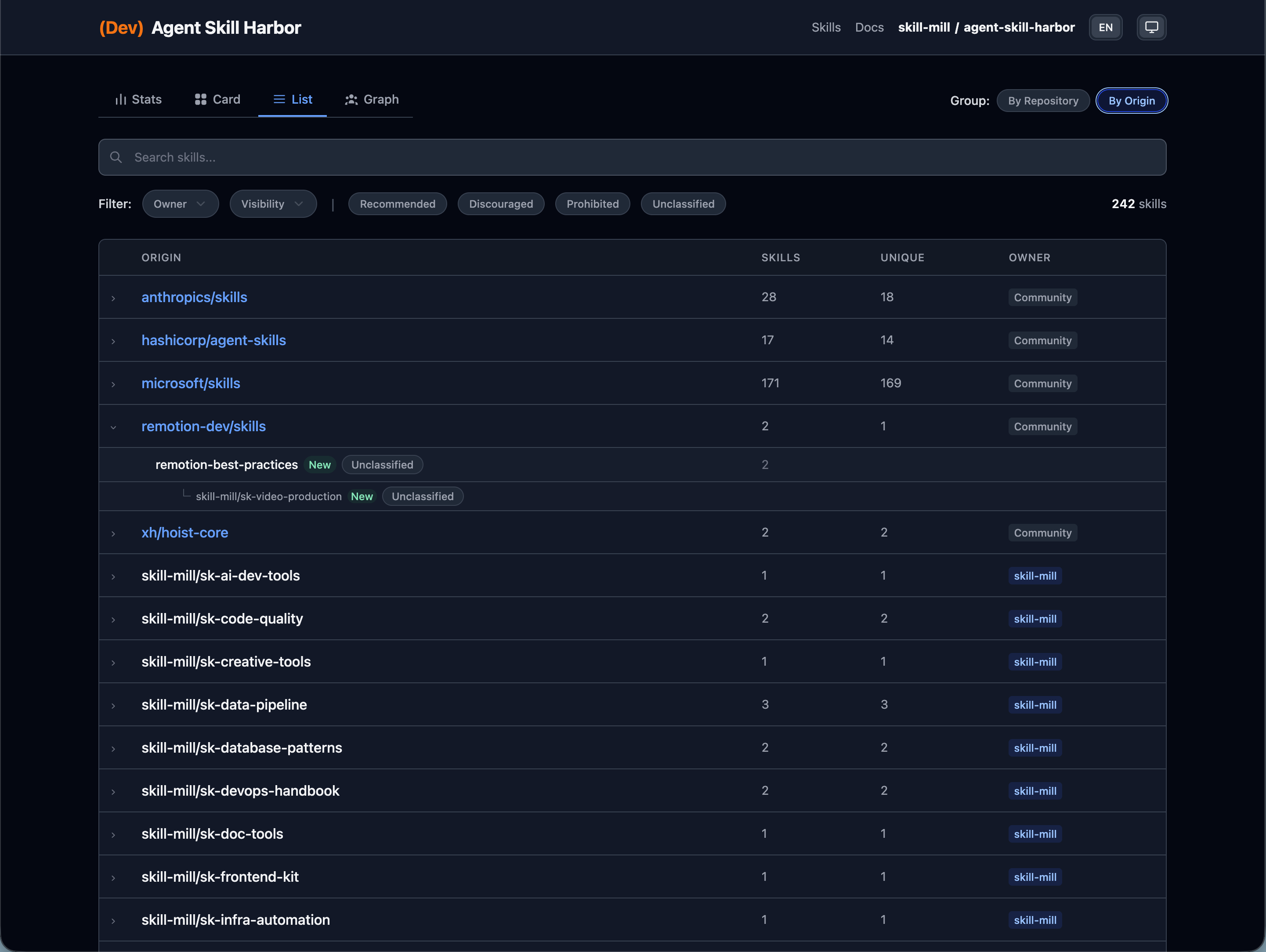 |

- Skill cataloging: collect and publish AI agent skills across repositories
- Governance: mark skills as recommended, discouraged, or prohibited
- Provenance: track copied or installed skills back to their origin
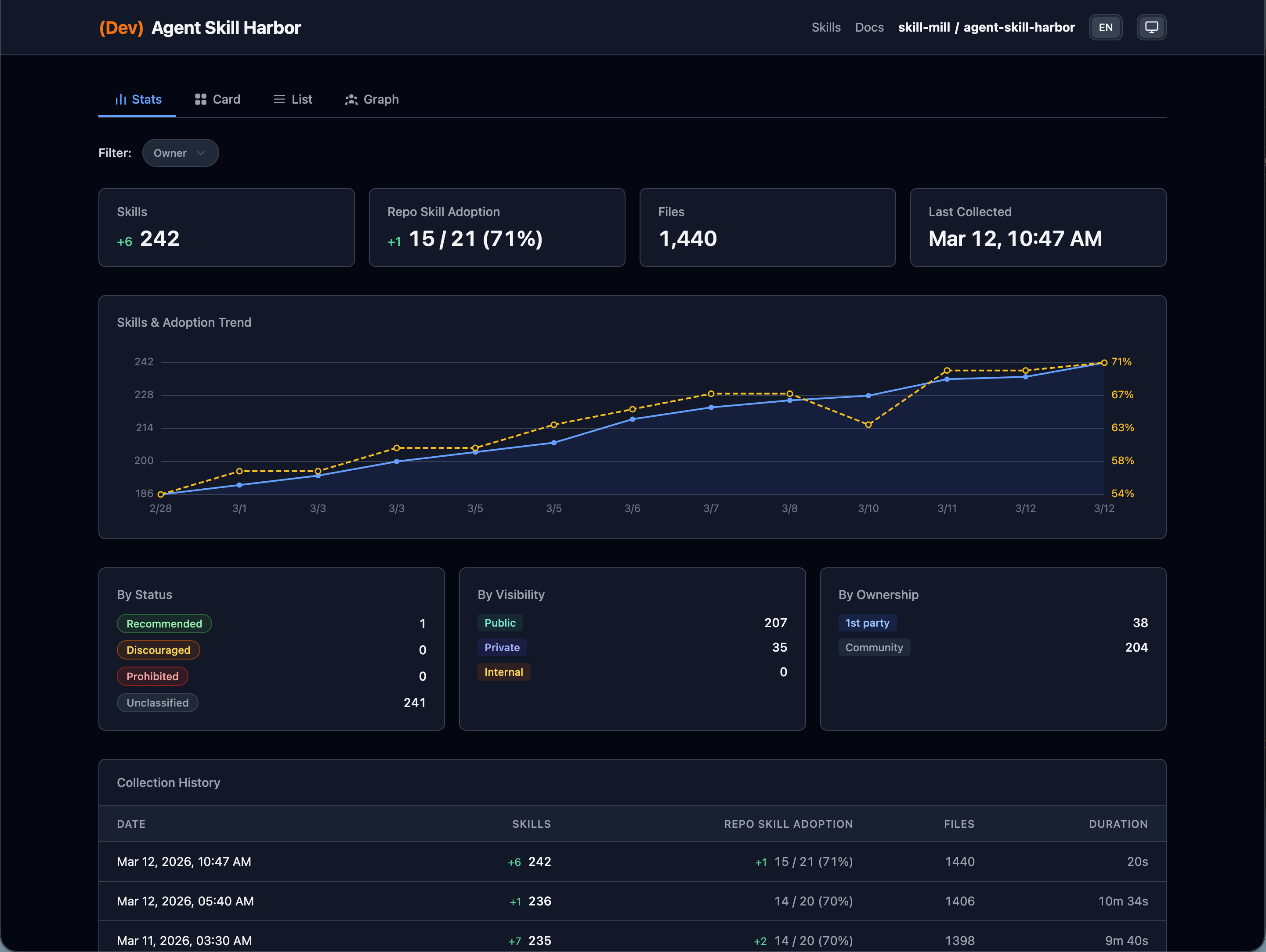
- Skill analysis:
builtin.audit-skill-scanneranalyzes collected skills and audits safety - Slack notification:
builtin.notify-slacksends post-collection summaries
- Serverless: the catalog UI is a prerendered static web app
- DB-less & Git-native: collected data is stored in
data/as YAML/JSON and committed back to Git - GitHub-native: data is updated with GitHub Actions and hosted on GitHub Pages
Demo site:
npx agent-skill-harbor init my-skill-harbor
cd my-skill-harbor
pnpm install
pnpm install --dir collector
# edit .env and set GH_ORG
gh auth login && GH_TOKEN=$(gh auth token) pnpm collect
# Or edit .env and set GH_TOKEN, then run:
# pnpm collect
pnpm devpnpm install installs the root package (agent-skill-harbor) for CLI + web.
pnpm install --dir collector installs the collector runtime used by pnpm collect and pnpm post-collect.
When installed, the main CLI is available as harbor or agent-skill-harbor.
| Command | Description |
|---|---|
harbor init [dir] |
Scaffold a new project |
harbor setup <plugin-id> |
Scaffold optional plugin runtime files |
Daily project operations are exposed through the generated root scripts:
pnpm collect
pnpm post-collect
pnpm dev
pnpm build
pnpm preview- Create a new project with
npx agent-skill-harbor init. - Push it to a private repository in your organization.
- Configure
GH_TOKENas a GitHub Actions secret. - Enable GitHub Pages or Cloudflare Pages.
- Run the generated
CollectSkillsworkflow once.
The generated CollectSkills workflow is a thin caller pinned to Harbor's reusable workflow at wf-v0.
Inside the reusable workflow:
collectinstalls onlycollector/core dependencies and runs collectionpost_collectrestores the collected artifact, installscollector/core dependencies again, then installs only enabled optional plugin manifests- the final
data/directory is committed back to the repository
This keeps GitHub collection and optional post-collect dependencies structurally separate.
See Organization Setup for details.
my-skill-harbor/
├── .github/workflows/
│
├── config/
│ ├── harbor.yaml # General application settings
│ └── governance.yaml # Additional governance settings
│
├── collector/ # Batch processing for skill collection
│ ├── package.json
│ └── plugins/
│ └── <plugin-id>/ # Per-plugin manifests and code
│
├── data/
│ ├── assets/
│ ├── collects.yaml # History of skill collection runs
│ ├── plugins/ # Outputs produced by each plugin
│ ├── skills.yaml # Index of collected skills
│ └── skills/ # Cached files for collected skills
│
├── .env
│
├── guide/
│
└── package.json # Manifest for the web UINotes:
- root
package.jsondepends only onagent-skill-harbor collector/package.jsonis a Harbor-managed runtime manifest foragent-skill-harbor-collector- optional plugin manifests and example user-defined plugins live under
collector/plugins/<plugin-id>/
Built-in plugins are enabled from config/harbor.yaml.
Examples:
builtin.detect-driftbuiltin.notify-slackbuiltin.audit-promptfoo-securitybuiltin.audit-skill-scanner
Optional runtime files are scaffolded with harbor setup:
harbor setup example-user-defined-plugin
harbor setup builtin.audit-promptfoo-security
harbor setup builtin.audit-skill-scannerGenerated files go under collector/plugins/<plugin-id>/.
See Post-Collect Plugins.
- Organization Setup
- Skill Catalog Guide
- Post-Collect Plugins
- Governance Guide
- Local Development
- Release
Yes. Harbor mainly stores text data such as YAML, JSON, Markdown, and cached skill files. It does not assume large multimedia assets like images or videos, and the total volume is usually limited enough that Git's compression works well.
GitHub's official documentation says repositories should ideally stay under 1 GB, and keeping them under 5 GB is strongly recommended. In Harbor's case, reaching that scale is highly unlikely unless you intentionally store large non-text assets or collect an unusually large amount of unrelated data.
See GitHub Docs: About large files on GitHub
Yes, absolutely. You can use Harbor to collect, manage, and catalog skills across your own repositories.
The main caveat is hosting. For personal use, GitHub Pages cannot be private, so you would likely want to host the generated site somewhere else you control securely. If there is enough demand, the documentation and workflows can be expanded to support that path more explicitly.
Or you may simply decide to publish your own skill catalog openly and not worry about that. That is entirely up to you.
Yes. The Agent Skills specification is shared across agents, but there is no restriction on YAML frontmatter keys that are not defined by the standard. In practice, agents often carry their own custom properties, and unknown properties are generally ignored.
Also, the _from property used by Harbor typically consumes only around 10 to 20 tokens. Even if a project loads dozens of skills, the impact is usually negligible.
MIT